Automated Machine Learning and Overfitting in Quantitative Finance
The Paradigm Shift in Quantitative Strategy Discovery
The landscape of quantitative finance has undergone a profound structural transformation over the past decade, culminating in a paradigm shift from traditional econometric factor modeling to the deployment of fully Automated Machine Learning (AutoML) frameworks. Historically, the discovery of systematic trading strategies relied heavily on human domain expertise. Quantitative researchers would manually engineer financial features, select parametric statistical models, and tune parameters through iterative, intuition-guided processes 12. However, the exponential increase in market data complexity - encompassing high-frequency order book dynamics, alternative unstructured data, and complex cross-asset correlations - has rendered human-centric discovery pipelines a severe computational bottleneck. The cognitive limits of researchers prevent the exhaustive exploration of non-linear interactions across high-dimensional datasets.
Recent literature from the 2023-2026 period, particularly emerging from top-tier institutional sources such as AQR Capital Management and foundational research by Marcos López de Prado, emphasizes that the true value of machine learning in finance is not merely in fitting data to a static predictive algorithm, but in automating the scientific method of hypothesis generation itself 12. Modern financial machine learning centers on frameworks that autonomously formulate hypotheses, generate feature engineering code, execute backtests, and recursively refine trading logic 56. These systems utilize Large Language Models (LLMs) to navigate complex feature engineering tasks, employ automated Neural Architecture Search (NAS) to dynamically construct deep learning topologies, and leverage evolutionary algorithms to avoid premature convergence in highly non-convex, noisy search spaces 23.
Yet, this automation paradoxically introduces profound systemic risks. The ability to test billions of parameter combinations and topological variations in computational silos exacerbates the multiple hypothesis testing problem, leading to an epidemic of backtest overfitting that plagues the modern asset management industry 28. Consequently, the discipline has been forced to evolve its statistical validation and out-of-sample testing protocols. Traditional methodologies such as the standard Sharpe ratio, traditional $K$-fold cross-validation, and simple out-of-sample walk-forward holdouts have been mathematically proven to be insufficient, and often actively misleading, in the presence of path-dependent, serially correlated financial data 9104.
In response, the industry has adopted rigorous mathematical controls derived from experimental mathematics and advanced econometrics. These include the Deflated Sharpe Ratio (DSR), the Probability of Backtest Overfitting (PBO), and Combinatorial Purged Cross-Validation (CPCV) 12514. Furthermore, top-tier publications in the Journal of Portfolio Management and the Journal of Financial Data Science underscore the critical necessity of controlling the Family-wise Error Rate (FWER) and the False Discovery Rate (FDR) when conducting automated strategy searches 26. This report provides an exhaustive analysis of these advances, dissecting the mechanics of modern AutoML frameworks, analyzing the geographic and asset-class divergence in model efficacy, evaluating the pathological shift of human bias, and codifying the advanced statistical protocols required to validate the next generation of algorithmic trading systems.
The Vanguard of AutoML: LLMs, Evolutionary Algorithms, and NAS
The latest generation of AutoML applied to quantitative finance moves far beyond basic hyperparameter optimization algorithms (such as grid search or random search). It introduces semantic understanding, topological mutation, and Darwinian selection directly into the strategy discovery pipeline.
LLM-Assisted Automated Feature Engineering
Feature engineering has traditionally been the most labor-intensive and intellectually demanding component of quantitative research, requiring deep domain knowledge of market microstructure, macroeconomic linkages, and accounting principles 167. Standard Automated Feature Engineering (AutoFE) for tabular data often utilizes expansion-reduction methods (e.g., Deep Feature Synthesis), which mathematically transform raw features through operations like moving averages or standard deviations, and then filter the results based on correlation metrics 3. However, in financial time series, blindly multiplying, dividing, or exponentiating technical indicators frequently produces collinear, massively overfit, or financially nonsensical variables that fail out-of-sample.
The integration of Large Language Models (LLMs) into AutoFE has revolutionized this process by injecting semantic domain knowledge into the search algorithm. Frameworks developed in 2024 and 2025 demonstrate that LLMs can act as "sequence generators" for feature transformation operations, guided by few-shot prompts that encode financial market logic and historical context 318. However, early iterations of LLM-driven AutoFE struggled with programmatic stability, often hallucinating non-executable or logically flawed Python code when attempting to build complex data pipelines 8. Recent empirical studies demonstrate an interesting counter-intuitive finding: smaller, domain-specific LLMs that have been explicitly fine-tuned on historical feature-effectiveness datasets exhibit significantly better code-generation stability for AutoFE than their larger, generalized, non-fine-tuned counterparts 8.
To further rectify the hallucination and instability issues, hybrid architectures such as the Evolutionary Large Language Model for Feature Transformation (ELLM-FT) have been introduced. By combining LLMs with Evolutionary Algorithms (EA), these frameworks maintain a multi-population database of feature sets. The system leverages a reinforcement learning data collector to structure this multi-population dataset, within which each population evolves independently 318. The LLM proposes novel, semantically logical features (e.g., combining order book imbalance metrics with specific macroeconomic interest rate lags), while the evolutionary algorithm acts as a stringent "decision science model." The EA ruthlessly culls underperforming, non-executable, or collinear features, simultaneously granting high-quality populations greater opportunities for mutation and crossover 318. This creates a high-quality iteration loop that explores vast feature spaces while anchoring the optimization in contextual financial knowledge, thereby realizing a highly adaptable and robust search paradigm.
Automated Neural Architecture Search (NAS) in Finance
While hyperparameter tuning optimizes the continuous weights, dropout rates, and learning rates of a predefined model, Neural Architecture Search (NAS) treats the neural network's architecture itself as a discrete or continuous variable to be optimized 120. Financial time series exhibit extreme non-stationarity, regime shifts, and low signal-to-noise ratios. Consequently, rigid network architectures designed for computer vision or natural language processing (e.g., standard ResNets or out-of-the-box Transformers) frequently fail to generalize when applied directly to asset pricing or volatility forecasting 79.
NAS automates the discovery of bespoke topologies tailored to specific financial tasks, autonomously exploring combinations of convolutional layers, recurrent cells, attention mechanisms, activation functions, and skip connections 1. The three dominant approaches in financial NAS include:
- Reinforcement Learning (RL) NAS: An agent proposes specific network architectures and receives a delayed reward based on the validation Sharpe ratio or directional accuracy out-of-sample. While highly expressive, RL-NAS (such as the early NASNet framework) is notoriously computationally expensive, requiring the training of thousands of distinct child networks to convergence before the RL controller can update its policy 122.
- Gradient-Based NAS: Techniques like Differentiable Architecture Search (DARTS) address the computational bottleneck by relaxing the discrete architectural search space into a continuous one. This allows the architecture to be optimized via standard gradient descent simultaneously with the network weights. This significantly reduces computational cost, but in highly noisy financial environments, gradient-based NAS can lead to unstable, overly dense architectures that suffer from catastrophic forgetting during market regime shifts 1.
- Neuroevolution: Methods such as NeuroEvolution of Augmenting Topologies (NEAT) and its deep learning extension, DeepNEAT, mimic natural selection to evolve better architectures over successive generations 120. In finance, NEAT's "complexification" approach is vital. NEAT mandates that architectures incrementally grow from minimal, sparse structures, adding nodes and connections only when mathematically justified by a fitness improvement 20. Starting with an overly complex, deep network almost guarantees immediate overfitting to historical noise; neuroevolution naturally penalizes superfluous complexity.
Agentic Evolutionary Frameworks
The culmination of LLMs, AutoFE, and NAS is realized in fully agentic evolutionary frameworks, such as QuantEvolve and MadEvolve. These systems operate as autonomous multi-agent loops that iteratively propose trading hypotheses, generate the executable logic in Python, backtest the strategy against high-frequency minute-bar data, and refine the approach based on a designated reward signal 2523.
In advanced frameworks like MadEvolve, the LLM continuously mutates strategy code within explicitly defined execution blocks, while a MAP-Elites (Multi-dimensional Archive of Phenotypic Elites) algorithm maintains a diverse population of trading algorithms 523. This quality-diversity optimization ensures that the system does not prematurely converge on a single, overfit local maximum. By synthesizing insights from both failed and successful historical paths - often maintaining "island-specific" institutional memory across different computational nodes to prevent repeated failures - these systems can jointly evolve the feature pipeline alongside the execution logic 256. The resulting agentic loops can discover structurally novel execution heuristics, matching or exceeding the out-of-sample performance of manually engineered baselines by creating non-linear alpha generation systems that dynamically adapt to shifting volatility regimes 623.
The Illusion of Objectivity: The Displacement of Human Bias
A pervasive misconception regarding AutoML and fully algorithmic trading is that these systems eradicate human cognitive bias from the investment process 224. In reality, AutoML does not eliminate bias; it merely displaces it systematically from the direct, downstream selection of models and features to the upstream architectural design of the hyperparameter search space and the mathematical definition of the fitness functions 242510.
Bias in the Definition of the Search Space
In any AutoML, NAS, or evolutionary deployment, the algorithm can only discover solutions that exist within its predefined, mathematically bounded search space 10. If a quantitative researcher limits a NAS framework to explore only Convolutional Neural Networks (CNNs) with a maximum depth of five layers, the system is fundamentally blind to potentially superior solutions requiring deep Long Short-Term Memory (LSTM) networks, Transformers, or Graph Neural Networks 24.
The design of the search space is an inherently human decision, heavily laden with theoretical biases regarding how market microstructure operates. For example, restricting a search space to linear combinations of traditional value, size, and momentum factors assumes a stationary, linear econometric world, ignoring complex non-linear interactions 11. Conversely, providing an overly expansive, unconstrained search space (e.g., allowing unrestricted deep learning architectures to comb across thousands of alternative, unstructured datasets) exponentially increases the dimensionality of the problem. This virtually guarantees that the algorithm will latch onto spurious correlations, fitting the model perfectly to historical noise 2812. Therefore, "human bias" in modern finance manifests as the delicate, often subjective calibration of the search space boundaries - balancing sufficient architectural expressivity to capture latent alpha with strict regularization constraints to ensure out-of-sample generalizability 2024.
The Normative Nature of Fitness Functions
The second major vector of displaced bias resides in the performance estimation strategy, commonly known as the fitness function or objective function 2410. In evolutionary algorithms and RL agents, the fitness function serves as the sole arbiter of survival. If a financial AutoML system is tasked with maximizing the standard, in-sample Sharpe ratio, it will inevitably select strategies characterized by high leverage, excessive turnover, and a tendency to harvest short-term mean-reversion premia 1331. These models will appear optimal in-sample but will often ignore tail risks, fat-tailed non-normal distributions, and real-world transaction costs, leading to catastrophic out-of-sample failure 31.
To counteract this, sophisticated institutional frameworks employ composite, highly customized fitness functions. For instance, the GT-Score integrates raw return performance, statistical significance, return consistency, and downside risk metrics to guide optimization away from data snooping 31. Similarly, platforms like MadEvolve explicitly optimize for impact-adjusted PnL rather than the raw Sharpe ratio, forcing the evolutionary algorithm to account for adverse selection, order book depth, and inventory risk during the simulation 523. The choice of the fitness function is a profound expression of the portfolio manager's risk aversion, time horizon, and philosophical view of market efficiency. A poorly designed, naive fitness function will perfectly and efficiently optimize the machine learning system toward financial ruin.
Comparing Discovery Frameworks: Traditional vs. AutoML
To contextualize the evolution of quantitative research, it is essential to map the operational distinctions between traditional hypothesis-driven discovery and modern AutoML frameworks across critical dimensions of pipeline speed, computational cost, and validation requirements.
| Analytical Dimension | Traditional Quantitative Research Methods | Modern AutoML & Agentic Frameworks (e.g., MadEvolve, ELLM-FT) |
|---|---|---|
| Pipeline Speed & Automation | Highly manual; requires months of specialized human research for hypothesis generation, feature engineering, and iterative backtesting 1632. | Automated end-to-end; can generate, evaluate, and iteratively mutate thousands of algorithmic variants within hours 614. |
| Specific Overfitting Vectors | Human selection bias; p-hacking by selectively reporting successful single-path backtests; reliance on linear, stationary assumptions 834. | Extreme multiple hypothesis testing; fitting to non-stationary historical noise due to vast, over-parameterized search spaces 3115. |
| Validation Requirements | Standard out-of-sample holdouts; basic walk-forward analysis; traditional standard error estimates and t-statistics 8. | Requires advanced combinatorial mathematics (CPCV), regime-aware synthetic data generation, and rigorous multiple-testing corrections (DSR, PBO, FWER) 363738. |
| Computational Cost | Relatively low; execution of linear regressions, Markowitz mean-variance optimization, and simple heuristic routines requires minimal infrastructure 32. | Extremely high; evaluating complex NAS topologies or EA populations against deep high-frequency order-book data requires substantial GPU clusters 116. |
| Interpretability | High; standard econometric models (e.g., Fama-French factors) offer clear coefficients and easily explainable linear relationships 2840. | Low ("Black Box"); requires post-hoc Explainable AI (XAI) overlays (e.g., SHAP values) or LLM-generated narrative reports to decipher logic 232840. |
Geographic and Asset-Class Divergence in AutoML Efficacy
The propensity for AutoML overfitting manifests uniquely across varying market microstructures. The underlying physics of price formation differ drastically when contrasting highly efficient Developed Markets (DM) with Emerging Markets (EM), and traditional Equities with Cryptocurrencies.
Developed vs. Emerging Markets
Highly efficient developed markets, such as US large-cap equities, possess extraordinarily low signal-to-noise ratios. In these environments, simple linear models often perform comparably to complex deep learning networks out-of-sample, as any predictive alpha is rapidly arbitraged away by competing algorithms 1141. The "random walk" nature of highly integrated markets limits the effectiveness of unrestrained NAS.
Conversely, emerging markets exhibit structural inefficiencies, lower liquidity, less stringent regulatory transparency, and delayed information propagation 42. Comprehensive studies by institutional quant teams, analyzing over 15,000 unique stocks from 32 emerging countries over three decades, indicate that machine learning algorithms significantly outperform traditional linear factor models 11. In these studies, linear models yielded approximately 0.8% monthly returns. However, non-linear tree-based models (Random Forest, Gradient Boosting) generated 1.0% per month, and deep Neural Networks combined with machine learning ensembles delivered up to 1.2% per month 11. This suggests there is between 0.2% and 0.5% of monthly alpha left to capture in EM that linear models completely miss. The non-linear capabilities of AutoML excel at detecting these complex, financially material relationships between company characteristics that would elude human researchers 11. However, EM models are highly susceptible to overfitting idiosyncratic country risks and political volatility if not properly regularized, demanding models that capture generalizable, cross-border knowledge rather than local anomalies 181142.
Traditional Equities vs. Cryptocurrencies
Cryptocurrency markets present a radically different topological landscape: they operate continuously 24/7 without centralized closing periods, are heavily driven by retail sentiment and momentum, and exhibit extreme volatility and fragmented cross-venue liquidity 1243. Traditional equity AutoML frameworks - which often rely on daily closing prices and fundamental quarterly accounting data - fail spectacularly when ported directly to digital assets.
For instance, models relying on standard time-based bars (e.g., 1-minute or 5-minute intervals) frequently suffer from information lag and oversampling during quiet periods, while undersampling during violent crypto price breakouts. Successful crypto AutoML requires the utilization of volume or "dollar bars" to sample data dynamically based on actual market activity, preserving the statistical properties of the series 1217. Furthermore, crypto models must integrate vast, noisy, unstructured datasets - such as on-chain wallet flows, transaction clustering, derivative funding rates, and real-time social sentiment metrics from platforms like Discord and X - to avoid out-of-sample failure 4318.
The extreme noise in cryptocurrency means that overly complex deep neural networks often underperform simpler, heavily regularized models or targeted LSTMs, as the former quickly overfit to wild, unrepeatable historical price spikes 124619. Studies have shown that while deep learning can achieve state-of-the-art accuracy in crypto, its black-box nature and propensity to memorize noise require extensive regularization and walk-forward validation to remain viable 2216.
The Pathology of Overfitting and Out-of-Sample Degradation
In algorithmic trading, the chasm between a seemingly compelling historical backtest and a stable, profitable live system is the graveyard of systematic strategies 31. The financial literature is replete with documented case studies and structural analyses of models that spectacularly degraded out-of-sample (OOS).
Notorious Degradation Case Studies
The academic consensus, pioneered by researchers like McLean and Pontiff, demonstrates that even rigorous, peer-reviewed anomaly-based portfolio returns typically degrade by 26% immediately out-of-sample, and suffer a further 58% decay in the five years post-publication due to rapid investor arbitrage and market learning 48. However, the degradation of over-parameterized machine learning models is often far more severe, instantaneous, and structurally catastrophic.
During the unprecedented macroeconomic regime shifts and volatility spikes of 2022 and 2023, numerous heavily parameterized quantitative hedge funds suffered notorious and significant losses 495051. Post-mortem structural analyses revealed that their machine learning models had implicitly memorized the low-volatility, zero-interest-rate quantitative easing (QE) regimes of the 2010s 5051. As Marcos López de Prado emphasizes, financial markets are not static, rule-bound physical systems; they are reflexive, adversarial, and non-stationary 1331. An algorithm that perfectly predicts a financial time series in-sample is not demonstrating intelligence; it is demonstrating memory, falling into a dangerous statistical trap known as overfitting 5220.
When a model learns spurious, high-dimensional patterns specific to a historical epoch, it becomes extraordinarily fragile to regime shifts. This fragility was evident in early deep learning applications predicting the S&P 500, where naive models optimized on price sequences collapsed entirely when unprecedented macroeconomic factors (e.g., persistent inflation shocks and rapid central bank tightening) overrode historical technical momentum 4054. Modern analysis reveals that without strict regime-aware validation segmentation and causal factor design, neural networks simply overfit to the prevailing autocorrelation of the training window, mistaking a prolonged bull market for a universal law of price physics 2213.
Advanced Statistical Mitigation Protocols
To combat the epidemic of false discoveries generated by AutoML frameworks - which possess the computational capacity to test millions of strategy combinations in minutes - the quantitative finance community has adopted rigorous statistical penalty frameworks that account for the massive expansion of the search space 8.
The Multiple Testing Problem and The False Strategy Theorem
When a researcher or an AutoML agent evaluates thousands of predictive features or architectures, standard statistical significance tests (e.g., p-values) become entirely meaningless. According to the False Strategy Theorem, if an algorithm tests 1,000 worthless, completely random trading strategies at a standard 5% significance level, approximately 50 of those strategies will appear highly profitable and statistically significant purely by random chance 65556. If the researcher only publishes or deploys the "best" strategy without disclosing the 999 failed attempts, they suffer from acute selection bias, rendering the in-sample statistics invalid 28.
To address this, researchers must control error rates across the entire family of tests conducted by the AutoML system.
- Family-wise Error Rate (FWER): The FWER is strictly defined as the probability of making at least one false positive discovery across all tests conducted ($FWER = P(V \ge 1)$) 5721. The most common mathematical control for FWER is the Bonferroni correction, which aggressively divides the target significance level ($\alpha$) by the total number of tests ($M$) 622. While FWER control provides rigorous, ironclad protection and is preferred in high-stakes environments where a single failure is catastrophic, it is severely conservative. As $M$ grows exponentially - a typical scenario in evolutionary AutoML - FWER thresholds become so strict that they virtually guarantee high Type II errors, blinding the system to true, valid market signals because the mathematical hurdle for significance becomes insurmountable 6552324.
- False Discovery Rate (FDR): Recognizing the extreme conservatism of FWER, statisticians developed the FDR (e.g., the Benjamini-Hochberg procedure), which shifts the focus from preventing any error to controlling the expected proportion of false discoveries among the rejected null hypotheses ($FDR = E[FP / (FP + TP)]$) 572124. For quantitative finance, where discovering a diversified portfolio of marginally profitable, uncorrelated signals is often the primary goal, FDR provides a highly adaptive, scalable alternative. It allows for a more powerful detection of valid trading factors while maintaining a mathematical ceiling on the proportion of "lucky" algorithms entering the portfolio 821. Recent advances by López de Prado also emphasize the use of Bayesian FDR to make inference statistically valid, integrating prior beliefs about market efficiency to better identify true causal alpha 2.
Deflated Sharpe Ratio and Probability of Backtest Overfitting
Because the standard Sharpe ratio is upwardly biased when multiple strategies are tested (selection bias), the Deflated Sharpe Ratio (DSR) was introduced to mathematically discount the reported Sharpe ratio 12538. The DSR accounts for three critical factors: the number of independent trials conducted by the AutoML system, the variance of the Sharpe ratios across all tested strategies, and the non-normality (specifically negative skewness and excess kurtosis) of the underlying asset returns 1238. By deflating the ratio, practitioners can ascertain whether the performance is genuinely skillful or merely an artifact of excessive data mining.
Going a step further, the Probability of Backtest Overfitting (PBO) quantifies the exact mathematical likelihood that a strategy optimized to maximize in-sample performance will systematically underperform the median out-of-sample performance of all other tested variants 1255. Computed using a technique called Combinatorially Symmetric Cross-Validation (CSCV), the PBO constructs a vast distribution of paired in-sample and out-of-sample performance matrices 2862. A high PBO (e.g., >50%) provides an empirical, mathematical warning that the AutoML strategy selection process is entirely compromised by historical noise, acting as a final safeguard against deploying fragile algorithms to live trading environments 2812.
Revolutionary Validation Mechanics: Beyond Walk-Forward
The most profound methodological shift in algorithmic strategy development lies in how time-series data is partitioned for validation. Standard machine learning validation protocols, borrowed from static image recognition or natural language tasks, fail catastrophically when applied to finance.
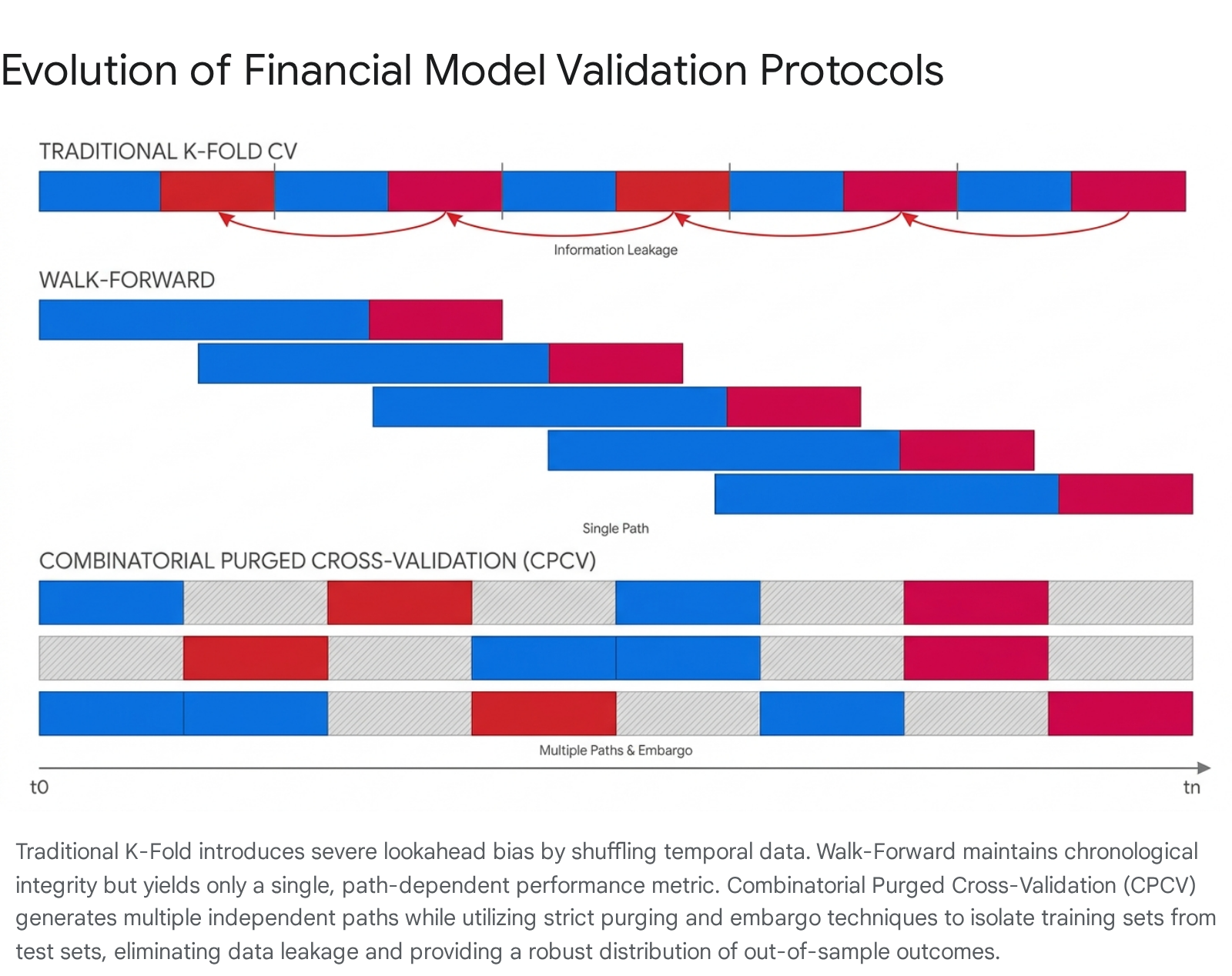
The Failure of K-Fold and the Limits of Walk-Forward
Traditional K-Fold Cross-Validation operates on the fundamental assumption that data points are Independent and Identically Distributed (IID). It randomly shuffles and partitions data into folds, indiscriminately mixing past, present, and future observations 94. In financial modeling, this causes massive, fatal lookahead bias. Predicting a stock's price on Tuesday using a neural network training set that inadvertently includes Wednesday's price structurally invalidates the model, leading to inflated performance metrics that vanish the moment the algorithm is deployed live 910.
To solve the lookahead bias, the quantitative industry standard became Walk-Forward (WF) Validation. WF preserves strict chronological integrity by training on a historical window (e.g., 2018-2020) and testing on the immediate subsequent period (e.g., 2021). The training window then rolls forward 1022. While WF effectively prevents lookahead bias and closely simulates a realistic trading deployment, it suffers from extreme path dependency 104. Walk-Forward validation tests only a single, specific historical trajectory. The resulting performance metric is highly contingent on the specific chronological sequence of historical events, leading to high variance in performance estimation. It fails to answer the critical question of how the algorithmic model would perform under different chronological sequences or alternative market regimes 92263. The computational complexity of WF is also substantial, often denoted as $O(K \cdot W \cdot N \cdot |\Theta| \cdot F)$ for deep learning models, yet it yields only a limited set of test metrics 22.
Combinatorial Purged Cross-Validation (CPCV)
Developed to resolve the deficiencies of both methods, Combinatorial Purged Cross-Validation (CPCV) systematically generates a multitude of chronology-respecting train-test partitions 414. Instead of a single point estimate, CPCV provides a comprehensive empirical distribution of out-of-sample performance metrics 963.
To prevent information leakage while mixing temporal blocks across different combinations, CPCV enforces two critical mechanisms: 1. Purging: Any observation in the training set whose event timestamp falls within or overlaps with the testing set label horizon is strictly removed (purged) 414. 2. Embargoing: Because financial series exhibit strong serial correlation and volatility clustering, simply purging overlapping labels is insufficient. An "embargo" period - a strict temporal buffer - is inserted immediately following the test set before the training data is allowed to resume. This ensures complete statistical independence between the folds, preventing the model from inferring test-set dynamics from the immediately subsequent training data 10464.
By partitioning the time series into $N$ sequential groups and combinatorially selecting $k$ groups as test sets, CPCV generates $nCr(N, N-k)$ unique backtest paths 1064. This combinatorial explosion allows quantitative researchers to calculate the variance, skewness, and kurtosis of the Sharpe ratio across diverse simulated market regimes, significantly reducing the probability of deploying an overfit model while overcoming the single-path limitation of Walk-Forward analysis 4366465.
| Validation Protocol | Mechanic / Partitioning Logic | Key Financial Vulnerability | Mitigation of Overfitting |
|---|---|---|---|
| Traditional K-Fold | Randomly partitions data into $k$ equal-sized folds. Trains on $k-1$, tests on the remaining fold 9. | Assumes IID data. Introduces massive Lookahead Bias as future labels influence past training features 4. | Fails entirely in financial time series. Yields dangerously optimistic, structurally false results 910. |
| Walk-Forward (WF) | Sequential rolling or expanding window. Trains on past data ($t-n$ to $t$), tests on immediate future ($t+1$) 1022. | Path Dependency. Generates a single historical path. Performance is highly sensitive to the specific, unrepeatable sequence of events 963. | Moderate. Successfully prevents lookahead bias but provides a limited sample size of out-of-sample scenarios 3765. |
| Combinatorial Purged Cross-Validation (CPCV) | Divides data into $N$ groups, tests on $k$ combinations to yield $nCr(N, N-k)$ paths 10464. | Implementation complexity. Requires precise boundary coding to ensure embargo logic does not inadvertently leak data 63. | Exceptionally High. Eliminates leakage via Purging/Embargoing and generates a robust statistical distribution of OOS Sharpe ratios 1436. |
Conclusion
The deployment of Automated Machine Learning in quantitative finance represents an irreversible shift in the epistemology of trading strategy discovery. With the advent of LLM-assisted feature engineering, automated Neural Architecture Search, and autonomous agentic evolutionary frameworks like MadEvolve, algorithms can now autonomously navigate multi-dimensional hypothesis spaces that vastly eclipse human cognitive capacity. However, the foundational law of quantitative finance remains immutable: algorithms that test millions of variations without rigorous statistical discipline are merely highly efficient, sophisticated engines for backtest overfitting.
Recognizing that human bias has not been eliminated but merely shifted upstream to the architectural design of search spaces and the normative calibration of fitness functions, the industry must prioritize methodological rigor over raw computational scale. The catastrophic out-of-sample degradation witnessed during the macroeconomic regime shifts of 2022-2023 underscores the acute danger of deploying complex, non-stationary models validated by archaic protocols that implicitly memorize low-volatility eras. To survive in live, adversarial markets - whether navigating the highly efficient structures of developed equities or the noisy, fragmented arenas of cryptocurrency - practitioners must anchor their AutoML pipelines in advanced statistical inference. Utilizing Deflated Sharpe Ratios, rigorously controlling the False Discovery Rate, and enforcing Combinatorial Purged Cross-Validation are no longer optional best practices; they are the mandatory mathematical prerequisites for discerning true algorithmic intelligence from historical noise.