Test-time compute scaling in large language models
The Evolution of Scaling Laws and the Data Wall
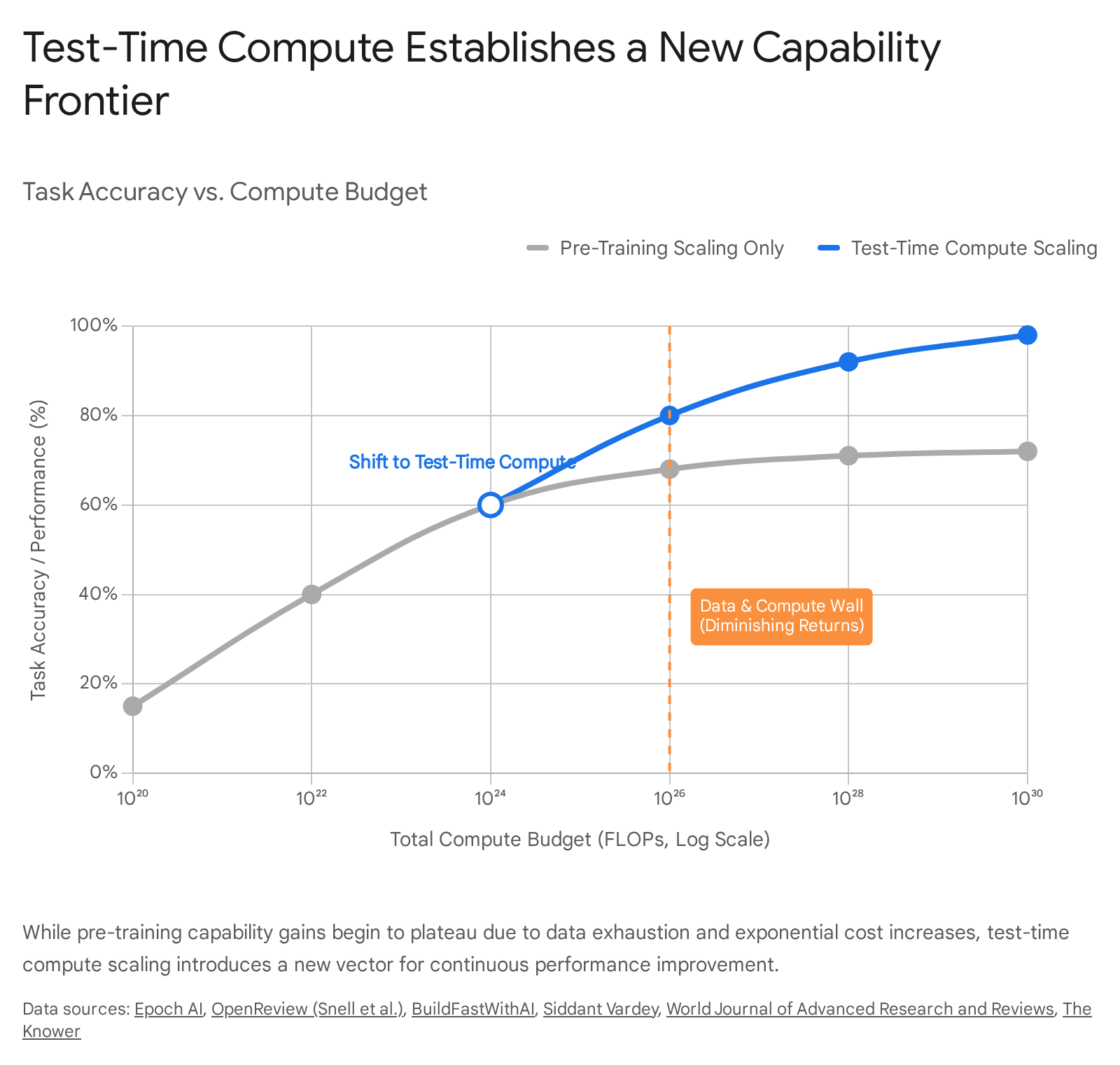
For the past half-decade, the trajectory of artificial intelligence was governed by a predictable set of scaling laws, establishing that model capabilities improve smoothly as a power-law function of parameter count, dataset size, and training compute 123. The Chinchilla formulations dictated an optimal allocation of resources - approximately 20 training tokens per parameter - driving the development of increasingly massive dense architectures 123. However, by late 2024 and extending into early 2026, the marginal utility of massive pre-training runs began to exhibit severe diminishing returns. The empirical reality of the "data wall" emerged as a critical bottleneck, with projections indicating the exhaustion of publicly available, high-quality human text by 2026 to 2032 223.
Simultaneously, the sheer capital required to train a frontier model skyrocketed. With costs for models like GPT-4 estimated at roughly $100 million in compute alone, direct extrapolations suggested that maintaining historical scaling trajectories would soon require infrastructure clusters costing hundreds of billions of dollars 2348. These mega-clusters push against the absolute limits of national power grids, semiconductor supply chains, and economic feasibility. Epoch AI analyses from late 2025 highlight a compounding friction: every additional tenfold increase in training compute scale extends project lead times by approximately one year 48. Consequently, a hypothetical trillion-dollar training cluster, initially projected for 2030, faces inevitable delays to 2035 or beyond 4.
In response to these compounding physical and economic frictions, the artificial intelligence industry pivoted toward a new dimension of capability enhancement: test-time compute scaling. Rather than front-loading all computational effort into the pre-training phase - attempting to compress the statistical structure of the internet into static model weights - test-time scaling defers a significant portion of computation to the inference stage 5. This approach allows models to allocate extensive computational resources during generation, engaging in prolonged, step-by-step logical deduction before committing to a final output 25. The transition from naive parameter scaling to test-time scaling marks a fundamental architectural and economic realignment, shifting the core bottleneck from data acquisition and training hardware to inference efficiency and algorithmic search 256.
Mechanisms of True Test-Time Scaling vs. Basic Chain-of-Thought
The contemporary paradigm of test-time scaling extends far beyond the basic sequential Chain-of-Thought prompting popularized in 2022. Early iterations of intermediate logic generation relied on static, autoregressive decoding where the model was simply instructed to output its internal steps before providing an answer. While this improved performance on complex tasks, it suffered from a critical vulnerability: premature commitment 7. If the model made an error in an early step, the autoregressive nature of the transformer forced it to build upon that error, often leading to hallucinations, limited self-correction, and compounding logical failures 7.
True test-time scaling addresses this through systemic verification, search algorithms, and reinforcement learning frameworks designed specifically to manage and navigate vast decision trees during inference. The shift is from a monotonic stream of text generation to an iterative process of algorithmic simulation 7.
Dynamic Backtracking and Self-Rectification
Advanced test-time compute mechanisms fundamentally alter the decoding process by allowing models to act as combinatorial optimizers 7. One of the most significant architectural advancements in 2025 is dynamic backtracking. Unlike standard autoregressive generation, dynamic backtracking allows a model to seamlessly undo and revise its own history within a single forward pass or through coordinated multi-agent orchestration 12.
In models specifically trained for extensive test-time compute, backtracking emerges mechanistically. Systems trained with explicit backtrack tokens (such as <backtrack>) can autonomously recognize dead-ends and revert to a previous, higher-confidence state, thereby internalizing both solution search and validation without strict reliance on auxiliary reward models 13. This is practically implemented in frameworks like the Self-Rectified Large-Scale Code Generator (SRLCG), which utilizes a multidimensional pathway. In SRLCG, strategic, tactical, and operational generation steps are iteratively verified. If a generated sub-function fails a local test, the dynamic backtracking algorithm isolates the failure, prunes the branch, and regenerates the specific component without discarding the entire generated sequence 141516.
The transition from monotonic token generation to dynamic, self-correcting trajectories requires models to process and monitor conditional entropy effectively. Studies measuring the utility of generation steps via conditional entropy reduction demonstrate that correct logic paths consistently decrease in entropy as the context expands. Conversely, flat or increasing entropy correlates heavily with flawed logic or unproductive tangents 14. By monitoring these internal confidence states, inference engines can preemptively halt unproductive paths, optimizing the allocation of test-time computational budgets rather than merely generating long, flawed sequences.
Outcome vs. Process Verification Models
A critical component of scaling inference compute is the deployment of external verifiers to score and guide the model's intermediate outputs. Historically, Outcome Reward Models (ORMs) were utilized to evaluate only the final state of a generated response. ORMs assign a scalar value to the completed sequence, which is highly efficient for high-throughput environments such as database query generation or code validation where a compiler or execution environment provides definitive binary feedback 818.
However, for nuanced logical deduction, Process Reward Models (PRMs) emerged as the dominant verification mechanism. PRMs provide dense, granular supervision by scoring every intermediate step of a generated solution 818910. This step-wise evaluation allows search algorithms to prune incorrect branches early, preventing the model from wasting computational resources. Despite their theoretical advantages, PRMs face significant operational challenges. The creation of PRM training datasets requires immense human annotation effort. Furthermore, naive step-wise aggregation in discriminative PRMs can compound labeling errors as the length of the generated response grows, leading to a phenomenon known as "reward hacking," where the model learns to exploit the verifier's biases rather than producing genuinely correct solutions 8101112.
Late 2025 literature highlights a pronounced shift toward Generative Outcome Reward Models (GenORM), which challenge the prevailing assumption that fine-grained process supervision is universally superior. Extensive unified evaluations across diverse multi-domain settings indicate that GenORMs frequently outperform traditional PRMs because they avoid the accumulated label noise inherent in step-wise scoring, proving more robust for exceptionally long self-correcting generation paths 81012. Alternatively, frameworks like GenPRM attempt to bridge this gap by integrating generative processing directly into the verifier, utilizing relative progress estimation and code execution to produce more accurate, dynamic evaluations without the severe compounding error penalty seen in purely discriminative classifiers 9.
Algorithmic Search Strategies in Inference
To fully leverage the available computational budget at inference time, raw token generation must be paired with structured search strategies. The choice of search algorithm dictates the computational overhead, memory requirements, and the fundamental balance between exploration (finding new solutions) and exploitation (refining known solutions). The efficiency of these algorithms is paramount, as inference costs scale linearly - and sometimes exponentially - with the breadth of the search.
Search Strategy Characteristics
- Best-of-N Sampling (BoN): This is the foundational parallel sampling technique. The model generates $N$ distinct candidate solutions independently, and a verifier selects the highest-scoring candidate 1314. While simple, Best-of-N scales poorly in complex domains. As $N$ becomes exceedingly large, the probability of the verifier selecting a flawed but highly-scored output increases substantially 11. The time complexity is linear, $O(N)$, but memory usage can be problematic if all candidates are maintained in parallel context 1415. To address these inefficiencies, researchers developed Self-Truncating BoN (ST-BoN), which utilizes internal consistency signals to truncate bad paths early, achieving BoN performance at significantly lower latency 15.
- Beam Search: Instead of generating full sequences independently, Beam Search evaluates candidates level-by-level. At each depth $d$, the algorithm retains a fixed number of the most promising paths (the beam width, $b$), expanding each by a branching factor $w$. The computational complexity is defined as $O(d \times b \times (w + 1))$ 142616. Beam Search is particularly effective for highly deterministic, difficult algorithmic problems under constrained compute budgets, as it aggressively prunes suboptimal paths early 1317. However, it traditionally suffers from a lack of semantic diversity, often producing highly homogenous candidates.
- Monte Carlo Tree Search (MCTS): Adapted from reinforcement learning and game-playing algorithms, MCTS builds a decision tree through randomized sampling and value backpropagation. It iterates through selection, expansion, simulation, and backpropagation phases 1526. MCTS dynamically balances exploring new logic branches against exploiting known high-value branches. The time complexity is bounded by $O(n \times d)$, where $n$ is the number of total simulations. While highly effective for complex, open-ended problem-solving spaces, MCTS incurs significant computational and memory overhead - approaching $O(w^d)$ in the worst case - due to the necessity of maintaining the complete tree state and repeatedly querying process verifiers 2616.
- Lookahead Search: An adaptation of sequential revision, lookahead search simulates $k$ steps ahead before committing to a current node. This approach utilizes additional compute, scaling as $N \times (k+1)$ samples, and inherently carries a verification overhead 17.
Comparative Analysis of Search Strategies
| Strategy | Time Complexity | Memory Usage | Exploration vs. Exploitation | Primary Use Case & Characteristics |
|---|---|---|---|---|
| Best-of-N (BoN) | $O(N)$ | $O(N \times d)$ | High Exploration (Independent) | General knowledge and easily verifiable tasks. Prone to reward hacking at high $N$. Highly parallelizable but token-inefficient. 11131415 |
| Beam Search | $O(d \times b \times (w + 1))$ | $O(b \times d)$ | High Exploitation | Harder algorithmic and mathematical problems under lower compute budgets. Maintains fixed beams, sacrificing diversity for local optimization. 13261617 |
| Monte Carlo Tree Search (MCTS) | $O(n \times d)$ | $O(w^d)$ (Worst Case) | Balanced (Stochastic) | Complex, multi-step spaces requiring verifiable intermediate steps. High computational cost; requires dense PRM integration. 14152616 |
| Self-Truncating BoN (ST-BoN) | $< O(N)$ | $< O(N \times d)$ | High Exploration | Cost-optimized BoN. Uses internal consistency signals to truncate bad paths early, achieving BoN performance at lower latency. 15 |
| Lookahead Search | $O(N \times (k+1))$ | Moderate | High Exploitation | Simulates $k$ steps ahead before committing to a current node. Expensive due to constant verifier querying overhead. 17 |
Geopolitics and Architectures: US Proprietary vs. Chinese Open Ecosystems
The divergence in test-time scaling philosophies is vividly illustrated by the contrasting approaches of leading United States proprietary models (such as OpenAI's o-series) and Chinese open-weight architectures (such as DeepSeek-R1 and Qwen). This bifurcation represents not only a difference in technical methodology but also a fundamental divide in deployment economics, infrastructure utilization, and market accessibility.
The Proprietary Frontier: Simulated Processing and Enormous Capital
OpenAI's o1 and subsequent o3 models represent the apex of proprietary test-time scaling. These models are heavily augmented with large-scale reinforcement learning algorithms that train the system to utilize extensive internal deliberation before responding 229. The o3 model, released in early 2025, integrates advanced "simulated reasoning," allowing the model to project multiple steps ahead and adaptively allocate compute based on user-defined effort levels (low, medium, high) directly within the API 1819.
The benchmark performance of the o3 architecture is formidable. On the ARC-AGI benchmark - a notoriously difficult dataset designed to resist memorization and test pure spatial and logical adaptation - o3 achieved an unprecedented 87.5% accuracy under maximum test-time compute allocations, essentially matching the human baseline of 85% 18192033. Similarly, on the AIME 2024 mathematical assessment, o3 achieved 96.7% accuracy, and hit 71.7% on the SWE-bench Verified coding assessment, demonstrating exceptional capabilities in domains with verifiable outcomes 1819.
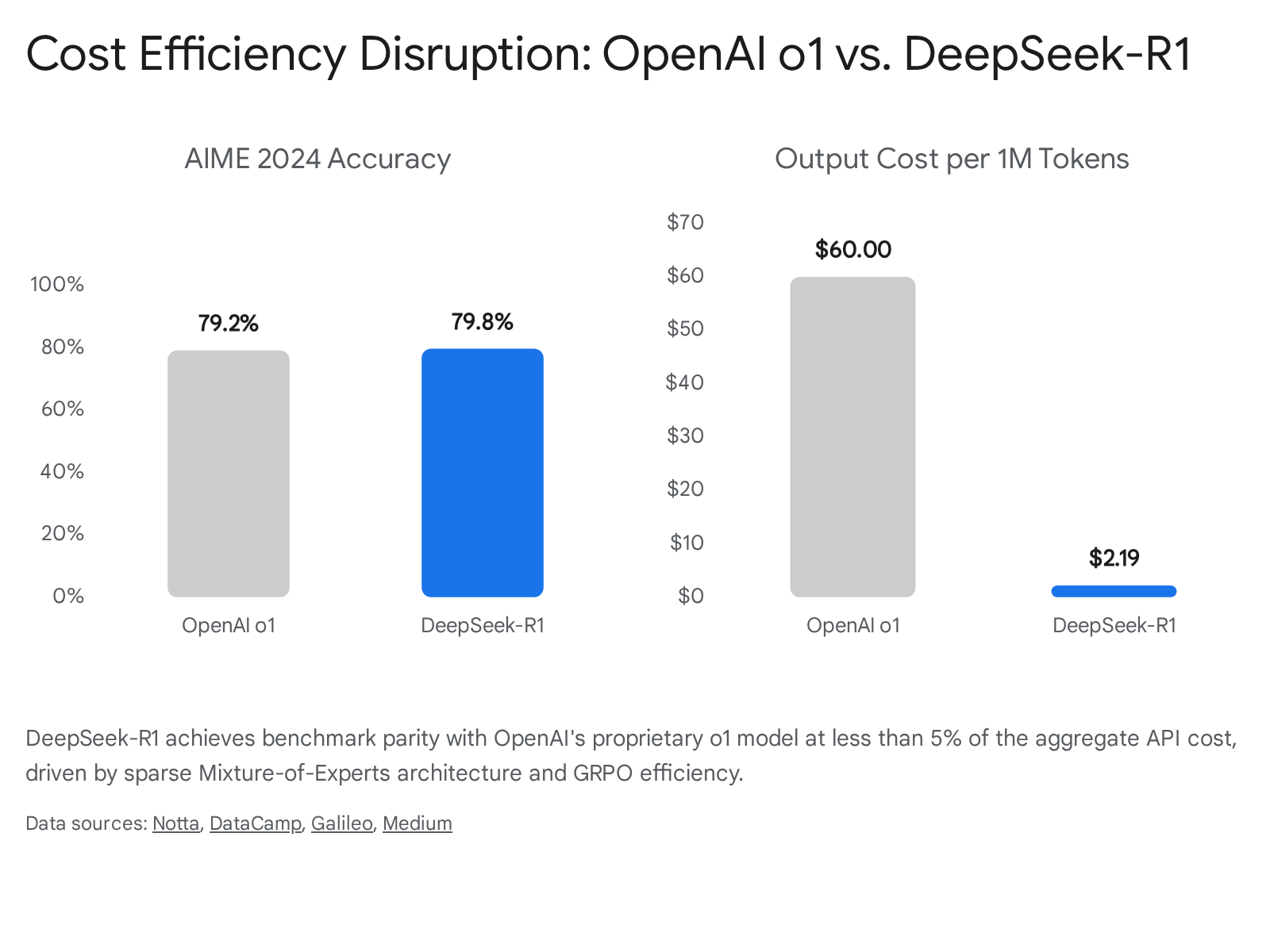
However, this capability comes at an extreme economic premium. The inference cost for the o1/o3 class models is staggering compared to traditional architectures. With API pricing set at $15.00 per million input tokens and $60.00 per million output tokens, and with some maximum-compute queries costing upwards of $3,460 per transaction, the proprietary US approach relies on massive, centralized hyperscale infrastructure 3334352137. The architecture acts as a black box, outputting synthesized summaries of its internal processes rather than raw trace logs, prioritizing safety alignment, commercial monetization, and intellectual property protection over operational transparency 22.
The Open Disruption: Algorithmic Efficiency and Extreme Cost Reduction
In stark contrast, the Chinese artificial intelligence ecosystem, led primarily by DeepSeek and Alibaba's Qwen, demonstrated that state-of-the-art test-time scaling could be achieved without the multi-billion-dollar infrastructure previously thought mandatory. DeepSeek-R1, for example, was trained on a cluster of merely 2,000 GPUs with an estimated total budget of $5.58 million - a fraction of the estimated $6 billion+ investment poured into US counterparts 22139.
DeepSeek achieved this via a highly optimized, four-stage training pipeline and a novel RL framework known as Group Relative Policy Optimization (GRPO). Traditional reinforcement learning (such as PPO) requires a separate "critic" model - often equal in size to the primary model - to evaluate actions, effectively doubling the memory footprint and compute requirement. GRPO eliminates the critic model entirely. Instead, it samples a group of outputs from the policy, calculates a reward for each using a rule-based system (e.g., verifying mathematical correctness or compiler success), and derives the advantage baseline directly from the group's mean score and standard deviation 23.
The DeepSeek-R1 pipeline began with a "Cold Start" utilizing thousands of highly curated, long-form demonstration examples to teach a base model to output readable step-by-step logic. This was followed by intensive reasoning-oriented RL, rejection sampling to generate 600,000 high-quality synthetic traces, and a final RL alignment phase to ensure human preference alignment 23. During the RL phases, developers observed an autonomous "Aha moment," where the model spontaneously learned to allocate more thinking time by reevaluating its initial approach, actively outputting phrases like "Wait, let's reevaluate," autonomously increasing its test-time compute allocation to self-correct 23.
Structurally, DeepSeek-R1 utilizes 671 billion total parameters but activates only 37 billion parameters per token generation via extreme Mixture-of-Experts (MoE) sparsity 224142. This results in API economics that completely disrupt the proprietary market: $0.55 per million input tokens and $2.19 per million output tokens, rendering R1 approximately 96% cheaper than o1 on equivalent workloads 34352143.
Similarly, the Qwen ecosystem has rapidly advanced test-time capabilities in open models. Qwen2.5-Math integrates reward models directly into the inference stage to guide sampling, optimizing the performance of the model on highly complex mathematical datasets ranging from grade school to AIME24 44. Open-weights models like QwQ-32B and Qwen2.5-32B have proven that smaller, highly distilled dense models can execute extensive test-time processing, competing fiercely with models multiple times their size 4524.
Despite the vast disparity in infrastructure cost, benchmark performance remains intensely competitive. DeepSeek-R1 slightly outperformed OpenAI o1 on AIME 2024 (79.8% vs. 79.2%) and MATH-500 (97.3% vs. 96.4%) 214347.
However, the proprietary US models maintain a distinct edge in broad, general-knowledge scenarios, creative flexibility, and handling ambiguous, unstructured data (e.g., GPQA Diamond and MMLU), indicating that extreme optimization for logic-based test-time scaling may require trade-offs in general linguistic fluidity 22434725. Furthermore, unlike the summarized outputs of o1, R1 provides complete, unredacted raw logic traces, a feature highly valued by developers building downstream software agents 2122.
Training-Time versus Test-Time Scaling Trade-offs
The core premise of the current technological shift relies on a predictable substitution ratio between the compute utilized during a model's pre-training phase and the compute deployed during inference. As pre-training scaling encounters severe economic and physical limits, developers must navigate a complex optimization surface to achieve desired capabilities.
Empirical analyses, heavily led by groups like Epoch AI, have established quantitative trade-offs. The fundamental relationship dictates that increasing the amount of compute per inference query by 1 to 2 orders of magnitude (OOM) allows developers to maintain identical performance while reducing the required training compute by approximately 1 OOM 26. Scaling test-time compute even further - by 5 to 6 OOM - can yield savings of 3 to 4 OOM in the pre-training phase 26.
This trade-off is particularly robust in domains where correctness can be cheaply verified 26. In a FLOPs-matched comparison, optimally scaling test-time compute allows a remarkably small language model to outperform a static base model that is 14 times larger 13. By dynamically adjusting the amount of generation allowed based on prompt difficulty - a compute-optimal strategy - systems achieve massive throughput efficiency gains over static generation paradigms 13.
Comparative Table: Compute Substitution and Trade-offs
| Factor | Training-Time Scaling (Pre-2024 Paradigm) | Test-Time Scaling (2025 Paradigm) |
|---|---|---|
| Compute Investment | Heavy upfront capital expenditure (CapEx). Millions of GPU hours spent before deployment. 565051 | Distributed operational expenditure (OpEx). Compute is burned per-query during active user sessions. 5651 |
| Substitution Ratio | 10x (1 OOM) increase in training data/parameters yields predictable performance gains. 226 | 100x (2 OOM) increase in inference compute can substitute for ~1 OOM of missing training compute. 262753 |
| Primary Bottleneck | Exhaustion of high-quality human data; power grid capacity for 1+ GW mega-clusters. 22354 | Extreme inference latency; compounding logic errors in ultra-long generation sequences; KV Cache limits. 582928 |
| Model Size Dynamics | Requires continuous parameter expansion (dense 1T+ models) to achieve intelligence gains. 23 | Enables smaller models (e.g., 7B-32B parameters) to punch above their weight via search algorithms. 134528 |
| Regulatory Thresholds | EU AI Act and similar policies focus heavily on static training compute thresholds (e.g., $10^{25}$ FLOPs). 56 | Evades static regulation: a small model with massive test-time compute can exceed the capabilities of heavily regulated frontier models. 56 |
These trade-offs carry profound implications for infrastructure and policy. Because existing regulations - such as the EU AI Act - are predicated on static training compute thresholds (e.g., the $10^{25}$ FLOPs boundary), the advent of test-time scaling creates a regulatory blind spot. A smaller, under-the-threshold model leveraging vast amounts of test-time processing can achieve capabilities that rival or exceed those of restricted frontier models, effectively bypassing the intended regulatory framework 56.
Limitations, Frictions, and Diminishing Returns
While the integration of advanced test-time processing has revolutionized performance benchmarks, it is not immune to the fundamental laws of diminishing returns. The scalability of inference compute is subject to distinct physical, algorithmic, and domain-specific constraints.
The Kinetics Scaling Law and Architectural Thresholds
Recent large-scale studies into test-time compute have identified a phenomenon referred to as the Kinetics Scaling Law. This law demonstrates that test-time scaling is not uniformly beneficial across all model sizes. There appears to be a critical capability threshold - frequently observed around the 14-billion parameter mark - below which extensive inference scaling is highly inefficient 28. For exceptionally small models (e.g., 1.5B to 7B parameters), allocating additional compute budget toward scaling the model's static parameters yields better returns than forcing the small model to generate thousands of tokens of flawed logic 28. The base model must possess a minimum viable understanding of the world to generate productive search paths.
However, for models positioned above this threshold (14B+ parameters), further computation is exponentially more effective when spent on inference algorithms (search, repeated sampling, and revision) up to the point of diminishing returns 28. Furthermore, because test-time scaling inherently generates massive context lengths, the memory access bottleneck of the Key-Value (KV) cache quickly becomes the dominant cost factor, eclipsing the cost of parameter computation. This constraint necessitates the use of extreme sparse attention mechanisms during generation to maintain physical viability on modern silicon 2857.
Domain Specificity and Diminishing Returns
The effectiveness of test-time scaling is highly domain-dependent. It achieves its most spectacular results in environments with strict, verifiable outcomes - such as competitive programming, combinatorial optimization, and formal mathematics 13958. In these domains, the model can rely on clear binary signals (e.g., a test suite passing or failing) to guide its backtracking and search mechanisms.
Conversely, in open-ended creative writing, general linguistic summarization, and subjective knowledge tasks, inference scaling exhibits rapid diminishing returns 35859. Generating 10,000 tokens of internal deliberation does not fundamentally improve a model's ability to draft a pleasant email or summarize a historical text. Human expert evaluations reveal that in tasks involving personal writing and editing, base models like GPT-4o perform on par with, or better than, deliberative models like o1, and do so much faster 596061. Moreover, when verification models are applied to these subjective domains, the system becomes highly susceptible to reward hacking. If $N$ candidates are generated in a Best-of-N search, a large $N$ will inevitably produce an output that superficially satisfies the verifier's stylistic preferences while actually degrading the underlying semantic quality 1811.
Latency and User Experience
From a product deployment perspective, the most severe friction is latency. Models engaging in deep test-time compute can take tens of seconds to several minutes to yield a final response. For instance, the o1 model operates at approximately 30 times the latency of the standard GPT-4o architecture 2961. While acceptable for asynchronous pharmaceutical research or complex software architecture planning, this delay completely disqualifies heavy test-time models from real-time applications such as autonomous vehicle navigation, voice-based conversational agents, and high-frequency trading systems 62.
Hardware and Data Center Resource Reallocation
The transition from training-centric scaling to inference-centric scaling is forcing a massive reallocation of capital and a fundamental redesign of global data center architecture. The economic center of gravity in artificial intelligence is shifting rapidly from the research laboratory to the deployment edge.
The Divergence of Cluster Design
Historically, the AI hardware market was monopolized by the demand for training mega-clusters. Training workloads require tens of thousands of GPUs (e.g., NVIDIA H100s) connected via ultra-high-bandwidth optical fabrics to process massive batches of data synchronously 5062632965. These facilities are characterized by enormous power density. Each new GPU generation draws significantly more power - NVIDIA's Blackwell architecture consumes roughly 4.8 times as much power as the preceding Hopper generation 54. As a result, training mega-clusters are projected to require systems of 1 to 5 Gigawatts by 2030, operating at 60 to 160 kW per rack, and are typically located in remote geographic areas adjacent to cheap, abundant power sources 5429.
Inference workloads fundamentally alter these requirements. Because test-time scaling requires models to serve millions of discrete user queries continuously, inference clusters prioritize ultra-low latency, decentralized geographic distribution, and high-speed network access to end-users 5462. While training clusters maximize throughput, inference facilities currently operate at a broader spectrum of 12 to 60 kW per rack, distributed across hundreds of smaller edge and metro-adjacent facilities 54. The inference process is highly atomizable; individual user queries do not require the entire cluster to synchronize. Serving real-time inference queries requires processing small batch sizes quickly, even if only a fraction of the GPUs are active at any given moment, creating a continuous optimization problem between latency and throughput 6229.
Silicon Evolution and Market Projections
The specific silicon powering these data centers is also bifurcating. While the training market remains tightly controlled by NVIDIA's high-end SXM-based modules, the inference market is significantly more fragmented and price-sensitive 516768697071.
Because inference involves unique, customized algorithms (like proprietary search or specific sparsity patterns), Application-Specific Integrated Circuits (ASICs) are gaining substantial ground 2971. Cloud providers are deploying custom silicon - such as AWS Inferentia2 and Google TPUs - which offer vastly improved price-to-performance ratios for inference workloads compared to general-purpose GPUs 516971. For example, AWS's Trainium 2 and Google's TPUv5 offer unit computing power costs that are 60% and 70% of Nvidia's H100, respectively 71. Furthermore, PCIe-based GPUs (such as the RTX PRO 6000) are becoming popular for edge inference deployments, offering plug-and-play capability without the massive infrastructure overhaul required for liquid-cooled SXM training racks 5468.
The financial implications of this architectural shift are profound. Analysts project that inference infrastructure will consume 65% to 75% of total AI compute demand by the end of the decade 5156. The AI inference market is forecast to grow from roughly $106 billion in 2025 to over $255 billion by 2030, driven almost entirely by the relentless continuous processing required by advanced test-time scaling protocols 5156. As reasoning-heavy models consume orders of magnitude more tokens per query than their predecessors, the aggregate lifetime cost of power, cooling, and silicon at the deployment stage will eventually dwarf the initial capital expenditure of model pre-training 25051.
Conclusion
The evolution of artificial intelligence has firmly exited the era of brute-force parameter scaling. The integration of test-time compute scaling represents a fundamental maturation of the field, shifting the focus from simply teaching models language to teaching them how to execute complex, multi-step logical search algorithms. By substituting massive upfront training capital with dynamic, per-query inference processing, the industry has unlocked a new capability frontier that bypasses the limitations of the data wall and the exponential costs of pre-training mega-clusters.
However, this frontier is defined by profound geographic, economic, and technical bifurcations. The United States proprietary ecosystem continues to push boundaries using massive capital, simulated processing, and closed models, while the Chinese open-source ecosystem has demonstrated that algorithmic ingenuity - such as GRPO and extreme MoE sparsity - can achieve benchmark parity at a fraction of the cost. As the industry races toward 2030, the battleground will no longer be solely defined by who possesses the largest training dataset, but rather by who can most efficiently orchestrate the algorithms, custom silicon, and distributed grid infrastructure required to let these models continuously deliberate in real time.