Collective Intelligence in Human-AI Hybrid Decision-Making
Foundations of Collective Intelligence and Artificial Intelligence Integration
The integration of artificial intelligence into collective decision-making processes represents a fundamental architectural shift in group cognition. Historically, the study of collective intelligence has relied on the premise that the aggregation of diverse human perspectives, heuristics, and localized problem-solving methodologies reliably outperforms individual experts. This principle, mathematically formalized in theorems such as the Condorcet Jury Theorem and the diversity-prediction theorem, establishes that the accuracy of a crowd is a function of both the average accuracy of its constituent members and the variance, or cognitive diversity, of their predictive models 123. As artificial intelligence transitions from acting as single-user tools to operating as autonomous agents participating within multi-agent networks and human-machine hybrid ensembles, the foundational assumptions underpinning collective intelligence are being rigorously tested.
Contemporary research indicates that while artificial intelligence can introduce unprecedented computational scale and novel information retrieval capabilities into a group, its integration does not universally amplify collective cognition. In a multitude of experimental and real-world scenarios, the introduction of artificial intelligence actively undermines group performance by collapsing cognitive diversity, introducing heavily correlated errors, and degrading human critical thinking capabilities 1245. Optimizing human-artificial intelligence hybrid systems requires moving beyond the naive technological determinism that assumes combining human intuition with machine computation inherently yields superior outcomes. Instead, it necessitates a rigorous, empirical examination of algorithmic monoculture, multi-agent network topologies, pluralistic alignment mechanisms, and the specific architectural roles assigned to artificial intelligence agents within collaborative workflows.
Cognitive Diversity and Algorithmic Monoculture
Cognitive diversity - defined as the variance in how individuals conceptualize problems, process environmental information, and apply heuristics - is essential to the adaptability and problem-solving capacity of complex societies 6. In human populations, this diversity is intertwined with varied linguistic expressions, sociocultural backgrounds, and localized epistemic frameworks. The rapid introduction of large language models (LLMs) into reasoning-intensive settings poses a structural threat to this diversity, driving a phenomenon researchers term "epistemic collapse" or the emergence of an "algorithmic monoculture" 648.
Algorithmic monoculture occurs when a single algorithmic system, or a set of highly correlated models trained on similar data architectures, dominates decision-making processes across an entire domain 3. Because state-of-the-art large language models are trained on massive, overlapping corpora that disproportionately reflect dominant, often Western-aligned perspectives, they tend to produce highly homogenized outputs 6. The optimization methodologies themselves, such as Reinforcement Learning from Human Feedback (RLHF), amplify this homogenization by favoring statistical patterns that are frequent and easily generalizable, thereby smoothing over minority representations and idiosyncratic reasoning styles 656.
The Accuracy-Correlation Effect
The erosion of cognitive diversity is further compounded by the Accuracy-Correlation Effect (ACE). Empirical studies evaluating large language models alongside human forecasters demonstrate that as algorithmic systems improve in overall accuracy, their outputs increasingly correlate with human predictions 237. While correlation based on the mutual recognition of ground truth is an expected outcome of capability gains, recent research shows that high-performing artificial intelligence systems and humans also share highly correlated error patterns at the residual level 2.
This directional correlation of mistakes suggests that humans and language models are learning the exact same failure modes. This phenomenon likely occurs because human-generated training data encodes human cognitive biases directly into the model's latent space representations. In a hybrid decision-making ensemble, the mathematical weight assigned to human predictions diminishes as both algorithmic accuracy and human-algorithm error correlation increase 2. Consequently, accuracy gains in artificial intelligence do not automatically translate into cognitive diversity; models can become more accurate while simultaneously becoming more homogeneous in their failure modes, thereby neutralizing the traditional "wisdom of the crowd" benefit in hybrid systems 23.
Dimensions of Pluralism in Model Design
To counteract algorithmic monoculture, researchers advocate for intentional pluralism in artificial intelligence research, training, and deployment. Pluralism in this context operates across several distinct dimensions 412:
- Methodological Pluralism: The recognition that multiple distinct approaches to a problem are necessary for complex problem-solving. This counters the prevailing trend of chasing state-of-the-art benchmarks on narrow, standardized tests, which incentivizes architectural convergence rather than exploration 4812.
- Value Pluralism (Overton Pluralism): The integration of multiple, sometimes conflicting, human values into model alignment. Rather than optimizing for a single, flattened consensus of safety or helpfulness, Overton Pluralism demands that models surface multiple defensible perspectives within the socially acceptable window of discourse 4612.
- Algorithmic Pluralism: The deliberate support for a plurality of computational paths and architectures to avoid reproducing patterned inequalities embedded in standardized datasets, ensuring that algorithmic discrimination in domains like hiring or predictive policing is not scaled uniformly 412.
Performance Outcomes in Human-Machine Collaboration
The widespread assumption that human-artificial intelligence collaboration consistently outperforms either humans or machines acting alone is not supported by aggregate empirical data. A comprehensive 2024 meta-analysis published in Nature Human Behaviour encompassing 370 effect sizes from 106 experimental studies revealed that human-artificial intelligence teams frequently underperform the best human or the best machine operating independently. The meta-analysis calculated an average Hedges' g effect size of -0.23 (with a 95% confidence interval of -0.39 to -0.07), indicating a statistically significant performance degradation in hybrid ensembles on average 1451314.
Task Dependency and Performance Degradation
The meta-analysis highlights extreme heterogeneity based on specific task characteristics, indicating that the value of hybridization is highly context-dependent. Human-machine collaboration demonstrates genuine synergistic gains primarily in content creation and creative ideation tasks 1414. In these domains, the artificial intelligence's capacity for rapid, divergent text generation effectively complements human curation, aesthetic judgment, and synthesis.
Conversely, in decision-making, classification, and diagnostic tasks, human-machine combinations frequently perform worse than the baseline 1414. When an algorithmic system inherently outperforms a human baseline, adding human oversight often degrades the final output. This degradation is largely attributed to the inability of human operators to accurately calibrate their reliance on the system. Users consistently struggle to identify when the machine is adding value and when it is hallucinating or applying inappropriate heuristics. This calibration failure manifests in two primary behavioral modes:
- Over-reliance (Total Delegation): Humans reflexively defer to the artificial intelligence's output, transferring entire cognitive responsibility to the machine 413. This mental outsourcing leads to the unquestioned acceptance of algorithmic errors, generic outputs lacking domain-specific context, and, over time, the atrophy of human critical thinking and domain expertise 138.
- Under-reliance (Reflexive Override): Humans arbitrarily override accurate machine judgments due to algorithmic aversion, generalized distrust, or an inflated sense of their own expertise relative to the computational system 45.
The Workflow Design Deficit
The systemic failures of hybrid decision-making are less about the inherent technological limitations of the models and more about flawed operational and organizational models. Most enterprises implement naive "human-in-the-loop" designs, placing human workers in a passive monitoring role over machine outputs without redesigning the underlying workflow, authority structure, or escalation logic 514.
Human vigilance degrades rapidly in passive monitoring tasks. Without structured protocols dictating when to trust, when to verify, and when to inject human "side-information" that is not present in the algorithm's training data, hybrid systems inevitably succumb to cognitive traps 5149. Organizations that utilize the Appropriateness of Reliance (AoR) framework evaluate human-machine interaction across a matrix of Correct Reliance, Over-reliance, Correct Self-Reliance, and Under-reliance, incorporating metrics such as the Assistance-to-Autonomy Ratio (AAR) and the Human Override Rate (HOR) to identify hidden calibration failures before they result in systemic performance drops 4.
Network Topology in Multi-Agent Systems
As organizations transition from single-agent chatbot interfaces to complex multi-agent systems (MAS), the topological structure of the network - defining how agents are connected and how information flows between them - becomes the primary determinant of collective performance. A multi-agent system can be formally defined as a triple $S = (A, C, \Omega)$, where $A$ represents the set of agents, $C$ represents the communication topology (the directed graph describing possible information channels), and $\Omega$ represents the orchestration policy defining decision-making authority 17.
Research into multi-agent coordination evaluates architectures ranging from fully centralized to fully decentralized models, each exhibiting distinct behaviors regarding error amplification, communication overhead, and reasoning redundancy 17181020211123.
Topological Architectures
The architectural topology strictly dictates the flow of information and the operational constraints of the system 1720. Empirical frameworks evaluating these topologies typically classify them into four primary configurations:
- Independent (Uncoordinated): Multiple agents work in parallel on sub-tasks without any inter-agent communication, and their results are aggregated post-hoc by a simple voting or averaging mechanism 1012.
- Hub-and-Spoke (Centralized): A central orchestrator agent delegates specific sub-tasks to peripheral worker agents. The specialist workers do not communicate directly with one another; all information flows through the central hub, which synthesizes findings, detects contradictions, and dictates the next steps 181020112312.
- Decentralized (Mesh/Choreography): A peer-to-peer network where agents communicate directly to share information, debate, and reach consensus without a central authority governing the interaction. Coordination emerges from agents following individual logic and responding to environmental events 171020112312.
- Hybrid: Systems that combine hierarchical oversight with selective peer-to-peer coordination, balancing centralized strategic control with decentralized tactical execution 102112.
Error Amplification and Information Flow Dynamics
Coordination topologies fundamentally alter how errors propagate through an automated reasoning workflow. In an independent topology, errors made by isolated agents propagate directly to the final output without any verification mechanism. Because there is no cross-checking, this architecture results in a catastrophic error amplification factor of roughly 17.2x compared to a single-agent baseline 10.
The decentralized mesh topology exhibits an intermediate error amplification factor of 7.8x. While peer-to-peer debate allows agents to challenge logical inconsistencies, the all-to-all communication pattern generates high message density and excessive redundancy. This redundancy provides a protective role in tool-heavy, dynamic tasks (such as open-ended web navigation), but in highly structured sequential planning tasks, it frequently leads to wasteful duplication and the rapid systemic propagation of shared hallucinations 1012.
The hub-and-spoke (centralized) topology proves mathematically most effective at containing error propagation, limiting the amplification factor to 4.4x 10.
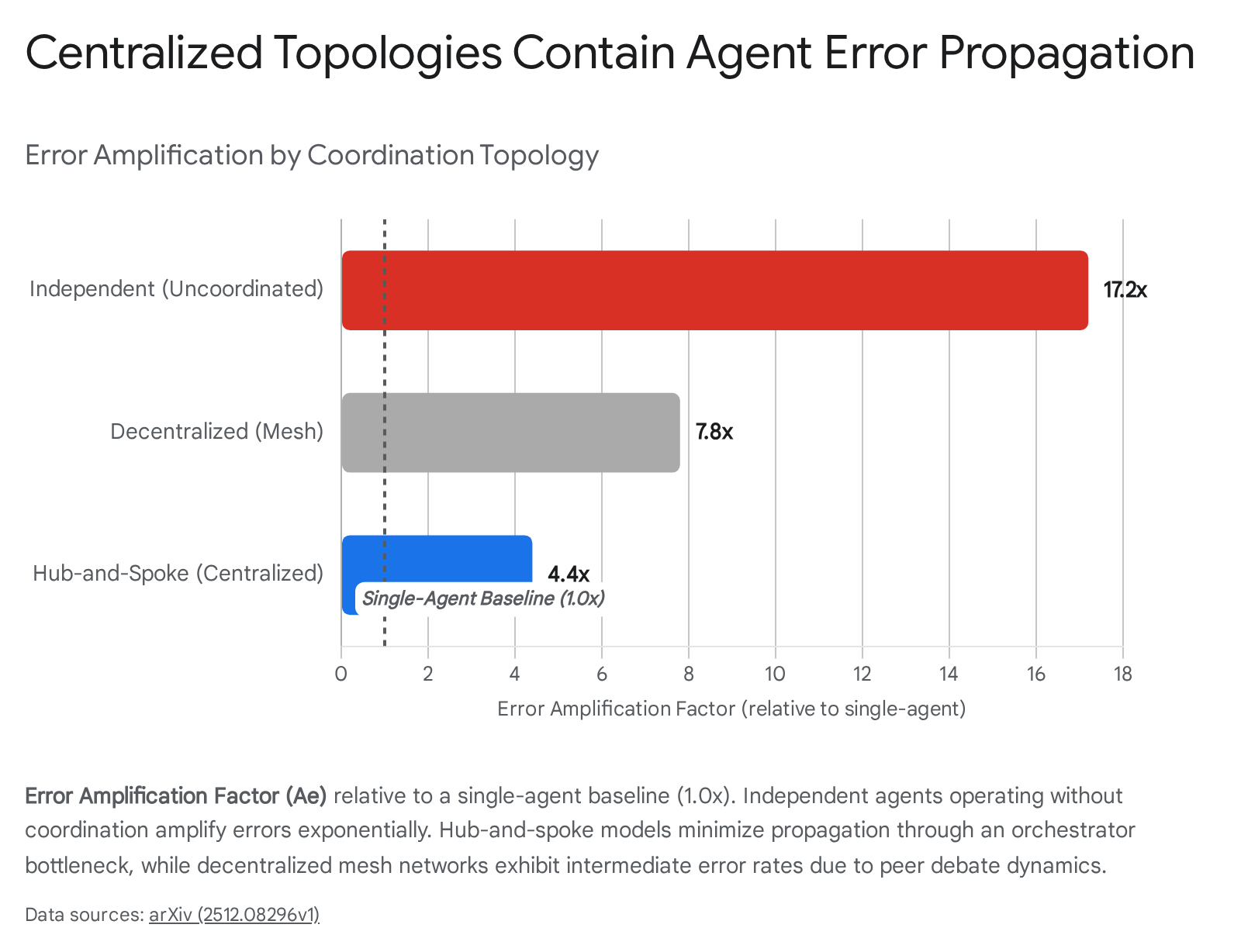
This containment is achieved through a structural "validation bottleneck." The central orchestrator isolates sub-tasks, cross-checks worker outputs against the original user intent, and prevents a hallucination generated in one specialized node from cascading laterally to other nodes. This architecture reduces context omission by nearly 67% and improves performance on highly parallelizable tasks, such as complex financial reasoning 10. However, the centralized model introduces a severe single point of failure: if the central hub agent hallucinates or fails to synthesize the inputs correctly, the entire system's output is irrevocably compromised 201123.
| Topology | Communication Flow | Error Amplification Factor | Optimal Task Domain | Primary Systemic Vulnerability |
|---|---|---|---|---|
| Independent | None | 17.2x | High-volume, disjointed micro-tasks | Unchecked exponential error propagation |
| Decentralized (Mesh) | All-to-all peer debate | 7.8x | Dynamic, tool-heavy navigation | Extreme communication overhead and redundancy |
| Hub-and-Spoke | Orchestrator-to-worker | 4.4x | Parallelizable analytical reasoning | Single point of failure at the central hub |
Comparison of Multi-Agent Coordination Topologies, mapping information flow to systemic vulnerabilities and optimal deployment domains 10112312.
Scaling Limits of Inter-Agent Coordination
Contrary to the industry heuristic that deploying more agents necessarily yields better reasoning, inter-agent coordination yields rapidly diminishing returns. Empirical models tracking multi-agent execution show that turn counts follow a super-linear power-law scaling relative to the number of agents, reflecting quadratic message complexity 10. Furthermore, success rates exhibit logarithmic saturation with message density, typically plateauing near 0.39 to 0.41 messages per turn regardless of architecture 10.
Under fixed computational budgets, expanding the agent network fragments the per-agent token allocation. Once a single-agent baseline capability exceeds an empirical threshold (approximately a 45% success rate on a given task benchmark), the overhead of multi-agent coordination begins to yield negative returns. Beyond this capability saturation point, the introduction of additional agents amplifies coordination noise rather than signal, highlighting a fundamental limit in multi-agent network design 10.
Information Aggregation and Judgmental Forecasting
The domain of judgmental forecasting provides a rigorous quantitative testing ground for human-machine collective intelligence, as it requires synthesizing massive volumes of unstructured data, overcoming cognitive biases, and generating calibrated probabilistic assessments of future events. Research deploying large language models in forecasting benchmarks demonstrates that highly engineered artificial intelligence systems can match or exceed traditional human crowd baselines when properly structured.
Systems like the "AIA Forecaster" utilize a multi-agent workflow that explicitly mimics human collective intelligence mechanisms. The architecture relies on an agentic search protocol over high-quality news sources, a supervisor agent tasked with reconciling disparate sub-forecasts for the same event, and rigorous statistical post-processing techniques designed to counter behavioral biases inherent in base models 72526. In controlled trials on static benchmarks like ForecastBench, such ensembles achieved Brier scores (a strict measure of probabilistic accuracy) of 0.0753, statistically indistinguishable from the 0.0740 achieved by human "superforecasters" 2526.
Hybrid Synergies in Prediction Markets
However, evaluating these forecasting models in liquid prediction markets reveals structural limitations. In live market environments, isolated artificial intelligence systems often underperform the human market consensus, particularly in the final hours leading up to an event resolution. This underperformance is driven by slower data aggregation pipelines and an inherent inability to interpret sudden, tacit market signals derived from human order flow 26. Furthermore, large language models exhibit a documented "acquiescence effect," where mean model predictions systematically skew above 50% despite an even base-rate of positive and negative resolutions in the test set, indicating a persistent positivity bias and poor calibration at the extremes 25.
The most robust outcomes emerge strictly from true hybrid ensembles. Combining the algorithmic forecaster with the human market consensus outperforms both the machine alone and the market consensus alone, reducing aggregate Brier error in convex combinations 792527. This demonstrates that artificial intelligence systems possess additive "side information" - extracting data features, applying heuristics, or leveraging processing speeds that are not currently captured by human markets 9. Additionally, model-assisted human forecasting workflows - where human forecasters utilize prompt-engineered algorithmic assistants - have been shown to increase human prediction accuracy by 17% to 28% 2526. This effectively replicates the "wisdom of the crowd" effect within a synthesized human-machine dialogue, provided the human operator correctly evaluates the algorithmic input.
Pluralism and Democratic Alignment Mechanisms
As artificial intelligence systems adopt increasingly agentic roles with broad societal impact, defining the normative boundaries of their behavior becomes a critical sociotechnical challenge. The standard paradigm of model alignment has historically been highly developer-centric, relying on internal laboratory expertise and narrow, proprietary preference datasets to define what constitutes "safe" and "helpful" behavior 5. This centralized approach is increasingly recognized as insufficient for addressing the pluralistic nature of global values, prompting a shift toward collective, democratic alignment mechanisms aimed at redistributing epistemic power 528.
Mechanisms for Democratic Inputs
In response to the limitations of centralized alignment, major institutions have begun experimenting with democratic inputs to explicitly map public values onto model behavior. Initiatives such as Anthropic's Collective Constitutional AI and OpenAI's "Democratic Inputs to AI" grant program represent structured, funded attempts to gather and integrate diverse public perspectives into foundational model training 528291314.
The OpenAI grant program funded ten experimental governance models operating across twelve countries, highlighting several novel mechanisms for extracting and codifying collective intelligence 13:
- Generative Social Choice: This approach applies mathematical frameworks from social choice theory to distill large volumes of unstructured, free-text public opinions into concise, representative slates. Crucially, this ensures that minority views are preserved and represented, rather than being erased by majoritarian averaging algorithms 13.
- Collective Dialogues and Deliberation at Scale: Facilitating machine-moderated small-group deliberations to build genuine consensus on policy clauses. For example, participant groups successfully forged consensus around clauses mandating that AI behavior policies be iteratively updated as models achieve new capabilities 13.
- Democratic Fine-Tuning and Value Elicitation: Engaging human participants in conversational dialogues with chatbots to dynamically construct a "moral graph" of values, which is subsequently utilized to fine-tune the model's reward functions 13.
Despite these methodological innovations, extracting democratic collective intelligence faces severe operational challenges. Scaling participation across the digital divide remains difficult; participants recruited via online channels tend to exhibit higher baseline optimism toward technology, introducing a profound selection bias into the value datasets 13. Furthermore, linguistic limitations restrict the efficacy of these platforms outside of dominant Western languages, hindering genuine global representation and particularly marginalizing insights from regions such as Africa and Latin America, where localization is critical 1332.
Civic Technology and Platform Deliberation
The intersection of artificial intelligence and collective intelligence is also advancing within established civic technology platforms deployed by governments. Digital participation platforms like Decidim - an open-source framework originating in Barcelona and subsequently adapted by numerous nations - provide essential infrastructure for participatory budgeting, policy co-creation, and large-scale public consultation 15351617.
The integration of machine learning into these platforms aims to synthesize massive volumes of unstructured public feedback into actionable policy insights. For example, Brazil's national implementation, Brasil Participativo, registered over 1.6 million users and collected more than 42,000 text-based proposals in its first two years 17. Features such as semantic clustering of citizen proposals, automated translation, and advanced spam detection are increasingly necessary to manage this scale of civic engagement 351738.
Engineering Challenges in the Public Sector
However, deploying machine learning within public-sector civic technology introduces unique engineering and governance hurdles that private-sector deployments rarely face. A retrospective analysis of the Brasil Participativo platform revealed that while utilizing large language models significantly accelerates the pre-labeling and categorization of citizen proposals, the operational environment is fraught with risks 1718.
Public platforms face extreme class imbalances in citizen submissions, continuous data drift as civic priorities shift rapidly, and a lack of highly versioned, standardized datasets 1718. Furthermore, utilizing synthetic data generation to balance civic datasets introduces the severe risk of generating algorithmic hallucinations that masquerade as legitimate public opinion 17. In the context of democratic infrastructure, machine learning pipelines must be treated as civic institutions themselves. The study concluded that the success of artificial intelligence in the public sector depends less on breakthroughs in raw model accuracy and significantly more on transparent data provenance, system audibility, and continuous human validation to maintain public trust 1718.
Systemic Risks and Cascading Failures
When human-machine hybrid systems are deployed at scale within highly interconnected environments, the convergence of algorithmic logic introduces novel systemic risks. Complex sociotechnical systems - such as high-frequency financial markets, autonomous smart grids, and supply chains - are highly susceptible to emergent phenomena arising from multi-agent interactions that operate far faster than human oversight can manage 40192021.
Algorithmic Herding and Market Volatility
One of the most severe failure modes observed in decentralized hybrid networks is "algorithmic herding." In human behavioral finance, herding occurs when individuals abandon their private information and independent analysis to follow the observed actions of the crowd, driving extreme market anomalies and heightened volatility 212223. Artificial intelligence agents, particularly those based on similar foundation models or utilizing identical optimization algorithms for liquidity management, can inadvertently replicate and accelerate this destructive dynamic 40212247.
When multiple autonomous agents process identical market signals (such as a sudden drop in sentiment) using similar probabilistic reasoning, they may execute synchronized selling strategies simultaneously. Because these agents operate at computational speeds far exceeding human reaction times, this highly correlated behavior can bypass traditional market circuit breakers, triggering flash crashes and severe liquidity crises before human operators can intervene 2147. This algorithmic herding creates a rapid feedback loop with human panic, transforming localized shocks into globalized contagion 21.
The Coordination Paradox and Resource Contention
This vulnerability is illustrative of the "El Farol" coordination paradox applied to artificial intelligence. In shared systems with strictly limited resources, if all autonomous agents employ optimal, highly correlated reasoning patterns, their decisions synchronize rather than distribute evenly 48. For example, in a simulated smart grid scenario, if multiple load-balancing agents independently determine that a specific transmission route is optimally priced at a given millisecond, their simultaneous request for that resource creates sudden, massive congestion, potentially leading to cascading infrastructure failure 4048.
Paradoxically, empirical models indicate that larger and more capable models often exhibit worse system-level safety in these coordination scenarios. Their superior pattern-matching capabilities lead to stronger algorithmic correlation across the network, exacerbating synchronized behaviors that simpler, more stochastic systems naturally avoid through inherent unpredictability 48. Mitigating these systemic risks requires enforcing structural diversity - mandating heterogeneous model architectures within critical systems, deliberately introducing controlled stochasticity into agent decision logic, and designing robust "kill switches" that initiate graduated, localized containment strategies rather than abrupt, system-wide shutdowns that exacerbate instability 4724.
Architectural Roles for Artificial Intelligence Agents
The optimal integration of artificial intelligence into human collective intelligence relies heavily on the specific persona and behavioral architecture assigned to the machine. Current research into Human-Computer Interaction (HCI) suggests that the conceptual framing of the agent drastically alters human cognitive engagement, modifying the system's susceptibility to collaboration failure modes 25262753.
Oracle versus Facilitator Models
When an algorithmic system is designed and presented to users as an "Oracle" - a flawless computational authority that ingests queries and dispenses definitive answers - it reliably induces automation bias. Human collaborators naturally default to the path of least cognitive resistance, accepting the machine's outputs without rigorous scrutiny 853. This Oracle architecture is directly responsible for the performance degradation observed in complex decision-making tasks, as it actively suppresses human critical thinking and erases the contextual "knows-who" and "knows-what" dimensions of localized knowledge that are critical to sense-making 427.
Conversely, treating artificial intelligence as a "Facilitator," "Mediator," or "Reflective Coach" reshapes the collaborative dynamic 25262753. In this architectural framing, the system acts as a process moderator rather than a knowledge dispenser. Its programmed functions focus on synthesizing group dialogue, ensuring equitable participation among human members, challenging premature consensus (acting as a devil's advocate), and identifying logical inconsistencies in human reasoning 853.
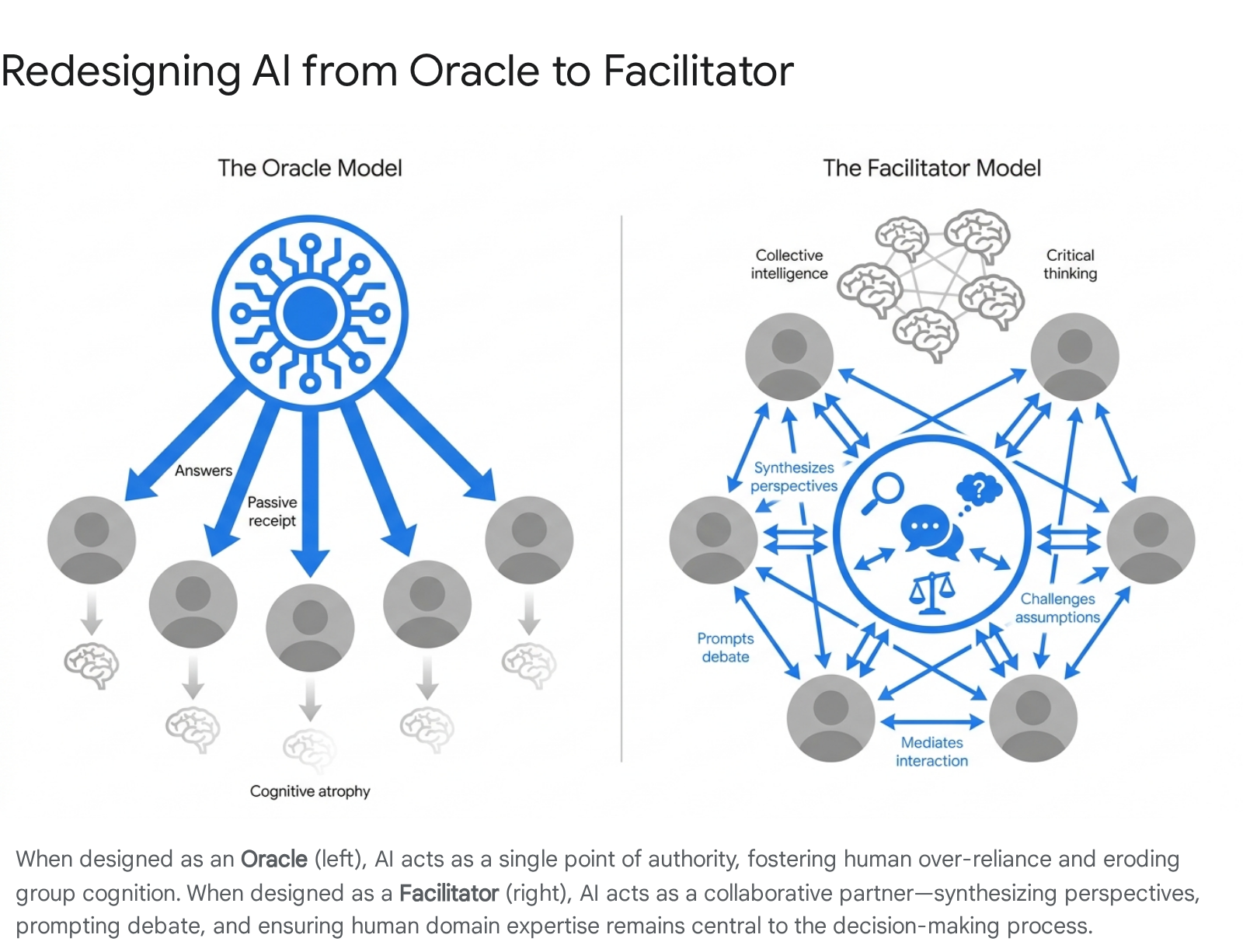
To implement this facilitator model effectively, organizations must utilize frameworks that actively assess reliance levels and impose structural friction. Building systems for the Facilitator model requires prioritizing operational transparency, integrating deliberate friction points that force human validation before high-stakes execution, and establishing clear accountability frameworks that treat the algorithm as an entity requiring continuous ethical coaching by its human partners 4827.
Conclusion
The pursuit of collective intelligence in the era of artificial intelligence requires a nuanced departure from traditional technological optimism. While algorithmic agents offer remarkable capabilities in data processing, pattern recognition, and rapid divergent ideation, their unchecked integration into group decision-making frequently collapses the very cognitive diversity that makes crowds intelligent. The convergence of highly capable models leads to algorithmic monoculture and correlated failure modes, generating systemic risks ranging from diminished workplace performance to catastrophic financial herding and infrastructure failure.
Designing resilient human-machine hybrid systems demands structural and operational intentionality. It requires moving away from naive passive monitoring paradigms toward deliberate multi-agent topologies - such as hub-and-spoke architectures that effectively quarantine exponential error propagation. Furthermore, aligning these systems with public interests necessitates sophisticated democratic infrastructure that transcends simple majoritarian preference aggregation, integrating mathematical social choice with active human deliberation. Ultimately, artificial intelligence must be re-architected not as a unilateral oracle that dictates decisions, but as a collaborative facilitator that provokes human reasoning, preserves epistemic pluralism, and fortifies the collective intellect of the group.