Architecture of Multimodal Vision and Language Models
Introduction to Vision-Language Processing
The transition from unimodal natural language processing to multimodal artificial intelligence represents a structural paradigm shift in machine learning. Early large language models (LLMs) were restricted to textual input and output, severely limiting their capacity to interpret real-world information. Multimodal Large Language Models (MLLMs), or Vision-Language Models (VLMs), integrate distinct data modalities - such as text, images, audio, and video - into a shared semantic space, enabling models to reason across diverse information formats 122. This integration is achieved by combining domain-specific encoders with language model backbones, either through sequential "stitching" of pre-trained models or through native, end-to-end multimodal training 345.
The development of these models is driven by the necessity to process complex, interrelated data types found in real-world environments. For instance, in clinical decision-making, the combination of structured tabular data, unstructured physician notes, radiological imaging, and continuous signal data (such as electrocardiograms) provides a significantly more comprehensive diagnostic profile than any single modality 6. Multimodal approaches have been shown to outperform unimodal algorithms in the vast majority of clinical tasks, highlighting the critical importance of cross-modal reasoning 6. Similar necessities exist in autonomous robotics, document parsing, and geospatial intelligence 8.
Despite substantial advancements in benchmark performance, MLLMs continue to face severe architectural bottlenecks. The primary challenges include the computational cost of processing high-resolution visual tokens, the optimal integration method for varying data modalities, and the persistent issue of modality interference. In cases of modality interference, models default to learned language priors rather than grounding their responses in the provided visual or auditory evidence, resulting in hallucinations 7108. Analyzing the underlying mechanics of visual tokenization, projection strategies, and the specific architectures of frontier models like GPT-4o, Gemini 1.5 Pro, Qwen2.5-VL, and InternVL 2.5 provides a comprehensive understanding of how current multimodal artificial intelligence operates.
Visual Tokenization and Embedding
Language models operate exclusively on discrete tokens represented as high-dimensional vectors 910. Because images consist of continuous grids of pixels, they cannot be directly processed by a transformer architecture built for discrete sequential data. To bridge this gap, multimodal models employ a visual tokenization pipeline that translates continuous pixel data into a discrete token format compatible with the language model's embedding space 11.
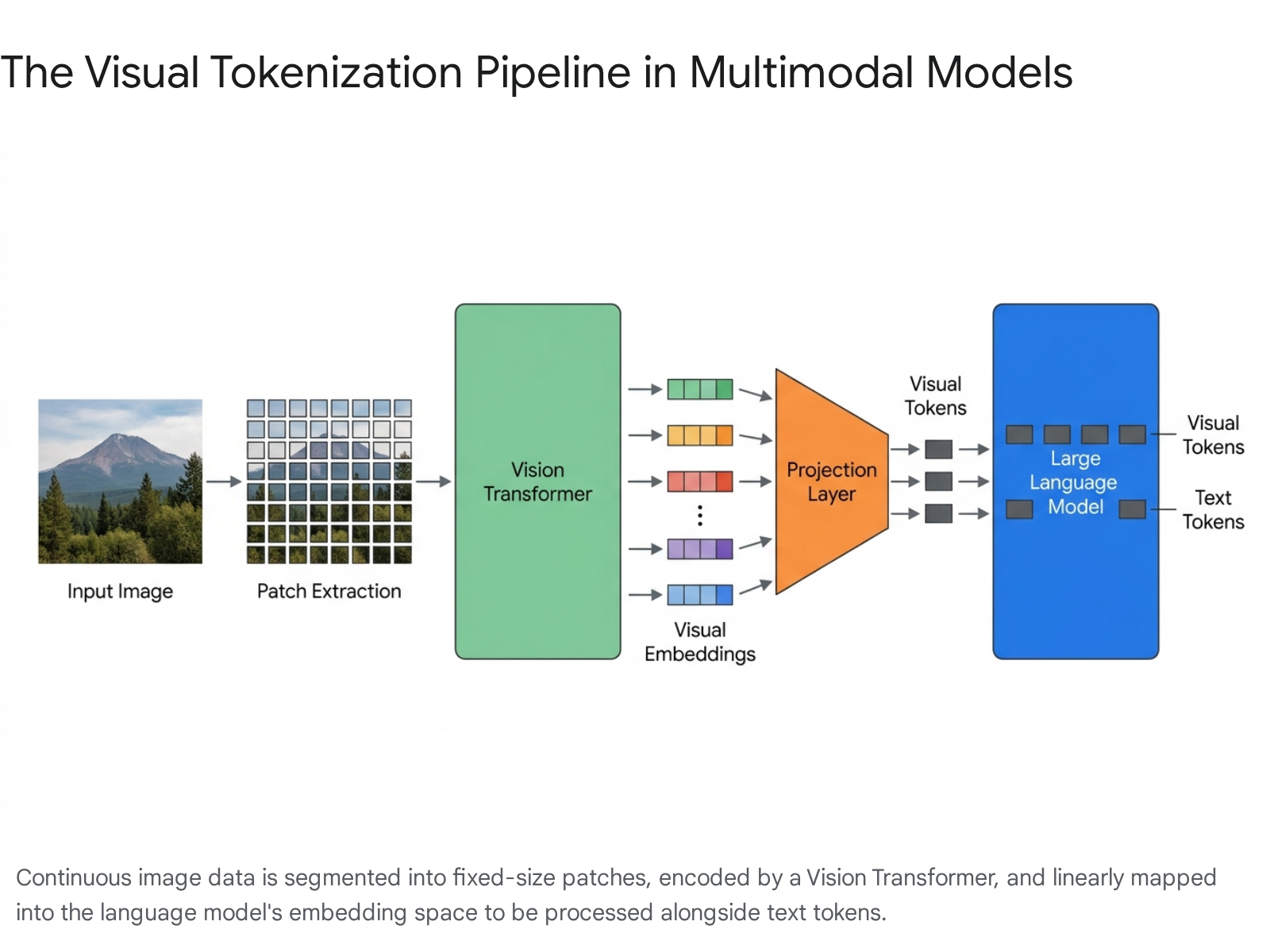
Pixel Decoding and Patch Extraction
A common misconception regarding multimodal processing is that language models directly interpret the base64 encoded string of an image file 10. In reality, language models never read the base64 string, as treating image data as standard text characters would instantly overwhelm any context window; a standard high-resolution image would consume hundreds of thousands of textual tokens 10. Instead, when an image is supplied via an application programming interface, it is first decoded into a raw pixel grid of RGB values 10.
The image is then resized to fit the model's internal resolution constraints and divided into a sequence of non-overlapping square patches, typically measuring 1414 or 1616 pixels 101112. This patch extraction is fundamentally different from human visual perception. An image of a street scene, for instance, is fractured such that a traffic light might span multiple disconnected patches, requiring the neural network to computationally reconstruct the concept of the object from fragmented geometric and textural data 11.
The Vision Transformer Pipeline
Once the continuous image is divided into patches, a Vision Transformer (ViT) acts as the primary image tokenizer 913. Each extracted patch is flattened and linearly projected into a high-dimensional vector. In standard ViT architectures, a special [CLS] (classification) token is prepended to the sequence of patch embeddings 1217. The entire sequence is then processed through multiple Transformer encoder blocks containing multi-head self-attention mechanisms and feed-forward networks 12.
Within these layers, the self-attention mechanism allows each individual patch to attend to every other patch, enabling the model to capture global spatial context, structural patterns, and relationships across the entire image 1217. The visual embeddings produced by the ViT are essentially dense geometric coordinates in a highly dimensional feature space. Crucially, the ViT does not possess natural language understanding; it does not assign explicit semantic labels like "cat" or "vehicle" to the image 13. It operates strictly as a geometric feature extractor, compressing visual structure into embeddings, while the language model backbone performs the actual cognitive reasoning and semantic translation 13.
Computational Bottlenecks in High-Resolution Processing
A significant constraint across all vision-language architectures is the severe computational bottleneck imposed by high-resolution image tokenization. Standard uniform patch extraction treats all areas of an image equally 14. While a low-resolution 224*224 image generates a manageable 196 patches, processing high-resolution images or extended video sequences generates an unwieldy number of tokens. Because transformers utilize self-attention mechanisms where computation scales quadratically with the sequence length, treating high-resolution grids uniformly leads to prohibitive inference costs and extreme latency 811.
If a model attempts to bypass this by aggressively downscaling the image before patch extraction, critical fine-grained details - such as small text in a document or distant objects in a landscape - are permanently lost 1114. To address this inherent tradeoff, advanced architectures implement dynamic resolution and dynamic patch sampling. Frameworks like the Token-Efficient Vision Language Model (TEVA) introduce a region proposal module that identifies subject-oriented areas 14. TEVA dynamically samples high-resolution patches only from these specific areas of interest, while relying on low-resolution patches to maintain global context . Similarly, hierarchical self-attention layers can iteratively select a subset of high-resolution tokens based on an initial low-resolution attention map, effectively shrinking computational costs by nearly 40% without sacrificing critical details 15.
Modality Projection and Alignment Strategies
After the Vision Transformer processes the image, the resulting visual tokens exist in the specific vector space of the visual encoder. Language models, however, operate in entirely different vector dimensions 9. To align these disparate dimensional spaces, multimodal models rely on a projection layer - often referred to as a vision-language adapter - that maps the visual embeddings into the language model's token space 913.
Multi-Layer Perceptron Adapters
The most straightforward architectural approach to projection relies on Multi-Layer Perceptrons (MLPs). Early frameworks like LLaVA 1.5, as well as contemporary models like InternVL 2.5 and Qwen-VL2, utilize simple linear projection layers or two-layer hybrid MLPs 161723. In this paradigm, visual features from the ViT are projected into the embedding space of the LLM and directly concatenated to the input sequence of the text decoder 1317.
MLP adapters are highly effective at preserving exact spatial relationships and fine-grained token alignments, allowing the language model to apply full attention to the visual tokens 17. However, this method provides minimal control over the ultimate sequence length. Because the raw, high-dimensional visual features are used directly without pooling or downsampling, the LLM must process a massive influx of visual tokens, heavily taxing the model's maximum context window and computational resources 1617.
Perceiver Resampler Architectures
To mitigate the quadratic complexity of long visual sequences, distinct architectures - most notably DeepMind's Flamingo and subsequent models like Idefics - employ a Perceiver Resampler 171825. The Perceiver Resampler serves as an attention-based pooling mechanism designed to convert a variable and potentially massive number of input embeddings into a fixed, much smaller array of latent output tokens 172619.
Architecturally, the Perceiver Resampler introduces a fixed number of learnable latent queries. Inside the module, these latent vectors serve as queries, while the flattened visual features from the ViT - combined with temporal positional encodings - serve as keys and values in a cross-attention mechanism 1928. This allows the resampler to selectively extract the most relevant information from a vast array of image patches or video frames, distilling the data into a strict token budget (e.g., 64 or 256 tokens) regardless of the original image resolution 2930. While the Perceiver Resampler successfully stabilizes sequence lengths and enables efficient video processing, the aggressive compression can occasionally discard crucial high-resolution details required for precision tasks like dense document parsing 1426.
Structural Paradigms in Multimodal Systems
The architectural methodology for integrating distinct modalities into a single computational system broadly divides into two dominant strategies: modality-stitched architectures, also known as late fusion, and native multimodal models, known as early fusion 3420.
Modality-Stitched Architectures (Late Fusion)
Modality-stitched models are constructed by taking separately pre-trained unimodal models - such as a robust off-the-shelf image classifier and an autoregressive text LLM - and connecting them via a newly trained projection module 42021. This modular, late-fusion approach is historically common because it leverages the vast parametric knowledge already embedded in models trained on billions of parameters, significantly reducing the compute required to train the vision-language system from scratch 2022.
However, stitching high-capacity unimodal models together does not inherently guarantee optimal multimodal performance. Research indicates that the parametric capacity of a unimodal model is an unreliable predictor of its performance once stitched into a multimodal framework; often, smaller models specifically tuned for alignment outperform combinations of massive, misaligned models 20. Furthermore, late-fusion architectures inherently segregate data processing. Text and images are processed in isolated silos until the final layers of the network, which frequently causes the model to miss nuanced cross-modal interactions, such as spatial relationships described contextually by adjacent text 3610.
Native Multimodal Models (Early Fusion)
Native Multimodal Models (NMMs) represent a shift away from modular pipelines. NMMs are defined by unified backbone architectures trained end-to-end to jointly perceive, process, and generate across multiple modalities without relying on separately frozen vision encoders or late-fusion adapters 421. In true early-fusion architectures, all modalities are tokenized and merged at the input layer into a shared representation space. The core transformer blocks then jointly mix and compute attention across all modalities simultaneously from the very first layer onward 34.
Recent exhaustive scaling law studies evaluating hundreds of multimodal configurations reveal that early-fusion architectures exhibit significant structural advantages. Contrary to assumptions regarding the efficiency of pre-trained models, late-fusion architectures offer no inherent performance advantage when trained from scratch 52123. Early-fusion NMMs achieve stronger performance at lower parameter counts, converge faster for a given compute budget, and scale more predictably 2123.
The efficiency of native models is further amplified by incorporating Mixture-of-Experts (MoE) routing. MoE enables the native network to dynamically allocate specialized parameter pathways for specific modality tokens, overcoming the heterogeneous nature of multimodal data without requiring the rigid asymmetry of a late-fusion pipeline 42123.
Retrieval-Augmented Generation in Multimodal Systems
The architectural divide between early and late fusion also extends to Multimodal Retrieval-Augmented Generation (RAG) systems. In a late-fusion RAG architecture, distinct modalities are retrieved independently using specialized databases (e.g., a text vector database and a separate image similarity engine) and merged prior to generation. While highly modular and easy to update, this method risks missing critical cross-modal links 24. Conversely, early-fusion RAG encodes text and images into a shared embedding space, allowing for direct cross-modal retrieval (such as using text to query an image database). This produces stronger contextual understanding but demands computationally expensive, perfectly aligned multimodal datasets to prevent one modality from dominating the retrieval vectors 24.
Architecture of Frontier Multimodal Models
The current landscape of multimodal artificial intelligence is dominated by a mix of proprietary frontier models and rapidly advancing open-weights architectures. Each system employs highly customized variants of tokenization, projection, and fusion to achieve competitive benchmark performance.
Generative Pre-trained Transformer 4 (GPT-4V and GPT-4o)
Generative Pre-trained Transformer 4 with Vision (GPT-4V) extends the base GPT-4 text model to accept image inputs. The training pipeline mirrored the original GPT-4 process, utilizing next-word prediction pre-training on vast multimodal web datasets, followed by Reinforcement Learning from Human Feedback (RLHF) to align outputs 1. Empirical system evaluations document several structural limitations within GPT-4V's spatial reasoning capabilities. The model frequently fails to recognize precise spatial locations and color mappings. When separate textual components are physically adjacent in an image, the model is prone to merging them into unrelated concepts 1. Furthermore, GPT-4V exhibits ungrounded inferences, occasionally providing inconsistent interpretations of the same image or misdiagnosing laterality in radiographic medical imaging 1.
To resolve the latency and reasoning limitations of cascaded models, OpenAI developed GPT-4o ("Omni"). Unlike its predecessor, which operated on separate modules for audio and text, GPT-4o handles text, vision, and audio natively within a single, early-fusion architecture 3. This native processing allows for near-instantaneous audio conversational responses, dropping average voice latency to approximately 0.32 seconds 3. In its visual processing pipeline, GPT-4o utilizes a unified high-fidelity tokenization system based on 32*32 pixel patches, discarding the fragmented "detail modes" used by earlier iterations to ensure dense feature mapping 10.
Gemini 1.5 Pro
Google's Gemini 1.5 Pro is a natively multimodal model built upon a sparse Mixture-of-Experts (MoE) Transformer architecture 362526. The MoE design utilizes a sophisticated routing function that directs specific input tokens to a small subset of the network's parameters 263940. This conditional computation allows Gemini to drastically expand its total parametric capacity while maintaining the active inference cost of a much smaller model 426.
The defining characteristic of Gemini 1.5 Pro is its unprecedented context window, capable of securely processing up to 2 million tokens simultaneously 392728. This capacity fundamentally alters temporal multimodal reasoning. Gemini 1.5 Pro can ingest up to 10.5 hours of video natively (representing approximately 9.9 million tokens in internal testing) by extracting frames at a rate of one frame-per-second, allowing it to retrieve hyper-specific events embedded anywhere within the timeline 2629.
Similarly, the model processes up to 107 hours of audio natively 3626. Older audio transcription models required audio files to be chopped into strict 30-second segments, passing segmented text across boundaries and resulting in context loss. By processing the audio continuously in its native format, Gemini achieves substantially lower Word Error Rates 26. This extended context allows for remarkable in-context learning capabilities; when provided with a grammar manual for Kalamang - a language with fewer than 200 speakers globally - the model successfully learned to translate to and from English at a level comparable to a human learner 2544.
Qwen2.5-VL
Developed by Alibaba Cloud, the Qwen2.5-VL architecture heavily optimizes spatial and temporal tokenization to serve as an open-weights frontier model 3031. The model integrates a native dynamic-resolution Vision Transformer trained entirely from scratch. Unlike previous generations that forced images into fixed resolution squares (causing distortion), Qwen2.5-VL utilizes Window Attention algorithms to process images natively at varying scales and aspect ratios while severely reducing computational overhead 31.
For temporal multimodality, Qwen2.5-VL introduces absolute time encoding alongside an enhanced interleaved-MRoPE (Multimodal Rotary Positional Embedding) 3031. This specific temporal architecture replaces standard token tracking, allowing the model to natively perceive precise temporal dynamics across videos lasting several hours, granting it second-level event localization capabilities 31. The visual and textual modalities are fused using a DeepStack integration module that leverages multi-level ViT features to tighten vision-language alignment 30.
InternVL 2.5
The InternVL 2.5 series represents a highly refined approach to the modality-stitched paradigm. The architecture relies on the standard "ViT-MLP-LLM" configuration, integrating a pre-trained InternViT vision encoder with language models like InternLM 2.5 or Qwen 2.5 via a 2-layer MLP projector 1647.
A unique aspect of the InternVL architecture is its progressive scaling strategy during training. The developers observed that visual features generated by a ViT aligned with a small LLM are highly generalizable and easily understood by other language models 3233. Therefore, the InternViT is initially trained alongside a resource-efficient 20B parameter LLM to optimize fundamental cross-modal alignment without exorbitant compute costs. The system is then progressively scaled up, culminating in an integration with massive 78B parameter models 4732. Furthermore, the model dynamically adapts to image aspect ratios by applying a pixel unshuffle operation, dividing high-resolution images into 448x448 tiles and reducing visual tokens from 1024 to 256 per tile to maintain efficiency 16.
Benchmark Performance Analysis
The evaluation of multimodal artificial intelligence relies on specialized benchmarks designed to test cross-modal reasoning, quantitative chart analysis, and spatial document comprehension. Key academic benchmarks include: * MMMU (Multimodal Multi-task Benchmark): Evaluates models on college-level subject knowledge that requires synthesizing interleaved text and image data across disciplines 34. * MathVista: Tests the capacity for visual mathematical reasoning and spatial geometry 30. * ChartQA: Evaluates precise reasoning and data extraction from complex charts and graphs 35. * DocVQA: Tests visual question answering on scanned, dense document images 27. * AI2D: Assesses the understanding of scientific diagrams and instructional graphics 27.
Evaluation scores demonstrate near-parity among frontier models, with GPT-4o maintaining a slight edge in complex visual document and chart reasoning. Specifically, GPT-4o achieves 85.7% on ChartQA and 92.8% on DocVQA, compared to Gemini 1.5 Pro's 81.3% and ~89% respectively. Meanwhile, open-weights models like InternVL 2.5 have crossed the critical 70% threshold on highly complex academic benchmarks like MMMU.
The following table summarizes the comparative performance of leading architectures across recognized industry benchmarks:
| Benchmark Framework | GPT-4o | Gemini 1.5 Pro | GPT-4.5 | Claude 3 Opus | InternVL 2.5 |
|---|---|---|---|---|---|
| ChartQA | 85.7% | 81.3% | Data Unavailable | 80.8% | Data Unavailable |
| DocVQA | 92.8% | ~89.0% | Data Unavailable | 89.3% | Data Unavailable |
| MMMU (Pro/Val) | 88.27% | ~87.51% | 75.2% | ~80.0% | > 70.0% |
| MathVista | Data Unavailable | 68.1% | 72.3% | Data Unavailable | Data Unavailable |
| AI2D | 94.2% | Data Unavailable | Data Unavailable | Data Unavailable | Data Unavailable |
Note: Due to variations in benchmark versions (e.g., MMMU vs. MMMU Pro) and testing frameworks, certain precise numeric figures are unavailable or represent approximated cross-evaluations from aggregated reporting 2734355253. InternVL 2.5 is specifically recognized as the first open-source MLLM to surpass a 70% threshold on the standard MMMU benchmark, achieving parity with proprietary commercial systems 4732.
Modality Interference and Hallucination Mechanics
Despite achieving high accuracy on benchmark evaluations, contemporary multimodal architectures remain highly susceptible to multimodal hallucinations. A multimodal hallucination occurs when the model's generated textual output diverges factually from the provided visual or audio input, presenting confident but entirely fabricated claims 754. In visual tasks, models have been observed confidently identifying items on menus that do not exist, or providing wildly incorrect analyses of chemical structures 1. This phenomenon is driven by a fundamental architectural vulnerability defined in recent literature as modality interference or modality bleed 553637.
The Mechanics of Modality Conflict
Modality interference describes a failure in cross-modality competency; the model lacks the internal mechanisms required to fairly evaluate and integrate information across modalities, leading spurious signals from an irrelevant modality to distort the final output 5538.
Over-reliance on Unimodal Language Priors Because MLLMs are built upon language model backbones pre-trained on massive text corpora, the models possess intensely strong linguistic expectations. When visual input is ambiguous, obscured, or contradicts standard logical assumptions, the model's reliance on language priors intensifies 7. Experimental analyses demonstrate that during a visual hallucination, the visual branch of the model exhibits high uncertainty, assigning nearly equal confidence scores to both accurate and erroneous token candidates. The language decoder resolves this uncertainty by leaning on its inherent linguistic bias, effectively overpowering the visual evidence and generating text that sounds plausible but is factually ungrounded in the image 39. Research into the "Curse of Multi-Modalities" (CMM) indicates that visual-only MLLMs score poorly on hallucination metrics precisely because they default to these language priors whenever visual input conflicts with linguistic expectations 7.
Attention Drift in Extended Reasoning While leveraging increased test-time compute to generate extended reasoning chains - such as Chain-of-Thought prompting - drastically improves performance in pure mathematical and logical tasks, it inadvertently exacerbates visual hallucinations in perception-focused tasks 40. Systemic attention analyses reveal that as the language model generates an increasingly long sequence of reasoning tokens, its attention mechanism gradually drifts away from the original visual input tokens. The model begins to attend almost exclusively to its own generated text, diminishing its visual focus and causing the final conclusion to become entirely decoupled from the actual image 40. To quantify this specific degradation, researchers utilize the RH-AUC metric, which evaluates the exact balance between reasoning capability and hallucination risk 40.
Imbalanced Training Data and Missing Modalities Modality bias is also fundamentally linked to training data characteristics. Language data is inherently compact and abstract, whereas visual and audio data are highly complex and redundant 41. If an architecture is trained primarily on text-heavy pairs and relies sparsely on audio, the model will neglect the rich information available from auditory inputs during inference 41. Furthermore, when an expected dominant modality is completely missing during a query (e.g., prompting a visual model without an image), the system's performance drastically degrades, as it lacks the mechanistic robustness to adapt its reasoning pathways securely 4142.
Mitigation Strategies and Causal Interventions
Addressing modality interference requires intervening directly in the decoding process and restructuring the training pipeline.
Decoding Interventions Rather than retraining massive models from scratch, researchers have developed algorithms that intervene during the inference generation phase. Techniques like Visual Contrastive Decoding (VCD) and Multi-Modal Mutual-Information Decoding (M3ID) manipulate the logits produced by the model just before a token is generated. M3ID actively amplifies the influence of the reference image tokens over the language prior, mathematically favoring the generation of text tokens that share higher mutual information with the visual prompt 3943. By downgrading candidates advocated merely by the language model's bias, these decoding strategies dramatically reduce the percentage of hallucinated objects in image captioning tasks 3943.
Causal Modeling and Perturbation-Based Fine-Tuning Recent theoretical frameworks approach modality bias as a confounding variable within a causal graph 3744. The CausalMM framework applies structural causal modeling directly to the attention mechanisms of MLLMs. By employing backdoor adjustments and counterfactual reasoning at both the visual and textual attention levels, the framework actively severs the spurious correlations driving hallucinations, resulting in substantial accuracy improvements 44.
Similarly, researchers employ perturbation-based fine-tuning strategies to build inherent model robustness against modality bleed 5536. During training, data is augmented with heuristic and adversarial perturbations - such as intentionally injecting unrelated, contradictory textual facts into an image-focused prompt, or applying worst-case alignment disruptions via Projected Gradient Descent 5545. The model is then trained using consistency regularization, forcing the network to output the same correct answer whether the spurious perturbation is present or not. This strategy forces the network to distinguish task-relevant from irrelevant signals, severing the model's reliance on linguistic shortcuts and vastly improving its strict cross-modality competency 373845.
Conclusion
The architecture of multimodal artificial intelligence relies upon the complex translation of continuous real-world data into discrete tokens that a transformer mechanism can manipulate. While early architectural iterations relied heavily on bridging disparate, pre-trained unimodal systems via projection layers like Perceiver Resamplers or simple MLPs, the frontier of AI research is shifting definitively toward native multimodal models. Architectures featuring early fusion, dynamic resolution tokenization, and sparse Mixture-of-Experts - exemplified by models like Gemini 1.5 Pro, GPT-4o, and Qwen2.5-VL - demonstrate vastly superior scaling efficiency and cross-modal reasoning capabilities, particularly over hours-long temporal contexts.
However, the persistent structural reliance on massive language model backbones continues to introduce systemic modality interference. Current architectures remain highly vulnerable to overriding empirical visual and auditory data in favor of dominant linguistic expectations, resulting in confident hallucinations. Future architectural advancements will likely necessitate the integration of strict causal fine-tuning frameworks, perturbation-based training augmentations, and dynamic attention constraints to ensure that cross-modal fusion enhances, rather than corrupts, the factual reliability and deductive accuracy of the system.