How the Internet Went from ARPANET to TikTok
It is a ubiquitous, almost involuntary modern morning ritual: waking up, reaching for a smartphone, and spending ten minutes scrolling through a curated feed of short-form videos before the day has even officially begun 1. Within those few minutes, a user might be served a tutorial on vintage cake recipes, a hyper-targeted advertisement for sustainable skincare, and a political commentary from a stranger halfway across the globe 12. The content is seamless, frictionless, and endlessly addictive, served up by invisible algorithms that understand the user's behavioral psychology better than the user's own peers might 34.
Yet, to understand how global society arrived at this specific digital paradigm - a centralized, attention-driven, algorithmic entertainment ecosystem - one must look back over a half-century of technological evolution. The fifty-year arc of the internet represents one of the most profound socio-technical shifts in human history. It is the story of how a decentralized, text-based military communications network designed to survive geopolitical catastrophes metamorphosed into an artificial intelligence-driven commercial marketplace that dictates modern consumption, political discourse, and human interaction.
This comprehensive research report provides an evidence-based exploration of this transformation. By tracing the architectural, economic, and algorithmic shifts from the 1960s to the present day, the analysis reveals how hardware constraints in Asia, the limitations of chronological feeds, and the commercialization of artificial intelligence collectively reshaped the original decentralized vision of the internet.
What is the Difference Between the Internet and the World Wide Web?
Before tracing this fifty-year trajectory, it is critical to clarify a foundational misconception that persists in public discourse: the conflation of the "Internet" and the "World Wide Web." The distinction between the two is not merely semantic; it represents the difference between physical infrastructure and the software environments built upon it.
To understand the difference, consider a simple analogy: the "roads versus buildings" framework. The Internet represents the network of physical roads, highways, and the underlying infrastructure - the asphalt, the traffic lights, and the fundamental routing rules that dictate how vehicles travel from one city to another. The World Wide Web, conversely, consists of the shops, libraries, and buildings constructed alongside those roads. One can travel the roads without ever entering a building, just as one can use the Internet without using the Web (for instance, by sending a localized network ping, playing an online multiplayer game through a dedicated client, or using older protocols like email or Telnet).
The Internet's "roads" were laid down decades before the Web's "buildings" were constructed. The foundation of computer networking began in 1958 when researchers at Bell Labs released the Bell 101 modem, a device designed to modulate and demodulate digital information into signals capable of traveling across telephone wires 5. Spurred by the launch of the Soviet satellite Sputnik, the United States government founded the Advanced Research Projects Agency (ARPA) - later known as DARPA - which funded the creation of ARPANET 5. By 1969, the first nodes of ARPANET were connected, utilizing a revolutionary concept known as "packet switching" 5. Unlike older telecommunications systems that required a dedicated, open circuit between two callers (circuit switching), packet switching broke data down into small packets that could independently navigate a web of decentralized nodes to reach their destination 5. If one node was destroyed, the data simply found another route.
For decades, the Internet remained a sparse, utilitarian highway system. In 1979, the USENET system was formed to host news and discussion groups, and by 1983, ARPANET fully transitioned to the Transmission Control Protocol/Internet Protocol (TCP/IP), standardizing how these disparate networks communicated 51. It was not until 1989 and 1991 that Tim Berners-Lee, a scientist at the European Organization for Nuclear Research (CERN), introduced the World Wide Web 12. Berners-Lee created HyperText Markup Language (HTML), allowing decentralized resources to be linked together via a document-centric model 12.
However, the Web was not the only "building" proposed for the Internet's infrastructure. In 1991, a team led by Mark P. McCahill at the University of Minnesota released the Gopher protocol, a menu-driven, hierarchical directory system designed to fetch documents across the Internet 23. Gopher - named after the university's sports mascot and serving as a homonym for a "gofer" who fetches information - predated the widespread popularity of the Web and was highly suited to text-oriented computer terminals 234. For a brief period, "Gopherspace" was the primary method for navigating the nascent internet, effectively solving the bottleneck of finding resources distributed across isolated File Transfer Protocol (FTP) servers 24.
The eventual triumph of the World Wide Web over Gopher was dictated by a singular economic decision. In 1993, overwhelmed by the costs of maintaining the rapidly expanding network, the University of Minnesota announced it would charge licensing fees for commercial Gopher servers 23. This decision was met with immediate backlash and caused development to stagnate 23. In stark contrast, CERN released the World Wide Web into the public domain for free in April 1993 3. This open, free-form, hypertext-driven model ultimately absorbed Gopher's functionality, transforming the underlying infrastructure of the Internet into the vibrant, interactive digital metropolis known today 34.
What Are the Defining Eras of the World Wide Web?
Since its public introduction in the early 1990s, the World Wide Web has undergone several distinct evolutionary phases. These eras are not separated by hard chronological borders, but rather by paradigm shifts in how users interact with data, how businesses monetize attention, and how the underlying technology structures information.
The trajectory from a static digital library to a decentralized, artificially intelligent ecosystem demonstrates a persistent tension between centralization and decentralization. While Web 1.0 was technologically decentralized, content creation was centralized in the hands of a few technical webmasters. Web 2.0 democratized content creation but centralized the distribution and monetization of that content into the hands of a few mega-corporations. The current transition into Web 3.0 and Web 4.0 represents an attempt to return ownership to the user while simultaneously grappling with the highly centralized computing power required to train and run massive artificial intelligence models.
The specific characteristics defining these evolutionary periods are detailed in the comparison table below.
| Web Era | Alternate Designation | Approximate Timeline | Core Characteristics & Technological Focus | The Role of the User |
|---|---|---|---|---|
| Web 1.0 | The Static Web | 1991 - Early 2000s | Built on basic HTML pages, hosted on early ISPs or personal servers. Decentralized but highly static. Featured text-heavy directories, minimal styling, and no login systems 511. | Consumer: Users were anonymous, passive readers consuming read-only content created by webmasters 511. |
| Web 2.0 | The Social & Participatory Web | Early 2000s - Present | Characterized by two-way communication, user-generated content, mobile-first design, and cloud applications. Platforms like Facebook, Twitter, and YouTube emerged to capture user data 51213. | Creator / Product: Users interact, collaborate, and generate content, while their personal data is monetized by centralized platforms 1213. |
| Web 3.0 | The Semantic & Decentralized Web | Emerging 2020s | Focuses on data ownership, privacy, and decentralization. Powered by blockchain technology, cryptography, and smart contracts to remove centralized intermediaries 126. | Owner: Users actively control their digital identity, assets, and data, interacting through trustless, peer-to-peer networks 126. |
| Web 4.0 / 5.0 | The Algorithmic & Intelligent Web | 2023 - Future | Defined by artificial intelligence, the Internet of Things (IoT), and generative engines. Information is dynamically synthesized, filtered, and generated by predictive machine learning models 1112. | Curator / Collaborator: Users engage with AI agents that anticipate needs, generate hyper-personalized content, and seamlessly integrate the digital and physical worlds 1112. |
Why Did Chronological Feeds Die and the Social Graph Rise?
To understand how the modern internet became an algorithmic powerhouse during the Web 2.0 era, one must examine the death of the chronological feed. In the early days of social networking, platforms like Facebook and Twitter operated on a simple, egalitarian premise: reverse-chronological order 1516. When a user logged into their account, they were presented with the newest posts at the top of their feed, followed by progressively older posts buried underneath 1617.
This system was highly transparent and strictly time-dependent. Early adopters, bloggers, and emerging influencers found immense success because the only requirement for visibility was posting frequently and at optimal times of day 16. Users had total, unfiltered access to everything posted by the accounts they followed, ensuring that digital distribution was equitable 16.
However, as social media platforms experienced exponential user growth throughout the late 2000s and early 2010s, the chronological model collapsed under its own weight. The sheer volume of content generated by billions of users resulted in severe "information overload" 1516. High-quality updates from close friends and family were routinely buried beneath a flood of mundane, high-frequency posts from peripheral acquaintances, news outlets, or brands 1516. Platforms recognized that if users could not easily locate content that mattered to them, they would spend less time on the application, thereby threatening advertising revenue 18.
The solution to this scaling problem was algorithmic intervention. The goal of the algorithm was to prioritize relevance over recency, thereby maximizing the time users spent on the platform and increasing the number of advertisements they viewed 1518. In 2007, Facebook pioneered one of the first highly successful social media algorithms, originally dubbed "EdgeRank" 17. Adapted conceptually from Google's PageRank, EdgeRank abandoned chronological sorting and instead calculated the relevancy of a post based on a user's past interactions - such as likes, comments, and shares - as well as the type of media being displayed 17. This fundamental shift gave birth to the "Like" economy, where engagement metrics became the new digital currency 16.
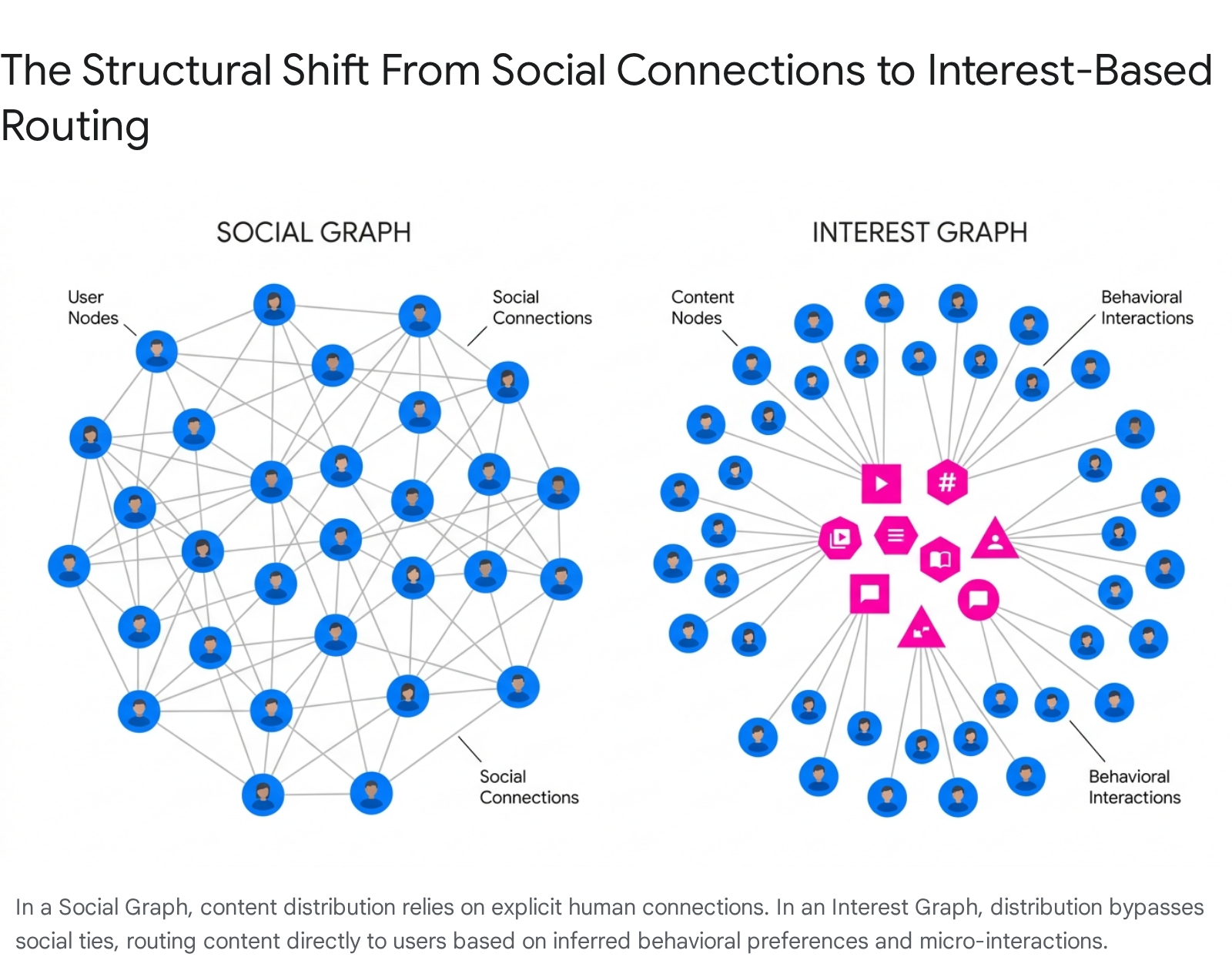
This transition formalized the era of the Social Graph. A social graph is a digital mapping of personal relationships - documenting who a user knows, their family members, their coworkers, and their friends 19. The underlying logic of the social graph algorithm is deeply rooted in sociology, specifically the "triadic closure principle" 7. This principle posits that if Person A has a strong connection with Person B and Person C, then Persons B and C are highly likely to share interests or eventually form a connection themselves 7.
Facebook's entire business model relied on this graph. The platform's algorithm operated on the assumption that a user would be more interested in a product, restaurant, or article if their real-world friends had previously engaged with it 3. For nearly a decade, the social graph ruled the digital landscape, allowing platforms to deliver highly personalized advertisements based on familial and social ties 3.
However, the social graph possessed a fatal flaw. Knowing someone in the physical world does not inherently mean sharing their digital interests. A user might be deeply passionate about vintage computing, while their high school friend - with whom they are tightly connected on the social graph - posts exclusively about sports and politics 3. Under a pure social graph model, the user is frequently force-fed content they do not care about simply because of a historical, real-world connection.
As the 2010s progressed, algorithmic curation extracted diminishing marginal benefits from the social graph. User engagement began to plateau because the content, while socially relevant, was not strictly aligned with individual passions 18. Furthermore, younger generations began to view the social graph as a liability, associating platforms like Facebook with familial surveillance rather than entertainment 2122. A new paradigm was required to keep users engaged, and its origins trace back to the unique technological and economic landscape of Asia.
How Did Asian Mobile Leapfrogging Create the Super App?
While Silicon Valley was busy mapping the social connections of the Western world, the Eastern hemisphere was experiencing a completely different digital evolution. The development of the internet in Asia, particularly in China and Southeast Asia, was defined by a socioeconomic phenomenon known as "technological leapfrogging" 238.
In North America and Europe, consumer internet adoption followed a linear, incremental path: from massive desktop computers with dial-up modems, to widespread broadband laptops, and eventually to smartphones 239. Western consumers grew accustomed to a fragmented digital ecosystem where different tasks were performed on different software programs or discrete mobile applications. Conversely, the vast majority of consumers in emerging Asian markets bypassed the personal computer era entirely 23926. For millions of citizens in these regions, their very first access to the internet occurred through relatively inexpensive mobile devices 23926.
This mobile-first environment collided with two other critical socio-economic factors. First, early budget smartphones in the Asia-Pacific (APAC) region had severely limited storage capacity. The median storage purchase in these markets was historically between 64GB and 128GB, making it highly impractical for a user to download, update, and juggle dozens of separate applications for messaging, banking, and shopping 27. Second, there was a massive lack of traditional financial infrastructure. By 2018, more than 1 billion people in Asia were considered "unbanked," meaning they lacked access to formal financial services, credit lines, or standard bank accounts 10. In Southeast Asia specifically, banking penetration hovered at a mere 27%, leaving roughly 438 million individuals without basic financial tools 8.
This perfect storm of mobile-first adoption, low-storage hardware, and unbanked populations birthed the Super App. A super app is a single, closed mobile platform that integrates a dizzying array of services - instant messaging, digital payments, food delivery, ride-hailing, e-commerce, and microloans - into one unified ecosystem 2930. Rather than downloading separate applications, users log into a single platform that serves as the operating system for their daily lives 30.
The quintessential example of this phenomenon is WeChat, developed by the Chinese technology conglomerate Tencent in 2011 2931. Originally launched as a simple messaging platform named Weixin, WeChat's meteoric rise was catalyzed by internal competition against Tencent's older messaging service, QQ 32. To differentiate itself, WeChat rapidly evolved by embedding "mini-programs" - lightweight, third-party applications that run directly inside the WeChat interface without requiring separate downloads or installations 3111.
Today, WeChat boasts 1.385 billion monthly active users 11. It is not merely a social network; it functions as the foundational digital infrastructure of modern China. The integration of WeChat Pay fundamentally altered the regional economy; by 2023, WeChat Pay processed over 4 trillion RMB, capturing 74% of China's mobile payment market 11. This system allowed millions of previously unbanked citizens to participate in digital commerce via QR codes, paying street vendors and utility bills with equal ease 11. Similar super apps, such as Grab and Gojek, conquered Southeast Asia by providing digital wallets that allowed unbanked users to remit money, pay bills, and order transportation through a single interface, collectively raising over $15 billion in funding to dominate the market 82630.
Despite the overwhelming success of super apps in the East, Western markets have largely resisted this model. The divergence in adoption is driven by several structural and cultural factors, which are detailed in the comparative analysis below.
| Factor | Asian Market Dynamics (Super App Success) | Western Market Dynamics (Super App Resistance) |
|---|---|---|
| Hardware Constraints | Consumers historically relied on budget devices with limited storage (64GB-128GB), necessitating a single, all-in-one application to save space 27. | Consumers possess high-storage devices (median 256GB+), allowing for the installation of dozens of specialized, standalone apps without performance issues 27. |
| Financial Infrastructure | High populations of "unbanked" citizens lacked traditional credit. Super apps filled this void by providing instant digital wallets and microloans 81029. | Consumers have deeply entrenched, long-standing relationships with legacy banks and credit card companies, making them hesitant to trust tech firms with primary financial management 9. |
| Cultural Psychology | Collectivist cultures prioritize communal utility, convenience, and integrated ecosystems over strict digital individualism 3412. | Individualistic cultures favor best-in-class, specialized tools (e.g., Uber for rides, Spotify for music) and prefer fragmented choices over centralized monopolies 273412. |
| Regulatory Environment | Governments often supported domestic tech champions to rapidly modernize economies and digitalize public services 911. | Western regulators actively discourage multi-category conglomerates, frequently launching antitrust probes to ensure fair competition and prevent monopolistic data harvesting 9. |
However, while the West rejected Asia's structural super app model, it was completely blindsided and subsequently conquered by an Asian algorithmic innovation: the Interest Graph.
What is the Interest Graph and How Did TikTok Redefine Social Media?
If Facebook built an empire on who you know, the Chinese company ByteDance conquered the world by understanding exactly what you want to see 36. In 2016, ByteDance launched TikTok (known as Douyin in China), a short-form video platform that fundamentally shattered the social graph paradigm 337.
TikTok's unprecedented global success is staggering. By 2025, the platform reached 1.99 billion monthly adult users globally, operating in over 150 countries and 75 languages 38. The application completely dominates the attention economy, with users spending an average of 95 to 97 minutes per day on the platform - significantly higher than the 33 to 55 minutes spent daily on Instagram 38. Furthermore, TikTok achieved an average engagement rate of 3.7% to 4%, drastically outperforming Instagram's 0.5% to 1.5% 38.
This dominance is driven entirely by TikTok's reliance on the Interest Graph 337.
The interest graph (sometimes referred to as the socio-interest graph or content graph) connects people not based on their personal relationships, but on their shared behaviors, passions, and content consumption 19739. When a user downloads TikTok, they do not need to follow anyone, import their contacts, or explicitly state their preferences 3. The platform immediately begins serving a frictionless stream of full-screen vertical videos. The algorithm learns passively, mapping the user's interests by measuring micro-behaviors: how many milliseconds a user hovers on a video, whether they re-watch a loop, if they check the comments, and how quickly they swipe away 337.
This shift from social connections to interest-driven content discovery democratized viral reach. In the social graph era, distribution was tied to network size; a brand or influencer needed millions of followers to guarantee millions of views, creating an entrenched hierarchy 3940. In the interest graph era, reach is audience-led rather than audience-owned 40. A brand-new account with zero followers can post a highly engaging video that algorithms push to millions of highly targeted users purely because the content matches their behavioral profile 2139.
The success of the interest graph triggered a phenomenon known as "TikTokification" across the entire Western tech ecosystem. Recognizing that users preferred frictionless, hyper-personalized entertainment over mundane updates from their extended family, incumbent platforms aggressively overhauled their interfaces to mimic ByteDance's model. Meta introduced Instagram Reels, shifting the application from a square-photo feed of friends to a full-screen, algorithmic video feed prioritizing unconnected reach 2241. By early 2025, Instagram Reels accounted for a staggering 50% of all time spent on the application 38.
Even professional networking platforms were not immune to this algorithmic shift. Between late 2024 and early 2025, LinkedIn - historically the last bastion of the pure professional social graph - began aggressively pushing a dedicated, full-screen vertical video feed on both its mobile app and desktop interface 421314. Modeled directly after TikTok, this "Videos For You" carousel allowed users to seamlessly swipe through professional content from creators outside their immediate network 1445. The strategy yielded massive engagement, with LinkedIn reporting a 36% year-over-year growth in total video viewership and a 100% growth in video creation on the platform by the first quarter of 2025 1345.
Perhaps the most significant economic consequence of the interest graph is its existential threat to traditional search engines. A dramatic shift in search behavior has occurred, particularly among younger demographics. By 2025, more than half (51%) of Generation Z users reported tapping TikTok first when searching for new products or engaging in brand discovery, rather than utilizing Google 1. Furthermore, a Google internal study revealed that over 40% of Gen Z users prefer TikTok or Instagram over Google Search when looking for places to eat or products to buy 46.
The logic driving this shift is rooted in a desire for authenticity and visual verification. Younger users inherently trust raw, user-generated video content of a peer testing a product more than a polished, SEO-optimized text article 4647. In response, brands and marketers have had to pivot away from traditional keyword-stuffing toward "Social Search Optimization" (SSO). To rank within interest graph algorithms, businesses now rely on keyword-rich text overlays within videos, descriptive captions, and micro-creator seeding, recognizing that polished corporate advertisements are routinely rejected by audiences seeking genuine community context 146.
How is Generative AI Altering the Fabric of Digital Discovery (2023 - 2026)?
While social media platforms transitioned from social graphs to interest graphs, the fundamental act of retrieving information - search - has undergone its own radical transformation, driven by the rapid commercialization of Artificial Intelligence.
For two decades, the traditional search engine model (the hallmark of Web 2.0) operated as a gateway. A user typed a query, the search engine indexed millions of static pages based on keyword density and backlinks, and the engine provided a list of blue links. It was then the user's responsibility to click through multiple websites, synthesize the disparate data, and formulate an answer 48.
The explosion of Large Language Models (LLMs) and generative AI between 2023 and 2026 entirely shattered this model. Generative search engines - such as OpenAI's ChatGPT, Google's Gemini, Google's AI Overviews, and Perplexity - do not act as gateways; they act as authoritative interpreters . Rather than pointing to information, they analyze user intent, synthesize vast amounts of data across the internet in real-time, and generate a cohesive, conversational answer directly on the search results page 4850.
The speed of this transition is unprecedented. By 2025, generative AI-driven traffic was growing 165 times faster than traditional organic search traffic 48. Research analyzing over one billion search sessions indicated that AI Overviews appeared in 1 in 4 U.S. Google searches, and in over 50% of searches involving complex queries of seven words or more . Approximately 10% of U.S. consumers (roughly 13 million people) had completely shifted their primary search habits to generative AI platforms, a figure projected to scale to 90 million by 2027 52.
This algorithmic paradigm shift necessitates a move from traditional Search Engine Optimization (SEO) to Generative Engine Optimization (GEO) 4852. Because visibility increasingly happens inside AI-generated answers, users often complete their decision-making process without ever clicking a link to an external website, resulting in lost traffic for brands even if they maintain strong traditional rankings .
To remain visible in this new era, digital marketers can no longer rely on superficial keyword insertion. Generative AI models evaluate content based on topical authority, clear semantic structure, and deep contextual comprehension 4850. Content must be structured with highly logical headers, provide comprehensive answers to related follow-up questions, and maintain rigorous factual accuracy to be selected and cited by the AI 52.
Earning a citation from a generative AI tool is highly lucrative. AI-driven referral traffic features a 23% lower bounce rate, generates 12% more page views, and results in a 41% longer dwell time compared to non-AI traffic 48. Furthermore, being cited by an AI not only drives highly engaged traffic, but it signals to other machine learning models that the content is a trusted node of authority, creating a compounding cycle of algorithmic visibility 48.
How Can Users Curate Their Digital Diet? (Practical Takeaways)
The convergence of interest graphs and generative AI means that the modern internet is no longer a passive repository of information; it is a highly active, predictive engine designed to capture and monetize human attention. As algorithms grow increasingly sophisticated at exploiting psychological vulnerabilities and the "fear of missing out" (FOMO), users must transition from passive consumers to active curators of their digital diets 4.
Just as physical health is dictated by nutritional intake, mental well-being in the Web 4.0 era requires strict curation of algorithmic inputs. Digital sociologists and psychologists recommend several actionable strategies to reclaim agency over one's digital environment, which are summarized in the curation matrix below.
| Curation Strategy | Mechanism of Action | Practical Implementation |
|---|---|---|
| Starving the Negative Feedback Loop | Interest graph algorithms learn purely from engagement, viewing watch time as a proxy for preference 353. Lingering on controversial or anxiety-provoking content signals to the AI that the user desires more of it 4. | Consciously refuse to interact with negative content. Scroll past immediately or close the application to deny the algorithm the behavioral data it requires to reinforce the loop 453. |
| Active Rejection Mechanisms | Platforms utilize explicit rejection data to refine their predictive models 53. | Aggressively utilize the "Not Interested" or "Mute" features on platforms like TikTok and Instagram. This provides strong negative data signals, forcing the algorithm to recalibrate the user's psychological profile 453. |
| Intentional Engagement | Algorithms will optimize for whatever content receives likes, saves, and thoughtful comments 453. | Deliberately engage with content that promotes education, well-being, or genuine hobbies. By consciously interacting with positive content, users manually train the AI to serve as a tool for personal growth 453. |
| Breaking the Filter Bubble | Interest graphs naturally tend toward echo chambers, serving identical viewpoints and narrowing a user's worldview to maximize comfort and watch time 454. | Proactively seek out and follow creators, journalists, and experts outside of immediate comfort zones. Regularly audit feeds to ensure diverse sources are represented, introducing algorithmic diversity into the daily digital diet 454. |
The Bottom Line: How Hardware and Algorithms Changed the Decentralized Vision
The evolution of the internet from the 1970s to the present day is a profound study in unintended consequences and technological adaptation. ARPANET was explicitly designed as a decentralized, utilitarian communications network intended to democratize data and survive physical disruption. For its first few decades, the World Wide Web upheld this ethos, serving as an open, document-centric frontier where users possessed equal footing.
However, the hardware constraints of the mobile era - particularly in Asian markets - and the economic imperatives of attention-based monetization birthed the super app and the algorithmic feed. To prevent users from drowning in a chronological sea of information, tech conglomerates introduced the social graph, leveraging real-world human relationships for digital engagement. When that model plateaued, the interest graph was deployed, bypassing human connection entirely in favor of hyper-personalized, behavior-driven routing. Today, combined with generative AI that pre-synthesizes all available knowledge into conversational responses, the internet has become a highly centralized, predictive ecosystem.
The original vision of the internet as a decentralized infrastructure remains intact beneath the surface. However, the buildings constructed upon it have transformed into algorithmic walled gardens, where human attention is the primary currency, and artificial intelligence serves as both the architect and the gatekeeper.