State space models and Mamba for long sequence modeling
Introduction: The Architectural Crossroads of Sequence Modeling
For the better part of the past decade, the Transformer architecture has served as the undisputed mathematical engine of the artificial intelligence revolution. Driven primarily by the self-attention mechanism, Transformers have achieved unprecedented success across natural language processing, computer vision, computational biology, and multimodal reasoning 12. However, the foundational mathematics of self-attention carry a severe computational penalty: a time and space complexity that scales quadratically with the length of the input sequence. As the demand for models capable of processing entire books, hour-long high-definition videos, and exhaustive genomic sequences has surged, this quadratic scaling has created an almost insurmountable memory wall, colloquially known within the machine learning community as the Key-Value (KV) cache bottleneck 342. The quadratic growth of the attention matrix means that every new token generated requires the model to compute its relationship against every preceding token, leading to exponential increases in computational cost and memory allocation 36.
To circumvent these computational limits, researchers began exploring alternative mathematical paradigms that could offer the parallel training efficiency of Transformers while restoring the constant-time inference complexity of legacy Recurrent Neural Networks (RNNs). This search led to the renaissance of State Space Models (SSMs). Rooted in classical control theory and continuous-time signal processing, SSMs possess the unique ability to compress sequence histories into a fixed-size hidden state, theoretically allowing for infinite context windows with linear computational scaling 73. The release of the Mamba architecture by researchers at Carnegie Mellon University and Princeton University marked a watershed moment in this pursuit, introducing a novel "selective scan" mechanism that allowed the model to dynamically filter information based on the input 94.
However, the rapid iteration from Mamba-1 to Mamba-2, and subsequently to complex hybrid architectures, reveals a highly nuanced reality. While Mamba achieves remarkable throughput and memory efficiency, it is not the monolithic replacement for attention that early hyperbolic discourse suggested. Instead, theoretical constraints regarding associative recall - often termed the "copying problem" - have catalyzed a profound architectural shift toward sophisticated hybrid models 115. These models strategically interleave SSM layers with attention and Mixture-of-Experts (MoE) mechanisms, acknowledging that linear scaling and perfect recall represent an inherent trade-off 131415.
This comprehensive research report provides an exhaustive, expert-level analysis of the state space model ecosystem. It details the theoretical underpinnings of Mamba-2's State Space Duality (SSD), dissects the hardware-aware memory optimizations of parallel scans concerning SRAM and HBM hierarchies, demystifies the limitations of pure SSMs in random-access retrieval, and explores the global, decentralized research landscape. By examining contributions from major Western laboratories like Cartesia, AI21, and Stanford alongside pioneering non-Western institutions in the United Arab Emirates, China, and South Korea, this document outlines the trajectory of sequence modeling beyond the quadratic bottleneck.
The Mathematical Evolution: From Traditional SSMs to Selective Spaces
To thoroughly appreciate the breakthrough represented by Mamba, one must first examine the mathematical limitations of traditional state space models, such as the widely studied S4 architecture. Classical SSMs model a continuous-time sequence by mapping a one-dimensional input signal to a hidden state via a transition matrix, and subsequently mapping that hidden state to an output via projection matrices 36.
When discretized for digital computation in machine learning hardware, the continuous-time ordinary differential equations are converted into discrete recurrence relations. The SSM updates the hidden state sequentially by multiplying the previous state by a discretized transition matrix and adding the current input multiplied by a continuous-to-discrete projection matrix. Finally, the output is generated by multiplying the hidden state by a separate observation matrix 36.
In traditional SSMs, these state-space matrices are entirely independent of the input data sequence. This time-invariant structure is highly advantageous for training because it allows the entire sequential operation to be mathematically unrolled and computed as a global convolution using Fast Fourier Transforms (FFTs) 12. This convolutional property enables highly efficient, parallelized training across massive datasets. However, because the parameters do not change based on the specific data they are processing, traditional SSMs operate as rigid linear filters. They lack "selectivity," meaning they cannot dynamically choose to remember a critical piece of context or forget a redundant, uninformative token 26. This lack of context-awareness severely hindered their performance on complex language modeling tasks compared to the dynamic routing capabilities of self-attention 16.
The Mamba-1 Innovation: Input-Dependent Selectivity
The original Mamba architecture, frequently referred to in the literature as S6, resolved the expressivity deficit of traditional SSMs by making the parameters time-varying and input-dependent 97. By allowing the model to adapt its state transition and projection matrices based on the current token, Mamba gained the ability to selectively filter information. If the model encounters an important noun, the input-dependent parameters can trigger an update that strongly writes to the hidden state; conversely, if it encounters a stop-word or punctuation, the parameters can effectively bypass the update, preserving the historical context 418.
However, introducing time-varying, input-dependent parameters fundamentally destroyed the ability to compute the model using efficient global convolutions 2. Without the convolutional property, researchers were forced to compute the model as a sequential recurrence. A naive recurrent implementation requires the processing of step two to wait for the completion of step one, a sequential dependency that is unacceptably slow for training on modern parallelized hardware accelerators 19. This threatened to render the selective SSM theoretically powerful but practically unusable for large-scale pretraining.
Breaking the Memory Wall: Hardware-Aware Parallel Scans
To solve the computational bottleneck caused by the loss of convolutional parallelism, the authors of Mamba engineered a highly specialized "hardware-aware parallel scan" algorithm. Understanding the brilliance of this algorithm requires an analysis of the physical memory hierarchy of modern Graphics Processing Units (GPUs) and the mechanics of the von Neumann bottleneck 196.
A modern GPU's memory architecture is divided into distinct domains characterized by inverse relationships between capacity and speed. The primary domain is High Bandwidth Memory (HBM). This is the massive pool of memory where the model's billions of parameter weights and the entire input sequence data are stored. While HBM is vast in capacity, physically moving data in and out of it is relatively slow and consumes significant electrical energy. Conversely, Static Random-Access Memory (SRAM) constitutes a tiny pool of memory physically located directly next to the computing cores (often referred to as L1/L2 caches or shared memory). SRAM is incredibly fast, operating at the clock speed of the processors, but its capacity is severely limited 619.
In standard, unoptimized neural network operations, the GPU repeatedly shuttles data back and forth between the slow HBM and the fast SRAM for every mathematical step of the sequence. The processor loads the previous hidden state and the current input from HBM to SRAM, computes the new hidden state, writes the new state back to HBM, and then repeats the cycle for the next token. For long sequences, this constant shuttling causes an extreme Input/Output (IO) bottleneck. The hyper-fast computing cores sit idle, starved for data, while waiting for the slow HBM transfers to complete 619.
Mamba's hardware-aware parallel scan bypasses this IO bottleneck entirely through a technique known as kernel fusion. Instead of moving data back and forth for every step of the sequence, the algorithm loads the input-dependent parameters and a large chunk of the input sequence from the slow HBM into the ultra-fast SRAM only once 26. It then performs the entire recurrent state update for that chunk entirely within the physical confines of the SRAM. Because the hidden state is updated continuously in the fast local memory without being written back to the slow global memory at every intermediate step, the GPU's computing cores can run at maximum theoretical efficiency. Only the final output sequence is written back out to the HBM 28.
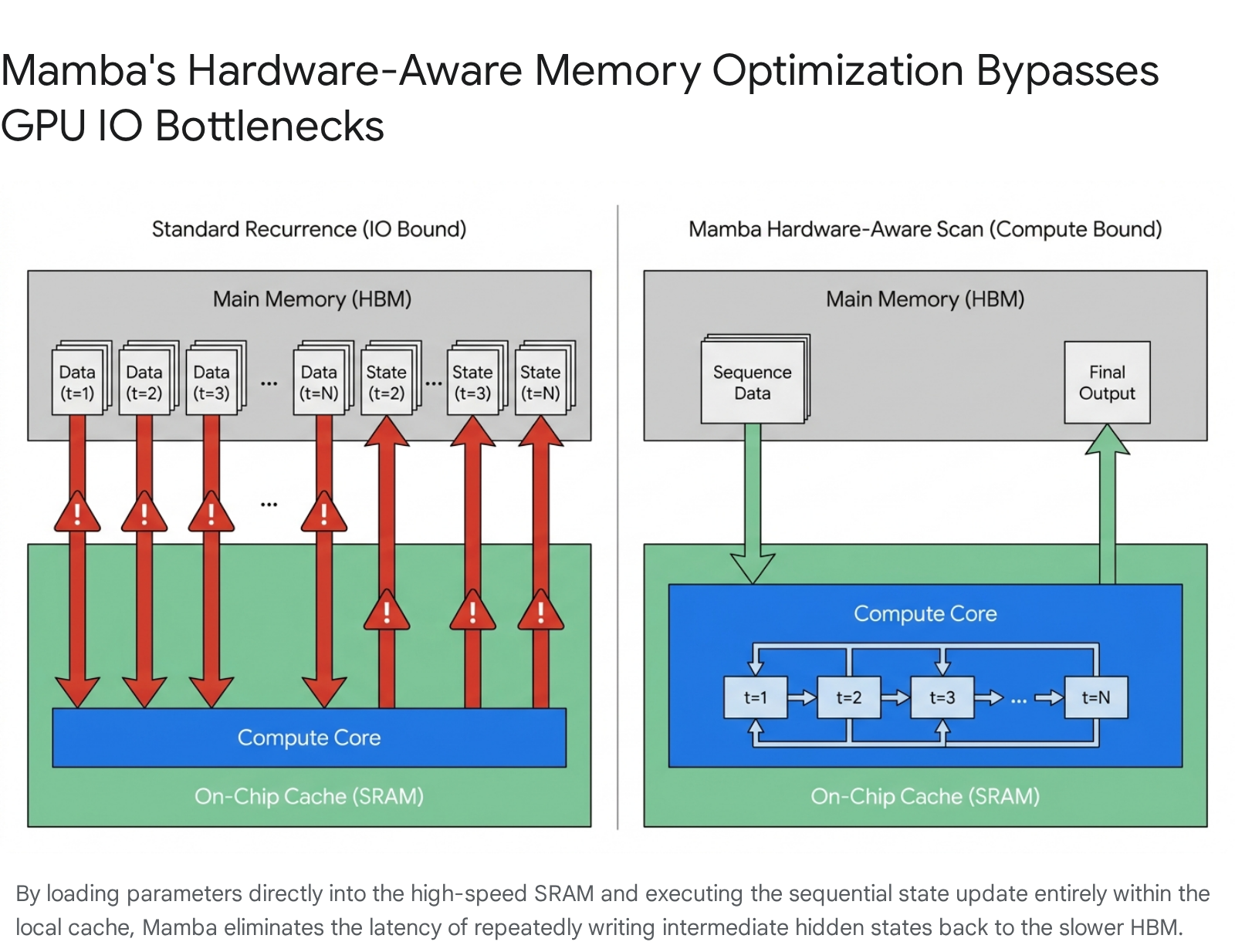
This fusion of operations allows Mamba to achieve the training speed of highly parallelized Transformers while simultaneously maintaining the linear memory footprint of a classical RNN, firmly establishing its viability as a foundation model backbone for extreme-length sequences.
Mamba-2 and the Revelation of State Space Duality (SSD)
Despite the profound empirical success of Mamba-1, its selective scan algorithm possessed architectural limitations. It relied on highly customized CUDA kernels that, while avoiding the IO bottleneck, could not natively leverage the massive matrix multiplication units (Tensor Cores) built into modern GPUs 8922. Furthermore, the original Mamba design remained mathematically segregated from the dominant attention mechanism paradigm, making it difficult for researchers to apply the vast ecosystem of Transformer-based systems optimizations to the new architecture 2210.
In mid-2024, researchers Tri Dao and Albert Gu published an extensive theoretical framework that resolved these underlying issues, culminating in the release of Mamba-2. The core of this advancement is the mathematical proof of Structured State Space Duality (SSD) 724. SSD is a profound conceptual bridge demonstrating that structured state-space models and specific forms of linear self-attention are, in fact, two representations of the exact same underlying mathematical operation, united by specific matrix decompositions 1025.
The Mathematics of Duality
To bridge the gap between continuous state spaces and discrete attention mechanisms, the authors of Mamba-2 imposed a strategic structural restriction on the transition matrix governing the hidden state. In Mamba-1, the transition matrix was structured diagonally. In Mamba-2's SSD layer, this matrix is simplified further into a "scalar-times-identity" format 711. By enforcing this specific scalar structure, the evolution of the hidden state across a sequence can be represented mathematically as a 1-semiseparable matrix 71025.
In advanced linear algebra, a semiseparable matrix contains blocks of data that can be efficiently decomposed and factored into smaller sub-components 25. Dao and Gu proved that when sequence modeling is expressed via these structured semiseparable matrices, the exact same mathematical output can be achieved through two distinct computational pathways: 1. The Primal Form (SSM Mode): Solving the equation as a sequential linear recurrence, which guarantees constant memory usage and linear scaling during autoregressive inference 181127. 2. The Dual Form (Attention Mode): Solving the equation via block decomposition and matrix multiplication, which heavily resembles the quadratic operations of self-attention but operates on compressed structured matrices 182511.
Systems Optimizations and Tensor Core Acceleration
The implications of State Space Duality extend far beyond theoretical elegance; they fundamentally alter how the sequence model interacts with silicon hardware. By utilizing the "Dual Form" during the training phase, Mamba-2 translates the traditionally sequential SSM operations into massive block matrix multiplications 89. Because modern GPUs (such as NVIDIA's H100) are explicitly engineered to perform matrix multiplications at extraordinary speeds via Tensor Cores, Mamba-2 achieves training throughputs between two and eight times faster than Mamba-1 1912.
Furthermore, the architectural restructuring in Mamba-2 enables profound systems-level optimizations. In Mamba-1, some of the input-dependent parameters were functions of the inner activations of the layer itself, meaning they had to be computed sequentially. In Mamba-2, utilizing a parallel projection structure, all sequence parameters are generated as functions of the initial input to the layer in parallel 82213. This shift allows Mamba-2 to seamlessly adopt the standard distributed training toolkit developed over years for Transformers: * Tensor Parallelism (TP): Distributing a single neural network layer across multiple GPUs requires constant synchronization. Mamba-1 required two costly all-reduce communication operations per layer. By altering the projection matrices and utilizing grouped normalization, Mamba-2 reduces the required synchronizations to just one all-reduce per layer, halving the communication overhead across massive GPU clusters 813. * Sequence Parallelism (SP): The model can easily split astronomical context lengths along the sequence dimension and assign different segments to different devices using context parallelism techniques directly analogous to Ring Attention 813.
As a direct result of these immense efficiency gains and the shift to block matrix multiplication, Mamba-2 can support significantly larger state dimensions without suffering computational slowdowns. Where Mamba-1 was tightly constrained to a state dimension of sixteen, Mamba-2 routinely operates with state dimensions of sixty-four, one hundred and twenty-eight, or even two hundred and fifty-six, drastically increasing the model's capacity to store complex semantic representations within its hidden state 18811.
Comparative Complexity Analysis
To comprehensively quantify the architectural shifts defining the sequence modeling landscape, the following table details the formal time and space complexity profiles (using Big $\mathcal{O}$ notation) of standard Transformers, traditional SSMs, Mamba-1, and Mamba-2.
| Architecture | Training Time Complexity | Training Space Complexity | Inference Time (per token) | Inference Space (Memory) | Dominant Mathematical Paradigm |
|---|---|---|---|---|---|
| Transformer | $\mathcal{O}(L^2 \cdot d)$ | $\mathcal{O}(L^2)$ | $\mathcal{O}(L \cdot d^2)$ | $\mathcal{O}(L \cdot d)$ | Global Self-Attention (Quadratic Scaling) |
| Traditional SSM | $\mathcal{O}(L \log L \cdot d)$ | $\mathcal{O}(L \cdot d)$ | $\mathcal{O}(1)$ | $\mathcal{O}(N \cdot d)$ | Fast Fourier Transform (Global Convolution) |
| Mamba-1 | $\mathcal{O}(L \cdot N \cdot d)$ | $\mathcal{O}(L \cdot d)$ | $\mathcal{O}(1)$ | $\mathcal{O}(N \cdot d)$ | Hardware-Aware Selective Scan (Custom CUDA) |
| Mamba-2 (SSD) | $\mathcal{O}(L \cdot d)$* | $\mathcal{O}(L \cdot d)$ | $\mathcal{O}(1)$ | $\mathcal{O}(N \cdot d)$ | Semiseparable Matrix Multiplication (Tensor Core) |
Complexity Contextualization: In the above table, $L$ represents the sequence length, $d$ represents the model's hidden dimension, and $N$ represents the state dimension of the SSM. The critical differentiator is found in inference time: while Transformers require computing over a growing KV cache causing $\mathcal{O}(L \cdot d^2)$ slowdowns as context increases, all SSM variants maintain a constant $\mathcal{O}(1)$ time complexity per generated token 12712. Mamba-2 achieves its highly optimized $\mathcal{O}(L \cdot d)$ training scaling via block decomposition matrix multiplications that fully leverage hardware Tensor Cores, effectively masking the $\mathcal{O}(N)$ overhead present in Mamba-1's selective scan during high-throughput parallel operations 1712.
The "Transformer Killer" Misconception: Unpacking the Copying Problem
Following the initial release of the Mamba architecture, aggressive speculation within the broader technology sector positioned state space models as absolute replacements for the Transformer architecture. However, rigorous empirical testing and geometric diagnostics - most notably by Jelassi et al. and the computational linguistics community - have demonstrated that pure SSMs possess fundamental cognitive blind spots that prevent them from fully displacing attention mechanisms 514.
To evaluate sequence architectures objectively, researchers decompose the process of computational inference into three core functional primitives: 1. Accumulation: The fundamental ability to gather static sufficient statistics over time (a primitive achievable by relatively simple Long Short-Term Memory networks, or LSTMs). 2. Transport: The ability to move, update, and route beliefs dynamically based on evolving context. This is where Mamba truly excels, achieving state-of-the-art results on continuous tracking tasks like Hidden Markov Model filtering 514. 3. Random-Access Binding: The ability to retrieve stored hypotheses and exact data points by their content rather than their position in a sequence 514.
Transformers realize all three primitives effortlessly. When a Transformer is probed for a highly specific piece of information from one hundred thousand tokens ago, its self-attention mechanism executes an exact, uncompressed matching operation. The current "Query" vector calculates a dot-product against every historical "Key" vector, identifying the highest correlation and extracting the exact "Value" with lossless precision 531. Because the Transformer stores the entire explicit history in its KV cache, its memory is perfect.
Mamba, conversely, must aggressively compress the entire sequence history into a finite, fixed-size state vector at each step 45. This mechanism is unparalleled for efficiently tracking evolving narratives, fluid contexts, or smooth continuous signals. However, it inherently suffers from irreversible information loss. When faced with an "Associative Recall" task - often referred to in the literature as the Copying Problem - Mamba's architecture falters 532. If the model must extract a highly specific, rare exact string (such as a specific phone number, a specialized technical term, or a randomly generated identifier buried deep within a massive document), the compressed hidden state may no longer retain the exact sequence of characters 1432.
Because the SSM selection mechanism routes information based on transition dynamics rather than executing a direct content-based lookup, it cannot reliably perform the random-access retrieval required for precise copying 514. Consequently, Mamba-2, while highly efficient for general text generation and summarization, often underperforms comparable Transformers on stringent benchmarks requiring strict in-context learning, multi-step reasoning, few-shot prompting, and precise data retrieval 1132.
The Era of the Hybrid Consensus
The recognition of the strict trade-offs between architectures - where Transformers provide lossless recall but suffer infinite inference scaling costs, and SSMs provide constant inference costs but suffer lossy recall - drove the leading artificial intelligence research laboratories to a singular conclusion: the future of foundation sequence modeling lies in hybrid architectures 7119.
By late 2024 and continuing into the present, the industry definitively converged on interleaving state space layers with traditional attention layers. To further scale parameter counts efficiently without ballooning active computational requirements, these models are frequently augmented with sparse Mixture-of-Experts (MoE) routing networks 1114. This "Hybrid Consensus" seeks to utilize SSMs for the vast majority (seventy to ninety percent) of the sequence processing to maintain enormous context windows and high throughput, while periodically injecting full attention layers to preserve the model's random-access binding and in-context learning capabilities 71114.
Topography of Hybrid Architectures
The following table details the specific architectural compositions of the leading hybrid models developed by major commercial and academic laboratories.
| Model Family | Developing Laboratory | Core Sequence Components | Architectural Mix Ratio | Parameter Density & MoE Strategy | Key Innovation |
|---|---|---|---|---|---|
| Jamba 1.5 Large | AI21 Labs | Mamba-1 + Self-Attention | 1:7 (Attention to Mamba) | 398B Total / 94B Active | ExpertsInt8 quantization; massive 256k long-context enterprise deployment 1516. |
| Zamba2-7.4B | Zyphra | Mamba-2 + Shared Attention | 1:6 (Attention to Mamba) | Dense / Non-MoE | Parameter-sharing with depth-specific LoRA adapters; highly optimized for edge deployment 27. |
| Samba | Microsoft | Mamba-1 + Sliding Window Attention | Interleaved | Dense | Combines SSM with local Sliding Window Attention (SWA) for infinite context extrapolation 3536. |
| Qwen3-Next | Alibaba Cloud | Gated DeltaNet + Gated Attention | 1:3 (Attention to Linear) | 80B Total / 3B Active (512 Experts) | Replaces Mamba with Delta Rule linear attention; ultra-sparse 96.25% MoE layout 373839. |
| Granite 4.0 | IBM | Mamba-2 + Self-Attention | 1:9 (Attention to Mamba) | Dense | Achieves a 70%+ RAM reduction for enterprise workflows requiring exceptionally long inputs 411. |
Deep Dive: Architecting the Hybrid Front
Jamba (AI21 Labs): Developed by the Israeli artificial intelligence laboratory AI21, Jamba proved the absolute viability of hybrid models at an enterprise scale. The flagship Jamba 1.5 Large model features a staggering 398 billion total parameters, but through a highly sparse MoE integration, it only activates 94 billion parameters per token 151617. Jamba interleaves Attention and Mamba layers at a precise 1:7 ratio 114118. This specific architectural balance allows the model to maintain an effective context length of 256,000 tokens while seamlessly fitting onto a single 8-GPU computing node. To achieve this, AI21 introduced a novel ExpertsInt8 quantization technique that heavily compresses the MoE routing weights, slashing the KV cache memory footprints by an order of magnitude compared to pure dense Transformers of similar intelligence 1516.
Zamba and Zamba2 (Zyphra): Zyphra approached the hybrid problem by ruthlessly prioritizing parameter efficiency for local, on-device deployment. Instead of inserting distinct attention layers throughout the network depth, Zamba2 utilizes a unique shared global attention block 1427. The architecture relies almost entirely on Mamba-2 blocks for temporal processing, but it routes the residual stream through the exact same set of Attention weights periodically (yielding a 1:6 ratio of attention computations to SSM computations) 27. To allow this single shared attention block to specialize slightly depending on how deep the sequence has penetrated the network, Zamba2 utilizes non-shared Low-Rank Adapters (LoRAs). This provides high expressivity and retrieves forgotten context at a microscopic parameter cost, rendering the model exceptionally small yet highly capable 273243.
Samba (Microsoft): Researchers at Microsoft and the University of Illinois introduced Samba, a hybrid that eschews full global attention in favor of Sliding Window Attention (SWA). SWA limits the attention mechanism's receptive field to a localized block of recent tokens, ensuring computation remains linear. By interleaving Mamba layers (which compress long-term semantic context) with SWA layers (which perfectly recall recent immediate context), Samba achieves exact memory recall up to 256K tokens and can extrapolate predictions out to an astonishing 1 million token context length with near-perfect accuracy 353644.
Qwen3-Next (Alibaba Cloud): Representing a major architectural leap in hybrid design, the Qwen3-Next model from Chinese technology giant Alibaba replaces standard SSMs entirely with Gated Delta Networks (Gated DeltaNet) 113719. Emerging from research presented at ICLR 2025, Gated DeltaNet improves upon Mamba-2 by combining Mamba-style gating (which enables adaptive memory control and rapid forgetting) with a delta update rule (which facilitates highly precise, targeted memory modifications) 2021. Alibaba deployed this linear mechanism in a 3:1 ratio (three Gated DeltaNet layers for every one Gated Attention layer) alongside an ultra-sparse MoE layout featuring 512 distinct experts 373839. Despite possessing 80 billion parameters, the model activates a mere 3 billion parameters per token. This staggering 96.25% sparsity allows Qwen3-Next to natively support 256K to 1M token context windows while matching the coding and reasoning capabilities of much heavier dense models at a fraction of the inference cost 383948.
Furthermore, academic investigations such as Stanford University's Mixture-of-Mamba (MoM) push hybrid boundaries by introducing modality-aware sparsity. MoM expands the MoE concept directly into the SSM framework, allowing specialized Mamba routing blocks to adapt dynamically to distinct data types, further establishing hybrid structures as the definitive baseline for multimodal processing 49.
The Global Decentralization of AI Architecture Research
The rapid proliferation and optimization of state space models marks a noticeable shift in the geopolitical and geographic centers of artificial intelligence research. While the Transformer era was heavily dominated by Silicon Valley titans, the SSM and hybrid era is fiercely global, characterized by significant breakthroughs from non-Western laboratories and strategic international alliances 1122.
The Middle East: TII and FalconMamba
The Technology Innovation Institute (TII) based in Abu Dhabi, United Arab Emirates, has emerged as a premier global hub for foundational open-source model research. In August 2024, TII released FalconMamba 7B, achieving the status of the top-performing fully open-source pure State Space Language Model 623. Trained extensively on 5.8 trillion tokens, FalconMamba proved that a pure, attention-free SSM architecture could directly rival standard dense Transformers like Meta's Llama-3.1 8B and Mistral 7B on generalized reasoning benchmarks 62352. This achievement underscores a strategic shift where state-backed technological initiatives in the UAE are aggressively pushing the frontiers of alternative algorithmic architectures to ensure regional sovereignty in foundational AI capabilities 2223.
Asia: Alibaba, Tencent, and Academic Institutions
Chinese institutions have equally accelerated the departure from pure attention mechanisms. Beyond Alibaba's massive engineering feat with Qwen3-Next's Gated DeltaNet, Chinese academic and corporate laboratories are leading the charge in adapting SSMs to diverse data modalities. Researchers at the University of Science and Technology of China (USTC), Tencent Hunyuan Research, and Renmin University have spearheaded the integration of Mamba into highly complex visual domains. The development of advanced architectures like Vamba and TimeViper demonstrates sophisticated multi-directional scanning mechanisms capable of integrating linear complexity into spatial reasoning, rendering the processing of massive image datasets and hour-long videos computationally tractable 532455.
Furthermore, the optimization of sequence models is no longer viewed merely as an isolated natural language processing pursuit, but rather as a critical vector of international scientific and economic competition. Strategic trilateral frameworks signed between the United States, Japan, and the Republic of Korea aim to leverage advanced computational sciences - specifically the high-efficiency linear models pioneered by these architectures - for massive-scale environmental modeling, fusion reactor simulation, and advanced materials science 252627. The involvement of major national laboratories, such as South Korea's Korea Institute of Science and Technology (KIST), highlights the global recognition that transcending the quadratic bottleneck is essential for simulating physical reality at scale 2526.
Real-World Applications: Expanding Modalities Beyond Language
Because State Space Models compress sequential context into bounded, fixed-size mathematical states rather than explicitly storing every data point, they are uniquely equipped to handle scientific and multimedia datasets possessing extreme dimensionalities that mathematically paralyze standard Transformers.
Genomics and Single-Cell Biology
The biological blueprint of life is inherently sequential, but genomic sequences stretch into the millions of base pairs. Utilizing quadratic attention to map comprehensive gene-gene interactions across an entire genome is computationally unfeasible. To address this, researchers developed SC-MAMBA2, a foundational model specifically engineered for single-cell transcriptomics capable of handling sequences spanning more than 60,000 distinct genes simultaneously 59. Pre-trained on an extensive dataset of 57 million cells, SC-MAMBA2 heavily modifies the standard causal Mamba architecture into a bidirectional framework 59. This bidirectionality is vital to efficiently capture the non-causal, highly complex regulatory dependencies between genes. This linear biological scaling allows researchers to perform in-silico treatment analysis, cell annotation, and multi-omics data integration at resolutions previously deemed impossible 59.
Computer Vision and Remote Sensing
Standard two-dimensional images are traditionally parsed as one-dimensional sequences of patches in Vision Transformers (ViTs), but Mamba's natively causal (strictly left-to-right) continuous-time nature requires fundamental modification to understand spatial data. Architectures like Vamba address this by introducing sophisticated two-dimensional cross-scanning mechanisms. This approach processes the image along four distinct spatial directions concurrently, ensuring that each visual patch receives holistic contextual information from its surroundings before the state is updated 2428.
This linear spatial scaling has triggered a revolution in remote sensing. High-resolution satellite imagery contains billions of pixels representing minute topographical details. Frameworks such as DC-Mamba and MambaSeg employ multi-directional state space blocks augmented with edge-aware attention to extract fine boundary features and long-range geospatial dependencies 2428. By avoiding the $\mathcal{O}(L^2)$ memory explosion inherent to Vision Transformers, these models achieve superior accuracy in structural integrity, small object recognition, and semantic consistency for critical earth observation tasks 2428.
Continuous Video Processing
Processing high-definition video requires modeling both intricate spatial relationships and complex temporal dynamics over thousands of consecutive frames. The TimeViper architecture implements a hybrid Mamba-Transformer backbone to achieve what researchers term "vision-to-text aggregation." This mechanism progressively compresses visual tokens into recurrent hidden states, stripping away temporal redundancy. This highly efficient state updating allows the model to process continuous, hour-long videos exceeding 10,000 frames on standard consumer hardware without resorting to the aggressive, lossy frame-dropping techniques required by legacy models 55.
Audio and Speech Processing
Similar to genomics, raw audio waveform data is characterized by incredibly high frequencies and astronomically long sequences (often tens of thousands of samples per second of audio). While Transformers traditionally require audio to be heavily compressed into lower-resolution spectrograms to remain tractable, the linear scaling of Mamba and its hybrid variants allows for the direct ingestion and processing of raw audio waveforms over immense time steps 29. This enables sequence models to generate and analyze speech, acoustic phenomena, and music with zero-loss temporal fidelity, mapping the continuous-time signal directly into the SSM's continuous-time mathematical foundations 29.
Next-Generation Horizons: Mamba-3 and MIMO Capabilities
While hybrid models undeniably represent the current industry consensus for general-purpose deployment, research into pure state space architecture continues to evolve at a blistering pace. In early 2026, researchers from Cartesia AI, Princeton University, and Carnegie Mellon University published the technical framework for Mamba-3, targeting the specific hardware inefficiencies and cognitive deficits that plagued earlier iterations of the architecture 152962.
Mamba-3 introduces three radical, highly mathematical methodological updates to the SSM paradigm that redefine its operational limits:
- Multi-Input, Multi-Output (MIMO) Formulation: Traditional SSMs, including Mamba-1 and Mamba-2, operate on a Single-Input, Single-Output (SISO) recurrence. While fast, SISO severely underutilizes the immense parallel compute bandwidth (the arithmetic intensity) of modern GPUs during autoregressive decoding. MIMO fundamentally alters this by increasing the rank of the input and output projections, transforming the sequential state update from a simple outer product into a dense matrix-matrix multiplication 156263. This allows the model to execute up to four times more Floating Point Operations (FLOPs) during decoding, effectively doing substantially more computational "thinking" per step without increasing the wall-clock latency 1563.
- Complex-Valued State Updates: By modeling the state space mathematically utilizing complex numbers rather than strictly real numbers, Mamba-3 massively expands its internal state-tracking capabilities. This structural shift directly attacks the cognitive deficits seen in Mamba-2, allowing Mamba-3 to achieve near-perfect accuracy on synthetic state-tracking, associative recall, and modular arithmetic parity tasks where earlier SSMs failed entirely 152963.
- Exponential-Trapezoidal Discretization: Replacing the older, simpler exponential-Euler heuristic utilized in Mamba-1 and Mamba-2, this advanced continuous-to-discrete mathematical mapping provides a significantly more expressive and stable dynamical recurrence, capturing higher-order relationships in the data stream 2962.
Through these profound mathematical innovations, Mamba-3 proves that an advanced SSM can achieve the perplexity and downstream performance of a Mamba-2 model while utilizing only half the state size memory footprint 6263. As the artificial intelligence industry moves rapidly toward agentic workflows that require extensive, continuous "Chain-of-Thought" processing over millions of tokens, the inference-time compute scaling offered by MIMO SSMs positions them as the critical infrastructure required for the future of autonomous systems 1563.
Conclusion
The narrative surrounding State Space Models has matured significantly from the sensationalized search for a singular "Transformer killer" into a highly sophisticated, pragmatic engineering discipline. The original Mamba and its mathematically rigorous successor, Mamba-2, successfully circumvented the quadratic memory wall of self-attention by leveraging structural properties like State Space Duality and executing hardware-aware parallel scans that brilliantly navigate the physical realities of GPU memory hierarchies.
However, recognizing the inherent theoretical limitations of fixed-size state compression - namely the irreversible loss of precise associative recall and in-context learning fidelity - the global artificial intelligence community has masterfully synthesized the strengths of competing architectures. The contemporary frontier of sequence modeling is definitively characterized by the Hybrid Consensus: models like Jamba, Zamba2, and Qwen3-Next that seamlessly weave sub-quadratic linear attention, causal SSMs, highly sparse expert routing, and global self-attention into cohesive, ultra-efficient cognitive engines.
Driven by decentralized, global research hubs pushing deep into specialized, high-dimensional modalities like single-cell genomics, high-resolution geospatial imaging, raw audio processing, and temporal video analysis, the sub-quadratic revolution is firmly established. As cutting-edge architectures like Mamba-3 begin to manipulate complex-valued mathematical states and parallelized multi-input paradigms, sequence modeling is fundamentally moving past the rigid constraints of the attention matrix, enabling a future defined by unbounded, continuous machine context.