AI and human feedback in writing, coding, and creative work
Introduction to the Shifting Feedback Paradigm
The integration of generative artificial intelligence, particularly large language models (LLMs), into educational technology has catalyzed a structural shift in how formative feedback is generated, scaled, and delivered to learners. Foundational pedagogical theories establish that timely, highly specific, and personalized feedback is an essential mechanism for effective learning. It guides students toward specific learning goals, fosters metacognitive awareness, and supports the cyclical phases of self-regulated learning 1234. Historically, providing this level of personalized, immediate feedback at scale has been fundamentally constrained by the limited availability and high cognitive load of human instructors 156. Traditional automated systems, such as early Intelligent Tutoring Systems (ITS) and basic Computer-Aided Instruction (CAI), offered scalability but required extensive expert authoring and rigid rule-based designs that limited their applicability to complex, open-ended tasks 7.
The advent of neural large language models introduces new capabilities for natural language processing, dynamic content generation, and adaptive instruction without the need for explicitly programmed pedagogical rules 7. Current research, highly active within the fields of human-computer interaction (HCI) and educational psychology, evaluates how this AI-generated feedback compares to traditional human instruction across diverse disciplines. Empirical investigations span coding and computer science education, language acquisition, academic writing, and creative ideation 18910. The aggregated data reveals a nuanced landscape where the effectiveness of feedback depends less on the raw computational capability of the model and more on the pedagogical framework, the perceived source of the feedback, the subject domain, and the student's foundational feedback literacy 31112. Calibrated uncertainty remains necessary when interpreting long-term learning outcomes, as the rapid evolution of LLMs means many current studies capture cross-sectional snapshots of evolving technologies rather than longitudinal data.
Meta-Analytic Efficacy of Artificial Intelligence Feedback
To assess the macro-level impact of AI-generated feedback compared to human-provided feedback, educational researchers rely on meta-analyses that synthesize dozens of empirical studies. The aggregate statistical data indicates that while pure AI feedback is statistically comparable to human feedback in terms of overall learning performance, extreme heterogeneity exists across specific implementations, making hybrid instructional models the most statistically effective intervention.
Historical Context and Current Effect Sizes
Prior to the dominance of LLMs, Automated Writing Evaluation (AWE) systems demonstrated reliable efficacy. Early comprehensive meta-analyses of broad educational feedback interventions indicated a medium overall effect size (d = 0.48) on student learning, while specific AWE interventions yielded larger positive effects (g = 0.861) for writing quality, particularly among post-secondary students and English as a Foreign Language (EFL) learners 13.
Recent meta-analyses evaluating modern AI and LLM feedback present a more variable picture. A synthesis of 41 studies involving 4,813 students revealed no statistically significant differences in general learning performance between students receiving AI-generated feedback and those receiving human-provided feedback 1314. The pooled effect size comparing the two conditions for post-assessment task performance was small and statistically insignificant (Hedge's g = 0.25, CI [ - 0.11; 0.60]), indicating that AI systems perform, on average, on par with human instructors 13.
When researchers isolate studies measuring performance gains from a baseline pre-test to a post-test, the pooled effect size rises to Hedge's g = 0.36, but features a massive prediction interval ranging from - 2.21 to 2.93 and considerable heterogeneity (I2 = 94%) 13. A separate meta-analysis of 32 empirical studies isolated to Chinese educational databases found a more robust pooled effect size of Hedges' g = 0.51 (95% CI [0.42, 0.60]), representing a significant moderate positive facilitative effect, though still subject to high heterogeneity (I2 = 83.45%) based on academic stage and feedback type 14. This variance suggests that the success of AI feedback is heavily contingent on localized context, study design, and the specific technological platform deployed 13.
The Superiority of the Hybrid Intelligence Framework
The most critical finding from comparative meta-analyses in higher education is the statistical dominance of hybrid intelligence systems - where human instructors and AI tools operate in tandem - over single-source feedback. When evaluated specifically in the context of English writing performance, pure AI feedback generated a modest, statistically insignificant effect size (g = 0.26) 15. In contrast, hybrid human-AI feedback generated a substantially larger, statistically significant effect size (g = 0.80) 15.
The identity of the human partner in the hybrid model further moderates this efficacy. When AI feedback is combined specifically with teacher feedback, the pooled effect size peaks at g = 1.44, significantly outperforming combinations of AI with multiple human providers (g = 0.93), AI with peer feedback (g = 0.58), or AI with self-reflection (g = 0.39) 15.
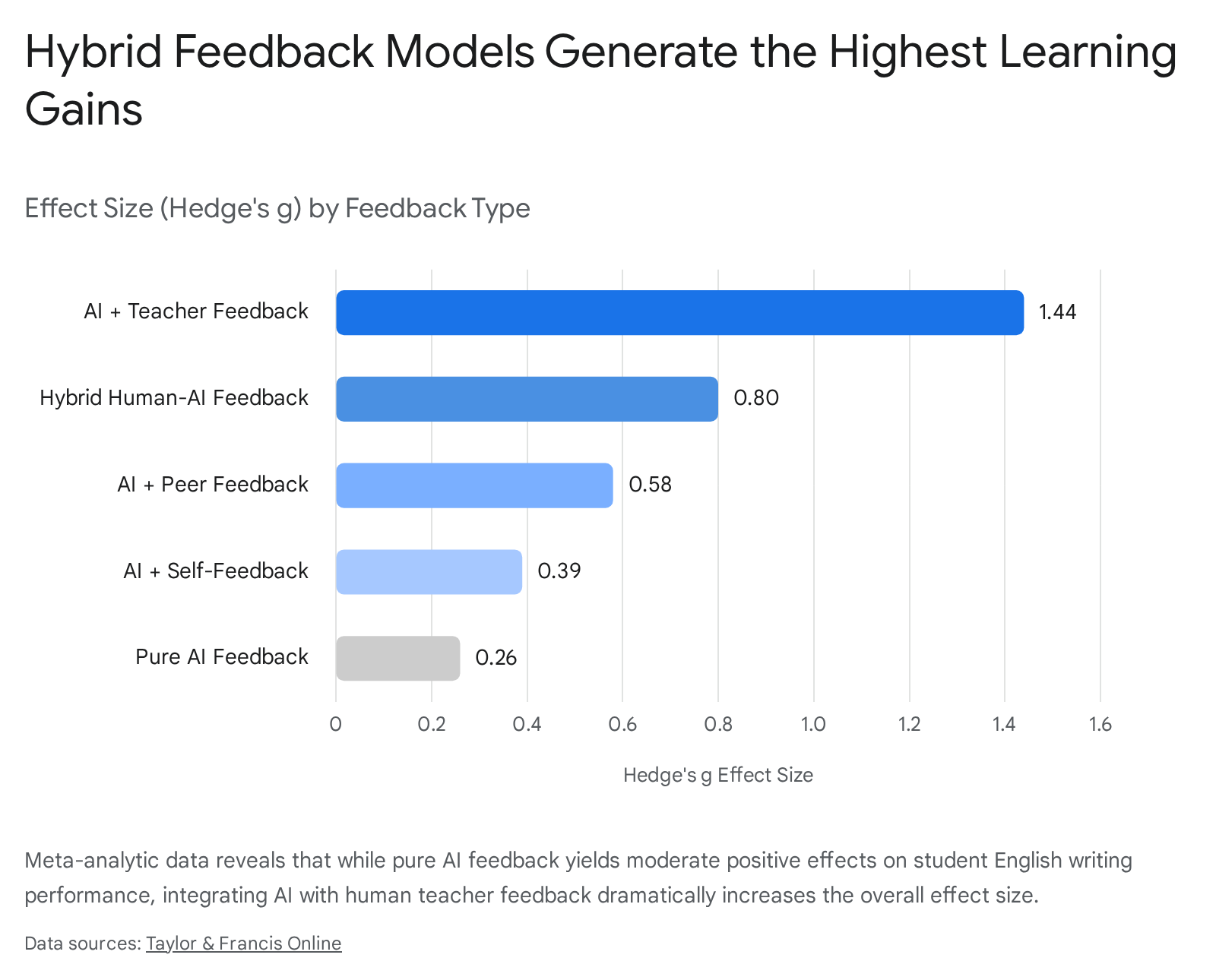
Theoretical frameworks, such as Self-Determination Theory, suggest that human instructors satisfy students' psychological needs for relatedness and emotional support, while the AI satisfies the need for immediate competence building through rapid, granular diagnostics 1516.
Feedback Dynamics in Computer Science Education
Computer science education, particularly introductory programming (CS1), represents one of the most mature domains for the integration of automated feedback. Because code is inherently deterministic and rules-based, automated grading and basic tutoring systems have been utilized for decades 710. However, the introduction of large language models has fundamentally altered the feedback loop by enabling dynamic code repairs, conceptual explanations, and adaptive knowledge modeling 10.
Formative Code Feedback and Adaptive Scaling
In contemporary programming pedagogy, LLM applications are categorized into three primary focal areas: formative code feedback, automated assessment, and knowledge modeling 10. Formative feedback involves generating scaffolding, hints, or error explanations that assist students in reasoning about their mistakes 10. Advanced implementations feature Automated Program Repair (APR) systems, which identify logic errors and provide context-sensitive fixes or worked examples directly aligned with the student's flawed logic 10. Automated assessment utilizes LLMs as scalable teaching assistants capable of producing rubric-aligned evaluations with moderate to high agreement with human graders, while knowledge modeling algorithms extract discrete "Knowledge Components" (e.g., variables, loops) from student inputs to track individual competency trajectories 10.
The primary advantage of LLM feedback in this domain is adaptive scalability. Research demonstrates that LLM-powered adaptive instruction in introductory computer science environments significantly improves student retention and task performance by addressing structural gaps inherent in one-size-fits-all instruction. In a notable deployment, personalized LLM scaffolding improved the code correctness rate of the most vulnerable demographic of students from 54.4% in the control group to 72.6% in the personalized group - an 18.2 percentage point improvement 7. By acting as an immediate diagnostic partner, AI reduces the latency between a student's error execution and the pedagogical intervention, a metric highly predictive of long-term course success 1017.
Limitations of Artificial Intelligence in Debugging and the Escalation Model
Despite their high capabilities, LLMs exhibit persistent limitations in programming education. They frequently struggle with complex bug localization and multi-line semantic logic errors. Performance and accuracy often degrade when transitioning from controlled benchmark datasets to the authentic, noisy, and highly idiosyncratic code produced by novice students 10. Consequently, AI systems can produce incorrect, misleading, or educationally unhelpful feedback that occasionally provides direct answers without proper educational scaffolding, risking the undermining of productive learning interactions 110.
To mitigate these technological limitations, HCI researchers have tested hybrid systems employing an "escalation mechanism." In a deployment involving 82 students in a data science programming course, an interface provided immediate AI-generated hints but allowed students to escalate their queries to a human teaching assistant (TA) when the AI's support proved insufficient 1. During the study, the AI generated 673 hints. Students rated 22% of these (146 hints) as unhelpful, primarily because the hints were incorrect, misfocused, or unclear 1. Hints related specifically to debugging faced an even higher rejection rate of 26% 1.
The escalation study revealed critical vulnerabilities not only in the AI but also in the human-centric fallback model. Human expertise is severely constrained by availability and cognitive load. Students utilizing the escalation pathway waited an average of 13.5 hours for a human TA response 1. While waiting, students remained engaged (continuing to code 87.5% of the time within the first hour), but they were only able to independently solve the programming question before receiving the delayed instructor feedback in 25% of the escalated cases 1. Furthermore, qualitative investigations into the human responses revealed that when a student escalated due to an incorrect AI hint, 86% of the subsequent instructor feedback was also classified as low-quality, incorrect, or insufficient 1. This indicates that when complex coding problems defeat an advanced LLM, human evaluators frequently lack the immediate context, time, or attention necessary to solve the error effectively, establishing a practical ceiling to the "human-in-the-loop" safeguard if human raters are fatigued.
| Feedback Provider | Speed of Delivery | Quality Constraints | Primary Benefit |
|---|---|---|---|
| Generative AI | Near-instantaneous (~20 seconds) | Struggles with complex multi-line logic errors; occasional hallucinations. | High scalability and adaptive scaffolding for routine errors. |
| Human Teaching Assistant | Highly delayed (13.5 hours average) | Limited by fatigue and cognitive load; high failure rate on escalated complex bugs. | Contextual nuance, pedagogical empathy, and deeper relational trust. |
Source Attribution and Learner Engagement
Beyond functional accuracy, the perceived source of the feedback fundamentally alters how programming students engage with instructional support. A controlled study utilizing a creative coding interface isolated the psychological variable of source attribution by providing mathematically identical LLM-generated feedback to all participants. Half of the cohort was informed the feedback was "AI-generated," while the other half was informed it came from a "human TA" 11.
The results demonstrated profound behavioral disparities based entirely on the label. Learners in the human TA condition spent significantly more time and effort engaging with the feedback, writing substantially more code on average (843 lines, SD=584) than those in the AI condition (631 lines, SD=359), resulting in a notable effect size (d = 0.44) 11. Furthermore, the psychological criteria by which students evaluated the feedback diverged. Ratings for feedback explicitly attributed to AI were heavily predicted by the student's pre-existing trust in AI as a technology (r = 0.85). In contrast, ratings for feedback attributed to the TA were predicted by the perceived genuineness of the text (r = 0.65) 11. This confirms that in analytical STEM environments, the efficacy of feedback is not solely a product of technical accuracy, but is heavily moderated by the social presence, psychological authority, and effort-based reciprocity attributed to a human evaluator.
Feedback in Writing and Language Acquisition
While programming relies on deterministic syntax, academic writing and language acquisition require subjective evaluation of narrative structure, argumentation, stylistic voice, and cultural context. AI systems have achieved high proficiency in providing surface-level grammatical and criteria-based assessments, but empirical data shows human instructors maintain a distinct advantage in advanced pedagogical nuances and emotional resonance 1819.
Criteria-Based Scoring Versus Contextual Nuance
Automated Writing Evaluation (AWE) tools and modern generative AI have demonstrated high effectiveness in accelerating the formative assessment loop for English as a Foreign Language (EFL) and English as a Second Language (ESL) learners 13. Studies indicate that AI feedback on academic writing improves revision quality when coupled with explicit guidance on interpretation 813. Non-native speakers frequently view AI-generated feedback positively, appreciating the immediate, detailed error analyses and the objectivity of the algorithmic review, which can lower language anxiety 2120. In some academic measurements, AI-generated feedback is found to be more detailed, highly readable, and generated significantly faster than human feedback 1920.
However, comparative studies reveal a persistent human superiority in holistic, narrative assessment. A comprehensive study evaluated ChatGPT against trained human instructors across five specific dimensions of essay feedback: addressing essay criteria, providing directions for improvement, accuracy, maintaining a supportive tone, and prioritizing important comments 21. The human evaluators scored better in four of the five categories 21. The AI only outperformed humans in criteria-based feedback - effectively functioning as an algorithmic checklist against a rubric 21. Generative AI often struggles to assess the ultimate logical validity of a student's narrative content, occasionally hallucinating corrections or providing generic, unprioritized lists of line-edits that overwhelm learners rather than targeting the most critical structural flaws 1819. Students routinely rate human feedback as significantly more credible, empathetic, and relational, viewing pure AI feedback as lacking the emotional intelligence necessary to motivate deeper revision 20.
| Feedback Dimension | AI Proficiency Level | Human Instructor Proficiency Level |
|---|---|---|
| Rubric / Criteria Adherence | Very High (Superior to Humans) | High |
| Grammar and Syntax | Very High | High |
| Prioritization of Edits | Low (Often overwhelming/unranked) | Very High |
| Directions for Improvement | Moderate | High |
| Supportive Tone & Empathy | Moderate (Often perceived as generic) | Very High |
Language Homogenization and Artificial Intelligence Colonialism
A critical, emerging area of research concerns the cultural and linguistic implications of relying on Western-developed LLMs for qualitative writing feedback. Because frontier models are trained predominantly on datasets reflecting North American and Western European linguistic norms, their feedback algorithms actively homogenize global writing styles, presenting significant risks to educational equity 2223.
A study presented at the ACM CHI 2025 conference investigated this phenomenon by asking 118 participants in the United States and India to write about cultural topics with and without an AI writing assistant 22. The researchers logged keystrokes and acceptance rates of autocomplete suggestions. The data showed that Indian participants were more likely to accept the AI's help (keeping 25% of suggestions compared to 19% for Americans), but they were also significantly more likely to have to manually modify the suggestions to fit their specific topic and cultural style 22.
The AI consistently asserted Western defaults, overriding localized context. For example, when Indian participants wrote about their favorite food or holiday, the AI persistently suggested "pizza" and "Christmas," respectively 22. When an Indian participant attempted to describe the Diwali festival independently, they utilized specific terminology like "worship goddess Laxmi." However, participants utilizing AI autocomplete shifted their vocabulary to mimic a Western lens, adopting generic phrases like "traditional Indian breakfast items" 22.
Researchers classify this phenomenon as "AI colonialism," where algorithmic feedback suppresses cultural nuances and presents Western narrative structures as the default standard of quality 222427. This dynamic creates a "correction tax" for non-Western students; while the AI assistant helped both groups write faster overall, Indian users received a significantly smaller productivity boost because they had to expend cognitive effort repeatedly pushing back against inappropriate cultural suggestions 22. This underscores the necessity for human oversight to ensure that writing feedback remains culturally responsive and equitable 28.
Generative Artificial Intelligence in Creative Ideation and Design
The application of AI feedback extends into the creative arts and design education - disciplines historically viewed as the exclusive domain of human intuition and subjective aesthetic judgment. Current research establishes a bifurcation in this area: students highly value AI feedback during the structural, early phases of creative ideation, but demonstrate profound psychological biases against AI when evaluating final aesthetic products.
Brainstorming and Structural Design Feedback
During the early, highly divergent phases of design education, the high student-to-professor ratio often prevents the delivery of rapid, iterative feedback necessary for optimal ideation 5. In these environments, generative AI functions effectively as a collaborative brainstorming partner. A controlled study involving 25 academic design students compared feedback generated by GPT-4 against feedback from six human educators during a foundational brainstorming task 9.
Contrary to the assumption that humans are uniquely required for creative critique, the students rated the AI-generated feedback higher than human feedback across all measured dimensions, including social-emotional perception, encouragement, inspiration, and coherence 59. The AI generated its feedback in a median time of 1.59 minutes, providing highly structured and organized responses that received median ratings of 5.0 (out of 5.0) for overall organization 9. In contrast, the human lecturers' comments varied widely based on individual communication style, time constraints, and subjective involvement, occasionally resulting in critiques that were perceived as less structured or less encouraging 9. This evidence suggests that for early-stage creative ideation, the structured, consistent, and endlessly patient nature of conversational AI provides a psychologically safe environment for students to refine abstract concepts without the fear of human judgment 5.
Aesthetic Judgment and Anti-Artificial Intelligence Bias
While AI is embraced as a supportive structural partner behind the scenes, its outputs are heavily penalized during formal aesthetic evaluation. In the creative arts, the perception of quality is tightly bound to the presumed human effort and emotional intent behind the creation.
Multiple studies reveal a persistent and measurable "anti-AI bias" in the evaluation of creative works, spanning visual art, poetry, choreography, and creative writing 25. In a controlled experiment, human participants evaluated a series of abstract paintings that were all, in fact, generated by AI. The researchers randomly assigned either a "Human-created" or "AI-created" label to each piece 25. Across all four primary rating criteria - Liking, Beauty, Profundity, and Worth - participants systematically downgraded the artwork labeled as AI-created 25.
This bias was moderated by variables such as "narrativity" (the perceived story behind the art) and the assumed cognitive effort required to create it. Human observers inherently value the struggle and emotional intent they assume is embedded in a creative product. Consequently, feedback and outputs explicitly known to be generated by algorithms are judged to lack profound meaning, regardless of their objective visual or textual characteristics 2526. Furthermore, while AI models demonstrate higher statistical flexibility and volume in generating rapid creative interpretations during standardized psychological assessments (such as the Alternative Uses Task), the absolute highest performers in complex, multimodal creative interpretative tasks remain top-tier human subjects, whose best outputs surpass AI in perceived subjective creativity 27.
Psychological Dimensions of Human-Computer Interaction
The efficacy of AI-generated feedback is deeply constrained by the psychological phenomena governing how humans interact with automated systems. Two opposing cognitive biases - automation bias and algorithmic aversion - dictate learner engagement, leading to significant downstream impacts on long-term cognitive development and skill acquisition.
Automation Bias and the Cognitive Debt Cycle
Automation bias occurs when users over-rely on an automated system that appears competent, accepting its outputs with limited scrutiny even when those outputs conflict with their own prior knowledge or judgment 1232. In educational human-AI interaction (HAI), this manifests as a dangerous shift from active, deliberate problem-solving to passive evaluation of machine-generated content 12.
When students habitually utilize generative AI to bypass complex cognitive tasks, they accumulate what researchers term "cognitive debt" 12. Analogous to technical debt in software engineering, cognitive debt accrues when a student prioritizes short-term expedience (such as delegating a difficult coding or writing task to an AI) over the effortful learning processes required for deep mastery 12. A study evaluating 299 STEM students revealed that routine users of generative AI reported significantly lower levels of reflection, critical thinking, and an intrinsic need for understanding in their coursework 12. The routine usage of AI predicted massive reductions in "System 2" cognitive work - the deliberate, effortful questioning of assumptions and weighing of evidence 12.
Paradoxically, students with traits generally celebrated in STEM fields - high technophilic motivations, risk tolerance, and strong computer self-efficacy - were found to be the most vulnerable to this cognitive disengagement 12. High self-efficacy translates into higher trust in the technology, which lowers the student's reluctance to delegate tasks. This creates a self-reinforcing downward spiral where genAI becomes increasingly necessary as independent intellectual habits atrophy 12. Controlled neurophysiological studies corroborate these self-reports, showing that students writing with AI assistance exhibit reduced brain activation in neural networks associated with cognitive control and creativity, culminating in weaker long-term memory recall 12. Consequently, generative AI often creates an "illusion of competence," where task completion rates and apparent quality accelerate, but underlying metacognitive skills (such as the ability to debug code or adapt when the AI fails) severely deteriorate 12.
Algorithmic Aversion and Trust Calibration
Conversely, algorithmic aversion occurs when individuals distrust or actively refuse to rely on automated systems, often favoring human intervention even when the algorithm demonstrates superior or equal performance 3233. This aversion is frequently driven by a lack of systemic transparency and a fear of losing control over the learning process. If a student cannot understand the underlying logic of how an LLM arrived at a critique of their essay or code, they are highly likely to reject it 3334.
In double-blind educational studies, undergraduate students frequently rate AI feedback as more objective and useful than human feedback. However, once the source is disclosed as an AI, the subjective valuation of the feedback plummets 20. Research demonstrates that algorithmic decisions are considered highly trustworthy for mechanical, syntax-based tasks (e.g., code linting, spelling checks), but are met with high aversion when applied to domains considered fundamentally "human," such as creative writing evaluation, emotional support, or subjective grading 34.
The Algorithmic Trust Study, a massive laboratory effort involving 9,000 participants across nine countries, demonstrated that impartiality remains difficult when interfaces hide uncertainty 32. Overcoming algorithmic aversion - and simultaneously combating automation bias - requires interfaces that communicate calibrated uncertainty, allowing users to verify the AI's reasoning. The study found that introducing simple "confidence bands" (visual indicators of the AI's certainty regarding its feedback) reduced over-reliance by 17%, forcing users to re-engage their critical thinking 32.
Cross-Cultural Dynamics and Teacher Acceptance
The acceptance of AI-generated feedback is not globally uniform. Cultural contexts, geographic locations, and variations in educational paradigms heavily influence the Technology Acceptance Model (TAM), dictating whether students and educators view AI as a valuable pedagogical tool or a threat to educational integrity.
Student Technology Acceptance Models Across Regions
Cross-cultural studies applying the TAM framework reveal diverging priorities among student populations. In a large survey of 800 university students, distinct patterns emerged between Chinese and international (predominantly Western) cohorts. Chinese students exhibited a significantly stronger relationship between "Perceived Usefulness" (PU) and their behavioral intention to adopt AI feedback 35. This aligns with Hofstede's cultural dimensions theory, reflecting a cultural emphasis on pragmatism, utility, and high academic performance metrics. Conversely, Western and international students placed a much stronger emphasis on "Perceived Ease of Use" (PEOU) and individual autonomy when deciding to interact with AI systems 35. Broadly, research also indicates that non-native English speakers exhibit more positive views toward AI feedback tools than native speakers, primarily because the AI provides highly useful, objective linguistic scaffolding that helps level the academic playing field 21.
Teacher Authority and Geographic Variations
The successful implementation of AI feedback relies heavily on teacher endorsement, yet educator trust in AI varies significantly across geographic regions. A comprehensive survey of 508 K-12 teachers across six countries (Brazil, Israel, Japan, Norway, Sweden, and the USA) revealed that higher AI self-efficacy and technical understanding directly correlated with greater trust in AI educational technology, regardless of the teacher's age, gender, or level of education 36.
However, broader national surveys highlight severe hesitation. In the United Kingdom, a survey of 1,228 primary and secondary school teachers found that while 87.5% had heard of generative AI, only 47.7% had actually used it in an educational context 23. In regions where AI integration threatens traditional hierarchies of teacher authority, or where open discussion of AI is considered professionally taboo, adoption remains stagnant 23. Many educators across Europe, South America, and the Middle East express profound concerns regarding data privacy, the potential for culturally inappropriate algorithmic outputs, and the erosion of the empathetic student-teacher relationship 2327. These findings suggest that globally scaling AI feedback requires culturally responsive models and localized professional development that respects regional pedagogical values.
The Human-in-the-Loop Pedagogical Workflow
To reconcile the massive scalability and technical diagnostic precision of AI with the relational, emotional, and complex cognitive requirements of effective pedagogy, the consensus across HCI and educational research points to the necessity of the "Human-in-the-Loop" (HITL) paradigm. Within this framework, AI serves as an augmentation tool to accelerate baseline diagnostics, rather than an autonomous evaluator replacing the instructor 2828.
Mechanisms of Co-Produced Feedback
The most effective realization of the HITL paradigm is "co-produced" feedback. In this model, an AI generates an initial draft of student feedback based on specific rubrics, which an instructor then reviews, modifies, and contextualizes prior to delivery to the student 21.
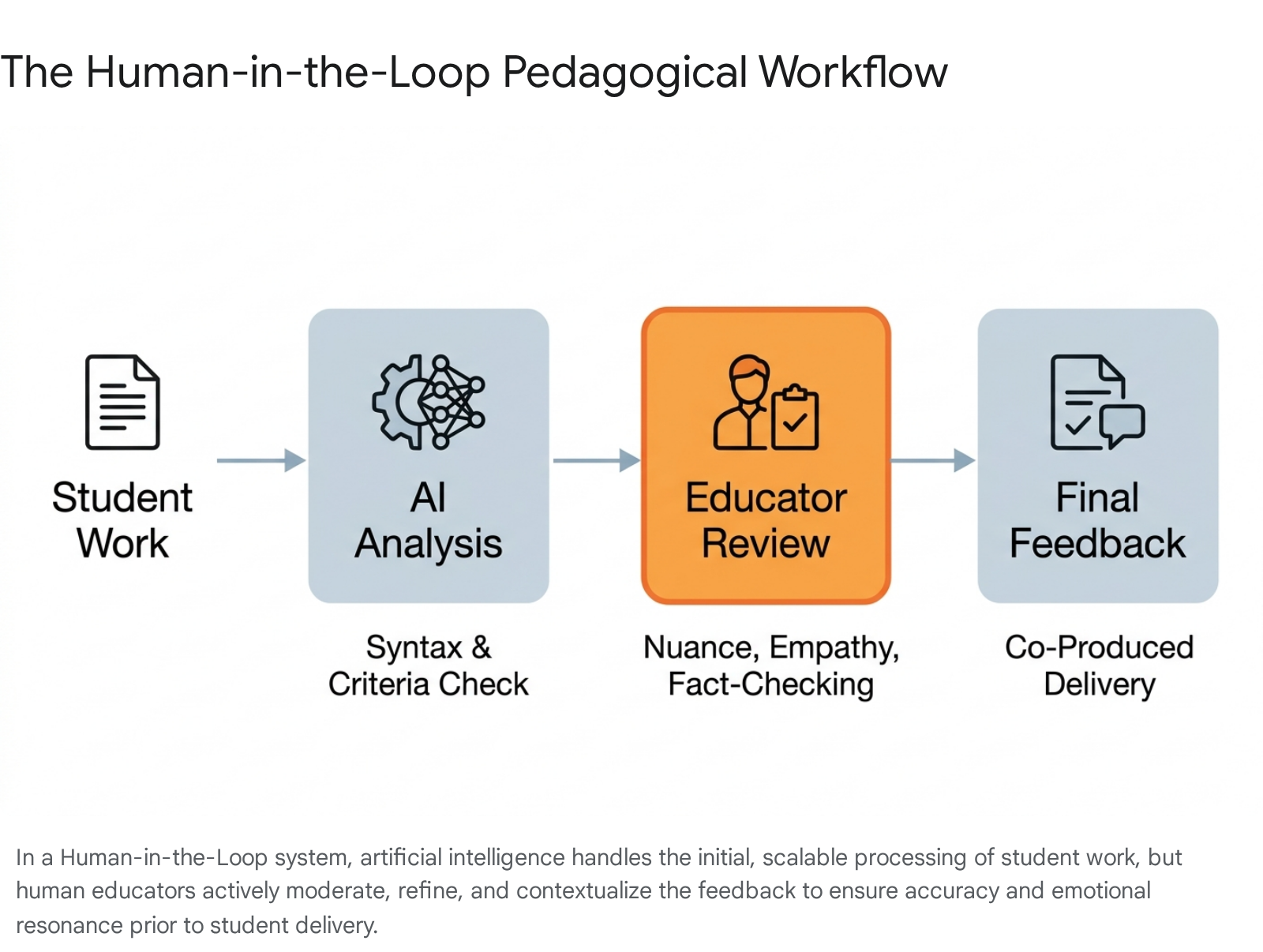
This workflow delegates low-level diagnostics (e.g., syntax errors, punctuation, surface-level adherence to prompt guidelines) to the machine, allowing the instructor to dedicate their cognitive resources to higher-order tasks, such as moderating tone, adding empathetic encouragement, fact-checking hallucinations, and ensuring the feedback aligns with the student's holistic development trajectory 192138.
Research demonstrates that feedback co-produced by humans and AI successfully circumvents algorithmic aversion. Students rate co-produced feedback as highly credible and genuine - on par with purely human-generated feedback - while simultaneously benefiting from the rapid, comprehensive structural analysis provided by the algorithm 2021. Furthermore, HITL allows educators to intercept instances of algorithmic bias, such as the suppression of cultural nuances or the propagation of Western-centric examples, safeguarding educational equity 2828.
Operational Challenges and Competency Frameworks
While theoretically robust and highly effective for students, the implementation of HITL introduces practical friction for educators. A primary societal goal of integrating AI into education is the reduction of instructor workload. However, studies indicate that reviewing, auditing, and heavily editing flawed AI-generated feedback can occasionally take an instructor longer than composing original feedback from scratch 39. If the AI model requires extensive, complex prompting to produce usable drafts, or if its outputs consistently misalign with the instructor's specific pedagogical style, the "loop" becomes an administrative burden rather than an efficiency multiplier.
To realize the benefits of human-AI collaboration at scale, institutions must invest in structured AI literacy and feedback competency frameworks for educators. A comprehensive scoping review of 76 peer-reviewed studies across Ibero-American universities identified five critical competency clusters required for modern teachers: feedback literacy with AI (including criterion-anchored prompting and revision-based workflows), rubric validation and traceability, data interpretation and fairness, integrity and transparency in AI assessment, and the orchestration of platforms when AI assists scoring 28. Only through targeted professional development across these clusters can educators effectively transition from traditional manual assessors to expert orchestrators of AI-assisted, human-moderated feedback ecosystems 2328.
Conclusion
The current state of educational research unequivocally demonstrates that AI-generated feedback is not a monolithic replacement for human instruction, but a highly capable, domain-specific augmentation tool. In deterministic fields such as computer science and programming, AI excels at providing the immediate, scalable diagnostics that drastically improve the retention and task performance of vulnerable students, though it remains constrained by its inability to reason through complex, multi-line logic errors. In qualitative disciplines such as academic writing and the creative arts, AI delivers robust structural and grammatical assessments with unprecedented speed, yet consistently falls short of human instructors in providing emotional resonance, cultural sensitivity, and holistic narrative prioritization.
Crucially, the efficacy of AI in educational settings is deeply mediated by human psychology. The cognitive phenomena of algorithmic aversion and automation bias present dual threats: learners may either reject highly accurate machine feedback due to a lack of systemic trust, or they may over-rely on the technology to the point of incurring long-term cognitive debt, thereby eroding their own critical thinking and problem-solving capacities.
Consequently, the most effective pedagogical strategy identified across the literature is the hybrid, human-in-the-loop framework. By combining the rapid, analytical processing power of large language models with the contextual understanding, pedagogical empathy, and authoritative presence of human educators, educational systems can achieve statistically significant enhancements in learning outcomes that neither entity could accomplish in isolation. Moving forward, the focus of educational technology research and institutional policy must shift away from maximizing the autonomy of AI systems, and instead focus on optimizing the collaborative interface between the algorithm, the instructor, and the student.