Uncertainty Quantification in Artificial Intelligence
Theoretical Foundations of Model Uncertainty
The Dichotomy of Aleatoric and Epistemic Uncertainty
In the deployment of artificial intelligence architectures across high-stakes and safety-critical environments, the capacity of a model to express precisely what it does not know is fundamentally as critical as the accuracy of its predictions. The discipline of uncertainty quantification formally addresses this challenge by deconstructing the total predictive uncertainty of a system into two primary constituent components: aleatoric uncertainty and epistemic uncertainty. While historical and philosophical literature delineates these categories as distinct and non-overlapping, applied implementations in machine learning consistently reveal them to be deeply intertwined and highly context-dependent 1.
Aleatoric uncertainty, frequently denoted as statistical or data uncertainty, is a product of the inherent stochasticity, measurement noise, or natural randomness embedded within the data-generating process itself 22. The terminology originates from the Latin alea, referring to the roll of a die, emphasizing that this uncertainty is a structural property of the observable world 4. Because it originates from intrinsic variability or imperfect sensor fidelity, aleatoric uncertainty is fundamentally irreducible; gathering a larger volume of data or expanding the computational capacity of the neural network will not eliminate it 234. Classical examples include the strict unpredictability of a quantum event, the outcome of a fair coin flip, or the background noise captured by a medical imaging sensor 7. In probabilistic machine learning frameworks, aleatoric uncertainty is typically captured directly by the likelihood function and its associated noise model 24.
Epistemic uncertainty, conversely, describes systematic uncertainty stemming from a structural lack of knowledge or a fundamental ignorance about the true physical process or the optimal model parameters 223. Often referred to as model uncertainty, it reflects the artificial intelligence system's inability to perfectly capture the true data manifold due to constraints such as limited training samples, deficient architectural representations, or exposure to out-of-distribution inputs 34. The term derives from the Greek word episteme, meaning knowledge 4. Unlike aleatoric uncertainty, epistemic uncertainty is theoretically reducible. Exposing the model to a more comprehensive dataset, introducing targeted human feedback, or refining the architectural representation can systematically narrow the gap between the learned approximation and the theoretical Bayes-optimal hypothesis 244.
Despite this standard pedagogical dichotomy, advanced theoretical analyses suggest that the boundary between aleatoric and epistemic uncertainties is not entirely absolute, representing more of a fluid spectrum than rigid categories 17. Mathematical definitions of these uncertainties can conflict across different schools of thought; some frameworks define epistemic uncertainty by the sheer number of plausible models that could explain the observed data, while others define it by the maximal mathematical disagreement between the learner's internal beliefs 1. Furthermore, whether a specific uncertainty is categorized as reducible often depends heavily on the specific modeling context, the engineered feature space, and the intermediate information practically available to the agent at inference time 175.
Geometric Representation of Uncertainty Distributions
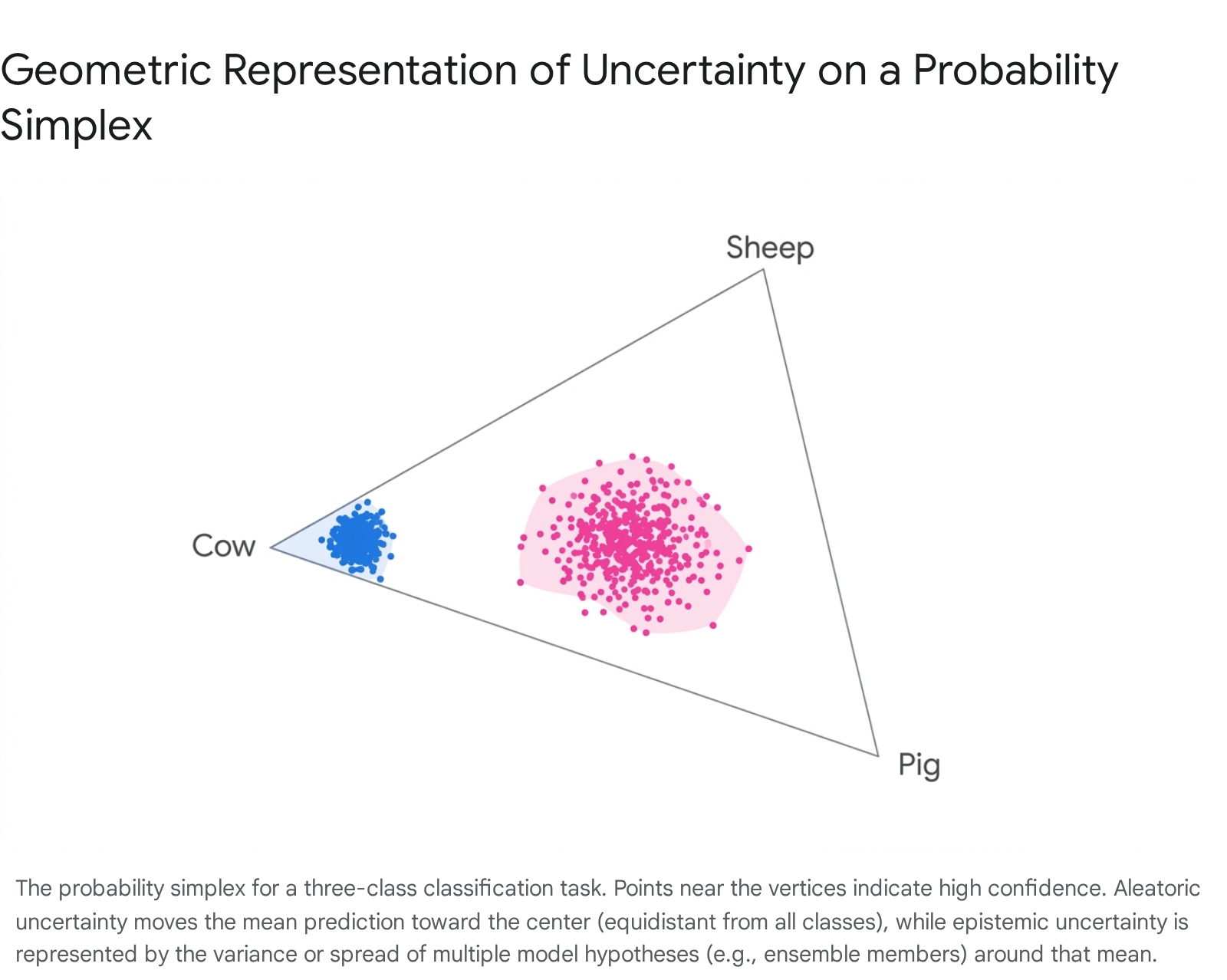
The theoretical distinction between data and model uncertainty can be mapped geometrically using a probability simplex. In a standard three-class classification problem - such as an image recognition system trained exclusively to differentiate between cows, sheep, and pigs - the output probabilities can be plotted on a two-dimensional triangular plane, where each vertex corresponds to an absolute certainty (a probability of 1.0) for a specific class 10.
When a model is highly confident in its prediction, the output probability distribution maps to a specific coordinate extremely close to one of the vertices (for example, assigning a 0.8 probability to the cow class, 0.05 to the sheep class, and 0.15 to the pig class) 10. Aleatoric uncertainty manifests when the visual data is inherently ambiguous due to poor lighting or occlusion. The model correctly identifies this data ambiguity by returning a probability distribution that is relatively flat across all classes (e.g., 0.35, 0.32, and 0.33 respectively) 10. On the geometric simplex, this probability coordinate lies near the exact center, equidistant from all vertices, indicating maximum entropy in the data representation 10.
Epistemic uncertainty, however, is best visualized not as a single discrete point, but as an entire distribution of points representing multiple model instantiations or hypotheses 10. If the model parameters are profoundly uncertain due to the introduction of out-of-distribution data, the predictions generated by different ensemble members will scatter widely across the simplex space 10. By fitting a Gaussian distribution over these points, the center corresponds to the mean ensemble prediction, while the variance - the physical spread of the probability coordinates across the simplex - quantifies the magnitude of the epistemic uncertainty 10.
Softmax Calibration and Systemic Overconfidence
Modern deep neural networks fundamentally struggle with providing accurate pointwise uncertainty estimates due to their architectural reliance on the softmax function for multi-class classification 6. The softmax function mathematically converts raw, unbounded neural network output scores (logits) into a normalized probability distribution that sums to one 612. However, because the softmax operation inherently relies on mathematical exponentiation, even moderately large logit values are exponentially magnified relative to their peers. This drives the highest class probability aggressively toward 1.0 while simultaneously shrinking all other probabilities to near-zero, a phenomenon that can trigger numerical instability issues like overflow or underflow 6. Frameworks mitigate this specific numerical instability using the log-sum-exp trick, which subtracts the maximum logit value before exponentiation, though this does not solve the underlying calibration failure 6.
This exponentiation results in severe systemic overconfidence, often termed the "I Know Everything Syndrome" 6. A neural network operating on anomalous, out-of-distribution data may yield entirely arbitrary, unsupported logits, but the softmax operation forces the network to express near-absolute certainty in whichever class happens to have the marginally highest raw score 61213. Mathematically, if the classes are perfectly separated within the training manifold, the log softmax scores can grow unbounded, mimicking the behavior of strict overfitting and producing exceptionally unreliable confidence metrics upon real-world deployment 12.
To mitigate softmax overconfidence, several post-hoc calibration techniques operate directly on the logits. Temperature scaling introduces a user-defined scalar parameter (T > 1.0) during inference that globally smooths the logit distribution before the softmax operation is applied, reducing the extremity of the output probabilities without altering the actual class predictions or the underlying network accuracy 67. While temperature scaling, Platt scaling, and isotonic regression can effectively minimize the Expected Calibration Error (ECE) on tightly controlled in-distribution validation sets, comprehensive empirical surveys reveal that these post-hoc methods become progressively less reliable - and sometimes actively counterproductive - under severe distribution shifts 137. Foundation models, surprisingly, have been shown to occasionally exhibit underconfidence on in-distribution data but improved calibration on shifted data, challenging established narratives regarding how architectural scaling impacts calibration curves 13.
Probabilistic Methodologies for Deep Neural Networks
To bypass the mathematical limitations of softmax point estimates, the field of machine learning has engineered robust probabilistic frameworks that explicitly model the distribution of possible network parameters or construct statistically rigorous prediction sets.
Deep Ensembles and Monte Carlo Dropout
Two foundational, competing techniques for estimating epistemic uncertainty in deep learning architectures are Deep Ensembles and Monte Carlo (MC) Dropout.
Deep Ensembles operate on the principle of training multiple neural networks featuring identical architectures but initialized with different random weights and exposed to randomly shuffled data batches during training 8. During the inference phase, a novel input is passed independently through all members of the ensemble. The variance across the ensemble's disparate predictions serves as a highly robust proxy for epistemic uncertainty. When evaluated on complex out-of-distribution benchmarks and medical imaging diagnostics, Deep Ensembles frequently outperform alternative methodologies in capturing uncertainty boundaries and reducing the Mean Absolute Error (MAE) of the final aggregated prediction 910. However, their practical utility is severely constrained by the massive upfront computational overhead required for training, maintaining, and executing multiple deep networks in parallel 910.
MC Dropout provides a computationally lighter approximation of true Bayesian inference. Originally conceived purely as a regularization technique to prevent overfitting by randomly zeroing out targeted neuron activations during the training phase, researchers subsequently discovered that maintaining active dropout layers during the evaluation phase allows a single, deterministic network to function as a functional probabilistic model 91811. By executing multiple forward passes of the exact same input using different stochastic dropout masks, the network generates an empirical distribution of predictions 91120. The standard deviation calculated across these passes yields a variational approximation of the model's epistemic uncertainty 1811. While MC Dropout elegantly circumvents the requirement to train multiple distinct models, it mandates multiple sequential or parallel forward passes during inference, introducing non-trivial latency bottlenecks 918. Furthermore, empirical studies on mid-infrared spectroscopy and hyperspectral imaging indicate that MC Dropout alone frequently struggles to achieve desired statistical coverage probabilities on out-of-domain data, occasionally failing to encompass the true observation within its stated 90% prediction intervals 1222.
Conformal Prediction Frameworks
Conformal Prediction (CP) has rapidly gained significant traction across the machine learning community as a distribution-free, model-agnostic approach to uncertainty quantification 201213. Instead of fundamentally modifying the neural network architecture or assuming a specific underlying Bayesian data distribution, CP constructs statistically rigorous uncertainty bands (or prediction sets) surrounding the model's standard point predictions 20.
The standard CP methodology relies heavily on an inductive hold-out dataset, termed the calibration set. The pre-trained model generates predictions on this specific calibration set, and the outputs are systematically compared against the ground truth to compute a vector of non-conformity scores 1120. These scores mathematically quantify how unusual or divergent a new example is relative to the previously observed training data 1120. By identifying the empirical quantile of these accumulated non-conformity scores, the CP algorithm establishes a specific calibration threshold 1120. During active inference, this exact threshold is applied to generate a prediction interval that provides a mathematical guarantee of marginal coverage - meaning the true value will fall within the generated interval with a precise, user-specified probability (e.g., exactly 90% or 95%) 1112.
While CP provides unparalleled and rigorous statistical guarantees, its primary operational drawback is its tendency to produce highly conservative, unnecessarily wide prediction intervals, particularly when the underlying heuristic scores utilized for calibration are poorly scaled or uninformative 1213.
Hybrid Implementations and Adaptive Computational Modulation
| Deep Learning UQ Methodology | Primary Algorithmic Mechanism | Key Advantages | Primary Limitations |
|---|---|---|---|
| Deep Ensembles | Aggregates predictions across multiple independently trained neural networks. | Unmatched empirical robustness; excellent at capturing pure epistemic uncertainty. | Severe computational and memory overhead for parallel training and storage. |
| MC Dropout | Executes multiple forward inference passes while active dropout layers randomly mask neurons. | Entirely model-agnostic; requires no additional training phases; low storage overhead. | Increases inference latency significantly; frequently struggles to hit precise marginal coverage targets. |
| Conformal Prediction | Utilizes calibration hold-out sets to compute empirical non-conformity quantiles. | Mathematically guarantees exact marginal coverage; strictly distribution-free. | Prone to producing overly wide, highly conservative prediction intervals that limit decision utility. |
| Adaptive MC-CP | Adjusts MC Dropout distributions via Conformal Prediction thresholds while applying early-stopping. | Achieves exact coverage guarantees while maintaining narrow, sample-specific intervals; reduces latency. | Still requires multiple inference passes; highly dependent on optimal calibration set selection. |
To actively balance the precise out-of-domain sensitivity provided by MC Dropout with the rigorous mathematical coverage guarantees established by Conformal Prediction, researchers have engineered hybrid techniques, most notably Monte Carlo Conformal Prediction (MC-CP) 1112.
MC-CP functions by first utilizing the MC Dropout methodology to generate a base prediction interval for an individual sample, effectively capturing the localized epistemic uncertainty intrinsic to that specific input. Conformal prediction is subsequently applied on top of this generated distribution to systematically extend or adjust the interval based on the calibration set's pre-calculated non-conformity quantile 11. In rigorous empirical testing on complex soil spectral models, the MC-CP architecture successfully corrected MC Dropout's severe under-coverage (raising empirical coverage from an inadequate 74% to the target 91%) while concurrently producing significantly narrower and more practically informative prediction intervals than native, standalone Conformal Prediction 111222.
To directly address the inference latency inherently caused by requiring multiple forward passes, Adaptive MC-CP incorporates principles from the Law of Large Numbers to modulate the algorithm dynamically at runtime. Because each distinct dropout pass can be accurately modeled as a Bernoulli process, the unique variance added by subsequent passes diminishes exponentially over time 18. Adaptive frameworks monitor this stabilization and halt the MC Dropout iterations early once the prediction variance delta falls below a specific threshold, aggressively preserving memory and compute resources without materially degrading the quality or coverage of the final uncertainty interval 1824.
Uncertainty Estimation in Large Language Models
The paradigm shift from standard classification networks to autoregressive Large Language Models (LLMs) fundamentally alters the landscape and mathematical formulation of uncertainty quantification. LLMs do not simply output a singular probability distribution for a fixed, finite set of classes; rather, they iteratively generate open-ended sequences of tokens, massively complicating the theoretical definition of what constitutes a "correct" or "confident" model state 2526.
Token-Level Versus Sequence-Level Calibration
LLM calibration must be rigorously evaluated across two highly distinct operational axes: the token level and the sequence level. At the token level, an LLM outputs a localized, granular confidence measure via the specific log-probability of the single next token it predicts 26. Traditional calibration literature and empirical evaluations suggest that base pre-trained models - those trained strictly via maximum likelihood estimation without subsequent alignment - are generally exceptionally well-calibrated at this next-token level 1415. Metrics such as token-wise Expected Calibration Error (ECE), token margin scores, and calibration tokens are highly effective mechanisms for assessing and enforcing this local alignment during inference 2616.
However, sequence-level calibration remains a volatile and highly contested research frontier 26. A model may be statistically highly confident in predicting the next syntactic token (e.g., a grammatical conjunction), but remain entirely uncertain regarding the overarching factual trajectory or semantic meaning of the complete sentence being constructed. Furthermore, modern post-training alignment techniques - specifically Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO), and Group Relative Policy Optimization (GRPO) - heavily disrupt sequence-level calibration architectures 2514. These fine-tuning methodologies fundamentally alter the model's behavior to maximize abstract human-preference rewards, aggressively shifting the internal probability mass away from maximum likelihood estimation and artificially exacerbating systemic overconfidence 72514.
Consequently, heavily instruction-tuned models frequently generate highly confident, exceptionally articulate, yet entirely factually hallucinated prose because their sequence-level confidence has been decoupled from empirical accuracy 725. To counteract this misalignment, engineers are developing token-level reward models that attempt to assign granular preference or utility signals to each individual token generated in a sequence, effectively bridging the gap between token-level statistical likelihood and sequence-level factual alignment 3031. By utilizing Q-function estimation and contrastive distillation to learn robust signals, these models provide dense, actionable feedback at each generation step, vastly improving credit assignment 3031.
Logit-Based and Verbalized Confidence Metrics
To successfully extract uncertainty from production LLMs, researchers traditionally rely on either white-box, logit-based methods or black-box, verbalization-based methods 17.
Logit-based methods utilize the raw token probabilities directly from the model's generator head to mathematically assess confidence. While computationally highly efficient - requiring no additional generation passes or complex secondary prompting - they are frequently totally inaccessible in commercial, API-only deployments where internal states and weight matrices are heavily obfuscated by providers 2533. Furthermore, logit-based metrics exhibit high sensitivity to inference temperature manipulation. At lower sampling temperatures, the inherent diversity of the generated results systematically decreases, which artificially inflates the raw confidence metric and dangerously masks the true epistemic uncertainty of the underlying model 17.
Verbalized confidence seeks to bypass the strict requirement for logit access by directly prompting the LLM to linguistically state its own certainty (e.g., embedding a system prompt demanding: "Answer the following query and provide a rigorous confidence score between 0 and 100") 1718. While highly interpretable and exceptionally simple to integrate into zero-shot agentic pipelines, verbalized confidence is empirically prone to severe miscalibration 1920. Academic studies heavily indicate that LLMs consistently exhibit a phenomenon termed "suggestibility bias," reliably reporting exceptionally high verbal confidence on completely hallucinated or factually incorrect claims, particularly when actively faced with niche information they possess very little pre-trained knowledge about 19.
To systematically mitigate this verbalized overconfidence, advanced frameworks like Distractor-Normalized Coherence (DiNCo) have been introduced to the literature. DiNCo actively estimates the LLM's inherent suggestibility bias by explicitly forcing the model to verbalize confidence across multiple self-generated, mutually exclusive distractors (alternative, incorrect factual claims). By mathematically normalizing the target answer's stated confidence against the total cumulative verbalized confidence of the surrounding distractors, the system is capable of producing a much less saturated, significantly more reliable sequence-level uncertainty estimate 19.
Semantic Entropy and Equivalence Clustering
Perhaps the most significant theoretical barrier to precise LLM uncertainty quantification is the phenomenon of semantic equivalence: an LLM can successfully generate the exact same underlying factual answer using vastly different phrasing, structure, and token sequences (e.g., stating "Paris," "It's Paris," or "The capital of the nation is Paris") 1537. If an evaluation system naively measures uncertainty solely by looking for identical, repeating token sequences across multiple samples, it will incorrectly flag benign semantic variations as catastrophic epistemic uncertainty.
To definitively solve this, researchers developed the concept of Semantic Entropy 37. This advanced black-box technique begins by sampling multiple, diverse responses to a single identical prompt, typically operating at an artificially high sampling temperature to force generation diversity. It then utilizes an auxiliary Natural Language Inference (NLI) model to explicitly cluster the resulting generations based strictly on their semantic equivalence, entirely ignoring their superficial lexical token composition 3721. The mathematical entropy is subsequently calculated over these aggregated semantic clusters rather than the raw token outputs. A highly entropic distribution of clusters decisively indicates that the model is generating factually disjoint, contradictory answers, signaling severe epistemic uncertainty and a high probability of hallucination 3739. Further advancements, such as Semantic Density, refine this by establishing a response-specific confidence metric grounded in deep semantic analysis, enabling granular evaluation without requiring any additional training or fine-tuning of the base models 40.
While Semantic Entropy is highly predictive of actual model accuracy and factual grounding, its fundamental reliance on multi-sample generation heavily impairs its viability in real-time production applications, conventionally requiring between five to ten full sequence inference calls merely to generate a single validated confidence score 22. Alternatively, novel architectural frameworks like Recurrent Attention-based Uncertainty Quantification (RAUQ) actively attempt to measure deep uncertainty in a single forward pass by directly leveraging the intrinsic signals of attention weights and internal probabilities, bypassing the massive computational need for repeated sampling entirely 42.
Bayesian Inference over Textual Prompts
A critical, frequently overlooked limitation of current LLM UQ frameworks is the rigid assumption of prompt certainty. Models are notoriously highly sensitive to the precise lexical phrasing of input prompts, yet the vast majority of UQ methodologies treat the input prompt as a static, flawless oracle 2023.
Recent theoretical advancements have successfully introduced Bayesian inference directly over the vast space of free-form text prompts. By formally interpreting prompts as textual parameters within a unified statistical model, researchers have successfully applied advanced sampling algorithms, such as Metropolis-Hastings through LLM Proposals (MHLP), to iteratively sample from a true Bayesian posterior of optimized prompts 2023. Passing these dynamically sampled, varying prompts through the LLM provides a highly principled, fully Bayesian quantification of overarching uncertainty that accurately accounts for both the inherent ambiguity in human instruction formulation and the internal generative variance of the foundation model itself 23.
Computational Overhead and Deployment Constraints
The theoretical development of advanced UQ methods frequently clashes violently with the physical and financial constraints of production hardware, particularly when attempting to scale rigorous probabilistic evaluation to foundation models possessing 70 billion parameters or more.
The Memory Wall in Massive Parameter Inference
During the autoregressive decoding phase, an LLM sequentially generates a single token per forward pass. To execute this discrete mathematical pass, the underlying GPU architecture must read absolutely all of the model's static weights from VRAM directly into the compute units 24. For a 70B parameter model explicitly utilizing FP16 precision, these weights alone occupy roughly 140GB of VRAM 2445. Additionally, the KV cache - which stores attention states dynamically scaling with sequence length - further compounds this memory footprint 24.
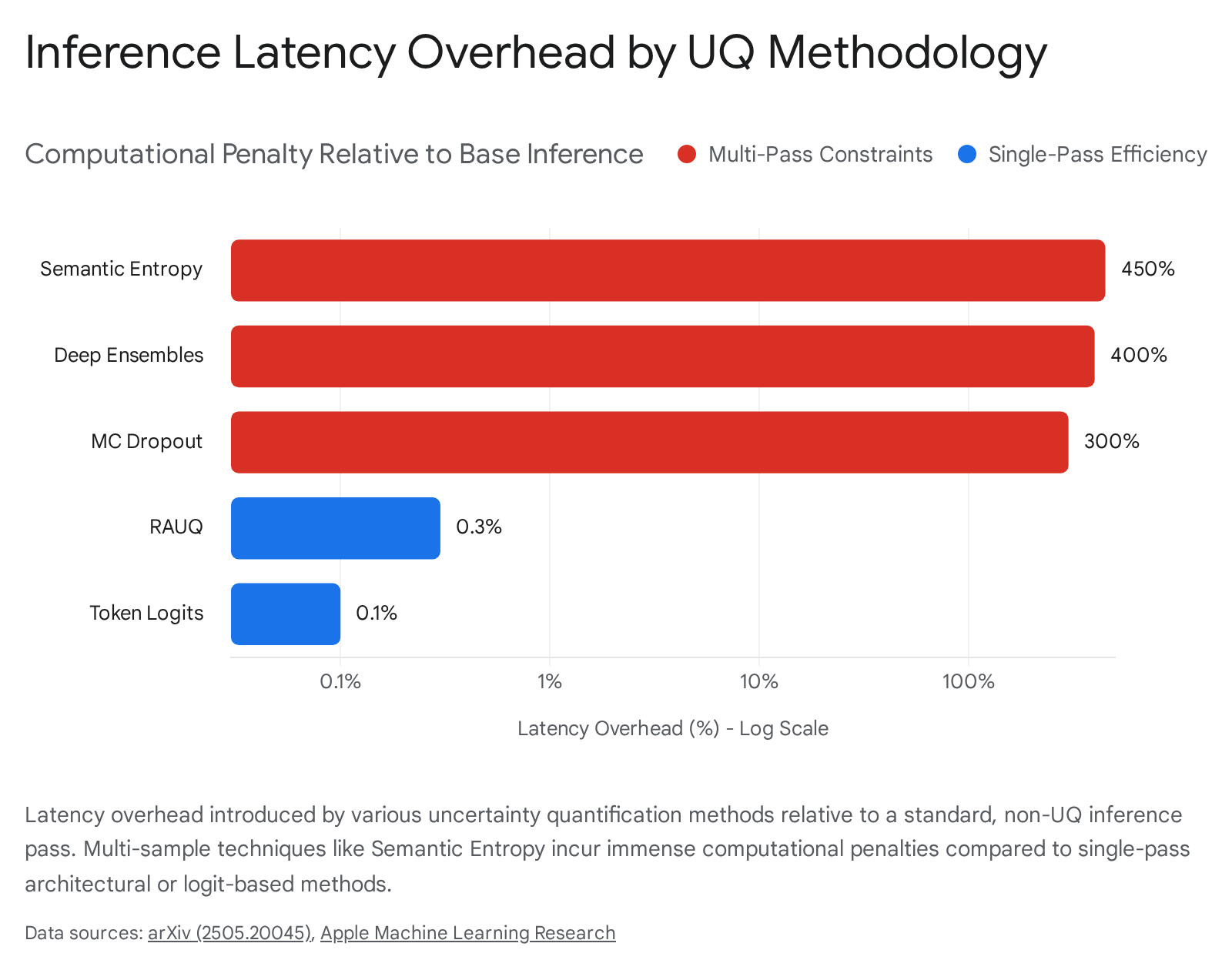
Because modern high-performance GPUs compute arithmetic operations vastly faster than they can physically transfer bytes of data across the memory bus, LLM inference is almost exclusively constrained by what engineers term the "Memory Wall" 24. The arithmetic intensity of autoregressive decoding sits far below the compute roofline. On an Nvidia H100 SXM5, operating at a maximum theoretical memory bandwidth of 3.35 TB/s, transferring 140GB of weights consumes approximately 42 milliseconds per token, leaving raw FLOPS entirely idle 24. Because the operational latency bottleneck is strictly tied to sequential data movement rather than raw computation, executing multiple sequential passes for MC Dropout or Semantic Entropy multiplies this 42-millisecond latency penalty linearly per sample 2445. A multi-sample UQ approach that requires ten inference calls introduces an untenable 400% to 800% computational overhead, rendering these methods financially and operationally unviable for high-concurrency, low-latency commercial applications 4245. Conversely, single-pass methods like RAUQ introduce a negligible latency overhead of roughly 0.3% because they piggyback on the intrinsic attention computations already occurring during the primary forward pass 42.
Hardware Benchmarks and Quantization Trade-Offs
| Hardware Infrastructure | VRAM Capacity | Memory Bandwidth | Operational Capability & Cost Trade-Offs |
|---|---|---|---|
| Nvidia H100 SXM5 | 80 GB | 3.35 TB/s | Extremely high throughput for FP8 Tensor Cores. Cannot fit a 70B FP16 model alone; requires a costly dual-GPU setup (~$5.98/hr) 2445. |
| Nvidia H200 SXM5 | 141 GB | 4.8 TB/s | Sufficient VRAM to comfortably hold a 70B FP8 model alongside a large KV cache. Best latency-per-token for memory-bound applications 24. |
| AMD MI300X | 192 GB | 5.3 TB/s | Massive memory capacity allows serving 140GB FP16 models natively with headroom. Superior memory bandwidth reduces decode latency without multi-GPU coordination 24. |
| Nvidia RTX 4090 | 24 GB | ~1.0 TB/s | Consumer-grade cost-efficiency ($0.49/hr). Requires aggressive 4-bit INT4 quantization to span across multiple cards for 70B models, sacrificing some precision for extreme cost savings 46. |
To aggressively mitigate the Memory Wall and reduce the massive GPU costs associated with 70B parameter deployments, machine learning engineers routinely apply Post-Training Quantization (PTQ) to permanently reduce the precision of the model weights. Compressing a 70B model from FP16 down to 4-bit integer (INT4) formats via advanced techniques like AWQ or GPTQ slashes the VRAM requirement by up to 75% 46. This compression theoretically allows the model to fit on significantly cheaper consumer-grade hardware (e.g., dual RTX 4090s instead of dual A100s) and drastically improves memory bandwidth throughput by halving the bytes moved per token 46.
However, the precise intersection of extreme quantization and uncertainty quantification remains highly sensitive and frequently unstable. Research indicates that while 8-bit quantization results in minimal quality degradation (typically less than a 1% drop in accuracy), 70B parameter models experience noticeable performance drops and severe calibration distortions when pushed to 4-bit representations without advanced activation-aware calibration 46. Quantization structurally alters the underlying logits; if an uncertainty framework fundamentally relies on evaluating exact, continuous token probabilities (as in white-box UQ), the mathematical truncation of weights can artificially compress or warp the distribution, fatally corrupting the epistemic uncertainty signal 46.
Agentic Uncertainty and Interactive Refinement
Historically, academic uncertainty quantification has primarily treated LLMs as static, isolated oracles: a system prompted exactly once, and evaluated strictly by the pointwise uncertainty of a single, definitive response 25. However, as the industry rapidly shifts toward deploying LLM-driven autonomous agents capable of dynamic tool-calling, database querying, and multi-step reasoning architectures, this static evaluation paradigm is rapidly becoming obsolete.
Mitigating Failure in Multi-Step Reasoning
In an open, interactive environment, AI agents acquire new contextual information iteratively. If an agent experiences high epistemic uncertainty regarding a specific prompt or sub-task, it does not necessarily need to immediately abstain or fail gracefully; it can execute interactive, corrective actions - such as directly requesting clarification from the user or retrieving external verifying data to systematically resolve the ambiguity 25.
The critical challenge in agentic UQ is preventing the catastrophic propagation of overconfident errors across exceptionally long interaction trajectories. Because errors made in the early planning or retrieval stages compound non-linearly, agents must be engineered to accurately assess the statistical likelihood of failure at each discrete step before committing to irreversible or highly costly actions 2526. Recent comprehensive studies evaluating models on complex, multi-step reasoning benchmarks actively demonstrate that stepwise, token-level confidence scoring vastly outperforms holistic, sequence-level scoring in detecting potential agentic failures, yielding up to a 15% relative increase in the AUC-ROC detection metric 26. Furthermore, testing UQ against specifically designed ambiguous question-answering datasets (such as AmbigQA and MAQA) reveals that traditional estimators - including both deep ensembles and predictive distributions - frequently degrade to near-random performance under genuine semantic ambiguity, motivating a shift toward algorithms that explicitly model ambiguity during the primary training phase 27.
Advanced algorithmic deployments, such as SIFT (Selecting Informative data for Fine-Tuning), integrate test-time training to dynamically and economically manage this uncertainty. By indirectly measuring its own uncertainty during active text generation, the LLM autonomously computes the exact volume of external context it must dynamically retrieve to confidently cross a pre-set reliability threshold, adapting its raw computational overhead strictly based on the complexity of the query 28.
Open-Source Ecosystems and Evaluation Libraries
| UQ Evaluation Library | Supported Architectures | Core Capabilities and Methods Implemented |
|---|---|---|
| Torch-Uncertainty | General Deep Neural Networks (PyTorch) | Standardizes application of MC Dropout, Deep Ensembles, and Bayesian architectures. Built-in routines for OOD detection, calibration metrics, and automated reliability plotting 1051. |
| uqlm | Large Language Models | Democratizes hallucination detection with off-the-shelf implementations of Semantic Entropy (black-box), logit-based (white-box), and LLM-as-a-judge scorers. Normalizes diverse signals into a standard [0,1] confidence score 332129. |
| LM-Polygraph | Large Language Models (Hugging Face) | Integrates natively with the HF ecosystem to offer highly controllable evaluation environments for both raw and normalized generation-time uncertainty metrics over various text generation tasks 2130. |
The extreme fragmentation of historical UQ research - characterized by divergent definitions, unstandardized metrics, and bespoke implementations - has historically hindered its active adoption by software engineers in commercial settings 30. Recently, several highly robust, open-source programming libraries have emerged to successfully standardize uncertainty evaluation across both traditional deep learning ecosystems and modern LLM deployment pipelines.
For general deep neural networks, comprehensive libraries such as Torch-Uncertainty provide rigorously unified PyTorch implementations of classical algorithms. The framework aggressively standardizes the application of MC Dropout, Deep Ensembles, and complex Bayesian architectures across diverse classification and semantic segmentation tasks, simultaneously offering built-in routines for out-of-distribution detection and expected calibration error reporting 1051.
For generative language models, the uqlm (Uncertainty Quantification for Language Models) Python package actively democratizes generation-time hallucination detection. uqlm provides off-the-shelf, highly optimized implementations of black-box (Semantic Entropy), white-box (logit-based), and LLM-as-a-judge scorers 332129. Crucially, the library mathematically normalizes these diverse, disparate uncertainty signals into a standardized [0, 1] confidence scale, allowing software engineers to establish strict programmatic safety guardrails at generation time without requiring access to external ground-truth data or demanding heavy infrastructure modifications 3321. Similarly, LM-Polygraph extends the established Hugging Face ecosystem to offer controllable evaluation environments for benchmarking novel UQ techniques, acting as a critical, standardized bridge between theoretical academic UQ research and reliable, production-grade AI deployment 2130.