What Apple, Google, and Qualcomm Will Ship on 2026 Phones
In 2026, on-device artificial intelligence has transitioned from a specialized, cloud-dependent novelty into a mandatory, system-level hardware foundation. Driven by high-efficiency Neural Processing Units (NPUs) and architectures boasting 12GB to 24GB of RAM, modern flagship smartphones can now process complex generative tasks, real-time agentic workflows, and multi-billion-parameter multimodal inputs entirely locally. This localized processing paradigm democratizes advanced intelligence while mathematically guaranteeing unparalleled data privacy and zero-latency execution.
For the everyday smartphone user, this under-the-hood revolution translates directly into tangible, quality-of-life enhancements that fundamentally alter human-device interaction. Consider the experience of sitting in a subway tunnel with zero cellular reception, yet your smartphone seamlessly acts as a real-time voice translator, transcribing and vocalizing a conversation with a foreign traveler without a millisecond of delay. Picture pointing a phone camera at a complex document while in airplane mode and having the device instantly summarize the text, extract calendar dates, and draft a response. By keeping the processing localized, on-device AI ensures that deeply personal interactions - from drafting sensitive work emails to screening potential scam calls - never leave the physical boundary of the handset, merging peak convenience with airtight privacy.
Demystifying the Silicon: NPUs, Parameters, and TOPS
To understand the 2026 smartphone computing landscape, it is essential to decode the technical terminology that dictates device performance. As semiconductor manufacturers shift their marketing focus from traditional clock speeds and megapixel counts to artificial intelligence capabilities, three concepts dominate the engineering discourse: NPUs, parameters, and TOPS.
The NPU (Neural Processing Unit)
If the Central Processing Unit (CPU) of a smartphone is akin to a versatile executive chef capable of managing an entire kitchen and cooking any diverse dish, and the Graphics Processing Unit (GPU) represents a massive team of line cooks rapidly executing repetitive tasks like chopping vegetables in parallel, the Neural Processing Unit (NPU) is a highly specialized pastry chef. The NPU is purpose-built to execute one specific, highly complex task - matrix multiplication - with flawless precision and maximum energy efficiency 123. While a traditional CPU could technically run AI calculations, it would consume vast amounts of battery power and rapidly overheat the device. The NPU is the dedicated hardware accelerator that allows smartphones to process AI tasks continually without draining the battery or experiencing severe thermal throttling 45.
Parameters and Quantization
When discussing localized AI models, such as Google's Gemini Nano v3, Meta's Llama 3.2 3B, or Qwen3-8B, the size and complexity of the model are measured in "parameters" (e.g., 3 billion parameters, or 3B) 537. Parameters function as the sheer volume of a neural network's knowledge base, similar to the number of synaptic connections in a human brain or the number of highly detailed reference books in a library. A model with more parameters possesses a deeper understanding of language nuance, coding logic, and contextual reasoning.
The technological leap realized in 2026 is that hardware developers can now compress and fit 3B-parameter models into the limited memory of a pocket-sized device through a process called quantization. By reducing the precision of the model's weights from standard 16-bit or 32-bit floating-point numbers down to 4-bit (INT4) representations, the memory footprint of a 3B model drops to roughly 1GB to 2GB 589. This allows the intelligence to reside entirely within the phone's physical RAM array.
TOPS (Trillions of Operations Per Second)
If parameters dictate how intelligent the AI model is, TOPS serves as the speed limit or the horsepower rating of the NPU. It measures exactly how many trillions of mathematical operations the hardware can execute in a single second. A higher TOPS rating translates directly to faster image generation, quicker text summarization, and smoother real-time video translation 104. While early on-device AI processors hovered around 35 to 40 TOPS, the 2026 generation of flagship processors routinely pushes past 100 TOPS, fundamentally changing the responsiveness of the user interface 210.
Privacy and Safety: The Local vs. Cloud AI Paradigm
A persistent misconception regarding smartphone artificial intelligence is that utilizing smart assistants inherently compromises personal privacy, operating under the assumption that all voice recordings, photos, and text prompts are uploaded to remote corporate servers for processing. The 2026 local AI paradigm actively dismantles this concern, creating a distinct dichotomy between cloud compute and edge (local) compute.
Cloud AI relies on transmitting user data to massive data centers, introducing network latency and potential security vulnerabilities in transit or storage. Conversely, local AI downloads the neural network weights directly to the device's silicon. With features like Android 17's Gemini Intelligence and Apple's iOS 26 FoundationModels framework, user requests are processed exclusively within the device's hardware sandbox 513. Because the Large Language Model (LLM) operates locally, an application can analyze a user's private financial messages, summarize local health data, or categorize family photos without that data ever interacting with a network interface 51314.
Both Apple and Google have instituted strict software boundaries to enforce this privacy. Apple's iOS 26 utilizes a privacy-first design where user data stays on the device unless explicitly routed through highly encrypted Private Cloud Compute nodes for tasks too heavy for the local chip 13. Furthermore, developers utilizing the new Swift APIs can tap into the SystemLanguageModel to offer rich generative features without absorbing cloud inference costs or risking user data exposure 1314. Similarly, Google's Android 17 incorporates AI-powered Scam Detection that analyzes call audio entirely on-device, explicitly ensuring that voice data never leaves the phone while still instantly alerting users to fraudulent behavior via haptic and visual cues 6.
The Ecosystem Shift: FAQ-Worthy Inquiries
As consumers and enterprise users navigate the transition to AI-first operating systems, several critical inquiries arise regarding device longevity, operational safety, and minimum hardware requirements.
Will On-Device AI Drain the Battery?
Historically, intensive computational tasks have been synonymous with severe battery degradation. However, the architectural shifts in 2026 silicon specifically address this bottleneck. Flagship processors, such as the Qualcomm Snapdragon 8 Elite Gen 5 and the Apple A19 Pro, are manufactured on cutting-edge 3-nanometer (and upcoming 2-nanometer) process nodes by the Taiwan Semiconductor Manufacturing Company (TSMC) 16718. This extreme transistor density drastically reduces the power required to move electrons.
Furthermore, offloading tasks to the highly specialized NPU consumes significantly less energy than engaging the primary CPU or keeping the 5G modem active to transmit data to the cloud. Google's LiteRT framework (formerly TensorFlow Lite) demonstrates that utilizing NPU and GPU acceleration for local inference can speed up models by up to 25x while reducing power consumption by 5x compared to standard CPU execution 4. Qualcomm's architecture further mitigates battery drain by introducing Adreno High-Performance Memory (HPM), which embeds 18MB of localized cache directly on the chip, boosting memory bandwidth by 38% and heavily reducing the power consumption associated with fetching data from the main system RAM 12. Therefore, while continuous local AI utilizes power, the dedicated hardware renders the battery impact highly manageable.
Is Local AI Safe and Reliable?
Safety in the AI era encompasses both data security and the reliability of the generated output. From a security standpoint, localized processing is inherently safer than cloud processing because the attack surface is reduced to the physical device and its encrypted storage 513. Operating systems now strictly sandbox AI runtimes, preventing malicious applications from accessing the context windows of other apps. From a reliability perspective, developers are utilizing heavily refined, quantized models that have been rigorously tested to prevent hallucinations. Google evaluates its ML Kit GenAI APIs through a robust pipeline of LLM-based raters, statistical metrics, and human reviewers to ensure consistent, safe outputs across different device manufacturers 8.
Why Do I Need a Flagship Phone for These Features?
The most controversial aspect of the 2026 AI rollout is the stringent hardware gatekeeping. Google's official developer documentation for Android 17 explicitly limits the full Gemini Intelligence experience - including features like Rambler, Create My Widget, Pause Point, and intelligent Autofill - to devices possessing a minimum of 12GB of RAM, a flagship-tier processor, and native API support for the Gemini Nano v3 model 2021910.
Running an LLM requires massive amounts of immediate, high-speed memory. If a 3-billion-parameter model takes up roughly 3GB of RAM just to sit idle, and processing a long context window requires an additional large memory buffer (the KV cache), a standard 8GB phone would rapidly experience severe memory bottlenecks. This forces the operating system to forcefully shut down background applications to keep the AI running, resulting in a poor user experience. Consequently, devices that lack 12GB of RAM or specific NPU throughput - including high-profile recent releases like the standard Google Pixel 9 series, the Samsung Galaxy S25, and even the premium Samsung Galaxy Z Fold 7 - are locked out of the full Gemini Intelligence suite, restricted to the older Gemini Nano v2 API 91112. The flagship requirement is not an arbitrary marketing tier; it is a hard physical limitation defined by silicon memory architectures.
The 2026 Flagship Landscape: Apple, Google, and Qualcomm
The 2026 semiconductor market is defined by three distinct engineering philosophies regarding silicon design, instruction sets, and artificial intelligence integration. The performance metrics of these chips dictate the capabilities of the entire mobile ecosystem.
Apple: The A19 Pro and the FoundationModels Framework
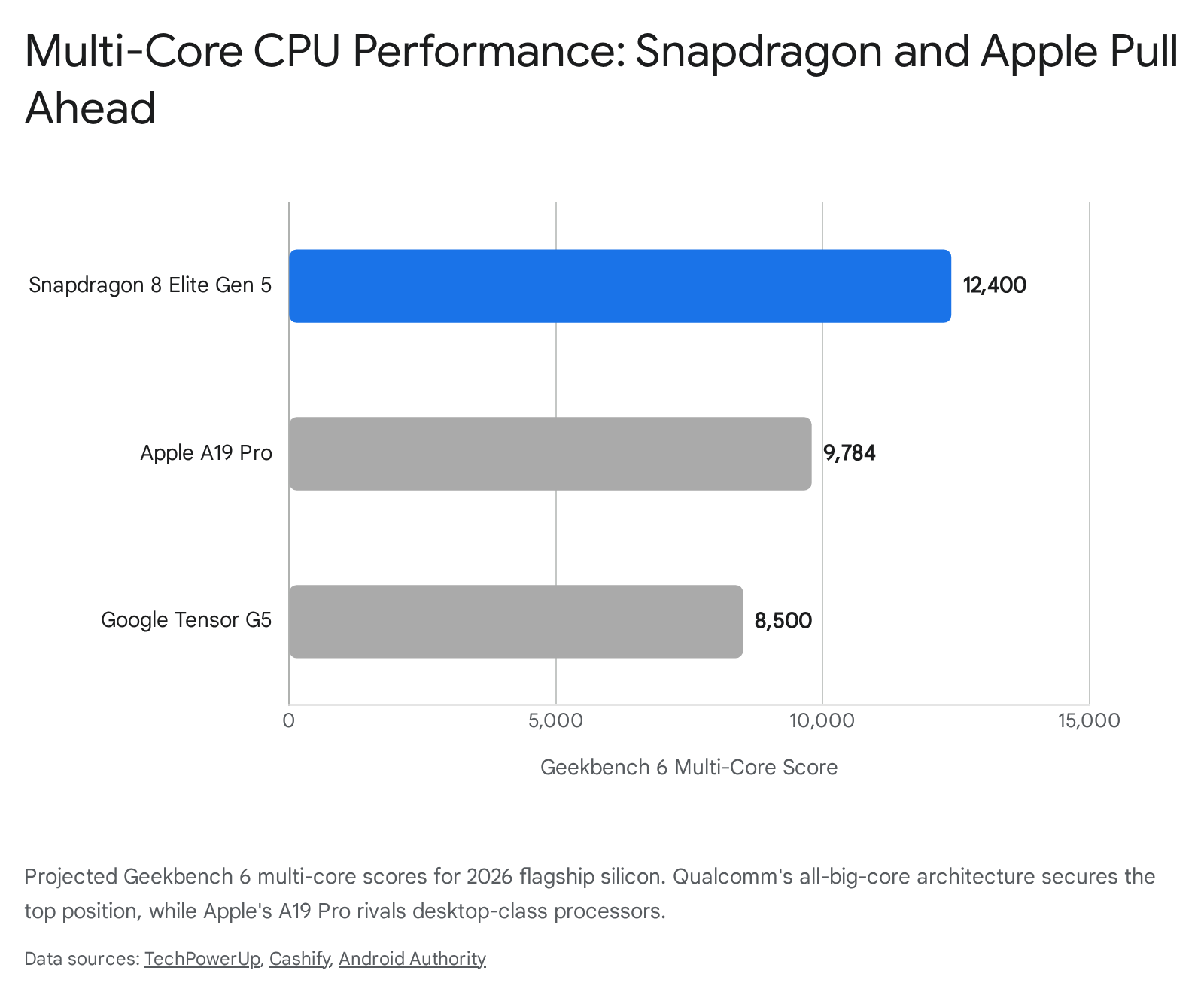
Powering the iPhone 17 Pro, the iPhone 17 Pro Max, and the ultra-thin iPhone Air, the A19 Pro represents Apple's refinement of the TSMC 3-nanometer process 2627. The chip features a 6-core CPU architecture comprising two high-performance "Avalanche" cores reaching clock speeds of 4.26 GHz, paired with four "Blizzard" efficiency cores 26. Early Geekbench 6 benchmarks indicate the A19 Pro shatters the 10,000-point barrier, achieving an estimated 9,784 to 10,300 in multi-core performance, rivaling desktop-class M2 chips from previous generations 262829.
Where the A19 Pro distinguishes itself is its neural architecture. The 16-core Neural Engine is estimated to exceed 40 TOPS, specifically optimized for transformer models 1013. In a significant architectural shift, Apple integrated neural accelerators directly into the 6-core GPU, functioning similarly to tensor cores for rapid matrix multiplication 326. In conjunction with a baseline of 12GB of RAM - a substantial increase intended to satisfy Apple Intelligence demands without utilizing swap memory - developers leveraging the iOS 26 FoundationModels Swift API can execute complex local AI tasks natively 131415. Independent developer benchmarks using Apple's MLX framework on the A19 Pro demonstrate the chip generating up to 70 tokens per second on quantized 1.2B models (like LFM2.5 1.2B at 4-bit) on the iPhone 17 Pro, and up to 124 tokens per second on the M5 iPad Pro, bringing desktop-tier inference speeds to mobile devices 833.
Looking ahead to the next cycle, Apple has secured TSMC's cutting-edge 2-nanometer (N2) node for the A20 Pro chip, slated for the iPhone 18 lineup in late 2026. This process incorporates Wafer-Level Multi-Chip Module (WMCM) technology, integrating RAM directly onto the wafer alongside the CPU, GPU, and Neural Engine to further eliminate latency bottlenecks and improve power efficiency by an estimated 30% 181434.
Google: The Tensor G5 (Laguna)
With the Tensor G5 (codenamed Laguna), Google enacted a massive strategic shift by abandoning Samsung Foundry in favor of TSMC's 3-nanometer N3E node 3516. Powering the Pixel 10 series, the G5 utilizes a 1+5+2 CPU cluster: a single high-performance Arm Cortex-X4 core running at 3.78 GHz, five Cortex-A725 mid-cores running at 3.05 GHz, and two efficiency Cortex-A520 cores at 2.25 GHz 1738.
Interestingly, Google departed from traditional Arm Mali graphics, opting for an Imagination Technologies DXT-48-1536 GPU running at 1.1 GHz 35. While this unusual GPU configuration limits raw gaming performance and lacks hardware ray tracing compared to Apple and Qualcomm 3818, Google's engineering focus remains squarely on the Tensor Processing Unit (TPU). The G5's 4th generation TPU is custom-tailored to run Gemini Nano v3 locally, delivering a 60% increase in AI processing power over the G4 and running on-device models up to 2.6x faster and twice as efficiently 81718. Google's internal testing via the ML Kit GenAI APIs demonstrates the Pixel 10 Pro achieving prefix processing speeds of 610 to 940 tokens per second for Gemini Nano, allowing near-instantaneous contextual understanding of prompts and images 8. The Tensor G5 represents an ecosystem play; it may trail in brute-force synthetic CPU benchmarks, but it natively accelerates Google's proprietary agentic OS features flawlessly.
Qualcomm: The Snapdragon 8 Elite Gen 5
Qualcomm's Snapdragon 8 Elite Gen 5 is the dominant force powering the premium Android ecosystem in 2026, utilized by Samsung, Xiaomi, Honor, Oppo, and Vivo 219. Fabricated on TSMC's advanced N3P node, the chip features the third generation of Qualcomm's custom Oryon CPU cores aligned with the Arm v9 instruction set 220. Embracing an aggressive "all-big-core" philosophy, Qualcomm abandons low-power efficiency cores entirely, utilizing two Prime cores clocked at a staggering 4.6 GHz and six Performance cores at 3.62 GHz 120.
The AI capabilities of the Elite Gen 5 set the industry benchmark. The Hexagon NPU features a fused AI accelerator architecture (12 scalar, 8 vector) that boasts a 37% throughput increase over the previous generation, with native support for mixed-precision INT2 and FP8 formats 14321. During developer showcases, the Snapdragon 8 Elite Gen 5 was recorded processing the Llama 3.2 3B parameter model at an astonishing 220 tokens per second - a 10x increase over previous generation norms 321.
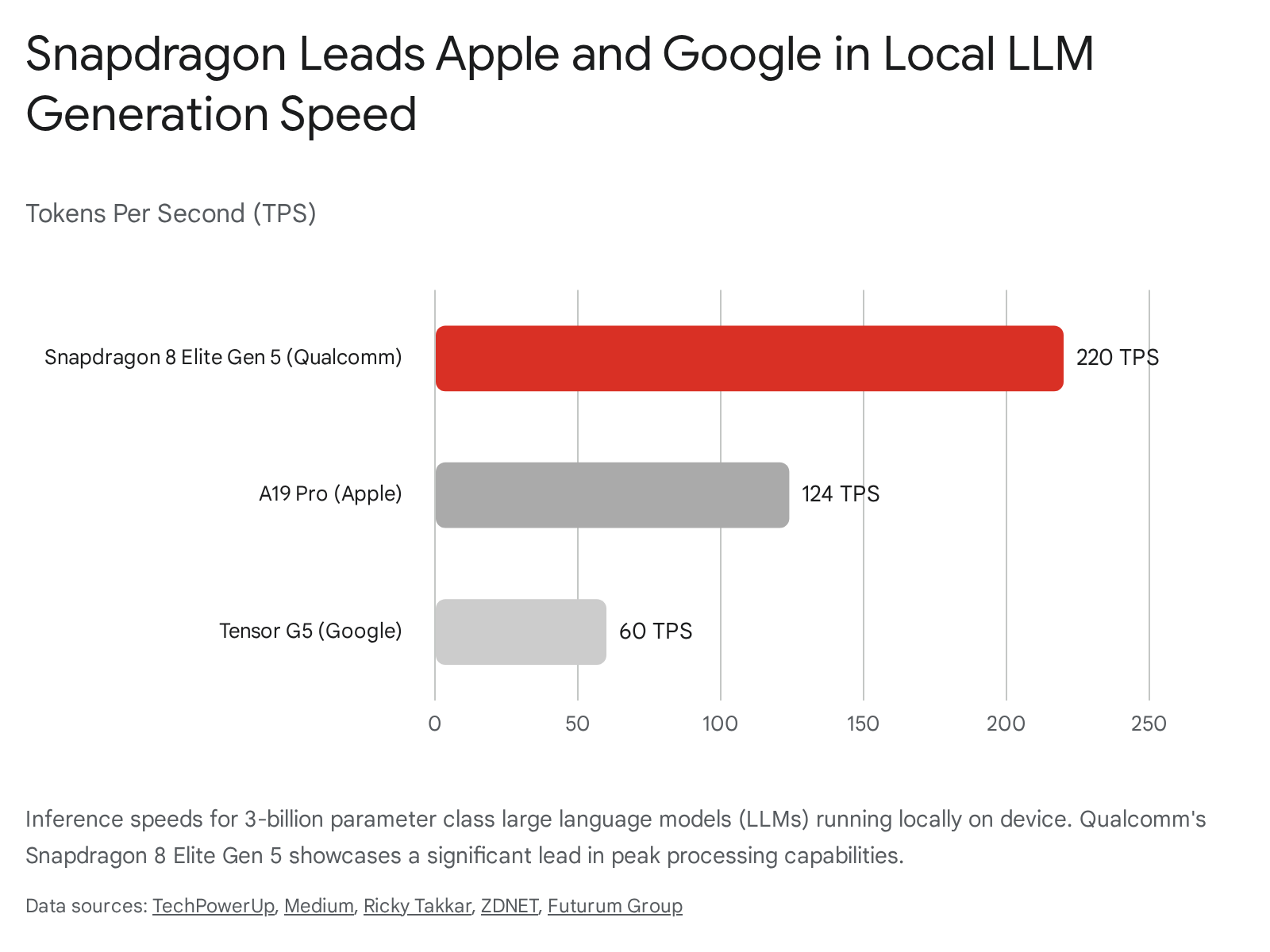
Furthermore, Qualcomm introduced Adreno High Performance Memory (18MB of dedicated cache) that feeds the GPU and NPU, increasing memory bandwidth by 38% and drastically reducing power consumption during prolonged AI and gaming workloads 221. This architecture allows the chip to dominate synthetic benchmarks, achieving AnTuTu V11 scores exceeding 3.7 million and Geekbench 6 multi-core scores around 12,400 224623.
To contextualize the hardware divergences, the following comparison table illustrates the specifications of the three primary flagship offerings dictating the 2026 market.
| Manufacturer | Flagship Processor | Fabrication Node | CPU Architecture | Peak Clock Speed | NPU / TPU Architecture | Primary Local AI Models Supported |
|---|---|---|---|---|---|---|
| Apple | A19 Pro | TSMC 3nm | 6-Core (2 Avalanche + 4 Blizzard) | 4.26 GHz | 16-Core Neural Engine (~40+ TOPS) | Apple FoundationModels, CoreML |
| Tensor G5 (Laguna) | TSMC 3nm (N3E) | 8-Core (1 Cortex-X4 + 5 A725 + 2 A520) | 3.78 GHz | 4th Gen Tensor Processing Unit | Gemini Nano v3 | |
| Qualcomm | Snapdragon 8 Elite Gen 5 | TSMC 3nm (N3P) | 8-Core (2 Prime + 6 Performance) | 4.60 GHz | Hexagon NPU (12 Scalar, 8 Vector) | Llama 3.2 3B, Qwen3-8B |
Data compiled from verified supplier documentation, official hardware specifications, and cross-platform benchmark databases 129261723.
The Operating System Software Layer: Android 17 Cinnamon Bun
Hardware is rendered useless without operating systems capable of leveraging it. Google's Android 17, internally codenamed "Cinnamon Bun," serves as the software bridge bringing these hardware capabilities to consumers 524. Expected to achieve stable release by June or July 2026, Android 17 introduces profound shifts in how the operating system interacts with applications and user intent 5.
Android 17 mandates screen adaptability across all applications (excluding intensive games), forcing developers to support dynamic resizing across phones, foldables, and tablets 49. This sets the foundation for a deeply refined Desktop Mode, featuring advanced window snapping and multitasking bubbles that allow users to minimize and stack multiple floating applications simultaneously 5. The integration of the ML Kit GenAI API ensures that developers can easily tap into Gemini Nano v3 for summarization, proofreading, and rewriting tools directly within their codebases, standardizing the AI experience regardless of the host application 58.
Geographically Diverse Implementation in Major Asian Manufacturers
While Google and Apple define the baseline ecosystem requirements for their respective operating systems, the true hardware scaling and regional customization of on-device AI are executed by major Asian smartphone manufacturers. By adopting the Snapdragon 8 Elite Gen 5, these hardware giants introduce hyper-specialized AI features tailored to regional user bases and specific use cases.
Samsung: System-Wide Integration and The Privacy Display
Samsung has aggressively positioned itself as the dominant force in the AI smartphone sector. The company aims to integrate Galaxy AI features into a staggering 800 million devices globally by the end of 2026 50. Samsung operates under an "AI OS" philosophy, utilizing a contextual engine where personal data is processed locally on the handset, while complex reasoning can be offloaded to the cloud seamlessly 25.
The Samsung Galaxy S26 Ultra represents the pinnacle of this strategy. Beyond standard generative text tools, the S26 Ultra implements Real-time Camera Translation, utilizing the Snapdragon NPU to overlay language translations directly onto the live camera viewfinder, maintaining font and style consistency without cloud latency 26. Universal Screen Translation expands upon this, allowing users to leverage the S Pen to circle and instantly translate text across any third-party application, removing the friction of copying and pasting text into a dedicated translation app 26.
In a major hardware and software synergy, Samsung introduced the Privacy Display, a security feature exclusive to the S26 Ultra that utilizes AI to dynamically restrict the viewing angle of the 6.9-inch OLED screen, preventing visual hacking from bystanders 252728. Coupled with a massive 200-megapixel primary sensor with an F1.4 aperture, and the Advanced Professional Video (APV) codec processing - which allows for near-lossless real-time semantic segmentation during video recording - the Galaxy S26 Ultra leverages AI at every stage of the hardware pipeline 272930.
Xiaomi: Aggressive Hardware Scaling
Xiaomi's strategy relies on brute-force hardware scaling to outpace competitors. The Xiaomi 17 and 17 Ultra, running early developer builds of Android 17 integrated into their proprietary HyperOS 4 framework, were among the first devices globally to debut the Snapdragon 8 Elite Gen 5 221.
To support the massive, sustained power draw required by continuous local LLM inferencing and advanced gaming (such as running native hardware-accelerated ray tracing and mesh shading on the Adreno 840 GPU), Xiaomi equips the 17 Ultra with a colossal 6,000 mAh battery and 90W rapid charging 2057. This aggressive power architecture allows Xiaomi to sustain peak NPU performance without thermal throttling, delivering uncompromising speeds for local inference tasks. Paired with massive 1-inch 50-megapixel main camera sensors co-developed with Leica, the localized AI applies complex noise reduction and computational photography algorithms directly on the Image Signal Processor (ISP) without pausing for prolonged rendering times 5731.
Oppo and Vivo: Photographic Synergy and BBK Engineering
Operating under the massive BBK Electronics umbrella, both Oppo and Vivo integrate local AI heavily into their photographic and video pipelines. The Oppo Find X9 Ultra and the Vivo X300 series meet the strict hardware requirements for Android 17's Gemini Intelligence, combining 12GB+ of RAM with the Snapdragon 8 Elite Gen 5 912.
Oppo's implementation in the Find X9 Ultra (running ColorOS 17) utilizes the Hexagon NPU to manage its unique dual periscope zoom lenses seamlessly 2159. The local AI interprets complex depth-of-field calculations and edge detection in real-time for video portraits, ensuring stable foreground matting even in extreme low-light scenarios. By shifting the processing of complex lighting and semantic image segmentation entirely to the NPU rather than the CPU, Oppo maintains 4K 120fps video recording with persistent AI enhancements running frame-by-frame - a computational feat unachievable on previous-generation silicon 433059. Vivo follows a similar trajectory, utilizing the Snapdragon NPU to enhance its proprietary imaging chips, bringing professional-grade color grading and noise reduction to mobile video formats.
Bottom Line
The 2026 smartphone computing landscape marks a definitive and permanent departure from cloud-dependent processing, ushering in an era where advanced artificial intelligence lives entirely within the physical silicon of the device. Driven by the massive computational leaps of the Qualcomm Snapdragon 8 Elite Gen 5, Apple's A19 Pro, and Google's Tensor G5, smartphones now possess the vast RAM and extreme NPU throughput required to run multi-billion-parameter LLMs locally at blistering speeds. While the strict 12GB RAM requirements for features like Android 17's Gemini Intelligence force a necessary hardware upgrade cycle that leaves older devices behind, the transition mathematically guarantees unprecedented data privacy, zero-latency execution, and continuous offline functionality. Led by the foundational software frameworks of iOS 26 and Android 17, and accelerated by the massive manufacturing scale of companies like Samsung, Xiaomi, and Oppo, on-device AI is no longer a premium gimmick; it is the fundamental operating system layer that defines modern mobile computing.