Theory of mind and false belief tasks in large language models
The Cognitive Foundations and the Theory of Mind Debate
Theory of Mind (ToM) refers to the cognitive capacity to attribute mental states - such as beliefs, desires, intentions, and emotions - to oneself and others, and to understand that others possess beliefs, perspectives, and knowledge that may differ from one's own 123. In human developmental psychology, this capacity is considered a foundational pillar of social intelligence, typically emerging between the ages of four and six 33. It is the underlying mechanism that enables humans to interpret indirect requests, recognize deception, understand irony, and navigate the complex, unstated rules of social interaction 4.
With the rapid scaling of Large Language Models (LLMs) over recent years, a highly contested question has emerged within cognitive science and artificial intelligence research: Do these artificial systems possess a Theory of Mind, and what do their performances on standardized cognitive tests actually measure? The debate in the literature is distinctly polarized. One faction of researchers suggests that ToM-like capabilities have spontaneously emerged in large parameter spaces as a byproduct of next-token prediction over vast corpora of human discourse 165. Proponents of this view point to evidence that advanced models can track character knowledge and navigate complex social scenarios at a level comparable to, or sometimes exceeding, adult human performance 66.
Conversely, an equally prominent body of research posits that LLMs rely entirely on superficial statistical pattern matching, demonstrating what is termed "literal" or "illusory" Theory of Mind 97. In this framing, LLMs can successfully mimic mentalizing behaviors by leveraging linguistic correlations and syntactic structures learned during pretraining. However, they fundamentally lack the stable, robust, and embodied internal world models required to functionally apply ToM in novel, dynamic, or adversarial environments 8129. Evaluating these competing claims requires a meticulous examination of how LLMs perform across classic psychological assessments, newly designed algorithmic benchmarks, and functional, multi-agent interactions.
Performance on Classic Psychological Benchmarks
False Belief Tasks and Developmental Milestones
The traditional gold standard for assessing Theory of Mind in developmental psychology is the "False Belief Task" (commonly instantiated as the Sally-Anne test or the unexpected contents test). This paradigm evaluates whether a subject recognizes that a character can hold a belief that contradicts reality 414. In these narratives, a character places an object in a specific location and leaves; a second character moves the object in their absence; the test then asks where the first character will look for the object upon returning 610.
Initial evaluations of LLMs using these classic paradigms revealed a sharp, almost phase-transition-like developmental trajectory. Early language models, particularly those deployed prior to late 2022, universally failed false belief tasks, achieving near-zero accuracy 6. However, the introduction of the GPT-3.5 and GPT-4 architectures marked a significant inflection point in the literature. Extensive research demonstrated that GPT-4 could solve approximately 75% of classic false belief tasks, performing equivalently to a six- or seven-year-old human child 611.
Building on this, researchers adapted human assessments into machine-readable datasets such as ToMi (Theory of Mind in Interactions). Early results on ToMi suggested that large-scale models had mastered the ability to track first-order and second-order false beliefs (e.g., "Alice thinks that Bob believes...") based purely on textual inputs 212. This led to early assertions that neural networks were developing generalized capacities for multi-step belief reasoning 6.
Irony, Faux Pas, and Strange Stories
To probe the depth of these emergent capabilities, researchers expanded testing beyond simple spatial false beliefs to include complex social phenomena. A comprehensive 2024 study by Strachan et al., published in Nature Human Behaviour, subjected frontier models (including GPT-4 and Llama 2) to a broad battery of psychological ToM tests alongside a sample of 1,907 human participants 56.
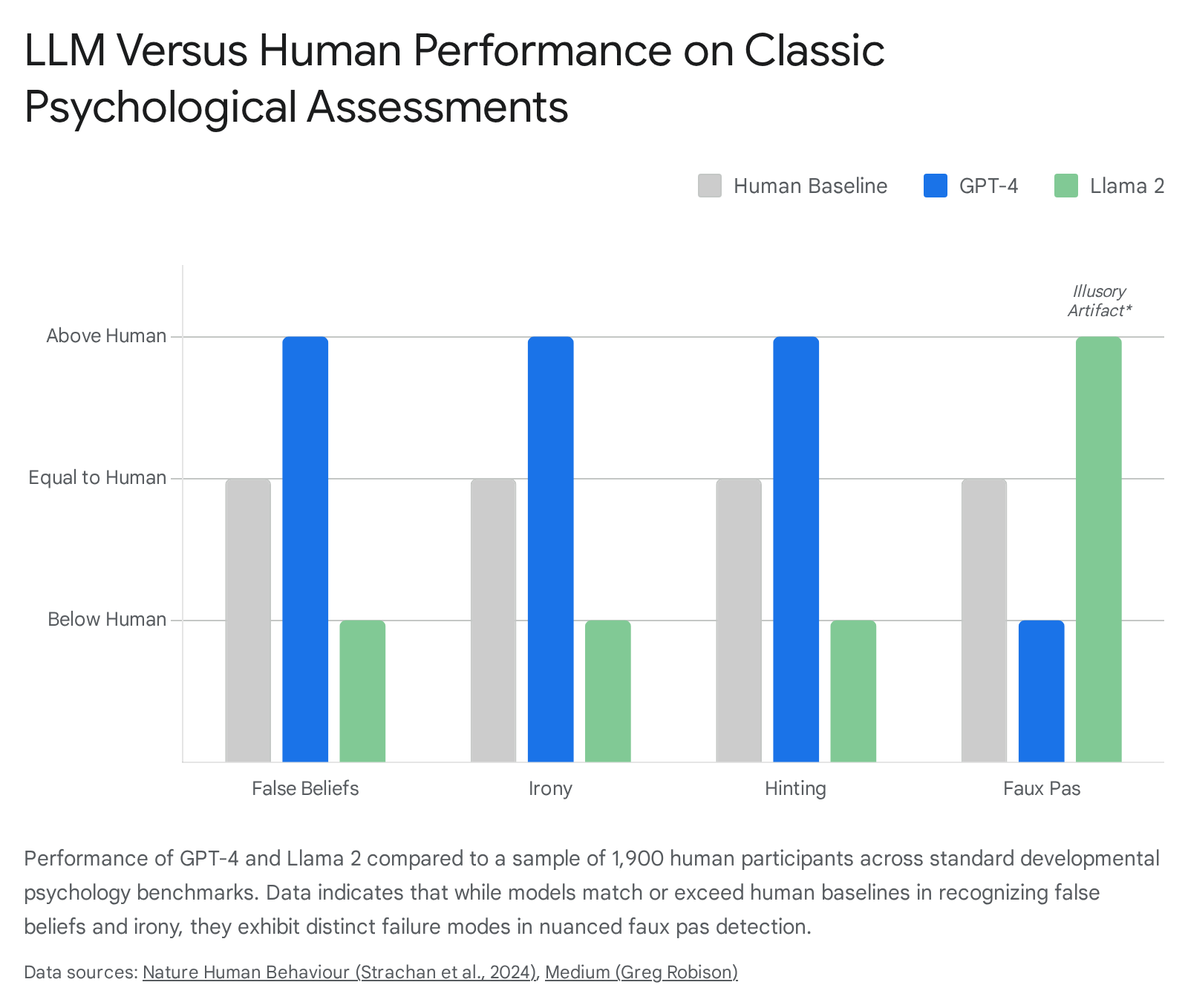
The assessments included the Hinting Task (inferring hidden intentions), Happé's Strange Stories (understanding white lies and sarcasm), and faux pas detection (recognizing socially inappropriate remarks) 66.
The empirical findings were striking: GPT-4 models performed at, or occasionally above, human levels in identifying indirect requests, tracking misdirection, and recognizing irony 56. However, nuanced limitations emerged upon closer analysis. GPT-4 struggled significantly with faux pas detection. Follow-up diagnostic testing revealed that this failure did not stem from an inability to represent another character's ignorance; rather, it was an artifact of the model's reinforcement learning from human feedback (RLHF) 66. GPT-4 exhibited a hyper-conservative alignment posture, demonstrating a profound hesitation to label any generated statement as socially insulting or inappropriate 6.
In the same study, the Llama 2 architecture appeared to outperform human participants on the faux pas test 6. However, subsequent structural manipulations of the belief likelihoods in the prompts demonstrated that Llama 2's apparent superiority was illusory. The model possessed a systemic bias toward attributing ignorance to characters regardless of context, which coincidentally yielded high scores on tests where ignorance was the correct answer, but failed entirely when the logical structure required a different heuristic 6. These findings underscore that success on static, text-based narratives - many of which are likely present in the models' vast pretraining data - does not equate to actual cognitive mentalizing 712.
The Divergence of Explicit and Applied Social Reasoning
To rigorously test whether LLMs possess a functional understanding of mental states rather than a memorized heuristic, researchers have introduced paradigms that differentiate between Explicit Theory of Mind and Applied Theory of Mind. Explicit ToM measures the ability to state what a character perceives or believes based on the text. Applied ToM measures the ability to use that inferred knowledge to accurately predict downstream behavior or judge the rationality of an action 13.
Mental State Inference Versus Behavior Prediction
The "SimpleToM" benchmark, released in 2024, was designed to explicitly target this cognitive gap. SimpleToM utilizes concise, everyday narratives featuring natural information asymmetries - for example, a customer picking up a grocery item that contains a hidden defect, or a patient interacting with a healthcare provider who lacks complete records 141516. The benchmark asks models three sequential questions that escalate in functional complexity 15: 1. Mental State Inference (Explicit ToM): Is the character aware of the hidden defect? 2. Behavior Prediction (Applied ToM): Will the character proceed to purchase the item or report the defect? 3. Behavior Judgment (Normative Applied ToM): If the character purchases the item, was that action reasonable given their perspective?
The empirical results from SimpleToM expose a jarring fragility in modern LLM architectures. State-of-the-art models - including GPT-4o, Anthropic's Claude 3.5 Sonnet, Meta's Llama 3.1 405B, and OpenAI's reasoning model o1-preview - demonstrate near-perfect proficiency in Explicit ToM. These models consistently achieve greater than 95% accuracy when asked to infer the character's mental state 171819.
However, when asked to functionally apply this knowledge to predict behavior, performance collapses. For instance, GPT-4o's accuracy drops from 95.6% on mental state prediction to 49.5% on behavior prediction 1319. The collapse indicates that while LLMs excel at tracing factual awareness through a text sequence (a process dependent on linguistic lookback mechanisms), they struggle to integrate that inferred knowledge with commonsense rules of human action 12. When a human realizes a character does not know a product is defective, the human seamlessly predicts the character will act in ignorance and buy it. LLMs, conversely, frequently fail to bridge the logical gap between "knowing the character is ignorant" and "predicting the character will act on that ignorance" 14.
Normative Judgments in Contextual Scenarios
The deficit deepens substantially at the third stage of evaluation: normative judgment. When asked to evaluate the rationality of a behavior based on the character's restricted knowledge, accuracy plummets. GPT-4o's performance falls to 15.3% on these judgment tasks, representing a score far below random chance 1319. Claude 3.5 Sonnet and the heavily compute-optimized o1-preview exhibit similar degradation curves. Despite generating hundreds of hidden reasoning tokens prior to answering, o1-preview scored 84.1% on behavior prediction but fell to 59.5% on judgment 131719.
Researchers found that applying specific inference-time interventions - such as explicitly reminding the model of its own prior mental state prediction, or forcing a ToM-specific Chain-of-Thought (CoT) - can artificially boost behavior prediction scores. For example, applying these scaffolds raised GPT-4o's behavior prediction accuracy from 49.5% to 82.8%, and raised Claude 3.5 Sonnet's scores to 96.9% 131719.
However, these interventions serve as external crutches. A truly robust, generalized Theory of Mind would not require explicit algorithmic hand-holding to connect a character's beliefs to their subsequent actions. The reliance on engineered, task-specific prompts indicates that the models' capabilities are brittle, contextual, and fundamentally different from human cognitive competence, presenting a cautionary tale for the deployment of autonomous LLM agents in social environments 1519.
| Model Architecture | Explicit ToM Accuracy (Mental State) | Applied ToM Accuracy (Behavior Prediction) | Normative ToM Accuracy (Behavior Judgment) |
|---|---|---|---|
| GPT-4o | > 95.0% | 49.5% | 15.3% |
| Claude 3.5 Sonnet | > 95.0% | < 50.0% | 24.9% |
| Llama 3.1 405B | > 95.0% | < 50.0% | < 25.0% |
| OpenAI o1-preview | > 95.0% | 84.1% | 59.5% |
| Llama 3.1 8B | ~ 88.0% | < 40.0% | ~ 54.6% (Near Random Guessing) |
(Data derived from SimpleToM benchmark evaluations spanning explicit, applied, and normative social reasoning tasks 13171819.)
Adversarial Benchmarks and Interactivity
Recognizing that classic, static tests are saturated and highly susceptible to pretraining data contamination, the cognitive science and NLP communities have pivoted toward dynamic, adversarial, and embodied evaluation paradigms 2420. These next-generation benchmarks reveal steep capability drop-offs, providing further evidence that LLM ToM remains algorithmic rather than cognitive.
Conversational Information Asymmetry
Unlike static narrative stories, the FANToM (Theory of Mind in Interactions) benchmark stress-tests ToM within the context of information-asymmetric conversational environments 920. The benchmark simulates a multi-party dialogue centered on everyday topics. As the dialogue progresses, characters enter and leave the room; characters who are absent miss critical information shared among the remaining participants 921. LLMs are subsequently asked various types of questions (multiple-choice, binary, and list formats) requiring them to track who is aware of what information 9.
The results from FANToM reveal that state-of-the-art LLMs perform significantly worse than human baselines 9. While models show marginal proficiency on multiple-choice belief questions, they fail drastically on list-type questions that require identifying all participants privy to a fact 9. Furthermore, model performance drops sharply when evaluated for coherent reasoning across multiple question types based on the exact same underlying belief 9. This lack of internal consistency proves that successful instances of ToM reasoning in standard LLMs are often illusory, as true mentalizing would yield logically coherent answers regardless of the question format 9.
Algorithmic Story Generation and State Tracking
To prevent models from relying on simple linguistic templates or memorized literature, the ExploreToM framework utilizes programmatic A* search over a custom domain-specific language to adversarially generate highly complex, diverse, and unconventional story structures 1022. These scenarios are designed to stress-test the limits of basic state tracking and belief attribution.
When evaluated on these adversarial scenarios, frontier models collapse entirely. Meta's Llama 3.1 70B and OpenAI's GPT-4o exhibited accuracies as low as 0% and 9%, respectively, on certain ExploreToM-generated data splits 1022. The benchmark demonstrates that LLMs struggle with the most basic, foundational state tracking when a narrative structure deviates from familiar training distributions. If a model cannot accurately track the physical state of an object through a convoluted text, it cannot successfully track the mental state of a character regarding that object 10.
Notably, researchers found that fine-tuning models like Llama 3.1 8B Instruct directly on synthetic ExploreToM data yields a massive 27-point accuracy improvement on classic benchmarks like ToMi 1022. However, this indicates that models are learning to parse a specific type of complex syntactic puzzle rather than developing an innate, generalized social intelligence 22.
Embodied and Multi-Agent Environments
Moving beyond pure text, benchmarks such as SoMi-ToM evaluate multi-perspective ToM in embodied, multi-agent virtual interactions. In these environments, models must track visual fields, physical actions, and spatial relationships to infer what another agent desires or believes 312. In these multimodal settings, Large Vision-Language Models (LVLMs) trail human baselines by up to 40.1% in first-person evaluations, highlighting a massive gap between text-based pattern matching and grounded social perception 312.
Similarly, benchmarks based on the board game Decrypto isolate pragmatic inference and belief modeling by forcing models to communicate cooperatively with an ally while competing against an adversarial eavesdropper 23. In these zero-sum environments, LLMs consistently fail to adapt their communication strategies to the shifting mental models of other agents, proving unable to maintain coherent long-horizon strategies 23. Together, these interactive benchmarks validate the necessity of "Functional Theory of Mind." While models have mastered "Literal Theory of Mind" - the ability to statically predict a behavior based on parsed text - they consistently fail Functional ToM, which demands real-time, in-context adaptation to the dynamic beliefs of interactive partners 7.
Vulnerabilities and Systemic Failure Modes
The assertion that LLMs rely on statistical approximations rather than stable internal world models is further supported by their high susceptibility to trivial perturbations 2425. While human social reasoning is generally resilient to minor changes in syntax or narrative framing, LLM performance frequently degrades when presented with structurally altered text that preserves the underlying logical constraints.
Syntactic Brittleness and Trivial Perturbations
Recent studies from MIT and other institutions reveal that LLMs often bypass logical reasoning entirely, relying instead on grammatical patterns learned during pretraining 26. When researchers took questions that models answered correctly and replaced specific words with synonyms, antonyms, or random nouns - while keeping the underlying syntax identical - the models frequently output the original answer, even when the resulting question was complete nonsense 26. Conversely, when researchers restructured the exact same logical question using a new part-of-speech pattern, the LLMs failed to provide the correct response 26.
In the specific context of ToM tasks, researchers such as Ullman (2023) demonstrated that introducing "trivial alterations" into classic false belief narratives - such as adding irrelevant contextual details, modifying the phrasing of the prompt, or altering character names - can turn previously successful outcomes into complete failures 24252728. This vulnerability proves that models are frequently executing syntax-driven heuristics rather than maintaining a coherent, dynamic mental model of the entities within the narrative 2629.
Causal Misdirection and Parametric Conflict
LLM ToM failures are uniquely characterized by deficits in causal tracking 2930. Models exhibit a profound chronological bias, assuming that earlier events described in a narrative directly cause later events 29. When narratives are presented in a reverse causal order, or when causal links are obfuscated by dense, intervening text, LLM causal reasoning and subsequent mental state tracking plummets 29.
Furthermore, models are heavily influenced by their parametric knowledge - the static facts and associations embedded in their neural weights during pretraining 29. If a ToM narrative introduces a scenario that conflicts with standard parametric assumptions (e.g., an object behaving counter-intuitively, or a character acting against a heavy societal stereotype), the model will often hallucinate or override the provided context in favor of its pre-trained bias 2931. This results in "Harmful Factuality Hallucination," where the LLM attempts to "correct" a perceived error in the prompt's premise, thereby failing the ToM task by refusing to accept a character's false belief 31.
Multi-Hop Memory and Compositional Decay
A central architectural limitation of transformer models is their inability to consistently propagate intermediate entity states across long or complex reasoning chains 30. LLMs are proficient at shallow, one-hop tasks but degrade sharply on multi-hop compositional problems 30. Diagnoses reveal that this is driven by activation drift in the hidden states; attention heads begin to focus on high-frequency distractors rather than query-relevant concepts as the context length increases 30. Consequently, when evaluating higher-order ToM (e.g., recursive beliefs such as "Alice thinks that Bob believes that Charlie knows..."), accuracy drops precipitously, often approaching 0% at the fourth or fifth order for models that haven't been heavily optimized for long-context inference 37.
| Failure Mode Category | Description of Phenomenological Breakdown | Impact on Theory of Mind Reasoning |
|---|---|---|
| Syntactic Over-reliance | Models map specific grammatical structures to expected outcomes rather than evaluating the logical constraints of the prompt 26. | Fails to recognize identical mental states if the sentence structure deviates from standard pretraining templates 2630. |
| Parametric Conflict | Pre-trained factual knowledge overrides the specific, localized narrative context provided in the user prompt 29. | Fails to accept a character's false belief if that belief conflicts with the model's absolute factual knowledge 2931. |
| Multi-Hop Memory Decay | Inability to propagate intermediate entity states across long or complex conversational context windows 30. | Fails higher-order belief tracking due to activation drift in hidden states as story complexity scales 130. |
| Applied Application Gap | Inability to translate successfully inferred mental states into normative behavioral predictions or judgments 14. | Solves explicit awareness questions but resorts to random guessing for subsequent actions without external scaffolding 1319. |
| Reversal Curse | Failure to infer bidirectional equivalence (e.g., if A knows B, does B know A?) despite mastering unidirectional facts 25. | Causes severe inconsistencies in multi-agent belief tracking, particularly in conversational information asymmetry 25. |
The Impact of Inference-Time Compute on Mentalizing
To combat these vulnerabilities, frontier AI developers have introduced models optimized for test-time (inference-time) compute. Models such as OpenAI's o1 and o3-mini, alongside systems like DeepSeek R1, utilize large-scale reinforcement learning to generate hidden chains of thought prior to producing a final output 32394041. By spending more time "thinking," these models can theoretically backtrack, correct errors, and trace character beliefs step-by-step through a complex narrative 3940.
Initial benchmark results for reasoning models have been broadly impressive. OpenAI's o1 models frequently outperform standard dense models like GPT-4o on complex, multi-hop scientific reasoning, competitive programming, and advanced mathematics 324233. In the specific context of ToM, inference-time scaling theoretically allows models to better parse dense narratives. Using techniques related to "thought-tracing" - where models explicitly log the mental states of characters at each narrative turn - reasoning models demonstrate substantial improvements on paraphrased variants of the ToMi benchmark 3445.
The Paradox of Extended Chain of Thought
However, increased computational effort does not yield a linear or universal improvement in social cognition. The application of reasoning models to ToM tasks has uncovered highly paradoxical behaviors. In OpenAI's o1 architecture, the API allows developers to dictate the model's "reasoning effort" (setting it to low, medium, or high). While a high reasoning effort improves scores on static, highly structured false-belief tasks, it actively degrades performance on complex, interactive benchmarks 34. For example, on BigToM, FANToM, and MMToM-QA, the o1 model operating with low reasoning effort consistently achieves the highest performance 3445.
This phenomenon suggests that extended CoT reasoning can lead to over-complication, hallucination, or catastrophic compounding errors in social reasoning. DeepSeek R1, for instance, has been observed exhibiting severe uncertainty when tracking beliefs, occasionally looping in its hidden thoughts, or outputting a concession (e.g., "I give up") before providing a known incorrect answer on ToM questions 20.
Furthermore, on the ToMATO benchmark - which tests diverse mental states through LLM-to-LLM self-play and information asymmetry - reasoning models frequently performed worse than their non-reasoning counterparts. In controlled pairings, non-reasoning models like the base Qwen3-8B achieved higher scores than the compute-heavy Qwen3-8B-Reasoning variant 46. The empirical data suggests that while slow, methodical inference excels at mathematical deduction and formal logic, social reasoning often relies on rapid, intuitive pattern integration that rigid, step-by-step chain-of-thought protocols can disrupt. Consequently, while thought-tracing and inference-time scaling mitigate some multi-hop memory failures, they do not inherently instil a functional, human-equivalent Theory of Mind 344546.
The Anthropomorphic Fallacy in Human-Computer Interaction
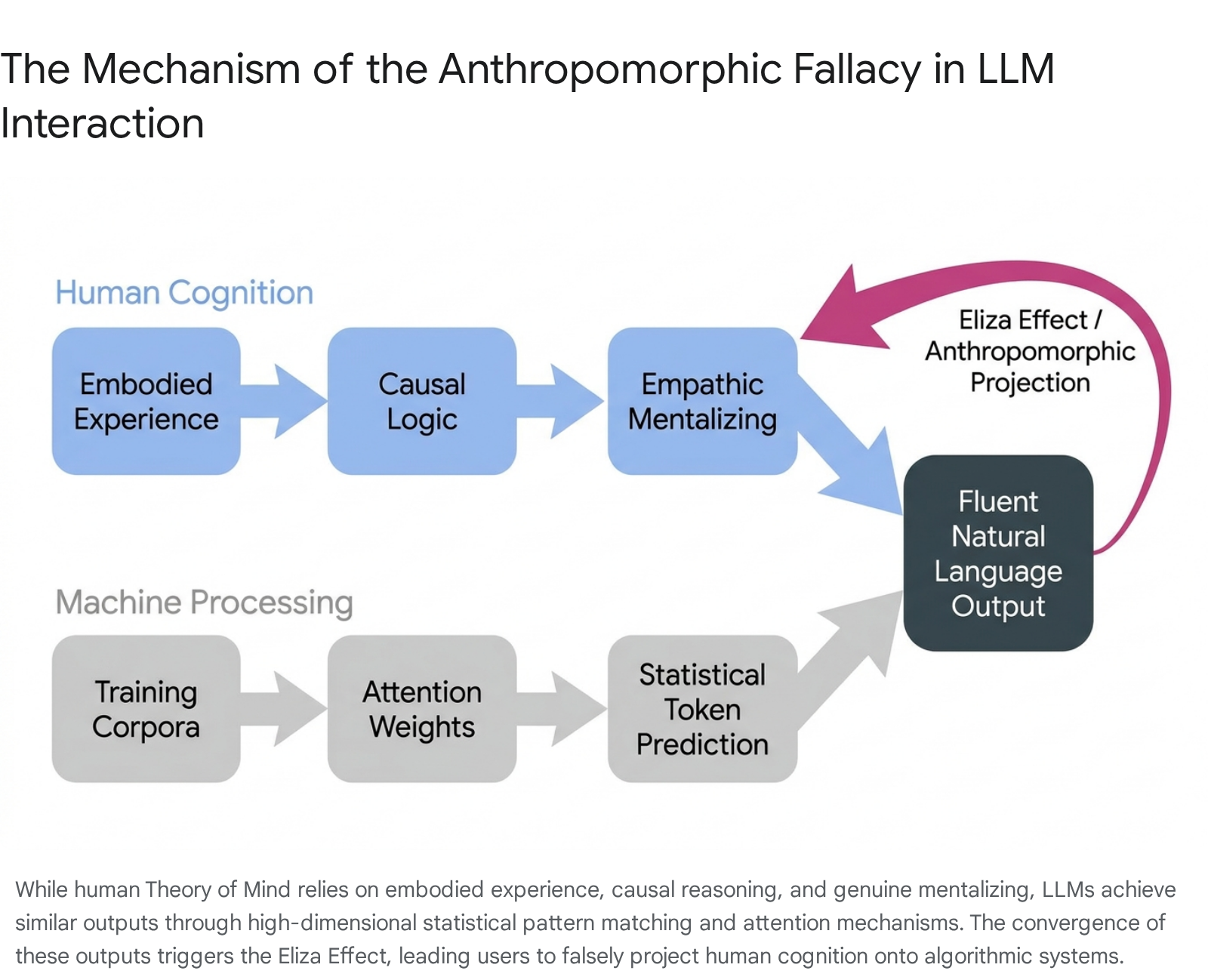
If LLM performance on rigorous, applied ToM benchmarks is fundamentally flawed, brittle, and algorithmically driven, why do human users consistently perceive these models as possessing deep empathy, self-awareness, and intent? The answer lies not in the architecture of the neural network, but in the architecture of human psychology.
The Eliza Effect and Algorithmic Mirroring
The tendency to project human-like consciousness, emotion, and sapience onto artificial systems is known as the Eliza Effect 354836. The phenomenon is named after Joseph Weizenbaum's 1966 chatbot, ELIZA, which mimicked a Rogerian psychotherapist using simple keyword matching and substitution rules 3536. Even when users were explicitly informed that ELIZA was a rudimentary script, they formed deep emotional attachments, confiding intimate secrets and demanding privacy during interactions 3650.
Evolution has wired the human brain to operate on a powerful social heuristic: if an entity utilizes fluent natural language and exhibits communicative reciprocity, it is treated as a sapient social agent 3550. Modern LLMs exploit this evolutionary instinct at an unprecedented scale. Through RLHF, instruction tuning, and massive data ingestion, models are optimized to adopt a helpful, adaptive, and highly convincing conversational persona 37. When an LLM correctly answers a complex ToM question, the human user unconsciously infers that the model utilized the same complex, empathic, and embodied cognitive processes that a human would use to arrive at the same answer 137.
This is the Anthropomorphic Fallacy (or the Pygmalion Complex in digital contexts): the assumption that successful behavioral imitation implies deep cognitive equivalence 37525338. Cognitive scientists draw a stark, ontological distinction between human mentalizing and machine statistical pattern matching. Humans rely on contextual, lived experience, physical embodiment, and causal logic to evaluate mental states. Large Language Models, lacking any perceptual connection to the physical world, generate responses based solely on multi-dimensional statistical word distributions, attention weights, and loss optimization 5812.
Epistemic Risks in Social Science and Deployment
The Anthropomorphic Fallacy carries severe epistemic risks, particularly in academic and commercial fields attempting to use LLMs as "in silico participants" to simulate human psychological or social dynamics 83940. While LLMs can efficiently reproduce population-level statistical averages on simple surveys, they fundamentally fail to capture real-world human heterogeneity and diversity 839.
Because LLMs are trained to output the most statistically probable response across their vast pretraining data - which is disproportionately biased toward Western, Educated, Industrialized, Rich, and Democratic (WEIRD) societies, predominantly in English - they compress the rich variance of global human opinion into simplified, typological structures 83940. An LLM functionally simulates a single, highly averaged "participant" rather than a diverse demographic group 40. Consequently, relying on LLMs for psychological simulation, or trusting their ToM capabilities in high-stakes human-computer interactions, risks codifying behavioral averages while entirely missing the unstated, dynamic context of true social exchange 383940.
Conclusion
The assertion that modern Large Language Models possess a human-equivalent Theory of Mind fundamentally mischaracterizes the nature of artificial intelligence. While frontier models exhibit an extraordinary, statistically derived capacity to navigate textual representations of social scenarios - often passing classic false-belief tasks at rates surpassing young children - these achievements represent a mastery of "Literal Theory of Mind." They are the byproduct of sophisticated attention mechanisms tracking linguistic correlations across massive datasets, not the result of stable, empathetic, or embodied mentalizing.
Rigorous stress-testing across next-generation benchmarks reveals profound capability gaps. When models are tasked with "Applied Theory of Mind" - translating an inferred mental state into a behavioral prediction or a normative judgment - their performance collapses to near-random chance. They remain deeply vulnerable to trivial syntactic perturbations, adversarial narrative generation, and the complexities of real-time, multi-agent dialogue. Furthermore, while the injection of massive inference-time compute allows reasoning models to brute-force certain logical pathways, it frequently results in over-complication and hallucination in fluid social contexts, proving that raw computational scale is not a substitute for cognitive embodiment.
Ultimately, the persistent belief in machine ToM is a manifestation of the Eliza Effect. As LLMs become more rhetorically fluent, they increasingly exploit human evolutionary biases, prompting users to project consciousness onto algorithmic probability distributions. Moving forward, both AI development and socio-technical deployment must prioritize functional, interactive benchmarking, ensuring that the integration of LLMs into human environments relies on objectively validated system capabilities rather than the anthropomorphic illusions they so effortlessly project.