A Guide to Large Language Models for Non-Engineers
A large language model is a highly advanced artificial intelligence system trained on massive datasets to predict and generate human-like language. By calculating the mathematical probability of which word should logically come next in a sequence, these systems can answer complex questions, write functional software code, translate languages, and automate sophisticated analytical tasks across industries.
The Foundations of Artificial Language
To understand how modern artificial intelligence operates, one must first demystify the core mechanism driving it. Large language models (LLMs) are often perceived by the general public as thinking entities, but at their foundation, they function as giant statistical prediction engines 1. When a user types a prompt into a conversational interface, the system does not "read" the text in a human sense, nor does it search a hardcoded database of pre-written answers. Instead, it predicts the most mathematically probable next piece of text, one fragment at a time, based on statistical patterns it absorbed during its training phase 23.
This concept is often compared to the autocomplete feature on a smartphone keyboard, but scaled up billions of times 3. Where a phone might predict that the word "Happy" is generally followed by "Birthday," a large language model can predict that a complex legal premise should be followed by a specific contractual clause, or that a specific mathematical formula requires a specific programmatic function. This prediction loop happens thousands of times per second, creating the profound illusion of intelligent, continuous thought 3.
The tendency for humans to attribute sentience to language-generating machines has deep psychological roots. In 1966, an early computer program named ELIZA was designed to simulate a Rogerian psychotherapist using relatively simple pattern-matching rules and scripted responses 4. Users quickly formed deep emotional bonds with the software, even asking researchers to leave the room so they could converse in private, demonstrating that humans are naturally wired to perceive intelligence and empathy in anything that can sustain a coherent conversation 4.
Modern large language models are vastly more sophisticated than ELIZA, leveraging deep learning techniques and neural networks with billions of parameters, but they share a fundamental underlying limitation. Despite their remarkable fluency, they do not possess a genuine, grounded understanding of the physical world or the underlying meaning of the content they process 25. They rely entirely on statistical correlations derived from their training data rather than true comprehension, which makes them highly capable of generating plausible, useful text, but equally capable of generating confident, nonsensical errors when they encounter unfamiliar scenarios 2.
The Mechanics of Machine Reading
The word "large" in the term large language model refers to two distinct but connected metrics: the immense volume of data the model was trained on, and the sheer number of "parameters" inside the model's neural network architecture 13. Parameters act as tunable computational dials or artificial synapses that hold the statistical relationships between words. Modern frontier models feature hundreds of billions, or even trillions, of these parameters, allowing them to capture highly nuanced dependencies in human language 35.
The Tokenization Process
Before a neural network can process human language, it must convert text into a mathematical format. This is achieved through a critical preprocessing step known as tokenization. A "token" is the fundamental atomic unit of data that a large language model reads and generates 13. Contrary to popular belief, a token is not always a full word. It is often a chunk of a word or a subword, comprising roughly three-quarters of a standard English word on average 3.
When a user submits a prompt, the system mathematically chops the text into these token fragments and assigns each a unique numerical ID 16. For example, the word "unbelievable" might be split into "un", "believ", and "able". Once tokenized, these numbers are mapped into a high-dimensional mathematical space known as an embedding. In this embedding space, tokens with similar meanings, grammatical roles, or contexts are placed close together geometrically 8. Through this spatial mapping, meaning becomes independent of format; the model does not differentiate between the word "bank" as a financial institution and "bank" as a river edge until it mathematically observes the surrounding tokens to establish the correct context 69.
The Multilingual Gap and the Tokenization Tax
The mechanics of tokenization explain one of the most persistent shortcomings in modern artificial intelligence: the severe performance degradation that occurs when models process non-English languages 7. Despite their global reach, large language models possess a structural bias toward English. While a lack of diverse training data plays a role, researchers have identified that over 70% to 80% of multilingual failures stem from fundamental architectural limitations, specifically tokenizer inefficiency 7.
Because the dominant foundational models have historically been built by English-speaking engineering teams and trained predominantly on English-centric corpora, their tokenizers are heavily optimized for English syntax and morphology 1112. When processing a morphologically rich or non-Latin script language, the tokenizer often performs severe "oversegmentation" 12. For instance, a single word in Arabic, or an agglutinative word in Korean where grammatical particles are attached to root words, might be sliced into numerous arbitrary, meaningless token fragments 1213. In languages like Chinese or Japanese, which lack the white spaces that clearly separate words in English, the model struggles to identify linguistic boundaries, further compounding the issue 13.
This dynamic creates a severe "tokenization tax" that disproportionately impacts low-resource languages 14. If an Arabic sentence requires three times as many tokens to express the exact same thought as an English sentence, it fragments the model's attention 7. The model must expend significant computational effort simply reconstructing the basic morphology of the word before it can even begin to understand the higher-level context 1213. Consequently, in long conversational workflows, reasoning accuracy in non-English languages drops significantly faster than in English, as the highly dense, fragmented input quickly exhausts the model's working memory 7.
Furthermore, because complex reasoning pathways are primarily formed using English training data, models often attempt to "think" in English internally. When asked a complex question in a target language, the model will often map the prompt to its English latent space, perform the logical deduction in English, and then translate the final output back to the user, introducing further opportunities for logical breakdown 78.
Inside the Transformer Architecture
The current era of artificial intelligence is built almost entirely upon a specific neural network architecture known as the Transformer, introduced by researchers in a seminal 2017 paper titled "Attention Is All You Need" 2416.
Before the advent of Transformers, AI systems processed sequential data using Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks 41617. These older architectures processed text sequentially, reading from left to right 17. This created a severe computational bottleneck. Because they processed one word at a time, RNNs often suffered from a vanishing gradient problem, meaning they "forgot" the context of the beginning of a long paragraph by the time they reached the end 1617.
The Transformer architecture solved this sequential memory bottleneck by allowing the model to process all tokens in a sequence simultaneously 216. By removing the sequential requirement, Transformers became highly parallelizable, meaning they could take full advantage of modern graphics processing units (GPUs) to ingest ridiculous amounts of training data at unprecedented speeds 16. The key to this parallel processing power is a mathematical mechanism known as "self-attention."
The Self-Attention Mechanism
The self-attention mechanism allows the model to dynamically focus on the most relevant parts of the entire input sequence when deciding how to process a specific token, regardless of how far apart those words are in the text 817.
To intuitively understand attention, one can use the analogy of a group discussion. In the older sequential models, the dynamic was akin to each person having to listen to the previous speaker and then add their thoughts one after the other, causing early information to dilute as the chain grew longer 17. The Transformer, however, creates an environment where everyone in the room has the ability to listen to everyone else simultaneously, focusing their attention only on the specific voices that are most relevant to what they want to say next 17.
Under the hood, self-attention operates using a sophisticated system of linear algebra, specifically utilizing Queries, Keys, and Values 818. * The Query: Represents what a specific token is looking for in the surrounding sentence. * The Key: Represents the information or context that other tokens are exposing or offering. * The Value: Represents the actual content or semantic payload the token carries.
If the input is the sentence, "The sun was setting over the hills, and the sky was ___," the model must predict the blank 8. The token representing the blank vector mathematically sends out a "Query." The surrounding words in the context window, such as "sun," "setting," and "sky," present matching "Keys." The attention mechanism calculates the dot product between these queries and keys to determine relevance, assigns them high attention weights, and pulls their corresponding "Values" 817. This computation informs the model that words like "orange," "pink," or "dark" are highly probable next tokens 818.
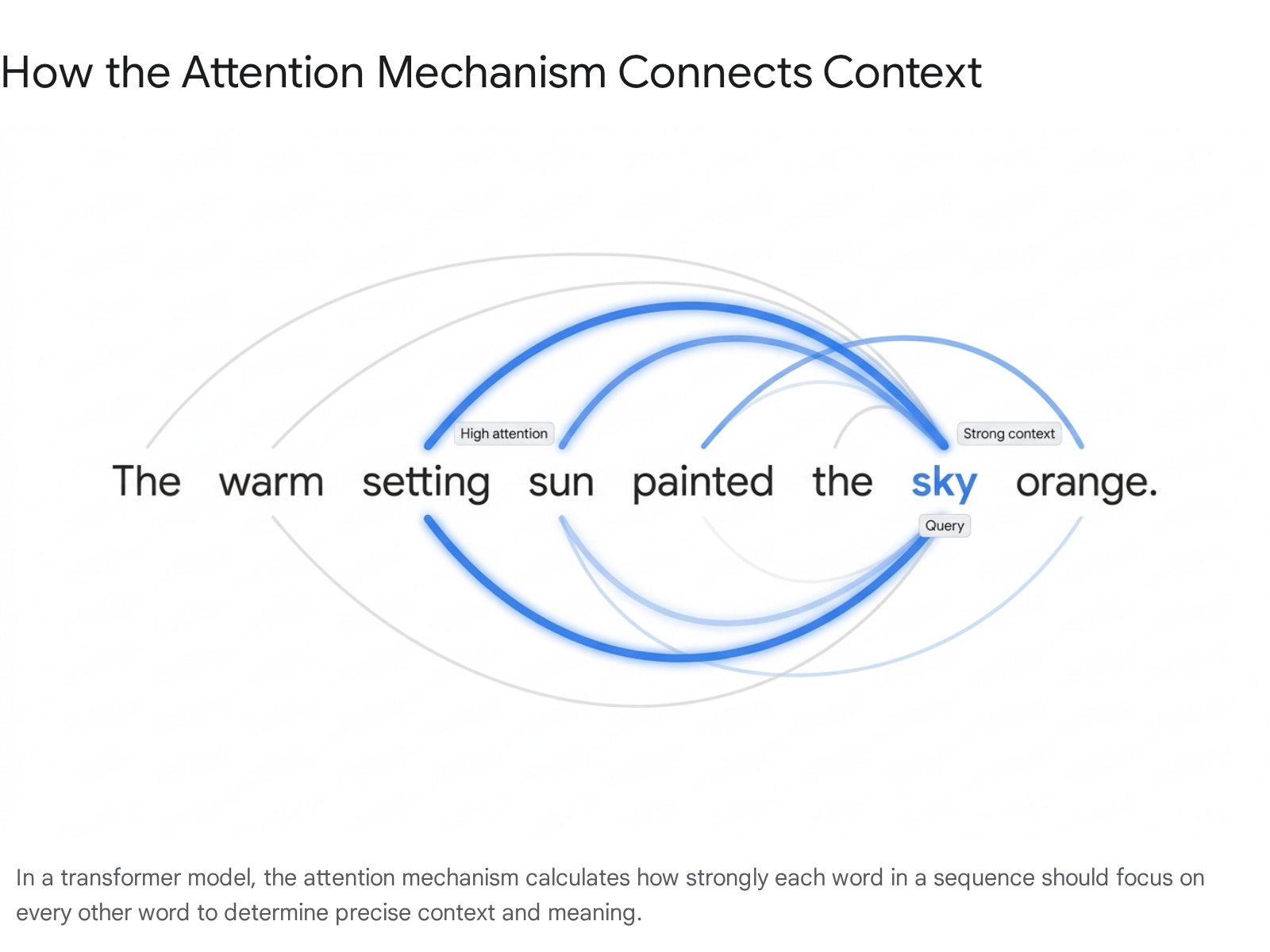
Multi-Head Attention and Positional Encoding
Looking at relationships from just one perspective might not capture all the nuances in the data. To address this, Transformers utilize "multi-head attention" 17. By running several attention mechanisms in parallel, the model can simultaneously learn vastly different types of relationships within the exact same input sequence. One attention head might focus strictly on grammatical structure (linking verbs to subjects), another might track the timeline of events, and a third might focus on the emotional tone of the paragraph 17.
Because the Transformer processes all words simultaneously rather than sequentially, it natively has no concept of word order 16. To solve this, engineers add "positional encodings" to the input embeddings 16. These mathematical markers inject information about the relative or absolute position of each token in the sequence, ensuring that the model understands the critical difference between "the dog bit the man" and "the man bit the dog."
While attention is exceptionally powerful, it scales quadratically; for a sequence of length L, the computational work required is L-squared 9. This mathematical reality makes it difficult to scale traditional transformers to extremely long sequences, such as reading an entire book, prompting ongoing research into "linear transformers" and hybrid models that attempt to bypass this computational bottleneck 9.
The Training Lifecycle of a Language Model
A large language model is not born with knowledge; it must be methodically trained through a multi-stage lifecycle that transforms raw internet text into a helpful, conversational agent 1. This process is highly resource-intensive, requiring immense amounts of data, specialized hardware, energy, and human expertise 1.
Phase 1: Unsupervised Pre-training
The foundation of any LLM is built during the pre-training phase. Here, the model is exposed to a massive corpus of text - often billions or trillions of words - and tasked with a simple objective: predicting the next token in the sequence 12. During this phase, the model absorbs the statistical structure of language, learning grammar, facts, reasoning patterns, and a broad representation of human knowledge 220.
The datasets used for pre-training are staggering in scale. One of the most critical resources is Common Crawl, a public domain archive that scrapes the internet monthly. The March 2026 Common Crawl dataset, for example, contained over 344 terabytes of text spanning nearly 2 billion web pages 2122. Because raw internet data is highly noisy, teams apply aggressive quality filtering pipelines to remove boilerplate code, duplication, and undesirable content 122. Derivative datasets, such as Google's Colossal Cleaned Corpus (C4) or EleutherAI's The Pile, are frequently used to provide high-quality English text for base models 22.
For specialized domains, models are trained on highly curated corpora. Coding models rely heavily on datasets like The Stack v2, which contains over 67 terabytes of permissively licensed source code across 600 programming languages 21. Medical reasoning models are trained on specialized datasets like MIMIC-IV, which contains millions of de-identified clinical records, discharge summaries, and radiology reports, embedding specialized healthcare terminology that general web scraping cannot replicate 21.
During pre-training, the model adjusts its billions of internal parameters through an algorithmic process called backpropagation 2. By comparing its prediction to the actual text in the training data, the model calculates its error rate and iteratively adjusts the weights of its neural network to minimize that error over time 2.
Phase 2: Instruction Tuning
A base model that has only completed pre-training is essentially a highly advanced document completer. If a user inputs "Write a recipe for a chocolate cake," a base model might simply output "Write a recipe for vanilla frosting," mimicking the structure of an internet list rather than fulfilling the command 23.
To make the model useful, it undergoes "instruction tuning" 20. In this phase, the model is fine-tuned on thousands of high-quality, curated examples of specific prompts and desired responses. Datasets like OpenHermes 2.5, which contains synthetic instructions covering coding, math, and general conversation, are used to teach the model how to behave as an assistant that follows directions and formats its outputs correctly 21.
Phase 3: Alignment and RLHF
The final phase involves aligning the model's behavior with human values, ensuring it is helpful, honest, and harmless 20. The dominant technique for this is Reinforcement Learning from Human Feedback (RLHF) 620.
In RLHF, the model generates multiple different responses to a single prompt. Human annotators or highly specialized AI supervisors then rank these responses from best to worst 24. These rankings are used to train a separate "reward model," which assigns a numerical helpfulness score to any output 24. The main LLM is then optimized using reinforcement learning algorithms, such as Proximal Policy Optimization (PPO), to consistently generate text that yields high scores from the reward model 24.
This alignment phase is critical for enterprise deployment, as raw models frequently exhibit baked-in biases or generate toxic outputs 24. By relying on expert curation rather than raw data volume, techniques like RLHF dramatically reduce the hallucination rate and improve task accuracy 24.
The Data Wall and the Limits of Scaling Laws
For the better part of a decade, the artificial intelligence industry operated under a predictable paradigm known as "scaling laws" 2510. Established by seminal research papers such as OpenAI's Kaplan laws in 2020 and DeepMind's Chinchilla laws in 2022, these empirical power-law equations demonstrated that a model's performance improved predictably simply by scaling up three factors: the number of parameters in the model, the volume of training data, and the amount of compute budget allocated 25. The Chinchilla laws notably proved that model size and data volume must be scaled equally, suggesting an optimal ratio of roughly 20 training tokens for every parameter in the model 25.
This catechism - that bigger models are inherently better - powered a massive race to construct trillion-parameter systems and billion-dollar data centers 2527. However, as the industry progressed through 2025 and 2026, research from Stanford University and multiple frontier labs converged on a sobering reality: the exponential returns from brute-force scaling had begun to flatten 1028.
Exhausting the Human Internet
The most pressing constraint on scaling laws is physical data exhaustion. LLMs are voracious consumers of text, and there is a finite limit to the amount of high-quality, human-generated data in existence 11. Researchers estimating the effective stock of quality and repetition-adjusted human text place the global limit at roughly 300 trillion tokens 11.
As companies race to ingest books, code repositories, and public forums, models are consuming data faster than humanity can produce it. Current projections indicate that the AI industry will fully utilize the global stock of high-quality human text at some point between 2026 and 2032 11. While some developers have attempted to use synthetic data - text generated by older AI models - to train newer ones, relying too heavily on synthetic data can lead to model collapse or the amplification of existing biases, making high-quality human data the dominant bottleneck 2428.
The Inference Hardware Crisis
Beyond the data wall, pure parameter scaling has collided with severe economic and hardware constraints, specifically during the inference phase 2812.
In LLM deployment, there are two distinct computational phases: prefill and decode 12. The prefill phase, where the model reads the user's prompt, processes all tokens simultaneously in parallel, meaning it is generally limited only by processing compute 12. However, the decode phase - where the model actually generates the response - is inherently sequential. The model must generate Token A, use it to generate Token B, and so on 12.
This sequential generation makes the decode phase fundamentally memory-bound rather than compute-bound 12. The processor sits idle waiting for data to be fetched from memory. This bottleneck is exacerbated by the Key-Value (KV) cache, a memory store that grows linearly with the total sequence length of the conversation 12. As enterprise models push for massive context windows of 128K or 1 million tokens, the KV cache size explodes, outpacing the economic delivery capabilities of current High Bandwidth Memory (HBM) hardware 12.
The total cost of ownership, average power draw, and carbon emissions required to maintain dense, trillion-parameter models for everyday consumer queries have forced the industry to rethink its architecture entirely 2812.
The Shift to Reasoning and Specialized Architectures
The flattening of scaling laws did not signal the end of AI progress, but rather a pivot from "bigger models" to "smarter scaling" 2527. The intellectual shift defining the 2026 AI landscape is the move away from monolithic reflex models toward specialized architectures and "thinking models" 2728.
System 1 vs. System 2 Intelligence
Traditional large language models operate similarly to human "System 1" thinking 31. They are fast, intuitive, and reflexive. When prompted, they output a prediction immediately. This architecture is highly efficient and perfectly suited for tasks where speed matters more than extreme precision, such as creative writing, summarization, or basic customer service chat 31.
However, for tasks demanding rigorous correctness - such as solving complex mathematics, scientific research, drug discovery, or multi-step logic puzzles - System 1 models frequently fail 31. To solve this, developers introduced reasoning models, effectively granting AI a "System 2" cognitive process 31.
Reasoning models do not answer immediately. Instead, they rely on "inference-time compute" (or test-time compute) 273132. By allocating more computational power and time to the generation phase, the model deliberates before responding 2733. It generates hidden chains of thought, exploring multiple parallel logical paths simultaneously, checking its own logic, and backtracking from dead ends before finalizing a response 2733. While this makes each query slower and more computationally expensive, the resulting increase in output quality for hard problems is dramatic 31.
The Mixture of Experts (MoE) Architecture
To deploy massive models without incurring crippling computational costs, the industry broadly adopted the Mixture of Experts (MoE) architectural pattern 271231.
Instead of a dense architecture where every single parameter in the model activates for every query, an MoE model divides its neural network into distinct, specialized sub-networks or "experts" 2831. When a user submits a prompt, an internal gating mechanism or router analyzes the input and dynamically directs it only to the specific experts highly trained for that topic, skipping the rest of the network 2731.
For example, a model might contain 671 billion parameters in total, giving it massive overarching capacity, but it may only activate 20 billion parameters per token during inference 31. This sparse activation allows frontier performance at a dramatically lower compute and electricity cost than a dense model of equivalent capability, fundamentally altering the economics of enterprise AI 2731.
| Feature | System 1 (Traditional LLMs) | System 2 (Reasoning Models) |
|---|---|---|
| Cognitive Approach | Reflexive, fast pattern matching and next-token prediction. | Deliberative, multi-step logic and parallel reasoning paths. |
| Compute Focus | Front-loaded heavily into the pre-training phase. | Utilizes significant inference-time (test-time) compute. |
| Speed & Latency | Near-instantaneous response generation. | Noticeable delay; model "thinks" before answering. |
| Primary Architecture | Historically dense networks (all parameters fire). | Heavily relies on Mixture of Experts (sparse activation). |
| Ideal Enterprise Use Case | Content generation, text summarization, front-line chatbots. | Code generation, architectural planning, scientific proofs. |
| Leading 2026 Models | GPT-4o, Gemini 2.5 Flash, Claude 3.5 Haiku. | OpenAI o3, DeepSeek R1, Claude 3.7 Sonnet. |
Evaluating True Intelligence
As large language models became exponentially more capable, the traditional benchmarks used to evaluate them became obsolete. For years, the industry relied on tests like the MMLU (Measuring Massive Multitask Language Understanding) and HumanEval to rank models 34. However, by 2026, these benchmarks saturated, with frontier models routinely scoring above 90% 34.
Furthermore, high scores on static, text-based multiple-choice tests increasingly reflected training data contamination - where the test answers accidentally leaked into the model's vast training data - rather than genuine fluid intelligence 3435. The industry required tests that measured generalization over memorization 36.
The ARC-AGI Benchmarks
To evaluate true problem-solving, AI researchers pivot heavily to the Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI) 3637. Considered the hardest public reasoning benchmark, ARC-AGI measures fluid intelligence through visual grid puzzles 37. Models are presented with a few input-output examples and must identify the hidden, novel pattern to generate the correct output for an unseen input 3637. Every task is designed to be solvable by humans but difficult for algorithms 36.
On ARC-AGI-2, the introduction of System 2 reasoning models led to massive breakthroughs. Frontier models like GPT-5.5 and Gemini 3.1 Deep Think achieved scores up to 85%, largely mastering static compositional tasks 3637.
However, in March 2026, researchers released ARC-AGI-3, marking a radical transformation in evaluation. ARC-AGI-3 abandoned static grid puzzles entirely, dropping AI agents into interactive, video-game-like environments with no stated rules, no instructions, and no win conditions 38. Agents had to observe a visual grid, take actions (move, click), and figure out both what their goal was and how to achieve it through pure interaction 38.
The results were a stark reality check for the industry. While models scored 85% on static puzzles, frontier LLMs like GPT-5 and Claude scored below 1% on ARC-AGI-3 38.
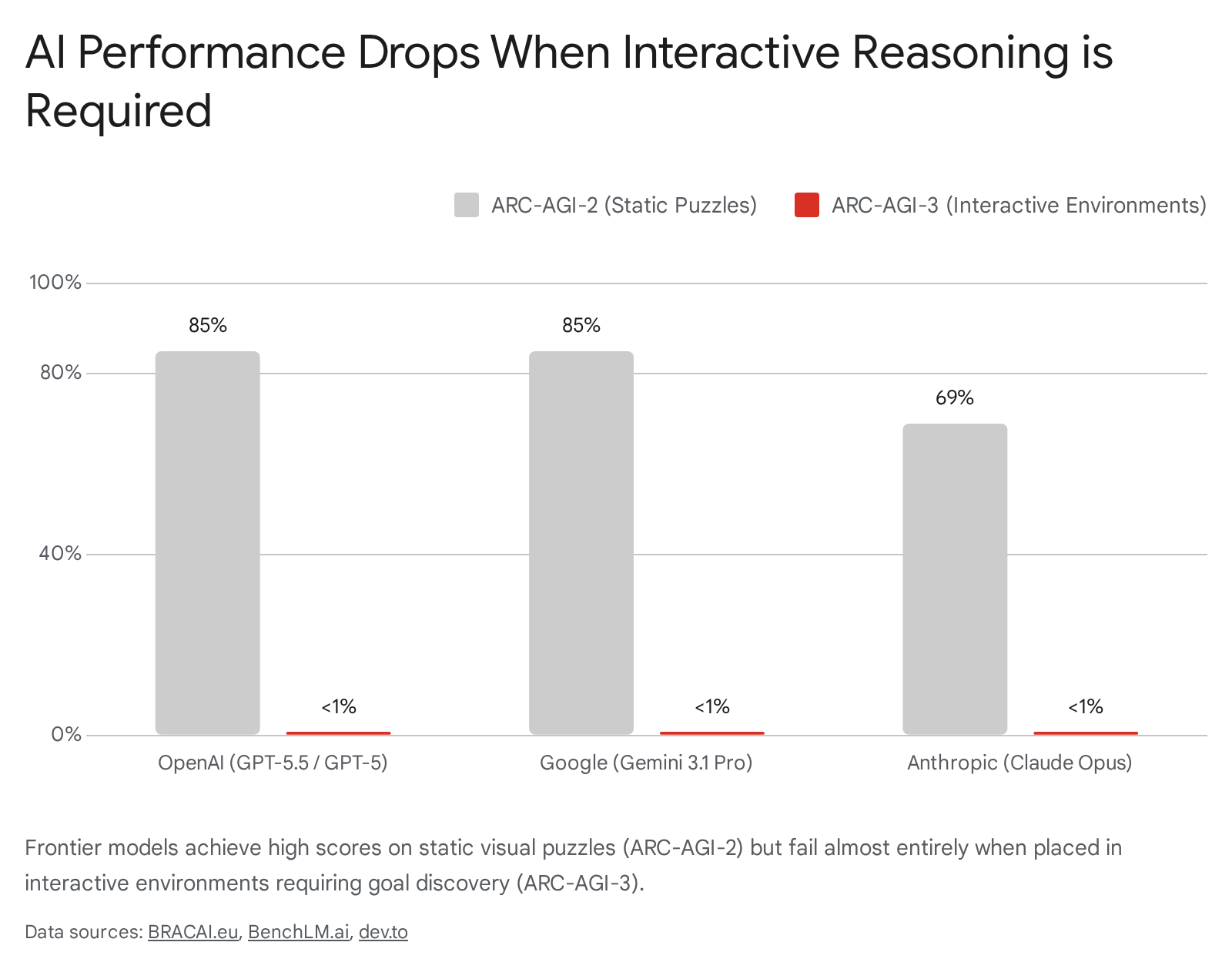
This collapse highlights a profound, unresolved challenge in LLM research: current architectures excel at passive textual analysis but demonstrably lack the capacity for interactive exploration, goal discovery, and real-world physical reasoning 538.
The Rise of Native Multimodality
Historically, large language models were strictly unimodal, meaning their architecture only allowed them to process text 9. If a user needed the AI to analyze an image, developers utilized a "bolt-on" or "late fusion" approach 939. A separate, specialized vision model would analyze the image, generate a text description of the visual content, and pass that text to the language model for reasoning 9.
While functional, this approach was highly flawed. Every translation step compressed information, flattening context and causing the system to lose vital structural and spatial detail 40.
By 2026, the technological standard shifted definitively to "native multimodality" 3940. Modern frontier models - such as the Gemini 3 series, GPT-4o, and the Llama 4 family - are trained from scratch to process multiple data formats simultaneously 39.
In a native multimodal architecture, distinct modalities are not stitched together after the fact. Instead, image patches, audio frames, and text are tokenized into a single, shared embedding space 3940. The mathematical vector for the word "apple," the vector for an image of a red fruit, and the vector for the spoken audio of the word "apple" are all placed close together mathematically 9.
This allows the model's core Transformer engine to perform joint reasoning directly across modalities without a translation bottleneck 939. For instance, a user can upload a screenshot of a complex architectural diagram or a broken software interface. The model can natively read the image, understand the spatial relationships of the data, and instantly produce corrected code in one continuous pass, significantly lowering latency and reducing the hallucination of visual details 39. Neuroscientists from MIT note that this mechanism mirrors the human brain, which integrates visual, tactile, and semantic information in a centralized, modality-agnostic "semantic hub" before formulating a response 8.
Understanding and Mitigating AI Hallucinations
Because large language models are probabilistic text generators rather than verified databases, they suffer from a persistent operational flaw known as hallucination 4142. Some psychologists push back against this terminology, arguing that "hallucination" implies conscious perception, and instead propose calling these instances of false information "confabulations" 43.
A hallucination occurs when the model encounters missing data, ambiguous prompts, or queries that fall outside its training dataset 4344. Rather than admitting ignorance, the model is compelled by its design to predict a fluent sequence of words . It confidently fills the gaps with plausible-sounding fabrications, presenting them as undisputed facts 4344.
Because these models lack physical grounding or direct perceptual experience, they have no built-in mechanism for distinguishing truth from statistically probable fiction 544. The consequences of relying uncritically on hallucinated outputs can be devastating in professional environments. In 2025, a major consulting firm was forced to return hundreds of thousands of dollars to a government client after an AI-generated healthcare report was found to contain completely incorrect hospital statistics, destroying trust and brand reputation 46.
The Danger of Ghost Citations
One of the most insidious forms of AI hallucination is the "ghost citation" 42. When asked to back up a claim, an LLM might generate a reference to a research paper, attributing it to real researchers, naming a reputable academic journal, and even providing a randomly generated Digital Object Identifier (DOI) number 4446. To a casual reader, the citation looks perfectly legitimate, but the document does not actually exist on the internet 44.
Enterprise Mitigation: RAG and Guardrails
To combat hallucinations in enterprise environments, developers rely heavily on a system architecture known as Retrieval-Augmented Generation (RAG) 2041.
Instead of allowing the LLM to answer a prompt from its internal, generalized "memory," a RAG system intercepts the query and first searches a secure, verified external database - such as a company's internal HR documents or proprietary legal contracts 41. The system retrieves the exact factual text required, feeds that specific context into the LLM, and instructs the model to generate its response only using the provided documents 41. This grounds the model in verified reality, dramatically reducing factual errors 41.
Fact-Checking Protocols for Users
For individual users and non-engineers, mitigating AI hallucinations requires the adoption of rigorous verification protocols:
- Lateral Reading: Users should never accept AI output as a single source of truth. When encountering a high-impact claim, open a separate browser tab to cross-reference the information against primary sources, human-written journalism, or official databases 4313.
- Verify Original Sources: Always manually check AI-generated citations. Use tools like Google Scholar or PubMed to verify that the cited piece not only exists but actually supports the claim the AI is making 4213.
- Human-in-the-Loop Review: Treat all AI-generated content - especially legal filings, medical summaries, or published research - as a first draft. A subject matter expert must review the output, as humans understand nuance and context blending that algorithms frequently miss 4213.
- Cross-Model Validation: If a fact seems questionable, input the same prompt into multiple different AI platforms from different vendors. Comparing responses can highlight inconsistencies and increase risk awareness 1348.
Best Practices for Prompt Engineering
The skill of interacting with large language models, known as "prompt engineering," has matured rapidly. In the early iterations of generative AI, users often relied on lengthy, conversational paragraphs, emotional pleading ("please try hard"), or keyword stuffing to elicit good responses 1450. By 2026, prompt engineering has transitioned from a dark art into a disciplined practice of writing clear, structural specifications 50.
Analysis of millions of production prompts reveals several foundational rules for achieving reliable outputs:
1. Structure Matters More Than Length
Long, conversational prompts easily confuse models 1450. Models process explicitly structured text far more reliably than walls of prose 14. Industry best practice dictates breaking prompts into clearly labeled blocks. Instead of writing, "I need you to analyze these reviews and tell me what people like," users should use structural headers: TASK: Analyze reviews., INPUT: [data], OUTPUT FORMAT: JSON. 14. Separating instructions from the input context makes the prompt infinitely easier to debug when outputs fail 50.
2. Define Output Contracts
The most common cause of poor model output is poorly defined acceptance criteria 50. Rather than using subjective adjectives like "Make it comprehensive" or "Write a good summary," users must define the exact parameters of success 1450. A strong output contract specifies the exact format (e.g., Markdown, bullet points), the tone (formal, technical), the precise length restrictions, and explicitly outlines constraints regarding what the model must not do 1450.
3. Show, Don't Tell (Few-Shot Prompting)
When precision in formatting or stylistic tone is required, descriptive adjectives fail. The most reliable method is to provide two or three distinct examples of the desired input-output pair directly within the prompt 1450. One example establishes a pattern; three examples make it highly reliable, forcing the model to conform strictly to the demonstrated structure 14.
4. Adjust for Model-Specific Behaviors
Prompts are no longer universally portable; different foundation models require entirely different approaches 51.
* Anthropic's Claude: Claude models are strictly literal and respond best to structured XML tags. Wrapping instructions in <instructions> and data in <context> yields highly predictable, controllable outputs 51. Furthermore, aggressive language ("CRITICAL!", "YOU MUST") actively degrades Claude's performance; calm, direct instructions work best 51.
* OpenAI's GPT Models: GPT models utilize internal routing mechanisms to decide when to employ deep reasoning. Explicitly instructing a GPT reasoning model to "think step by step" can actually confuse its internal logic router and hurt performance 51. Prompts for OpenAI models should remain conversational and direct, avoiding artificial chain-of-thought commands 51.
The Market Landscape and Enterprise Adoption
As of mid-2026, the generative AI market has consolidated around a few massive technology providers, sparking fierce competition over enterprise deployment and user market share 5253. While the initial hype phase focused heavily on benchmark scores, the current industry battle is focused entirely on workflow integration and distribution 54.
The pricing landscape has largely standardized. Most providers offer a robust free tier to drive consumer adoption, a $20-per-month standard professional subscription, and newly introduced $100-per-month power-user tiers aimed at heavy developer workloads 5255.
Comparing the Major 2026 AI Platforms
| Platform | Market Position | Best Fit For... | Notable Features (2026) |
|---|---|---|---|
| ChatGPT (OpenAI) | The dominant all-purpose leader with over 800M weekly active users 15. | Users seeking a broad, reliable default assistant for diverse tasks. | Advanced voice mode, deep agentic workflows, custom GPT creation 525557. |
| Claude (Anthropic) | The preferred choice for professional writers, researchers, and enterprise deployments 52. | Processing massive documents, coding, and nuanced long-form writing 5257. | Industry-leading 200K context window; native XML tag compliance; Claude Code CLI 5557. |
| Gemini (Google) | The seamless ecosystem option, capturing 400M monthly active users 15. | Workflows heavily reliant on Google Workspace (Docs, Gmail, Drive) 52. | Massive 1M+ token context window; real-time native web search; includes 2TB cloud storage 5257. |
| Grok (xAI) | The social-first model, integrated deeply into the X platform 52. | Real-time social context, trend analysis, and live news parsing 52. | Unfiltered access to X data streams; Deep Search capabilities 5258. |
| Llama (Meta) & DeepSeek | The open-weight and cost-efficiency disruptors 52. | Builders requiring self-hosting, infrastructure control, or extreme cost savings 52. | Completely free access (Meta AI); API costs a fraction of proprietary rivals 5255. |
The Reality of Enterprise Deployment
The integration of large language models into the global workforce has moved at an unprecedented pace. By 2026, 67% of global organizations use generative AI products powered by LLMs in their daily operations 5359. Usage is no longer a niche technical pursuit; 75% of employees report using generative AI tools, indicating mass normalization across standard white-collar roles 59.
The largest enterprise deployments highlight a massive shift away from experimental API calls toward deep, structural integration. In May 2026, the "Big Four" consulting firms made aggressive moves, with KPMG deploying Anthropic's Claude to 276,000 employees globally 54. Rather than treating the AI as an external chatbot, KPMG integrated Claude directly into their core client delivery platforms, allowing consultants to build real-time agentic workflows that adapt to changing tax laws in minutes rather than weeks 54. Similar global scale deployments by PwC and Deloitte highlight that conversational AI has become mandatory infrastructure 54.
The most dominant use cases across these enterprises include automated customer support, which captures over 27% of the global LLM market, and information extraction, where legal and financial teams deploy models to synthesize regulatory documents instantly 535960. Despite this rapid adoption, true enterprise-wide impact remains elusive for many, hindered by ongoing challenges regarding data privacy, hallucination mitigation, and the immense costs of operating at scale 53.
Educational Impact and the Push for AI Literacy
The rapid proliferation of generative AI has fundamentally disrupted global education systems, creating a massive gap between student usage and institutional policy. According to the 2026 Artificial Intelligence Index Report published by Stanford University's Human-Centered Artificial Intelligence (HAI) institute, four out of five U.S. high school and college students now use AI regularly for schoolwork, primarily for research, essay editing, and brainstorming 16.
However, formal education policy has severely lagged behind technological capability. Only half of middle and high schools have formal AI policies in place, and a mere 6% of teachers report that those policies are clear and actionable 16.
The 2026 State AI Literacy Mandates
Recognizing that artificial intelligence is now a foundational layer of modern civic and professional infrastructure, governments have begun forcing integration. By early 2026, twelve U.S. states - including California, New York, and Texas - passed mandatory AI literacy frameworks 62. These mandates require school districts to implement structured AI curricula by the 2026-2027 academic year, shifting AI from an optional enrichment elective to a mandatory compliance requirement 62.
The goal of these mandates is not necessarily to turn students into machine learning engineers, but to ensure they understand the mechanics, ethical risks, and societal impacts of algorithmic systems 62. Educators are provided with specific AI literacy checklists to evaluate competencies, requiring students to understand how training data introduces bias, how to craft and refine effective prompts, and how to critically evaluate AI outputs for hallucinations and stereotypes 63.
A critical bottleneck in implementing these educational mandates is student data privacy 62. The 2026 state mandates strictly require that educational AI tools comply with the Children's Online Privacy Protection Act (COPPA), explicitly banning tools that retain user data or train their public models on student inputs 62. This forces districts to carefully audit vendor compliance before allowing models into the classroom 62.
Bottom line
Large language models represent a profound leap in computational capability, transitioning machines from rigid calculators into systems capable of analyzing, generating, and reasoning through complex human language. However, beneath their highly fluent conversational interfaces, they remain statistical prediction engines that lack grounded real-world understanding, making them structurally susceptible to hallucinations and contextual errors. As the industry faces the exhaustion of human training data and pivots away from brute-force scaling toward specialized, reasoning-based architectures, the utility of artificial intelligence will increasingly depend on human oversight. Users must approach AI as a collaborative tool - structuring prompts with precision, rigorously verifying outputs against primary sources, and understanding the inherent limitations of the architecture.