Current State of AI Mathematical Reasoning
Evolution of Evaluation Benchmarks
The evaluation of artificial intelligence has historically relied on static datasets to measure discrete cognitive milestones. In the domain of mathematical reasoning, the rapid acceleration of large language model (LLM) capabilities has systematically dismantled these traditional yardsticks. Mathematical problem-solving represents a unique paradigm for artificial cognition: unlike natural language generation, which often involves subjective semantic evaluation, mathematical reasoning demands precise, deterministic logic with objectively verifiable conclusions 12. As model architectures have shifted from purely associative pattern matching to sequential, chain-of-thought methodologies, the benchmarks used to quantify these abilities have required continuous escalation to prevent complete saturation.
Saturation of Foundational Datasets
The first major wave of mathematical AI evaluation was anchored by two primary datasets: the Grade School Math 8K (GSM8K) and the MATH benchmark. Introduced to test multi-step reasoning, GSM8K consists of 8,500 linguistically diverse word problems requiring elementary arithmetic operations and two to eight logical steps 1. It was designed to assess whether an AI could successfully translate everyday language into foundational mathematical operations. For several years, GSM8K served as the gold standard for foundational reasoning, particularly for models in the parameter ranges of early Llama architectures 3.
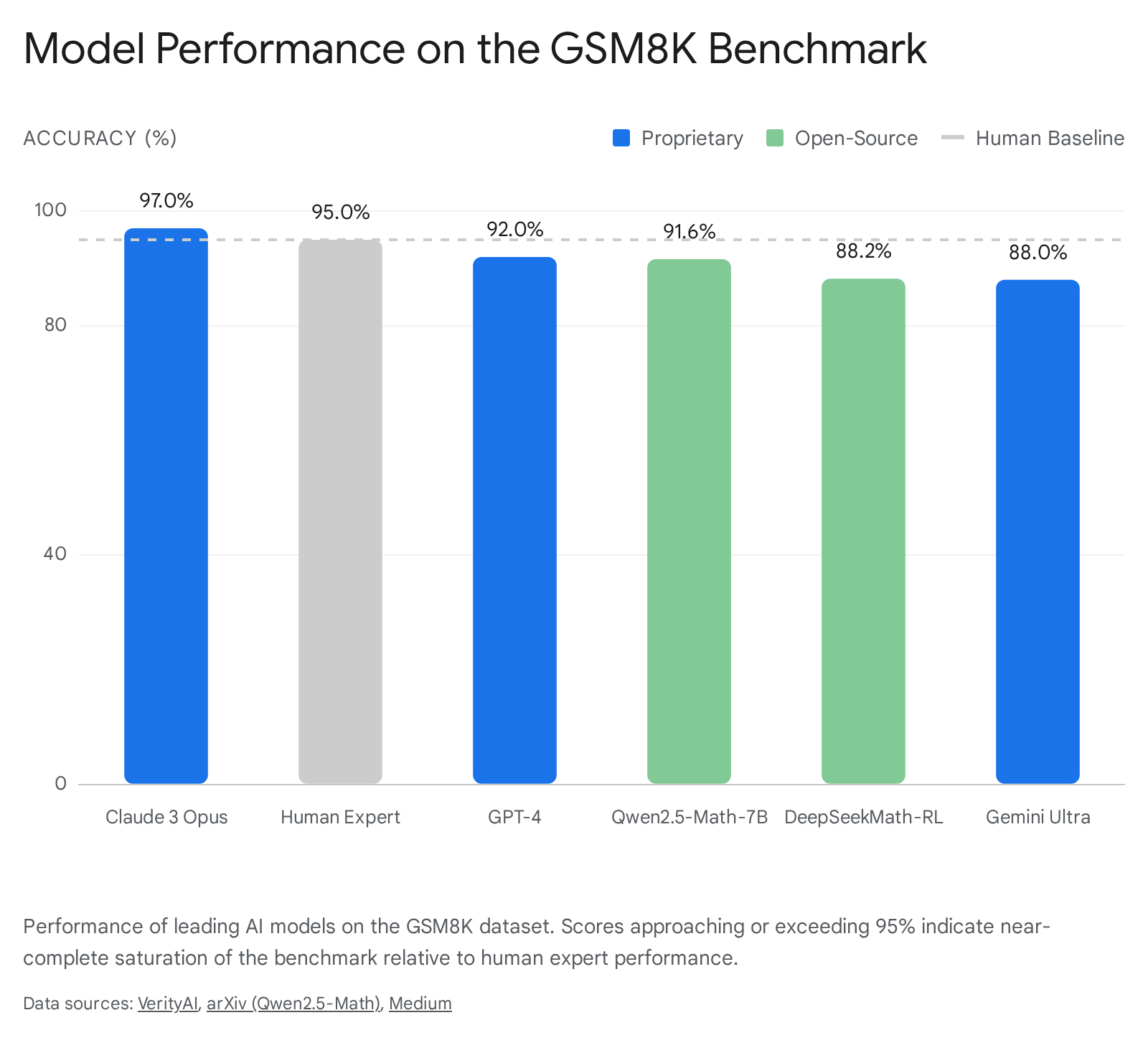
By mid-2025, GSM8K had become completely saturated. Leading proprietary models such as Claude 3 Opus achieved 97.0% accuracy, OpenAI's GPT-4.5 reached 97.0%, and Gemini Ultra secured 88.0% 14. Open-weight models mirrored this trajectory, with Qwen2.5-Math-7B achieving 91.6% and DeepSeekMath-RL achieving 88.2% 56. Because human expert performance on GSM8K is estimated at 95%, these systems effectively matched or surpassed the baseline of human competency on fundamental arithmetic reasoning tasks 1.
The MATH benchmark, containing 12,500 challenging competition-style problems spanning algebra, geometry, and calculus, was introduced as a significantly more rigorous alternative 2. Initially, MATH presented a formidable barrier for models relying strictly on zero-shot inference. Yet, the adoption of test-time compute and tool-integrated reasoning rapidly eroded this difficulty barrier. State-of-the-art systems achieved accuracy levels crossing the 90% threshold on MATH by early 2025, with models like Qwen2.5-Math-72B-Instruct establishing unprecedented open-source performance records on the dataset with a zero-shot score of 66.8% and approaching 90% using external tools 361. The saturation of both GSM8K and MATH demonstrated that evaluating frontier models on structured, high-school-level curricula was no longer sufficient to differentiate cutting-edge cognitive capabilities 22.
Transition to Competition-Level Mathematics
As foundational datasets lost their discriminative utility, the research community pivoted to evaluating models against problems sourced from elite human mathematics competitions. Chief among these was the American Invitational Mathematics Examination (AIME), a benchmark comprising problems that rarely require advanced undergraduate mathematical knowledge but instead demand deep, creative problem-solving, multi-step proofs, and the synthesis of non-obvious connections 1. The AIME dataset evaluates answers requiring single integers from 0 to 999, utilizing an exact-match scoring system with no partial credit, making it an unforgiving test of end-to-end logical persistence 3.
The progression on AIME followed a highly compressed timeline. In 2023, the best models scored between 50% and 60% 1. By early 2025, inference-time scaling and reinforcement learning optimizations pushed the frontier models to score between 95% and 99% 1. For context, the average human participant historically answers approximately 27% to 40% of the questions correctly (4 to 6 out of 15) 3. OpenAI's o3 model achieved 96.7% accuracy on AIME 2024, while DeepSeek's R1 model attained 79.8% on the same edition 1011. By 2026, models like DeepSeek R1 had reached 96% on AIME 2025 1. The rapid saturation of AIME - moving from 50% to 95% in approximately 18 months - indicated that even high school Olympiad-level mathematics was effectively solved under standard testing conditions 1.
Research-Level and Formal Datasets
With AIME scores compressing at the upper limits, the testing ecosystem evolved toward the International Mathematical Olympiad (IMO) and explicitly research-level datasets. The IMO represents the pinnacle of high school mathematics, containing theoretical problems that frequently require formal, page-length proofs rather than integer outputs 12. The complexity is immense: IMO problems often require sustained creative thinking, extending the necessary reasoning time horizon for AI models from approximately 0.1 minutes for GSM8K to multiple hours of computation 12.
Further efforts to build rigorous evaluations led to the creation of datasets like FrontierMath, FormalMATH, and OlymMATH 23. FrontierMath utilizes unpublished problems from active research mathematics, designed to prevent pre-training memorization by continuously removing solved problems 2. FormalMATH tests the ability to produce reasoning that survives automated checking in formal verification languages like Lean 4, assessing whether a model can generate logic that a strict machine compiler will accept 2. OlymMATH provides parallel English and Chinese Olympiad-level questions meticulously curated from printed materials - such as specialized magazines and official offline competition records - to avoid the risks of web scraping and subsequent online contamination 3. On the hardest tier of OlymMATH, leading models like DeepSeek-R1 and o3-mini scored only 19.5% and 31.2% respectively, highlighting the remaining performance gap at the highest levels of theoretical logic 3.
| Benchmark Entity | Primary Problem Domain | Scoring Methodology | Current Saturation Status |
|---|---|---|---|
| GSM8K | Elementary word problems | Final answer extraction | Fully Saturated (~97%) 14 |
| MATH | Competition algebra, geometry | Final answer extraction | Highly Saturated (>90%) 313 |
| AIME | Creative multi-step math | Exact match (0-999 integer) | Highly Saturated (95-99%) 1 |
| IMO | Advanced high school theory | Formal proof verification | Partially Saturated (Silver/Gold levels achieved) 45 |
| FrontierMath | Unsolved research mathematics | Expert verification | Unsaturated (~30-40% on tier 1-4) 2 |
Benchmark Contamination and Verification Methodologies
The exponential improvement in benchmark scores has raised profound epistemological concerns regarding data contamination. Benchmark Data Contamination (BDC) occurs when the exact questions, or highly similar variants, from a test set inadvertently exist within the massive web-crawled corpora used to pre-train language models 16. In mathematical evaluations, distinguishing genuine reasoning capabilities from the latent memorization of training data is critical to ensuring the validity of AI progress 26.
Mechanisms of Data Contamination
Contamination manifests in two primary forms. Direct contamination involves identical text sequences of the mathematical problem and its solution appearing in the training data 6. Indirect contamination occurs when problems are semantically equivalent but syntactically altered, such as paraphrased word problems, translated equations, or differently named variables 6. Because data contamination occurs during pre-training, it remains non-intervenable during the evaluation phase 7.
Studies that have created perturbed, contamination-free versions of standard benchmarks (such as GSM1k) frequently observe notable performance drops in frontier models, strongly suggesting that high scores on public leaderboards partially reflect overfitting to the original benchmark distributions 2. If an AI model has memorized the heuristic steps of a specific dataset, evaluations fail to accurately assess its capacity to generalize mathematical reasoning to novel scenarios.
Dynamic and Contamination-Free Benchmarks
To combat this vulnerability, researchers have engineered dynamic and variable-driven benchmarks. The MathArena framework leverages a real-time stream of newly released problems from recurring competitions (e.g., AIME, HMMT, SMT). By evaluating models immediately upon the public release of the problems, MathArena effectively eliminates the possibility of pre-training exposure 8. Using this methodology, MathArena identified strong signs of contamination in the static AIME 2024 dataset, suggesting that some high scores on older benchmarks were artificially inflated by memorization 8.
Another methodological approach is RV-BENCH, which systematically introduces random variables (RVs) into existing mathematical problems 27. By mirroring the background structure of known benchmark problems but randomizing the specific numerical combinations, RV-BENCH tests whether an LLM understands the inherent mathematical logic or is merely reciting a memorized solution path 7. When evaluated on RV-BENCH, over 30 representative LLMs experienced significant accuracy drops, exposing a severe proficiency imbalance between encountered data distributions and unseen variable configurations, demonstrating limited generalization across similar mathematical tasks 7.
Test-Time Compute and Inference-Time Reasoning
The transition from static scaling laws - which posited that intelligence strictly scales with parameter counts and pre-training data volume - to inference-time optimizations marks a fundamental inflection point in AI mathematical reasoning. The introduction of Test-Time Compute (TTC) paradigms has demonstrated that allowing models to perform extended internal computation before generating an output is highly efficient for complex algorithmic problem-solving 921.
Chain-of-Thought and Process Reward Models
Historically, LLMs were optimized for single-pass generation, committing to an answer token by token 21. In mathematical tasks, this architecture is highly error-prone due to the cumulative nature of logic; a single computational error early in a sequence corrupts all subsequent deductions 6. Chain-of-Thought (CoT) reasoning forces models to break down complex tasks into intermediate steps, plan approaches, and verify intermediate conclusions, mimicking a human mathematician writing out their work 610.
While initial CoT implementations relied on specific user prompt engineering, modern architectures integrate this reasoning inherently through extensive reinforcement learning (RL). By shifting computational expenditure from the pre-training phase to the inference phase, models explore multiple solution paths, self-correct, and allocate variable amounts of time depending on problem difficulty 2122. Experimental data indicates that performance gains are heavily dependent on aligning Process Reward Models (PRMs) with policy models 22. Unlike traditional outcome supervision that only rewards the correct final answer, PRMs provide granular feedback on the quality of individual reasoning steps, significantly improving search efficiency through decision trees 522.
Optimization Strategies for Inference Computation
The strategic allocation of runtime computation has proven capable of beating raw model size. Research demonstrates that smaller models, when paired with tailored Test-Time Scaling strategies, can surpass massive counterparts. For instance, a highly optimized 1-billion parameter model utilizing compute-optimal TTS surpassed a 405-billion parameter model on the MATH-500 dataset 22. Similarly, a 7-billion parameter model exceeded GPT-4o and DeepSeek-R1 on AIME 2024 with higher overall inference efficiency 22.
This reward-aware compute-optimal strategy adapts computation based on task complexity, the model's inherent capability, and continuous PRM feedback, replacing older, less efficient percentile-based difficulty groupings 22. Scaling compute budgets inversely with model size ensures that smaller models receive the extensive sampling necessary to match or exceed trillion-parameter architectures 22.
Architecture and Training Methodologies of Frontier Models
The development of specific model lineages highlights divergent but equally successful paths to achieving mathematical excellence, ranging from OpenAI's general-purpose reinforcement learning to DeepSeek's open-weight algorithmic optimizations and Qwen's tool-integrated self-improvement cycles.
OpenAI o1 and o3 Architectures
OpenAI's o1 and subsequent o3 models epitomize the success of scaling test-time compute. The o1 model operates by generating a hidden chain of thought, utilizing general-purpose reinforcement learning to systematically dismantle logic puzzles, execute code, and self-verify before outputting a solution 1023. Empirical observations confirmed that performance consistently scales by increasing both the amount of reinforcement learning training compute and test-time inference compute 23.
While o1 relied on these generalized mechanisms, OpenAI created a specialized system, o1-ioi, tailored specifically to compete in the 2024 International Olympiad in Informatics (IOI). This system used hand-engineered inference strategies and domain-specific heuristics similar to AlphaCode 23. Under relaxed competition constraints, o1-ioi achieved a gold medal, but only placed in the 49th percentile using strict, standard constraints 23.
The successor model, o3, rendered human-designed heuristics obsolete. Through end-to-end RL training, o3 organically developed complex, autonomous test-time reasoning strategies without coding-specific test-time pipelines defined by humans 523. For example, when attempting to verify a highly optimized algorithmic solution, o3 learned to autonomously generate a simple, brute-force implementation of the same logic to cross-check its own outputs for errors 523. This autonomous logic yielded unprecedented results. The o3 model achieved a gold medal at the 2024 IOI under strict competition constraints, reaching an elite 2724 CodeForces rating (the 99.8th percentile, placing it at the International Grandmaster level) 52425. In software engineering, o3 achieved a 71.7% success rate on the SWE-bench Verified benchmark 105. In pure mathematics, OpenAI reported that o3 successfully solved 35 out of 42 points on the 2024 IMO, surpassing the gold medal threshold strictly through its natural language reasoning framework without relying on formal symbolic engines 261011.
| Model Specification | IOI 2024 Performance | CodeForces Rating (Percentile) | Key Architectural Advancement |
|---|---|---|---|
| OpenAI o1 | Not entered formally | 1673 (89th) 24 | General-purpose RL CoT reasoning 2324 |
| OpenAI o1-ioi | 49th percentile (standard) / Gold (relaxed) | 2214 (98th) 24 | Hand-crafted competition heuristics 23 |
| OpenAI o3 | Gold Medal (strict constraints) | 2724 (99.8th) 24 | Autonomous test-time strategies via pure RL 523 |
DeepSeek-R1 and DeepSeekMath
Simultaneous with proprietary advancements, the open-weight community achieved comparable breakthroughs through highly efficient data curation and novel training algorithms. DeepSeekMath, a 7-billion parameter model, sourced 120 billion high-quality math-related tokens from Common Crawl. This was achieved through an iterative pipeline beginning with a seed corpus from OpenWebMath, training a fastText classifier to distinguish mathematical content, and applying it across deduplicated web domains 529.
Instead of standard Proximal Policy Optimization (PPO), DeepSeek utilized Group Relative Policy Optimization (GRPO). GRPO eliminates the need for a separate value/critic model; instead, it estimates the baseline directly from group scores 530. This significantly reduces memory requirements during training while simultaneously boosting in-domain mathematical performance 530. DeepSeekMath-RL achieved 88.2% on GSM8K and 51.7% on the MATH benchmark using only chain-of-thought reasoning 5.
DeepSeek-R1 pushed this methodology further by attempting to induce reasoning capabilities through pure reinforcement learning with almost no supervised fine-tuning (SFT) data. The pure RL experiment, R1-Zero, improved its AIME accuracy from a baseline of 15.6% to 71% strictly through policy updates and simple rule-based rewards for format and correctness 12. While R1-Zero exhibited remarkable problem-solving leaps, its raw linguistic output was jagged, featuring language mixing and cryptic notations 12. By subsequently combining a small, curated SFT "cold start" dataset with GRPO, the hybrid DeepSeek-R1 stabilized its outputs and achieved 79.8% on AIME and 97.3% on MATH-500, rivaling the capabilities of OpenAI's o1 while operating as an open-source model 1112.
Qwen2.5-Math
Alibaba's Qwen2.5-Math series utilized an intensive self-improvement pipeline integrated across pre-training, post-training, and inference. In the pre-training phase, Qwen2.5 scaled its high-quality datasets to an enormous 18 trillion tokens 32. Post-training heavily utilized a Reward Model (RM) generated by sampling extensively from instruct versions; this RM iteratively evolved the data used in supervised fine-tuning and ultimately guided the reinforcement learning phase 61334.
A core feature of Qwen2.5-Math is Tool-Integrated Reasoning (TIR), which allows the LLM to write and execute code via a Python interpreter 6. For mathematical problems requiring heavy algorithmic complexity, finding roots of quadratics, or computing large matrix eigenvalues, TIR significantly outperforms standard CoT text generation 6. Utilizing TIR and RM guidance, the Qwen2.5-Math-72B model achieved a 66.8 score on the zero-shot MATH benchmark and approached 90 points when allowed to utilize the Python interpreter 6. The 1.5B and 7B models exhibited extreme parameter efficiency, with the 7B model matching the performance of much larger 72B legacy models 6. Interestingly, while TIR drastically improved English benchmark performance, failure analysis noted that it did not show a similarly significant advantage over CoT mode for Chinese benchmarks 6.
Neuro-Symbolic Systems and Proof Assistants
Despite the remarkable capacity of LLMs to generate informal mathematical proofs in natural language, their probabilistic architectures remain vulnerable to hallucinations, subtle logical leaps, and arithmetic instability 353637. To establish absolute epistemic certainty in AI-generated mathematics, researchers are increasingly integrating neural networks with formal proof assistants - software environments such as Lean 4, Coq, and Isabelle that verify arguments step-by-step using strict axiomatic foundations 2383940.
The Role of Autoformalization
Autoformalization is the process of translating informal, natural-language mathematics (such as textbooks, research papers, and problem statements) into rigorous, machine-verifiable code for a proof assistant 384014. This serves as the critical bridge between the intuitive leaps of an LLM and the deterministic verification of a symbolic engine.
Historically, the primary bottleneck in training models for formal mathematics has been extreme data scarcity. There is a lack of large-scale, aligned corpora pairing informal mathematical concepts directly with their formal Lean or Coq equivalents 38. Furthermore, informal texts are inherently underspecified; human mathematicians frequently rely on implicit assumptions or "hand-wave" trivial steps that a formal compiler requires to be explicitly defined 38. When an AI autoformalizes a statement, it must abductively reason to fill in these missing axiomatic gaps, map informal terms to heavily abstracted formal definitions, and navigate the continuously evolving taxonomies of formal libraries like Lean's mathlib 38. The lack of reliable evaluation metrics complicates this, as traditional machine learning metrics like BLEU do not correlate well with actual logical correctness in formal languages 38.
AlphaGeometry and Deductive Database Arithmetic Reasoning
Google DeepMind has led the development of neuro-symbolic hybrids - systems that couple the creative, intuitive search capabilities of neural networks with the strict logical governance of symbolic engines 43715.
AlphaGeometry, introduced to conquer Olympiad-level geometry, demonstrates this bifurcation. The system utilizes a neural language model to suggest useful auxiliary constructs (such as adding a point, line, or circle to a diagram), while a Deductive Database Arithmetic Reasoning (DDAR) symbolic engine exhaustively computes the logical consequences of those additions 3715.
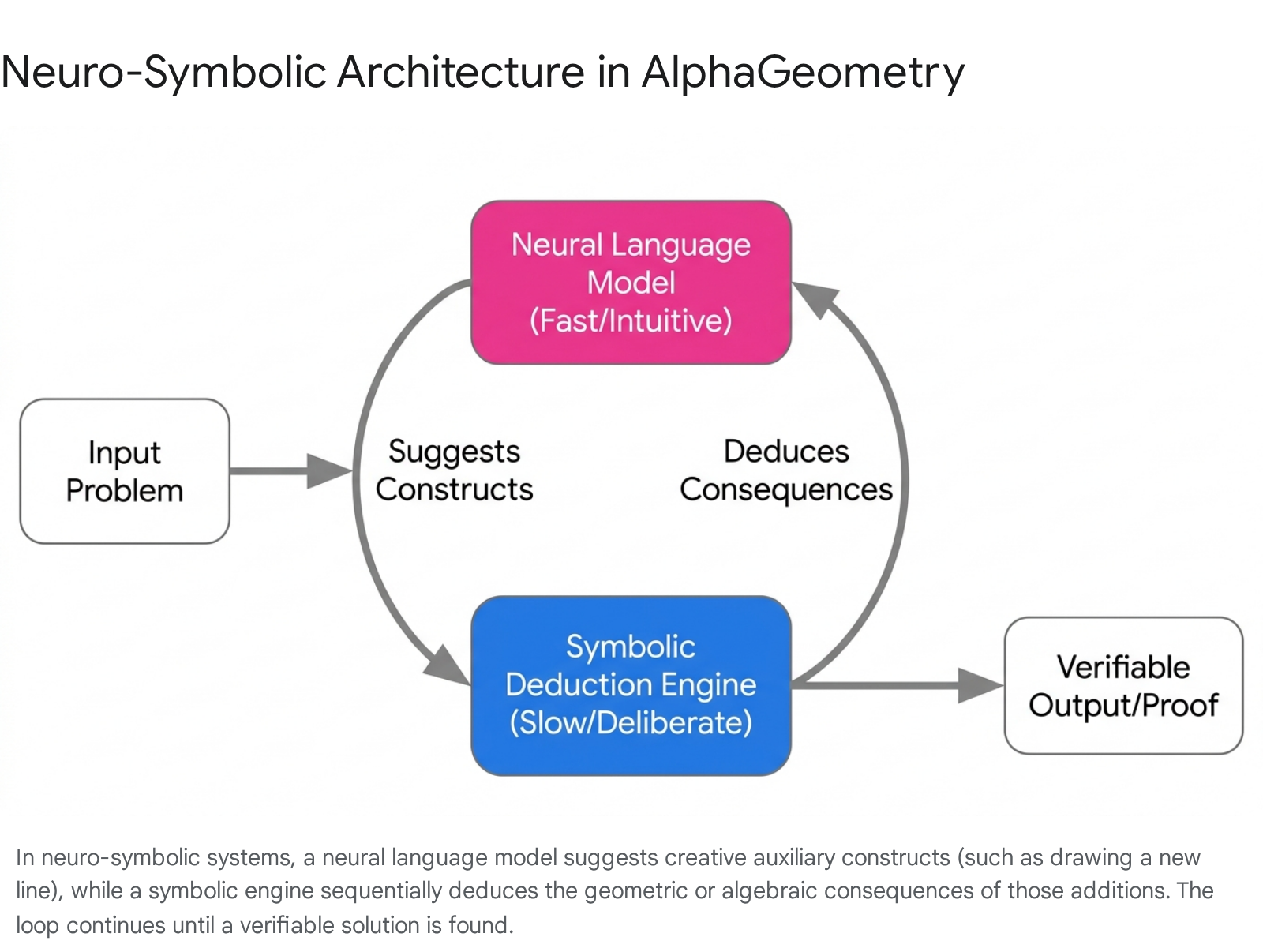
Trained on 100 million synthetic data points, the original AlphaGeometry solved 25 out of 30 benchmark IMO geometry problems 15.
AlphaGeometry 2 substantially improved this architecture by integrating a Gemini-based language model and a symbolic engine capable of running two orders of magnitude faster 4316. The updated system handles dynamic object movements, ratios, and distances, allowing it to solve 83% of all IMO geometry problems from the last 25 years - including finding the solution to IMO 2024 Problem 4 in just 19 seconds 374316.
AlphaProof and Formalizer Networks
DeepMind's AlphaProof applies a similar logic to algebra, combinatorics, and number theory. It pairs a pre-trained language model with the AlphaZero reinforcement learning algorithm, previously used to master chess and Go 44316. To overcome the formal data bottleneck, a fine-tuned Gemini model was used as a "formalizer network" to translate natural language problems into formal statements in Lean 1617. A solver network then searches for proof steps within the Lean environment, generating solution candidates that are either mathematically verified or disproved 416.
When a proof is found and formally verified, it reinforces the language model in a continuous feedback loop 16. The combination of AlphaGeometry 2 and AlphaProof achieved a silver-medal equivalent at the 2024 IMO, successfully conquering four of the six problems, including the notoriously difficult Problem 6 416.
Scaling Lean 4 for Research-Level Mathematics
The efficacy of autoformalization and formal proving has recently advanced from solving isolated competition problems to completing major, research-level tasks. A prominent example occurred when Math Inc.'s Gauss AI agent was deployed to formalize the strong Prime Number Theorem (PNT) in Lean 4 17. The project had previously stalled after 18 months of manual human effort 17.
Operating autonomously for extended periods, thousands of concurrent AI agents consumed terabytes of cluster RAM to generate approximately 25,000 lines of verified Lean code, formalizing over 1,100 theorems and complex analysis infrastructure (such as the Borel-Carathéodory theorem) in just three weeks 17. This milestone demonstrated that AI systems could dramatically compress the timelines required to digitize and verify high-level mathematics, functioning as reliable research copilots capable of mitigating long-standing verification bottlenecks in exploratory mathematics 4017.
Model Limitations and Failure Modes
Despite paradigm-shifting breakthroughs, the application of LLMs to advanced mathematics is still constrained by fundamental architectural and epistemological limitations. Progress is uneven; an AI that performs at the level of a PhD candidate in algebra may fail on basic spatial reasoning tasks, exposing the difference between vast statistical approximation and grounded logical competence 36.
Token Bias and Probabilistic Deficits
At their core, Large Language Models are stochastic systems designed to predict subsequent tokens based on high-dimensional probability distributions 3646. Mathematics, conversely, is governed by absolute necessity rather than probability; a theorem is strictly true or false regardless of its distributional frequency in a training corpus 36.
This underlying friction creates highly specific failure modes. Research into LLM logical processing reveals severe "token bias," where models inadvertently favor or disfavor specific tokens based on their training context 47. Small, non-mathematical changes in the linguistic formulation of an input prompt can drastically alter the model's output 47. When evaluating multi-step tasks requiring the selection of many precise tokens in sequence, the probability of the AI maintaining rigorous adherence to the logical path decreases exponentially 47. Consequently, when LLMs are confronted with adversarial problem variations or entirely novel structural formulations, they frequently resort to applying surface-level pattern recognition instead of genuine logical deduction, resulting in "hallucinated" mathematical claims 3646. When generating full proofs without a symbolic engine, step verification often reveals errors such as citing non-existent theorem names, referring to non-existent prior steps, or executing invalid geometric constructions 37.
Algorithmic Complexity and Spatial Reasoning Limits
Even highly specialized neuro-symbolic systems possess strict domain boundaries. AlphaGeometry 2, despite its elite performance, does not cover roughly 12% of IMO geometry problems from 2000 - 2024. It explicitly fails on problems that require 3D spatial geometry, inequalities, or non-linear equations 37. Furthermore, the system lacks the ability to handle problems containing a variable, countable number of points (e.g., "$n$ points where $n$ is an arbitrary positive integer") 37.
Current automated systems also struggle heavily with meta-planning and large-scale architectural strategy within mathematics 48. Even top-performing systems fail on combinatorial problems that require spatial intuition and high-level structural overviews rather than sequential algebraic deductions 48. This limitation was evident at the 2024 IMO, where neither AlphaProof nor AlphaGeometry 2 could solve the competition's two combinatorics problems 43516.
When formal tools are not utilized, models relying strictly on Chain-of-Thought reasoning exhibit high failure rates in routine but tedious algorithmic calculations 6. Evaluating the internal step-by-step reasoning often shows that models possess the correct conceptual strategy but fail to arrive at the correct final output due to basic computational instability during intermediate matrix multiplications 6.
Constraints of Formal Verification Systems
While integrating LLMs with proof assistants addresses the hallucination problem, the formal systems themselves introduce rigid bottlenecks. Mathematical proofs often function across different representational spaces, such as symbols, geometries, and topological structures. Converting this multidimensional reasoning into one-dimensional, strict text code can be incredibly restrictive and frequently encounters structural limits (e.g., higher-dimensional structures requiring alternative foundations like homotopy type theory) 38.
Additionally, achieving strong proofs or formal guarantees about the behavior of AI systems as they act in the physical world is severely limited. Mathematical proofs work on highly abstracted symbol systems, not on the messy, complex initial conditions of the physical world, placing a hard ceiling on the utility of formal verification for solving real-world alignment and safety threats 49.
Conclusions on AI Mathematical Capabilities
The trajectory of AI mathematical reasoning has evolved from the rote parsing of grade-school word problems to the generation of formal, machine-verified proofs capable of earning gold medals at the International Mathematical Olympiad. This progression signals that artificial intelligence is transitioning from a linguistic interface to a functional cognitive engine capable of deep, multi-hour logic synthesis.
The saturation of the GSM8K, MATH, and AIME benchmarks confirms that scaling inference-time compute through reinforcement learning is currently the most viable path to super-human performance in highly structured domains 12122. The autonomous development of verification strategies by models like OpenAI's o3, and the extreme parameter efficiency achieved by open-weight frameworks like DeepSeek-R1, suggest that the necessity of massive, human-annotated supervised data is diminishing in favor of dense reward signals and algorithm optimization 51250.
However, the dichotomy between informal probabilistic generation and formal symbolic verification remains the central challenge. The field is rapidly bifurcating into models that simulate reasoning through highly effective statistical correlation, and neuro-symbolic hybrids that ground their insights in deterministic axioms 3615. As these systems increasingly interoperate - using language models to navigate the intuition of discovery and symbolic engines to anchor the proofs - AI stands poised to drastically compress the timelines of mathematical research, serving as a rigorous copilot for the exploration of the mathematical sciences 4017.