How Nvidia Blackwell Affects AI Cloud Costs in Summer 2026
The release of Nvidia's Blackwell architecture has revolutionized AI capabilities, yet severe manufacturing bottlenecks in advanced packaging and memory have prevented cloud compute costs from falling. Consequently, major hyperscalers are aggressively rationing GPU access, forcing buyers to navigate a complex landscape of neo-cloud spot markets, strategic self-hosting, and hardware-agnostic infrastructure to survive the summer 2026 squeeze.
The Dawn of the Blackwell Era
The transition from the Hopper architecture (H100/H200) to the Blackwell generation (B200, GB200, and the newly released B300 Blackwell Ultra) represents the most significant shift in artificial intelligence infrastructure economics to date. For buyers evaluating infrastructure in summer 2026, understanding why this hardware commands a premium is essential for accurate capacity planning.
Breaking the Memory Wall
The defining characteristic of the Blackwell architecture is not merely raw compute speed, but memory capacity and bandwidth. Large language models (LLMs) and computer vision systems have historically been constrained by the "Memory Wall" - the physical limitation of moving data between the processor and the memory bank.
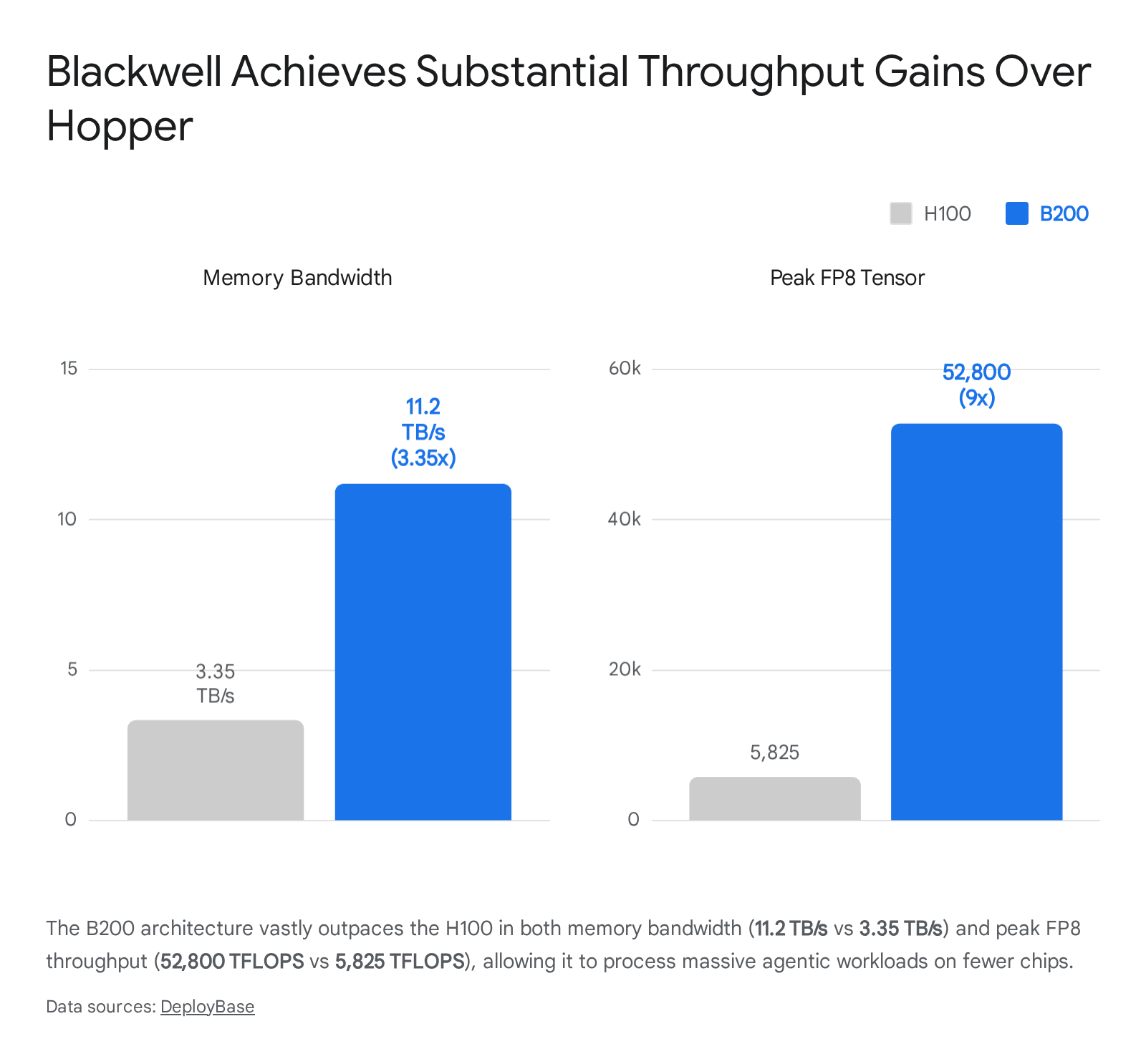
The original H100 was equipped with 80GB of High Bandwidth Memory (HBM3) running at 3.35 terabytes per second (TB/s) 123. While revolutionary in 2023, it forced developers to "shard" or split large models across multiple GPUs, introducing latency and increasing costs. The Blackwell B200 solves this by utilizing a dual-die design - binding two logic chips together with a high-speed interconnect - resulting in 208 billion transistors 45.
More importantly, the B200 is equipped with 192GB of HBM3e, delivering 11.2 TB/s of memory bandwidth 135.
By mid-2026, the B300 (Blackwell Ultra) began shipping in volume, offering 288GB of HBM3e across 12-high memory stacks, pushing memory bandwidth to a staggering 8 TB/s per chip 672. This allows a single HGX B300 node to host a 100-billion+ parameter model entirely within its GPU memory without having to swap weights to system RAM, dramatically reducing inference latency 6.
FP4 Quantization and Performance Multipliers
Beyond memory, Blackwell introduces a second-generation Transformer Engine featuring native FP4 (4-bit floating point) quantization support 27. This allows the hardware to dynamically adjust the precision of model weights, delivering massive throughput gains for inference tasks without significant accuracy loss 6.
In real-world benchmarking, the B200 delivers roughly 3 times the training performance and up to 15 times the inference performance of the H100 79. When testing computer vision workloads, a self-hosted 8x B200 cluster consistently trains models up to 57% faster than an equivalent H100 setup simply because the expanded memory allows developers to double the batch size 110.
The New Economics of Chip Manufacturing
Despite the performance gains, the Blackwell B200 is the most expensive merchant AI accelerator ever produced. The estimated Cost of Goods Sold (COGS) for a B200 is approximately $6,400, nearly double the H100's $3,320 312.
This pricing reveals a structural shift in semiconductor economics: memory, not logic, now drives the cost of AI accelerators. HBM memory components account for 45% to 50% of the B200's total manufacturing cost 312. By comparison, the two massive 800mm2 logic dies fabricated on TSMC's 4NP process only cost roughly $850 combined 3. Yet, because Nvidia operates in a severely supply-constrained market, the company maintains extraordinary pricing power, selling the B200 for $30,000 to $50,000 per unit to sustain an estimated 84% gross margin 312.
Architecture Comparison: Hopper vs. Blackwell
| Feature | H100 (Hopper) | B200 (Blackwell) | B300 (Blackwell Ultra) |
|---|---|---|---|
| Release Date | Early 2023 | Late 2024 / 2025 | Mid 2026 |
| Transistor Count | 80 Billion | 208 Billion | 208 Billion |
| Max Memory | 80GB HBM3 | 192GB HBM3e | 288GB HBM3e |
| Memory Bandwidth | 3.35 TB/s | 11.2 TB/s | 8.0 TB/s (12-Hi Stack) |
| NVLink Bandwidth | 900 GB/s | 1,800 GB/s | 1,800 GB/s |
| Power (TDP) | 700W | 1,000W | 1,400W |
(Data compiled from NVIDIA architectural specifications and 2026 hardware benchmarks 357.)
The 2026 AI Compute Supply Crisis
The reason cloud pricing has not dropped linearly with compute efficiency is rooted in severe, physical supply chain constraints. By the summer of 2026, lead times for new Blackwell deployments at major datacenters extend between 36 and 52 weeks 1314. The bottleneck is no longer about fabricating the raw silicon dies; it is a crisis of advanced packaging and high-bandwidth memory production.
The Taiwan CoWoS Packaging Squeeze
The global semiconductor supply chain remains excessively concentrated in Taiwan, which produces over 90% of the world's leading-edge logic chips 4. To build a Blackwell GPU, Taiwan Semiconductor Manufacturing Company (TSMC) relies on its Chip-on-Wafer-on-Substrate (CoWoS) packaging technology.
Because the B200's dual-die configuration and eight memory stacks exceed the reticle size limit of a traditional monolithic silicon interposer (CoWoS-S), Nvidia was forced to adopt CoWoS-L (Local Silicon Interconnect) 316. CoWoS-L utilizes an organic interposer embedded with tiny silicon bridges, a highly complex process that yields slowly and structurally limits total global output 316.
Despite TSMC effectively doubling its CoWoS capacity year-over-year - scaling from 35,000 wafers per month in 2024 to a projected 120,000 to 130,000 wafers per month by late 2026 - demand continues to outpace supply 567. The largest hyperscalers (Microsoft, Google, Meta, and Amazon) placed multi-billion-dollar forward orders in 2025, essentially locking up TSMC's allocation through the end of 2026 14. To relieve the bottleneck, TSMC has begun outsourcing packaging to secondary OSAT (Outsourced Semiconductor Assembly and Test) providers like Powertech and Amkor, but these alternatives are also fully booked through 2027 789.
The High-Bandwidth Memory Deficit
Simultaneously, the AI boom has created a severe vacuum in the global memory supply. The B200 and B300 require massive volumes of HBM3e. Manufacturing HBM consumes roughly three times the raw wafer capacity of standard commodity DRAM 10. As the industry moves toward future HBM4 architectures, this ratio will widen 10.
Because memory suppliers like SK Hynix, Samsung, and Micron are prioritizing high-margin AI datacenter demand, they are neglecting consumer electronics. This has caused a spillover effect into GDDR7 memory, forcing Nvidia to slash consumer RTX 5000-series GPU production by 30% to 40% in early 2026 1411. Due to these constraints, Samsung and SK Hynix hiked HBM3e contract prices by roughly 20% for 2026 deliveries, an input cost directly passed down to end-users renting cloud GPUs 1224.
Geopolitics and Sovereign AI
Further tightening the open cloud market is the aggressive rise of "Sovereign AI." Recognizing computational power as critical national infrastructure, governments are bypassing commercial cloud providers to build localized AI factories.
In 2026, this geopolitical scramble is removing tens of thousands of GPUs from the commercial supply chain. The UK government invested £500 million in a Sovereign AI Unit, Saudi Arabia backed the $100 billion HUMAIN venture, and Singapore channeled over S$1 billion into local AI development 12. In May 2026, Armenia activated a $120 million, 35MW GPU-native AI factory powered by Blackwell B300 processors, strategically positioning the South Caucasus as a new node on the global AI map 26. This wave of nation-state buying ensures that hyperscalers and mid-market enterprises must fight over a shrinking pool of available merchant silicon 12.
Cloud Pricing and Hyperscaler Rationing
The combination of rising manufacturing costs, packaging bottlenecks, and sovereign demand has created a highly bifurcated cloud market in 2026. Buyers are largely split between hyperscalers (AWS, Azure, GCP) and specialized neo-clouds (Spheron, GMI Cloud, RunPod, Lambda Labs).
The Hyperscaler Squeeze
Major cloud providers are presently reserving their Blackwell inventory for internal AI workloads, proprietary foundation models, and top-tier enterprise clients 1427. In Q2 2026, reports emerged that Microsoft instituted a tiered access system for its Azure GPUs, heavily prioritizing "Tier 1" clients 27.
Smaller startups attempting to rent B200s or even legacy chips are facing harsh new realities. Cloud providers are demanding that smaller customers commit to renting at least 1,000 GPUs for a minimum of one year to access Blackwell hardware 27. Furthermore, startups renewing existing hyperscaler contracts in 2026 have faced price hikes of up to 32%, with hardware rates jumping from $2.80 to $3.70 per hour for older architectures 27. Some providers simply refuse to negotiate with accounts that lack massive scale, or revoke pay-as-you-go GPU access if instances remain idle for even a few hours 27.
The Neo-Cloud Alternative
Driven away by hyperscaler rationing, independent developers and mid-market enterprises are flocking to neo-clouds. These specialized providers operate with lower overhead, offer transparent pay-as-you-go pricing, and critically, do not charge the predatory egress data fees that can inflate hyperscaler bills by 20% to 40% 1329.
By May 2026, the secondary market has seen a stark divergence in hourly pricing, particularly on spot (preemptible) markets.
Summer 2026 GPU Cloud Pricing Comparison
| GPU Model / Memory | Median Hyperscaler On-Demand (AWS, Azure, GCP) | Median Neo-Cloud On-Demand (Spheron, Lambda, GMI) | Market Spot / Preemptible Floor |
|---|---|---|---|
| Nvidia H100 (80GB) | ~$6.88 - $8.00 / hr | $2.00 - $2.50 / hr | $1.03 - $1.19 / hr |
| Nvidia H200 (141GB) | N/A (Highly Restricted) | $2.50 / hr | ~$0.50 / hr (Tiered) |
| Nvidia B200 (192GB) | $14.24+ / hr | $5.50 - $6.02 / hr | $2.12 / hr |
| Nvidia A100 (80GB) | ~$3.00 - $4.00 / hr | $1.07 - $1.29 / hr | $0.60 - $0.67 / hr |
(Data aggregated from May 2026 pricing benchmarks across 15+ providers. Hyperscaler rates frequently obscure additional surcharges for networking egress and storage. 132930)
This table reveals a critical dynamic for buyers: on spot markets and specialized clouds, the on-demand cost of an older H100 ($2.00/hr) is essentially equal to the spot rate of a next-generation B200 ($2.12/hr) 13. For teams running fault-tolerant batch inference or checkpoint-heavy training, utilizing B200 spot instances on neo-clouds is currently the most efficient cost-per-token strategy available in 2026.
The Jevons Paradox: Why AI Prices Won't Crash
A logical question arises: if the Blackwell B200 is up to 15 times more efficient at inference than the Hopper architecture, why haven't total AI compute costs crashed for end-users?
The answer lies in the Jevons Paradox - an 1865 economic principle stating that as technological efficiency improves, the total consumption of the underlying resource actually rises due to induced demand 313214. Today, AI is putting the Jevons paradox on steroids 34. In fact, Nvidia's Blackwell GPU delivers 105,000 times more energy efficiency per token than its 2014 Kepler generation, yet global data center electricity use continues to grow roughly 12% per year 32.
As the cost-per-token plummets via native FP4 quantization, developers are not simply running the same tasks cheaper; they are building vastly more complex applications. In early 2026, the industry shifted decisively toward "Agentic AI" workflows and reasoning models (such as DeepSeek R1 and OpenAI's reasoning iterations) 12431. These models utilize chain-of-thought architectures that iteratively generate thousands of hidden sub-tokens to "think" before delivering a final answer to the user 2415.
Consequently, token generation volumes have grown exponentially. Every efficiency gain delivered by the B200 is immediately consumed by developers feeding models 2-million-token context windows, running continuous multi-agent loop workflows, and scaling synthetic data generation for fine-tuning 632. This structural shift guarantees that overall cloud utilization rates remain near 100%, effectively establishing a firm price floor of $2.50 to $3.00 for modern compute on the open market 24.
Datacenter Challenges: Power and Cooling
Deploying these massive chips is creating unprecedented physical challenges. The infrastructure requirements for Blackwell differ substantially from anything organizations have deployed previously. While the H100 consumed 700 watts of power, the B200 draws 1,000 watts, and the newer B300 Ultra draws an astonishing 1,400 watts per chip 357.
This massive thermal density exceeds the limits of traditional air cooling. For server racks like the GB300 NVL72 - which packs 72 GPUs and 36 Grace CPUs into a single rack to operate as a 1.1 exaflop supercomputer - direct-to-chip liquid cooling is mandatory 716. Data centers are currently scrambling to splice water lines and order coolant distribution units (CDUs), which themselves carry a 6-to-12 month lead time 17. By 2026, the market is swinging violently away from the legacy air-cooled fleets that currently make up 90% of global data centers, transitioning to liquid-cooled AI factories 17.
Survival Strategies for Independent Developers
For independent developers, IT leaders, and startups staring down extended lead times and hyperscaler rationing, adapting to compute scarcity requires a strategic shift from brute-force hardware provisioning to highly disciplined workflow optimization.
1. Navigating the Buy vs. Rent Equation
While the initial capital expenditure for Blackwell is daunting, the long-term total cost of ownership (TCO) heavily favors ownership for sustained, predictable workloads. By 2026, the breakeven point between cloud rental and self-hosting has compressed.
Factoring in capital depreciation, power, and cooling, self-hosting an 8x B200 cluster drops operating expenses to roughly $0.51 per GPU-hour 110. Compared to cloud rates ranging from $2.95 to over $14.00 per hour, continuous production users can see an ROI on owned hardware in roughly 15 months 1012. Furthermore, the used market has finally softened; used H100 SXM5 nodes have dropped from their $40,000 peak to between $6,000 and $22,000, making previous-generation hardware a highly viable option for cost-conscious labs seeking immediate capacity 30.
2. Implement Model Routing and SLMs
The most expensive mistake a developer can make in 2026 is routing every query through a massive frontier model running on premium B200 hardware 38. Up to 80% of routine corporate tasks - summarization, basic data extraction, and email drafting - can be handled by Small Language Models (SLMs) in the 7B-14B parameter range (e.g., Llama 3 8B, Phi-3, Gemma 27B) 138.
Implementing systematic model routing - directing simple tasks to self-hosted SLMs running on older, cheaper hardware like the RTX 4090 or L40S, while reserving the expensive B200 APIs strictly for deep reasoning tasks - can realistically reduce total AI operational costs by 70% to 100x 38. A specialized inference card like the L40S consumes significantly less power and offers excellent price-to-performance for mid-sized generative workloads, allowing companies to scale user bases without burning cash on H100s 1840.
3. Build Cloud-Agnostic Infrastructure
Locking into a single AI provider or relying strictly on AWS or Azure in 2026 introduces massive concentration risk and subjects buyers to predatory pricing 41. Successful startups are building model-agnostic and cloud-agnostic architectures 41.
By containerizing inference engines (using frameworks like vLLM) and utilizing spot markets on neo-clouds, developers can dynamically route workloads to the lowest cost-per-token provider, completely avoiding the stringent 1-year commitments demanded by hyperscalers 2742. Furthermore, utilizing optimization techniques like prompt caching and batch APIs can cut input token costs by 50% to 90% 38.
4. Look Ahead to Blackwell Ultra and Vera Rubin
When budgeting, buyers must plan for rapid hardware obsolescence. Stop buying hardware optimized for today's models and budget for what will run 18 months from now 40. Nvidia's B300 "Blackwell Ultra" is actively shipping in the second half of 2026, delivering the 288GB HBM3e capacity required for 100B+ parameter inference 67.
Following closely is the next-generation "Vera Rubin" architecture (R100), expected to launch in late 2026 into 2027. Rubin will integrate the Vera CPU and utilize HBM4 memory, delivering what Nvidia describes as a massive step up in compute capability 244. Buyers locking into three-year cloud contracts for older Hopper (H100) architecture today are making a severe financial error, as depreciation and rapid software optimization will quickly render those instances uncompetitive against Blackwell hardware 30.
Bottom line
The summer of 2026 is defined by a paradoxical AI hardware market: silicon has never been faster or more energy-efficient per token, yet immense agentic demand and structural packaging bottlenecks have kept absolute costs punishingly high. While major hyperscalers are leveraging their inventory to strong-arm small buyers into long-term commitments, smart enterprises are fighting back by diversifying into neo-clouds, exploiting spot pricing, and aggressively utilizing Small Language Models for routine tasks. Ultimately, securing affordable AI compute in 2026 requires abandoning blind cloud loyalty in favor of agile, multi-provider infrastructure planning.