Evolutionary computation for trading rule discovery
Introduction
The application of evolutionary computation and genetic algorithms to financial market forecasting represents a sustained, multi-decade effort to solve one of the most computationally complex problems in applied mathematics: extracting predictive signals from highly non-stationary, adversarially noisy time series data. Historically, the theoretical foundation of quantitative finance was dominated by the Efficient Market Hypothesis, a paradigm formalized by Eugene Fama in the 1960s and 1970s. This hypothesis posited that asset prices fully and instantaneously reflect all available information, rendering the systematic generation of risk-adjusted excess returns, or alpha, an impossibility 12. Under the strict interpretation of this framework, any appearance of predictive power is merely statistical noise or adequate compensation for assuming a higher degree of systemic risk.
However, the persistent observation of market anomalies, behavioral biases, and microstructural inefficiencies has catalyzed the development of alternative theoretical frameworks. The field of evolutionary finance reconceptualizes markets not as perfectly efficient mechanisms in static equilibrium, but as complex, adaptive ecologies populated by heterogeneous agents operating with bounded rationality 23. Within these digital ecologies, algorithmic trading systems are designed to detect and exploit temporary market disequilibria 15. Early quantitative research relied heavily on human intuition to manually formulate hypotheses, combine technical indicators, and backtest trading rules. While seminal studies in the early 1990s demonstrated that simple heuristics like moving averages and trading range breakouts could hold predictive power, the manual discovery process was inherently constrained by human cognitive limitations, slow iteration cycles, and an intense susceptibility to behavioral biases 567.
To transcend these limitations, researchers turned to evolutionary computation to automate the discovery of trading rules. Inspired by the principles of biological natural selection, evolutionary algorithms maintain a population of candidate quantitative strategies, evaluate their performance against historical market data via a defined fitness function, and apply operators such as crossover and mutation to iteratively produce superior generations of trading algorithms 589. While early genetic programming systems demonstrated the theoretical viability of evolving functional trading rules, they frequently failed in out-of-sample deployment due to massive overfitting, an inability to adapt to regime shifts, and a failure to account for market microstructure realities like transaction costs and survivorship bias 11011.
Recent advancements, particularly those emerging between 2024 and 2026, have fundamentally transformed the evolutionary computation landscape in finance. The integration of Large Language Models within multi-agent evolutionary frameworks has shifted the optimization paradigm from evolving simple mathematical trees to evolving comprehensive research trajectories, complex semantic hypotheses, and executable trading code 12132. Concurrently, the implementation of mathematically rigorous statistical validation techniques, such as Combinatorial Purged Cross-Validation and the Model Confidence Set, has provided robust quantitative defenses against the pervasive threat of backtest overfitting 1516. This report provides an exhaustive, critical analysis of the methodologies, multi-agent architectures, operational constraints, and validation frameworks that define the modern landscape of evolutionary trading rule discovery.
Foundational Genetic Programming Methodologies
The core architecture of early evolutionary trading rule discovery relies on standard Genetic Programming (GP). Unlike basic Genetic Algorithms that optimize a fixed-length string of parameters, Genetic Programming evolves the actual structure of computer programs or mathematical formulas. In the context of algorithmic trading, these programs are represented as syntax trees where the internal nodes consist of mathematical operators, trigonometric functions, or logical operators, and the leaf nodes represent scalar financial features such as closing prices, trading volume, or pre-calculated technical indicators 34.
The Limitations of Standard Genetic Programming
Early seminal applications of standard GP to financial markets attempted to evolve profitable technical trading rules for major indices like the Standard and Poor's composite stock index 1920. These early implementations demonstrated that GP could successfully identify historical periods of high returns and low volatility in-sample. However, a pervasive finding across the literature was that standard GP models consistently failed to outperform simple buy-and-hold benchmark strategies during out-of-sample testing periods once realistic transaction costs were applied 119.
The failure of standard GP in financial forecasting is largely attributable to its structural handling of data. Standard GP models process data strictly on a point-by-point basis, ingesting scalar values at specific timestamps 45. This architecture is inherently devoid of temporal awareness. To understand broader market trends or historical contexts, a standard GP model requires the manual engineering of lagged variables or explicit rolling-window features to be provided as distinct scalar inputs. This manual feature engineering reintroduces human bias and severely limits the algorithm's ability to discover novel, multi-scale temporal patterns. Consequently, modern comparative analyses consistently rank standard GP among the least effective evolutionary methods for robust financial forecasting 346.
Vectorial Genetic Programming Architectures
To resolve the limitations inherent in scalar processing, researchers developed Vectorial Genetic Programming (VGP). This advanced framework extends the traditional GP architecture by allowing the system to ingest, process, and manipulate entire vectors - specifically, arrays of time series data - as terminal symbols 5623.
The defining innovation of VGP is the introduction of specialized aggregation operators that can extract statistical features directly from data vectors over autonomously defined segments. Rather than relying on a human researcher to pre-calculate a fifty-day moving average, a VGP model can utilize parametric aggregate functions. These functions utilize internal parameters to define the specific lookback period and the window size, applying aggregation operations (such as calculating the mean, variance, or median) to that dynamically extracted segment of the vector 623. This capability grants the evolutionary agent significant temporal context, allowing it to evaluate historical price action and autonomously identify the most predictive lookback horizons for any given market regime 523.
The introduction of vectorial operators and dynamic windowing exponentially increases the dimensionality and complexity of the evolutionary search space 46. To navigate this vastly expanded landscape without succumbing to computational intractability or severe overfitting, the field has developed highly specialized variants of VGP:
Complex Vectorial Genetic Programming (CVGP): Financial time series frequently exhibit cyclical behaviors and wave-like oscillations that are difficult to model using standard real-number arithmetic. CVGP addresses this by evolving programs that operate entirely within the domain of complex numbers. The model accepts multi-dimensional vectors of complex numbers and utilizes a unique function set tailored for complex arithmetic. To translate the final complex output into an executable trading signal, the system evaluates the real part of the resulting complex number, applying threshold logic to execute long, short, or neutral positions 34. By operating in the complex plane, CVGP expands the mathematical expressiveness of the evolutionary agent, allowing it to capture subtle phase shifts in market momentum that traditional models overlook.
Strongly Typed Vectorial Genetic Programming (STVGP): While VGP and CVGP expand the search space, they also increase the probability of generating semantically meaningless or computationally invalid programs. STVGP mitigates this risk by imposing a rigorous, strongly typed framework upon the evolutionary process 5. In STVGP, every variable, vector, and operator is assigned a specific data type constraint. The evolutionary operators of crossover and mutation are algorithmically restricted from producing syntax trees where the output type of a child node does not exactly match the required input type of its parent node 35. By amalgamating the robust data constraints of Strongly Typed GP with the temporal processing power of VGP, the system effectively prunes vast swaths of invalid genetic material from the search space. Extensive empirical testing across various financial instruments and multi-year datasets demonstrates that the STVGP variant consistently ranks among the most effective evolutionary methodologies, exhibiting a superior capacity to navigate shifting market conditions, minimize downside risk, and prevent backtest overfitting 345.
| Evolutionary Framework | Data Input Architecture | Core Operator Capabilities | Search Space Characteristics | Empirical Out-of-Sample Performance |
|---|---|---|---|---|
| Standard GP | Scalar point-in-time values. | Basic arithmetic, trigonometric, and logical operators. | Moderate size; highly susceptible to converging on local optima. | Generally poor; frequently fails to outperform buy-and-hold baselines 319. |
| Vectorial GP (VGP) | Full time series vectors and arrays. | Vector arithmetic; autonomous windowed aggregations. | Exceptionally large; high risk of parameter bloat without regularization. | Moderate to high; capable of extracting robust temporal features 623. |
| Complex Vectorial GP | Multi-dimensional vectors of complex numbers. | Complex arithmetic; phase and amplitude manipulation. | Very large; high mathematical expressiveness. | High; effective at modeling cyclical and oscillatory market dynamics 34. |
| Strongly Typed Vectorial GP | Vectors governed by strict, hierarchical data-type constraints. | Type-constrained vectorial operators. | Large, but systematically pruned of semantically invalid combinations. | Consistently strong; demonstrates high resilience against overfitting across regimes 35. |
Neuroevolution and Dynamic Architecture Search
While Genetic Programming focuses on evolving programmatic rules and mathematical expressions, neuroevolution applies the principles of evolutionary computation to the optimization of Artificial Neural Networks (ANNs) deployed in financial forecasting. In traditional deep learning approaches applied to quantitative finance, human data scientists manually design the topology of the neural network - dictating the number of layers, the type of neurons, and the inter-layer connectivity - and then utilize gradient descent algorithms to optimize the internal weights 2425. Neuroevolution automates both processes simultaneously, operating under the premise that the optimal network architecture for predicting non-stationary financial markets is unlikely to match standard, off-the-shelf topologies.
Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, and Gated Recurrent Units (GRUs) are the dominant architectures utilized in this domain due to their capacity to maintain internal memory states and process sequential time series data 24252627. The Evolutionary eXploration of Augmenting Memory Models (EXAMM) algorithm represents a sophisticated application of Neural Architecture Search (NAS) specifically tailored for these recurrent structures 282930. EXAMM does not rely on pre-trained networks or fixed topologies; instead, it progressively evolves lightweight RNNs by continually augmenting memory models through specialized mutation and crossover operations 282930.
Empirical applications of the EXAMM framework have demonstrated significant predictive advantages. In studies applying EXAMM to the individual constituent stocks of the Dow Jones Industrial Average, the neuro-evolved RNNs were utilized to drive a simple daily long-short portfolio trading strategy 2728. The evolutionary algorithm autonomously generated bespoke recurrent architectures for each individual company. When evaluated out-of-sample, the portfolio guided by the evolved RNNs generated excess returns that outperformed both the Dow Jones Industrial Average and the broader S&P 500 Index across fundamentally opposed market regimes, including the pronounced bear market of 2022 and the subsequent bull market recovery of 2023 283031.
Furthermore, the deployment of online Neural Architecture Search introduces real-time evolutionary adaptation to algorithmic trading. Unlike offline neuroevolution which trains on historical batches, online NAS dynamically generates, evaluates, and modifies RNN topologies sequentially as live data streams into the system 29. This continuous evolution allows the neural architecture to rapidly restructure itself in response to sudden distributional shifts in the underlying market data, maintaining predictive accuracy even as the statistical properties of the financial instrument drift over time 2932. Empirical comparisons assert that neuro-evolved networks, particularly those leveraging advanced memory units, exhibit state-of-the-art predictive capabilities that rival highly complex, attention-based Transformer models in stock forecasting, while requiring significantly less computational overhead 2933.
Large Language Models and Multi-Agent Evolutionary Trajectories
The most profound paradigm shift in evolutionary quantitative finance between 2024 and 2026 has been the integration of Large Language Models (LLMs) into multi-agent evolutionary architectures. Historically, evolutionary computation in finance operated in a purely symbolic or parameter-based domain, lacking any inherent understanding of the underlying economic reality. The introduction of LLMs has shifted the optimization target from the evolution of disparate mathematical operators to the evolution of high-level financial hypotheses, sophisticated trading code, and full-scale research trajectories 713234.
In these advanced frameworks, LLMs are not utilized merely as static code generation tools. Instead, they act as the cognitive engines of autonomous agents operating within a continuous evolutionary loop 3478.
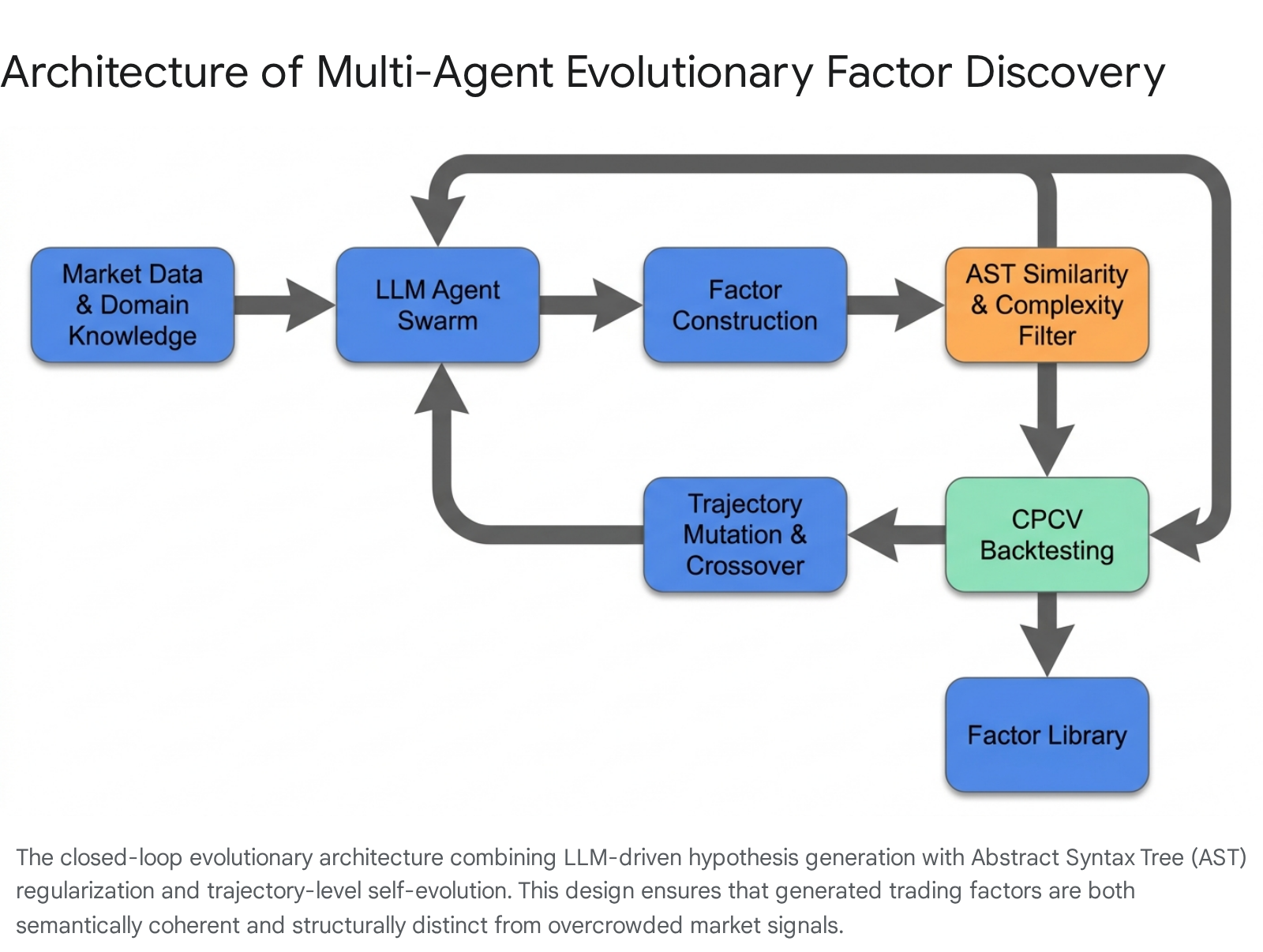
This transition addresses a fundamental bottleneck in traditional quantitative research: the human researcher's bounded attention and susceptibility to cognitive fatigue when exploring vast combinatorial hypothesis spaces 79.
Trajectory-Level Self-Evolution
A critical vulnerability of early LLM-assisted factor discovery was its reliance on static, one-shot prompt iterations that failed to retain institutional memory or adapt to changing market conditions 38. To overcome this, advanced architectures such as the QuantaAlpha framework reconceptualized the fundamental unit of evolutionary selection. Rather than mutating individual lines of code or discrete parameters, QuantaAlpha treats the entire end-to-end alpha mining run as an evolvable "trajectory" 12132.
A trajectory in this context is defined as the complete, ordered sequence of decisions spanning from the initial formulation of an economic hypothesis, through the programmatic construction of the factor, down to the final backtested execution code 1239. The evolutionary process operates directly upon these trajectories to drive continuous self-improvement: 1. Trajectory Mutation: When a candidate trading strategy demonstrates suboptimal performance during evaluation, the LLM agent utilizes self-reflection to localize the specific logical or programmatic fault within the trajectory. The mutation operator then rewrites only that specific localized action - perhaps altering the time scale of an indicator or introducing a new regime-filtering condition - while strictly preserving the successful prefix of the trajectory 12240. This ensures that the agent does not suffer from catastrophic forgetting and maintains coherence across generations. 2. Trajectory Crossover: To accelerate the discovery process, the crossover operator synthesizes new child trajectories by recombining complementary, high-reward segments from multiple successful parent trajectories. This allows the system to autonomously merge a highly effective economic hypothesis generated by one agent with a superior risk-management programmatic implementation developed by another 24041.
The empirical results of trajectory-level self-evolution are substantial. Backtesting the QuantaAlpha framework on the China Securities Index 300 (CSI 300) yielded an Information Coefficient (IC) of 0.1501, generating an Annualized Rate of Return of 27.75% while maintaining a highly constrained Maximum Drawdown of 7.98% 12240. Crucially, the factors discovered through this evolutionary process demonstrated remarkable cross-sectional robustness; factors evolved exclusively on the CSI 300 transferred effectively to the China Securities Index 500 and the US Standard & Poor's 500 Index, delivering cumulative excess returns of 160% and 137% respectively over a four-year out-of-sample period, indicating that the evolutionary process was capturing fundamental market mechanics rather than merely memorizing local index noise 12240.
Stigmergic Coordination and Quality-Diversity Optimization
Beyond trajectory evolution, the organizational structure of the agent swarms has evolved to mimic biological complex systems. Frameworks such as "The Hive" utilize principles of stigmergy - a mechanism of indirect coordination where individual agents modify a shared environment, and those modifications guide the future actions of the swarm, similar to the pheromone trails utilized by ant colonies 942. In a quantitative trading context, the "pheromone field" is represented by shared memory structures that dynamically map the topography of the market state and the historical success rates of various factor formulations 943.
A defining feature of these advanced multi-agent systems is the utilization of Quality-Diversity (QD) optimization algorithms, prominently the MAP-Elites framework 944. Traditional evolutionary algorithms attempt to converge the entire population toward a single, global optimal solution. In non-stationary financial markets, converging on a single strategy is highly fragile; if the market regime shifts, the entire system fails. Quality-Diversity optimization abandons this singular focus. Instead, it seeks to discover and maintain a massive, highly diverse archive of elite strategies that cover a wide spectrum of behavioral descriptors, such as holding period duration, directional bias (long vs. short), asset class focus, and volatility preference 7944.
By continuously populating a feature map aligned with these diverse trading styles, the orchestrator agent can dynamically allocate capital across a vast, evolved strategy portfolio, seamlessly rotating out of trend-following strategies and into mean-reversion strategies as the stigmergic indicators signal a shift in the macroeconomic regime 94244. Crucially, architectures like The Hive structurally eliminate lookahead bias by strictly separating the LLM's role in hypothesis generation from the compiled, deterministic subsystems that execute the trades on real-time data streams, ensuring that the theoretical models are practically deployable without data contamination 9.
Regularized Exploration and the Mechanics of Alpha Decay
A consistent reality documented in quantitative research is that discovering a profitable trading signal in-sample is vastly easier than maintaining its profitability in live execution. This phenomenon is known as alpha decay - the rapid deterioration in the predictive power and risk-adjusted return of a trading rule following its discovery 124546. Research investigating the post-publication performance of documented stock anomalies reveals that Sharpe ratios decay by an average of five percentage points annually immediately following their publication in academic or financial journals 47.
This decay is driven by two primary forces: market non-stationarity and alpha crowding. Non-stationarity dictates that the fundamental statistical distributions of asset returns are constantly shifting due to macroeconomic events, regulatory changes, and evolving market microstructures 1213. A trading rule heavily optimized for the low-volatility, large-cap momentum regime of 2019 will invariably fail during the high-volatility, thematic rotation regime of 2023 1213. Alpha crowding occurs when multiple quantitative funds and researchers discover highly similar predictive factors. As institutional arbitrage capital flows into these identical signals, the competitive buying and selling pressure rapidly erodes the underlying market inefficiency, driving the excess return to zero 121347.
LLM-Driven Regularization Mechanisms
While unconstrained LLM-driven evolutionary frameworks are exceptional at generating code, they are highly susceptible to alpha crowding. Because LLMs are trained on massive corpuses of public historical data, their unguided evolutionary output naturally converges on well-known, heavily published, and massively overcrowded trading strategies that suffer from immediate alpha decay 134849.
To counteract this, state-of-the-art frameworks like AlphaAgent implement strict "regularized exploration." This involves embedding rigid constraints directly into the evolutionary loop to force the system to search for novel, unexploited inefficiencies rather than memorizing historical consensus 485010. This regularization operates through three primary mechanisms:
- Originality Enforcement via AST Similarity: To prevent the generation of overcrowded signals, the system parses all newly evolved trading rules into Abstract Syntax Trees (ASTs). It then calculates the mathematical and structural similarity between the new candidate AST and a vast library of known, public baseline factors (such as the widely used Alpha101 dataset). Any candidate factor that is structurally identical or highly isomorphic to an existing known factor is heavily penalized or discarded, forcing the evolutionary search into novel regions of the solution space 484910.
- Semantic Consistency and Hypothesis Alignment: The framework mandates that the generated mathematical code must logically align with the underlying economic hypothesis it was designed to test. The LLM acts as an independent evaluator, scoring the semantic consistency between the stated market intuition (e.g., "high overnight volume relative to historical averages indicates informed institutional accumulation") and the actual mathematical operators utilized in the generated Python code. Factors that fail this alignment check are eliminated, ensuring the algorithm does not rely on spurious, unexplainable correlations 484910.
- Complexity Control: Evolutionary algorithms naturally tend toward "parameter bloat," creating massive, over-engineered syntax trees that perfectly memorize the training data but fail catastrophically out-of-sample. Regularized exploration applies strict AST-based structural constraints and parameter counting to heavily penalize unnecessary complexity, favoring parsimonious models that capture genuine signal rather than fitting to noise 47484910.
Empirical evaluations across the CSI 500 and S&P 500 markets demonstrate that these regularization mechanisms significantly improve resistance to alpha decay, allowing the evolutionary framework to maintain stable predictive effectiveness and high Information Coefficients across both bull and bear market cycles long after traditional factors have eroded 484952.
Operational Market Constraints: Transaction Costs and Survivorship Bias
The transition from theoretical backtesting to live algorithmic execution exposes evolutionary models to the friction of real-world market mechanics. A trading rule that appears highly fit in simulation will rapidly collapse if the evolutionary fitness function fails to explicitly model implicit market costs and data integrity biases 115354.
Transaction Costs and Market Impact Modeling
In high-frequency and quantitative trading, transaction costs act as a persistent, compounding drag on strategy performance. These expenses are broadly categorized into explicit costs, such as broker commissions, exchange fees, and regulatory taxes, and implicit costs, which include bid-ask spreads, execution latency, and market impact 535455. Market impact, commonly referred to as slippage, occurs when the execution of a large order directly alters the supply and demand dynamics of the order book, resulting in the asset being bought at a higher price or sold at a lower price than intended at the moment the trading signal was generated 105354.
The methodology used to model these costs within the evolutionary fitness function fundamentally alters the types of strategies the algorithm will produce. If a Genetic Algorithm is evaluated using a zero-cost or overly simplified flat-cost model (where the cost of a trade is assumed to be identical regardless of its size or market liquidity), the algorithm will inevitably evolve toward hyper-active, high-turnover strategies 1055. These strategies appear incredibly profitable in simulation by exploiting microscopic price discrepancies thousands of times a day, but they are entirely illusory; in live markets, the compounding transaction fees and latency slippage immediately turn the simulated profits into severe losses 53545511.
To develop robust models, modern evolutionary backtesting frameworks optimize for the "implementable efficient frontier" - evaluating candidate strategies strictly on their performance net of dynamic, realistic transaction costs 12. It is widely accepted in quantitative modeling that actual transaction costs are not flat, but rather follow a quadratic function relative to the size of the trade 10. By incorporating Transaction-Cost-Aware (TCA) factors into the fitness evaluation, the algorithm is heavily penalized for excessive turnover. Studies indicate that optimizing evolutionary models with TCA factors can increase the net maximum squared Sharpe ratios of the final deployable portfolio by up to a factor of 2.5 compared to cost-agnostic optimization 11.
Survivorship Bias in Universe Selection
A more insidious threat to evolutionary trading rule discovery is survivorship bias - a fundamental flaw in dataset construction where the algorithm is trained and evaluated only on financial instruments that have survived to the present day, while entirely ignoring the historical data of companies that went bankrupt, merged, or were delisted 115860.
If a researcher defines their testing universe based on the current constituents of the S&P 500 and runs an evolutionary algorithm over the past twenty years of data, they are essentially providing the algorithm with a universe of guaranteed historical winners 11. Under these conditions, the evolutionary search process will inevitably "discover" rules that are highly correlated with the specific characteristics of these surviving entities, creating a massive upward bias in the backtest results 115860. Furthermore, because the bankrupt companies have been retroactively erased from the dataset, the algorithm is never exposed to catastrophic failure events, resulting in an unrealistic assessment of downside risk and maximum drawdown 5860.
To mitigate survivorship bias, evolutionary frameworks must be trained exclusively on point-in-time datasets 58. These databases meticulously reconstruct the exact composition of market indices for every single historical trading day, ensuring that the algorithm is exposed to the price action of delisted and failed companies exactly as they existed before their collapse 5860. This ensures the evolutionary process learns genuine predictive signals rather than merely identifying retroactive survival traits.
Rigorous Statistical Validation Methodologies
Given that multi-agent systems and genetic algorithms evaluate millions of potential trading rules across multiple generations, they represent massive multiple hypothesis testing environments. If traditional statistical validation techniques are used, the probability of backtest overfitting approaches absolute certainty; the algorithm will inevitably discover a rule that perfectly memorizes the noise of the historical dataset by pure random chance 151647.
Standard machine learning validation techniques, such as basic k-fold cross-validation, are fundamentally invalid when applied to finance. Standard cross-validation randomly partitions data into training and testing sets under the assumption that the data points are independent and identically distributed (IID). Financial time series are highly serially correlated and decidedly non-IID. Randomly selecting data points for training and testing destroys the chronological sequence of the market and introduces massive lookahead bias, as the algorithm is essentially trained on future data to predict the past 2661.
Combinatorial Purged Cross-Validation (CPCV)
To resolve the catastrophic data leakage associated with standard cross-validation while maximizing the utility of limited historical data, the quantitative finance discipline has adopted Combinatorial Purged Cross-Validation (CPCV), a methodology specifically designed to combat backtest overfitting in non-stationary time series 15266263.
CPCV operates by partitioning the historical dataset into $N$ chronologically sequential blocks. It then generates all possible combinatorial groupings of these blocks to form multiple distinct training and testing sets 62. To strictly prevent the leakage of information between the training and testing phases, CPCV enforces two critical mechanisms: 1. Purging: Any observation in the training set whose evaluation horizon overlaps in time with an observation in the testing set is explicitly purged (deleted) from the training data 6263. This ensures that the algorithm cannot peek at the outcome of a trade before making a prediction. 2. Embargoing: Because financial markets exhibit strong serial correlation - where a major macroeconomic shock on Tuesday continues to dictate price action on Wednesday - purging alone is insufficient. CPCV introduces an embargo period, which creates a chronological dead zone immediately following the test set 63. This prevents the training set from absorbing the immediate, highly correlated aftermath of events that occurred within the test set.
By forcing the evolutionary algorithm to optimize its trading rules across multiple combinatorial paths that have been strictly purged and embargoed, CPCV provides a far more rigorous assessment of out-of-sample robustness compared to traditional walk-forward analysis, significantly increasing the resulting deflated Sharpe ratios and ensuring that the evolved strategies have not simply memorized a single historical trajectory 15964.
The Model Confidence Set (MCS)
While CPCV ensures the integrity of the data splits, researchers must still determine which of the thousands of evolved trading rules should actually be deployed. Relying solely on the single model with the highest backtest return is statistically hazardous due to the inherently low signal-to-noise ratio in finance; the top-ranked model may simply be the luckiest variant rather than the most predictive 163313.
The Model Confidence Set (MCS) methodology addresses this selection uncertainty. Rather than attempting to isolate a single "best" model, the MCS procedure applies a sequence of rigorous equivalence tests (such as the Equal Predictive Ability statistic) to iteratively eliminate statistically inferior models based on a defined loss function - such as forecasting error, Expected Shortfall, or Value-at-Risk 16331314. The result is the Set of Superior Models (SSM): a refined group of trading rules that are statistically indistinguishable from the true optimal model at a specified confidence level 1614.
The MCS framework is particularly powerful when integrated with evolutionary multi-agent systems. Instead of selecting one fragile strategy, the outputs of the Set of Superior Models can be aggregated using dynamic model averaging or ensemble weighting schemes to create highly robust composite predictors that smoothly transition across shifting market regimes 16256768.
| Validation Methodology | Core Statistical Mechanism | Financial Applicability | Key Vulnerabilities |
|---|---|---|---|
| Walk-Forward Analysis | Uses a rolling window of historical training data followed immediately by a subsequent out-of-sample testing period. | Moderate (preserves strict chronological sequence). | Inefficient use of data; evaluates the model on only one historical path, increasing susceptibility to regime-specific overfitting 6970. |
| Standard k-Fold Cross Validation | Randomly partitions the dataset into k subsets, training on $k-1$ sets and validating on the remaining set. | Poor (fundamentally violates the non-IID nature of financial time series). | Introduces catastrophic data leakage and lookahead bias; entirely invalidates backtest integrity 2661. |
| Combinatorial Purged Cross-Validation (CPCV) | Generates combinatorial data splits while actively purging overlapping observations and embargoing post-test data to prevent serial correlation leakage. | Excellent (specifically engineered to handle the complexities of financial time series). | Highly computationally intensive; difficult to implement correctly within continuous evolutionary loops 156263. |
| Model Confidence Set (MCS) | Iteratively conducts equivalence tests to eliminate inferior models based on a specific loss function, identifying a statistically robust group of top performers. | Excellent (accounts for market noise and provides a foundation for ensemble model construction). | Does not generate new validation data paths; highly dependent on the initial quality and diversity of the candidate models generated 161314. |
Comparative Efficacy Across Diverse Asset Classes
The predictive power and stability of evolutionary trading algorithms are not universal; performance is heavily dictated by the specific market microstructure, regulatory environment, and relative efficiency of the underlying asset class. Algorithms that thrive in highly volatile, retail-driven environments frequently fail to generate alpha in mature, institutionally dominated markets.
Developed Versus Emerging Equity Markets
Extensive empirical studies spanning decades of market data reveal a stark dichotomy in the efficacy of technical trading rules across different global equity markets 671. In developed financial markets - such as the United States (S&P 500), the United Kingdom (FTSE 100), and Germany - the markets are characterized by immense liquidity, advanced institutional infrastructure, and the massive presence of high-frequency algorithmic arbitrageurs. Consequently, these markets exhibit a high degree of efficiency. In such environments, simple evolutionary trading rules and traditional technical heuristics consistently fail to generate statistically significant outperformance against simple buy-and-hold benchmarks once realistic transaction costs are applied 1671. To extract alpha in developed markets, quantitative researchers must deploy highly complex models - such as LLM-guided trajectory evolution, deep reinforcement learning, or advanced neuroevolution - capable of identifying deeply obscured, non-linear cross-sectional dependencies that evade standard linear arbitrage 61272.
Conversely, emerging financial markets - such as those in Taiwan, Thailand, Mexico, and the broader BRICS nations - operate under significantly different microstructural conditions. These markets often suffer from lower overall liquidity, higher degrees of informational asymmetry, less stringent regulatory reporting requirements, and a higher proportion of retail investors prone to behavioral biases and herding effects 1673. This combination results in more pronounced fractal market behaviors and prolonged trends 1. Under these conditions, the simplest forms of technical trading rules and basic evolutionary algorithms frequently demonstrate the capacity to accurately predict future stock values and generate substantial excess profits 671. However, long-term studies indicate that this predictability is rarely persistent; as emerging markets mature, adopt stronger regulatory frameworks, and attract global institutional capital, the efficacy of simple evolutionary rules diminishes drastically, forcing a transition toward more sophisticated modeling techniques 67173.
The Unique Optimization Landscape of Cryptocurrencies
The cryptocurrency market represents a fundamentally distinct operational environment for evolutionary computation. Characterized by continuous 24/7 trading, the absence of traditional market-close phenomena, heavy dominance by retail sentiment, and extreme asymmetric volatility that routinely runs three to four times higher than major equity indices, crypto assets pose severe challenges for standard optimization algorithms 727475. Algorithms deployed in this space must be capable of rapidly adapting to violent, sudden regime shifts rather than merely forecasting stable, continuous price trends 72.
Systematic factorial experiments comparing various hyperparameter optimization frameworks across major cryptocurrency pairs (such as BTC/USDT, ETH/USDT, and SOL/USDT) highlight the distinct behavior of evolutionary models in high-volatility environments 74. While Bayesian optimization methods (such as the Tree-Structured Parzen Estimator) generally show high sample efficiency, evolutionary approaches like Differential Evolution (DE) exhibit extreme strategy-specific compatibility. For instance, DE has proven remarkably effective when applied to trend-following strategies across crypto assets, demonstrating consistent competitiveness and an ability to navigate vastly different parameter space topologies 74. However, the same evolutionary optimizer frequently suffers complete testing failures when applied to mean-reversion strategies within the crypto domain, as the highly non-stationary nature of crypto drawdowns causes the algorithm to severely overfit to localized noise 6974.
To manage this extreme volatility and mitigate the impact of sudden downside shocks, advanced algorithmic frameworks targeting digital assets increasingly abandon pure technical approaches in favor of hybrid architectures. These systems integrate genetic algorithms with sophisticated statistical risk models - such as Exponential Generalized Autoregressive Conditional Heteroscedasticity (EGARCH) filters - or quantum neural network structures, allowing the evolutionary agent to dynamically adjust its trading behavior in response to surging market variance, thereby protecting capital during catastrophic market corrections 1516.
Conclusion
The intersection of evolutionary computation and quantitative finance has progressed profoundly from the naive, in-sample optimization of basic technical indicators. Modern trading rule discovery is no longer defined by simple parameter tuning, but represents a sophisticated synthesis of multiple artificial intelligence sub-disciplines. The integration of Large Language Models has allowed evolutionary processes to escape the rigid confines of mathematical syntax trees, enabling the autonomous generation, critique, and refinement of semantically coherent financial hypotheses and full-scale research trajectories.
However, the defining characteristic of successful contemporary quantitative systems is not merely their generative capacity, but their rigorous defensive engineering. Acknowledging that financial time series are defined by adversarial non-stationarity and exceptionally low signal-to-noise ratios, cutting-edge evolutionary frameworks mandate strict regularization. Mechanisms such as AST-based structural constraints actively suppress the generation of overcrowded factors, directly combatting the inevitability of alpha decay. Furthermore, the application of mathematically robust validation paradigms - specifically Combinatorial Purged Cross-Validation and the Model Confidence Set - ensures that evolved algorithms are evaluated against un-leaked, chronologically sound historical paths rather than single, overfitted scenarios. Ultimately, the ability of evolutionary algorithms to transition from simulated success to persistent, live-market profitability relies entirely on their structural alignment with market realities: accounting for dynamic transaction costs, correcting for survivorship bias, and acknowledging the continuous, combative evolution of the broader financial ecology.