Superposition hypothesis in neural networks
Introduction to Mechanistic Interpretability
The rapid proliferation and scaling of deep learning architectures have produced artificial intelligence systems of unprecedented capability, yet the internal mechanisms governing their computations remain largely opaque. This opacity presents substantial challenges for safety, alignment, and reliability, driving the emergence of mechanistic interpretability. Mechanistic interpretability is a dedicated research domain aiming to reverse-engineer the opaque, high-dimensional weight matrices of trained neural networks into discrete, human-understandable algorithms and computational circuits 113.
The historical trajectory of this field initially centered on vision models during the mid-2010s. Researchers operating within this early paradigm frequently hypothesized that neural networks functioned via a strict one-to-one mapping, wherein individual neurons corresponded to distinct, identifiable concepts, such as a "curve detector" or a highly specific "Jennifer Aniston" neuron 23. However, as the focus of interpretability research transitioned toward large language models (LLMs) and advanced multimodal systems, this foundational assumption of monosemanticity began to collapse.
Empirical investigations consistently revealed that the vast majority of neurons in complex networks did not respond to single, isolated features. Instead, individual neurons activated in response to a chaotic pastiche of multiple, seemingly unrelated concepts - a phenomenon termed polysemanticity 364. A single neuron might activate strongly in the presence of images of cats, the structural syntax of Python code, and specific textual descriptions of vehicles 85. Because tracing the activation of a polysemantic neuron provides inherently ambiguous information regarding what concept the network is actively processing, polysemanticity emerged as a critical roadblock to mapping the computational circuits of advanced AI systems 6.
The Framework of the Superposition Hypothesis
To resolve the paradox of polysemantic neurons, researchers formulated the superposition hypothesis. The superposition hypothesis posits that neural networks are fundamentally unconstrained by the finite number of neurons (or dimensions) they possess within any given layer. Instead of enforcing a strict one-neuron-per-feature architecture, networks learn to represent an exponentially larger set of features by embedding them as vectors within a shared, high-dimensional activation space 37813.
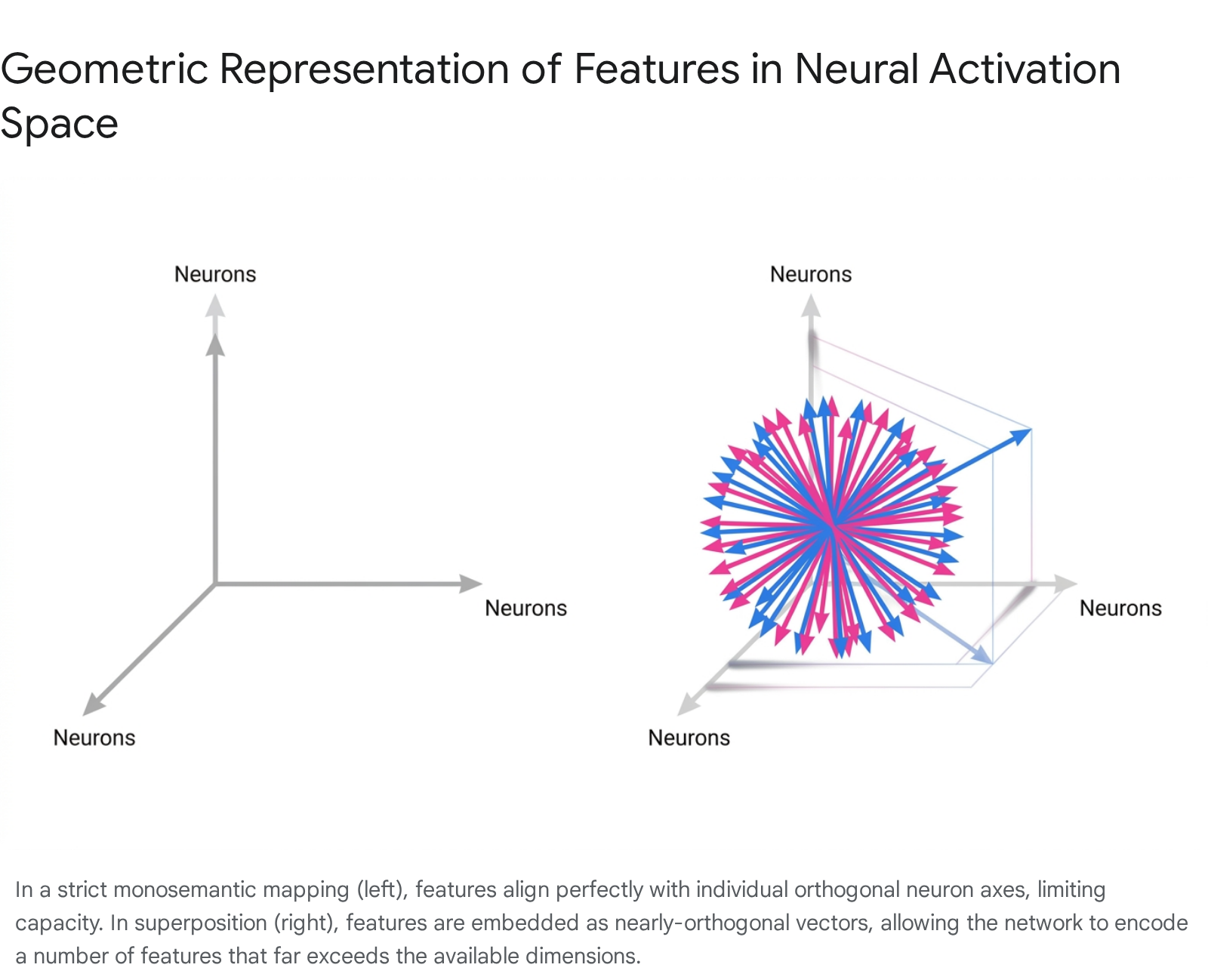
Under this framework, a network representing features in superposition does not allocate individual neurons to individual concepts. Instead, each feature corresponds to a specific direction across the entire activation space. Because these directions overlap, each neuron contributes to the representation of multiple features, and each feature is distributed as a pattern across multiple neurons 3. When an input contains a specific feature, the network activates the corresponding vector direction. If multiple features co-occur, the resulting activation vector is a linear sum of those individual feature directions 313.
Superposition is not a failure of the optimization process or an architectural flaw; rather, it is a mathematically optimal, compressed representation strategy naturally discovered by gradient descent. By multiplexing features through a shared vector space, neural networks effectively simulate the representational capacity of a hypothetically much larger, highly sparse network 3714.
High-Dimensional Geometry and Capacity Limits
The theoretical viability of the superposition hypothesis is deeply anchored in the geometry of high-dimensional spaces, a property most clearly articulated through the Johnson-Lindenstrauss lemma 61516. In low-dimensional geometry, the number of strictly orthogonal directions is exactly equal to the number of dimensions. However, as dimensionality scales upward into the thousands - typical for the hidden layers of modern LLMs - the geometry of the space shifts dramatically.
High-dimensional spaces contain an exponentially larger number of nearly orthogonal directions compared to strictly orthogonal ones 39. If a network is willing to tolerate a minuscule amount of mathematical noise or interference between vectors, it can pack an enormous volume of concepts into a restricted bottleneck. The Johnson-Lindenstrauss lemma formally establishes that a set of $m$ points can be linearly projected into a lower-dimensional space of size $O(\log m)$ while preserving the Euclidean distances between all pairs of points within a small error margin 1510.
For neural networks, this mathematical property translates into a staggering upper bound for passive representation. Assuming a neural network layer possesses $n$ neurons, the Johnson-Lindenstrauss lemma dictates that the layer can theoretically encode up to $2^{O(n)}$ passive features using nearly orthogonal vectors 616. This exponential capacity demonstrates why polysemanticity is an inevitable consequence of parameter-efficient training: to access this massive representational volume, the network must utilize vectors that project across multiple standard neuron axes simultaneously 89.
Sparsity and the Interference Threshold
While the mathematical capacity of high-dimensional space enables superposition, the strategy introduces an inherent, inescapable cost: interference. Because the feature vectors are nearly orthogonal rather than strictly orthogonal, they are not mathematically isolated. When a network activates a specific feature vector, it inevitably generates a non-zero dot product - or projection noise - along the dimensions corresponding to other superimposed features 7819.
The feasibility of maintaining accurate representations in the presence of this interference relies entirely on the natural sparsity of the input data 1112. In the context of language or visual processing, the true environment contains millions of potential features, but only a microscopic fraction of these features are actively relevant to any single input instance 313.
If the data distribution were dense - meaning hundreds or thousands of features co-occurred constantly - the additive interference from the non-orthogonal projections would compound rapidly 1112. This noise would operate like a random walk, quickly overwhelming the true signal and rendering the network's activations unintelligible. However, because features are sparsely distributed (often possessing an activation probability well below 0.05), the likelihood of numerous overlapping features firing simultaneously remains exceptionally low 11.
Mathematical models indicate that if $l$ features are active simultaneously within a network of $n$ dimensions attempting to store $m$ total features, the average interference noise scales proportionally to $\epsilon \sqrt{l}$, where $\epsilon$ dictates the baseline overlap between vectors 9. For the network to reliably decode the signal, the activation strength of the true feature must remain significantly higher than the compounding $\sqrt{l}$ interference noise generated by the other sparsely active elements 9.
Architectural Influences on Feature Representation
The specific mechanisms by which neural networks deploy superposition are heavily constrained by their underlying architectures. A critical concept in understanding why features map to neurons in certain layers but remain completely distributed in others is the distinction between privileged and non-privileged bases.
Privileged versus Non-Privileged Bases
In linear algebra, a vector space has no intrinsic orientation; any orthogonal rotation of a coordinate system represents the data with perfect mathematical equivalence. However, within the architecture of a neural network, certain operations break this rotational invariance, establishing a "privileged basis" 823.
A privileged basis exists when the network architecture inherently distinguishes the standard basis directions - the individual neurons themselves - from arbitrary directions in the activation space 82314. The primary mechanism that establishes a privileged basis is the application of element-wise non-linear activation functions, such as Rectified Linear Units (ReLU) or Gaussian Error Linear Units (GELU) 1415.
Because a ReLU function operates on each neuron individually - setting all negative values on that specific axis to zero while leaving positive values unchanged - the operation is not rotationally invariant. If the entire activation space is mathematically rotated, the ReLU will truncate entirely different components of the representation, destroying the encoded information 15. Consequently, the network faces a strong optimization incentive (inductive bias) to align its most critical, frequently used features directly with these individual neuron axes. When features align perfectly with the standard basis, the result is the emergence of monosemantic neurons 81416.
Conversely, a non-privileged basis lacks any architectural mechanism that treats specific axes differently from others. The residual stream in transformer models, as well as the keys, queries, and values within attention heads, operate as non-privileged spaces because they rely primarily on linear transformations 231427. In a non-privileged space, the optimization process has no incentive to align semantic features with the arbitrary axes defined by the neurons 15. As a result, the network distributes information redundantly across all available dimensions. In these spaces, polysemanticity occurs naturally regardless of capacity constraints, simply because the feature vectors exist at arbitrary, unaligned rotations relative to the standard basis 816.
| Architectural Domain | Basis Type | Primary Mechanisms | Feature Alignment Characteristics | Implications for Polysemanticity |
|---|---|---|---|---|
| MLP Hidden Layers | Privileged Basis | Element-wise non-linearities (ReLU, GELU); L1 regularization. | Strong inductive bias to align highly important features perfectly with individual neuron axes. | Polysemanticity primarily emerges due to capacity constraints (necessary superposition) forcing multiple features onto the same axes. |
| Residual Streams | Non-Privileged Basis | Purely linear transformations; matrix multiplication bottlenecks. | No optimization incentive for axis alignment. Features are distributed arbitrarily across the vector space. | Polysemanticity is the default state due to arbitrary vector rotation, even if the number of neurons equals the number of features. |
The Mechanics of Non-Linear Interference Filtering
The establishment of a privileged basis via non-linearities does more than just encourage feature alignment; it provides the fundamental mechanism that makes superposition computationally viable.
In a strictly linear model lacking activation functions, interference is entirely unmitigated. The interference is mathematically defined as the sum of squared dot products between all pairs of feature vectors: $\sum_{i \neq j} |W_i \cdot W_j|^2$ 7. Because any overlap strictly degrades the accuracy of the representation, linear models actively avoid superposition. When faced with more features than dimensions, a linear model will simply drop the least important features, dedicating its dimensions exclusively to orthogonal representations of the most critical variables 1217.
However, the introduction of non-linear thresholding, such as a ReLU, alters the cost-benefit analysis of interference. A ReLU acts as an active "interference filter" 71218. Models learn to apply slightly negative bias weights to their neurons. When sparse, nearly orthogonal features generate small amounts of cross-talk projection noise, this negative bias shifts the sum of the noise below zero. The ReLU then maps these negative values precisely to zero, completely eliminating the interference from the forward pass 71217. This dynamic allows the network to tolerate the non-orthogonality of superposition because the activation function mathematically silences the resulting baseline static, protecting the high-magnitude true signals 78.
The Geometric Organization of Superimposed Features
When neural networks rely on non-linear filtering to manage interference, the features embedded in superposition do not scatter randomly throughout the activation space. Empirical investigations using idealized toy models reveal that features self-organize into highly structured geometric motifs dictated by their relative sparsity and importance 717.
Phase Changes and Geometric Polytopes
Research into feature organization demonstrates that superposition operates via first-order phase changes 730. In idealized models where input features are statistically independent and uniformly sparse, the optimization landscape is characterized by distinct, discontinuous thresholds 730. As the sparsity of the data increases - making it safer for the model to pack features more densely - the network's optimal weight configuration abruptly transitions between different geometric shapes 47.
A network effectively assigns fractions of a hidden dimension to each feature, calculated as the squared norm of the feature's weight vector divided by the sum of its squared projections onto all other features: $D_i = ||W_i||^2 / \sum (\hat{W_i} \cdot W_j)^2$ 7. As capacity pressures shift, the network gravitates toward highly stable mathematical "sticky points" corresponding to specific fractional dimensionalities 7.
When allocating dimensions to features, networks generate distinct polytopes: * Dimensionality 1: A dedicated, orthogonal dimension for a highly important feature (no superposition). * Dimensionality 1/2: Features organize into antipodal pairs, occupying the exact same dimension but pointing in opposite directions, relying on the ReLU to filter out the negative activation of the opposing feature 717. * Dimensionality 2/3: Three features distribute themselves evenly across a 2D plane, forming an equilateral triangle 7. * Dimensionality 3/4: Features arrange into a three-dimensional tetrahedron 7. * Dimensionality 2/5: Five features distribute into a regular pentagon 717.
These geometric configurations demonstrate that superposition is a highly structured, mathematically rigorous strategy for minimizing mutual interference while maximizing the number of representable concepts 717.
Constructive Interference and Bag-of-Words Superposition
While idealized toy models assume that features are statistically independent, real-world datasets - such as the massive corpora of internet text ingested by frontier LLMs - are defined by highly correlated features 1819. Recent studies analyzing feature geometry in the context of realistic data statistics indicate that when features are correlated, interference ceases to be purely a detrimental noise source requiring ReLU filtration 18.
Researchers have documented the phenomenon of Bag-of-Words Superposition (BOWS), a regime in which networks leverage the covariance matrix of the training data to generate constructive interference 1819. If two features frequently co-occur (e.g., the concepts of "snow" and "cold"), the network places them in the activation space such that their vectors positively align 18. When an input contains both features, their respective projections constructively sum together, amplifying the true signal while naturally overwhelming the noise from unrelated features 18.
This reliance on constructive alignment allows the model to achieve highly efficient reconstructions of the data with lower weight norms and tighter rank requirements 18. Consequently, rather than forming isolated regular polytopes, correlated features in real LLMs form semantic clusters and cyclical structures that visually reflect their linguistic and contextual relationships 1820. These findings confirm that the standard geometric picture of superposition is dynamically modulated by the covariance statistics of the underlying dataset 18.
Alternative Origins: Necessary Compression versus Incidental Polysemanticity
The standard superposition hypothesis frames polysemanticity as an optimal, necessary solution to the problem of high-dimensional compression 35. However, an ongoing debate within the mechanistic interpretability community highlights an alternative paradigm: incidental polysemanticity 3321.
The classic superposition hypothesis - termed "necessary polysemanticity" - asserts that neurons become polysemantic exclusively because the network must compress a vast number of environmental features into a restrictive representational bottleneck 521. In contrast, research into incidental polysemanticity demonstrates that neurons can activate for multiple completely unrelated concepts even when the network possesses ample capacity to represent every single feature perfectly orthogonally 2122.
Incidental polysemanticity is an artifact of the network's training dynamics, specifically random initialization paired with winner-take-all optimization incentives 2122. At the beginning of the training process, neural weights are assigned randomly. Purely by stochastic chance, a single, uninitialized neuron may exhibit a slight mathematical correlation with two entirely unrelated, independent features within the dataset - for example, the visual concept of a "dog" and the concept of an "airplane" 521.
If the network utilizes regularization techniques that enforce sparsity, such as L1 regularization or dropout noise, the learning algorithm establishes a winner-take-all dynamic 2122. Instead of slowly building a new, dedicated neuron for the "airplane" feature, gradient descent simply amplifies the pre-existing, slightly advantageous correlation in the neuron that is already partially tracking the "dog" feature 521. Over thousands of training steps, this overlap becomes permanent.
The resulting polysemantic neuron is not a product of geometric optimization or a lack of capacity, but rather a historical accident cemented by gradient descent 521. Studies using toy models have shown that networks exhibiting incidental polysemanticity can achieve perfect task accuracy, indicating that this phenomenon does not inherently degrade performance, but severely damages the post-hoc interpretability of the model 22. This duality presents a profound challenge for interpretability researchers, as any attempt to reverse-engineer a network must distinguish between features compressed out of mathematical necessity and features entangled purely by the chaos of initialization.
| Polysemanticity Origin | Primary Mechanism | Capacity Condition | Implications for Interpretability |
|---|---|---|---|
| Necessary (Superposition) | Intentional packing of features into nearly-orthogonal vectors to maximize data coverage and representational efficiency. | Occurs strictly when the environment contains exponentially more features than the network possesses neurons. | Requires advanced dictionary learning (e.g., Sparse Autoencoders) to project the compressed vectors back into an interpretable overcomplete basis. |
| Incidental | Random initialization biases amplified by gradient descent, L1 regularization, dropout, and winner-take-all dynamics. | Can occur even when the network possesses ample neurons to represent all features perfectly monosemantically. | Suggests that some polysemanticity is an optimization artifact that could be prevented architecturally without sacrificing capacity, potentially through training interventions. |
The Complexity of Active Computation in Superposition
Much of the foundational literature surrounding superposition focuses on representational capacity - the ability of a network bottleneck to passively store and retrieve information without catastrophic data loss 233724. However, frontier AI systems do not merely store features; they actively perform complex non-linear operations, logical reasoning, and algorithmic transformations on the data 1639. Recent theoretical research demonstrates that computation in superposition operates under significantly stricter mathematical boundaries than passive representation 1610.
While the Johnson-Lindenstrauss lemma allows $n$ neurons to passively represent an exponential $2^{O(n)}$ number of features, active computation fundamentally shrinks this capacity 1610. When a neural network must ingest superimposed inputs and explicitly compute combinatorial logical outputs, the requisite parameter counts scale dramatically 3940.
Mathematical models investigating computation in superposition have focused on fundamental operations, such as emulating a Universal AND (U-AND) boolean circuit that computes the pairwise logical ANDs of a set of input features 39. Theoretical proofs establish that to compute $m'$ output features from superimposed inputs, a network fundamentally requires at least $\Omega(m' \log m')$ parameters and $\Omega(\sqrt{m' \log m'})$ neurons 1610.
Despite these stricter bounds, neural networks remain capable of sub-linear computation. Researchers have successfully constructed specific Multi-Layer Perceptron (MLP) architectures capable of emulating the U-AND circuit for $m$ features using roughly $\tilde{O}(m^{2/3})$ neurons, effectively processing the logical operations while the inputs remain heavily compressed in superposition 233739. Furthermore, deep fully-connected networks with a width of $d$ can emulate sparse boolean circuits with a width of $\tilde{O}(d^{1.5})$ across arbitrary polynomial depths 37. Crucially, probabilistic analysis confirms that randomly initialized networks are highly likely to naturally linearly represent these U-AND circuits if the network width is sufficiently large, suggesting that real-world models naturally discover and utilize these compressed computational pathways 2339.
These findings possess monumental implications for the interpretation of advanced AI systems. They formally define the "exponential gap" between simply encoding features and executing logical reasoning 1610.
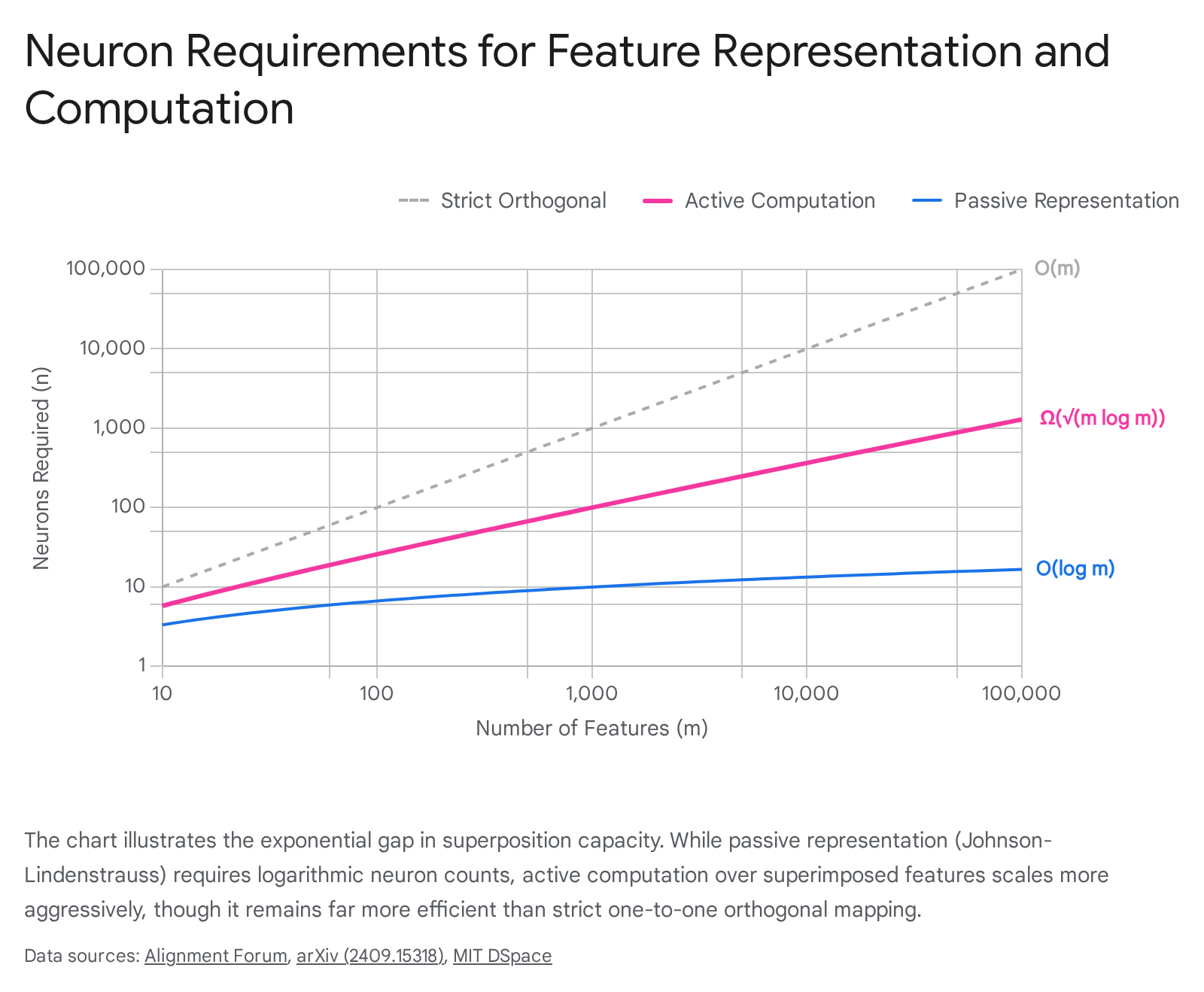
If researchers aim to quantify the true algorithmic capabilities of frontier LLMs, the total parameter count serves as a significantly tighter constraint on computational potential than the highly permissive bounds of passive representation 16.
Feature Disentanglement via Sparse Autoencoders
Because features exist in dense geometric superposition, analyzing the raw weights or activations of an LLM's internal layers yields an incomprehensible mixture of signals. To isolate distinct concepts, the mechanistic interpretability community has widely adopted dictionary learning techniques, predominantly utilizing Sparse Autoencoders (SAEs) 11441.
SAEs are a specialized neural architecture appended to the frozen, trained layers of a target model. Unlike classical autoencoders - which are conventionally utilized to compress high-dimensional data into a restrictive, lower-dimensional bottleneck - SAEs perform the inverse operation 614. An SAE takes the low-dimensional, highly polysemantic activations of an LLM layer and projects them outward into a massive, overcomplete hidden dimension 1. The objective is to reconstruct the original activation while strictly enforcing sparsity upon the overcomplete dimension.
This sparsity is typically achieved by incorporating an L1 regularization penalty ($\lambda \sum |w|$) into the autoencoder's loss function during training 614. The optimization process must balance reconstruction fidelity against the L1 penalty, forcing the SAE to activate only a sparse handful of its neurons for any given input token 611. This induced sparsity mirrors the theoretical sparsity of the natural data distribution that originally necessitated superposition. As a result, the SAE learns a vast dictionary of distinct vector directions, where each direction corresponds to a highly specific, monosemantic feature 14.
The application of SAEs has revolutionized the ability to map the internal cognitive state of frontier models. Major AI research institutions have successfully trained massive SAEs on state-of-the-art models, extracting tens of millions of distinct features from architectures like Claude 3 Sonnet and GPT-4 1141325. The extracted dictionaries encompass a vast semantic spectrum, ranging from basic syntactic detectors to abstract conceptual representations such as "Golden Gate Bridge," "social bias," "scam email drafting," and "deceptive language" 142543.
Furthermore, applying advanced representational similarity metrics (such as Singular Value Canonical Correlation Analysis) to SAE-extracted features has revealed significant evidence for "feature universality" 41. Feature universality implies that entirely different model architectures, such as Meta's Llama and Google's Gemma, independently converge on highly similar geometric representations for identical semantic concepts within their latent spaces 4144. However, researchers acknowledge that fully mapping the capabilities of frontier LLMs may eventually require SAEs scaled to billions or trillions of features, a computationally prohibitive threshold given current methodologies 1325.
Applications in Model Steering and Alignment
The extraction of monosemantic features via SAEs extends far beyond observational analysis; it provides a direct mechanism for causal intervention. By mapping specific conceptual features back to the model's original latent space, researchers can artificially manipulate the network's forward pass, a technique known as "activation steering" or "feature steering" 144345.
Hallucination Reduction and Query Enrichment
A highly promising application of SAE steering is the real-time mitigation of AI hallucinations. Both Large Language Models (LLMs) and Large Vision-Language Models (LVLMs) frequently generate plausible but factually incorrect assertions due to misaligned or entangled internal representations 44462648.
Recent developments, such as the Sparse Autoencoder-Based Framework for Robust Query Enrichment (SAFE), demonstrate the capacity of steering to refine inputs dynamically without retraining the base model. The SAFE architecture employs a two-stage process. First, it detects potential hallucinations during generation using entropy-based uncertainty estimation 4449. If high uncertainty is detected, the framework queries an attached SAE to extract semantically grounded, monosemantic features related to the input context. These features are utilized to enrich the query, actively steering the model toward relevant factual directions while suppressing extraneous, hallucination-inducing noise 4427. Empirical evaluations on benchmark QA datasets (e.g., TruthfulQA) confirm that SAFE significantly reduces hallucination rates, achieving response accuracy improvements of up to 29.45% 4449.
Similar interventions targeting multi-modal architectures - such as Contrastive Neuron Steering (CNS) and Steering LVLMs via SAE Latent Directions (SSL) - operate by identifying the specific SAE latents associated with "faithful" content versus "hallucinatory" content. By artificially amplifying the true visual directions and suppressing the spurious noise latents identified via the SAE, models demonstrate marked improvements in factual consistency regarding image inputs 2648.
Jailbreak Defense and the Capability Trade-Off
In the context of AI safety and alignment, SAE steering provides a powerful mechanism for enforcing behavioral guardrails. Safety interventions can identify the specific features that mediate a model's refusal behaviors when faced with harmful or malicious prompts 5152. By artificially clamping the activation values of these "refusal features" to high, static thresholds during inference, models become significantly more robust against sophisticated single-turn and multi-turn jailbreak attempts 5152.
However, manipulating features extracted from a heavily superimposed state introduces profound complexities regarding global model performance. Empirical research highlights a severe, fundamental trade-off between SAE-enforced safety steering and general computational capabilities 5152. In detailed evaluations using the Llama 3 8B architecture, researchers discovered that while steering specific refusal features (e.g., amplifying "Feature 9000" or suppressing "Feature 43692") improved safety metrics on Air Bench by 8.8% to 10.0%, these interventions triggered catastrophic capability degradation 28. Associated utility scores on benchmarks like AlpacaEval dropped precipitously (up to 16.3%), demonstrating systematic degradation in factual recall, logical reasoning, and general instruction-following, even on completely benign, non-harmful inputs 5228. This suggests that safety-relevant features remain deeply entangled with general linguistic capabilities within the superposition manifold, complicating isolated interventions 51.
Endogenous Steering Resistance
A secondary, highly complex challenge in feature steering is the phenomenon of Endogenous Steering Resistance (ESR), observed primarily in high-parameter frontier models. When researchers inject SAE latents to deliberately force a model off-topic or modify its personality traits, sufficiently large models demonstrate an innate, internal self-correction capability 54.
In targeted experiments on the 70-billion parameter Llama 3.3 model, the network successfully recognized the artificial activation shift generated by the steering vector. The model would halt its generation mid-sequence (e.g., generating text such as "wait, that's not right") and actively attempt to return to the original prompt trajectory, demonstrating an ESR success rate of 3.8% 54. Through SAE latent analysis, researchers identified 26 specific latents that fired differentially during this off-topic detection phase; zero-ablating these specific latents successfully reduced the model's self-correction rate by 25% 54.
While ESR serves as an excellent natural defense against malicious adversarial manipulation, it acts as a "double-edged sword" by actively resisting beneficial safety steering injected by researchers 54. If models naturally develop computational resistance to activation steering as they scale, the long-term viability of intervention-based alignment remains a critical and unresolved question for the mechanistic interpretability community.
Future Trajectories in Interpretability Research
The formalization of the superposition hypothesis has fundamentally redefined the scientific paradigm surrounding artificial neural networks. By demonstrating that models utilize the geometry of high-dimensional spaces to encode exponentially more features than they possess physical neurons, researchers have established a coherent, mathematical explanation for the deeply polysemantic nature of neural computation 39.
The field is currently experiencing a rapid theoretical expansion. The establishment of strict mathematical boundaries distinguishing the capacity for passive representation from the parameter requirements of active logical computation provides a rigorous framework for assessing network efficiency 161039. Simultaneously, the recognition that realistic, correlated data induces constructive interference and semantic clustering shifts the superposition hypothesis away from idealized, independent geometric models toward the practical realities of linguistic data statistics 18.
While Sparse Autoencoders have unlocked the unprecedented ability to disentangle superimposed features and map the cognitive architecture of models like GPT-4 and Claude 3, their practical application for steering remains constrained by architectural entanglement 132551. Moving forward, the discipline of mechanistic interpretability must reconcile the extraction of monosemantic features with the holistic capabilities of the network, ensuring that safety interventions can be targeted without degrading foundational reasoning capacity 5152. As frontier AI continues to scale, mastering the complex mechanics of superposition will be essential for ensuring that neural networks remain trustworthy, steerable, and fundamentally comprehensible to their human operators 229.