Systematic Findings in Large Language Model Prompt Engineering
Foundational Mechanisms of Prompt Processing
The practice of prompt engineering has transitioned from an intuitive exercise based on heuristic experimentation to a systematic discipline grounded in computational linguistics and machine learning. In the early stages of large language model (LLM) deployment, practitioners relied on anecdotal strategies and unverified phrasing to elicit desired outputs. However, as the underlying architecture of these models - specifically the transformer mechanism and its attention networks - has been subjected to rigorous empirical analysis, a formal science of prompting has emerged. This scientific approach examines how natural language inputs and inference parameters manipulate the probability distributions of token generation. Current research isolates specific variables that govern model behavior, ranging from hyperparameter configurations to the structural topology of the reasoning requested in the prompt. By evaluating how models respond to specific syntactical structures, contextual positioning, and algorithmic constraints, researchers have quantified the efficacy of different prompting methodologies.
Zero-Shot and Few-Shot In-Context Learning
A primary axis of prompt engineering relies on the concept of In-Context Learning (ICL), which capitalizes on the pre-trained weights of the model without requiring parameter updates. The most fundamental application is zero-shot prompting, wherein the model is given a task instruction with no prior examples and must rely entirely on its pre-training data to infer the correct response format and semantic boundaries 12. Empirical studies indicate that zero-shot prompting is highly efficient and effective for straightforward classification, translation, and summarization tasks 13.
However, zero-shot performance degrades significantly when tasks require domain-specific formatting, structured extraction, or nuanced interpretation 1. In these scenarios, few-shot prompting demonstrates marked superiority. By providing a small number of input-output examples (typically two to five) directly within the prompt context, practitioners create a localized learning environment 24. This approach guides the model's pattern-matching capabilities, significantly improving the consistency and structural reliability of the output 123.
Despite its advantages in formatting, few-shot prompting is not universally optimal. For complex logical reasoning or mathematics, providing complete examples can inadvertently constrain the model. Research indicates that models forced to follow a highly specific few-shot logic path may copy flawed steps or struggle to generalize to slightly different problem structures, whereas zero-shot chain-of-thought instructions allow the model more flexibility to generate an organic, accurate logical path based on its pre-trained reasoning capabilities 4.
| Prompting Methodology | Data Requirements | Primary Application Domain | Limitations |
|---|---|---|---|
| Zero-Shot | Task instruction only; no examples 12. | General categorization, rapid prototyping, sentiment analysis 13. | Inconsistent output formatting; poor adaptation to specialized domain nuances 1. |
| One-Shot | Instruction plus one explicit example 3. | Ambiguity reduction for simple structured extraction 3. | Insufficient for teaching complex, multi-step logical variations 3. |
| Few-Shot | Instruction plus 2 to 5 carefully curated examples 2. | Consistent structured data extraction, domain-specific labeling 14. | Increased token overhead; potential to inadvertently constrain reasoning pathways 24. |
Hyperparameter Modulation and Token Sampling
While the semantic content of a prompt is the primary driver of model output, the algorithmic parameters that govern token sampling at inference time exert a profound, independent influence on the generated response. Language models generate text by producing probability distributions over a vast vocabulary 5. The prompt engineer must manipulate these distributions through inference hyperparameters, most notably temperature, Top-k, and Top-p (nucleus sampling).
Temperature acts as a scalar applied to the raw logits (unnormalized predictions) prior to the softmax function, reshaping the entire probability curve. A temperature of 1.0 represents the default probability distribution. Mathematical models of inference show that as temperature approaches 0.0, the model becomes increasingly deterministic, overwhelmingly selecting the token with the highest predicted probability 56. Conversely, higher temperatures (e.g., 0.7 to 1.0) flatten the distribution, reducing the confidence gap between the most likely token and lower-probability alternatives, thereby giving the latter a greater chance of selection 78. It is noted in computational research that a temperature of exactly 0.0 does not guarantee absolute determinism across all hardware implementations due to minute floating-point arithmetic variations in parallel processing, though it serves as a functional proxy for determinism 57.
Despite a pervasive assumption in the practitioner community that higher temperatures universally enhance "creativity" and improve solution-space search, empirical studies challenge this narrative for structured tasks. A large-scale reproducibility study examining the impact of temperature across nine LLMs and 1,000 problem-solving tasks found that variations in temperature between 0.0 and 1.0 did not have a statistically significant impact on accuracy for logical and mathematical benchmarks 9. The correct answer accuracy remained remarkably stable across this spectrum, although text variability predictably increased as temperature rose 9. Consequently, researchers recommend setting the sampling temperature to 0.0 for problem-solving, analytical, and factual tasks. This setting maximizes reproducibility, minimizes the generation of unnecessary output tokens, and constrains the potential for hallucination without degrading the model's inherent reasoning capacity 69.
Nucleus sampling, or Top-p, operates via a different mathematical mechanism. Rather than reshaping the entire probability curve, Top-p dynamically truncates the distribution 5. The algorithm first sorts the available tokens by probability in descending order, calculates the cumulative sum, and eliminates all tokens beyond the specified probability threshold (e.g., 0.90) 578. Top-k filtering is often applied prior to Top-p, imposing a hard numerical limit on the total number of candidate tokens considered, regardless of their cumulative probability 6. This dynamic truncation allows the model to consider a wide array of tokens when its confidence is dispersed among many plausible options, while strictly limiting choices when a few tokens dominate the probability mass 5. Simultaneous manipulation of both temperature and Top-p is generally discouraged in empirical studies, as their interacting effects on the underlying distribution can yield unpredictable token selection behavior 58.
Positional Bias in Context Windows
A critical finding in the science of prompt engineering is the discovery of severe positional biases within large context windows. LLMs exhibit phenomena analogous to human psychological primacy and recency effects, meaning they disproportionately weight information located at the beginning and end of a prompt while neglecting information situated in the middle 1011. As context windows have scaled to accommodate hundreds of thousands of tokens, managing this architectural limitation has become central to effective prompt design.
The U-Shaped Attention Phenomenon
Empirical research on long-context utilization reveals a pervasive "lost in the middle" phenomenon 1112. When researchers varied the placement of a target document containing the answer to a specific query within a large context window, retrieval accuracy plotted a distinct U-shaped curve 1314. Models performed at their peak when the relevant data appeared at the extreme beginning or extreme end of the prompt context, with a dramatic degradation in accuracy when the data was embedded in the center 1113.
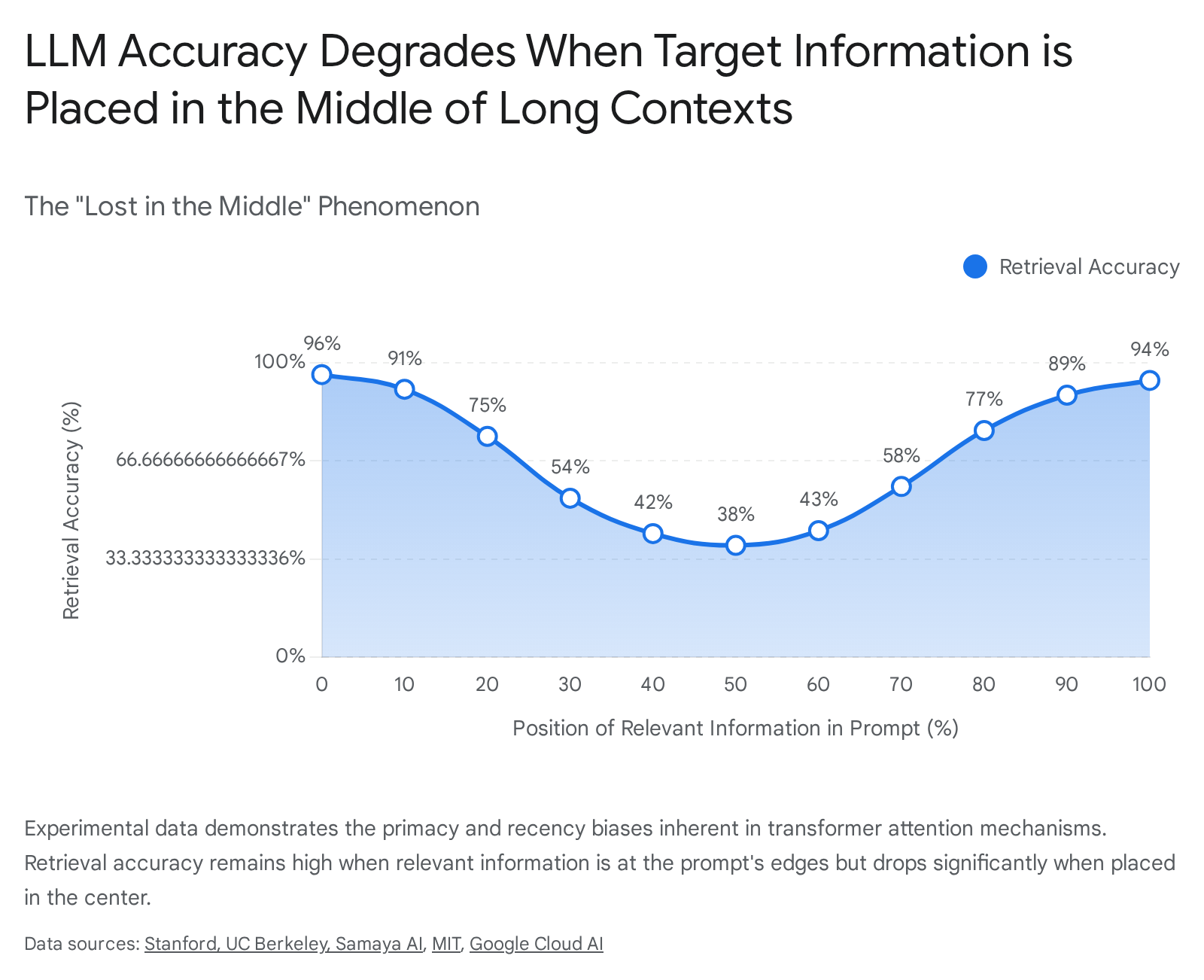
This bias is not a superficial artifact but is rooted deeply in the underlying transformer architecture. Micro-level analyses of attention weights indicate that causal masking inherently biases attention toward earlier positions in deeper network layers 1012. The causal mask forces the model to attend primarily to the preceding context; as the context grows, earlier tokens establish stronger attention connections, creating an "overcontextualization" of the prompt's head 1013. Furthermore, research demonstrates that position embeddings and specific dimensions in the hidden state carry information about absolute position, acting as systemic drivers of this attention bias 12. Consequently, even when information in the middle of a prompt is semantically highly relevant, the model's attention mechanism assigns it lower weight, leading to instances where the model confidently hallucinates an answer by blending less relevant information from the edges of the context window 1114.
Mitigation Strategies for Positional Bias
To engineer around this architectural limitation, researchers propose both prompt-level behavioral interventions and model-level architectural adjustments. On the prompt-engineering side, practitioners are advised to exploit primacy and recency biases directly. In tasks involving multiple-choice questions or long document retrieval - such as Retrieval-Augmented Generation (RAG) systems - ordering choices by semantic similarity or placing the highest-confidence retrieved documents strictly at the start and end of the prompt significantly improves accuracy 1011. For example, a ranking array of five documents should be organized such that the highest relevance documents sit at indices 1 and 5, while the lowest relevance document occupies index 3 11.
Furthermore, explicit instructions regarding safety, tone, or primary constraints must be placed at the very end of the prompt. Because of the recency effect, terminal placement ensures these instructions are processed last and weighted heavily during subsequent generation 10. Explicit metacognitive instructions, such as directly commanding the model to "carefully consider all of the provided documents, especially documents that appear in the middle," have also been shown to measurably, though not entirely, reduce the severity of the bias 11. At the architectural level, emerging research suggests mitigating position bias by calibrating positional attention bias via scaling specific hidden state dimensions, disentangling semantic relevance from absolute position encodings 1214.
Structural Modifiers and Contextual Cues
The early literature on prompt engineering often emphasized the use of specific, human-like phrasing to improve model performance. Practitioners frequently shared phrases purported to unlock advanced reasoning capabilities. Subsequent empirical research has rigorously scrutinized these phenomena, revealing that while contextual cues do impact output probability, they rarely function as universal mechanisms across different models and tasks.
The Fallacy of Universal Heuristics
The popular prompt engineering heuristic directing the model to "Take a deep breath and work on this problem step-by-step" is frequently cited as a universal performance booster. However, academic analysis reveals this specific phrase was discovered through an automated prompt optimization routine explicitly tailored for Google's PaLM 2 model evaluating the GSM8K (grade-school math) dataset 15. When this phrase was applied in that exact environment, accuracy increased to 80.2%, compared to 71.8% for the standard "Let's think step by step" prompt 15.
The scientific consensus challenges the generalization of such findings. Subsequent rigorous testing of various prompt components - including role assignments, deep-breath modifiers, and step-by-step instructions - across multiple open-weight LLMs found no universally optimal phrase. A comprehensive evaluation by VMware researchers tested 60 combinations of prompt components on the GSM8K benchmark across three different models. The results showed that combinations improving performance on one architecture often degraded performance on another. The researchers concluded that there is "no trend" in heuristic prompt modifiers, and generalized advice promoting specific phrasing is largely based on anecdotal evidence rather than robust, cross-model empirical truth 15. This indicates that models are highly sensitive to phrasing based on the idiosyncratic distributions of their specific pre-training data, warning practitioners against anthropomorphizing these systems by assuming they respond universally to human encouragement 15.
Emotional Framing and Politeness Vulnerabilities
Studies on the "EmotionPrompt" technique - appending high-stakes or emotional phrases like "This is very important to my career" - initially reported massive relative accuracy gains, sometimes exceeding 100% on specific open benchmarks 16. The mechanism driving these improvements is not empathy. Emotional stakes serve as powerful context cues because LLMs are trained on vast corpora of human text where urgent or high-stakes language correlates with rigorous, step-by-step reasoning (e.g., standardized exams, emergency protocols, critical memos) 16. The model's token prediction shifts to match the statistical profile of that serious tone.
However, the efficacy of emotional framing is heavily contested in more recent literature. Extensive peer-reviewed evaluations across diverse benchmark domains (including mathematical reasoning and reading comprehension) found that emotional tone is a weak, highly input-dependent signal 17. Across multiple models and tasks, static emotional prefixes produced only marginal changes in accuracy, acting more as a mild perturbation than a reliable general-purpose intervention 17. Conversely, other studies note that prompts framed with specific affective states, such as joy and apathy, yield consistently higher accuracy on the SuperGLUE benchmark compared to those framed with fear or anger 14.
The social framing of a prompt also dictates the likelihood of a model overriding its internal safety constraints. Research demonstrates that introducing polite language to adversarial prompt requests yields significantly higher success rates when asking LLMs to generate disinformation 15. In tests across multiple OpenAI models, polite adversarial prompting achieved up to a 100% success rate for disinformation generation on GPT-4, whereas impolite or demanding prompting drastically decreased the rate of non-compliant behavior 15. This vulnerability underscores the complex interplay between pre-trained social compliance mechanisms and safety tuning.
Evolution of Reasoning Topologies
The most substantial gains in LLM reasoning capabilities have emerged not from word-choice manipulation, but from structural transformations of the prompt, directing the model to generate intermediate computational steps before arriving at a final answer. This field of study classifies these structures into "reasoning topologies," which conceptualize the reasoning process as spatial and operational patterns extending the model's effective working memory 2016.
From Linear Chains to Graph Structures
The baseline approach to prompting is standard Input-Output (IO) prompting. In this topology, the LLM provides a final reply immediately upon receiving the user's initial prompt, mapping a single input node directly to a single output node without intermediate states. While sufficient for simple categorization, IO prompting fails reliably on complex mathematical or logical tasks 120. To address this, prompt engineering has evolved through a series of increasingly complex structural paradigms.
Chain-of-Thought (CoT): CoT prompting forces the model to generate a linear sequence of intermediate reasoning steps. By generating these steps explicitly (often initiated by the zero-shot phrase "Let's think step by step"), the model utilizes the expanding context window as a form of working memory, bringing relevant facts into its immediate attention span before making a final conclusion 172324. While CoT provides significant improvements in arithmetic and commonsense reasoning, its linear topology creates a distinct vulnerability: if the model makes a probabilistic error early in the chain, it possesses no structural mechanism to backtrack, and the error propagates irrevocably to the final answer 1725. A related offshoot, Program of Thoughts (PoT), seeks to mitigate calculation errors within linear chains by forcing the LLM to generate executable Python code for mathematical steps, disentangling linguistic reasoning from pure computation 1726.
Tree of Thoughts (ToT): To overcome the limitations of linear reasoning, ToT frames problem-solving as an active tree search. The prompt structure instructs the model to generate multiple diverse "thoughts" (partial solutions) at each step. An internal evaluator - often the LLM itself prompted to score the viability of each thought - determines the heuristic value of the branches. The system then utilizes search algorithms like breadth-first or depth-first search to decide which branches to pursue or abandon 172318. This topology supports backtracking and parallel exploration. In highly complex planning tasks like the "Game of 24," empirical studies demonstrate that ToT increased the success rate of GPT-4 from a mere 4% under standard CoT to 74% 18.
Graph of Thoughts (GoT): GoT advances this paradigm by modeling LLM reasoning as an arbitrary, interconnected graph. In GoT, thoughts act as vertices, and their logical dependencies represent edges. This non-linear structure permits the model to combine independent lines of reasoning into synergistic outcomes, distill the essence of entire networks of thoughts, and create cyclical feedback loops to refine ideas iteratively 172829. Empirical results demonstrate that GoT outperforms ToT significantly in complex aggregation tasks; for example, in sorting operations, GoT increased quality by 62% while simultaneously reducing computational token cost by over 31% compared to ToT, primarily by eliminating redundant parallel branches through node merging 2829.
| Reasoning Topology | Structural Flow | Parallelism & Backtracking | Example Benchmark Performance Gains |
|---|---|---|---|
| Input-Output (IO) | Single node mapping input directly to output. | None. Strictly linear. | Baseline performance; struggles with logic 120. |
| Chain-of-Thought (CoT) | Linear sequence of dependent reasoning steps. | None. Errors propagate fully down the chain 1725. | High accuracy on standard GSM8K; fails on complex planning 2418. |
| Tree of Thoughts (ToT) | Branching paths from single states; heuristic evaluation. | Supports extensive backtracking and parallel branching 1730. | Increased GPT-4 accuracy on Game of 24 from 4% to 74% 18. |
| Graph of Thoughts (GoT) | Arbitrary graph; branches can merge and loop. | Full parallelism, synergistic merging, and cyclic feedback 2829. | Increased sorting quality by 62% over ToT; reduced costs >31% 28. |
Scaling Laws and Emergent Capabilities
The effectiveness of advanced reasoning topologies is heavily dependent on the parameter scale of the base model. Complex reasoning structures like CoT and ToT were traditionally viewed as "emergent properties" - capabilities that appear unpredictably and non-linearly only when models reach a certain threshold of parameters and training data (historically cited around the 60-billion parameter mark for CoT) 243132.
However, the scientific definition of emergence is deeply contested in current research. While scaling laws dictate highly predictable decreases in pre-training loss as compute and data increase, specific task performance (like multi-digit arithmetic using CoT) appears to transition sharply from random chance to high accuracy 3132. Some researchers argue that this perceived emergence is an artifact of discontinuous measurement metrics (e.g., exact match accuracy) rather than a sudden cognitive leap in the model 32. They posit that structured reasoning is an inherent capability developed gradually during pre-training, which is merely elicited by precise prompting 24.
Recent advancements in reasoning models utilizing Reinforcement Learning (RL) and Monte Carlo Tree Search (MCTS) demonstrate that training models to self-generate extensive reasoning traces (Long-CoT) embeds these graph-like topologies directly into the model's behavior 1920. By penalizing short-cuts and rewarding extensive exploratory paths during post-training, models begin to exhibit internal backtracking and "aha moments" without requiring the explicit structural scaffolding of ToT or GoT prompts from the user 1920.
Multilingual Prompting Efficacy
The science of prompt engineering must also account for the linguistic medium of the prompt. Because the vast majority of pre-training corpora consists of English text, LLMs exhibit a pronounced performance bias toward English inputs, establishing it as the dominant medium for achieving high accuracy 3536. Evaluating the elementary multilingual capabilities of models beyond their intended language constraints has yielded counterintuitive findings regarding prompt transferability.
Disparities in Cross-Lingual Transfer
Empirical evaluations across diverse language benchmarks reveal substantial accuracy degradation when prompts are translated from English into non-English languages, even when the semantic meaning is identical 35. The disparity is particularly severe for low-resource languages, which suffer from limited representation in the training data, leading to semantic drift, cultural misalignment, and inaccurate task execution 3721.
Unexpectedly, performance degradation is not purely a binary between English and all other languages. Studies have found anomalies depending on the specific model and the linguistic structure. For instance, an evaluation across 26 languages using several leading AI models (including OpenAI, Gemini, and Llama) found that Polish outperformed English in precision and adherence to prompt commands, achieving an 88% accuracy rate and securing first place, while English ranked sixth 22. Researchers hypothesize this is due to the distinct morphological precision of certain languages acting as stricter constraints on the attention mechanism, despite having far less representation in the training data 22. Conversely, while some models (like Mistral) process multilingual input effectively despite being explicitly intended only for English, there remains a long tail of languages where models are neither faithful to the prompted language nor accurate in their reasoning 4023.
Optimization for Low-Resource Languages
To mitigate the performance gap for low-resource languages, researchers rely on specialized prompt engineering architectures designed to circumvent the model's linguistic weaknesses:
- Chain-of-Translation Prompting (CoTR): This method explicitly instructs the model to translate the low-resource language input into English, perform the analytical reasoning or task execution in the high-resource English latent space, and then translate the final output back to the original language. This bypasses the model's weak reasoning capabilities in the low-resource language while maintaining the desired user interface 42.
- Native-CoT: In this approach, the model is prompted to perform the step-by-step reasoning entirely in the native, non-English language. While this risks encountering the limitations of the model's non-English training, it preserves cultural context and avoids translation artifacts that may corrupt the logic 37.
- Chain-of-Dictionary (CoD): Applied frequently in few-shot translation tasks, CoD integrates multilingual dictionary information directly into the prompt as prior knowledge, anchoring the model's token predictions to verified semantic mappings rather than relying on its sparse pre-trained knowledge of the low-resource language 37.
- Multilingual and Multicultural Prompting: Generating multiple variations of a single prompt incorporating different cultural and linguistic cues, then ensembling the results, has been shown to increase output diversity and significantly reduce hallucinations associated with culturally specific information 24.
Instruction Hierarchy and Model Robustness
A critical sub-domain of prompt engineering research focuses on how LLMs adjudicate conflicting instructions within a single prompt context. In typical enterprise deployment, an LLM receives a "system prompt" (authored by the developer) containing operational rules and safety constraints, followed by a "user prompt" (which may contain adversarial, conflicting, or maliciously crafted requests). The science of securing these prompts requires analyzing the model's structural adherence to intent.
Susceptibility to Prompt Injection
Instruction-following models demonstrate severe vulnerabilities to prompt injection, a scenario where an attacker embeds malicious instructions within the user prompt or third-party data (like a retrieved web page) to successfully override the developer's system instructions 254526. Comprehensive evaluations utilizing benchmark QA datasets reveal that many models are overly tuned to execute any recognized instruction, frequently abandoning primary system constraints to comply with irrelevant or malicious user requests 264727.
Notably, a model's size and its general instruction-following capabilities do not reliably correlate with its robustness against prompt injection. In several instances, highly capable models with superior contextual understanding are more easily compromised because they are overly eager to follow deeply embedded conversational directives, whereas less capable models simply fail to process the complex injection 454727.
To combat prompt injection, developers utilize the concept of an Instruction Hierarchy. This architecture explicitly trains the model to understand privilege levels: developer system instructions hold the highest privilege, followed by user queries, model outputs, and finally third-party tool outputs 2850. While leading laboratories have successfully applied synthetic data generation methods to teach models to selectively ignore lower-privileged malicious instructions - yielding up to a 63% improvement in attack resistance - the application of system/user role separation is not foolproof 2850. Systematic evaluations show that despite instruction hierarchies, LLMs struggle to maintain consistent prioritization when facing simple formatting conflicts 29. Strikingly, models exhibit strong inherent biases based on their pre-training. Societal hierarchy framings - such as commands asserting authority, expertise, or broad consensus - often exert a stronger influence on model behavior than the explicit system/user role tags, acting as latent behavioral priors that can override post-training safety guardrails 29.
The Misinformation Paradox of Instruction Tuning
The process of Supervised Instruction Fine-Tuning (SIFT) - designed to make models highly responsive and aligned with user intent - inadvertently creates a structural vulnerability regarding truthfulness. Research demonstrates that instruction-tuned models are significantly more susceptible to accepting and acting upon misinformation than their foundational base models 3053.
Because instruction tuning heavily rewards compliance with the "user" role, the model develops an over-reliance on user-provided data. When misinformation is presented in the user prompt, the model will frequently override its own parametric knowledge to align with the user's false premise 30. This creates a paradox where the techniques used to make a model more steerable via prompt engineering simultaneously degrade its reliability when acting as an independent arbiter of factual reality 3053.
Programmatic Prompt Optimization
As context windows have expanded to accommodate millions of tokens, and as models have internalized much of the heuristic prompt engineering knowledge through Reinforcement Learning from Human Feedback (RLHF), the discipline of prompt engineering is undergoing a fundamental paradigm shift 3132. The era of manual, trial-and-error prompt tuning is increasingly viewed as obsolete for production environments, being replaced by systematic "context engineering" and automated prompt optimization pipelines 315633.
The Obsolescence of Manual Prompting
Manual prompt writing is inherently fragile. A prompt highly optimized for one model often experiences "Model Drifting," yielding severely degraded performance when executed on a different model architecture due to differing pre-training distributions and tokenization methods 34. Reusing a carefully crafted prompt across different foundational models requires costly, labor-intensive re-optimization 34. Furthermore, manual iteration lacks scalability; tweaking phrases based on human intuition is a subjective exercise that fails to provide consistent, metric-driven signals across large datasets 5633. Industry analysts note that prompt engineering has transitioned from crafting "magic sentences" to architecting robust data pipelines, where the primary objective is filling the model's context window with exactly the right programmatic information at the right time 31.
Automated Pipelines and DSPy
To address the limitations of manual iteration, frameworks like DSPy (Declarative Self-Improving Python) treat language models as programmable functions within a larger, self-optimizing pipeline 356061. DSPy abstracts the prompting process into text transformation graphs and modular components, such as retrievers, summarizers, and generators 3562. Rather than hand-crafting the exact wording of a system prompt or manually selecting few-shot examples, a developer defines the signature of the task (the inputs and the expected outputs) and provides a training dataset and an objective metric 3560.
The DSPy compiler then utilizes automated optimization algorithms - such as Cooperative Prompt Optimization (COPRO), which iteratively refines instructions, or Multi-Stage Instruction Prompt Optimization (MIPRO), which optimizes instructions and few-shot examples simultaneously - to learn the optimal prompt configuration 6061. By treating prompt parameters analogously to neural network weights, programmatic optimization replaces guesswork with continuous, data-driven cycles 5663.
Empirical studies indicate that DSPy-compiled pipelines outperform manually crafted expert prompt chains by substantial margins. Within minutes of compilation, automated optimization has been shown to improve baseline few-shot prompting performance by 25% to 65% depending on the task 62. Most notably, programmatic optimization allows smaller, open-weight models (such as the 770-million parameter T5 or Llama 13B) to achieve accuracy levels competitive with massive, proprietary models relying on human-authored prompt chains 6264. This demonstrates that the future of effective LLM interaction relies on algorithmic compilation rather than human linguistic artifice.
Conclusion
The science of prompt engineering has definitively established that interacting with large language models is a rigorous computational discipline. Empirical evidence systematically dismantles the utility of anecdotal "magic words" and anthropomorphic framing, proving that effective prompting relies on managing hyperparameter configurations, exploiting positional attention biases, and structuring complex mathematical reasoning topologies like the Graph of Thoughts. The vulnerability of models to prompt injection and their shifting susceptibility to misinformation underscore the critical importance of secure instruction hierarchies. As models grow increasingly capable of processing vast contexts, the field is evolving from manual string manipulation toward automated, mathematically optimized context engineering using frameworks like DSPy. To achieve reproducible, high-fidelity results, practitioners and researchers must abandon heuristic guesswork in favor of framework-driven optimization, rigorous empirical testing, and an acute awareness of the latent biases embedded within the transformer architecture.