Internal world models in artificial intelligence
Theoretical Foundations of World Models
The concept of a "world model" in artificial intelligence designates the capacity of a computational system to construct an internal, predictive representation of its environment. Rather than relying solely on surface-level statistical correlations or reactive stimulus-response mappings, an AI agent possessing a world model mathematically simulates the causal dynamics, spatiotemporal relationships, and structural rules of the domain in which it operates. This internal simulation mechanism allows the system to predict future states, infer missing or hidden information, and plan actions counterfactually without requiring direct environmental interaction 12.
Historically rooted in optimal control theory and reinforcement learning (RL), world models serve to alleviate the immense sample complexity associated with trial-and-error learning 23. If an agent possesses a faithful algorithmic simulation of its environment, it can learn optimal behaviors entirely within its own internal "imagination," vastly reducing the need to collect physical or simulated real-world data 24. Contemporary surveys typically categorize the functionality of world models into two primary domains: understanding the present state of the external world (e.g., encoding structural relationships, tracking hidden variables) and predicting the future dynamics of the physical world (e.g., video generation, embodied environment simulation) 13.
The debate surrounding the existence and efficacy of world models has expanded significantly with the rise of massive unsupervised and self-supervised architectures, particularly Large Language Models (LLMs) and diffusion-based video generation models. A central inquiry in modern AI research is whether systems trained exclusively on generative objectives - such as autoregressive next-token prediction or pixel-level denoising - incidentally construct robust, causal models of reality, or whether they merely memorize shallow heuristic patterns 56.
Explicit World Models in Reinforcement Learning
In model-based reinforcement learning (MBRL), world models are explicitly engineered architectural components designed to simulate environment dynamics. The Dreamer algorithmic lineage, culminating in DreamerV3, provides a foundational blueprint for how neural networks can map high-dimensional, multimodal sensory inputs into a tractable internal simulation 4. DreamerV3 demonstrates state-of-the-art performance across diverse domains - including continuous robotics control, discrete Atari games, and highly sparse-reward environments like Minecraft - using a single, fixed set of hyperparameters 478.
Recurrent State-Space Models
The core computational engine of the Dreamer architecture is the Recurrent State-Space Model (RSSM), which functions as the explicit world model. The RSSM continuously integrates historical environmental observations into a compact hidden state and simulates forward dynamics independently of the external environment 79. The RSSM is a composite architecture consisting of several interconnected neural components. First, a Sequence Model (typically a Gated Recurrent Unit, or GRU) maintains a deterministic hidden state ($h_t$) to track historical context across time steps 49. Second, an Encoder compresses the current sensory input ($x_t$) combined with the recurrent hidden state ($h_t$) into a stochastic latent embedding ($z_t$) 89.
The critical simulation capability is provided by the Dynamics Predictor, which predicts the subsequent latent embedding ($z_t$) relying solely on the prior hidden state ($h_t$), without requiring access to the actual external observation 79. Concurrently, Reward and Continuation Predictors estimate the immediate environmental reward and whether the current episode will terminate, basing their calculations entirely on the latent state representation 9. Finally, a Decoder reconstructs the raw input from the latent state to provide a rich self-supervised learning signal, ensuring that the latent space captures all physically and contextually relevant environmental features 89.
Discrete Latent Representations
A pivotal architectural evolution in the Dreamer series was the transition from continuous to discrete latent representations. DreamerV1 utilized continuous Gaussian variables to encode its latent space, a design choice that proved optimal for the smooth, continuous physical dynamics typical of robotic control tasks 4. However, this inductive bias failed drastically in environments characterized by abrupt, non-smooth state changes, such as classic Atari 2600 games where objects appear or vanish instantly, or where an agent transitions between entirely distinct game phases in a single frame 4.
Recognizing that a world model's performance is fundamentally constrained by its representational framework, researchers restructured the latent state $z_t$ in DreamerV2 and DreamerV3 as a set of 32 one-hot vectors sampled from 32 distinct categorical distributions 47. A unimodal continuous distribution inherently struggles to capture a future that could diverge into one of several highly distinct, mutually exclusive possibilities; discrete categories naturally accommodate this 4. Because standard backpropagation cannot natively pass gradients through discrete sampling operations, the architecture employs "straight-through gradients" to optimize the discrete latent variables 7.
Latent Optimization and Policy Execution
The RSSM is trained jointly via prediction, dynamics, and representation losses. To ensure that the internal representations remain robust, the model employs Kullback-Leibler (KL) balancing, preventing trivial solutions by forcing the dynamics predictor to match the representations derived from actual observations 7. Once the world model is sufficiently trained, DreamerV3's actor and critic networks learn entirely within the "dream" - a purely simulated trajectory of latent states 789.
The actor network optimizes a policy by maximizing expected lambda-returns generated by the critic across these simulated future trajectories 47. To handle widespread return distributions across varied environments, the critic utilizes an exponential moving average (EMA) to stabilize target networks and predicts two-hot-encoded symlog-transformed returns 810. Because the model accurately predicts rewards and episode terminations within its discrete latent space, DreamerV3 successfully learned to collect diamonds in Minecraft entirely from scratch, without human curriculum or demonstration data - a landmark validation of explicit world modeling in highly complex, open-ended environments 48.
Predictive Latent Architectures in Visual and Spatial Domains
While MBRL utilizes explicit world models for active decision-making, representation learning in spatial and visual domains has historically relied on generative reconstruction. Standard masked autoencoders attempt to perfectly reconstruct missing pixels from an input image or video. The Joint Embedding Predictive Architecture (JEPA), proposed by AI researcher Yann LeCun, abandons pixel-level generation in favor of purely abstract predictive world modeling 111213.
The Mechanism of Joint Embedding Predictive Architectures
The central theoretical premise of JEPA is that generating raw sensory data is computationally wasteful and mathematically unstable due to the inherent stochasticity of the physical world 121415. If a system attempts to generate the exact pixel layout of a crashing wave, the precise texture of moving foliage, or the static noise in a video frame, it exhausts its capacity modeling irrelevant, unpredictable details 1215. Instead, a functional world model should capture high-level semantic dynamics and causal structures 1617.
JEPA operates as an energy-based model featuring a tripartite structure: a context encoder, a target encoder, and a predictor network 13. The system processes a context block of an image or video, converts it into a latent embedding, and tasks the predictor network with forecasting the representation of the target block (the missing spatial or temporal information) 1113. Crucially, the target representation is not a fixed label; it is computed dynamically by the target encoder. The weights of the target encoder are updated via an exponential moving average (EMA) of the context encoder's weights 1113. This specific mechanism - analogous to self-supervised frameworks like BYOL or data2vec - prevents representational collapse (where the model outputs a constant vector for all inputs) without requiring computationally expensive contrastive negative sampling 1113. By predicting in a latent space, JEPA intrinsically suppresses high-variance, unpredictable features and attends to mutually predictive, semantically meaningful abstractions 1613.
Extensions to Video and Object-Centric Models
The JEPA framework has evolved into temporal and structured variants designed to simulate physical laws more accurately. V-JEPA (Video-JEPA) masks spatiotemporal tubes within video sequences, forcing the predictor to forecast the latent states of hidden video segments. This process compels the model to learn intuitive physics, object permanence, and dynamic interactions 141714.
Furthermore, C-JEPA extends this paradigm to object-centric representations. Rather than masking arbitrary geometric image patches, C-JEPA applies strict object-level masking, forcing the model to infer a hidden object's state based exclusively on the dynamics and positions of surrounding visible objects 14. This acts as a latent intervention that prevents the model from relying on shortcut solutions, making complex interaction reasoning essential 14. Empirical analysis demonstrates that C-JEPA vastly improves counterfactual reasoning in visual question-answering tasks - yielding an absolute improvement of approximately 20% compared to non-object-centric architectures 14. On agent control tasks, C-JEPA allows for highly efficient model-based planning, utilizing only 1% of the total latent input features required by standard patch-based world models while achieving comparable performance 14.
Adapting Predictive Architectures to Language
While JEPA originated in continuous sensory domains like vision, recent efforts have attempted to transpose this predictive architecture into the domain of natural language, resulting in LLM-JEPA 15. Historically, LLM pre-training and fine-tuning have relied entirely on input-space reconstruction (autoregressive next-token prediction) 15. LLM-JEPA utilizes custom attention masks to predict future text representations in an embedding space 15. Early empirical validations across models such as Llama-3, Gemma-2, and OpenELM indicate that training language models with JEPA-style latent predictive objectives outperforms standard generative objectives in reasoning tasks, demonstrating increased robustness to overfitting and inducing highly structured textual representations 15.
Autoregressive Language Models as World Simulators
A highly contested topic in modern artificial intelligence is whether autoregressive large language models, which are trained purely on next-token prediction over text corpora, develop internal world models or operate strictly as sophisticated, stochastic pattern matchers 56. Recent empirical research utilizing mechanistic interpretability and linear probing provides compelling, quantifiable evidence that LLMs do construct structured representations of reality within their residual streams 616.
The Othello-GPT Phenomenon
The "Othello World Model Hypothesis" provides one of the most rigorously analyzed demonstrations of an LLM inducing an internal environment simulator 617. In a series of experiments, researchers trained a GPT variant (Othello-GPT) on a synthetic dataset of randomly generated, legal Othello moves 16. The model received sequences of board coordinates (e.g., "C3, D3") and was tasked solely with predicting the next legal move. The model received no explicit rules regarding the game's mechanics, nor any prior knowledge of the spatial dimensions of an 8x8 grid 16.
Initial probing by the original authors found that non-linear multi-layer perceptrons (MLPs) could successfully extract the full board state from the model's internal activations, achieving a 1.7% error rate, but standard linear probes failed significantly, returning a 20.4% error rate 16. This discrepancy initially led researchers to conclude that the model's world representation was highly non-linear and entangled 16.
However, subsequent mechanistic analysis by Nanda et al. revealed a profound epistemological shift: the world model was perfectly linear, but it was perspective-dependent 16. The model did not represent grid squares as absolutely "black" or "white." Because the model was trained to play both sides of the game, it mapped the board relative to the current turn - representing pieces as "my color" or "their color" 1618. When researchers utilized an absolute linear probe, it failed because the representation mathematically flipped from positive to negative on alternating turns 16. Once the linear probe was adjusted for this turn-parity perspective, it extracted the board state with near-perfect accuracy 1618.
Crucially, this internal representation was proven to be causally active. By performing linear vector arithmetic on the residual stream at layer 4 - where the board state is fully computed - researchers could artificially "flip" the color of a piece in the model's internal memory 16. In response, the model immediately updated its output predictions to match the newly edited, counterfactual board state, proving that the latent representation directly governs behavior rather than existing as a passive artifact 16. Recent follow-up studies submitted to ICLR 2025 demonstrated that this emergent capability generalizes across architectures; larger foundation models including Llama-2, Mistral, and Qwen2.5 induce the Othello board layout with up to 99% accuracy in unsupervised grounding 172419.
Spatiotemporal and Syntactic Grounding
Evidence of implicit world modeling extends beyond constrained deterministic games to the physical realities of space, time, and linguistics. Research mapping the internal activations of the Llama-2 family reveals that LLMs learn linear representations of both space and time across multiple contextual scales 5. By training linear ridge regression probes on the hidden states of entities (e.g., global cities, natural landmarks, historical figures), researchers discovered specific "space neurons" and "time neurons" that reliably encode two-dimensional geographic coordinates (latitude and longitude) and one-dimensional temporal coordinates (timestamps) 5.
These representations generally improve in resolution and accuracy with model scale (e.g., Llama-2-70B outperforming the 7B variant) and typically solidify in the early-to-middle layers of the network, plateauing around the halfway point of the transformer depth 5. Furthermore, models represent diverse entity types - such as plotting populated cities and natural landmarks - within a unified coordinate system 5. While the models exhibit performance degradation when confronted with noisy prompts, and struggle with absolute positioning on completely held-out geographic regions (indicating potential memorization of human-to-model coordinate transformations), the robust relative spatiotemporal mapping strongly suggests the presence of a grounded internal map 5.
Similar structural grounding is observed in linguistic syntax. Hewitt and Manning's structural probes demonstrated that contextual word embeddings (such as those in BERT and ELMo) embed entire syntax trees within their vector geometry 2021. By identifying a specific linear transformation, researchers showed that the squared L2 distance between word vectors directly correlates with the number of edges separating those words in a dependency parse tree 2223. Furthermore, the squared L2 norm under this transformation correlates directly with the word's depth in the parsed tree 20. These findings assert that models exposed only to raw text sequences naturally deduce and encode the hierarchical, tree-based structure of human language, eschewing flat statistical correlations for deep structural geometry 2324.
Anticipating Epistemic Correctness
An advanced dimension of world modeling involves a model's internal tracking of its own knowledge boundaries. Recent studies extracted residual stream activations after an LLM read a prompt but strictly before it generated any output tokens 2526. Linear probes trained on this intermediate pre-generation state successfully predicted whether the model's forthcoming answer would be correct 2526.
This "in-advance correctness direction" generalizes across out-of-distribution knowledge datasets and consistently outperforms the model's own verbalized confidence (which is often poorly calibrated or susceptible to sycophancy) 25. Furthermore, when models generate an "I don't know" response, their internal activations strongly align with this probe score, indicating that the network internally flags its epistemic state and competence level before executing the generation 2526. Notably, this predictive power saturates in the intermediate layers but falters on questions requiring deep mathematical reasoning, illustrating a boundary in the model's meta-cognitive world state where rote factual certainty diverges from logical computation 2526.
| Phenomenon | Probing Methodology | Target Internal Representation | Key Findings / Limitations |
|---|---|---|---|
| Othello Board State | Linear probing (turn-parity adjusted); Activation patching 16. | Spatial geometry of 8x8 grid; Player vs. Opponent piece mapping 16. | Achieves >99% accuracy; Causal link proven via intervention. Dependent on game rules 1624. |
| Space and Time | Linear ridge regression; Principal Component Analysis (PCA) 5. | Two-dimensional Latitude/Longitude; One-dimensional absolute timestamps 5. | Unified representation across entity types. Generalizes poorly to absolute held-out regions 5. |
| Linguistic Syntax | Structural distance probes (L2 norm) 20. | Undirected Unlabeled Attachment Score; Dependency tree distance 2224. | Discovers hierarchical tree structures embedded entirely in continuous vector spaces 24. |
| Answer Correctness | Pre-generation linear probing 25. | Epistemic certainty; "In-advance correctness direction" 2526. | Accurately predicts "I don't know" logic before token generation; Fails to predict mathematical reasoning success 25. |
Mechanistic Interpretability: The "Probe vs. Feature" Debate
While probing yields compelling evidence for world models, the epistemological validity of these tools is fiercely debated within the mechanistic interpretability community. Mechanistic interpretability seeks to reverse-engineer neural networks at the algorithmic level, identifying the precise causal computations transforming inputs into outputs 3327. A central controversy in this field is whether a trained probe discovers a pre-existing, causally active feature inherently utilized by the model, or whether the supervised probe learns the target concept by aggregating loosely correlated, non-causal variables scattered throughout the network 28.
The Epistemology of Linear Probes
The linear representation hypothesis posits that neural networks naturally compute and store distinct semantic features as vectors (directions) in their high-dimensional activation space 1629. Under this hypothesis, if a simple linear probe cannot detect a feature, the feature does not explicitly exist in the representation. Conversely, if a complex non-linear probe succeeds where a linear probe fails, the complex probe is likely combining lower-level features to perform the task itself, rather than reading a fully formed representation from the model 2829.
This dynamic is further complicated by the "Linear Probing then Fine-Tuning" (LP-FT) phenomenon. Theoretical analyses utilizing the Neural Tangent Kernel (NTK) theory reveal that optimizing a linear head during LP significantly increases its norm 373031. When the model is trained with cross-entropy (CE) loss, the linear head norm grows substantially. This increased norm anchors the pre-trained features, minimizing their distortion during the subsequent fine-tuning stage 3730. While this preserves representation quality, it proves that probing physically interacts with the model's weight dynamics and can adversely affect model calibration (a defect generally correctable via temperature scaling) 3730. Ultimately, as an information-theoretic instrument, probes strictly measure mutual information; they capture correlations rather than absolute causation, requiring physical intervention to prove behavioral relevance 28.
Feature Superposition and Sparse Autoencoders
A structural barrier to mapping world models is the phenomenon of "feature superposition," wherein models pack exponentially more features into the residual stream than there are available mathematical dimensions. They achieve this by assigning features to almost-orthogonal, rather than strictly orthogonal, vectors 1840. Because of superposition, individual neurons become highly polysemantic - firing for multiple, seemingly unrelated concepts simultaneously - making it impossible to interpret the world model by looking at single neurons 18.
Sparse Autoencoders (SAEs) have emerged as the premier tool to disentangle these representations. SAEs reconstruct model activations using an overcomplete hidden layer combined with an L1 sparsity penalty, forcing the network to discover a set of monosemantic, interpretable features 1832. However, the aspiration to identify a canonical, objective set of features is challenged by SAE feature inconsistency. Research highlights that independent SAE training runs on the same model activations often yield disparate, non-converging feature sets 32. Recent advancements utilizing the Pairwise Dictionary Mean Correlation Coefficient (PW-MCC) demonstrate that high feature consistency (e.g., >0.80) is attainable with rigorous architectural constraints, establishing a critical mathematical requirement for verifying the exact shape of an LLM's internal world model 32.
Limitations of Counterfactual Interventions
To conclusively prove that a probed feature causally drives a model's behavior, researchers deploy counterfactual interventions, such as activation patching or causal tracing 182933. By ablating or modifying a specific hidden representation and observing a corresponding shift in the output logits, researchers attempt to map the computational circuit 3334.
However, reliance on counterfactuals introduces severe methodological vulnerabilities: 1. Overdetermination (Multiple Sufficient Causes): Neural networks heavily utilize dropout during training, forcing them to develop highly robust, redundant backup circuits 1633. If a concept is governed by multiple independent computational paths, ablating or intervening on only one path will yield no change in the output. This leads researchers to the false negative conclusion that the specific component is irrelevant 33. 2. Non-Transitivity of Counterfactuals: Causal dependence in complex, multi-layer networks is not strictly transitive. If node A influences node B, and node B influences node C, a counterfactual intervention on A might not demonstrably cascade to C due to non-linear saturation effects or compensatory routing mechanisms within the wider circuit 33. 3. Competition of Mechanisms: Models often harbor multiple distinct algorithms for resolving a prompt. For instance, a model may weigh relying on internal factual recall against following explicitly provided counterfactual context 34. Interventions must account for the dynamic interplay, suppression, and competition between these mechanisms, rather than analyzing them in isolated vacuums 34.
Architectural Advancements Facilitating World Models
The evolution of foundation models has introduced novel architectural techniques aimed primarily at maximizing computational efficiency. However, several of these techniques inadvertently strengthen a model's capacity to build coherent world representations by forcing deeper causal grounding and superior memory management 3545.
Mixture-of-Experts and Multi-Token Prediction
Models like Mistral's Mixtral and DeepSeek-V3 utilize Sparse Mixture-of-Experts (MoE) architectures to achieve massive parameter scales with highly efficient inference 4636. DeepSeek-V3 contains 671 billion total parameters, but dynamically routes tokens to activate only 37 billion parameters per forward pass 463749. To prevent MoE routing collapse - where all tokens are sent to a few "popular" experts, starving the rest - DeepSeek-V3 pioneered an auxiliary-loss-free load balancing strategy 355038. By relying on highly fine-grained experts (decomposing the hidden dimension into many smaller sub-networks and utilizing a shared expert for ubiquitous common knowledge), the model compartmentalizes diverse facets of its world knowledge efficiently, preventing catastrophic interference between unrelated concepts 3545.
More critical to the development of rigorous world modeling is the implementation of the Multi-Token Prediction (MTP) objective. In traditional autoregressive training, a model predicts only step $t+1$. DeepSeek-V3's MTP framework forces the model to sequentially predict multiple future tokens at each step, utilizing independent prediction heads 353852. This requires the model to forecast deeper into the causal chain, providing denser training signals. By verifying multiple output tokens simultaneously, the internal representations are forced to stabilize around broader semantic structures and long-term dependencies rather than myopic, immediate statistical correlations 3537.
Latent Attention and Memory Compression
To manage the immense memory demands of massive context windows (often up to 128k tokens), architectures are shifting from standard Multi-Head Attention (MHA) and Grouped-Query Attention (GQA) to Multi-Head Latent Attention (MLA) 3539. Standard MHA requires caching massive Key-Value (KV) vectors for every token across every layer, which heavily bottlenecks inference 39.
MLA resolves this by jointly compressing the Key-Value cache into a single low-dimensional latent vector (e.g., reducing token storage overhead from 14k values down to just 512, representing nearly a 28x reduction in memory footprint) 3539. The model utilizes up-projection and down-projection matrices during inference to decompress this data when necessary 3539. This extreme algorithmic compression acts as a powerful regularizer; it necessitates that the model's embeddings discard superficial noise and preserve only the most salient structural and causal information about the context 39.
Multimodal and Embodied World Models
True world models cannot be restricted purely to text. The integration of continuous sensory streams is essential for Embodied AI architectures to respect and interact with physical constraints 240. Multimodal models bridge the gap between high-level semantic reasoning and physics-aware simulation 40.
Audio and Full-Duplex Dialogue Models
Kyutai's open-source model Moshi demonstrates advanced world modeling in the audio domain, deploying a speech-to-speech foundation model capable of real-time, full-duplex conversational dynamics 415642. Traditional voice assistants rely on pipeline systems: a Speech-to-Text module translates audio to text, an LLM processes the text, and a Text-to-Speech module synthesizes the response 42. This pipeline destroys non-linguistic data (emotion, prosody, pacing) and introduces high latency 42.
Moshi bypasses this by processing audio directly as semantic and acoustic tokens over an underlying 7B-parameter language model backbone (Helium) 5642. Utilizing a state-of-the-art neural audio codec (Mimi) operating at 12Hz, Moshi combines semantic and acoustic data 56. The architecture employs an "Inner Monologue" technique, predicting time-aligned text tokens as a prefix to the generated acoustic tokens, bridging reasoning and audio synthesis 5642. By learning to continuously listen and speak simultaneously without explicit turn-taking markers, the model achieves a theoretical latency of 160ms 5658. Because it models arbitrary conversational dynamics including interruptions and interjections, it internalizes the temporal and emotional dynamics of human interaction, effectively constructing an acoustic world model 4142.
Video Generation and the Physical Simulator Controversy
The intersection of generative AI and physical simulation has sparked significant philosophical and technical disagreement. The controversy centers on whether scaling video generation models constitutes a path toward genuine world simulators 1459.
OpenAI's introduction of Sora - a text-to-video diffusion transformer capable of generating high-fidelity, minute-long sequences - was accompanied by the explicit claim that scaling video generation is a promising path toward building "general purpose simulators of the physical world" 5960. The assertion rests on the premise that by denoising highly complex video patches in latent space, the model inherently learns the intuitive physics of 3D geometry, occlusion, and fluid dynamics as emergent properties required for accurate synthesis 5960.
This generative premise is heavily criticized by researchers advocating for predictive representations. Yann LeCun asserts that "modeling the world for action by generating pixels is as wasteful and doomed to failure as the largely-abandoned idea of 'analysis by synthesis'" 1415. The core critique is epistemic: the physical world contains immense, irreducible stochasticity (e.g., the exact trajectory of a falling leaf or the precise ripples in a pond) 15. A generative simulator like Sora is forced to hallucinate these unpredictable details, conflating the prediction of structural physical reality with the rendering of specific, arbitrary textures 1517. Consequently, generative models frequently exhibit egregious physical violations upon close inspection, failing to maintain object permanence or consistent thermodynamics 59.
Proponents of the JEPA architecture argue that a true world simulator optimized for intelligent action must abstract away irrelevant pixel-level details and predict entirely in a conceptual latent space 1417. By discarding unpredictable information, architectures like V-JEPA improve sample efficiency by factors of up to 6x and avoid the catastrophic uncertainty limits inherent to generative models 15. The field thus remains fractured between the generative approach - which leverages massive computational scale to brute-force a visual semblance of simulation - and the predictive approach, which mathematically isolates the causal backbone of the environment 151759.
Synthesis and Conclusion
The accumulation of empirical evidence across model-based reinforcement learning, spatiotemporal probing, and abstract representation frameworks confirms that advanced AI models do construct internal models of reality.
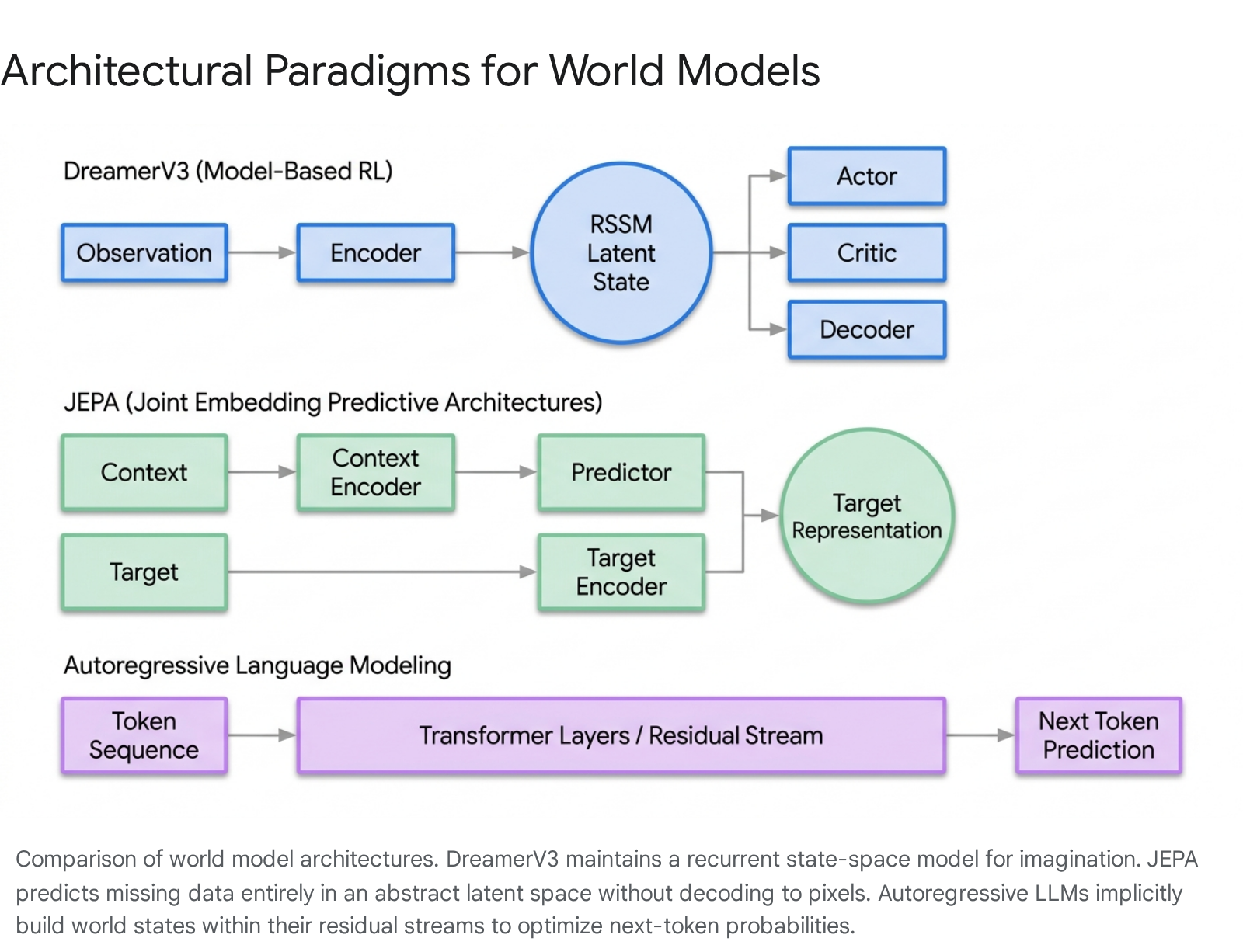
In explicitly structured systems like DreamerV3 and JEPA, this modeling is the mathematical objective: the models are architecturally forced to compress observations into latent states and forecast future dynamics 911.
More remarkably, autoregressive language models - despite being trained solely to optimize the superficial statistics of human text - incidentally induce highly structured, linear representations of space, time, syntax, and deterministic game logic 51623. These internal representations are not merely passive encodings but active, causally efficacious computational structures that strictly govern the model's outputs 16.
However, the field must navigate profound methodological hurdles to fully interpret these models. Interpretability techniques relying on counterfactual interventions are deeply vulnerable to the inherent redundancy and non-transitivity of neural architectures 33. Furthermore, the ambition to utilize generative diffusion models as robust physical simulators is bounded by the profound mathematical complexity of high-dimensional uncertainty 14. As diverse architectures converge - merging the logical abstraction of language models with the multimodal, real-time dynamics of audio and video - the realization of general-purpose, physically grounded world models hinges not on generating the world's surface appearance, but on reliably predicting its underlying causal structure.