Sustainable competitive advantages for AI startups in 2026
Introduction: The Shift from Static Moats to Dynamic Defensibility
The commercialization of generative artificial intelligence has fundamentally disrupted traditional frameworks for evaluating technological defensibility. Prior to the late-2022 paradigm shift, the software-as-a-service (SaaS) industry operated under predictable physics: value accrued to platforms that aggregated users, locked in data, and generated predictable, high-margin recurring revenue. However, the proliferation of foundation models, agentic workflows, and advanced reasoning architectures has triggered a systemic re-evaluation of competitive moats.
The initial wave of generative AI startups operated under the assumption that historical moats - particularly the "data flywheel" and raw application execution - would seamlessly transfer to the AI era. This assumption has proven severely flawed. As the baseline capabilities of frontier models have accelerated, the delta between closed-weight proprietary APIs and fine-tuned open-source models has narrowed, exposing massive vulnerabilities in the "thin wrapper" business model 12. The "death of SaaS" narrative, driven by fears that artificial intelligence will commoditize code and render software interfaces obsolete, has forced a critical examination of where true enterprise value resides 23.
This report provides an exhaustive analysis of the structural, architectural, and geopolitical dimensions of AI defensibility. It systematically dismantles the prominent "data is a moat" misconception, contrasting it with the realities of synthetic data generation and foundational model reasoning. Furthermore, it explores the tension between execution velocity and structural entrenchment, evaluating how geographic regulatory regimes - such as the European Union's AI Act and localized data sovereignty mandates in Asia - are creating unprecedented, state-sponsored barriers to entry 456. Through the lens of Hamilton Helmer's "7 Powers," the integration of Aggregation Theory, and a rigorous stratification of the AI technology stack, this analysis delivers a definitive framework for understanding margin implications, architectural lock-in, and long-term value capture in the generative AI economy.
The Fallacy of the "Data Moat" and the Rise of Reasoning
For over a decade, the dominant strategic heuristic in Silicon Valley was that proprietary data constituted an insurmountable competitive advantage. This paradigm, heavily reliant on a continuous "data flywheel" - where more users generate more data, which trains a better model, subsequently attracting more users - served as the foundational moat for Web 2.0 aggregators 77. In the early stages of the generative AI boom, investors and founders projected this exact dynamic onto large language models, assuming that startups capturing unique interaction logs or domain-specific text would inherently outcompete generic models 19.
The reality of the post-2023 landscape has aggressively challenged this assumption. Leading venture capital analyses now recognize that the pure data moat is eroding under the pressure of two concurrent technological breakthroughs: the efficacy of synthetic data generation and the evolution of advanced reasoning architectures 1710.
Synthetic Dilution and the Commoditization of Text
The assumption that an organization requires vast, proprietary troves of human-generated text to train a superior model has been undermined by the realization that models can generate their own high-fidelity training data. As frontier models achieve higher baseline intelligence, their ability to synthesize edge cases, simulate complex conversations, and generate contextually accurate training pairs has drastically reduced the barrier to entry for model fine-tuning 910. Consequently, if a startup's primary advantage is a database of customer service logs, basic coding syntax, or standard legal templates, that data can likely be approximated synthetically by a well-prompted foundational model. This reality renders the proprietary text dataset effectively commoditized, stripping it of its defensibility.
The Shift to Reasoning and Intent-First Paradigms
Furthermore, the advent of sophisticated reasoning models minimizes the need for brute-force, task-specific data training. Contemporary models utilize mechanisms like chain-of-thought, tree-of-thought, and reflexion processing to dynamically deduce solutions at inference time, rather than relying strictly on patterns memorized during pre-training 789. When a foundation model can logically reason its way through a complex, novel problem, the value of a startup's rigidly fine-tuned, task-specific dataset plummets.
As noted by Sequoia Capital, the data that application companies generate rarely creates an insurmountable barrier because the next generation of generalized foundation models frequently obliterates any marginal performance advantage a startup has cobbled together through basic data harvesting 7. The analytical consensus has shifted to recognize that "the moats are in the customers, not the data," with durable advantages found in workflow stickiness and user networks rather than raw information asymmetry 7.
The Surviving Data Moats: Deep Vertical and Physical Intersection
However, the death of the data moat is not absolute; rather, it has bifurcated. While easily accessible text and generic interaction logs are no longer defensible, deep, high-dimensional, proprietary data remains one of the few enduring advantages 1014.
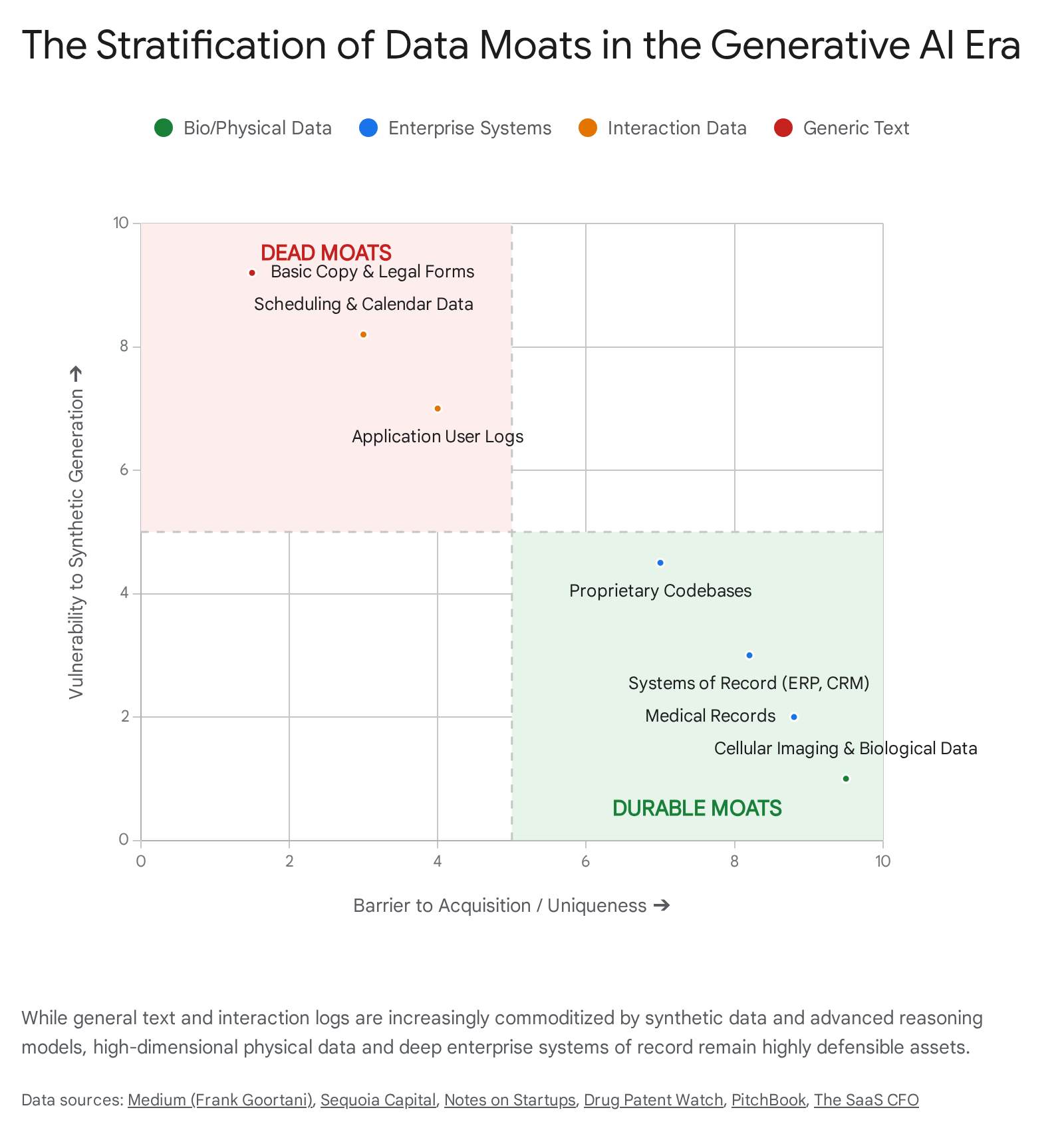
The critical distinction lies in the nature of the data and its distance from standard internet scraping.
Companies that generate data via complex physical processes hold immense power. For instance, enterprises utilizing automated wet labs to generate millions of high-dimensional cellular images weekly possess what is termed "digital oil" 10. This biological and physical exhaust cannot be synthetically hallucinated by a generalized language model; it is tethered to physical reality and protected as a trade secret, making it a near-impenetrable moat 10.
Similarly, enterprise data that is highly unstructured, historically deep, and heavily restricted by privacy regulations - such as private medical records, proprietary enterprise resource planning (ERP) transaction histories, and core banking logs - remains highly defensible 23. The moat here is not merely the data itself, but the exclusive access to it, which is guarded by legacy IT architectures, compliance standards, and organizational inertia.
Execution Velocity versus Structural Defensibility
A pervasive debate within the AI ecosystem centers on whether traditional structural moats are necessary, or if raw execution speed is the only viable defense against rapid model depreciation.
The "Speed as the Only Moat" Perspective
Prominent startup accelerators and venture capital firms have increasingly championed the perspective that, in the earliest stages of an AI company's lifecycle, the only true moat is velocity 11. With foundational model providers continually shipping updates that consume the feature sets of peripheral startups - a phenomenon characterized as the vulnerability of the "thin wrapper" - static defensibility is viewed by some as an illusion. Startups operating at the frontier have epitomized this approach, utilizing extreme execution speed, running one-day sprint cycles, and shipping continuously to outpace the bureaucratic inertia of incumbents 11.
The underlying logic dictates that massive hyperscalers and frontier labs, burdened by extensive product requirement documents, public relations reviews, communication protocols, and safety alignment procedures, simply cannot iterate at the speed of a focused, specialized team 11. In this view, achieving overwhelming product-market fit by solving an urgent, high-friction problem is the singular prerequisite to survival; worrying about structural defensibility before achieving critical mass is considered a premature distraction 11.
Transitioning to Deep Tech and Ecosystem Lock-In
However, rigorous market analysis indicates that while velocity is critical for navigating the initial product-market fit phase, it is entirely insufficient for sustainable scaling. Speed is a transient advantage; it does not compound geometrically in the way that true structural power does. Long-term survival in the AI ecosystem demands a transition from execution velocity to structural entrenchment.
This entrenchment is primarily achieved by intersecting software with domains that possess inherent physical or organizational friction 1217. As the half-life of pure software value compresses rapidly in the age of generative code, durability is found where artificial intelligence interacts with deep tech breakthroughs, hardware constraints, complex regulatory frameworks, and established ecosystem lock-in 212.
For example, an AI agent that merely drafts marketing copy operates purely in the digital realm and has zero structural defensibility; it is highly susceptible to displacement by generic models. Conversely, an AI platform that navigates the rigorous compliance requirements of KYC (Know Your Customer) protocols for tier-one financial institutions, or one that directly orchestrates factory automation via legacy manufacturing ERPs, builds profound switching costs 311. Displacing such a system requires an enterprise to reconstruct trust networks, legal compliance architectures, and operational workflows. This organizational disruption acts as a formidable barrier to exit, transforming a software tool into a structural necessity 312.
The Aggregation Theory Reckoning: Incumbents vs. Open Source
To understand the macro-competitive landscape of artificial intelligence, it is essential to contextualize it within established frameworks such as Aggregation Theory. Historically, economic power on the internet was marshaled by platforms that controlled demand and discovery - Aggregators like Google and Meta 1314.
Artificial intelligence represents a unique paradigm shift. For massive incumbents, generative AI functions as a sustaining innovation rather than a strictly disruptive one 151617. Meta, for example, utilizes massive GPU fleets to build probabilistic AI models that recover targeting efficacy lost to mobile privacy changes, while Google leverages AI to sustain its advertising and cloud dominion 1517. Because these incumbents already possess distribution, capital, and data center scale, they can subsidize the immense inference costs of deploying AI features directly to billions of users 2.
This dynamic creates a hostile environment for startups attempting to compete on raw capability. The primary battle lines are drawn not between startups and incumbents, but between the proprietary models of Big Tech and the open-source community 1316. Startups must therefore utilize "Counter-Positioning" - adopting business models that incumbents cannot mimic without damaging their existing revenue streams, such as replacing per-seat software licenses with outcome-based autonomous agents 217.
Geopolitical and Regulatory Moats: The Rise of Sovereign AI
A critical, yet frequently underappreciated, dimension of AI defensibility is the role of geography and regulation. State-sponsored policies are actively fragmenting the global AI ecosystem, acting as massive, artificial barriers to entry and creating distinct regional moats that transcend pure technological capability.
The European Paradox: The AI Act as an Incumbent Shield
The European Union's approach to AI governance, primarily enacted through the EU AI Act (phased into full enforcement by August 2027), fundamentally alters the competitive dynamics of the region 23. Framed as a pioneering effort to ensure ethical deployment and protect citizen rights, the comprehensive, risk-tiered framework imposes severe compliance burdens on companies developing foundation models and "high-risk" AI systems utilized in sectors like healthcare, hiring, and credit scoring 423.
The economic reality of the AI Act is that regulatory compliance functions as a massive, uniform fixed cost. Impact studies estimate that implementing the necessary management, auditing, and documentation systems for high-risk AI can cost a 100-employee business upwards of €400,000, representing a disproportionately high burden per employee 4. For hyperscalers and entrenched technology giants, this cost is a negligible rounding error, easily absorbed and amortized across massive global operations. For an early-stage startup, however, it constitutes an existential barrier to entry 4.
Consequently, the EU AI Act inadvertently mirrors the economic impact of the General Data Protection Regulation (GDPR): it reduces competitive intensity by heavily favoring large, well-capitalized platforms that possess the resources to employ armies of compliance officers and navigate regulatory sandboxes 418. It creates an artificial "Process Power" moat for incumbents, while systematically starving the European ecosystem of the highly agile startups necessary to challenge global tech dominance 41920. Recent surveys indicate that over 58% of EU and UK developers report regulation-driven launch delays, with startups losing hundreds of thousands of euros annually to compliance slowdowns 20. Ultimately, this regulatory burden acts as a structural moat protecting foreign hyperscalers already operating in the EU, while stunting domestic velocity and compounding Europe's reliance on non-EU infrastructure 1920.
The Asian Sovereignty Wall: State-Sponsored Defensibility
In stark contrast to the EU's compliance-heavy approach, nations in the Asia-Pacific region - most notably India and China - are utilizing data localization and digital sovereignty laws as strategic offensive weapons to foster domestic AI moats 527.
China's stringent data security framework, anchored by its Cybersecurity Law (2017) and Data Security Law (2021), explicitly mandates that critical data generated domestically must be stored and processed within Chinese borders 27. This creates absolute "technological sovereignty," effectively locking out Western foundation models and providing a protected, captive market for domestic AI giants and emerging local startups 2728.
India is executing a similarly ambitious strategy of digital independence. Recognizing that data processing is a matter of national security, the Indian government and local enterprises are increasingly mandating data localization for critical sectors 52130. The government's IndiaAI Mission, backed by a budget of over ₹10,000 crore, aims to build indigenous AI infrastructure, while regulators push to prohibit international data transfers 621. This strategy of data restriction is a calculated mechanism to force the development of localized AI infrastructure and promote "national champions" 621.
For regional startups, this geopolitical fragmentation is a massive strategic advantage. It creates an absolute "Cornered Resource" in the form of domestic data access, neutralizing the scale advantages of US-based hyperscalers who face friction or outright bans on processing that data 5631. Startups that build localized AI data centers and sovereign cloud frameworks instantly inherit a moat decreed by national security policy - a defensibility vector completely absent in the globally deregulated segments of the market 521.
Architectural Margin Defensibility: APIs vs. Open-Source Fine-Tuning
Beyond geopolitical borders, the most pressing operational decision dictating an AI startup's long-term enterprise value is its underlying infrastructure architecture. The choice between utilizing proprietary closed-weight APIs (e.g., OpenAI's GPT-4, Anthropic's Claude) versus self-hosting and fine-tuning open-source models (e.g., Meta's Llama 3, Mistral) has profound implications for margin structures, defensibility, and vendor lock-in 323322.
The API Trap: Margin Compression at Scale
In the prototyping and low-to-medium volume phases of a startup, proprietary APIs are the undisputed optimal choice. They require zero upfront capital expenditure, offer state-of-the-art general reasoning, and allow teams to iterate with maximum velocity without worrying about infrastructure provisioning 322336. However, this convenience masks a lethal margin trap at scale.
Because proprietary API pricing is strictly usage-based - charging per million input and output tokens - variable costs scale linearly, and sometimes exponentially due to the asymmetric pricing of output tokens, with user adoption 3237. A company relying entirely on a frontier API for high-volume, repetitive tasks (e.g., an AI agent routing 10 million customer support queries monthly) will face crippling inference costs. For example, relying on top-tier models for such volume could generate monthly API bills exceeding $150,000, fundamentally breaking the traditional SaaS gross margin profile of 70-80% 32338. Furthermore, relying entirely on a third-party API creates immense vulnerability; the startup becomes entirely dependent on the continuous benevolence, uptime, and pricing stability of the API provider, suffering from low internal switching costs where competitors can easily replicate the product 1239.
The Economics of Self-Hosting and Fine-Tuning
As the performance gap between proprietary models and open-source models narrows to negligible margins for specific tasks, a massive migration toward self-hosted, fine-tuned architecture is occurring 13340. The economic rationale is striking: while fine-tuning an open-source model requires an upfront investment in compute and engineering talent (roughly $500 for a standard training run), the ongoing inference costs plunge drastically 3223.
Strategic analyses indicate a clear volume inflection point.
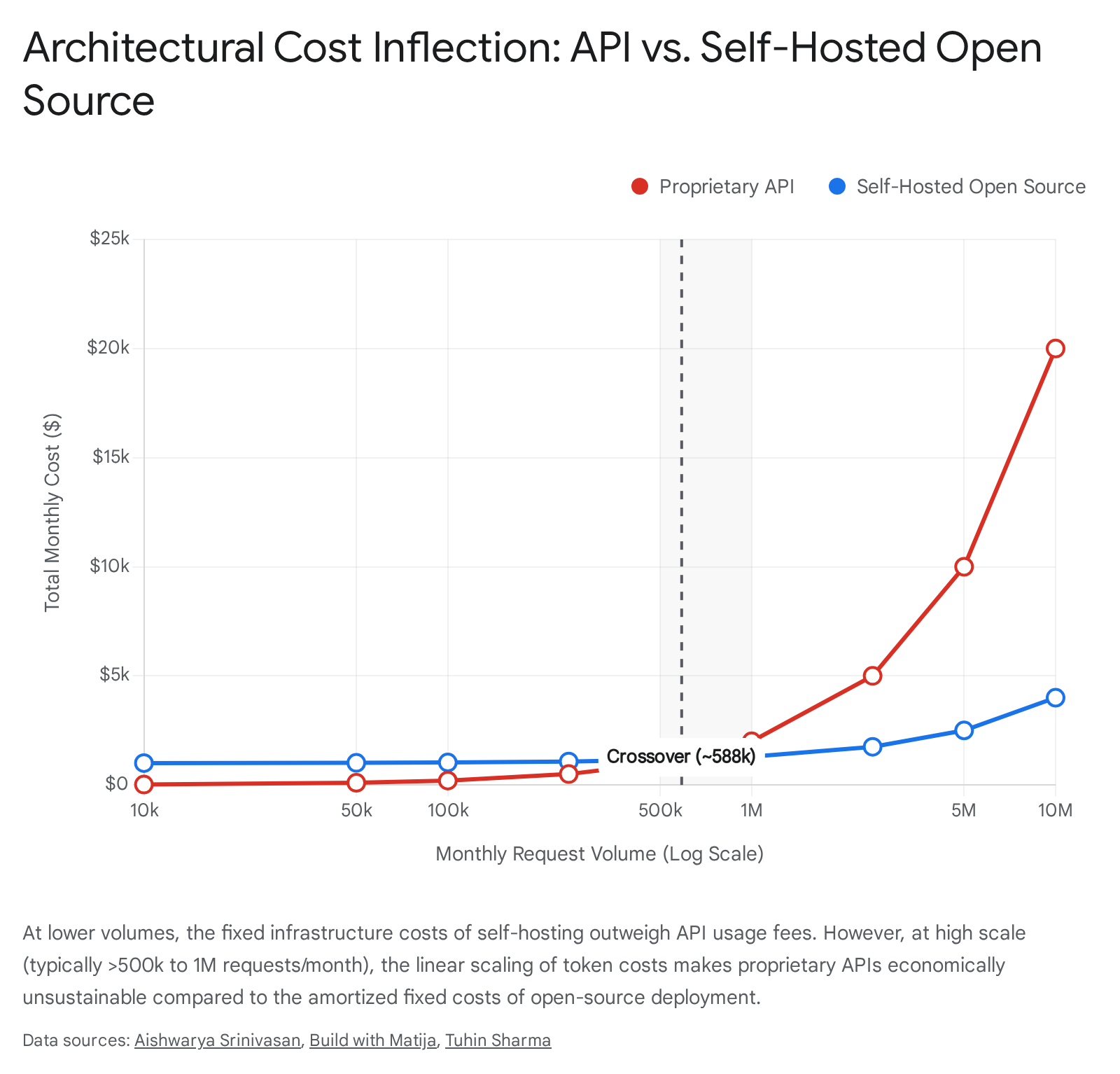
At low request volumes (under 50,000 to 500,000 monthly requests), the operational overhead of managing GPU clusters makes self-hosting economically irrational 2338. However, for high-volume, specialized workloads crossing 1 million requests per month, self-hosting a fine-tuned open-source model can drop inference costs to approximately $0.20 per million tokens - a 75x reduction compared to $15.00 per million on proprietary APIs 32. This yields cost reductions of upwards of 95% 38.
Beyond unit economics, fine-tuning provides structural defensibility. It allows a startup to bake domain-specific guardrails, latency optimizations, and specialized behaviors directly into the model's weights 3241. Perhaps most critically for enterprise adoption, self-hosting ensures absolute data privacy and regulatory compliance, allowing startups to sell into highly regulated sectors (healthcare, defense, fintech) that strictly prohibit sending sensitive data to external cloud providers 323322.
The Shifting Economics of SaaS and the "Agentic" Transition
As artificial intelligence alters the cost structure of software development, traditional enterprise pricing models are undergoing a massive transition. Traditional SaaS pricing was predominantly seat-based (charging per user, per month) because the marginal cost of serving an additional user was virtually zero 337. The AI paradigm breaks this math entirely. Every request made to an LLM provider carries a direct variable cost tied to token count 37.
Furthermore, as AI transitions from "Copilots" (assistants that help a human) to "Agents" (autonomous actors that execute multi-step workflows), the requirement for human seats diminishes 214. If an enterprise uses an AI agent to autonomously resolve 50% of its customer support tickets, its requirement for human agents drops, triggering an automatic collapse in traditional seat-based recurring revenue 23.
To survive, the software industry is aggressively pivoting toward usage-based billing, outcome-based pricing, and hybrid "wallet" models 33724. Vertical AI applications are now targeting the $11 trillion US labor spend rather than just the enterprise software budget, capturing value based on the labor they automate rather than the software licenses they issue 14. However, implementing this pricing requires highly complex metering infrastructure - the "metering trap" - to accurately intercept LLM responses, calculate token usage across multi-model routing, and deduplicate requests for accurate billing without eroding customer trust 37.
Re-mapping Hamilton Helmer's "7 Powers" to the Generative AI Era
Hamilton Helmer's "7 Powers" framework has long served as the canonical guide for evaluating durable competitive advantage, defining the structural conditions that allow a company to realize persistent differential returns 434445. The framework establishes that true strategy requires a structural advantage that competitors cannot or will not copy, yielding both a Benefit (cost advantage or higher pricing) and a Barrier (preventing imitation) 3145.
However, the generative AI paradigm requires a radical translation of these powers. What constituted a moat in the traditional SaaS era has frequently become a vulnerability, while entirely new dimensions of power have emerged that demand rigorous strategic alignment 174546. The following table meticulously maps Helmer's 7 Powers from their traditional SaaS applications to their redefined AI-era equivalents and vulnerabilities.
TABLE 1: Hamilton Helmer's 7 Powers: Traditional SaaS vs. AI-Era Equivalents
| Helmer's Power | Traditional SaaS Application | AI-Era Startup Equivalent (The New Moat) | AI-Era Vulnerability (How the Power Erodes) |
|---|---|---|---|
| 1. Scale Economies | Amortizing massive upfront software development and server costs across a large, fixed user base, achieving lower unit costs (e.g., Microsoft Windows, Costco) 314344. | Learning Economies: Amortizing model training and inference costs across vast user bases; cross-subsidizing niche AI features using core platform profits 17. | Commoditization of Code: AI coding agents reduce software development costs to near-zero, enabling micro-SaaS competitors to match features instantly, destroying scale advantages 2346. |
| 2. Network Effects | The product gains value as more human users join the network, creating many-to-many mapping (e.g., LinkedIn, Airbnb) 731434445. | The Data-to-Model Flywheel: Deep integration where continuous human-AI collaboration (RLHF, edge-case corrections) trains a hyper-personalized model, improving the product for all users 71725. | Synthetic Parity: If the "network effect" relies purely on generic text generation, synthetic data capabilities can replicate the network's value without requiring actual users 710. |
| 3. Counter-Positioning | A newcomer adopts a superior business model that incumbents cannot copy without damaging existing revenue (e.g., Netflix vs. Blockbuster) 314348. | Outcome-based vs. Seat-based Pricing: Selling automated labor (AI agents) at a fraction of the cost, forcing incumbents to destroy their own per-seat recurring revenue to compete 21417. | Incumbent Subsidization: Massive incumbents can leverage their core profitable businesses to offer AI features for free as a sustaining innovation, starving startups of margin 216. |
| 4. Switching Costs | High technical friction and retraining costs associated with ripping out software infrastructure 3143. | Workflow & Contextual Lock-in: The AI becomes deeply integrated into the physical organization, holding proprietary context, custom agentic workflows, and ERP integrations that require massive disruption to untangle 121749. | API Standardization: If an application is merely a "thin wrapper," the underlying LLM can be swapped via API in minutes, creating zero friction for the customer to leave 22339. |
| 5. Branding | Building an asset that communicates information and evokes positive emotional resonance and trust over decades 3143. | Trust and Safety Arbitrage: Establishing a reputation for absolute model safety, hallucination-free reliability, and strict enterprise compliance in a volatile, highly scrutinized market 173325. | Capability Degradation: In AI, brand loyalty evaporates instantly if a competitor releases a model with demonstrably superior reasoning capabilities, rendering emotional connection moot 125. |
| 6. Cornered Resource | Securing preferential access to a coveted, scarce asset (e.g., patents, premium real estate, top talent) 3143. | Regulatory Capture & Sovereign Data: Securing exclusive data partnerships, amassing scarce physical compute (GPUs), or leveraging localized data sovereignty laws (e.g., Indian AI mandates) 6917. | Open-Weight Proliferation: The release of highly capable open-source models (e.g., Meta's Llama 3) neutralizes the "cornered resource" of possessing a privately trained foundational model 3325. |
| 7. Process Power | Embedding superior, complex internal operations that are impossibly difficult to mimic (e.g., Toyota Production System) 314344. | The 99% Mission-Critical Solution: Engineering the unglamorous, edge-case orchestration required for AI to execute flawlessly in high-stakes environments (e.g., legal, medical, banking) 71750. | Native Model Upgrades: A startup spends years building complex orchestration to overcome a model's flaw, only for the next foundation model release to solve the problem natively, wiping out the process advantage 151. |
Stratification of the AI Tech Stack and Switching Costs
As the AI ecosystem matures, it is rapidly stratifying into distinct architectural layers. The long-term durability of an organization is inexorably linked to the specific layer of the stack it occupies and the barriers it constructs. "Aggregation Theory," traditionally applied to web platforms that aggregated consumer demand to modularize suppliers, is actively playing out within the AI stack 81326. Currently, value is aggressively polarizing at the absolute bottom of the stack (infrastructure and foundation models) and the absolute top (Systems of Record and proprietary workflows), creating a highly vulnerable, commoditized "middle" 151.
The following table dissects the modern AI technology stack, evaluating each layer's primary functions, expected moat longevity, and the switching costs associated with its deployment.
TABLE 2: AI Tech Stack Layers: Longevity and Switching Costs
| AI Stack Layer | Definition & Key Components | Moat Longevity | Switching Cost Profile | Strategic Defensibility Assessment |
|---|---|---|---|---|
| Layer 1: Energy & Physical Infrastructure | Power generation, cooling systems, data centers, and raw GPU/TPU compute availability (e.g., NVIDIA, AWS, sovereign data centers) 53545556. | Extremely High: Constrained by the physical realities of grid power, semiconductor supply chains, high-bandwidth memory (HBM) integration, and massive capital expenditure 855. | High: Migrating large-scale enterprise workloads between distinct hyperscaler ecosystems or physical data centers involves severe logistical and capital friction 5557. | The Ultimate Bottleneck: This layer captures immense value because demand infinitely outstrips supply. Geopolitical tensions and national sovereignty mandates further entrench local infrastructure moats 5855. |
| Layer 2: Foundation & Reasoning Models | The core intelligence engines trained on exabytes of data (e.g., OpenAI GPT-4, Google Gemini, Meta Llama) 385327. | Medium to High: Requires billions in R&D and elite, scarce research talent. However, the performance gap between closed and open-source models is rapidly narrowing 13353. | Low to Medium: Standardized API endpoints make swapping base models technically trivial. Cost considerations and specific reasoning capabilities drive transient loyalty 233951. | The Capability Arms Race: While highly defensible against startups, these frontier labs face intense commoditization pressures against each other. Success depends on setting developer defaults and building platform gravity 153. |
| Layer 3: Orchestration & Infrastructure Software | Middleware that connects models to data pipelines, memory, and deployment tools (e.g., LangChain, Databricks, Vector Databases) 54555727. | Medium: Highly susceptible to being subsumed natively by either the Foundation Model layer expanding features, or the Application layer above it 5154. | Medium: Developers build habits around these tools, but the codebase is modular. If a superior orchestration framework emerges, migration is painful but manageable 5154. | The Squeezed Middle: These platforms must rapidly evolve to offer deep observability, security, and enterprise governance to avoid being modularized by native model capabilities 5457. |
| Layer 4: System of Record (SoR) / Deep Workflow | Enterprise applications that house proprietary organizational data and govern critical business logic (e.g., Salesforce, SAP, specialized vertical ERPs) 2254951. | Very High: These systems own the contextual data required for AI agents to actually execute tasks. An AI agent is useless without access to this historical ground truth 23. | Extremely High: Ripping out an SoR is equivalent to "open-heart surgery" for an enterprise. It disrupts interconnected workflows, compliance audit trails, and daily operations 2312. | The Defensive Fortress: Traditional SaaS giants are leveraging deep integration to embed AI seamlessly into existing workflows. Their access to proprietary data allows them to capture immense value, refuting the "death of SaaS" thesis 21449. |
| Layer 5: UI-Layer "Thin Wrappers" | Applications that merely slap a graphical interface or simple prompt chain over a third-party API (e.g., basic copy-editing tools, generic scheduling chatbots) 253. | Extremely Low: Easily replicated by micro-SaaS competitors; constantly at risk of being rendered obsolete by native updates from Foundation Models 25153. | Zero: Customers have virtually no penalty for abandoning the software if a cheaper, faster, or natively integrated alternative arises 249. | The Extinction Zone: Lacking proprietary data, workflow lock-in, or deep technical IP, these companies compete purely on UX and initial speed-to-market. They possess no structural defensibility and suffer rapid margin compression 25153. |
Conclusion
The transition into the generative AI epoch has mandated a total reconstruction of competitive strategy. The initial assumption that legacy Web 2.0 moats - specifically the volume-based data flywheel - would seamlessly protect AI startups has been shattered by the ascendancy of synthetic generation and advanced foundational reasoning models. While execution velocity is the essential catalyst for early-stage survival, it is an insufficient defense against the structural power of foundation models, the massive capital advantages of incumbents utilizing AI as a sustaining innovation, and the deep workflow lock-in of traditional Systems of Record.
To achieve durable enterprise value, technology operators and investors must recognize that defensibility has migrated. It no longer resides in generic text aggregation, but rather in the friction of the physical world, the possession of high-dimensional biological or proprietary enterprise data, and the navigation of complex regulatory environments. The European Union's stringent compliance laws and the calculated data sovereignty mandates of Asia serve as poignant reminders that geopolitical boundaries and state-sponsored infrastructure initiatives are rapidly becoming the most insurmountable moats in the global digital economy.
Furthermore, architectural decisions made today will dictate the margin viability of tomorrow. The reliance on proprietary APIs, while highly advantageous for rapid iteration, introduces fatal unit economics at scale and prevents the deep architectural entrenchment required for long-term lock-in. Ultimately, the survivors of the AI platform shift will not be the entities that merely build the best wrappers around rented intelligence, but those that successfully embed self-hosted intelligence into proprietary systems, navigate geographic barriers, and capture the structural powers defined by the evolving, multi-layered technology stack.