Subnetworks with performance equal to full neural networks
Fundamental Principles of Neural Network Overparameterization
In the optimization of deep neural networks, a longstanding paradox has defined architectural design: massive overparameterization is empirically necessary to successfully train models using stochastic gradient descent (SGD), yet the final converged models can routinely be pruned of 90% or more of their parameters without any degradation in predictive performance 12. This phenomenon suggests that the vast majority of network capacity is required solely to navigate the optimization landscape rather than to represent the final learned function.
In 2018, Jonathan Frankle and Michael Carbin proposed the Lottery Ticket Hypothesis (LTH) to resolve this contradiction. The hypothesis formally conjectures that dense, randomly-initialized, feed-forward neural networks contain sparse subnetworks - termed "winning tickets" - that, when trained in isolation, can match or exceed the test accuracy of the original dense network after training for at most the same number of iterations 1345.
The hypothesis reframes a dense neural network as a vast ensemble of randomly initialized sparse subnetworks. The success of dense training relies on the combinatorial probability that at least one of these subnetworks is fortuitously initialized in a configuration highly aligned with the data and the loss landscape's gradient pathways 124. Consequently, optimization descends into a robust, wide minimum primarily due to the starting coordinates of this specific subnetwork. A critical corollary of the hypothesis is the importance of the original initialization geometry: if the structural architecture of a winning ticket is extracted but its weights are randomly re-initialized, the subnetwork typically fails to train effectively or converges to an inferior accuracy 145. This indicates that architectural sparsity alone does not constitute a winning ticket; the precise interplay between the topological connection graph and the specific initial weight values is what grants the subnetwork its optimization superiority.
Mechanics of Iterative Magnitude Pruning and Weight Rewinding
The canonical algorithmic mechanism for identifying winning tickets is Iterative Magnitude Pruning (IMP) combined with weight rewinding. While one-shot magnitude pruning - training a network to convergence and severing a large percentage of the lowest magnitude weights in a single operation - can uncover functional subnetworks at moderate sparsity levels, it generally fails at extreme sparsities. IMP discovers substantially smaller and more accurate winning tickets by allowing the remaining parameters to gradually adapt to the structural reduction 576.
The standard Iterative Magnitude Pruning process operates through a strict cyclical reduction. Initially, a dense neural network is established with random weights. The network is trained to convergence, and parameter importance is subsequently calculated, universally evaluated by the absolute magnitude of the converged weights. A specific fraction of the least important parameters (typically 10% to 20%) is pruned via a binary sparsity mask. Rather than continuing fine-tuning from the converged state, the critical step involves applying this binary mask to the original initialization state of the network. This action effectively "rewinds" the surviving connections back to their exact starting values at epoch zero. The sparse network is then retrained from this rewound state. This cycle of training, pruning, masking, and rewinding is repeated sequentially until the target sparsity threshold is achieved 57.
Subsequent research refined the IMP procedure upon discovering that for highly complex architectures (such as ResNet-50) trained on large-scale datasets (such as ImageNet), rewinding strictly to epoch zero could induce optimization instability 7. To counteract this, researchers introduced "Lottery Ticket Rewinding" (LTR) and "Learning Rate Rewinding" (LRR). Instead of reverting weights to absolute initialization, LTR rewinds the unpruned weights to values obtained after a very small number of training steps (e.g., epoch 2 or 5) 278.
This phenomenon uncovered the existence of "early-bird" tickets, which emerge when the winning ticket configuration stabilizes within the first 10% to 20% of training epochs, bypassing the highly chaotic initial phase of optimization 2. Instability analyses reveal that these matched subnetworks exhibit linear mode connectivity; the error barrier between the initialization and the converged state remains below a specified noise threshold, allowing the subnetwork to stably navigate the loss landscape 7. Furthermore, topological analyses utilizing neural persistence - a metric based on persistent homology - demonstrate that IMP effectively preserves the zeroth-dimensional topological features of the trained network throughout the pruning process, guaranteeing that the fundamental information pathways are retained 9.
The Strong Lottery Ticket Hypothesis
While the standard LTH relies on the iterative training of the discovered subnetwork, the Strong Lottery Ticket Hypothesis (SLTH) postulates a far more radical condition: within a sufficiently overparameterized, randomly initialized neural network, there exists a subnetwork capable of approximating a target function with high accuracy without any weight training or gradient updates 101112.
Initially observed empirically through heuristic algorithms like Edge-Popup, the SLTH was subsequently established mathematically. The proofs demonstrate that if the size of the dense candidate network scales polynomially relative to the target network's width and depth, a "supermask" can be identified that simply selects the correct random weights to construct a highly accurate model 1011. By leveraging weight decomposition and the subset sum problem, the overparameterization requirement was later reduced from polynomial to a logarithmic factor times the size of the target network 1011.
The implications of the SLTH are profound, suggesting that the parameter spaces of randomly initialized wide networks are so exceptionally dense with varied configurations that optimization via gradient descent can theoretically be replaced entirely by combinatorial subnetwork selection. The SLTH has since been proven to hold across diverse functional families, including convolutional neural networks (CNNs) and general $G$-equivariant networks 1213. Extended variations, such as the Multi-Prize Lottery Ticket Hypothesis, provide evidence that these untrained, highly accurate subnetworks are also structurally robust to extreme quantization regimes, such as binary weight representations, making them exceptionally valuable for deployment in low-power edge computing environments 16.
Pruning at Initialization and Dynamic Sparse Training
Despite its theoretical importance, identifying winning tickets via IMP is computationally exorbitant. Discovering a ticket at 95% sparsity may require training the network to convergence dozens of times. To transition the hypothesis from an analytical framework to a practical acceleration tool, researchers have developed algorithms aimed at discovering sparse networks either prior to training or dynamically during the training process.
Saliency Criteria for Pruning at Initialization
Pruning at Initialization (PaI) methods attempt to score and select parameters before a single optimization step is fully completed, allowing the model to train sparsely from the outset. Various mathematical criteria have been proposed to predict which weights will ultimately form the winning ticket.
| Algorithm | Scoring Criterion | Mathematical Formulation | Core Rationale |
|---|---|---|---|
| SNIP | Connection Sensitivity | $ | \nabla_w L \odot w |
| GraSP | Gradient Signal Preservation | $-H \nabla_w L \odot w$ | Uses Hessian-vector products to prune weights that minimally disrupt training dynamics and gradient flow. 815 |
| SynFlow | Synaptic Flow (Path Norm) | Iterative L1 Path Norm | A data-independent metric preventing layer-collapse by conserving synaptic flow across layers. 141516 |
While computationally efficient, standard PaI heuristics rely heavily on first-order saliency metrics that frequently ignore complex inter-weight dependencies. Consequently, they suffer from a measurable accuracy-sparsity trade-off compared to LTR and IMP 81718. Furthermore, PaI methods routinely fail basic empirical sanity checks; for instance, randomly shuffling the pruning mask within each layer often preserves or even improves accuracy, indicating that the per-weight pruning decisions made by SNIP or GraSP may not actually capture precise ticket topologies 817.
To rectify the shortcomings of saliency-based PaI, advanced combinatorial approaches like Concrete Ticket Search (CTS) reframe early subnetwork discovery as a holistic optimization problem. By applying a continuous relaxation to the discrete mask search space and minimizing the reverse Kullback-Leibler (KL) divergence between sparse and dense network outputs, CTS identifies subnetworks that robustly pass sanity checks. In empirical evaluations on ResNet-20, CTS achieves 74.0% accuracy at 99.3% sparsity in under eight minutes, substantially outperforming LTR protocols that require significantly greater computational time to reach equivalent performance 1718.
Dynamic Sparse Training Paradigms
As an alternative to static initialization masks, Dynamic Sparse Training (DST) methodologies continuously alter the network's sparse topology during the training phase. The Rigged Lottery (RigL) algorithm maintains a fixed global parameter count throughout optimization. At regular intervals, RigL removes the connections possessing the smallest magnitudes while simultaneously activating new connections exhibiting the largest instantaneous gradients. This dynamic reassessment allows the network to correct suboptimal early pruning decisions, yielding state-of-the-art accuracy profiles for highly sparse architectures 1419.
Similarly, the Continuous Sparsification framework integrates topological pruning directly into the objective function. By utilizing a continuous mathematical approximation of the non-differentiable $L_0$ regularization penalty, this method simultaneously optimizes both the weight values and the sparse network structure via gradient descent. Empirical results indicate that Continuous Sparsification surpasses conventional IMP in identifying high-performance subnetworks, while operating up to five times faster in parallel search configurations 2021.
Application to Large Language Models and Foundation Architectures
As the machine learning domain shifted from computer vision specific models to massive transformer-based foundation architectures, researchers sought to verify if the Lottery Ticket Hypothesis scales effectively to Large Language Models (LLMs).
Investigations into pre-trained BERT networks revealed that matching subnetworks exist reliably at 40% to 90% sparsity levels 2223. A critical deviation from prior LTH research is that in the context of foundation models, these winning tickets emerge at the pre-trained initialization rather than from a completely random initialization state 2223. Winning tickets identified by training against the Masked Language Modeling (MLM) objective - the core self-supervised task used to pre-train the dense model - exhibit "universal" transferability. These specific subnetworks maintain their efficacy and seamlessly transfer to a wide range of downstream Natural Language Understanding tasks, whereas tickets found via task-specific downstream fine-tuning transfer in a highly limited fashion 2223.
Multilingual Transfer via KS-Lottery
The hypothesis has also been instrumental in refining specific architectural components, such as embedding layers, to facilitate efficient multilingual transfer. LLMs generally perform well on high-resource languages but falter on low-resource linguistic distributions due to insufficient pre-training data. Expanding vocabulary efficiently is a persistent challenge.
The KS-Lottery algorithm applies the hypothesis directly to vocabulary expansion by utilizing the Kolmogorov-Smirnov (KS) Test to analyze the statistical distribution shifts of parameters before and after fine-tuning. This mathematically rigorous approach identifies certified winning tickets specifically within the token embedding layers. Researchers discovered an extraordinary degree of parameter redundancy in multilingual adaptation: fine-tuning a highly sparse subnetwork comprising merely 18 token embeddings in a LLaMA architecture is completely sufficient to achieve cross-lingual translation performance comparable to full model fine-tuning 242526.
Lottery Ticket Adaptation and Catastrophic Forgetting
In the current era of multi-task instruction tuning, adapting a single LLM to diverse new tasks frequently induces destructive interference. Methods that optimize all model weights simultaneously suffer from catastrophic forgetting, where the acquisition of a new skill (e.g., mathematical reasoning) overwrites the network's proficiency in previously learned capabilities (e.g., general instruction following) 2728.
The Lottery Ticket Adaptation (LoTA) framework applies sparse ticket search to directly mitigate this destructive interference. Rather than updating the full parameter space, LoTA conducts mask calibration to compute weight differentials, extracting a sparse "task vector" - a dedicated subnetwork representing the isolated adaptations required for a specific task. By reverting the majority of the model weights to their pre-trained state and fine-tuning only the highly sparse subnetwork (often at 90% sparsity), LoTA cordons off task-specific knowledge into non-overlapping parameter subsets 272829.
Extensive evaluations across reasoning, mathematics, coding, and summarization benchmarks demonstrate that LoTA rivals the performance of Full Fine-Tuning (FFT) and substantially outperforms conventional parameter-efficient techniques like Low-Rank Adaptation (LoRA) 272930.
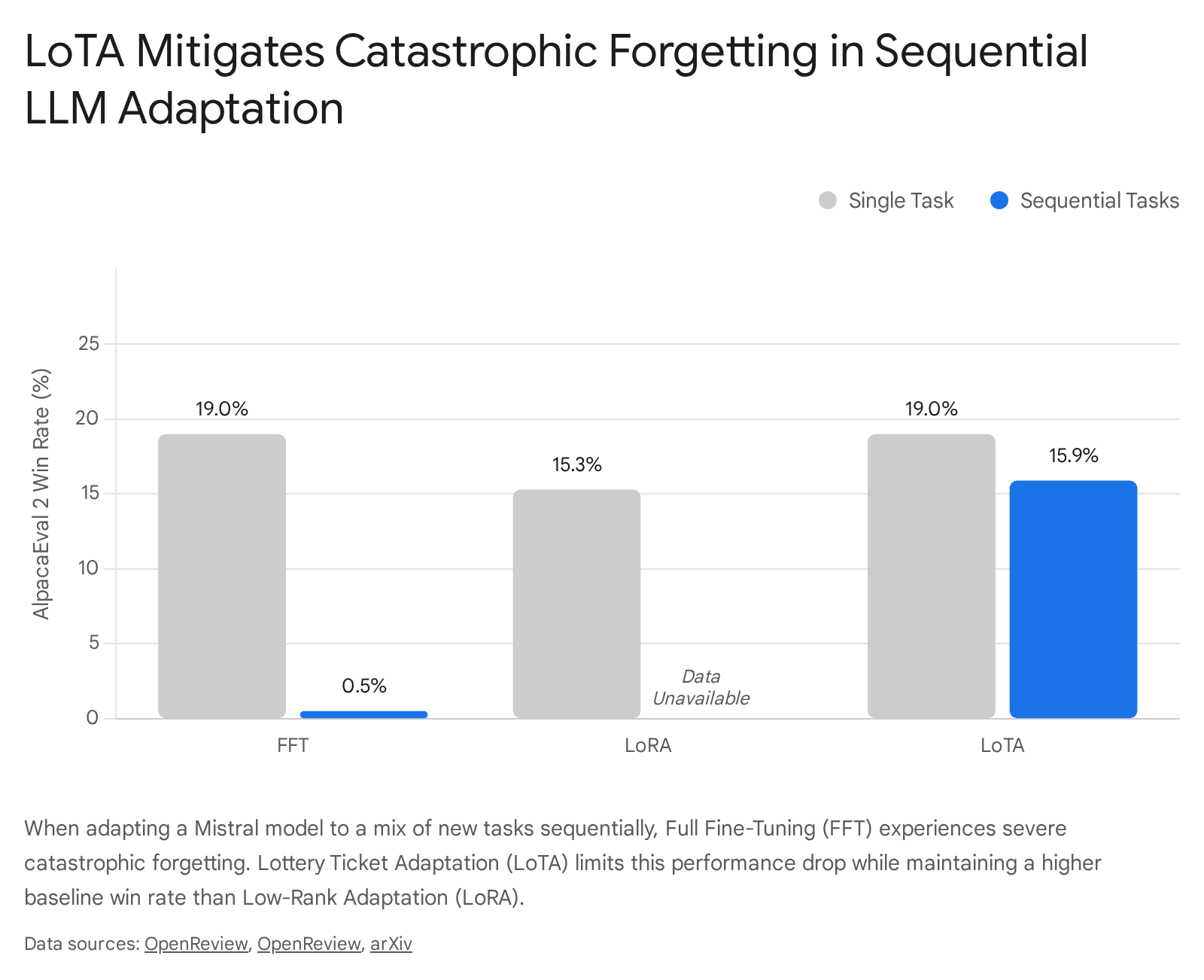
Beyond sequential adaptation, the extraction of sparse task vectors enables superior parallel model merging. While merging dense models across highly dissimilar tasks typically degrades performance due to parameter collisions, LoTA's naturally sparse task vectors are mutually sparse, preventing interference and allowing for robust multi-task unified models 272931.
Sparse Subnetworks in Low-Rank Adapters
As the computational burden of fine-tuning foundational models continues to expand, Parameter-Efficient Fine-Tuning (PEFT) methods - most notably LoRA - have become the industry standard. LoRA fine-tunes models by injecting trainable low-rank parameter matrices into the transformer layers. However, baseline LoRA architectures unnecessarily update entire parameter blocks, even when only highly specific task-relevant subspaces require adjustment 3233.
Recent investigations into PEFT mechanics have confirmed that the Lottery Ticket Hypothesis extends directly into low-rank adapters 3234. The "Partial-LoRA" methodology demonstrates that "winning tickets" exist within LoRA modules, where adapters randomly pruned to a task-specific sparsity can achieve identical or superior performance to fully dense adapters 33.
Crucially, researchers found that the success of these sparse adapter subnetworks relies less on the exact weights included in the mask and more heavily on the appropriate sparsity ratio applied to each individual layer. By systematically identifying task-relevant subspaces aligned with the pre-trained weights and applying random masking based on derived sparsity ratios, Partial-LoRA reduces the number of trainable parameters by up to 87% compared to dense LoRA baselines 323435. This validation of LTH principles inside PEFT structures provides a strict theoretical foundation for designing highly sparse, ultra-efficient fine-tuning regimes.
Hardware Constraints and Structured Sparsity
A persistent bottleneck in translating the theoretical parameter reduction of the Lottery Ticket Hypothesis into empirical wall-clock acceleration is a systemic phenomenon termed the "Hardware Lottery." This concept formalizes the observation that the success and adoption of algorithmic research is heavily gated by its structural alignment with prevailing hardware architectures, such as contemporary GPUs and Tensor Processing Units (TPUs) 40.
The sparsity patterns traditionally generated by Iterative Magnitude Pruning and unstructured PaI algorithms are inherently irregular. They eliminate individual weights strictly by magnitude, without regard to the dense, contiguous matrices that hardware accelerators are heavily optimized to process. Consequently, while removing 90% to 95% of the weights in an unstructured manner dramatically decreases theoretical Floating Point Operations (FLOPs), it delivers negligible practical inference speedups and minimal memory bandwidth savings unless executed on highly specialized, custom Application-Specific Integrated Circuits (ASICs) designed explicitly for sparse matrix-vector multiplication 4036.
To circumvent this hardware roadblock, researchers have actively pivoted toward discovering Structured Lottery Tickets. Instead of permitting purely unstructured element removal, advanced methodologies append post-processing techniques to the IMP cycle to enforce hardware-friendly structural topologies.
| Sparsity Pattern | Topology Characteristics | Hardware Acceleration Viability |
|---|---|---|
| Unstructured | Irregular, element-wise zeroing based on magnitude. | Low. Requires specialized sparse compilers or custom ASICs. |
| Channel-wise | Entire feature channels or filters are completely removed. | High. Naturally accelerates on standard GPUs via smaller dense matrices. |
| N:M (Block-wise) | Exactly N non-zero weights per block of M parameters. | High. Natively supported by modern GPU tensor cores (e.g., NVIDIA Ampere 2:4 sparsity). |
By systematically "re-filling" pruned elements within critical dense channels and subsequently "re-grouping" non-zero weights to conform to flexible group-wise structural patterns, structural ticket discovery algorithms successfully identify winning tickets that comply with modern hardware constraints. Empirical benchmarks demonstrate that these structurally constrained subnetworks achieve inference speedups of approximately 60% on standard GPU hardware at 50% to 80% sparsity levels, while seamlessly preserving the accuracy baselines established by their dense counterparts 3637.
Generative Weight Models and Bayesian Approaches
Looking toward the horizon of optimization research, the methodologies surrounding the Lottery Ticket Hypothesis are evolving from costly iterative discovery protocols toward direct weight generation and probabilistic modeling.
The conventional LTH paradigm mandates iterating through massive training datasets merely to locate the winning ticket's geometric topology. A disruptive alternative, DeepWeightFlow, circumvents this optimization bottleneck entirely by treating trained neural network weights as samples originating from an underlying high-dimensional continuous distribution. Operating directly in the parameter space via Flow Matching architectures, DeepWeightFlow learns the generative dynamics of functional network weights 3839.
To overcome the challenges posed by neural network permutation symmetries - where identical functions can be represented by vastly different parameter arrays - the model utilizes TransFusion and Git Re-Basin for structural canonicalization 383940. By employing Principal Component Analysis (PCA) for tractability, DeepWeightFlow scales effectively to architectures containing up to 100 million parameters. The resulting system can generate diverse, high-accuracy ensembles of complete neural networks in a matter of minutes, vastly outperforming diffusion-based counterparts and eliminating the necessity for fine-tuning or iterative pruning search 383940.
Concurrently, the principles of the LTH have been mapped onto Bayesian Neural Networks (BNNs). While BNNs are essential for rigorous uncertainty quantification in safety-critical applications, they are notoriously resource-intensive. Recent studies verify that Bayesian winning tickets exist reliably and independently of the model size, yielding sparse probabilistic networks that drastically reduce computational demands during both posterior approximation and inference 4142. In the Bayesian context, empirical evaluations indicate that optimal ticket discovery strategies must prioritize standard weight magnitude first, supplemented by standard deviation metrics, indicating that the loss landscapes traversed by Bayesian networks contain structurally analogous basins of attraction to deterministic models 4142.
Through its evolution from an intriguing phenomenon in small-scale image classification to a foundational architectural principle governing LLM parameter-efficient adaptation, structured hardware co-design, and generative weight modeling, the Lottery Ticket Hypothesis continues to redefine the theoretical limits of efficient deep learning parameterization.