Speculative decoding for large language models
The generation of text using large language models is fundamentally constrained by hardware memory bandwidth rather than raw computational capacity. Standard autoregressive decoding generates a single token per forward pass, requiring the full model weight matrix to be loaded from high-bandwidth memory to the compute units for each sequence step 12. Speculative decoding addresses this inefficiency by decoupling the prediction of future tokens from the heavy target model, utilizing a faster mechanism to draft multiple tokens simultaneously, which are then verified in parallel 13. This technique systematically increases the arithmetic intensity of the decoding process, converting latency-bound operations into throughput-optimized computations without degrading the statistical quality of the generated text 24.
Architectural Bottlenecks in Model Inference
To fully comprehend the mechanics of speculative decoding, it is necessary to analyze the underlying hardware constraints that define standard large language model inference. Modern graphical processing units execute tasks across a spectrum defined by two immutable hardware limits: peak memory bandwidth and peak computational throughput 4.
The Memory Wall and Arithmetic Intensity
The point at which a hardware system transitions from being memory-bound to compute-bound is determined by its roofline ratio 45. For example, a modern accelerator like the NVIDIA H100 SXM5 GPU features a peak computational capacity of 1,979 teraflops at half-precision and a peak high-bandwidth memory transfer rate of 3.35 terabytes per second 4. The intersection of these ceilings, known as the roofline ridge point, occurs at approximately 591 floating-point operations per byte 45.
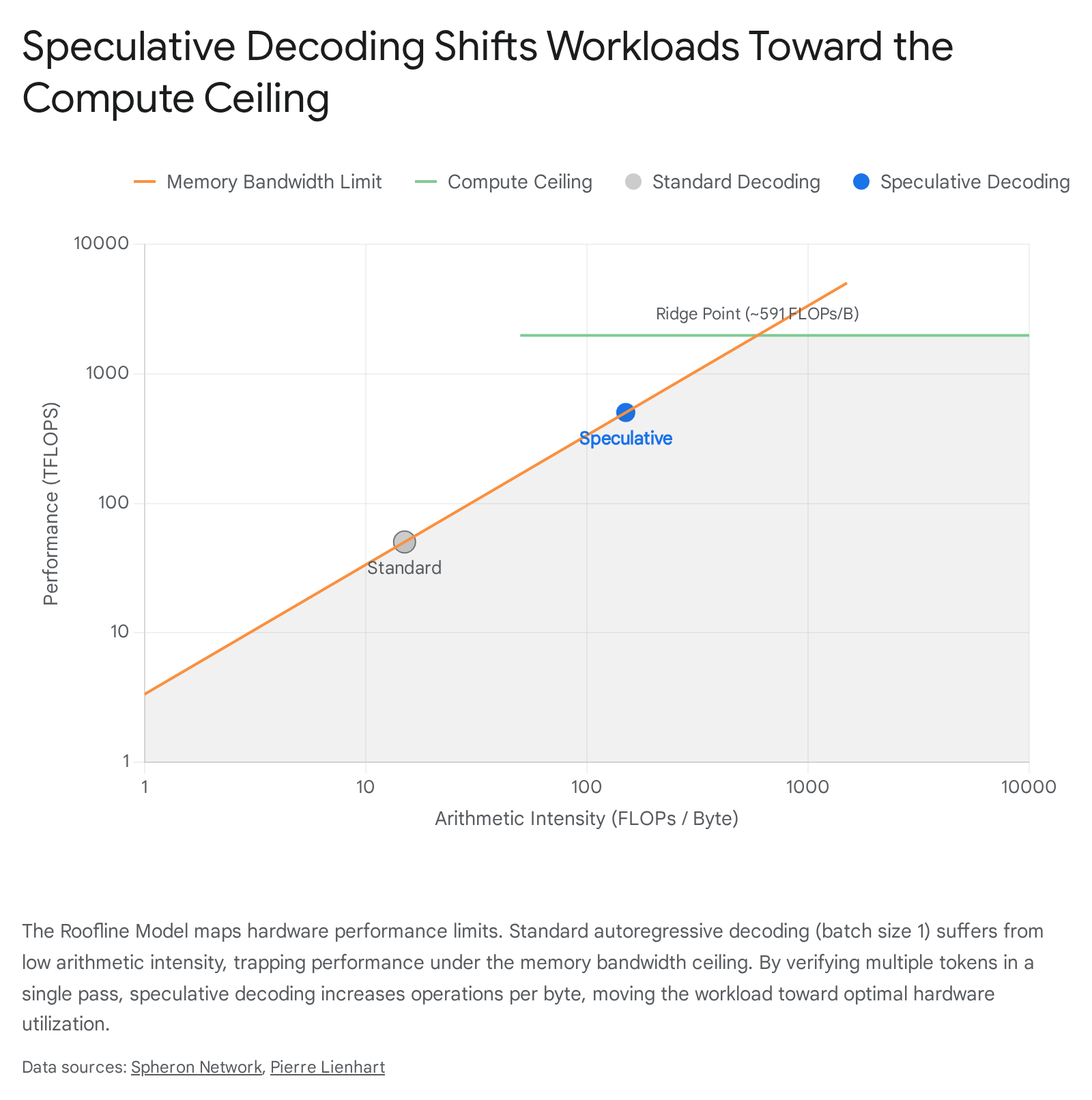
If an algorithm performs fewer than 591 arithmetic operations for every byte of data it transfers from memory, the hardware operates in a suboptimal memory-bound regime 45.
Autoregressive decoding at small batch sizes sits far below this roofline 4. Generating a single token from a 70-billion-parameter model at half-precision requires transferring approximately 140 gigabytes of weight data 4. On an H100 GPU operating at maximum theoretical bandwidth, this transfer inherently consumes about 42 milliseconds per token step, while the actual mathematical operations finish in a fraction of that time 4. The arithmetic logic units spend the majority of the processing cycle sitting idle, waiting for data retrieval 2.
Prefill and Decode Phase Discrepancies
Large language model inference consists of two distinct phases that tax hardware differently: prefill and decode 6. The prefill phase processes the initial prompt context in parallel, executing large matrix-matrix multiplications that easily saturate tensor cores and achieve high arithmetic intensities 7. Consequently, the prefill phase is typically compute-bound 56.
In stark contrast, the decode phase relies on matrix-vector multiplications to process tokens sequentially 6. This discrepancy means that standard hardware optimizations targeting matrix multiplication speed offer diminishing returns for the decode phase, necessitating algorithmic interventions to improve utilization 57. Speculative decoding intervenes specifically during this decode phase, forcing the hardware to evaluate multiple tokens per memory load, thereby mimicking the parallel processing efficiency natively found only in the prefill stage 29.
Core Mechanisms of Speculative Decoding
Speculative decoding circumvents the sequential memory bottleneck by converting sequential token generation into a batch verification task 210. When implemented rigorously, the algorithm guarantees that the final output distribution perfectly matches that of the target model, ensuring zero quality degradation while significantly accelerating completion times 18.
Draft Generation and Parallel Verification
The process relies on generating a sequence of candidate tokens efficiently and verifying them simultaneously against the primary model.
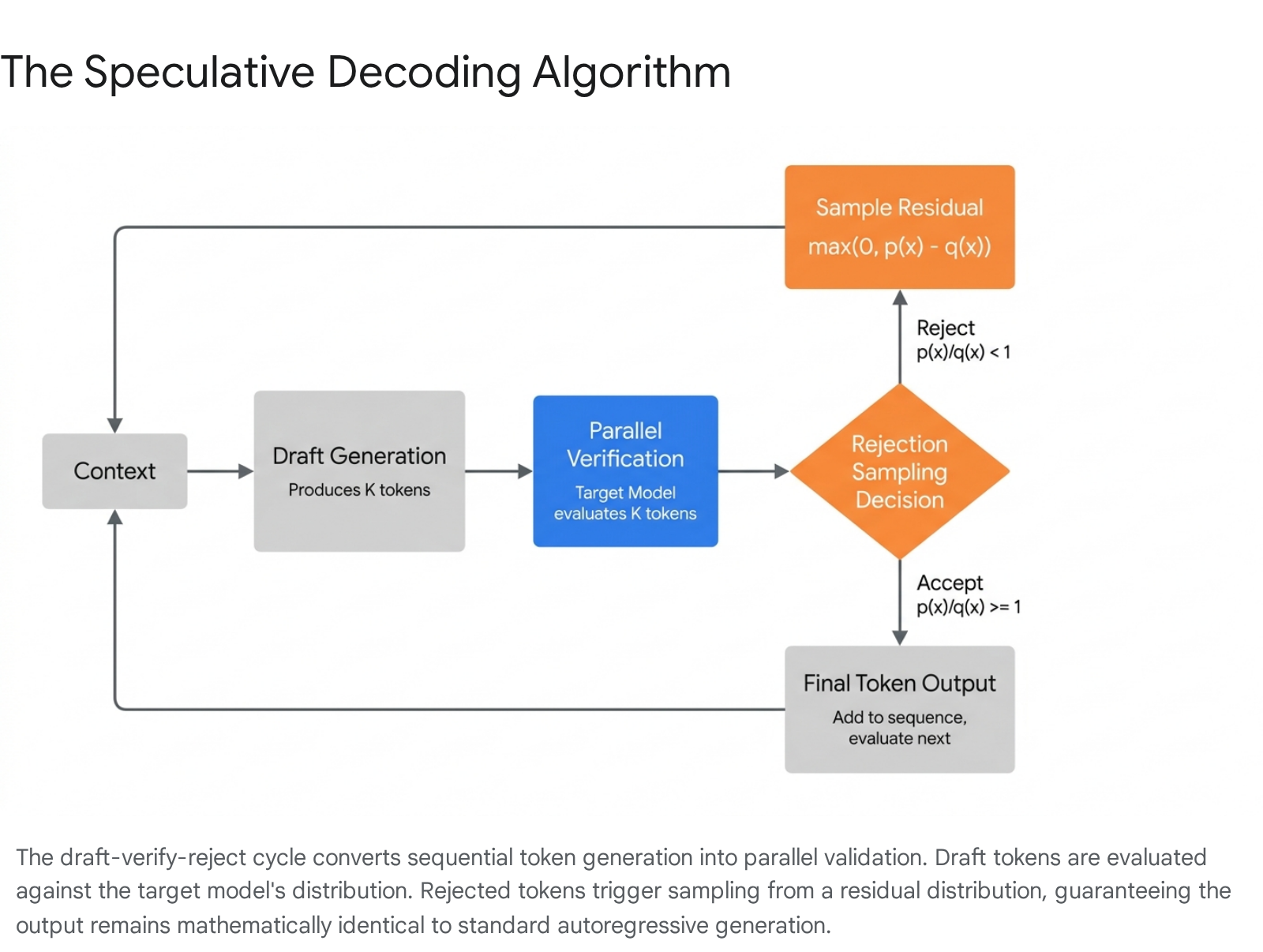
A secondary mechanism, operating at a fraction of the computational cost, rapidly generates a short sequence of candidate tokens conditioned on the current context 23. Once this draft sequence is prepared, the massive target model receives the original context appended with the drafted tokens 29.
Because transformer architectures can process entire sequences in parallel during a single forward pass, the target model computes the probability distributions for all of the drafted tokens at once 210. Loading the multibillion-parameter weight matrices to verify a block of five tokens takes roughly the same temporal overhead as loading them for a single token 2. The system then sequentially evaluates each draft token against the target model's generated probabilities. If a token is accepted, the system moves to the next in the sequence. The moment a token is rejected, the system discards the rejected token and all subsequent draft tokens in that batch 1112. Even in the worst-case scenario where the very first draft token is rejected, the target model still generates one valid replacement token for that forward pass, ensuring the process never falls behind the speed of standard autoregressive decoding 1216.
Distribution Matching via Rejection Sampling
The mathematical core of speculative decoding lies in its rejection sampling scheme, which ensures that the probability distribution of the final accepted sequence perfectly mirrors the target model's distribution, despite being initially proposed by a much weaker proxy 917. During parallel verification, the acceptance of a draft token is determined probabilistically by comparing the draft distribution to the target distribution 118.
If the target model assigns a higher or equal probability to the drafted token than the draft model did, the token is characterized by under-confidence and is accepted with absolute certainty 217. Conversely, if the draft model was over-confident and assigned a higher probability to the token than the target model, the token is subjected to a probabilistic rejection test. In this scenario, the token is accepted with a probability equal to the target probability divided by the draft probability 217.
When a token fails this probabilistic check and is rejected, the system must substitute it to ensure the generation process advances. To strictly preserve the target model's statistical distribution, the replacement token is not simply chosen via naive greedy sampling. Instead, it is sampled from a mathematically derived residual distribution 117. This residual distribution re-weights the probabilities across the entire vocabulary, taking the positive difference between the target and draft probabilities and normalizing this difference 9. The probability mass shifts aggressively toward tokens the target model favored more than the draft model did 9. By sampling from this corrected distribution, the algorithm guarantees that the overall output is identical to a standard, unaccelerated autoregressive run 9.
Temperature Scaling and Adaptive Thresholds
The efficiency of standard rejection sampling is highly sensitive to the sampling temperature requested by the user 1113. At a temperature of zero, corresponding to greedy deterministic decoding, the target model's probability distribution is maximally sharp, allowing a well-aligned draft mechanism to achieve acceptance rates exceeding 80 percent 13.
However, as the temperature rises to induce creative or diverse generation, the target model's probability distribution flattens 11. Under standard rejection sampling, this flattening results in a severe "random rejection" penalty 1113. Perfectly plausible draft tokens are discarded purely due to the expanded variance in the target model's sampling space, causing draft acceptance rates to plummet to roughly 30 percent and nullifying the speedup 13.
To counter this efficiency degradation, researchers developed mechanisms like Efficient Adaptive Rejection Sampling 11. This protocol introduces a dynamic tolerance threshold calibrated directly to the target model's real-time predictive confidence 1113. By defining uncertainty mathematically as the inverse of the maximum target probability, the system intelligently relaxes the acceptance criteria during high-entropy generation steps 13. This adaptive thresholding dramatically reduces wasteful random rejections, boosting token throughput in high-temperature scenarios with only negligible impacts on strict alignment quality 1113.
Speculative Architectural Variants
Since the initial formalization of speculative decoding, the industry has developed several distinct architectural methods to handle the drafting phase. The primary differentiator is whether the system relies on an entirely separate model, augments the target model with specialized prediction heads, or extracts drafts dynamically from iteration algorithms.
| Speculative Architecture | Core Operational Mechanism | Primary Advantages | Prominent Implementations |
|---|---|---|---|
| Dual-Model Assisted Generation | Employs a physically separate, smaller language model to draft token sequences 10. | Simple to integrate if a matching sub-model exists; requires no architectural modification 1014. | Standard Draft-Target 1, Universal Assisted Generation 15. |
| Multiple Decoding Heads | Appends independent prediction heads to the target model's final hidden layer to forecast subsequent steps 1416. | Eliminates separate model overhead; enables highly parallel verification via tree attention 1417. | Medusa 1724. |
| Feature-Level Extrapolation | Utilizes a lightweight autoregressive layer on the target's internal contextual features to draft tokens 1826. | Achieves exceptionally high acceptance rates; robust mapping of contextual semantics 1928. | EAGLE family 29, Multi-Token Prediction 26. |
| Non-Autoregressive Iteration | Frames decoding as a non-linear system solved via Jacobi iteration to predict multiple positions 3031. | Requires absolutely no draft models or additional parameters; highly self-contained 3120. | Lookahead Decoding 20, Jacobi Forcing 33. |
| Tree-Based Ensembles | Combines predictions from multiple small speculative models into a unified candidate token tree 3421. | Maximizes overlap between predicted paths; exceptionally efficient in distributed environments 3622. | SpecInfer 3421. |
Dual-Model Assisted Generation
The foundational implementation of speculative decoding requires a separate, lightweight draft model, typically an order of magnitude smaller than the target model, drawn from the same architectural family 338. For instance, an 8-billion-parameter model might serve as the dedicated drafter for a 70-billion-parameter target model 10. While conceptually straightforward, the primary limitation of this approach is system complexity. The serving infrastructure must manage two distinct models in memory, and historically, it imposed a strict requirement that both models utilize the exact same tokenizer to ensure probability distributions mapped identically 1015.
Recent advancements, such as Universal Assisted Generation, circumvent the tokenizer constraint by performing real-time two-way translations 1539. In this framework, the draft model's output tokens are temporarily converted to raw text and immediately re-tokenized using the target model's vocabulary prior to verification. This translation layer incurs almost zero overhead while drastically expanding the viable pairings of draft and target models across different architectural families 15.
Multiple Decoding Heads and Typical Acceptance
To eliminate the memory and operational overhead of hosting an entirely separate draft model, researchers introduced self-speculating architectures. The Medusa framework augments the target language model by appending multiple auxiliary decoding heads directly to the final hidden layer 1416. Each subsequent head is specifically trained to predict one token further into the future based on the current context state 16. If three Medusa heads are attached, a single forward pass yields the primary token plus three sequential speculative candidates 16.
During generation, these heads propose multiple branching candidates which are organized and processed using a sophisticated tree-based attention mechanism 1740. Rather than strictly utilizing standard rejection sampling, Medusa often employs an alternative called the Typical Acceptance Scheme 23. This method utilizes a dynamic threshold tied to the entropy of the probability distribution 23. It relaxes the matching criteria when the target model's entropy is high - indicating multiple valid continuations - and strictly enforces it when entropy is low 1723. While the Typical Acceptance Scheme does not mathematically guarantee an identical output distribution to the base model under all conditions, empirical validation shows it sustains high semantic quality while driving significant speedups 172442.
Feature-Level Extrapolation
The Extrapolation Algorithm for Greater Language-model Efficiency, widely known as EAGLE, pushes the self-speculation paradigm further by abandoning discrete token-level drafting in favor of feature-level autoregression 1819. Instead of relying on standard token probabilities, EAGLE attaches a lightweight prediction head consisting of minimal transformer layers that extrapolates the contextual feature vectors directly from the target model's upper layers 1018. Because internal hidden states carry rich semantic context, forecasting features proves statistically smoother and more accurate than forecasting discrete tokens 18. The predicted features are subsequently passed through the target model's frozen classification head to produce the final draft tokens 1843.
The EAGLE architecture has evolved through multiple iterations to maximize acceptance rates. The original EAGLE extracted features solely from the second-to-top layer, demonstrating threefold speedups over standard decoding 1829. EAGLE-2 introduced dynamic tree structures by utilizing draft confidence scores to approximate acceptance rates at runtime, building longer draft branches for highly predictable text and shorter branches for complex passages 1929. EAGLE-3 replaced single-layer extraction with tri-layer feature fusion. By simultaneously ingesting representations from early layers governing syntax, middle layers governing semantic relationships, and late layers governing output probabilities, the draft head gains comprehensive contextual awareness 44. This fusion allows EAGLE-3 to achieve token acceptance rates near 0.8, generating speedups of up to 6.5 times over baseline standard decoding 194445.
Non-Autoregressive Jacobi Iteration
Lookahead Decoding provides a purely mathematical and algorithmic alternative that requires no draft models, no fine-tuning, and no auxiliary data stores 2046. It reframes autoregressive decoding as a non-linear system of equations, adapting the fixed-point Jacobi iteration method commonly used in numerical analysis 3031.
In this framework, the generation process utilizes a parallel lookahead branch and a verification branch 47. The lookahead branch maintains a two-dimensional matrix defined by a window size, which dictates how far ahead to predict, and an n-gram size, which dictates how many steps to look back in the trajectory 2047. By iteratively updating future token variables from random initial guesses, the system tracks the trajectories of tokens over successive iterations 2046. These stabilized trajectories form disjoint n-grams, which are cached in a temporary pool 3048. Simultaneously, the verification branch checks these cached n-grams against the target model. If an n-gram matches the target distribution, the model accepts the entire block, skipping multiple decoding steps sequentially in a manner that scales logarithmically with the floating-point operations applied 20.
Tree-Based Speculative Inference
SpecInfer specifically targets distributed, multi-GPU serving environments where inter-node communication latency historically hampers fast generation 3449. It relies on a suite of collectively boost-tuned small speculative models to jointly predict the target's outputs 2150. Rather than presenting a single linear sequence of tokens to the target model, SpecInfer organizes the diverse predictions from these models into a cohesive token tree 3422.
The target model functions exclusively as a token tree verifier. Using a specialized tree-based parallel decoding kernel, the large model processes all nodes of the candidate tree in a single computational step 2249. Because the tree aggregates the diverse strengths of multiple draft models, it dramatically increases the statistical probability that a long, valid sequence overlaps with the target model's actual intent, reducing end-to-end inference latency substantially 2122.
Performance Dynamics and Hardware Utilization
The practical acceleration achieved by speculative decoding is not uniform across all deployments. Throughput gains are highly sensitive to specific infrastructure configurations, particularly the concurrency of the server, the available hardware constraints, and the inherent predictability of the generation task 1124.
Concurrency and Batch Size Interactions
Speculative decoding yields its highest relative speedups at low batch sizes, typically between one and four concurrent requests, where the graphical processing unit operates far below its computational ceiling 2425. When an inference server handles concurrent requests, it utilizes continuous batching to group multiple generation sequences into a single dense matrix operation 2453.
As the active batch size scales up toward 32 or 64 concurrent requests, the baseline autoregressive generation becomes increasingly compute-bound. The matrix dimensions grow large enough to fully saturate the arithmetic logic units on the hardware 2554. Under these high-concurrency conditions, the computational overhead of running the draft mechanism and performing parallel verification can exceed the latency savings 2455. In rigorous benchmark testing, fixed-length speculative decoding has been observed to degrade throughput when batch sizes grow exceedingly large, as the verification overhead outpaces the architectural gains 24.
To mitigate this bottleneck, modern implementations employ adaptive speculative decoding 25. These systems actively monitor the active batch size and dynamically scale down the speculation length as concurrency increases 25. Furthermore, methods like Batched Attention Optimized Speculative Sampling explicitly account for variable acceptance lengths across sequences in a batch, preventing the padding inefficiencies that traditionally stall tensor cores during irregular operations 26.
Economic and Energy Efficiency Implications
Beyond the immediate reductions in latency, the architectural shift provided by speculative decoding fundamentally alters the economics and environmental impact of deploying large language models at scale 57. Every rejected token in standard autoregressive decoding represents wasted floating-point operations 57. By cutting redundant computation and minimizing the time the hardware spends waiting on memory transfers, speculative decoding significantly reduces the overall energy draw per query 57.
For hyperscale deployments and enterprises bound by environmental, social, and governance metrics, this translates into measurable reductions in carbon footprint 57. Furthermore, clusters previously sized to accommodate worst-case latency under standard decoding can process a higher volume of queries per second using the same hardware footprint, effectively shifting the operational economics from a focus on faster individual responses to serving more users per unit of capital expenditure 57.
Production Implementation and Inference Engines
The transition of speculative decoding from theoretical research into production infrastructure requires profound modifications to memory management and request scheduling. Major open-source inference frameworks like vLLM and TensorRT-LLM orchestrate these dynamics using differing architectural philosophies 5859.
| Engine Characteristic | vLLM Implementation Strategy | TensorRT-LLM Implementation Strategy |
|---|---|---|
| Core Architecture | Highly dynamic, Python-based runtime engine focusing on flexibility and continuous batching 5859. | C++ based, ahead-of-time compiled engine focusing on low-level hardware kernel optimization 5859. |
| Speculative Operations | Utilizes distinct Draft and Target runners integrated seamlessly with PagedAttention scheduling 2728. | Leverages kernel fusion and CUDA graphs to capture drafting loops for maximum speed 2963. |
| Supported Methods | Broad ecosystem support including Draft Models, N-gram, Medusa, EAGLE-3, and MTP 30. | Highly optimized support for ReDrafter, EAGLE, Medusa, and Lookahead Decoding 3166. |
| Deployment Profile | Ideal for heterogeneous hardware, rapid prototyping, and highly variable traffic patterns 5963. | Unmatched performance for stable, high-volume production on dedicated NVIDIA clusters 5859. |
Dynamic Serving in Distributed Ecosystems
The vLLM framework utilizes a dynamic runtime intelligence centered heavily on PagedAttention, a memory management system that allocates key-value cache memory in non-contiguous blocks to minimize fragmentation 5859. In vLLM, speculative decoding operates via distinct execution runners: a Draft Runner processes the auxiliary models or heads to propose tokens, and a Target Runner executes the heavy verification pass 2728.
The system's scheduler dynamically manages continuous batching, intelligently interleaving drafted tokens into the forward pass alongside standard queries 28. The framework is prized for its flexibility and ease of deployment across heterogeneous hardware, allowing rapid integration of bleeding-edge speculative methods like EAGLE-3 and Multi-Token Prediction without requiring deep low-level code recompilation 5932.
Graph Optimization and Ahead-of-Time Compilation
In contrast, NVIDIA's TensorRT-LLM engine focuses on ahead-of-time compilation and low-level hardware orchestration 5859. To extract absolute maximum performance for speculative decoding, TensorRT-LLM aggressively leverages kernel fusion and CUDA graphs 2963.
TensorRT-LLM offers two distinct internal implementations for speculative workflows. The standard Two Model variant mirrors general serving concepts by attaching draft tokens to requests within the executor layer before they hit the target model engine 29. However, the highly optimized One Model implementation inserts the drafting mechanism directly into the target model's code as a compiled submodule 29. This architectural decision allows the entire drafting and verification loop to launch as a single unified CUDA graph, dramatically minimizing CPU-to-GPU synchronization delays and slashing the crucial time-to-first-token metric 2963. While TensorRT-LLM requires rigid, ahead-of-time engine compilation tailored to exact GPU configurations, it consistently yields the lowest absolute tail latencies for steady, high-volume inference environments 5932.