Mechanisms of in-context learning in large language models
In-context learning represents a profound paradigm shift in artificial intelligence, fundamentally separating the operation of large language models from traditional machine learning architectures. Without undergoing explicit parameter updates or iterative gradient descent optimization, a pre-trained large language model presented with a sequence of input-output examples can dynamically deduce the underlying task structure and apply it to novel queries. This capability, contained entirely within the forward pass of the neural network during inference, facilitates rapid, zero-latency adaptation to previously unseen tasks.
Despite its pervasive utility in modern deployment, the precise mechanisms enabling a static set of weights to simulate complex learning algorithms remain a focal point of intense scientific inquiry. Research spanning theoretical mathematics, mechanistic interpretability, cognitive psychology, and architectural comparisons has generated multiple frameworks to decode this phenomenon. These include modeling the process as implicit Bayesian inference over pre-training distributions, conceptualizing it as the internal simulation of parameter optimization, mapping specific subnetworks of attention heads responsible for inductive copying, and isolating abstract functional vectors in the model's activation space. This report provides a comprehensive examination of how in-context learning functions, the architectural prerequisites necessary for its emergence, and its comparative efficacy against localized fine-tuning methodologies.
Task Recognition and Meta-Learning Spectrum
The foundational debate regarding in-context learning focuses on the exact nature of the "learning" that occurs within the model's forward pass. Early assumptions presupposed that large language models were genuinely absorbing novel input-label mappings directly from the provided context window. However, rigorous empirical testing has continually challenged this assumption, revealing a complex spectrum between the mere retrieval of pre-existing knowledge and genuine, algorithmic meta-learning.
The Task Recognition Hypothesis
A prominent branch of research, significantly advanced by Min et al. (2022), argued that in-context learning does not inherently absorb specific relationships between inputs and labels provided in a prompt 1234. By demonstrating that replacing ground-truth labels with randomized or heavily corrupted labels barely degraded the model's predictive performance on certain classification tasks, researchers posited that the provided demonstrations serve primarily to prime the model rather than instruct it 12. Under this "task recognition" hypothesis, the context window assists the model in identifying the formatting, the general input distribution, and the applicable label space, while the actual mapping relies entirely on preexisting semantic associations forged during the extensive pre-training phase 345.
Further large-scale empirical analyses ablating memorization, distributional shifts, and prompting phrasing have corroborated that in-context learning is often limited in its ability to generalize to truly unseen tasks 5. When exemplars become highly numerous, accuracy frequently becomes insensitive to the exemplar distribution itself, suggesting that the model deduces patterns from regularities in the prompt structure rather than learning a robust, ad-hoc encoded rule 5. This highlights a degree of distributional fragility, particularly when utilizing complex phrasing structures like chain-of-thought prompting 5.
Evidence for Genuine Task Learning
Subsequent literature has contested the strict universality of the task recognition hypothesis, arguing that it primarily holds true for smaller parameter models, shorter context windows, or tasks that are already deeply entrenched in the pre-training corpus 23. Probabilistic analyses utilizing larger context sizes demonstrate that in-context predictions almost always exhibit a heavy dependency on the specific in-context labels provided 23.
When evaluated on complex, genuinely novel tasks that possess no parallel in the pre-training data - such as authorship identification based on private, unseen messages or synthetic mapping tasks that explicitly contradict pre-training priors - large language models demonstrate a distinct capacity to learn novel conditional label distributions 3. Consequently, in-context learning is more accurately modeled as operating along a continuous spectrum. When a prompt aligns with existing pre-training preferences, the model primarily engages in rapid knowledge retrieval 6. When a prompt introduces a truly novel functional mapping, the model engages in bounded meta-learning 56. Nevertheless, this meta-learning remains constrained; models frequently struggle to fully override deep-seated pre-training biases and exhibit a pronounced sensitivity to the physical ordering and proximity of information within the context window 3.
Implicit Bayesian Inference Frameworks
To explain how static weights can compute dynamic task adaptations, theorists have proposed mathematical frameworks that map the forward pass of a transformer to established statistical learning algorithms. One of the primary theoretical lenses views in-context learning as an emergent form of implicit Bayesian inference.
Latent Variable Marginalization
The Bayesian inference framework posits that in-context learning emerges naturally from the core objective of next-token prediction, provided the model is trained on a massive corpus exhibiting long-range semantic coherence 78910. Documents in natural pre-training datasets are rarely random assortments of tokens; they are systematically generated by latent variables that represent abstract concepts, overarching topics, or distinct data-generating functions, frequently modeled mathematically as a mixture of Hidden Markov Models (HMMs) 79.
According to theories developed by Xie et al. (2022) and corroborated by subsequent Stanford University studies, a large language model optimized for next-token prediction is forced to implicitly infer these latent variables to minimize its loss function 47810. When presented with an in-context learning prompt consisting of multiple input-output pairs at inference time, the model utilizes this identical generative structure to form a statistical posterior distribution over the possible latent concepts that could have generated the specific prompt 4710. The model's prediction for a novel test query is thereby calculated as a marginalization over this inferred posterior distribution 7.
Signal-to-Noise Ratios in Prompt Formulation
The Bayesian perspective elegantly explains why the structural formatting of prompts profoundly impacts performance and why models exhibit varying degrees of robustness to noisy data. The training examples provided in a prompt yield a statistical signal, which can be quantified as the Kullback-Leibler divergence between the target task concept and other competing concepts within the model's hypothesis space 8. Conversely, the transitions between disparate examples within the prompt introduce noise 8.
If the signal generated by the shared latent concept significantly outweighs the transitional noise, Bayes-consistent inference occurs 8. This mechanism explains why in-context learning successfully emerges despite the structural mismatch between artificially concatenated prompt examples and the natural, flowing documents the model was originally trained on 789. It also provides a theoretical foundation for understanding scaling laws; larger models trained on vaster, more coherent datasets develop a more precise structural mapping of latent variables, leading directly to the emergent capabilities associated with few-shot learning 79.
Implicit Gradient Descent and Optimization
Parallel to Bayesian theories, a distinct mathematical framework argues that the transformer architecture's forward pass literally simulates the mechanics of parameter optimization algorithms, such as gradient descent or closed-form ridge regression 810111312.
Simulation of Linear Regression
Research conducted by von Oswald et al., Akyürek et al., and Andreas provides constructive proofs demonstrating that the operations intrinsic to multi-head self-attention and feed-forward networks mathematically align with the iterative update steps of gradient descent 1011. Under this formulation, the transformer dynamically encodes a smaller, implicit linear model directly within its internal activations.
As new examples are sequentially processed within the context window, the attention mechanisms execute rank-one updates to an implicit weight matrix. This process is mathematically analogous to constructing the inverse covariance matrix required for exact least-squares regression 11. The trained in-context learners closely match the precise predictors computed by standard gradient descent, transitioning fluidly between different predictor types as transformer depth and dataset noise vary 11. Late layers in the network have been shown to non-linearly encode these temporary weight vectors and moment matrices, indicating that in-context learners fundamentally rediscover standard estimation algorithms during their forward operations 11.
Contextual Transformation of MLP Weights
Recent advancements exploring the implicit dynamics of in-context learning demonstrate that this optimization is not merely abstract. The specific architectural stacking of a self-attention layer followed immediately by a Multilayer Perceptron (MLP) enables the transformer block to execute a context-dependent, low-rank weight update directly to the MLP's parameters during the forward pass 131213.
By extracting representations across multiple residual layers, researchers have tracked the gradual overriding of pre-trained semantics by in-context information, observing that deeper layers actively modify their functional output based on the prompt's data 1316. The context is algebraically transformed into a low-rank weight update for the first MLP layer, generating a concrete mechanism for adaptation that occurs strictly at inference time 1213. This implicit meta-optimization allows the network to simulate the fine-tuning process without permanently altering the globally stored parameters, resolving the paradox of how a frozen model can acquire highly specialized, context-dependent behaviors 1313.
Mechanistic Interpretability and Induction Circuits
While theoretical and mathematical frameworks explain the algorithmic equivalence of in-context learning, the field of mechanistic interpretability seeks to reverse-engineer the specific neural circuitry responsible for executing these operations. This approach treats neural networks not as black boxes, but as computational graphs composed of distinct, analyzable sub-circuits 1714.
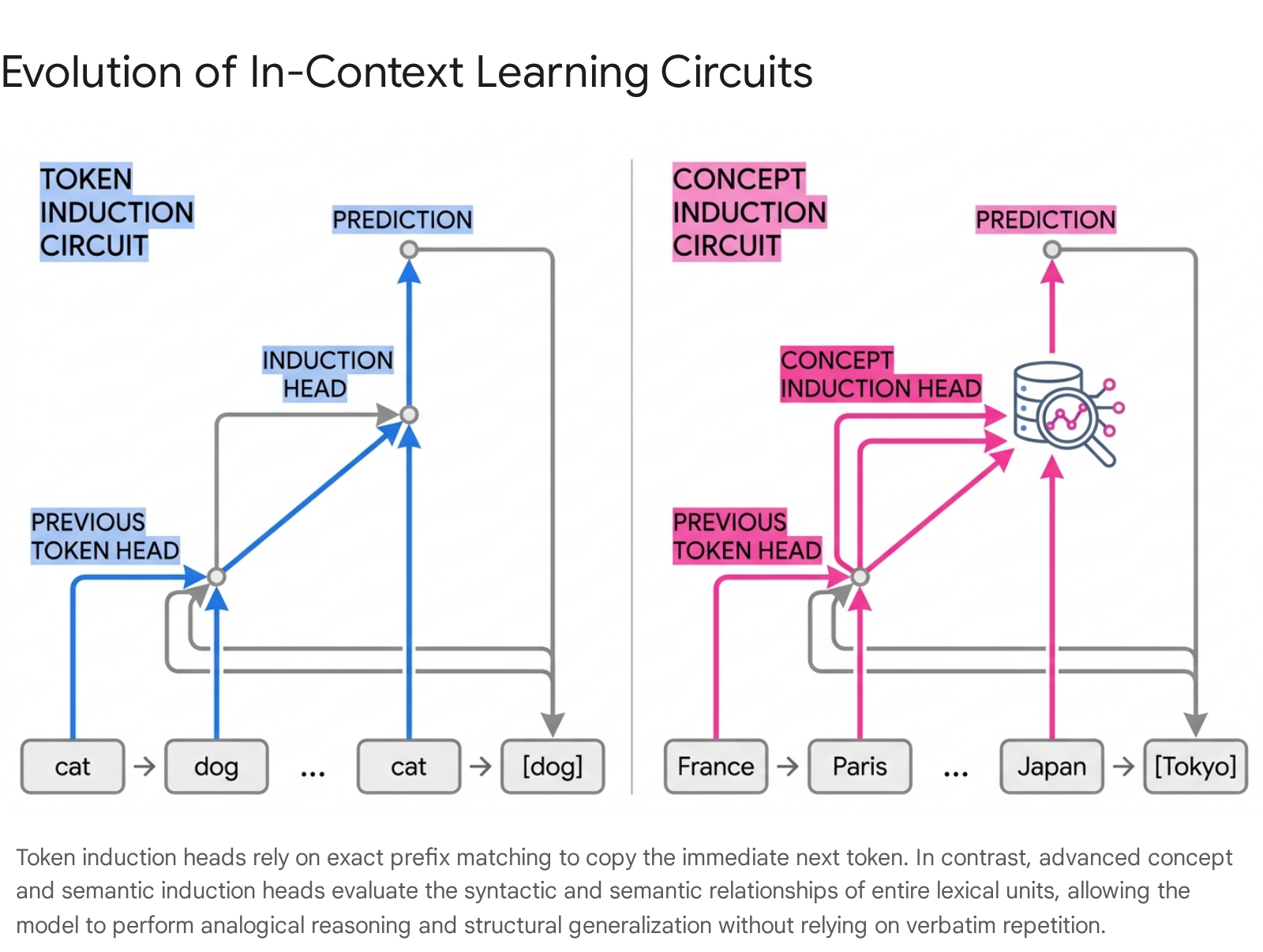
The Token-Level Induction Head Mechanism
The most robustly identified neural mechanism facilitating in-context learning is the "induction head" circuit, initially isolated and characterized by Elhage et al. (2021) and Olsson et al. (2022) 1715161718. Induction heads operate via a match-and-copy algorithm that enables a language model to recognize repeating sequential patterns within its context and output their historical continuations verbatim 151819.
The standard induction circuit functions through a two-step mechanism known as K-composition, which fundamentally requires information to pass through at least two separate transformer layers:
1. The Previous Token Head: Operating in an early layer, this attention head focuses strictly on the immediately preceding position in the sequence. It copies information regarding token $i-1$ directly into the residual stream of token $i$, ensuring that each position carries both its own identity and the identity of its predecessor 1819.
2. The Induction Head: A subsequent-layer head reads this composite representation from the residual stream. If the sequence features repeating tokens (e.g., [A][B] ... [A]), the induction head at the second [A] uses its query vector to search the sequence history for a key matching the previous context of [A]. Upon locating the first [A] - which currently holds information about the subsequent [B] - the head attends to [B] and promotes its corresponding logits in the final output distribution 181920.
The development of these induction heads during the pre-training phase correlates with a highly distinctive, sharp phase change in the model's loss curve. This phase change marks the exact computational moment the model acquires the capacity to utilize distant context effectively, transitioning from a simple n-gram predictor to an in-context learner 151819. Ablation studies demonstrate that forcefully removing induction heads in smaller models entirely eliminates their baseline in-context learning capabilities 1821.
Emergence of Concept and Semantic Heads
While standard token-level induction heads successfully explain verbatim sequence copying, they are fundamentally insufficient for explaining the complex analogical reasoning, syntactic manipulation, or linguistic translation tasks commonly performed via in-context learning. To account for this, mechanistic research conducted between 2024 and 2025 isolated more advanced, sophisticated derivations of the induction circuitry: semantic induction heads and concept induction heads 14212223.
Semantic Feature Extraction
Rather than blindly promoting the exact token that historically followed a matched prefix, semantic induction heads function by raising the output logits of tail tokens associated with specific latent relationships 202224. These relationships encompass syntactic dependencies extracted from grammatical structures or relational links mirroring knowledge graphs 20.
For example, if an in-context prompt establishes a distinct relational pattern (e.g., establishing a sequence of countries and their corresponding capital cities), attending to the subsequent head token "Japan" will trigger the semantic induction head. Instead of copying a historical string, the head recalls the tail token "Tokyo" based purely on matching the semantic feature vector mapped by the prompt's established relational logic 20. Studies confirm that the formulation of these semantic induction heads tracks closely with a model's emergence of complex in-context pattern discovery capabilities 22.
Multi-Token Concept Routing
Building on semantic identification, Feucht et al. (2025) identified concept induction heads, a specialized circuitry that operates on entire, multi-token conceptual units rather than arbitrary sub-word tokens 142325. Concept induction heads learn to attend explicitly to the end boundaries of multi-token words across the entirety of the training phase.
By conducting targeted lesioning and ablation studies, researchers proved that these separate circuits govern entirely different execution pathways. When standard token induction heads are ablated, models lose the ability to perform verbatim copying but will systematically paraphrase the requested output 142325. Conversely, ablating concept induction heads destroys the model's capacity to perform semantic tasks, high-level translations, and fuzzy copying operations 142325. Consequently, modern theoretical consensus views in-context learning not as the product of a monolithic mechanism, but as the concerted operation of a diverse "zoo" of attention heads. This includes token heads, semantic heads, n-gram heads, and symbolic heads, all operating in parallel to construct a functional hierarchy of adaptive reasoning 141921.
Task Vectors and the Linear Combination Conjecture
Mechanistic research has not only mapped the circuitry responsible for reading context but has also identified the precise format in which abstract instructions are stored and transported throughout the network. Through rigorous causal mediation analysis, analysts discovered that transformer models compress the complex task instructions defined implicitly by prompt demonstrations into a single, highly structured internal representation. This representation is formally categorized as a "task vector" or "function vector" 2631322728.
Robustness and Transferability of Functional Abstractions
A function vector is defined as a specific geometric direction within the model's activation space that rigidly encodes the abstract task itself (e.g., the command "translate from English to French" or "output the antonym") completely independent of the specific input-output string mappings from which the task was derived 313229. During the processing of an in-context learning prompt, a small subset of attention heads located primarily in the middle layers of the transformer calculates this exact vector and transports it forward through the residual stream 29.
These function vectors demonstrate extraordinary robustness and transferability. If an active task vector is mathematically extracted from a model currently processing a few-shot English-to-French translation prompt, that isolated vector can subsequently be injected into a completely different, zero-shot forward pass - one devoid of any contextual examples. The injected vector will forcefully steer the model to execute the French translation on the new, isolated input 312829. This empirical validation proves that in-context learning generates reusable, abstract semantic representations that operate as linear parameters within the network 3132. Furthermore, this mechanism scales beyond text; Multimodal Task Vectors (MTV) have been successfully extracted from Large Multimodal Models, enabling the massive compression of complex vision-language mappings without necessitating fine-tuning 27.
Mechanics of the Linear Combination Conjecture
The precise mathematical formation of these task vectors from raw text remained speculative until the proposal of the Linear Combination Conjecture by Dong et al. (2025) 1036. This theory posits that the centralized task vector, which emerges at the final query token of a prompt, is literally formed by the algebraic linear combination of the hidden states derived from the preceding in-context demonstrations 103630.
By plotting the mathematical process, the input-output text strings (e.g., "Cat->Gato," "Dog->Perro") are mapped into distinct, multidimensional geometric vectors. These individual vectors are then algorithmically summed together using distinct learned weights to form a single, highly concentrated algebraic entity - the Task Vector. When this resultant vector is injected into the residual stream of a novel input node, it acts as a synthesized proxy for a 1-shot demonstration, overriding default pathways to dictate the final output prediction.
By theoretically analyzing the complex loss landscape of linear-attention transformers functioning on triplet-formatted prompts, researchers proved that these combinations naturally crystallize at "arrow" or separator tokens, providing critical redundancy against information loss 10. However, the Linear Combination Conjecture also reveals a strict mathematical constraint. Because an inference utilizing a single task vector functions analogously to 1-shot in-context learning, it is inherently limited to representing low-complexity, rank-one meta-predictors under the gradient descent simulation perspective 10. Dong et al. validated this rank bottleneck by testing models against high-rank bijection tasks, confirming that a single task vector invariably fails to capture highly multidimensional mappings. To bypass this inherent limitation, researchers discovered that injecting multiple distinct task vectors back into the prompt drastically enriches the input representation, enabling the model to solve substantially more complex functions 1036.
Architectural Comparisons and State Space Models
The internal mechanics of in-context learning are entirely reliant on the underlying neural architecture. While standard transformers achieve remarkable in-context adaptability via full causal self-attention, the quadratic computational cost associated with scaling this attention mechanism has spurred the adoption of sub-quadratic architectures. State Space Models (SSMs), with Mamba representing the foremost iteration, offer linear scaling but present fundamentally different approaches to sequence tracking, illuminating the precise architectural requirements for optimal in-context learning 38313241.
Stateless Attention Versus Stateful Compression
Standard transformer architectures are intrinsically stateless; they maintain an exact Key-Value (KV) cache containing all historical tokens processed within the sequence window. This lack of compression allows the attention heads to perform perfect, lossless routing of information from any past position, a prerequisite for the precise prefix matching utilized by induction heads 4243.
Conversely, State Space Models like Mamba and Mamba2 are stateful. To bypass the quadratic memory bottleneck, they continuously compress historical sequences into a fixed-size, input-dependent hidden state matrix utilizing selective convolutions and specific gating algorithms 383243. Because SSMs actively compress the past, their in-context learning capabilities are highly domain-specific and frequently inconsistent 42.
Empirical benchmarking comparing 8B parameter Mamba models against equivalent-sized Transformers reveals stark operational differences. While both architectures exhibit similar innate knowledge bases (evidenced by equivalent 0-shot performance metrics), Mamba significantly underperforms Transformers in 5-shot in-context learning scenarios on comprehensive reasoning benchmarks like MMLU 42. Mamba performs admirably on standard regression tasks and actively outperforms Transformers on rigid, rule-bound tasks such as sparse parity learning. However, it fails catastrophically on non-standard retrieval functionalities that require exact, lossless access to highly specific prior context 383133. The fixed-size hidden state struggles to definitively isolate task-relevant signals from background noise when confronted with long, complex textual demonstrations 4243.
Hybrid Architectures and Compartmentalization of Learning
To mitigate the contextual shortcomings of SSMs while preserving their linear scaling advantages, hardware researchers have developed hybrid architectures - including MambaFormer, Jamba, TransMamba, and Zamba. These models intricately interleave SSM blocks with traditional multi-head self-attention blocks to capture the benefits of both paradigms 3141423345.
| Architecture Classification | State Tracking Mechanism | In-Context Learning Efficacy | Primary Architectural Limitations |
|---|---|---|---|
| Pure Transformer | Stateless (Lossless KV Cache) | Exceptional; reliable multi-shot adaptation and exact historical retrieval. | Severe quadratic compute and memory bottleneck over extended context windows. |
| Pure SSM (Mamba/Mamba2) | Stateful (Compressed Hidden State) | Highly variable; strong on regression and parity, poor on complex multi-shot logic. | Irreversible loss of precise historical token data due to continuous state compression. |
| Hybrid (e.g., MambaFormer, Zamba) | Interleaved (KV Cache + State Matrix) | Best-of-both-worlds; achieves high ICL fidelity across diverse task types. | High architectural complexity; requires intensive tuning to balance layer placement. |
Mechanistic evaluations of these hybrid models confirm that the computational responsibility for in-context learning is highly compartmentalized. In hybrid models such as Zamba2 and Hymba, the function vectors responsible for directing in-context learning and executing parametric knowledge retrieval are overwhelmingly concentrated within the self-attention layers, leaving the Mamba layers largely uninvolved in these specific vector computations 4546. This strict functional divide suggests that while State Space layers efficiently model local sequence continuity and process general context, the rigorous structural pattern matching required for few-shot task abstraction remains heavily reliant on the exact cross-token routing provided exclusively by self-attention mechanisms 45.
Working Memory Capacity and Cognitive Overload
As the mechanistic understanding of in-context learning deepens, researchers across cognitive science and computer science are drawing direct parallels between in-context processing in language models and the psychological frameworks of human working memory 47483435.
In foundational cognitive science, Information Processing Theory dictates a rigid distinction between Long-Term Memory (LTM) - a vast, permanent collection of neural associations - and Working Short-Term Memory (WSTM) - a highly constrained, transient workspace utilized for active data manipulation and immediate decision-making 5152. Translating this to artificial systems, the large language model's static parameters essentially represent the permanent LTM, while the active context window, driven by the dynamic updates of in-context learning, functions as the transient WSTM 53363738.
Despite recent hardware advances allowing models to accept context windows spanning millions of tokens, simply expanding the context array does not automatically scale the model's true cognitive workspace or processing limits 57. Extensive studies subjecting large language models to rigorous human cognitive assessments, such as the demanding N-back task, reveal that models suffer from severe "cognitive overload" when the volume and difficulty of tasks within a single prompt exceed a specific threshold 483639. When operating under high informational demands, models exhibit critical failure modes echoing human cognitive fatigue - producing self-contradictory logic, losing track of sub-task goals, and failing to execute multi-step mental reasoning 48353639.
These findings indicate that despite massive scale, large language models fundamentally lack the autonomous metacognitive ability to hold, securely manipulate, and iteratively update abstract latent information over multiple conceptual steps without relying heavily on explicitly generated external text buffers 3539. Current passive retrieval systems, such as standard Retrieval-Augmented Generation (RAG), fail to mimic the dynamic, task-driven nature of human metacognitive control 57. To achieve true functional infinite context, advanced paradigms like the proposed "Cognitive Workspace" framework advocate for active memory management. This involves utilizing hierarchical cognitive buffers and deliberate information curation algorithms to maintain persistent, stable working states, superseding the fragile, ad-hoc representations generated during standard in-context learning 5357.
Adaptation Strategy Trade-Offs
Understanding the underlying mechanisms, limits, and architectural dependencies of in-context learning directly informs strategic deployment in production environments. System architects must frequently decide between leveraging transient in-context learning (ICL), full Supervised Fine-Tuning (SFT), or Parameter-Efficient Fine-Tuning (PEFT) methods like Low-Rank Adaptation (LoRA) 5940.
Recent comprehensive comparative studies evaluating these distinct paradigms under strict, data-scarce scenarios highlight severe trade-offs between computational efficiency, raw skill acquisition, and historical knowledge retention 5940.
| Adaptation Methodology | Core Mechanism of Action | Compute & VRAM Cost Profile | Base Knowledge Retention | Novel Skill Acquisition Efficacy |
|---|---|---|---|---|
| In-Context Learning (ICL) | Transient latent activation updates strictly during the forward inference pass. | Training: Zero. Inference: High (Requires extensive KV Cache). |
Perfect. No permanent weight modifications occur, completely eliminating catastrophic forgetting. | Limited. Highly effective for formatting and facts, but struggles to permanently impart complex, non-native reasoning. |
| Supervised Fine-Tuning (SFT) | Full, global parameter gradient updates across all network layers during training. | Training: Extremely High. Inference: Standard baseline. |
Poor. Highly susceptible to severe catastrophic forgetting of generalized reasoning capabilities. | Exceptional. Fastest acquisition of complex, domain-specific skills requiring the absolute fewest data examples. |
| Low-Rank Adaptation (LoRA) | Updates restricted to injected low-rank matrices; core base model weights remain entirely frozen. | Training: Moderate to Low. Inference: Standard baseline. |
Strong. Constrained low-rank updates act as structural regularizers, preserving the integrity of base knowledge. | Good. Capable of mastering complex skills, but requires a higher "critical mass" of training data compared to SFT. |
Full Supervised Fine-Tuning requires updating billions of model weights simultaneously. While this embeds highly specific, complex skills extremely rapidly, it invariably triggers catastrophic forgetting - the aggressive degradation of the model's pre-trained general reasoning and factual knowledge capabilities as the network blindly over-optimizes on a narrow task distribution 59406141.
Low-Rank Adaptation mitigates this memory destruction by completely freezing the foundational model and isolating updates to approximately 1% of the parameter space via attached low-rank matrices 636465. Because LoRA structurally restricts the subspace available for optimization, it inherently acts as a powerful regularizer; the model "learns less and forgets less" 5941. LoRA effectively protects generalized world knowledge while successfully instilling new architectural skills, provided the system is fed a sufficient critical mass of training data to map the low-rank approximations 5941.
In-context learning remains highly attractive due to its absolute zero training cost and complete immunity to catastrophic forgetting, making it unparalleled for real-time, low-latency adaptation and dynamic multimodal integration 4066. However, because the implicit gradient updates executed during in-context learning are entirely transient and rigidly constrained by the limits of the model's working memory capacity and the mathematical rank of its task vectors, ICL frequently fails to permanently impart complex, deep-reasoning skills (such as high-level strategic planning) that directly conflict with ingrained pre-training priors 59. Therefore, for robust, domain-specific adaptation requiring structural, persistent shifts in behavior, LoRA represents the optimal optimization strategy, while in-context learning serves as the premier, zero-latency interface for dynamic, transient task alignment.