How GPT-5.6, Claude Sonnet 4.8, and Gemini 3.5 Pro Compare
The June 2026 artificial intelligence market is witnessing an unprecedented convergence as three frontier models prepare to reshape enterprise workflows. Google's Gemini 3.5 Pro targets deep reasoning and massive document ingestion, while highly credible developer leaks point to OpenAI's GPT-5.6 and Anthropic's Claude Sonnet 4.8 prioritizing autonomous coding agents. For businesses, deciding between these platforms now hinges on token economics, specific agentic capabilities, and verifiable hallucination rates rather than generic chat performance.
The Collapse of the AI Release Cycle
If you are waiting for a stabilized plateau in AI model development to build your next application, the current market dynamics suggest that plateau is not coming anytime soon. The most significant shift in the 2026 artificial intelligence landscape is not just the raw intelligence of the models, but the extreme compression of their release cycles.
Looking at the chronological timeline of AI development, the gap between frontier model releases has compressed from over a year in early 2025 to a matter of weeks by mid-2026. A clustering of major releases from OpenAI, Anthropic, and Google is now occurring simultaneously across April, May, and June 2026. A few years ago, the technology sector waited nearly three years to jump from GPT-3 to GPT-4, and well over a year to reach GPT-5 1. Now, the iteration cycle for major frontier model versioning has collapsed to a staggering 30 to 45 days 12.
OpenAI shipped GPT-5.5 on April 23, 2026, positioning it as a major leap in agentic workflows and intuitive intelligence 2. Yet, within barely three weeks, active evidence of GPT-5.6 development appeared in production logs 23. Anthropic has mirrored this aggressive pacing, releasing Claude Opus 4.7 in mid-April and following it up with its successor, Opus 4.8, just over a month later on May 28, marking an incredibly short 42-day gap between flagship iterations 45.
This acceleration is not merely a marketing blitz. It reflects a profound qualitative change in how these companies handle reinforcement learning cycles, automated auditing, and model architecture optimization 1. With Anthropic recently securing a $65 billion funding round that values the company at nearly $1 trillion - surpassing OpenAI's most recent valuation - the June 2026 convergence of Gemini 3.5 Pro, GPT-5.6, and Claude Sonnet 4.8 represents the most intense technical arms race the industry has ever seen 238.
Google's Gemini 3.5 Pro: The Long-Context Heavyweight
Google has historically faced challenges with its model tier messaging, but the Gemini 3.5 rollout strategy is ruthlessly clear. At the Google I/O developers conference on May 19, 2026, CEO Sundar Pichai immediately released the Gemini 3.5 Flash model, while explicitly holding back the flagship Gemini 3.5 Pro for a June 2026 general availability 94. When Pichai asked the live audience to "give us until next month to get it to you," the crowd reportedly groaned, highlighting the intense market anticipation for Google's true flagship 91112.
Why Flash Shipped First
The reason for the staggered launch reveals exactly what Pro is built to do. Gemini 3.5 Flash is currently a speed and efficiency powerhouse. It already beats the older Gemini 3.1 Pro on crucial coding, tool use, and agentic benchmarks. For example, on Terminal-Bench 2.1, 3.5 Flash scored 76.2% compared to 3.1 Pro's 70.3%, and on the MCP Atlas tool-use benchmark, it hit 83.6% against 3.1 Pro's 78.2% 11125. Furthermore, it accomplishes this at four times the speed of competing frontier models 45.
However, the Flash architecture made deliberate engineering trade-offs to achieve those speed and cost numbers. While it excels at fast, agentic tasks, Flash regressed on hard scientific reasoning and long-context retrieval depth compared to the older Pro models 12. Google's strategic repositioning signals that Flash is no longer a "cheap alternative" but the default tier for agent-first developers, while Pro is reserved for tasks requiring extreme cognitive depth 5.
The 2-Million Token Enterprise Promise
Gemini 3.5 Pro exists entirely to close that reasoning gap. Targeting a massive 2-million token context window, "Deep Think" reasoning capabilities, and frontier multimodal understanding, Pro is designed to absorb the heavyweight enterprise tasks that Google previously routed to its discontinued "Ultra" tier 9.
For enterprise developers, Gemini's native integration into the Google Cloud Vertex ecosystem, Google Workspace, and Android makes it an highly attractive default for massive document processing and ecosystem-native workflows 1415. If Gemini 3.5 Pro can match Flash's agentic speeds while restoring Google's lead in complex multimodal analysis - such as native video and audio understanding powered by Google's new Omni and Spark systems - it will solidify its position as the ultimate model for research and data-heavy corporate workflows 9166. As of late May 2026, Gemini 3.5 Pro is in limited internal use and Vertex preview for select enterprise customers, with its general release acting as the linchpin of Google's summer strategy 9.
OpenAI's GPT-5.6: The Agentic Canary Leak
OpenAI has not officially announced GPT-5.6, and the company has offered no public release dates 2. However, the model has become the worst-kept secret in Silicon Valley. Only three weeks after the April 23 launch of GPT-5.5, developers spotted a model routed as gpt-5.6 in OpenAI's Codex backend logs 1318.
The Codex Backend and "Iris-Alpha"
This backend discovery was the result of "canary testing" - a standard industry practice where a tiny fraction of real production traffic is quietly routed to an experimental build to measure performance and behavior before a wider rollout 319. The fact that this leak occurred specifically within the Codex environment suggests that GPT-5.6 is explicitly engineered for software engineering, debugging, and agentic coding workflows rather than general conversational chat 314.
Leakers and independent reports have identified several internal testing codenames for the GPT-5.6 variants, including "iris-alpha", "ember-alpha", and "beacon-alpha" 11418. The presence of multiple alphas suggests OpenAI is evaluating different model weights simultaneously, with rumors pointing heavily toward a dual-release strategy: a standard GPT-5.6 focused on multi-step reasoning, and a GPT-5.6 Pro version designed specifically for advanced, autonomous agent workflows 119.
The "Goblin Incident" and RLHF Retraining
The speed of this development cycle - moving to a 5.6 designation just weeks after 5.5 - has raised eyebrows. Industry researchers and analysts attribute this rapid pivot to an internal architectural issue within OpenAI's reinforcement learning from human feedback (RLHF) loops, colloquially termed the "goblin incident" 3.
This issue allegedly involved how RLHF feedback loops compounded negatively across training runs, requiring a massive technical effort to audit past reward signals, identify contaminated supervised fine-tuning (SFT) data, and retrain the reward model 3. Consequently, GPT-5.6 is heavily anticipated to be the first major model version trained entirely on this redesigned, post-incident reward audit pipeline, which explains why testing is moving faster than the previous GPT-5.4 to 5.5 cycle 3.
Front-End Generation and the 1.5M Context Window
According to leaked test conversations and backend data exposed through auxiliary tools like OpenCode, the "iris-alpha" variant of GPT-5.6 features a 1.5-million token context window 118. This is a nearly 43% increase over the GPT-5.5 API's 1.05-million token limit 18. In extreme real-world tests, developers reported that the model could smoothly handle inputs reaching 900,000 tokens, and even processed overload requests exceeding 1.05 million tokens without breaking 118. This massive window is specifically tailored for ingesting entire codebases, long legal contracts, and facilitating long-term multi-step workflows.
Beyond pure text capacity, GPT-5.6 is reportedly bringing a revolutionary evolution to front-end interface generation. Leaked screenshots show the model generating a highly polished, minimalist note-taking application interface called "Lumen Notes" without requiring any extra UI guidance or detailed prompting 1820. This "de-slopped" generation represents a leap away from the generic, gradient-heavy dashboards typically produced by earlier AI models, indicating a much deeper understanding of modern design aesthetics and functional software architecture 2021.
Anthropic's Claude Sonnet 4.8: The Coding Workhorse
Anthropic has cultivated fierce loyalty among software engineers by consistently offering some of the best coding models on the market. However, heading into June 2026, their product numbering convention has caused significant confusion among users.
Search volume for "Claude Sonnet 4.7" spiked throughout the spring, but the model does not exist and never will 22. Anthropic has officially broken its historical pattern of pairing Opus and Sonnet minor versions 7. While Opus 4.7 launched in mid-April, the company skipped Sonnet 4.7 entirely 227. The next mid-tier model will be Claude Sonnet 4.8, a fact the public learned not through a press release, but through a massive internal mistake.
The npm Package Source Map Leak
On March 31, 2026, a source map file accidentally shipped inside the npm package for Claude Code - Anthropic's autonomous coding agent that runs directly inside developer CLI terminals 724. This packaging error exposed roughly 512,000 lines of TypeScript source code across 1,900 files 24.
For developers, a source map leak of this magnitude is a goldmine. It revealed how the application is structured behind the scenes, exposing internal logic, hidden references, tool behavior, and pieces of Anthropic's unreleased product roadmap 24. Among these references were explicit strings for sonnet-4-8 and opus-4-8 alongside feature flags for background agent behavior and future automation systems 5724.
Why There Is No Sonnet 4.7
The skip from 4.6 directly to 4.8 is highly unusual for an AI lab, leading to intense speculation. The most credible technical explanation is that Anthropic's version numbers reflect internal development milestones and specific training runs rather than a requirement for strict parity between model tiers 22. The leaked code suggests that Sonnet 4.8 involves much more substantial architectural changes than a simple port of Opus 4.7's capabilities, essentially rendering a 4.7 release obsolete before it could ship 227.
Because the leak occurred within Claude Code, it is clear that Sonnet 4.8 is being optimized not just as a chatbot, but as a background agent capable of executing real work across local file systems 2425. Anticipated upgrades include cleaner code edits, superior instruction following, and the integration of advanced vision capabilities, bringing Sonnet in line with the visual acuity recently seen in the Opus tier 2225.
The Opus 4.8 Precursor and a $965 Billion Valuation
If anyone doubted the validity of the 4.8 leak, Anthropic silenced them on May 28, 2026, by officially launching Claude Opus 4.8 528. The release of the flagship Opus model strongly signals that Sonnet 4.8 is imminent.
Opus 4.8 was explicitly marketed around "honesty and reliability." Anthropic claims the new model is roughly four times less likely than its predecessor to let flaws in its own generated code pass unremarked 428. It also launched alongside a "Dynamic Workflows" research preview in Claude Code, an experimental feature that allows the model to plan work and subsequently orchestrate hundreds of parallel sub-agents in a single session to handle codebase-scale migrations 488.
The release of Opus 4.8 was accompanied by monumental financial news: Anthropic closed a $65 billion funding round, catapulting its valuation to $965 billion 38. This staggering valuation, combined with a separate enterprise rollout of a highly restricted cybersecurity model called "Claude Mythos," proves that Anthropic is aggressively targeting enterprise dominance and preparing for a potential public listing 81420.
Feature Breakdown and Technical Specifications
To understand how these three frontier models stack up heading into the June 2026 release window, we must evaluate them across their expected capabilities, context limits, and primary strengths.
| Specification | GPT-5.6 (Expected/Leaked) | Claude Sonnet 4.8 (Expected/Leaked) | Gemini 3.5 Pro (Preview/June GA) |
|---|---|---|---|
| Developer Lab | OpenAI | Anthropic | Google DeepMind |
| Release Status | Unannounced; Canary testing | Unannounced; Source code leaks | Vertex Preview; GA expected June |
| Context Window | 1.5 Million tokens | 1 Million+ tokens | 2 Million tokens |
| Estimated Pricing | Unconfirmed | ~$3.00 In / $15.00 Out (per 1M) | Unconfirmed (Flash is $1.50 / $9.00) |
| Primary Strength | Agentic workflows, front-end UI generation, deep multi-step reasoning | Sustained coding, CLI agents, instruction following, codebase migrations | Deep multimodal research, vast document ingestion, Google ecosystem |
| Key Integrations | OpenAI Codex, ChatGPT | Claude Code (CLI), Claude Team | Google Workspace, Vertex AI, Gemini Spark, Android Studio |
The Economics of Tokens and the Enterprise Budget Crisis
While benchmark victories and context windows dominate the headlines, the defining enterprise story of 2026 is the API pricing crisis. The sheer cost of token billing is actively breaking enterprise AI budgets, creating a fundamental shift in how companies procure and deploy artificial intelligence 9.
Usage-Based Billing Shocks
The crisis came to a head when major platforms began transitioning away from predictable flat-rate subscriptions. On June 1, 2026, Microsoft-owned GitHub Copilot shifted its AI coding assistant from flat-rate pricing to usage-based billing tied directly to token consumption 9. For developers running highly agentic, long-horizon coding tasks, the price shock was immediate. One developer reported their projected monthly cost rising from roughly €67 in April to around €966 under the new token model 9.
This is not an isolated incident for independent developers; massive corporations are feeling the burn. Uber Technologies' CTO recently confirmed that the company burned through its entire 2026 AI budget in just four months 9. The primary driver of this massive expenditure was the explosive adoption of Claude Code, which jumped from 32% to 84% among its 5,000-engineer organization. Monthly API costs per engineer skyrocketed to between $500 and $2,000, forcing the company "back to the drawing board" on how it budgets for software engineering 9.
DeepSeek V4 and the Multi-Model Routing Strategy
This economic reality is fundamentally changing how companies build AI architectures. It is no longer viable to default exclusively to premium models like GPT-5.6 or Claude Opus 4.8 for every single query in an automated pipeline 2829.
The market disruption was accelerated by the Chinese AI lab DeepSeek, which released DeepSeek V4 in late April 2026 1430. DeepSeek V4 is an open-weight model whose "Pro" version trails the best western closed models by only 3 to 6 months in capability, but costs a microscopic fraction of the price 14. When DeepSeek made its launch discount permanent, it undercut the $5/$25 per million token rate of western flagships so severely that it forced a reckoning across the industry 1429.
Consequently, the most effective production systems in 2026 rely on an intelligent "model routing layer" 142829. Sophisticated engineering teams are building logic that sends each task to the right model based on complexity, cost, and latency tolerances.
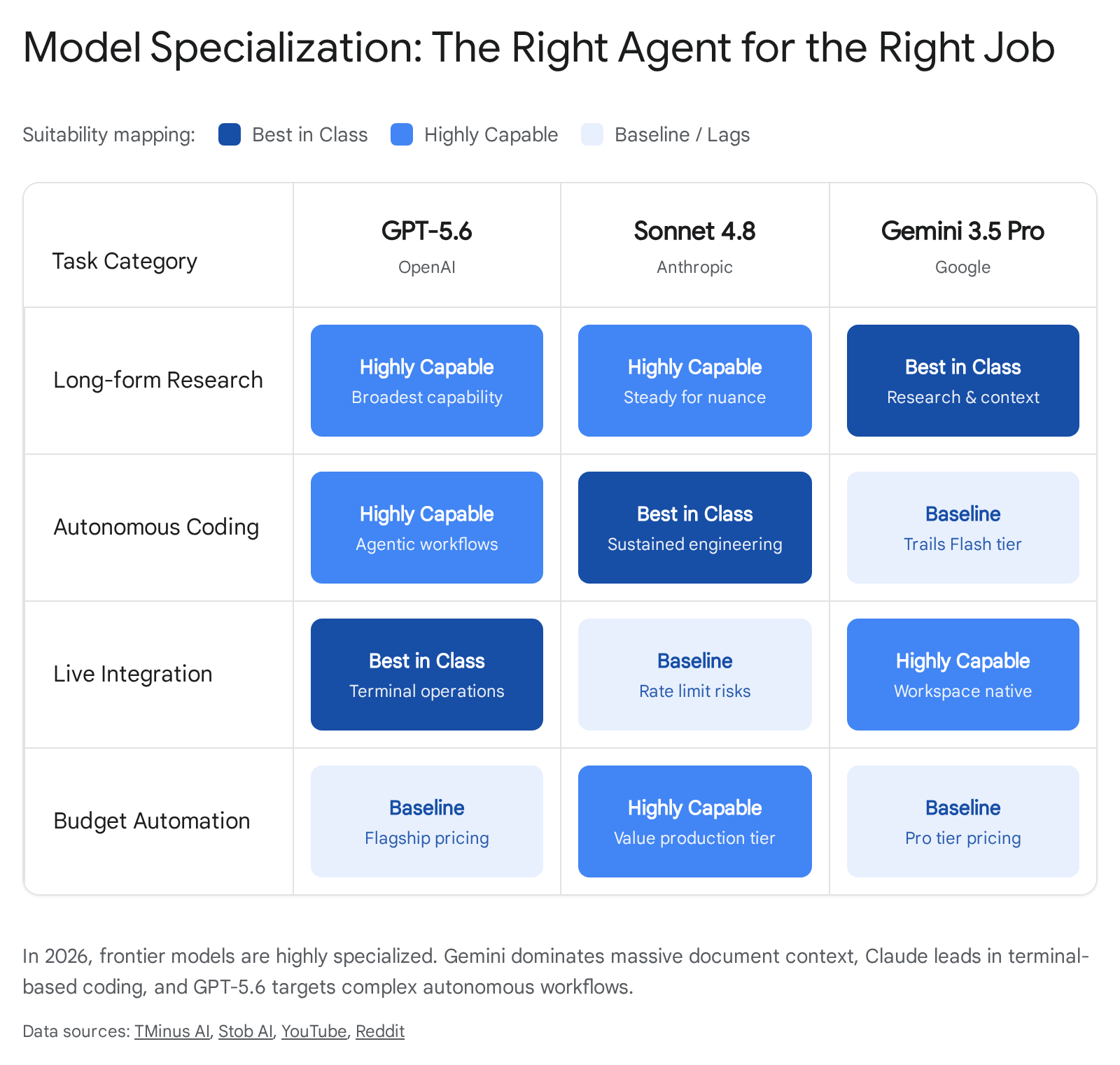
In practice, this means routing Anthropic's Claude for the hardest code reasoning and long-document nuanced writing, OpenAI's GPT for agentic terminal work and complex instruction following, Google's Gemini for deep research and ecosystem integration, and DeepSeek (or Gemini Flash-Lite) for high-volume, repetitive background triage tasks 14282931.
The Hallucination Reality Check in 2026
Regardless of 2-million token context windows and autonomous coding prowess, the single biggest barrier to unmonitored enterprise AI adoption remains the persistent hallucination problem. Generative AI, by its very design, cannot be entirely hallucination-free, and treating it as an infallible oracle remains a fast track to corporate liability 10.
In a comprehensive April 2026 benchmark testing 5,000 prompts across top frontier models, overall hallucination rates sat between 3.1% and 19.1% depending on the specific model, task family, and reasoning configuration 33. While this represents a massive, sustained improvement from the 15-45% error baselines seen in 2024, it is still measurably non-zero 33.
The Gemini Paradox vs. The Claude Refusal
The approach to handling factual uncertainty diverges wildly between the major providers, creating distinct personality profiles for each model.
Google's Gemini 3 Pro family suffers from a phenomenon researchers call the "Gemini Paradox" - it is routinely the most knowledgeable model, scoring highest on raw factual benchmarks, but it is simultaneously the least self-aware 10. When a Gemini model encounters the limits of its parametric knowledge, it attempts to answer anyway, resulting in catastrophic hallucination rates when ungrounded. For example, an earlier version of Gemini 3 Pro hallucinated 88% of the time when it didn't actually know an answer 10. (Notably, Google drastically improved this in the 3.1 Pro update, dropping that specific hallucination rate by 38 percentage points) 10.
In stark contrast, Anthropic has calibrated its Claude models to refuse rather than guess. Because of its Constitutional AI training, when Claude does not know a fact, it is structurally inclined to admit ignorance 34. This resulted in Claude 4.1 Opus achieving an unprecedented 0% hallucination rate on the AA-Omniscience knowledge task benchmark, simply because it declined to answer uncertain queries 10. The recent Opus 4.8 release doubled down on this philosophy; Anthropic specifically tuned it to flag uncertainties about its own work and reduce unsupported claims 88. For legal, medical, and compliance workloads where a fabricated answer is vastly more dangerous than a refusal, Claude's approach is structurally safer 1034.
OpenAI's GPT-5.5 utilizes advanced reinforcement learning to sit comfortably between these extremes. Utilizing its extended "thinking" modes, GPT-5.5 Pro established the baseline floor in recent factual tests, achieving a remarkable 4.2% hallucination rate on factual recall, making it a highly reliable engine for verifiable tasks like structured data extraction 3334.
Citation Fabrication and the Safety Illusion
If there is one area where all frontier models universally fail in 2026, it is citation accuracy. When asked to provide academic references, legal precedents, or news sources, models invent DOIs, paper titles, author names, and journal references at terrifying rates 33.
Citation accuracy is the single worst-performing task family across the frontier, with top models hallucinating references between 6.8% and 19.1% of the time 33. A Columbia Journalism Review study found that generative search tools gave incorrect answers on more than 60% of tested news-citation queries, while Stanford's HAI noted that purpose-built legal AI tools hallucinated up to 34% of the time on challenging legal research 3536.
| Hallucination Benchmark Metric (April 2026) | Performance / Rate | Context & Details |
|---|---|---|
| Best Factual Recall Rate | 4.2% | Achieved by GPT-5.5 Pro with extended thinking enabled 33. |
| Worst Citation Fabrication Rate | 19.1% | Average failure rate across frontier models for inventing DOIs and sources 33. |
| Code-Reference Hallucinations | 3.1% to 15.4% | Invention of phantom imports, APIs, and signatures 33. |
| Gemini "Uncertainty" Error Rate | 50.0% | Gemini 3.1 Pro's hallucination rate when forced to answer outside its knowledge 10. |
| Claude Knowledge Error Rate | 0% | Claude 4.1 Opus score on AA-Omniscience due to strict refusal behaviors 10. |
Furthermore, modern AI models still struggle with basic epistemology - specifically, the difference between knowledge and belief. Stanford's 2026 AI Index Report highlighted a new accuracy benchmark where hallucination rates across 26 top models ranged from 22% to 94% depending on the framing 11. When a false statement was presented as something another person believes, models handled it well. But when the exact same false statement was presented as something the user believes, model performance collapsed, with GPT-4o's accuracy dropping from 98.2% to 64.4% 11.
The Multilingual and Dialect Penalty
The hallucination problem is also heavily skewed by language. AI works best in English, and the performance gap is much wider than global capability benchmarks generally suggest 11.
A recent study evaluating 30 European languages utilizing the MultiWikiQA dataset exposed severe linguistic disparities 38. Smaller open-source models, like Qwen3-0.6B, exhibited alarming hallucination rates of up to 60% when dealing with lower-resource languages like Icelandic 38. Even among the largest frontier models, dialect-level nuances cause catastrophic failures. On a Slovenian commonsense reasoning test, several leading models lost close to half their accuracy when tested in a regional dialect rather than the standard language 11.
Mitigations: RAG, Web Search, and SLM Detectors
Because the models themselves cannot be fully trusted, the industry has shifted away from trying to build perfect base models and toward building perfect "defense-in-depth" architectures.
The data proves that web search access is the single biggest variable in reducing basic factual hallucinations, cutting error rates by 73% to 86% when enabled 10. However, web search does not solve multi-turn reasoning failures, leading enterprise CTOs to implement layered verification 35.
Rather than paying the "Frontier Tax" to use an expensive model like GPT-5.6 to check its own work (which doubles API costs and adds massive latency), modern architectures utilize Small Language Models (SLMs). A self-hosted SLM detector, acting as a judge, can handle the bulk of factual traffic verification for a fraction of the cost, reserving the heavy, expensive reasoning models only for highly ambiguous, low-confidence edge cases 39.
For accuracy-critical workloads in 2026, the only responsible stack combines a reasoning model like GPT-5.5 Pro or Claude Opus 4.8, retrieval grounding against an actual source database, and strict human-in-the-loop verification on a sampled share of outputs 33.
Bottom line
The June 2026 AI release window marks the definitive end of the "general-purpose chatbot" era and the dawn of specialized, highly autonomous agent systems. Google's Gemini 3.5 Pro is positioning itself to dominate massive-scale document reasoning and native ecosystem integration, while the heavily leaked GPT-5.6 and Claude Sonnet 4.8 will fight a fierce battle for supremacy over software engineering environments and background task execution. What remains uncertain is how the enterprise market will absorb the spiraling token costs required to run these highly capable agents, and whether the persistent, dangerous issue of citation hallucinations can be solved without relying entirely on external retrieval and verification architectures.