Impact of artificial intelligence on human expertise
The integration of artificial intelligence into cognitive labor and professional practice represents a foundational shift in how information is retrieved, validated, and applied. Historically, technological revolutions automated physical labor and routine computational tasks, leaving complex reasoning, pattern recognition, and semantic interpretation as the exclusive domain of human expertise. The emergence of generative artificial intelligence and large language models challenges this exclusivity, as these systems possess the capacity to synthesize information, construct narratives, and output probabilistically generated text that mimics human reasoning 123. This capability necessitates a fundamental reevaluation of what constitutes professional expertise, altering the traditional boundaries between human judgment and algorithmic processing 45.
The transition from predictive classification models to generative systems has catalyzed an epistemological rupture across professional domains 34. Where traditional search engines functioned as digital indexes requiring human users to evaluate and synthesize disparate sources, large language models collapse the retrieval and synthesis phases into a single algorithmic output 15. This alters the cognitive demands placed on knowledge workers, shifting their primary role from information synthesis to epistemic verification 6711. As these tools become embedded in critical sectors such as healthcare, law, and academic research, the socio-technical implications extend beyond productivity metrics to encompass questions of epistemic authority, automation bias, and global knowledge equity 8910. The macroeconomic landscape is simultaneously undergoing profound disruption, with labor markets projecting the displacement of millions of routine administrative roles alongside the creation of novel positions focused on system orchestration and governance 1112.
Evolution of Information Retrieval Systems
Algorithmic History and System Architectures
For decades, digital information retrieval has relied on algorithmic search engines designed to crawl, index, and rank web pages based on relevance and authority metrics 1. The earliest of these systems operated on Boolean matching principles, identifying documents that strictly contained the user's input keywords 13. While effective for basic retrieval, Boolean systems failed to rank documents by optimal relevance, leading to the development of weighting schemas such as TF-IDF (Term Frequency-Inverse Document Frequency) and BM25, which evaluated the statistical importance of words within a document corpus 13. These keyword-based paradigms served as the foundation of digital research, yet they struggled with semantic ambiguity, such as recognizing that a query for "dog toys" should retrieve documents referencing "puppy toys" 13. To maintain dominance in an increasingly complex digital landscape, traditional search engines have recently integrated technologies like FastSearch to optimize distributed indexing, and RankEmbed, which utilizes deep learning vector embeddings to rank results based on semantic similarity rather than mere keyword presence 14.
Generative large language models represent a departure from this retrieval-centric paradigm. Rather than pointing a user to external sources, generative systems ingest vast corpora of training data to synthesize natural language answers directly 1. These neural networks operate through next-token prediction, calculating the statistical probability of word sequences to produce novel text, thereby assuming the synthetic labor previously performed by the human user 1516. Unlike search engines, which rely on the continued existence and accessibility of original web pages, large language models generate responses from internal parametric memory, creating a conversational experience that allows users to refine inquiries interactively 1.
| Feature | Traditional Search Engines | Large Language Models (Generative AI) |
|---|---|---|
| Primary Function | Information retrieval and external indexing. | Information synthesis and natural language generation. |
| Output Format | Ranked lists of external hyperlinks. | Direct, conversational text responses. |
| Epistemic Role of System | Mediator pointing to external authorities. | Algorithmic synthesizer presenting direct claims. |
| Epistemic Role of User | Evaluator and synthesizer of multiple sources. | Prompter and verifier of machine-generated text. |
| Underlying Mechanism | Crawling, indexing, TF-IDF, vector embeddings. | Deep learning, neural networks, next-token prediction. |
| Inherent Limitations | Information overload, reliance on keyword exactness. | Hallucinations, lack of source attribution, "black box" opacity. |
Traffic Dynamics and Intent Shifts
The rapid adoption of generative tools indicates a structural shift in user behavior and digital traffic. Market analysis from mid-2025 indicates that while Google still processes an estimated 8.5 to 13.7 billion queries daily, maintaining an 89.6% market share, its dominance has shown sustained erosion, falling below the critical 90% threshold for the first time since 2015 5. Concurrently, artificial intelligence chatbot traffic grew by over 80.92% year-over-year between April 2024 and March 2025, with some platforms experiencing average monthly traffic increases exceeding 721% 5. By early 2025, leading generative models like OpenAI's ChatGPT reached unprecedented adoption milestones, processing approximately one billion interactions daily and capturing 78% of the AI search market 521.
This divergence in user preference aligns closely with query intent. Empirical data suggests that for direct, fact-based queries, such as public health guidelines or localized data, a majority of users still prefer the reliability and comprehensive indexing of traditional search engines 15. However, for generative tasks, user preference shifts decisively. Surveys indicate that 68% of users employ language models for research and summarization, 48% for interpreting news, and 42% for comparative recommendations 5. Industry forecasts project that by 2030, artificial intelligence platforms may handle over 50% of all global search queries, transforming the discovery landscape from a zero-sum competition into a dual-ecosystem where search engines handle high-intent, transactional queries, and answer engines manage informational, top-of-funnel research 1421.
Epistemological Foundations of Generative Models
Predictive Classification Versus Generative Synthesis
The integration of artificial intelligence into professional workflows requires distinguishing between predictive and generative models, as each carries distinct epistemological implications 4. Predictive artificial intelligence utilizes algorithms - such as traditional machine learning and deep learning - to analyze historical data from small to medium datasets 4. The goal of predictive systems is to classify data, find optimal boundaries, and forecast future outcomes based on established probability distributions 24. These systems act as discriminative models, identifying patterns to support human decision-making in discrete, measurable contexts 24.
Generative artificial intelligence marks a profound rupture in this computational lineage 3. Rather than classifying existing data, generative models utilize massive, pre-trained datasets to construct entirely new content, including text, imagery, and code 24. Driven by transformer architectures that compute attention vectors across vast sequences of tokens, these models simulate human fluency without replicating human cognitive mechanisms 4. This distinction is critical: while generative models do not possess an internal understanding of the concepts they manipulate, the resulting content appears highly rational, thereby challenging traditional assumptions about the origin and validation of knowledge 417.
The High-Dimensional Geometry of Knowledge
To comprehend how generative models produce knowledge without possessing semantic understanding, epistemologists and computer scientists are turning to the underlying mathematical structures of neural networks. Recent theoretical work proposes an "Indexical Epistemology of High-Dimensional Spaces" 18. In classic computing, information is processed as binary vectors where the semantics remain external to the machine 18. Neural network architectures fundamentally alter this relationship. When a prompt is submitted, the symbolic input is instantly projected into an unimaginably high-dimensional space where specific geometric coordinates correspond to semantic parameters 18.
The structural properties of high-dimensional Euclidean spaces - such as the concentration of measure, near-orthogonality, and exponential directional capacity - create a manifold of learned representations 18. A large language model does not "think" in a human sense; rather, it acts as a navigator across this geometric manifold 18. The knowledge it produces is termed "navigational knowledge," constituting a third mode of knowledge production that is distinct from traditional symbolic reasoning and basic statistical recombination 18. Because human epistemology is adapted to low-dimensional physical environments, the outputs derived from high-dimensional geometric spaces appear simultaneously brilliant and alien, leading to unpredictable epistemic behaviors 18.
Adaptive Epistemology in Social Sciences
The capacity of generative systems to output coherent analysis necessitates new methodological paradigms, particularly within the social sciences. Traditional epistemological frameworks - such as positivism, which demands objective replicability, or interpretivism, which relies on subjective human hermeneutics - are increasingly insufficient for managing data generated by autonomous algorithms 3. Sociologists advocate for a transition toward "adaptive epistemology," a paradigm that foregrounds reflexivity, dynamism, and the co-construction of meaning between human researchers and machine systems 3.
Under the framework of adaptive epistemology, generative algorithms are recognized not merely as computational tools, but as active non-human agents capable of surfacing latent semantic structures and alternative framings that transcend predefined theoretical boundaries 3. However, this agentic capacity introduces a recursive feedback loop. Data generated by AI systems is not a neutral reflection of reality but an artifact of continuous human-machine interaction 3. Over time, these interactions blur the boundary between empirical observation and automated synthesis, requiring researchers to treat machine outputs not as final, authoritative findings, but as dialogical prompts requiring situated, critical interpretation 3.
The Verification Tax in Academic Research
Algorithmic Truth and Epistemic Authority
As large language models output highly fluent, structurally coherent text, they inadvertently project an aura of epistemic authority, reconfiguring how truth is produced and validated in digital societies 61920. Sociologists of technology note the emergence of "Artificial Truth," a regime of epistemic governance where the determination of factual accuracy shifts from institutional expertise to platform-native computational infrastructures 2026. Generative models exert their epistemic force through linguistic form rather than propositional understanding, establishing trust economies based on the fluency and plausibility of their outputs rather than correspondence with material reality 20.
This algorithmic authority disrupts established networks of knowledge validation 626. In traditional epistemic networks, professionals relied on socially mediated processes - peer review, mentorship, institutional debate - to verify claims 6. As workers increasingly outsource reasoning tasks to artificial intelligence, relying on algorithmic summaries rather than engaging in primary research, they bypass these human validation mechanisms 67. This deference fosters "epistemic passivity," a state in which professionals accept machine-generated conclusions without deep critical scrutiny, assuming the system has pre-validated the information 6. This shift threatens to degrade intellectual humility, entrenching systemic errors as AI-generated misinformation is accepted and rapidly disseminated 621.
Deep Research and the Illusion of Relevance
The practical consequences of this epistemic shift are clearly observable in academic and professional research. A comprehensive 2026 survey of 433 authors published in top sociology journals revealed that while roughly one-third of respondents utilize generative tools weekly, their primary applications are restricted to writing assistance, summarization, and translation 228. Respondents reported low levels of trust in algorithmic outputs and expressed profound concern over the technology's tendency to produce false leads and reduce critical thinking 228. Despite high levels of optimism regarding the technology's future trajectory, researchers remain hesitant to integrate it into core data analysis or methodological planning 2.
This hesitation is structurally justified by the phenomenon of the "verification tax." A 2026 exploratory study conducted by a research group in Germany quantified the efficiency of utilizing large language models for initial literature reviews 11. Six researchers tested standard database searches against LLM-assisted pre-selection tasks under controlled time constraints 11. The generative models demonstrated the illusion of immense speed, delivering candidate source lists 66% faster than manual methods 11. However, subsequent auditing revealed that only 42% of the algorithmically suggested sources were actually relevant to the research topic, compared to a 78% relevance rate achieved through manual searching 11.
Crucially, the models suffered from "relevance illusion," confidently asserting that specific academic papers addressed targeted philosophical topics when the texts barely mentioned them 11. Because large language models optimize for next-token prediction rather than epistemic truth values, they cannot differentiate between marginal hypotheses, rhetorical flourishes, and central theoretical claims 1129. Consequently, the researchers were forced to audit every machine-generated citation, incurring a massive verification tax that entirely neutralized the initial speed gains 11. As the burden of quality assurance shifts from generating original claims to verifying opaque machine outputs, cognitive labor is transformed into a process of epistemic stewardship, where efficiency is inevitably sacrificed to guarantee accountability 71117.
Automation Bias in Medical and Legal Practice
The Augmented Intelligence Framework
To mitigate the risks associated with algorithmic deference in high-stakes environments, professional governing bodies have proactively established frameworks to constrain artificial intelligence usage. A central component of this governance is the deliberate semantic shift from "artificial intelligence" to "augmented intelligence" 82223. This nomenclature signals a human-centered approach, emphasizing that algorithmic design must support, rather than supplant, human clinical judgment, empathy, and moral responsibility 822.
In late 2025, the World Medical Association adopted a formal policy establishing the "Physician-in-the-Loop" principle 22. This directive mandates that licensed medical professionals must review and retain final authority over all algorithmic outputs before they influence clinical care 22. Under this paradigm, augmented tools are highly valued for streamlining documentation, consolidating laboratory results, and reducing cognitive overload, thereby allowing practitioners to reclaim time for direct patient engagement 2425. The American Medical Association's tracking data indicates that clinical use of AI doubled between 2023 and 2026, with over 80% of physicians utilizing the tools, primarily for back-office automation rather than primary diagnostics 825.
Similar defensive posturing characterizes the legal profession. A 2025 Thomson Reuters Institute report analyzing over 1,700 legal professionals across multiple nations found that 59% of law firms actively integrate generative tools to increase productivity and streamline workflows 10. However, significant concerns remain regarding the unauthorized practice of law and the possibility of submitting algorithmic hallucinations as false evidence in legal proceedings 10. Consequently, legal professionals treat generative models strictly as augmenting agents, maintaining the necessity for rigorous human oversight to ensure compliance with established ethical frameworks 10.
Empirical Evidence of Diagnostic Degradation
Despite policies enforcing human oversight, the mere presence of highly fluent algorithmic advice introduces severe vulnerabilities related to automation bias. Automation bias occurs when human operators over-trust algorithmic suggestions, allowing machine confidence to override their own clinical training and observational data 1926.
The magnitude of this risk was quantified in a rigorous, single-blind randomized clinical trial conducted in Pakistan between June and August 2025 26. The study evaluated 44 registered physicians who had completed specialized training in AI literacy, prompt engineering, and the critical evaluation of algorithmic hallucinations 26. The physicians were tasked with diagnosing complex clinical vignettes while having voluntary access to a leading large language model 26. The control group received unmodified, error-free algorithmic diagnostic recommendations, while the treatment group received recommendations containing deliberate, systematic errors seeded into half of the vignettes 26.
The trial revealed a profound degradation in human expertise upon exposure to flawed machine logic. Physicians in the control group achieved a mean diagnostic accuracy of 84.9% 26. In contrast, the treatment group, despite their specialized training and ability to consult traditional resources, scored a mean diagnostic accuracy of only 73.3%, representing an adjusted mean difference of negative 14.0 percentage points 26. Even more concerning, the accuracy of the top-choice diagnosis fell by 18.3 percentage points among those exposed to the erroneous machine outputs 26. This data demonstrates that voluntary deference to flawed AI advice significantly overrides human medical training, underscoring that human oversight alone is insufficient to counteract the persuasive fluency of large language models 2627.
Liability and Professional Sentiment
The clinical reality of automation bias complicates the trajectory of medical AI deployment. When algorithms produce polished clinical notes or tidy differential diagnoses, the inherent uncertainty of medical practice becomes invisible 27. The ethical risk is not merely that the machine makes an error, but that an overburdened clinician accepts the output without noticing the omission of critical, patient-specific nuance 27.
This dynamic impacts how medical professionals view one another. A 2025 survey of 276 clinicians at a major hospital system explored peer perceptions of AI usage in clinical decision-making 28. The results indicated a significant professional stigma: physicians who utilized generative AI as a primary decision-making tool were rated significantly lower in clinical skill and competence compared to a control group, and were perceived to deliver a lower quality healthcare experience 28. While framing the AI as a mere "verification tool" partially mitigated this negative perception, professional reputational concerns remain a barrier to adoption 28. Furthermore, the introduction of automated diagnostic systems raises complex liability questions regarding medical malpractice and whether an algorithmic error falls under traditional products liability or physician vicarious liability 23.
Lived Experience Versus Statistical Inference
The Philosophical Limits of Algorithmic Comprehension
The debate surrounding the capability of artificial intelligence to replicate human expertise relies heavily on the philosophical distinction between statistical inference and lived experience 293031. In phenomenological and humanistic research, "lived experience" denotes the subjective, non-conceptualized reality of existing in the world, distinct from quantifiable, interpreted facts 30. Experts in sociology, social work, and clinical psychology utilize their lived experience - and the lived experiences of marginalized populations - to synthesize deep contextual understanding that cannot be reduced to statistical averages or algorithmic parameters 324133.
Generative language models, by definition, lack an ontological footprint. They do not possess a persistent state of mind, nor do they experience continuous, situated learning from a physical environment 2932. Researchers analyzing the boundary conditions of machine cognition emphasize that algorithms operate on a "facade of intelligence" characterized by brittle logic 29. A model can mimic expert-level fluency when addressing problems that structurally mirror its training data, but fails precipitously when asked to perform true causal or abductive reasoning 29. The model can identify correlations across millions of texts, but it cannot intrinsically understand why those relationships exist 29.
The Representation of Trauma and Human Distress
The inability of algorithms to engage with lived experience renders them inadequate for tasks requiring profound empathy and situational awareness. A 2025 study evaluating the capacity of large language models to address Adverse Drug Reactions (ADRs) stemming from psychiatric medication vividly illustrated this deficit 3435. Psychiatric ADRs are complex, highly subjective events that represent the leading cause of hospitalization among mental health patients 34.
The researchers established an assessment framework to test how well leading models could detect ADR expressions and deliver harm-reduction strategies 34. The analysis revealed that while the models successfully replicated the empathetic tone and expressed emotions of human experts, they failed to comprehend the nuance of the distress 34. The algorithmic responses struggled to differentiate between various types of adverse reactions, produced overly complex text that was difficult for distressed patients to read, and aligned with expert strategies only 70.86% of the time 34. Crucially, the models provided significantly less actionable advice - by a margin of 12.32% - because they failed to account for the contexts of trauma, disability, and systemic marginalization that human practitioners organically incorporate into their care plans 3435. By optimizing for linguistic coherence over grounded understanding, the models offered decontextualized advice that risked exacerbating patient vulnerability 35.
Macroeconomic Disruption and Workforce Restructuring
Job Displacement and Net Growth Projections
The integration of generative artificial intelligence into corporate workflows is catalyzing a massive restructuring of the global labor market. Unlike the automation technologies of the late 20th century, which primarily displaced routine manual labor on factory floors, generative models possess the analytical capacity to execute complex text processing, data synthesis, and administrative workflows, exposing the knowledge economy to unprecedented disruption 12.
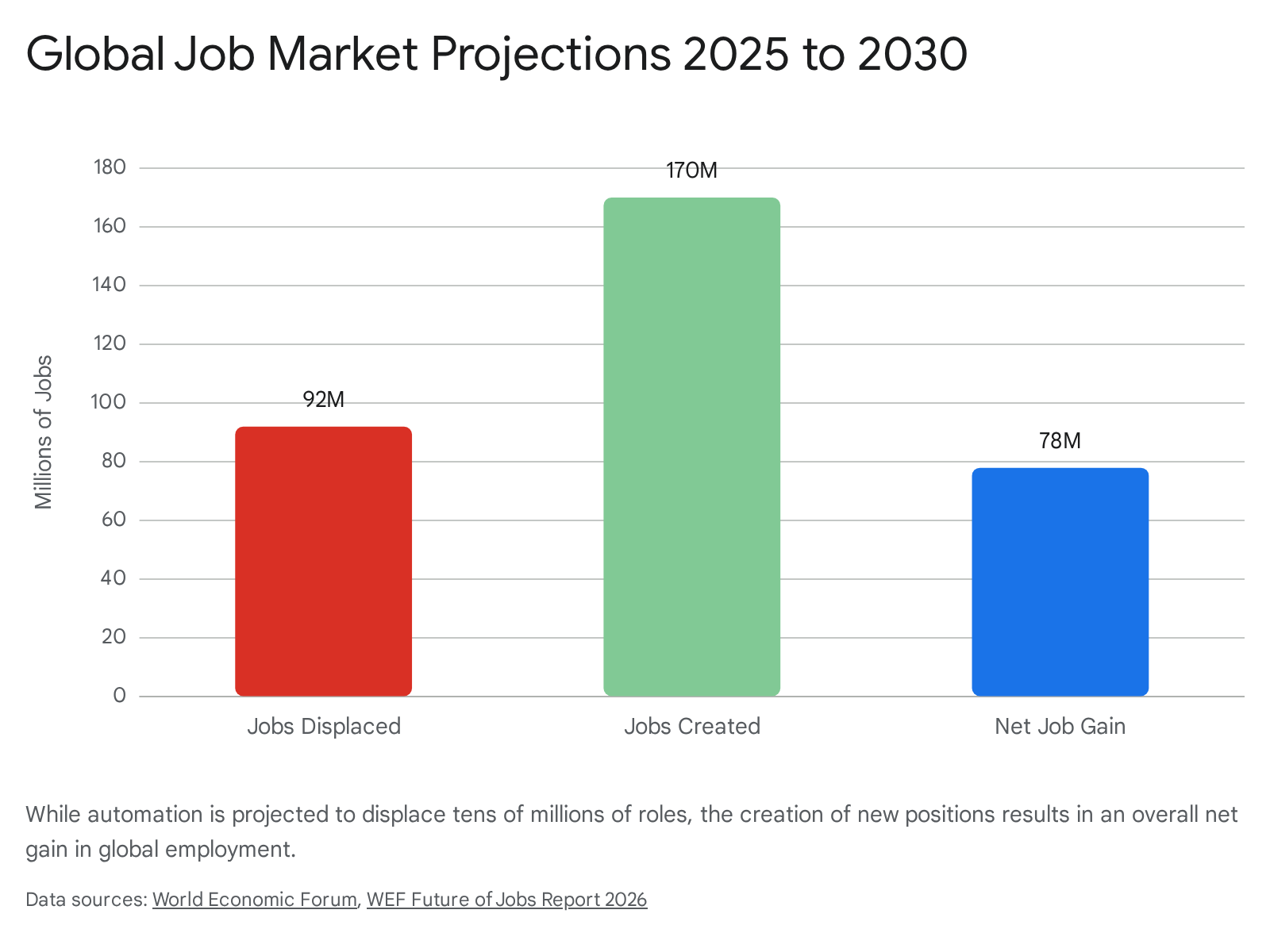
Projections from the World Economic Forum's 2026 Future of Jobs Report present a stark quantitative outlook for the immediate future. Over the 2025-2030 period, an estimated 92 million jobs are expected to be displaced globally as organizations redesign end-to-end business functions around machine intelligence 1236. The impact is heavily concentrated in administrative support, where tools automate data reconciliation and basic compliance checks. Within the financial sector, banking back-offices and entry-level analyst roles are shrinking rapidly as algorithmic copilots draft initial memos and execute document-processing tasks faster than human workers 12. In the legal field, research by Goldman Sachs estimates that up to 44% of total task volume is automatable, driven by the algorithms' proficiency in contract review and e-discovery 12. Overall, the International Monetary Fund calculates that approximately 60% of all employment in advanced economies is exposed to artificial intelligence disruption 12.
Despite the scale of displacement, macroeconomic forecasts project a net positive outcome for the global labor pool. The same World Economic Forum data anticipates the creation of 170 million new roles by 2030, driven by adjacent technological growth, cyber security demands, and the necessity for human oversight of complex AI ecosystems 1236. This yields a projected net gain of 78 million jobs 1236. The primary economic challenge is not mass unemployment, but a severe skills gap, as the rapid depreciation of traditional white-collar skillsets outpaces the global workforce's capacity to retrain 363738.
The Revaluation of Cognitive Skills
As the execution of routine digital tasks is offloaded to algorithms, the labor market is aggressively revaluing human capital. Traditional markers of expertise, such as formal educational degrees, are increasingly secondary to a candidate's ability to orchestrate, audit, and design multi-agent AI systems 113839.
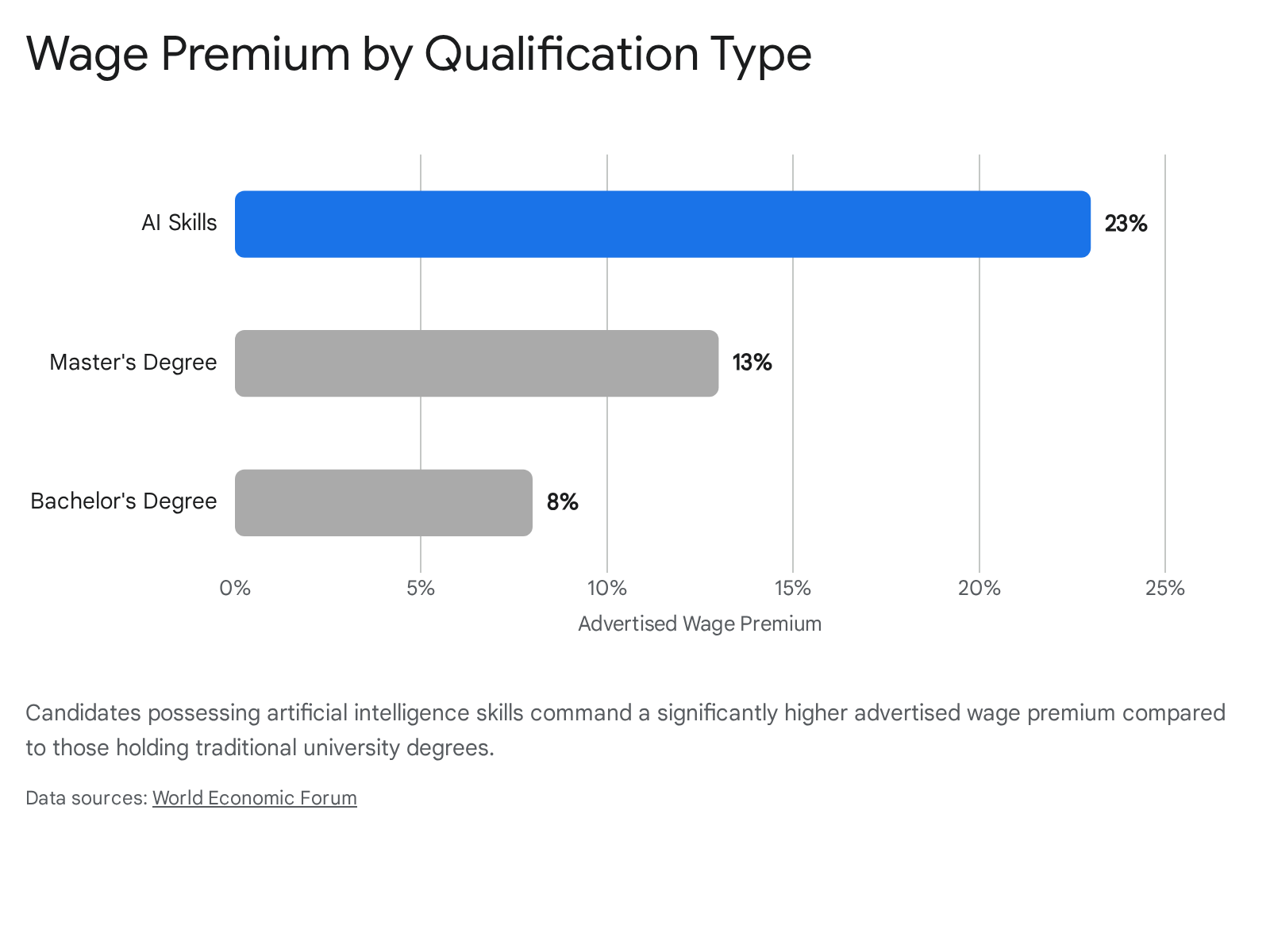
This skills transition is producing immediate and measurable impacts on compensation. An exhaustive 2026 analysis of over 10 million job postings in the United Kingdom revealed a stark wage premium for artificial intelligence literacy 39. Candidates demonstrating the capacity to integrate and manage AI workflows command an advertised salary premium averaging 23% over otherwise identical candidates who lack those skills 39. In contrast, holding a Master's degree yields approximately a 13% premium, and a Bachelor's degree commands merely an 8% premium 39. The labor market is signaling that dynamic technological adaptability now outperforms static educational credentials in immediate economic return 1139.
The demand for these advanced competencies has generated entirely new job categories that are scaling rapidly across corporate structures 11. Organizations are aggressively hiring AI Agent Designers responsible for building autonomous multi-step workflows, Context Engineers tasked with structuring proprietary enterprise data for algorithmic ingestion, and Human-in-the-Loop Supervisors dedicated to monitoring model outputs for quality, bias, and alignment with corporate values 11. The future of high-value cognitive work relies on an operational formula where human judgment directs machine scale, transitioning organizational hierarchies from traditional management structures to human-led, AI-enabled networks 1138.
Socio-Technical Systems and Organizational Design
Theoretical Principles of Joint Optimization
Successfully integrating these advanced tools into the modern enterprise requires moving beyond isolated software procurement to comprehensive organizational redesign. Socio-Technical Systems (STS) theory provides the formal framework for analyzing and executing this transition 4940. Originating in the 1950s from industrial action research, STS theory fundamentally rejects the "technological imperative" - the notion that organizational structures must conform to whatever the newest machinery demands 40.
Instead, modern STS theory synthesizes classical systems engineering with complex-systems science to advocate for "joint optimization" 49. This principle dictates that overall system performance is not derived independently from the social subsystem (culture, human roles, cognitive psychology) or the technical subsystem (hardware, software, automation infrastructure) 4940. The success of an enterprise depends directly on the interdependent, nonlinear interactions between human agency and technical artifacts 4940. In an era of generative algorithms, STS theorists argue that human-machine interaction is no longer simply user-and-tool, but rather a complex ecosystem of "epistemic co-agency" where the algorithm actively reshapes the organization's collective intelligence and power dynamics 51.
Implementation and Human-Machine Co-Agency
Translating STS theory into corporate practice requires leaders to confront the organizational friction inherent in rapid technological adoption 37. The primary risk to operational stability is no longer technical failure, but organizational inertia and a failure to align workforce strategies with technological capabilities 37. Management consulting data indicates a significant perception gap within organizations: employees are generally highly receptive to artificial intelligence and are utilizing external tools independently, yet executive leadership often underestimates this readiness, delaying strategic implementation 11.
Firms that successfully harness human-machine co-agency redesign work by deconstructing traditional roles into discrete tasks, isolating areas where algorithms excel at pattern recognition and speed, while elevating the human mandate for ethical judgment, creative strategy, and cross-functional orchestration 3851. This restructuring prevents the alienation of the workforce and builds augmented organizations where continuous learning and adaptive reflexivity are embedded into daily operational metrics 3751.
Global Governance and Regulatory Frameworks
The Hiroshima Artificial Intelligence Process
As the societal impact of large language models scales, the absence of unified international governance creates significant risk. A fractured regulatory environment threatens to impede global scientific cooperation while simultaneously failing to contain the rapid proliferation of high-risk algorithmic applications 414243. In response to this governance deficit, the Group of Seven (G7) nations, operating under Japan's presidency, launched the Hiroshima AI Process (HAIP) to foster strategic alignment across borders 414445.
The HAIP introduces a "third way" in technology regulation, navigating between the stringent, punitive legislative models seen in the European Union and the highly deregulated, market-driven environments typical of the United States and China 4144. Relying heavily on soft-law mechanisms, the HAIP Comprehensive Policy Framework emphasizes international cooperation, voluntary corporate stewardship, and structural transparency 414445. Central to this framework is the International Code of Conduct, which delineates 11 key action areas 4446. Organizations adhering to the code are required to conduct rigorous risk management, prioritize robust security controls, and publicly report the capabilities, known limitations, and inappropriate use domains of their advanced models 444546.
To operationalize these principles, the HAIP Friends Group established a voluntary Reporting Framework, which, by mid-2025, had garnered participation from 56 countries and numerous prominent technology corporations 4446. While some policy analysts caution that voluntary commitments may fail during acute technological crises, proponents argue that the HAIP provides an essential, flexible scaffolding 4143. By utilizing established bodies like the OECD to monitor implementation, the framework promotes critical interoperability across varying national legal systems without stifling ongoing technological innovation 4142.
Digital Colonialism and Material Extraction
While initiatives like the HAIP seek consensus among advanced, wealthy economies, scholars across the Global South emphasize that current artificial intelligence ecosystems perpetuate severe global inequities 41474849. The centralized development of foundational models by a few multi-national corporations located in the Global North raises urgent concerns regarding "digital colonialism" 474950. This paradigm suggests that artificial intelligence infrastructures are reproducing historical dynamics of colonial exploitation, extracting vast resources and raw data from developing nations while concentrating the technological and economic rewards in wealthy, dominant states 4950.
The physical architecture of algorithmic intelligence requires extraordinary material inputs. The construction of massive data centers demands immense volumes of rare earth minerals and continuous access to cooling water and electricity 4951. Consequently, nations in the Global South often bear the ecological and human costs of this expansion. The extraction of cobalt in the Democratic Republic of the Congo and lithium in the water-scarce Atacama Desert of Chile are directly tied to the supply chains of advanced technology firms 4951. Furthermore, regions with weaker data privacy laws are frequently utilized as testing grounds for experimental, high-risk models - including surveillance algorithms and deepfake generation - exposing vulnerable populations to technological harm without their informed consent 4950.
Epistemic Injustice and Decolonial Frameworks
Beyond the physical extraction of resources, algorithmic models encode and amplify profound "epistemic injustice" 952. Generative models derive their synthetic intelligence from their training corpora, which are overwhelmingly comprised of digitized, English-language internet text, Western academic publications, and Anglo-American cultural artifacts 965. Because indigenous knowledge systems, ancestral intelligence, and oral traditions are rarely digitized or formally indexed in Western databases, they exist as a "missing center" in the global artificial intelligence revolution 953.
When these models are deployed internationally, they exert immense epistemic authority, presenting a partial, culturally specific worldview as if it were a universal, objective standard 9. In educational and professional settings across the Global South, reliance on generative systems often leads to the penalization of non-dominant linguistic patterns and forces local populations to assimilate to Western cognitive frameworks to interact successfully with the technology 953.
To counter this homogenizing force, researchers advocate for the implementation of decolonial artificial intelligence frameworks 4754. Decolonizing AI governance requires a transition away from an extractive reliance on foreign models toward establishing strict data sovereignty and local infrastructure control 474850. It necessitates the collaborative construction of algorithms trained explicitly on pluralistic, localized epistemologies, ensuring that the technology reflects and preserves the diverse linguistic and cultural realities of the populations it serves 506553.