How Much Does It Cost to Build a Frontier AI Model
Training a single frontier artificial intelligence model now requires an upfront investment ranging from $70 million to over $200 million in raw computing power alone. When factoring in the broader research and development ecosystem - which includes securing elite engineering talent, licensing proprietary data, and building gigawatt-scale infrastructure - the total capitalization required for a flagship AI system frequently approaches half a billion dollars. Because the computing demands for state-of-the-art AI are compounding by a factor of 2.4 annually, analysts project the next generation of top-tier models will cross the $1 billion training threshold before 2028.
The Exponential Era of Artificial Intelligence
For the first few decades of artificial intelligence research, breakthroughs were driven primarily by clever algorithmic design and academic experimentation. Today, progress is dominated almost entirely by the brutal economics of scale. The governing rule of the current era is straightforward: feeding exponentially more data and more compute power into a neural network reliably produces a more capable model. But that scale comes at an unprecedented financial cost.
The historical trajectory of this cost scaling is staggering. In 2017, researchers at Google introduced the "Transformer," the underlying neural network architecture that powers virtually all modern generative AI. Training that foundational model cost a mere $930 1. Just three years later, OpenAI's GPT-3 required an estimated $4.3 million in computing resources 1. By 2023, training OpenAI's GPT-4 consumed an estimated $78 million in compute 123. Google's Gemini Ultra pushed the ceiling even higher that same year, demanding an estimated $191 million to train 134.
According to a comprehensive 2024 analysis by Stanford University's Institute for Human-Centered AI (HAI) and research firm Epoch AI, the amortized hardware and energy costs for the final training runs of frontier models have grown by an average factor of 2.4 to 3 times per year since 2016 456.
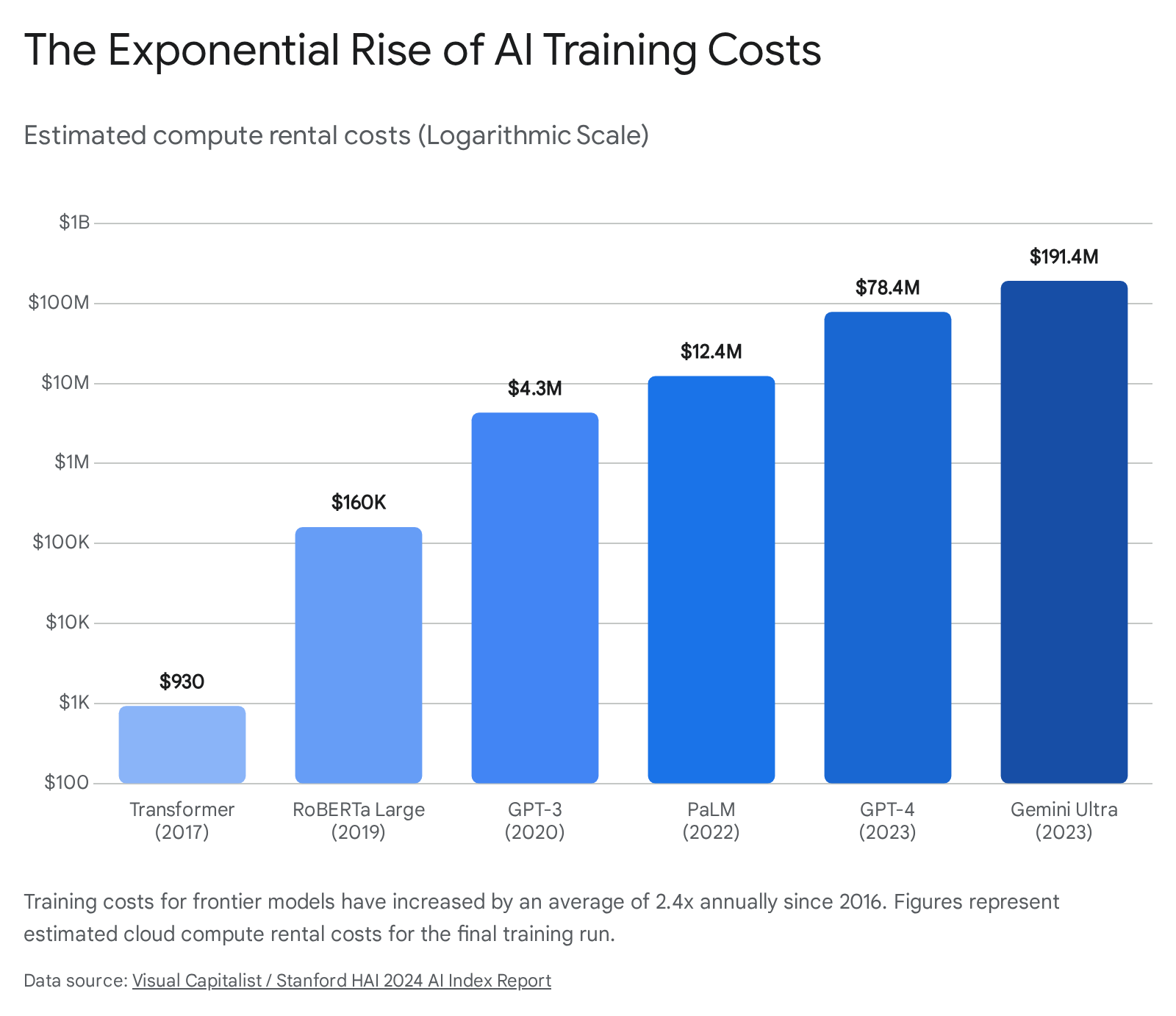
If this established trajectory holds steady, the computing hardware and power required to execute the largest model training runs will cross the $1 billion mark by 2027, making participation at the frontier a pursuit reserved strictly for the world's most heavily capitalized technology conglomerates 57. The rapid escalation underscores a stark reality: advancing artificial intelligence is no longer an exercise in pure software engineering; it has transitioned into a capital-intensive heavy industry.
Comparing the Compute Cost of Notable AI Models
The following table tracks the estimated cost of the computing hardware and electricity required for the final, successful training run of several milestone AI systems over recent years.
| Model Name | Release Year | Developer | Estimated Compute Cost |
|---|---|---|---|
| Transformer | 2017 | $930 | |
| RoBERTa Large | 2019 | Meta | $160,018 |
| GPT-3 (175B) | 2020 | OpenAI | $4,324,883 |
| PaLM (540B) | 2022 | $12,389,056 | |
| GPT-4 | 2023 | OpenAI | ~$78,352,000 |
| Llama 3.1 405B | 2024 | Meta | ~$170,000,000 |
| Gemini Ultra | 2024 | ~$191,400,000 |
Data sourced from the Stanford HAI 2024 AI Index Report and Epoch AI dataset. Values represent the amortized cost of hardware depreciation and energy usage during the final training run. 124
Breaking Down the Frontier R&D Budget
When a technology firm announces a $100 million AI model, that figure rarely captures the entirety of the project's financial footprint. The headline numbers usually refer exclusively to the "final training run" - the uninterrupted period, often lasting weeks or months, where a supercomputer cluster crunches the final, polished dataset to produce the finished neural network weights 6.
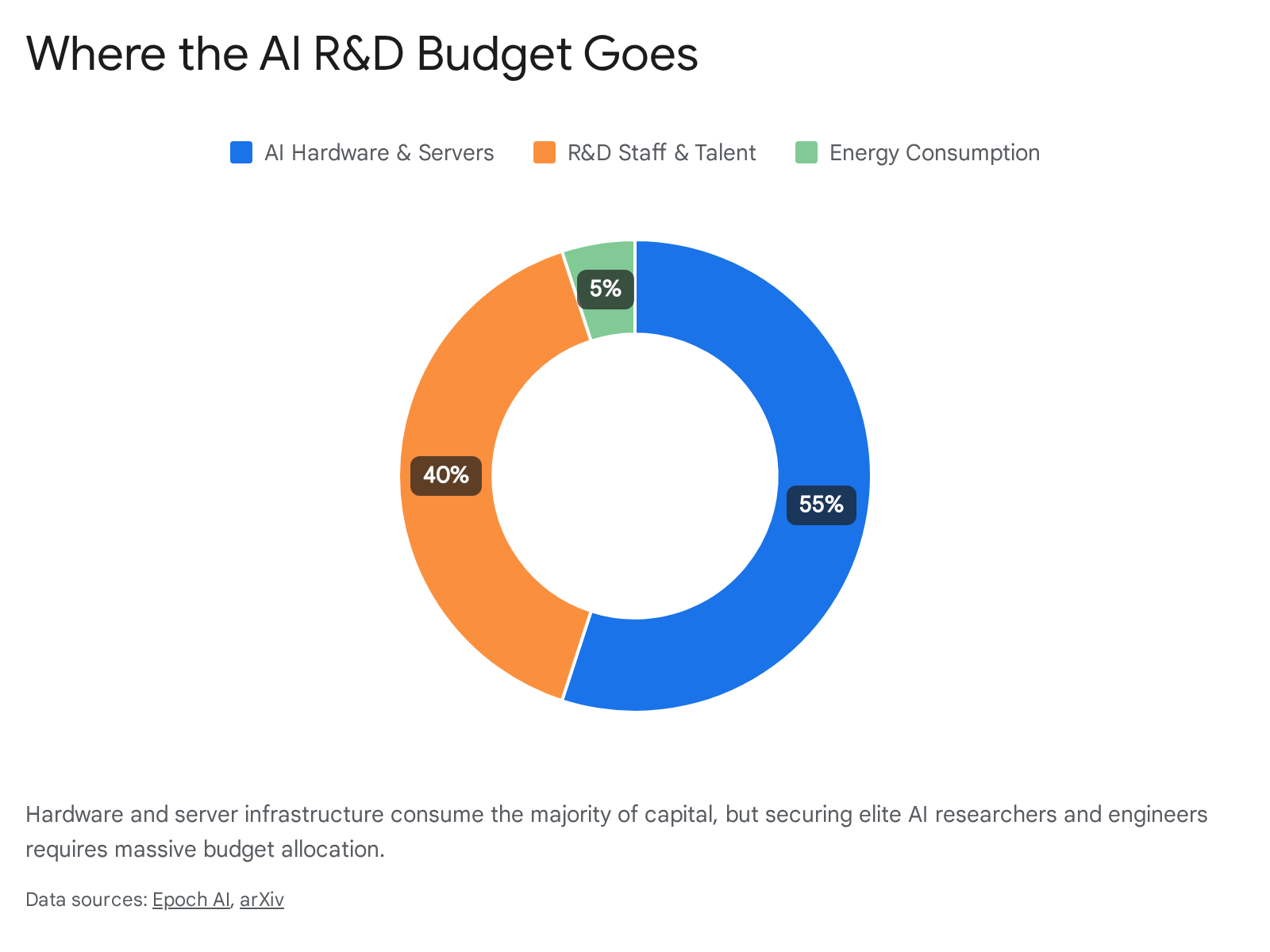
However, research from Epoch AI indicates that this final run is only a fraction of total research and development expenditures. For heavily capitalized labs, the vast majority of the budget is spent on preliminary scaling experiments, basic research, synthetic data generation, and smaller failed training runs that iterate toward the final architecture 6. When evaluating the true, all-inclusive cost of developing a frontier model, the budget is heavily concentrated into three core pillars: specialized silicon, elite human talent, and high-quality proprietary data 569.
Silicon, Servers, and the Hardware Monopoly
The computational muscle required to process trillions of tokens of text makes hardware the single largest expense in AI development. Epoch AI researchers estimate that computing hardware - including chips, servers, and networking interconnects - accounts for roughly 47% to 67% of a model's total development cost 567.
The undisputed backbone of this infrastructure is the Graphics Processing Unit (GPU), a market thoroughly dominated by NVIDIA. Originally designed to render video game graphics, modern GPUs feature thousands of parallel cores and massive high-bandwidth memory (HBM) perfectly suited for the dense matrix multiplications required in deep learning 10.
Leading AI models are currently trained on clusters comprising tens of thousands of these GPUs, primarily NVIDIA's H100 (Hopper architecture) and the emerging B200 (Blackwell architecture). The sticker price for this hardware is formidable. A single H100 chip typically sells for between $25,000 and $40,000, depending on the specific variant and memory configuration 10111213. But GPUs cannot operate in isolation. They must be housed in specialized servers with high-end CPUs, robust liquid cooling mechanisms, and complex networking fabrics like NVLink to ensure they can communicate with one another at high speeds. A fully equipped 8-GPU server node can easily cost between $350,000 and $450,000 1011.
The Economics of Renting vs. Buying Compute
Because AI silicon deprecates rapidly as manufacturers release superior architectures every few years, many AI startups and researchers opt to rent computing power from hyperscale cloud providers rather than purchasing the hardware outright 11.
In the cloud marketplace, an organization can rent an NVIDIA H100 for an average of $2.00 to $4.00 per GPU-hour, though peak scarcity during the AI boom has occasionally driven spot prices as high as $10.00 per hour 111214. Even at optimized pricing, the mathematics of distributed training add up quickly. If an organization rents a cluster of 25,000 GPUs to train a frontier model for 90 continuous days, the cloud compute bill will approach $160 million.
For the most aggressive industry players, however, renting is insufficient. Technology giants are increasingly purchasing hardware directly to build permanent, privately-owned AI data centers. By 2025, private industry controlled 80% of all AI supercomputer capacity, a sharp increase from previous years where academic and government institutions held a larger share 7.
The xAI Colossus Project: A Case Study in Scale
To grasp the true financial and physical magnitude of frontier AI infrastructure, one need only look to Elon Musk's xAI and its "Colossus" supercomputer facility in Memphis, Tennessee.
Initially launching in mid-2024 at a repurposed Electrolux manufacturing plant, Colossus came online with 100,000 interconnected NVIDIA H100 GPUs in an astonishing 122 days 8918. By early 2026, xAI aggressively expanded the site, purchasing adjacent facilities to house a total of 555,000 GPUs - a mix of Hopper and latest-generation Blackwell architectures 1920.
At standard market rates, a fleet of 555,000 cutting-edge GPUs represents an estimated $18 billion capital investment in microchips alone 919. For context, this localized capital expenditure rivals the cost of monumental national infrastructure projects. The Boston Central Artery/Tunnel ("Big Dig"), one of the most expensive urban infrastructure efforts in U.S. history, cost approximately $24 billion upon completion, while the initial segment of the California High-Speed Rail currently carries construction estimates exceeding $89 billion 2122. AI compute clusters have firmly entered the realm of civil megaprojects.
The Grid: Powering the Intelligence Explosion
As the volume of deployed silicon scales upward, the physical limitations of the global electrical grid are rapidly emerging as the primary bottleneck to AI advancement. An individual NVIDIA H100 GPU draws roughly 700 watts of power under load 1120. When these chips are organized into clusters of 100,000 or more, the power demands transition from the scope of traditional IT infrastructure into the realm of heavy industrial manufacturing.
Historically, standard enterprise data centers operated comfortably with a power capacity between 5 and 100 megawatts (MW) 10. Frontier AI training facilities are shattering these expectations, moving from megawatt-scale deployments to gigawatt-scale campuses. A one-gigawatt (1 GW) data center requires as much electricity as a medium-sized city, or roughly the continuous output of a nuclear reactor 710. The International Energy Agency expects demand from data centers to continue growing rapidly, noting that in 2022, data centers already consumed about 2% of global electricity demand - roughly equal to the entire annual consumption of France 24. By 2030, analysts project that the world's most powerful AI supercomputers could require up to 9 GW of power 725.
Infrastructure Constraints and Grid Bottlenecks
The electrical grid is struggling to accommodate this unprecedented surge in demand. In Northern Virginia - which serves as the world's largest data center market - utility providers have faced requests for over 40 GW of new power connections, a dramatic spike from previous years 11. This extreme localized demand has severely degraded "speed-to-power," the metric defining how fast a new facility can secure a grid connection. Data center developers in the region now face grid connection wait times extending up to 7 years, effectively halting immediate expansion plans 1213.
Similar constraints are manifesting globally. In Ireland, where data centers now consume more electricity than all of the nation's urban homes combined, authorities have begun restricting new data center connections around Dublin due to fears of grid instability and cascading blackouts 241129.
Furthermore, AI workloads place a unique physical strain on electrical systems. Traditional enterprise cloud computing experiences relatively steady and predictable power draws that rise and fall smoothly with user traffic. AI model training, however, exhibits a "pulsing" effect. During a massive computational pass, tens of thousands of GPUs calculate mathematical weights in synchronized steps, causing instantaneous power spikes across the facility 10.
To bypass utility grid delays, companies are taking extreme measures to generate power on-site. At the xAI Colossus facility, which targets a total load of nearly 2 GW, the company has deployed dozens of mobile combustion gas turbines - essentially modified jet engines mounted on trailers - alongside massive arrays of battery storage units to provide the necessary electricity independently of the regional grid 81920.
These colossal power and cooling requirements fundamentally alter the economics of commercial real estate. Constructing a traditional hyperscale data center costs approximately $10 million to $12 million per megawatt of capacity. However, building an AI-optimized facility capable of supporting the immense weight of liquid-cooled GPU racks - which can weigh up to 3,000 pounds each - pushes physical construction costs to $20 million per megawatt, and up to $40 million per megawatt when factoring in the hardware itself 3031.
The Arms Race for Elite Human Talent
While massive data centers do the heavy mathematical lifting, the humans responsible for designing the algorithms and managing the infrastructure command compensation packages more commonly associated with professional athletes or Wall Street executives. Epoch AI estimates that R&D staff costs represent a substantial 29% to 49% of the amortized cost of developing a frontier model, trailing only hardware in total expense 579.
The high cost of human capital is driven by extreme scarcity. The talent pool capable of writing the distributed computing code necessary to orchestrate a 100,000-GPU training run without the entire system crashing due to a fault is incredibly small. Consequently, Big Tech firms are locked in a ferocious bidding war for top researchers 14.
At OpenAI, the creator of ChatGPT, the workforce hails from elite institutions, and researchers sit at the very top of the market. While base salaries for AI research scientists range from $245,000 to $685,000, total compensation - buoyed by lucrative stock grants and annual bonuses - averages $1.5 million per employee 15. To retain key talent and fend off recruiters, OpenAI has reportedly offered retention bonuses as high as $1.5 million and accelerated stock vesting schedules, with top researchers reportedly earning up to $10 million annually 1416.
Meta, prioritizing its open-source Llama model ecosystem, has aggressively upended traditional pay structures to compete with OpenAI and Google DeepMind. Senior AI scientists at Meta can receive total compensation ranging from $5 million to $20 million over a multi-year vesting period 35. In a remarkable 2025 hiring spree, Meta CEO Mark Zuckerberg personally courted top engineers, resulting in pay packages worth hundreds of millions of dollars over several years for key executives. For instance, to acquire Andrew Tulloch and his team, Meta reportedly structured a deal involving bonuses initially valued at up to $1.5 billion over time, and offered a package to Apple AI executive Ruoming Pang that exceeded the compensation of nearly all top Apple executives 14.
Despite concerns over an "AI bubble," technology executives justify these salaries as rational insurance policies. When an organization is spending billions of dollars on data centers and silicon, allocating a fraction of that budget to ensure the brightest minds are optimizing the hardware is viewed as a necessary operational expense 14.
The End of Free Data and the Rise of Licensing
Historically, AI laboratories acquired the vast datasets necessary to train language models by indiscriminately scraping the public internet - consuming Wikipedia articles, blogs, forums, and digital books for free. That era has definitively closed. Facing a barrage of copyright infringement lawsuits from authors and media conglomerates, AI companies are now spending hundreds of millions of dollars to legally license high-quality, human-generated content 171819.
The economics of AI training data have birthed an entirely new revenue stream for the publishing industry. In May 2024, OpenAI signed a five-year licensing agreement with News Corp (owner of The Wall Street Journal and the New York Post) valued at more than $250 million, granting the AI developer access to vast archives of premium journalism 17181920.
Similar deals have propagated across the digital landscape. Reddit, recognizing the immense value of its human-authored forums for training conversational AI, secured a $60 million annual content licensing deal with Google and a subsequent $70 million annual partnership with OpenAI 171921. Amazon agreed to pay an estimated $20 million to $25 million annually to license content from The New York Times, while stock media giant Shutterstock projected $138 million in AI licensing revenue in 2024 alone 171920.
Human Feedback and the Hidden Cost of Labeling
Beyond licensing existing media, AI developers must pay armies of subject-matter experts to actively generate new data and grade AI outputs. This process, known as Reinforcement Learning from Human Feedback (RLHF), is vital for teaching raw, pre-trained models how to reason logically, follow instructions, and avoid generating harmful content 41.
The demand for human alignment data is so immense that data-labeling firms are experiencing explosive financial growth. Scale AI, a prominent data annotation company, generated roughly $870 million in revenue in 2023 41. Researchers analyzing these market dynamics have noted a fascinating inflection point: for certain fine-tuning operations, the cost of acquiring high-quality human data is now growing much faster than the cost of compute. In specialized tasks, such as training models for complex mathematical reasoning or high-level coding, the cost of paying PhD-level contractors to verify the AI's logic can be an order of magnitude more expensive than the marginal server cost of the fine-tuning run itself 41.
The DeepSeek Paradox: Algorithmic Efficiency vs. Scale
In the pursuit of ever-larger models, a pervasive assumption emerged: to build a better AI, a company must spend hundreds of millions of dollars on compute. However, in early 2025, a Chinese startup named DeepSeek forcefully challenged this paradigm with the release of DeepSeek-V3.
DeepSeek-V3 is an open-weight model that rivaled the benchmark performance of top-tier Western models like GPT-4 and Gemini 1.5. Yet, DeepSeek reported that the final training run for the model cost a mere $5.5 million - less than one-tenth of what competitors routinely spend 442434445.
DeepSeek achieved this radical cost reduction through intense algorithmic efficiency, relying on two primary architectural innovations:
- Mixture-of-Experts (MoE): Traditional "dense" neural networks like early iterations of ChatGPT activate every single parameter (the neural connections) for every word they generate. DeepSeek-V3, while a massive model possessing 671 billion parameters in total, uses a highly optimized MoE architecture. For any given token of text, the model routes the calculation only to specialized sub-networks, activating a mere 37 billion parameters 424445. This drastically reduces the required mathematical workload.
- FP8 Mixed-Precision Training: Standard AI models calculate their internal mathematics using 16-bit precision. DeepSeek pioneered a reliable method to train using 8-bit precision (FP8). By reducing the precision of the numbers, they effectively halved the memory bandwidth requirements, allowing them to train faster and use older, less powerful NVIDIA H800 GPUs highly efficiently 204345.
Why Efficiency Does Not Lower Total Spending
While DeepSeek's $5.5 million training run was a technical marvel, the figure itself sparked widespread misconceptions regarding the true cost of AI development 46. The $5.5 million accounts only for the direct server rental cost of the 55-day final training run on a cluster of 2,048 GPUs 4244. It completely excludes the immense capital required to curate the 14.8 trillion training tokens, the salaries of the research staff, the physical data center infrastructure, and the months of costly, failed experiments that preceded the final run 4246.
Furthermore, economists and AI researchers argue that algorithmic breakthroughs like DeepSeek's will not actually reduce global spending on AI compute. Instead, they trigger a technological phenomenon known as Jevons Paradox. As algorithmic efficiency makes compute cheaper and more effective, it unlocks new, highly profitable use cases (such as autonomous AI agents). This increased utility incentivizes technology firms to invest even more heavily in hardware to capture the newly accessible market value 22. Rather than resting on their laurels and saving money, companies use algorithmic efficiencies to train exponentially larger models for the same price.
Training vs. Inference: The Long-Tail Economics
When discussing the cost of artificial intelligence, media coverage heavily indexes on the initial training cost - the $100 million sprint to create the model. However, for a commercially successful AI product, the true financial burden lies in inference.
Inference is the act of the model actually answering user queries once it is deployed in the real world. Training creates the intelligence; it is an expensive, computationally intensive, but bounded, one-time event taking days or weeks. Inference applies that intelligence continually. It runs 24 hours a day, 7 days a week, and its costs scale directly with the volume of user traffic 2349.
While a single inference query might cost mere fractions of a cent, multiplying that by billions of daily requests results in staggering operational expenditures. Industry analysts estimate that over the lifetime of a deployed AI application, inference accounts for 80% to 90% of the total computing spend 49. For hyperscale deployments like ChatGPT, the ongoing inference bills can easily reach tens of millions of dollars per month, ultimately dwarfing the $78 million it took to train the underlying GPT-4 model 2350.
This dynamic explains why AI laboratories obsess over efficiency optimizations. An architectural choice that might increase the initial training cost by $10 million, but makes the resulting model 10% faster and cheaper to run during inference, will save a company hundreds of millions of dollars over the product's lifespan 49. As the industry matures and models transition from research projects into integrated consumer products, global spending on inference hardware is projected to overtake training hardware spending entirely 3023.
Geopolitics: The Hidden Premium of the Supply Chain
Looming over the economics of AI development is a stark geopolitical reality: the entire global supply chain relies almost exclusively on one geographic chokepoint. The Taiwan Semiconductor Manufacturing Company (TSMC) is responsible for producing over 90% of the world's most advanced microchips, including the NVIDIA GPUs that train every leading AI model 242526.
This creates a precarious single point of failure for the global technology sector. TSMC's fabrication facilities sit roughly 100 miles from mainland China. Military analysts, U.S. intelligence officials, and market strategists have repeatedly warned that any conflict, blockade, or severe geopolitical escalation in the Taiwan Strait would paralyze the global AI ecosystem 2526. A 2022 study commissioned by the Semiconductor Industry Association warned that a severe disruption of Taiwan's chip exports could trigger an economic recession more severe than the Great Depression, potentially reducing global output by over $10 trillion 26.
The acute vulnerability of this supply chain forces hyperscale technology companies and national governments to hoard chips, driving up prices and spurring panic buying. To mitigate this catastrophic risk, Western governments are injecting hundreds of billions of dollars in subsidies - such as the U.S. CHIPS and Science Act - to build redundant semiconductor manufacturing facilities outside of East Asia 252654. However, establishing localized fabrication plants requires massive capital expenditure and years of development, meaning the "geopolitical premium" on AI hardware will remain a defining cost factor for the foreseeable future.
Bottom line
The cost of building a frontier AI model has transitioned from a localized R&D expense into a macroeconomic phenomenon comparable to building major national infrastructure. While highly publicized figures often peg training costs near $100 million, the true financial burden is vastly higher when factoring in gigawatt-scale data centers, elite talent acquisition, proprietary data licensing, and the continuous, long-tail costs of running inference at scale. Although algorithmic breakthroughs prove that efficiency gains are possible, these efficiencies ultimately incentivize tech giants to train exponentially larger systems. Until physical constraints in semiconductor manufacturing or global power generation impose a hard limit, the financial barrier to entry at the frontier of intelligence will continue to rise.