How to Spot a Slow Failure Before a Sudden Collapse
Systems rarely fail overnight; they usually degrade slowly before hitting a sudden, catastrophic breaking point. By tracking early warning signals - such as delayed recovery from minor disruptions, an increasing reliance on temporary workarounds, and the gradual normalization of broken rules - analysts can spot hidden signs of decay. Recognizing these leading indicators allows organizations to intervene and rebuild structural resilience long before a slow decline accelerates into a sudden collapse.
When a suspension bridge collapses, a massive multinational corporation declares bankruptcy, or a global internet outage grounds flights worldwide, the public reaction is almost universally one of shock. The event feels instantaneous and unpredictable. However, to the engineers, forensic accountants, and network architects who sift through the digital or physical rubble, the story is entirely different. Post-mortem analyses almost invariably reveal that the system had been failing in slow motion for months, years, or even decades. The final breaking point was merely the moment the system exhausted its hidden, dwindling reserves of resilience.
Whether the subject is a global supply chain, a municipal water grid, a small business, or an individual's personal health, the mechanics of failure are remarkably consistent across domains. Systems send out distress signals long before they snap. The core challenge is that human beings and traditional management structures are neurologically and operationally wired to ignore these signals, frequently mistaking a lack of immediate catastrophe for proof of ongoing stability.
This report explores the underlying science of systemic decay, the psychological traps that blind operators to danger, and the concrete, evidence-based methodologies experts use to diagnose a failing system before the damage becomes irreversible.
The Physics of Collapse: Critical Slowing Down
To understand how complex systems fail, it is useful to look to the natural sciences. Ecologists, climate scientists, and physicists have spent decades studying "tipping points" - the exact thresholds at which a system reorganizes and irrevocably shifts from one stable state to another 12. What researchers have discovered across disparate domains is a universal phenomenon known as "critical slowing down" (CSD).
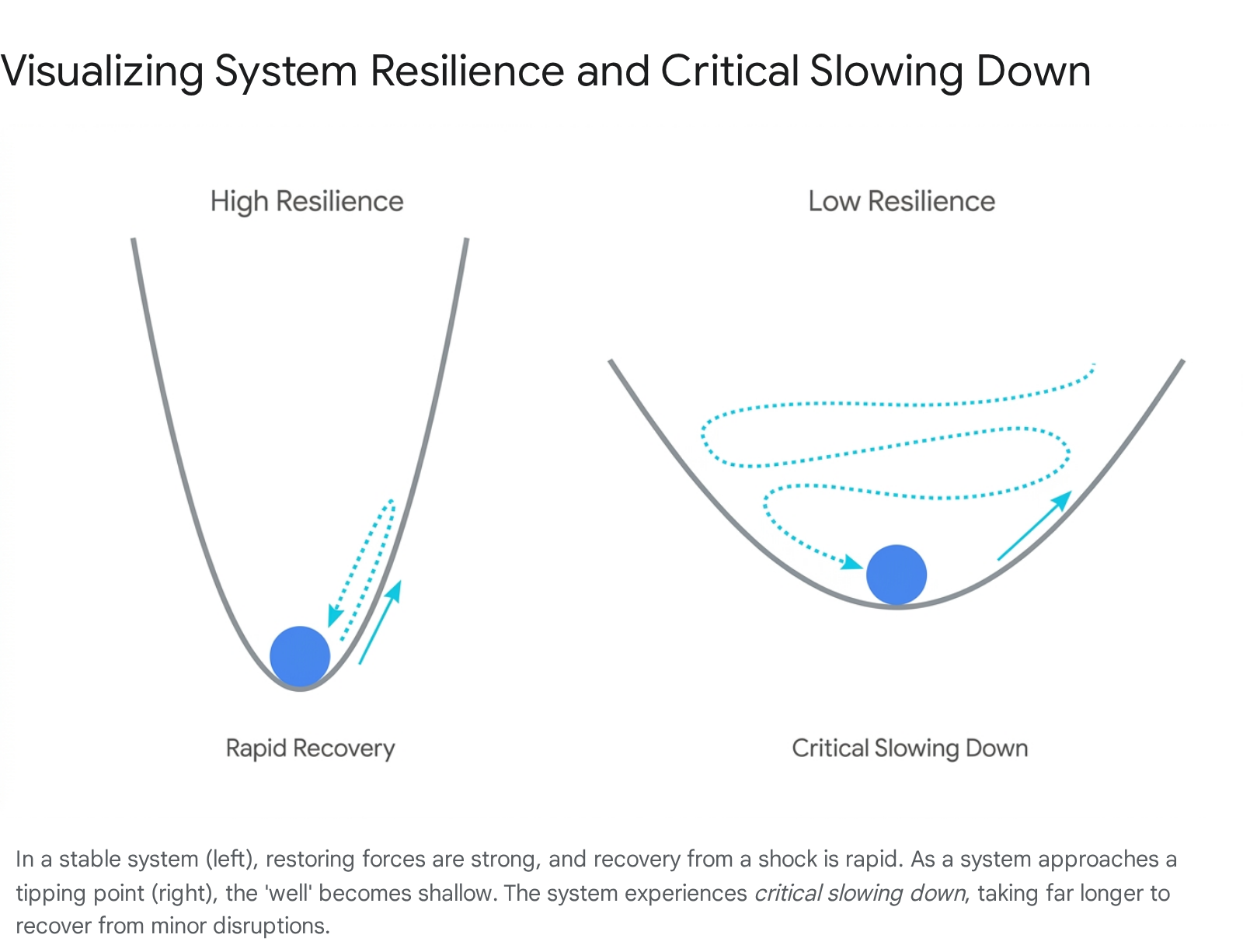
The "Ball in the Well" Analogy
As a system is pushed toward a breaking point by internal strain or external forcing, the restoring feedback loops that keep it stable begin to degrade and weaken 3. The system loses its natural elasticity. Scientists visualize this concept mathematically using the classic "ball in a potential well" analogy, first articulated in the dynamics literature in the 1980s 13.
Imagine a ball resting at the bottom of a steep, deep bowl. If a physical shock taps the ball, it rolls up the side slightly but quickly rushes back to the center. The steep sides represent strong restoring feedbacks; the system is highly stable, and its recovery from perturbations is rapid 14. Now, imagine a ball resting in a very shallow, wide basin. If a shock hits this ball, it still eventually settles in the center, but its recovery is incredibly sluggish. Because the sides of the basin are shallow, the system's restoring feedbacks are weak 14.
When any system approaches a critical tipping point, its metaphorical "bowl" becomes shallower. It takes longer and longer to recover from everyday shocks 3. Eventually, the restoring forces become so weak that the basin flattens out entirely. At this critical threshold, a completely random, minor disturbance - a gust of wind, a routine software configuration update, a single missed debt payment - can push the ball out of its initial state and into a new, often degraded, alternative state 1.
Mathematical Fingerprints: Variance and Autocorrelation
In real-world data, critical slowing down leaves distinct mathematical fingerprints that analysts can measure long before a transition occurs. The two most prominent signals are increased variance and increased autocorrelation 4.
As a system loses its ability to self-correct rapidly, its behavior becomes more erratic. This phenomenon, sometimes referred to as "flickering" or "wobbling," shows up in datasets as higher variance 5. Simultaneously, because the system is responding so sluggishly, its state tomorrow begins to look almost exactly like its state today. The system becomes highly correlated with its own immediate past, a metric scientists calculate as "lag-1 autocorrelation" or AR(1) 35. Mathematically, this occurs as the leading eigenvalue of the dynamical system approaches zero, indicating an infinitely slow recovery time from perturbations 34.
These physics concepts map perfectly onto everyday observations. If a healthy person catches a minor cold, their robust immune system clears the virus, and they bounce back in three days. If an elderly person with a compromised immune system catches the exact same cold, it might linger for weeks, developing into pneumonia. The biological "restoring feedbacks" have weakened, and the recovery time has critically slowed down.
The Psychology of Decay: Normalization of Deviance
While physical systems succumb to gravity, friction, and entropy, human-built systems - such as corporations, infrastructure networks, and operational workflows - are eroded by psychology. One of the most dangerous and insidious psychological forces driving systemic failure is the "normalization of deviance."
Coined by Columbia University sociologist Diane Vaughan during her investigation into the catastrophic 1986 Space Shuttle Challenger disaster, the normalization of deviance occurs when people within an organization become so accustomed to a dangerous or broken practice that they no longer consider it deviant 576. Despite the fact that these practices often far exceed the organization's own established rules for elementary safety or operational standards, they become invisible to the people inside the system 5.
The Gradual Shift of Acceptable Risk
Normalization of deviance is particularly dangerous because it relies on the absence of immediate failure to validate poor decision-making. If a construction worker skips wearing a safety harness to save time and does not fall, the human brain registers the shortcut as a success 9. If a manager demands that an engineering team push a software update without running full diagnostic tests and the servers do not crash, the skipped test becomes a standard operating procedure. Over time, what was once considered a terrifying violation of safety protocols gradually becomes "just the way we do things" 7.
This phenomenon happens across all scales of human activity: * Personal Life: Choosing not to wear a seatbelt for a short drive, ignoring a squealing car brake, relying heavily on auto-correct instead of proofreading, or skipping software backups because "nothing bad has happened yet" 57. * Corporate Ethics: The Wells Fargo banking scandal serves as a prime corporate example. Extreme management pressure to meet unrealistic sales quotas led employees to create millions of fake accounts. The behavior started small, became a pervasive cultural norm, and was justified by employees because everyone else was doing it and management rewarded the output 9. * Heavy Industry: Refineries operating slightly outside of design limits to boost yield, ignoring critical maintenance schedules to save budget, or viewing safety standards as bureaucratic "overkill" because they slow down production schedules 6.
Normalization of deviance acts as a slow poison to systemic integrity. It strips away a system's safety margins layer by layer. The time lag between the start of the deviant behavior and the inevitable consequences can be immense, but the erosion guarantees that when a critical shock finally does arrive, the system will have absolutely no buffer left to absorb it 6.
Diagnosing Organizational Rot and Capacity Failure
In the business world, sudden bankruptcies and massive operational failures are rarely truly sudden. They are preceded by long, quiet periods of organizational decay. Consultants and enterprise auditors look for specific, hidden symptoms that indicate a company's internal architecture is hollowing out.
The "ROT" Framework: Retention, Opportunities, and Training
When an organization is stretched beyond its capacity, often during periods of aggressive growth, it begins to experience what industry experts call "ROT" - systemic challenges surrounding Retention, Opportunities, and Training 7.
When a company grows too fast without properly scaling its workforce or upgrading its operational workflows, the existing team is forced to shoulder an unsustainable burden. Leadership begins relying on their absolute best employees to provide "temporary solutions" that quietly become permanent structural fixtures 7. As a result, the flexibility of when and how people work dwindles. This prolonged stress leads to plummeting retention rates, which only serves to shift even more burden onto the remaining survivors 7.
To cope with the immediate, overwhelming workload, the organization then slashes its training budgets and professional development time. The prevailing rationale is that the company cannot afford to pull people off the production line to learn new skills 7. This lack of training inevitably leads to increased errors, repetitious rework, and inefficiency, which further drags down overall capacity 7. Finally, the organization becomes so heads-down in survival mode that it begins missing golden strategic opportunities right in front of it, stunting long-term viability 7.
"Shadow Workflows" and Relational Disconnection
Another primary symptom of impending failure is the rise of recurring problems across multiple, historically siloed departments 11. When a system is breaking, leaders often misdiagnose the issue. They look at financial statements and conclude the company is spending too much, needs to fire its marketing agency, or requires a tighter budget 12.
However, deep-rooted failures are rarely purely functional; they are deeply relational. When leadership adopts a purely transactional, results-focused style, it breeds resentment and disconnects teams. Employees begin to feel like replaceable cogs rather than members of a cohesive whole 12. A McKinsey report highlighted this dynamic, noting that 70 percent of organizational transformations fail not due to technical flaws, but due to human resistance and relational breakdown 12. This lack of downward connection leads to miscommunication, duplicated efforts, and a profound organizational apathy 11.
To get around broken, misaligned corporate systems, employees will often invent "shadow workflows." They will abandon official software and approved processes to get their jobs done via private spreadsheets, direct messaging apps, and unofficial workarounds 13.
If an auditor examines a workflow and finds high "rework rates" (tasks constantly looping back for clarification because requirements were missing) or high "shadow process" usage, the official system is already failing 13. Another critical metric is the "Touch-to-Wait Time Ratio," which compares the actual time spent actively working on a task against the time it sits idle in a queue waiting for managerial approval. High wait times indicate a brittle, bottlenecked system 13.
The Illusion of Stability: The Chinese Real Estate Crisis
Sometimes, a system's slow failure is masked by massive, unsustainable growth. The most striking macroeconomic example in recent history is the collapse of the Chinese property development giants Evergrande and Country Garden.
For decades, these massive conglomerates operated on a debt-fueled model, racking up astronomical liabilities to fund continuous, rapid expansion across Asia. Evergrande's debt eventually exceeded its annual revenue tenfold, reaching roughly $300 billion, or 1.8 percent of China's total GDP 8. These companies were broadly deemed "too big to fail" by global investors, who assumed the Chinese government would always step in to provide a safety net and repay liabilities if returns faltered 9.
The slow, systemic failure was masked by rapid construction, soaring equity prices, and complex financial instruments. But underneath, the physical and financial assets were degrading. Country Garden, for instance, built a $100 billion mega-project in Malaysia known as "Forest City," designed for 700,000 residents; nearly a decade later, only 9,000 people actually lived there 916. The system was incredibly brittle, entirely dependent on non-stop access to cheap credit to pay off old debts and fund new, underutilized projects.
The Trigger and the Collapse
When Chinese regulators finally stepped in to enforce financial discipline in 2020 via the "three red lines" policy, the credit lifeline was instantly severed 816. The policy strictly capped debt-to-asset ratios at 70%, net debt-to-equity ratios at 100%, and demanded a cash-to-short-term debt ratio of at least 1 16.
Evergrande failed to meet any of the three criteria. The sudden collapse of these companies, resulting in a staggering $94 billion loss for Evergrande in 2021 and a $24.3 billion loss for Country Garden in 2023, was merely the lagging indicator of an economic system that had been fundamentally broken for years 810. Furthermore, the collapse exposed severe failures in systemic oversight; in late 2024, Chinese regulators imposed a massive 441 million yuan ($62 million) fine on PwC Zhong Tian and suspended their operations for failing to detect or report the massive financial irregularities that preceded Evergrande's fall 16.
The Brittleness of Modern Infrastructure
The physical and digital infrastructure that powers the global economy is experiencing its own version of critical slowing down. Decades of deferred maintenance, combined with the corporate pursuit of hyper-efficiency, have removed the essential slack from these networks.
The Concrete Deficit
Physical infrastructure in many developed nations is trapped in a vicious cycle of reactive maintenance.
| Infrastructure Category | 2025 ASCE Report Card Grade | Identified Systemic Failures and Funding Gaps |
|---|---|---|
| Aviation | D+ | Flight demand has grown 4x since 1976; airports are severely capacity-constrained. 11 |
| Roads & Highways | D | A projected $684 billion funding gap by 2035. Potholes alone cost US motorists $26 billion annually. 1112 |
| Bridges | C | 6.8% of the national bridge inventory has structural defects. A $373 billion funding gap exists for the next decade. 11 |
| Drinking Water | C- | Delayed investments in new treatments and water main replacements; severe vulnerability to PFAS contamination. 11 |
Instead of building durable, 100-year pavements, authorities patch potholes - a lagging symptom of underlying subgrade soil intrusion and surface fatigue 12. Similarly, when levees breach during catastrophic flooding events, post-disaster engineering audits frequently reveal that the structures failed before water levels reached their maximum design capacity. The slow deterioration of the concrete and earthworks - invisible to the naked eye and ignored in risk management models - had fatally compromised the system's ability to withstand the shock 13.
The Digital House of Cards
The digital realm is arguably even more fragile. In 2025, the world witnessed a series of cascading IT failures that exposed the extreme, precarious interdependency of modern technology infrastructure 21.
Major, multi-hour outages struck the world's largest hyperscalers, including Amazon Web Services (AWS), Microsoft Azure, and Cloudflare 1423. In October 2025, a faulty automated update to a core AWS service (DynamoDB) triggered cascading internal DNS failures in the US-EAST-1 region, taking down enterprise services like Slack and Atlassian for 15 hours and resulting in an estimated $581 million in economic damage 2324. In November and December, Cloudflare suffered multiple outages due to latent software bugs and routine configuration changes, briefly knocking major swaths of the internet offline, including Spotify, Canva, and ChatGPT 1425.
Crucially, these were not sophisticated cyberattacks orchestrated by hostile nation-states. They were minor, routine errors that cascaded into global catastrophes 23. The digital ecosystem has become so tightly coupled, and so heavily concentrated on a handful of single-vendor cloud providers, that it has lost its modular resilience. A single point of failure in a digital middleware layer now possesses a blast radius that spans the globe 2123.
The Dashboard for Survival: Leading vs. Lagging Indicators
If slow failure is largely invisible to the naked eye, how can leaders and individuals detect it? The key is shifting analytical attention away from lagging indicators and toward leading indicators.
- Lagging Indicators measure outcomes that have already occurred. They confirm results after decisions have played out. While they are concrete, easy to measure, and highly accurate, they are fundamentally "old news." By the time a lagging indicator turns negative, the opportunity to influence the outcome has passed, and the damage is already done 2627.
- Leading Indicators measure the inputs and activities that predict future conditions. They do not guarantee outcomes, but they provide early insight into momentum, friction, and risk. They are harder to define, require discipline to track, and their interpretation can feel uncertain, but they offer the crucial gift of foresight 2627.
Most human systems fail because leadership is exclusively managing the enterprise via lagging indicators (like quarterly revenue, stock price, or total traffic) while completely ignoring the leading indicators (like employee burnout, shadow IT usage, or software error rates) 1529.
Tracking Decay Across Domains
The necessity of tracking leading indicators applies across all disciplines.
| Domain | What You Are Trying to Prevent | The Lagging Indicator (Too Late) | The Leading Indicator (Early Warning) |
|---|---|---|---|
| Personal Health | Chronic illness, extreme weight gain, burnout | High body fat percentage, disease diagnosis, exhaustion 3031 | Daily caloric intake, hours of sleep, exercise frequency, protein tracking 3031 |
| Corporate Finance | Bankruptcy, severe insolvency | Annual net loss, high debt default rate, depleted bank accounts 2632 | Sales pipeline volume, quote-to-close ratio, 90-day cash flow projections 26 |
| Industrial Safety | Workplace injuries, fatalities, regulatory fines | Total number of accidents on a job site 33 | Percentage of workers actively wearing protective gear, completion of safety walks 533 |
| Software / IT | Customer churn, catastrophic system outages | Drop in Monthly Recurring Revenue (MRR), total downtime hours 2315 | Touch-to-wait time ratio, AR(1) autocorrelation in server load, user engagement drops 1315 |
| Macroeconomics | National economic recession | High unemployment rate, persistent inflation (CPI) 34 | Drop in new building permits, inverted yield curves, declining consumer confidence 3435 |
(Note: There is also a third category known as "coincident indicators," which move in real-time with the economy or business, such as current industrial production output or daily retail sales, providing a snapshot of the exact present moment 273435.)
To survive in a complex environment, an organization must heavily monitor the windshield (leading indicators), using the rearview mirror (lagging indicators) strictly to validate past assumptions 2935.
Active Defense: Stress-Testing Systems Before They Snap
If you wait for a system to break to test its resilience, you have already lost. High-performing organizations actively stress-test their operational, digital, and human systems using three specific methodologies designed to root out hidden vulnerabilities.
1. The Pre-Mortem Methodology
A traditional post-mortem reflects on a failure after it happens. A pre-mortem, a technique championed by decision scientists and project managers, takes place before a project even begins or a new system is launched 16.
To run a pre-mortem, you gather your entire team - including core developers, cross-functional partners, and subject matter experts - and explicitly state: "Imagine it is one year from now. Our project has completely and utterly failed. What went wrong?" 163738.
By assuming failure as a guaranteed, unavoidable fact, you bypass the psychological barriers of groupthink and optimism bias. Team members are suddenly free to point out the hidden risks, capacity constraints, and relational brokenness that everyone intuitively knows about but no one wants to bring up for fear of sounding negative 3839. You then compile these failure scenarios, rank them by likelihood and impact, and build structural mitigations and contingency plans into the project before you ever launch 1640.
2. Red Teaming and Adversary Simulation
In cybersecurity and physical infrastructure defense, relying solely on your own IT team to spot vulnerabilities is dangerous; they suffer from the same normalization of deviance as the rest of the company. Instead, organizations use "Red Teaming" - hiring skilled external experts to actively simulate real-world, multi-layered attacks against their systems 42.
A Red Team does not just run an automated software scan. They act exactly like a malicious adversary. They use Open Source Intelligence (OSINT) to map the organization's structure from the outside, utilizing DNS enumeration, subdomain discovery, and even analyzing job postings to guess the company's tech stack 4243. They send targeted phishing emails to tired employees, drop malicious USB drives in the company parking lot, and attempt to socially engineer their way past physical security through "pretexting" or "tailgating" through a locked door behind a legitimate employee 43.
By chaining together small, seemingly insignificant vulnerabilities - an unpatched server here, a shared password there - they expose the exact pathway a catastrophic failure will eventually take, allowing the "Blue Team" (defenders) to patch the holes before a real crisis occurs 44.
3. Engineering Micro-Resilience and Workflow Audits
Small businesses and individuals can replicate the principles of Red Teaming through rigorous internal audits. By regularly reviewing financial controls, tracking "First-Pass Yield" (how often work is done right the first time without needing review), and actively hunting for undocumented "shadow processes," they ensure compliance before an external auditor or a financial crisis strikes 454647.
Finally, all systems are ultimately made of people, and human resilience is a finite resource. Instead of viewing resilience as a massive, heroic recovery from trauma, organizational psychologists now advocate for "micro-resilience" 1749.
These are tiny, strategic habits embedded into the daily workflow that prevent the accumulation of stress, effectively breaking the cycle of human critical slowing down. Examples include: * The 4-7-8 Breathing Reset: Taking 20 seconds between stressful meetings to inhale for 4 counts, hold for 7, and exhale for 8, activating the parasympathetic nervous system to reduce stress hormones 50. * Cognitive Reframing: Taking 15 seconds to reframe a workplace crisis from "This is overwhelming" to "This is exposing a flaw we can fix," shifting the brain from panic to problem-solving 4950. * The 30-Second Gratitude Pause: Interrupting negative thought spirals by identifying one positive daily aspect, training the brain to find bright spots and preventing long-term burnout from taking root 50.
While these micro-habits seem inconsequential on their own, they compound over time. They represent the internal "restoring feedbacks" of the human mind, keeping the individual resilient enough to maintain the systems they operate.
Bottom line
Systems do not collapse without warning; they loudly signal their impending failure through critical slowing down, a reliance on shadow workarounds, and the quiet normalization of broken rules. By shifting analytical focus from lagging historical outcomes to leading predictive indicators, organizations can diagnose structural rot and infrastructure fragility while there is still ample time to act. Ultimately, long-term survival requires the courage to actively stress-test your own systems through rigorous pre-mortems and audits, confronting uncomfortable vulnerabilities before reality does it for you.