How the Human-AI Feedback Loop Drives Virality
Virality on social media is no longer an organic phenomenon; it is the mathematical outcome of continuous human-AI feedback loops prioritizing deep engagement over chronological delivery. Recommendation algorithms rapidly ingest behavioral data - such as watch time, swipe velocity, and share rates - to construct hyper-personalized feeds that inevitably favor emotionally arousing, polarizing content. While platforms provide tools for users to reset their feeds and scrub unwanted topics, breaking out of these algorithmic echo chambers requires sustained, deliberate interaction to actively retrain the underlying machine learning models.
The Architecture of Algorithmic Amplification
At the core of modern social media is the recommendation engine, a complex machine learning infrastructure designed to match content to users at scale. Unlike legacy chronological feeds, which simply displayed posts from followed accounts, contemporary platforms utilize deep neural networks and multimodal feature recognition to predict user behavior. The system operates on a continuous, self-reinforcing feedback loop: the algorithm predicts what a user wants, serves the content, observes the user's reaction, and immediately retrains its model based on that interaction 121.
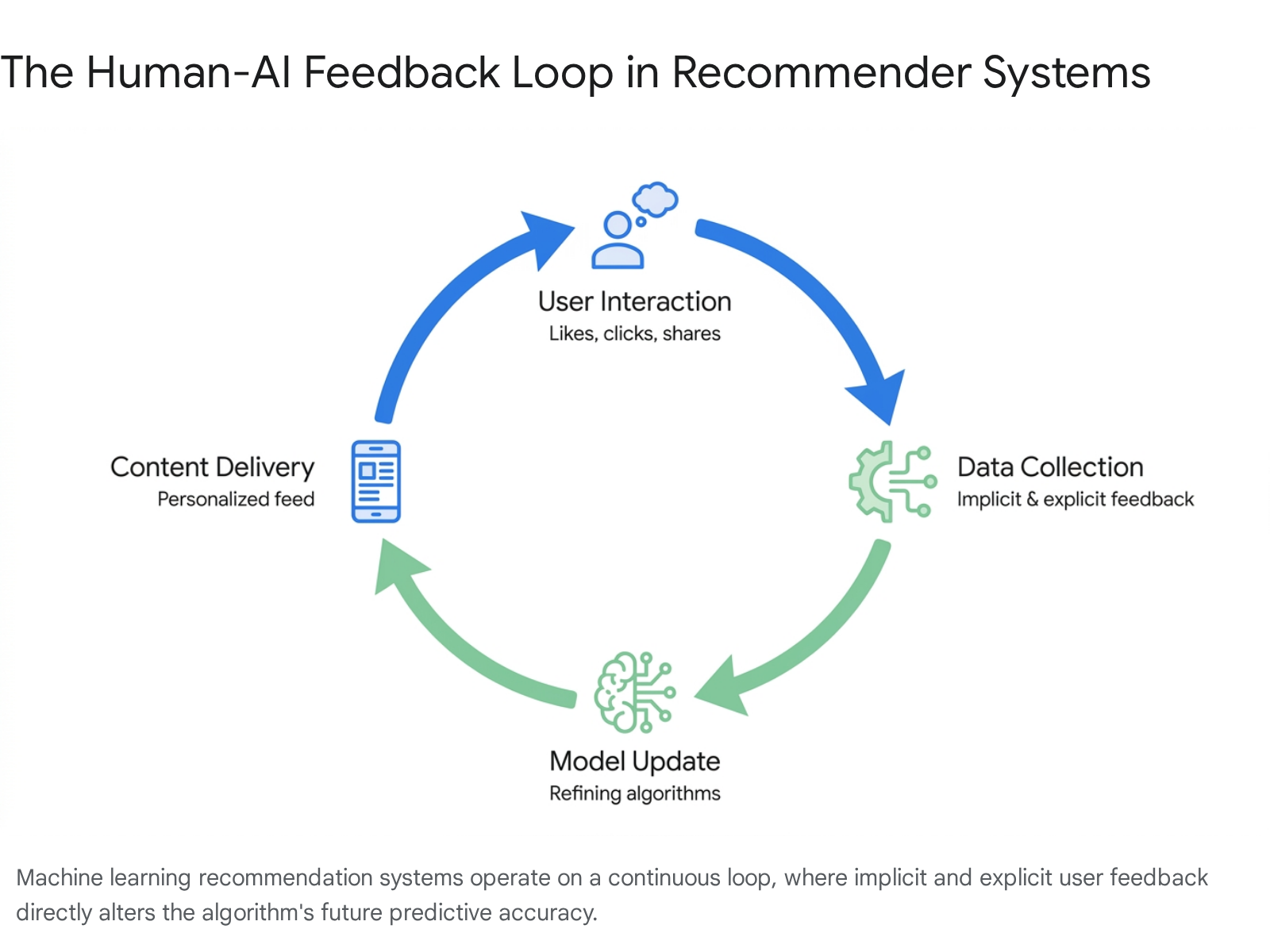
When a model is deployed into production, it encounters real-world data that often diverges from its initial training parameters 4. Therefore, the algorithm's accuracy depends entirely on collecting constant, real-time data from the user. This data is broadly categorized into two types of feedback:
- Explicit Feedback: These are intentional actions taken by the user, such as tapping the "like" button, leaving a comment, saving a post, or utilizing negative signals like the "Not Interested" feature 42.
- Implicit Feedback: These are passive, behavioral signals inferred from how the user navigates the platform. They include session duration, video completion rates, how quickly a user swipes past a video, and even micro-pauses while scrolling 26.
Because implicit feedback is significantly harder for users to fake - and occurs in much higher volumes - platforms increasingly weigh passive behaviors, like watch time, far more heavily than traditional explicit vanity metrics 3. The human-AI feedback loop is continuously fine-tuned by these subtle behavioral traces.
The Cold-Start Problem and the "Audition" Phase
Before a recommendation algorithm can distribute content widely, it must evaluate the content's viability. Recommender systems generally suffer from the "cold-start problem," a scenario where new videos or new users lack the historical interaction data necessary for accurate prediction 8.
To solve this, platforms treat the first few minutes of a post's lifecycle as a high-stakes audition 9. When a creator uploads a piece of content, the system's AI reviews it for basic compliance, extracting text features via Natural Language Processing (NLP), visual features through image recognition, and audio markers via voiceprint analysis 104.
Once cleared, the algorithm pushes the content to a small test batch of users - often just 200 to 500 initial viewers 10. If this cold-start audience provides strong early signals (e.g., watching past the first three seconds, finishing the video, or sharing it), the platform reads these actions as intent, and the "reach ceiling" opens up 39. Conversely, fast swipes or immediate drop-offs act as a hard ceiling, signaling to the algorithm that the post is not worth further inventory distribution 9. This ruthless initial gating mechanism is why a post can stall at 200 views or rapidly scale to 2 million based entirely on the initial cohort's reaction.
The Exploration-Exploitation Tradeoff
To prevent users from becoming bored by a highly repetitive feed, recommendation engines must continuously balance two competing imperatives: exploration and exploitation 513.
"Exploitation" occurs when the algorithm serves content that aligns perfectly with a user's deeply established, historical preferences to guarantee engagement 56. "Exploration" occurs when the algorithm introduces novel, untested topics outside the user's historical graph to discover new latent interests 513.
The exact ratio of this tradeoff determines how deeply a user is entrenched in a specific content niche. In a 2024 academic audit utilizing automated bots and real-user data donations via GDPR "data takeout" procedures, researchers analyzed the algorithmic behavior of TikTok 56. The study revealed that TikTok exploits a user's known interests in roughly 30% to 50% of the first 1,000 videos they encounter 56. The remaining 50% to 70% of the feed is dedicated to exploration.
If a user exhibits high engagement with an "exploration" video, the algorithm instantly updates the user's preference weights, converting that novel topic into a newly "exploited" interest 56. This rapid processing capability explains why users can fall down highly specific algorithmic rabbit holes in a matter of minutes.
Decoding Platform-Specific Ranking Mechanisms
While the foundational mathematics of machine learning are similar across the tech industry, different platforms weigh engagement signals uniquely based on their distinct business models and user interfaces. Understanding these nuances is critical to grasping how virality is manufactured in 2025 and 2026.
TikTok and Douyin: Behavioral Prediction at Scale
TikTok and its Chinese sister app, Douyin, operate on nearly identical technological frameworks developed by ByteDance, but they serve different markets with distinct regulatory environments and feature sets 1578. Douyin features deep e-commerce integration and adheres to local regulations, including a strict "youth mode" that limits users under 14 to 40 minutes of educational content per day 157.
At a technical level, both apps utilize deep learning models built on hierarchical interest label trees and partitioned data buckets 4. Rather than relying on a user's follower graph, the system directly predicts behavior through neural networks 10. In 2026, TikTok's algorithm heavily prioritizes watch time, completion rates, and shares 910. According to creator analytics, TikTok videos that achieve a 70% or higher completion rate reach five times more users than videos with a 40% completion rate 10. To maintain normal algorithmic distribution, a video must typically secure a 3% to 5% engagement rate within its first hour 11.
Instagram: AI Recommendations and the 3-Second Rule
Historically driven by follower networks and chronological timelines, Instagram has fundamentally transformed its infrastructure. By 2026, roughly 94% of content distribution on the platform is driven by AI recommendations rather than organic follower reach 3.
The platform utilizes distinct ranking algorithms for its Feed, Reels, Stories, and Explore page 21. For Instagram Reels, the algorithm aggressively prioritizes the first three seconds of a video; content that fails to capture a 3-second retention threshold is routinely suppressed 3. Furthermore, Instagram has deprecated the value of the simple "like" button. The primary signals for algorithmic amplification are now watch time and the "sends per reach" ratio, meaning content is judged largely on how frequently users share it with friends via Direct Message 31012. The platform also instituted penalties in 2025 for aggregator accounts, explicitly down-ranking unoriginal, reposted, or watermarked content to boost smaller, original creators 321.
Xiaohongshu (Red Note): The Community Engagement Score
Xiaohongshu (often referred to internationally as Red Note) operates under an entirely different paradigm. Blending the aesthetics of Instagram with the utility of Pinterest, Xiaohongshu functions heavily as a search engine; up to 60% of content discovery occurs through active search queries rather than passive feed scrolling 1123.
Because the platform relies on a decentralized distribution model governed by an "Interest Graph," follower counts are less vital to virality than content utility 24. The recommendation algorithm evaluates content using a proprietary Community Engagement Score (CES). Empirical analysis indicates the weighting of this score heavily penalizes low-friction interactions and rewards high-friction utility: Likes equal 1 point, Favorites/Saves equal 1 point, Comments equal 4 points, and Reposts/Shares equal 4 points, with subsequent Follows granting 8 points 102324. Consequently, highly polished, studio-shot advertisements often alienate the Xiaohongshu audience and face algorithmic suppression, while information-dense "encyclopedia" tutorials that generate massive "save-for-later" metrics achieve hyper-virality 2425.
WeChat Channels and X: Social-Powered and Conversational Ranking
Other platforms rely more heavily on social proximity and conversational dynamics. WeChat Channels prioritizes a "private domain to public domain flow," leveraging social relationships heavily in its distribution logic 1013. In 2025, the platform increased the algorithmic weight of the "Friends ♡" tab; content that gains traction in private group chats or Moments is exponentially more likely to be pushed to the broader public recommendation feed 1314.
Meanwhile, X (formerly Twitter) transitioned toward a fully AI-driven feed powered by the Grok language model, pivoting away from raw engagement metrics toward conversational density 15. The algorithm currently weighs replies and deep conversation threads far higher than standalone broadcast posts, ensuring that virality is tied to continuous discourse 15.
Quantifying Virality: Engagement Benchmarks and Methodology
Understanding virality requires accurate benchmarking, but interpreting social media statistics can be perilous due to conflicting methodologies across the analytics industry.
For instance, when evaluating engagement rates in the financial services sector, data firm Rival IQ reported a median Instagram engagement rate of 0.26%, while Hootsuite reported a massive 3.80% for the exact same vertical 2930. This severe discrepancy exists because Rival IQ calculates engagement by dividing total interactions by total followers, whereas Hootsuite divides interactions by the total impressions or reach of the post 2930. In an era where AI recommendations drive views far beyond a creator's follower base, measuring engagement strictly against follower counts yields artificially deflated metrics 30.
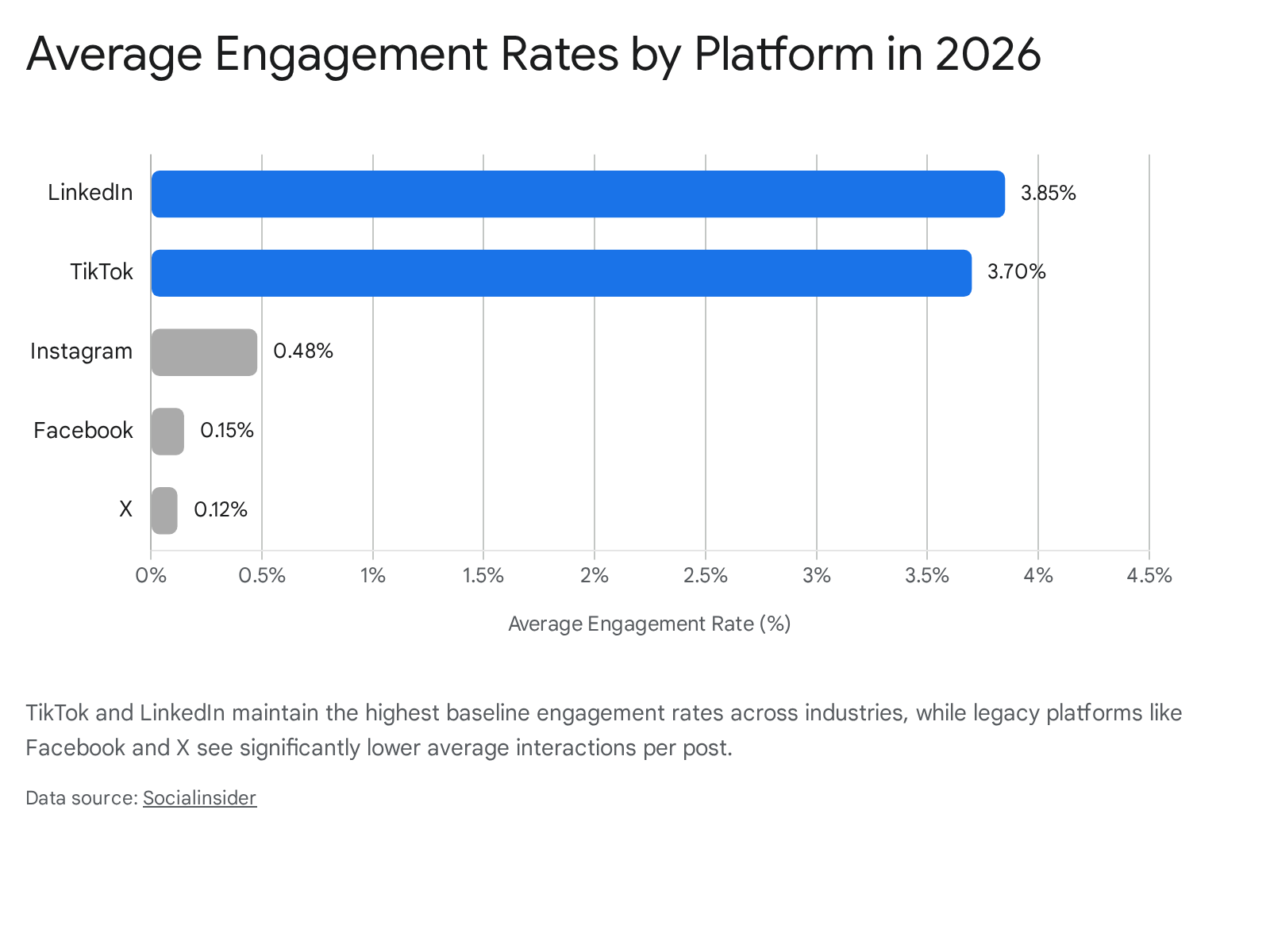
When looking at normalized data for 2025 and 2026, TikTok consistently maintains the highest baseline engagement rates across the digital landscape, though those rates decay rapidly as audience size grows.
2026 Cross-Platform Engagement Averages
Based on comprehensive cross-platform analysis of tens of millions of posts, the hierarchy of platform engagement becomes clear.
Smaller "nano-influencers" consistently outperform mega-accounts; on TikTok, accounts with under 100,000 followers average a 7.50% engagement rate, whereas accounts with over 10 million followers drop to roughly 2.88% 931.
| Platform | Core Distribution Engine | Average Engagement Rate (2026) | Primary Engagement Signals (Weighted Highest) |
|---|---|---|---|
| Professional interest graph & conversational AI | 3.85% 9 | Dwell time, long-form comments, shares | |
| TikTok | Behavior prediction & multimodal feature extraction | 3.70% 9 | Completion rate, watch time, shares 10 |
| Instagram (Reels) | AI recommendations & social graph | ~2.80% 29 | DM shares, saves, 3-second retention 3 |
| Instagram (Feed) | AI recommendations & social graph | 0.48% 9 | Saves, comments, prolonged dwell time |
| Hybrid chronological & algorithmic | 0.15% 9 | Meaningful social interactions, comments | |
| X (Twitter) | AI-driven conversational ranking via Grok | 0.12% 9 | Thread replies, active ongoing conversations 15 |
The Economics of Attention: Rage-Bait and Bias Amplification
The metrics that determine virality are entirely amoral. While technology executives frequently state their algorithms are trained to maximize "meaningful social interactions," in practice, the most reliable mechanism for extracting high engagement is emotional arousal.
Content that evokes strong, immediate emotional responses - particularly outrage, moral indignation, and partisan hostility - naturally holds human attention longer and provokes significantly higher comment and share velocities 1617. This psychological reality has birthed what researchers refer to as the "economy of words," where the unwritten operational doctrine of digital media is simply that "angry people click more" 1617.
When recommendation systems operate purely on engagement-based optimization, they naturally drift toward divisive and inflammatory content. To a machine learning model, "rage-bait" is not a stylistic flaw; it is a highly efficient content category that perfectly matches the optimization function. The user's "anger click" is simply the behavioral trace confirming the system's success 1617. Consequently, former platform designers acknowledge that notifications, feeds, and recommendations have been aggressively refined through continuous A/B testing to discover precisely which combinations of topics and headlines keep users enraged and returning 16.
The Danger of the Feedback Loop in Recommender Systems
This algorithmic preference for strong emotion creates severe mathematical vulnerabilities in the form of AI feedback loops. Recommender systems inherently rely on dynamic models that continually learn from user interactions based on their own prior predictions 21. Over successive cycles, these self-reinforcing loops can severely amplify existing biases, degrade recommendation diversity, and homogenize user behavior 218.
Techniques like Matrix Factorization and Collaborative Filtering - the foundational mathematics of many recommender systems - operate by predicting missing interactions based on past data 419. However, because the system influences the very behavioral data it subsequently uses to retrain itself, the algorithmic outputs become increasingly narrow 218. A vast majority of historical bias mitigation techniques were tested on static data splits (a single round of testing), failing to account for how fairness and diversity diminish over months of live, multi-round retraining 121. Only recently have researchers shifted toward dynamic simulation frameworks to audit the long-term, corrosive effects of these feedback loops on marginalized content and user behavior 11.
Echo Chambers and Filter Bubbles: Structural Isolation
As users interact with highly optimized, emotionally charged content, the feedback loop progressively narrows the scope of information presented to them, culminating in the creation of filter bubbles and echo chambers 2021.
A filter bubble occurs when algorithms systematically reduce exposure to diverse information, prioritizing content that perfectly aligns with a user's prior interactions 2122. An echo chamber is the social consequence of this filtering: an environment where individuals predominantly engage with like-minded voices, amplifying shared ideological perspectives while marginalizing dissenting views 21.
In a recent analysis of over 16 million TikTok videos spanning the 2019 to 2023 US election cycles, network mapping revealed highly distinct clusters of politically homogeneous networks 2324. Within these political echo chambers, users were systematically fed attitude-consistent content, and those receiving positive social feedback were highly likely to escalate their own political expression, further reinforcing the bubble 2324. Similar dynamics of homophily (the tendency to associate with similar individuals) were starkly illustrated in comparative studies of Parler and Twitter; users on platforms with overwhelming majority opinions exhibited longer retention and higher stability, while users exposed to dissent often migrated away entirely 25.
The algorithms also adapt to geopolitics. An online survey examining Douyin usage in Taiwan found that users identifying as Chinese and supporting political unification were significantly more likely to utilize the China-based platform and reside within its specific partisan echo chambers, highlighting the political consequences of authoritarian-led media environments on democratic populations 26.
The Efficacy of the Bubble: Does It Change Beliefs?
Despite the pervasive anxiety surrounding the "personalization-polarization hypothesis," the academic community is sharply divided on the actual power algorithms hold over deep-seated human beliefs.
Some sociologists warn that well-intentioned efforts to manually "pop" filter bubbles by forcibly exposing users to opposing viewpoints can actually backfire 20. Empirical models suggest that introducing highly foreign ideological opinions triggers "negative influence" or repulsion, causing users to retreat further into their extremes 20.
Furthermore, the direct causal link between algorithmic recommendations and real-world polarization is heavily debated. In 2025, a massive study published in the Proceedings of the National Academy of Sciences (PNAS) utilized a custom-built, naturalistic video platform mimicking YouTube to experimentally manipulate the recommendations of nearly 9,000 participants 27. The researchers intentionally forced users into heavy-handed algorithmic "rabbit holes" and filter bubbles. The results cast serious doubt on prevailing alarmist theories: the short-term exposure to these intense algorithmic manipulations had no detectable, consistent causal effect on users' actual policy attitudes 27. The researchers concluded that the burden of proof for claims regarding algorithm-induced political polarization must now be shifted, suggesting that algorithms are highly effective at capturing attention but much less effective at fundamentally rewiring human beliefs 27.
Additionally, some researchers point out that filter bubbles are not intrinsically negative. For marginalized communities or citizens living in nations with restricted press freedom, algorithmic isolation can serve as a "protective filter bubble," creating vital digital safe spaces free from harassment and state monitoring 22.
Strategies to Disrupt the Loop and Re-train Algorithms
Given the overwhelming influence of the human-AI feedback loop, users, researchers, and regulators are actively seeking methods to disrupt the algorithmic cycle and reclaim agency over digital feeds.
User-Level Audits and The "Not Interested" Efficacy
Most platforms offer user-interface controls purportedly designed to correct algorithmic mistakes, such as "Not Interested" or "Don't Recommend Channel" buttons. However, their actual efficacy has historically been shrouded in secrecy.
To test these tools, researchers conducted a massive "sock-puppet audit" of YouTube's algorithm. They deployed pre-programmed automated agents to simulate human users 2829. The agents first executed a "stain phase," binge-watching specific topics (like misinformation) to deeply bias the algorithm 2830. Next, the agents initiated a "scrub phase," repeatedly applying negative feedback tools to try and burst the bubble 2931.
The results were highly specific: clicking the "Not Interested" button was the single most effective strategy for cleaning the homepage, successfully removing an average of 88% of the targeted topic recommendations 2829. However, neither the initial staining nor the subsequent scrubbing had any significant effect on the "videopage recommendations" - the "Up Next" videos presented while a user is actively watching content 2829. Alarmingly, a corresponding survey of 300 adults revealed that 44% of users were completely unaware that the highly effective "Not Interested" button even existed 2830.
Recognizing widespread user frustration, platforms have begun offering algorithmic "nuclear options." In late 2025 and early 2026, Instagram globally launched a "Reset Suggested Content" feature, allowing users to wipe their algorithmic history across Explore, Reels, and their primary feed, effectively reverting the account to a blank-slate "cold start" 6348. TikTok features a similar "Refresh your For You feed" capability 3250. However, resetting an algorithm is only half the battle. Because the system immediately resumes its feedback loop, users must spend the critical 48 hours post-reset engaging heavily with desired topics and aggressively skipping irrelevant content to properly train the new model 6350.
Platform-Level and Regulatory Interventions
Systemic changes to the feedback loop require platform-level interventions. Studies have demonstrated that inserting friction into the virality cycle works. Research from Yale University analyzing the "Community Notes" feature (a crowd-sourced fact-checking framework) found that attaching a warning label to misleading content significantly reduces its algorithmic momentum 33. When a note was attached, posts saw an average of 46% fewer reposts and 44% fewer likes, effectively stopping the misinformation from penetrating deeply into networks - acting, as researchers noted, like a bush that grows "wider, but not higher" 33.
Similarly, Stanford researchers successfully designed a web-based tool capable of downranking anti-democratic and hostile partisan posts on social media without removing the content entirely. In an experimental setting during the 2024 elections, exposure to this downranked, less antagonistic feed successfully improved users' attitudes toward opposing political parties, proving that algorithmic de-escalation is technically feasible 34.
Governments are also attempting to force transparency. In 2026, US legislators introduced bills requiring platforms to submit comprehensive disclosures of their algorithmic weights, specifically demanding explanations for how engagement metrics like watch time and shares are coded 35. Concurrently, the European Union's AI Act introduced risk-based regulation and compliance models that legally obligate social media operators to take preventative action against the risks their algorithms pose, enforcing heavy financial penalties for enabling broadcast disinformation campaigns 36.
Incorporating Human-in-the-Loop (HITL) Architectures
The ultimate safeguard against runaway recommendation algorithms is the integration of Human-in-the-Loop (HITL) workflows. In commercial AI deployment, a model's release is never the final step; it requires continuous retraining, evaluation, and human oversight to manage the inevitable data drift and edge cases 437.
A sophisticated HITL pipeline does not merely use humans for basic content moderation. Instead, humans serve distinct, structural roles: as validators checking pre-action outputs, as editors contextualizing data, as deciders for high-risk edge cases, and as teachers providing nuanced training signals 38. For example, the HIVE framework for explainable recommender systems actively collects "veracity-based human feedback." By grading AI recommendations on both "fidelity" (factual accuracy) and "attunement" (user preference alignment), human operators continually update the user and item embeddings within the neural network, ensuring the algorithm does not collapse into a hallucination or an extreme bias loop 39. Integrating structured human oversight prevents the mathematical drive for engagement from wholly superseding accuracy and safety.
Bottom line
Recommendation algorithms dictate modern virality through a relentless human-AI feedback loop, instantly adjusting to passive behavioral signals like completion rates and swipe velocity. While optimizing for these metrics successfully captures user attention, it mathematically favors emotionally polarizing content, inadvertently constructing structural echo chambers. However, emerging research suggests these filter bubbles may be less effective at altering deep-seated beliefs than previously feared. Ultimately, while platform-level resets and "Not Interested" buttons offer temporary relief, reclaiming agency over a digital feed requires users to remain hyper-vigilant about the behavioral data they continuously feed the machine.