Text-to-video artificial intelligence technology and limitations
Historical Evolution of Video Generative Architectures
The development of text-to-video artificial intelligence represents a profound convergence of natural language processing and computer vision. Over the past decade, the field has evolved from early experiments in pixel-level prediction - which struggled to maintain coherence over mere fractions of a second - to massive, physics-approximating foundation models capable of generating minutes of photorealistic footage. The mathematical and architectural foundations underlying these modern systems emerged through years of iterative breakthroughs in deep generative modeling.
Early Recurrent Networks and Generative Adversarial Networks
Between 2014 and 2017, the generative artificial intelligence landscape was primarily dominated by two foundational frameworks: Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) 122. While these architectures proved highly capable of synthesizing static images, adapting them for video generation introduced the exponentially complex requirement of temporal consistency. Early attempts at video generation treated the problem as an extension of video prediction. In this paradigm, a convolutional neural network (CNN) would encode an initial frame and pass the extracted features to a sequence-to-sequence Recurrent Neural Network (RNN) to predict the pixel arrangements of future frames 1.
In 2016 and 2017, researchers attempted to stabilize this process by merging RNNs directly into GAN pipelines. These hybrid models allowed generators to push random noise through recurrent layers to construct sequential frames, while discriminators attempted to distinguish the synthesized sequences from real video data 12. However, GANs suffered from persistent structural vulnerabilities. The most notable limitation was mode collapse, a phenomenon where the generator fails to capture the full complexity of the underlying data distribution, resulting in a severely restricted variety of outputs 2. Furthermore, maintaining spatial and temporal coherence over more than a few frames proved computationally intractable for pure RNN-GAN hybrids, as the recurrent nature of the network caused errors to compound rapidly over time.
Latent Space Compression and Early Diffusion Models
The generative paradigm shifted significantly between 2018 and 2022. The introduction of Denoising Diffusion Probabilistic Models (DDPM) in 2020 provided a viable, highly stable rival to GANs 2. Diffusion models generate data by taking pure Gaussian noise and iteratively denoising it to recover a clean signal - a process inspired by non-equilibrium thermodynamics 2234. However, performing this diffusion process in high-dimensional pixel space for every frame of a video required exorbitant computational resources.
To solve this compute bottleneck, researchers developed Latent Diffusion Models (LDMs). LDMs utilize a pre-trained encoder to compress raw images into a dense, low-dimensional latent space. The diffusion process is then executed entirely within this compressed space before a decoder reconstructs the final pixel output 5. This innovation democratized access to powerful image generation and paved the way for the first true text-to-video models.
By 2022, the industry saw the release of models like CogVideo - a 9.4 billion parameter model utilizing a Chinese-language input - alongside Meta's "Make-A-Video" and Google's "Imagen Video" 6. These early video systems utilized 3D U-Net architectures, extending standard 2D image diffusion into the temporal dimension 56. While these systems proved the viability of text-to-video generation, they remained heavily constrained. Outputs were generally limited to low resolutions, short durations of under five seconds, and suffered from severe temporal flickering due to the limitations of convolutional downsampling across the time axis.
The Transformer Revolution in Visual Data
The most critical architectural leap in the history of video generation was the displacement of the U-Net backbone in favor of the Diffusion Transformer (DiT).
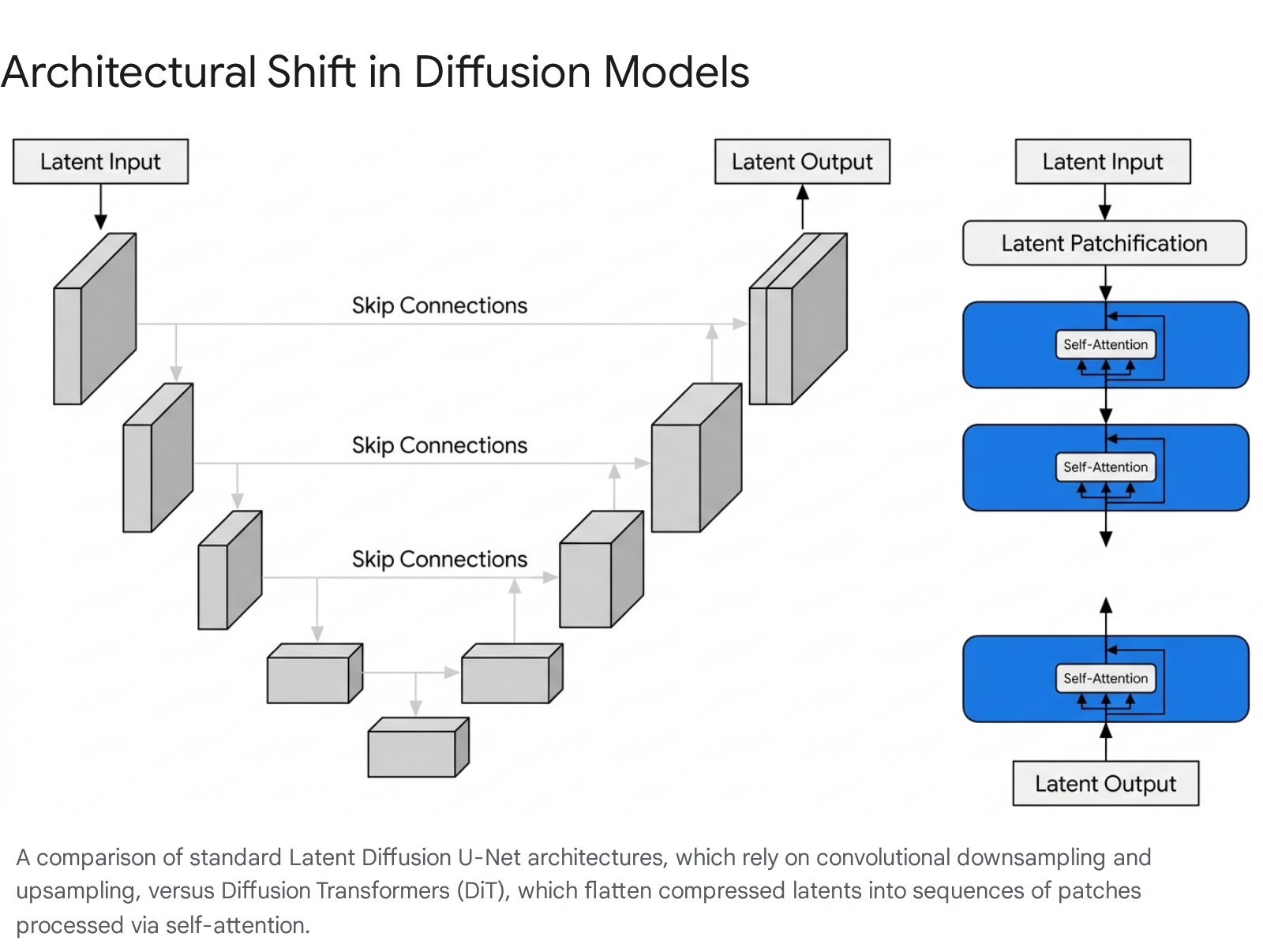
Historically, U-Nets relied on convolutional layers organized in an encoder-decoder structure with skip connections. Convolutions are naturally adept at capturing local patterns and spatial hierarchies due to their inherent locality bias and weight sharing 78. However, they struggle with long-range dependencies and lack the massive scalability required for minute-long video sequences.
In 2023, researchers demonstrated that the U-Net's convolutional inductive bias was not strictly necessary for high-quality diffusion 5109. The Transformer architecture, originally designed for natural language processing, processes sequences simultaneously via self-attention mechanisms rather than step-by-step 10. By replacing the U-Net with a transformer, developers discovered that models could evaluate complex relationships between distant parts of an image or video directly, providing a global receptive field from the very first processing layer 378.
Crucially, transformers exhibit highly predictable scaling laws. Research into forward pass complexity revealed a direct correlation between network complexity (measured in Gflops) and sample quality (measured by Fréchet Inception Distance, or FID). As transformer depth, width, or the number of input tokens increases, the generation quality reliably and consistently improves 10913. This architectural shift provided the scalability required to process millions of video frames, leading directly to the development of modern foundation models.
Architectural Framework of Sora and Modern Models
The current generation of text-to-video systems, exemplified by models like OpenAI's Sora, relies on a sophisticated orchestration of compression networks, language models, and transformer-based denoising engines. These systems treat video generation not as a sequence of discrete images, but as a continuous spatiotemporal volume.
Spatiotemporal Autoencoders and Latent Compression
Generating high-definition video in raw pixel space requires manipulating billions of variables per second. To make this computationally feasible, modern systems utilize an initial compression phase. Prior attempts to extend image autoencoders to video encoded each frame independently. This produced a sequence of compressed frames, but frequently resulted in severe temporal flickering when the frames were decoded and played back sequentially 1115.
To resolve this, modern architectures train a spatiotemporal autoencoder from scratch. This network takes raw video as input and outputs a latent representation that is compressed both spatially (reducing width and height) and temporally (reducing the sequence length) 111213. By compressing the video directly across all three dimensions, the diffusion transformer can operate on a highly dense, semantically rich representation of the video. Once the diffusion process is complete in the latent space, a corresponding decoder model maps the generated latents back into human-viewable pixel space 121314.
Spacetime Patches as Visual Tokens
In Large Language Models, text is broken down into discrete "tokens" that the transformer can process sequentially. To apply transformers to video, visual data must undergo a similar tokenization process. In DiT architectures, the compressed spatiotemporal latent representation is decomposed into "spacetime patches" 1213141516.
These patches act as the fundamental unit of visual information. By flattening the 3D latent tensor into a one-dimensional sequence of patch embeddings, the model can apply standard multi-head self-attention mechanisms 78. This allows every patch in a video to directly attend to every other patch, providing the model with a holistic understanding of the entire video sequence simultaneously.
However, this architecture introduces a phenomenon known as "objective interference." As the sequence length of a generated video increases, the sheer volume of video patches begins to mathematically overwhelm the text tokens provided by the user's prompt 21. To counteract this, advanced models utilize specialized cross-attention layers that reinforce text conditioning at deeper stages of the network, ensuring that the visual output remains tightly aligned with the textual instructions even as the video extends into minute-long sequences 2117.
Text Conditioning and Recaptioning Strategies
A persistent challenge in text-to-video generation is that internet-scraped training data often contains low-quality, sparse, or inaccurate alt-text descriptions. If a model is trained on poor descriptions, it will struggle to execute detailed user prompts during inference.
To mitigate this limitation, developers employ a sophisticated "recaptioning" technique. Leveraging powerful vision-language models, the training dataset is pre-processed to generate highly descriptive, exhaustive captions for every video and image 513. These synthetic captions detail object movements, lighting conditions, camera angles, and background elements 1318. By training the diffusion transformer on these dense captions, the mapping between specific text tokens and their corresponding spacetime patches becomes mathematically explicit. During inference, when a user provides a brief prompt, an integrated language model often expands it into a highly detailed script before passing it to the video generator, ensuring the final output faithfully aligns with complex visual intents 13.
Alternative Architectural Paradigms
While Diffusion Transformers currently represent the dominant approach for scaling, the field of generative video remains highly experimental. Several alternative architectures have yielded state-of-the-art results by addressing specific bottlenecks in the generation pipeline.
Space-Time U-Nets and Single-Pass Generation
Google's Lumiere model demonstrated that U-Net architectures could remain competitive at the frontier if drastically reimagined. Traditional U-Net video models often synthesized distant keyframes first, then employed a cascade of temporal super-resolution models to fill in the gaps between frames. This approach inherently struggled with global temporal consistency, as the interpolation models lacked full context of the entire sequence 1925.
Lumiere solved this by introducing a Space-Time U-Net (STUnet) that generates the entire temporal duration of the video at once, in a single pass. By deploying both spatial and temporal downsampling and upsampling modules, the network focuses its computation on a compact space-time representation. This interleaving of temporal blocks with spatial resizing allows the model to process full-frame-rate videos across multiple scales simultaneously, eliminating the need for cascading super-resolution and significantly reducing the "jumping" effects common in earlier interpolation models 192620.
Flow Matching and Multi-Stage Pre-training
Meta's Movie Gen suite - comprising a 30-billion parameter video model and a 13-billion parameter audio model - eschews standard denoising diffusion in favor of Flow Matching 182829. Standard diffusion models predict the noise that must be subtracted from a sample. Flow Matching, conversely, trains the model to predict the velocity of samples as they move through the latent space. This approach guides random noise toward the target data distribution along a smooth vector field, which is often more computationally efficient and performant than traditional diffusion 18.
Movie Gen utilizes a rigorous multi-stage training recipe to manage objective interference and scaling costs. The model begins with text-to-image pre-training at a low resolution of 256 pixels. It then progresses to joint image and video training at 768 pixels, developing its spatial positional encodings. Finally, it undergoes high-resolution, long-context video fine-tuning 183021. This progressive scaling ensures that the model learns fundamental visual concepts before attempting to master complex temporal dynamics.
Capabilities and Limitations in Physics Simulation
As text-to-video models achieve unprecedented levels of photorealism, an intense debate has emerged within the artificial intelligence research community. Observers are sharply divided on whether these models are merely sophisticated pattern matchers interpolating between training examples, or if they have begun to internalize the fundamental physical laws governing the real world.
Probabilistic Modeling Versus Explicit Physics Engines
Following the initial release of Sora, some researchers described the model as a "data-driven physics engine." Proponents of this view suggest that through pure architectural scale and gradient descent, the simulator had learned intuitive physics, long-horizon reasoning, and semantic grounding 3222. Observations of the model maintaining precise 3D spatial consistency across dramatic camera pans, tracking object permanence when items are temporarily occluded, and simulating complex fluid dynamics lent significant credence to this simulation hypothesis 142335.
However, strict analytical scrutiny reveals fundamental mechanical differences between generative video models and actual physics engines. Traditional physics simulators - such as Unreal Engine or MuJoCo - utilize explicit mathematical formulas, such as Navier-Stokes equations for fluid dynamics, to calculate deterministic outcomes based on fixed inputs, masses, and velocities 232425. Generative models, conversely, operate via probabilistic distributions. They do not calculate thermodynamics, gravity, or friction; they merely predict the most statistically probable arrangement of pixels based on the visual patterns present in their training data 222326.
This probabilistic nature leads to critical failures in out-of-distribution scenarios or complex physical interactions. Current video generation models frequently struggle with cause-and-effect state changes, such as the exact mechanics of glass shattering or a bite being taken out of an object. Furthermore, they fail to maintain the strict physical law of inertia when object velocities fall outside the specific ranges seen in their training datasets, often resulting in unnatural deceleration or morphing 1527.
Mechanistic Interpretability and the Meltdown Phenomenon
Recent research into the mechanistic interpretability of 3D diffusion transformers has uncovered specific, catastrophic failure modes that highlight the fragility of these probabilistic physics approximations. One heavily documented phenomenon, termed "Meltdown," occurs when arbitrarily small, imperceptible perturbations to the input data - such as a sparse point cloud or subtle noise pattern - cause the generated 3D output to violently fracture into disconnected pieces 272841.
By applying activation-patching techniques, researchers successfully localized this catastrophic failure to a single, early denoising cross-attention activation within the transformer network. Spectral analysis of this specific activation revealed that its singular-value spectrum provides a scalar proxy for the failure; specifically, its spectral entropy spikes massively when fragmentation occurs 2729. Interpreted through the lens of diffusion dynamics, this entropy spike tracks a symmetry-breaking bifurcation in the reverse diffusion process. This proves that the model's "understanding" of 3D structure is highly brittle and susceptible to chaotic trajectory shifts 274130. To counteract this, researchers have developed test-time interventions, such as "PowerRemap," which act as drop-in controls to stabilize sparse point-cloud conditioning and prevent the meltdown cascade 2728.
Temporal Consistency and Aliasing Artifacts
Long-context video generation is also plagued by persistent aliasing artifacts. In chaotic systems that are highly sensitive to initial conditions, minor mathematical errors compound over time. In transformer architectures processing video, these compounding errors often manifest as localized temporal "pixellation" or flickering, particularly in scenes requiring complex fluid or gas simulations where motion vectors are highly dynamic 24.
While techniques such as input data jittering - randomly time-shifting data at each step to distribute errors rather than allowing them to pile up at particular temporal locations - have been proposed to mitigate this, achieving absolute temporal consistency remains elusive 24. The quadratic computational cost of performing self-attention across tens of thousands of spacetime patches limits the ability of current models to perfectly resolve fine details over extended durations.
The Competitive Landscape of Video Generation Models
By early 2026, the text-to-video generation market evolved from a theoretical research discipline into a highly competitive, multi-billion dollar commercial ecosystem. The landscape is defined by divergent architectural philosophies, varying product strategies, and significant shifts in corporate resource allocation.
The Commercial Discontinuation of OpenAI Sora
Despite launching the industry into the generative video era with its spectacular technical demonstrations in early 2024, OpenAI executed a highly publicized and controversial phased shutdown of the Sora platform throughout 2026. On March 24, 2026, the company officially announced the discontinuation of the model. The consumer-facing web platform and mobile applications were permanently taken offline on April 26, 2026 313233.
The complete deprecation of the Sora API followed on September 24, 2026. After this date, all developer requests utilizing the standard video API endpoints returned permanent deprecation errors, marking a total business-line-level exit from commercial video API hosting 3132. This abrupt shutdown severely impacted enterprise adopters, marketing agencies, and software platforms who had built core dependencies on the Sora 2 and Sora 2 Pro APIs, forcing rapid, costly migrations to competing providers 3134.
The discontinuation was driven by a broader strategic pivot within OpenAI. The computational demands required to run high-fidelity physics simulation and video diffusion at scale were deemed too intensive relative to their commercial yield. Consequently, OpenAI opted to funnel its GPU clusters toward highly profitable enterprise coding assistants, natural language processing tools, and the development of unified "super apps" 33. Furthermore, the sudden shutdown triggered the collapse of high-profile entertainment contracts. A reported $1 billion integration partnership with Disney, which would have allowed Sora to natively render classic characters, was abruptly abandoned, highlighting the extreme volatility and massive compute overhead associated with commercializing foundation video models 3235.
Architectural Divergence in Rival Platforms
With Sora's exit from the commercial market, the remaining landscape in 2026 is distinctly multi-polar. No single model dominates all benchmarks; instead, architectural trade-offs dictate highly specific performance advantages tailored to different production workflows 36. Data indicates a clear segmentation between tools focused on cinematic realism, tools optimized for granular editing control, and tools prioritizing rapid social media deployment.
Google Veo 3.1 has emerged as a premier choice for holistic cinematic quality. Operating on an audio-native pipeline, Veo 3.1 excels at generating highly photorealistic outputs with tightly integrated, synchronized audio. It is particularly noted for maintaining exceptional scene consistency and object permanence across sequential generations, making it a favorite for establishing shots and narrative visualization 365037.
Kling 3.0, developed by Kuaishou, represents a breakthrough in output fidelity and scale. Transitioning away from the artifact-prone upscaling methods of previous generations, Kling 3.0 is the first major model to provide true native 4K (3840*2160) generation at 60 frames per second. Utilizing a multi-modal visual language architecture with full-attention spatiotemporal modeling, it supports multi-shot narrative sequencing up to 15 seconds per clip. Furthermore, its "Omni" variant features native dialogue lip-syncing across multiple languages, positioning it as a highly cost-effective solution for scaling production 3650383940.
Runway Gen-4 and Gen-4.5 have taken a decidedly different approach, pivoting from a pure generation tool to a "General World Model" integrated directly into professional editing suites. While Gen-4.5 prioritizes 4K consistency over extreme clip lengths (typically maxing at 10-second continuous generations), it is unmatched in granular control. Features such as "Director Mode" for node-based camera steering (pan, tilt, truck) and "Motion Brush 3.0" for vector-based movement control make it the preferred tool for marketing and advertising workflows where strict creative adherence is mandatory 504142574359.
Vidu Q1 and Q2, developed by China's Shengshu Technology, utilize a proprietary Universal Vision Transformer (U-ViT) architecture. Capable of generating 1080p, 16-second clips, Vidu focuses heavily on strict prompt adherence, deep Chinese-language semantic understanding, and maintaining robust character identity across sequential generations utilizing reference images 44456246.
Meta Movie Gen operates as an integrated suite of models utilizing Flow Matching. While public availability remains tightly controlled for safety and ethical alignment testing, the 30-billion parameter video model excels at generating 16-second 1080p clips, complemented by a 13-billion parameter audio model. Movie Gen is particularly notable for its highly steerable personalization capabilities, allowing users to upload a single reference image and generate highly accurate video outputs maintaining the subject's exact identity 18282921.
| Model | Native Resolution | Max Base Clip Length | Native Audio Generation | Primary Architectural / Workflow Advantage |
|---|---|---|---|---|
| Google Veo 3.1 | 1080p (4K upscale) | ~8 seconds | Yes | Unified audio-native pipeline; high scene consistency |
| Kling 3.0 | 4K (3840*2160) | 15 seconds | Yes (5 languages) | Native 4K 60fps; multi-shot storyboard capabilities |
| Runway Gen-4.5 | 4K | 10 seconds | No (Post-sync) | Granular vector motion control; node-based camera steering |
| Vidu Q2 | 1080p | 8 to 16 seconds | No | High-fidelity reference-based character consistency |
| Meta Movie Gen | 1080p | 16 seconds | Yes (via separate 13B model) | Flow Matching architecture; highly steerable personalization |
Copyright Litigation and Training Data Provenance
As text-to-video models became fully integrated into commercial ecosystems, the massive datasets required to train Diffusion Transformers triggered unprecedented legal and regulatory scrutiny. By 2026, the infrastructure surrounding copyright litigation and metadata provenance evolved from theoretical debate into strict operational mandates.
Legal Precedents in Fair Use and Output Infringement
The core mechanism of training generative artificial intelligence requires parsing millions of hours of copyrighted video and image data. Historically, AI developers defended this practice under the United States "Fair Use" doctrine, arguing that training a model constitutes a highly transformative act. They posited that models extract statistical patterns and weights rather than storing direct copies of the protected media 476566.
By 2025 and 2026, federal courts began establishing critical boundary lines regarding this defense amidst a wave of over 40 major copyright infringement lawsuits. In landmark summary judgments such as Bartz v. Anthropic and Kadrey v. Meta, judges largely affirmed the foundational premise that training LLMs and foundation models on lawfully acquired data is highly transformative and generally protected as fair use. The courts recognized that these models create entirely new content from learned statistical relationships 6548.
However, the courts drew a strict, punitive line against unlawfully acquired training sets. In a related class-action settlement in June 2025, Anthropic was severely penalized for utilizing databases of pirated books 49. This ruling signaled definitively that the fair use doctrine does not immunize the ingestion of explicitly stolen, pirated, or illegally scraped databases, exposing AI developers to massive compliance risks if their data provenance is flawed 4749.
Simultaneously, the legal battlefield shifted from analyzing the "input" (the training data) to scrutinizing the "output" (the generated video). Federal judges established a significantly higher burden of proof for creators claiming copyright infringement. Plaintiffs can no longer successfully sue merely by proving their artwork or video was included in a training dataset. Instead, they must provide concrete evidence that the AI generated an expressive output that is "substantially similar" to their specific copyrighted material, and they must demonstrate measurable, non-speculative economic market replacement 476648.
Cryptographic Provenance and C2PA Implementation
To address the proliferation of indistinguishable synthetic media, weaponized deepfakes, and stringent new regulatory compliance laws (such as the EU AI Act and California's SB 942), the technology industry coalesced around the Coalition for Content Provenance and Authenticity (C2PA) standard 505152.
C2PA operates as a cryptographically secure "nutrition label" for digital assets. When a video is generated by a compliant AI model, a "manifest" is created containing verifiable metadata about the specific tool used, the timestamp, and the origin. Crucially, this manifest is sealed using advanced cryptographic hashing (e.g., SHA2-256) and digital certificates (X.509) 515354. C2PA utilizes "hard binding," where a cryptographic hash of the actual video pixels is stored in the manifest, rendering the asset tamper-evident; any unauthorized pixel alteration or manual editing breaks the cryptographic seal, alerting the viewer that the content has been modified 5055.
Despite broad adoption pledges from major platforms like YouTube, Meta, and TikTok, implementation remains technically inconsistent. A major media audit in late 2025 revealed that social media platforms frequently stripped or failed to read C2PA metadata, successfully labeling AI content only roughly 30% of the time 56. The vulnerability stems from aggressive video transcoding operations native to streaming platforms (e.g., compressing a file to H.264 or HEVC for mobile delivery), which can inadvertently strip external metadata manifolds 57. To combat this fragility, newer models are combining C2PA external manifests with embedded, pixel-level invisible watermarking (such as Google's SynthID) to create a multi-layered, compression-resistant provenance architecture that survives standard OTT delivery pipelines 535758.
Future Trajectories in Video Generation
The rapid trajectory of text-to-video artificial intelligence underscores a broader paradigm shift from simple pixel-generation to complex environment simulation. The displacement of U-Nets by Diffusion Transformers proved that treating visual data as sequences of spacetime patches allows models to leverage the exact same scaling laws that propelled Large Language Models into ubiquity 571012.
However, the current generation of models has exposed the ceiling of purely probabilistic modeling. While they generate breathtakingly realistic frames and mimic fluid motion with high fidelity, their failure to reliably synthesize complex state changes, adhere to strict thermodynamic rules, or maintain structural coherence under sparse perturbation demonstrates that mapping pixel distributions is fundamentally distinct from modeling true physical reality 152327. The "Meltdown" phenomenon and persistent temporal aliasing artifacts serve as stark reminders that diffusion dynamics remain inherently chaotic and susceptible to trajectory bifurcations 242741.
Moving forward, the industry faces a structural bifurcation. Commercial platforms like Runway and Kling are optimizing for granular creative control, rendering speed, and cinematic utility, working to deeply integrate AI generation into traditional post-production workflows to serve immediate market demands 395743. Conversely, fundamental research into true "world models" must resolve the inherent tension between long-context temporal coherence and the quadratic compute costs of massive self-attention arrays. The next evolution of video generation will likely require hybrid architectures that fuse the stochastic, imaginative creativity of diffusion models with the deterministic, rule-based constraints of traditional physics engines, bridging the critical gap between hallucinated reality and structural truth.