Sparse Autoencoders for Large Language Model Interpretability
Black Box Models and the Interpretability Imperative
Large language models have achieved unprecedented performance across natural language processing, coding, spatial reasoning, and biological sequence analysis. Despite their ubiquity and rapidly expanding capabilities, the internal algorithms that govern their behavior remain fundamentally opaque. These deep neural networks function as "black boxes," where the transformation of inputs into sophisticated outputs occurs through billions of floating-point operations that lack intrinsic semantic meaning to human observers 1234. As frontier models are increasingly integrated into critical infrastructure, finance, healthcare, and autonomous decision-making systems, this lack of transparency introduces significant systemic risks. These risks include unpredictable failure modes, the perpetuation of allocative bias, and the potential for deceptive alignment, wherein a model behaves optimally during training but pursues misaligned goals during deployment 5576.
The field of mechanistic interpretability aims to resolve this opacity by reverse-engineering the internal computations of neural networks into human-understandable algorithms and concepts. Unlike behavioral evaluation - which treats the model as an oracle and audits its inputs and outputs - mechanistic interpretability operates as a bottom-up approach. It interrogates the fundamental structural components of the model, including features, neurons, layers, and circuits, to uncover precise causal relationships 3710. The ultimate theoretical objective is to map the computational graph of a large language model so comprehensively that its operations could be expressed as explicit, auditable pseudocode 37.
Among the tools developed to achieve this granular understanding, Sparse Autoencoders (SAEs) have emerged as the dominant methodological paradigm. Inspired by the sparse coding hypothesis in computational neuroscience, sparse autoencoders function as a structural microscope. They disentangle the complex, superimposed internal activations of a language model into discrete, interpretable components 1289. By transitioning the unit of analysis from the opaque individual neuron to the interpretable latent feature, sparse autoencoders facilitate advanced structural analyses, including circuit discovery, targeted behavioral steering, and rigorous safety auditing.
Polysemanticity and the Superposition Hypothesis
The primary obstacle to understanding neural network internals has historically been the phenomenon of polysemanticity. Early interpretability research hypothesized that individual artificial neurons might correspond to single, discrete concepts, analogous to the "grandmother cell" theory in neuroscience. If this hypothesis held true, understanding a neural network would simply be a matter of cataloging the specific concept that triggered each individual neuron. Empirically, however, researchers found that while some neurons cleanly map to specific features, the vast majority do not 1813. Instead, a single neuron in a modern large language model might simultaneously activate in response to academic citations, English dialogue, HTTP requests, and Korean text 1.
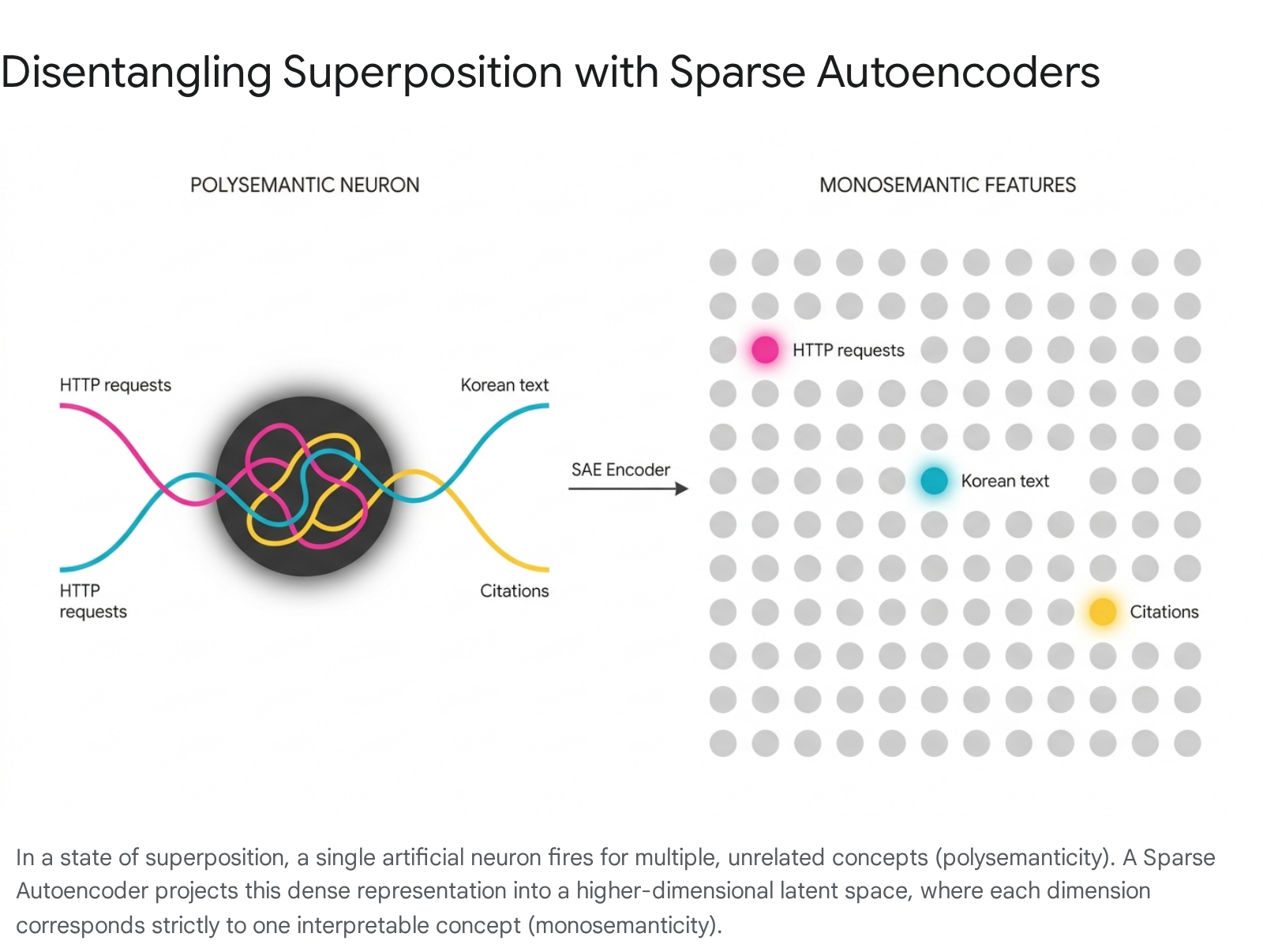
This polysemantic behavior renders neuron-level analysis inherently ambiguous and unsuitable for rigorous causal auditing. To explain why polysemanticity occurs, the mechanistic interpretability community formulated the superposition hypothesis 10111213. Neural networks operate in environments where the number of meaningful concepts, or features, vastly exceeds the number of available dimensions, or neurons, in the model's activation space 1911. Furthermore, many of these concepts are naturally sparse; for instance, the birthplace of a specific historical figure may appear in less than one in a billion training tokens, yet modern models must retain this information alongside an extraordinary amount of other factual data 1.
To accommodate this mathematical discrepancy, language models learn to represent concepts not as individual neurons, but as linear combinations of neurons, which exist as continuous directions in the activation space 71113. This functional dynamic is formalized as the Linear Representation Hypothesis 714. Because high-dimensional geometric spaces contain an exponentially large number of almost-orthogonal vectors, the network can compress, or superimpose, millions of distinct features into a smaller dimensional space. While this process is highly computationally efficient for the target language model, superposition dictates that any single neuron's activation is merely an interference pattern of multiple overlapping concept vectors. This architectural reality effectively locks the black box against direct human observation 2411.
Architectural Formulations of Sparse Autoencoders
Sparse autoencoders are deployed specifically to invert the superposition process, attempting to extract the true, uncompressed concept vectors from the target model's dense activations. At its core, a sparse autoencoder is a secondary, unsupervised neural network trained specifically on the cached internal activations of a frozen target language model 1111516.
The Encoder and Decoder Functions
A standard sparse autoencoder consists of two primary linear transformations. First, an encoder maps the dense input activation vector from the language model's residual stream or multi-layer perceptron into a higher-dimensional latent vector. This is achieved using a learned encoder weight matrix, a bias term, and a non-linear activation function 91317. Second, a decoder attempts to reconstruct the original dense input activation through a linear transformation of the sparse feature activations using a dictionary matrix 91317. The columns of this decoder matrix represent a dictionary of learned directions, frequently referred to as latent features or simply "latents" 17.
If the latent space is merely expanded without additional mathematical constraints, the autoencoder could trivially learn an identity mapping, revealing nothing about the underlying conceptual structure of the language model 9. To force the discovery of true, disentangled features, the training objective applies a sparsity penalty. The model is computationally penalized if too many latent features are active simultaneously for any given input token 91317. This constraint aligns with the empirical reality that while a model stores millions of concepts, only a tiny, sparse fraction are ever relevant to any single specific token of text 822.
Regularization and Structural Variations
The design of sparse autoencoders has undergone rapid architectural evolution to optimize the fundamental tension between reconstruction fidelity - the ability to faithfully represent the language model's original computation - and sparsity, which is required to ensure the resulting features are comprehensible to human researchers.
Historically, standard architectures utilized a Rectified Linear Unit (ReLU) activation function coupled with an L1 regularization penalty on the latent activations 91718. While effective at inducing sparsity, the L1 penalty causes a mathematical distortion known as activation shrinkage. This phenomenon systematically suppresses the true magnitude of the underlying features, warping the reconstructed vectors and reducing the accuracy of downstream analysis 918. To mitigate activation shrinkage and optimize the sparsity-reconstruction Pareto frontier, researchers developed several advanced variants designed to enforce sparsity without distorting activation magnitudes.
| Architecture Type | Sparsity Mechanism | Primary Advantage | Structural Limitation |
|---|---|---|---|
| Standard (ReLU) | L1 Regularization Penalty on latent activations | Simple to implement; provides a continuous and differentiable loss landscape for stable training. | Suffers heavily from activation shrinkage, artificially reducing feature magnitudes and distorting reconstructions. |
| TopK / BatchTopK | Hard k-sparsity (retains only the highest $K$ values per pass) | Separates feature selection from magnitude estimation; avoids L1 shrinkage entirely. | Imposes rigid sparsity constraints per token, struggling with complex inputs that naturally require more concepts. |
| JumpReLU | Learnable threshold parameter (Heaviside step + ReLU) | Allows for a variable number of active latents depending on token complexity; state-of-the-art fidelity. | Requires Straight-Through Estimators (STEs) for optimization due to non-differentiable L0 penalties. |
| Matryoshka (MSAE) | Nested dictionaries at multiple progressively expanding granularities | Simultaneously learns hierarchical concepts; limits feature absorption by forcing abstract concept retention. | High architectural complexity; necessitates balancing multiple reconstruction losses across varying dimensionalities. |
TopK and BatchTopK autoencoders enforce hard $k$-sparsity by simply ranking the latent activations by magnitude and zeroing out all but the highest values 9171819. BatchTopK improves this protocol by selecting the top activations across an entire batch rather than a single token, ensuring better utilization of rare features and reducing the incidence of "dead" latents - neurons that fail to ever activate 919.
JumpReLU autoencoders were introduced to achieve state-of-the-art reconstruction fidelity. This architecture utilizes an activation function that combines a shifted Heaviside step function as a gating mechanism with a conventional ReLU 917. The activation is zeroed out if it falls below a vector-valued, learnable threshold parameter, but remains completely un-shrunk if it exceeds the threshold 17. Because the resulting L0 penalty - which measures the exact count of active, non-zero elements - is piecewise constant and non-differentiable, JumpReLU models are optimized using straight-through estimators 1719.
Google DeepMind subsequently introduced the Matryoshka Sparse Autoencoder (MSAE) to resolve the tension inherent in dictionary size selection. Drawing inspiration from Matryoshka representation learning, MSAEs simultaneously train multiple nested dictionaries of varying expansion sizes 182021. The training objective forces the smaller, coarse-grained dictionaries to independently reconstruct inputs without relying on the larger, fine-grained dictionaries 1822. This structural constraint enforces a natural hierarchy of abstraction: early latents capture broad, general concepts, while deeper latents specialize in highly specific, rare features 1822.
Compute Scaling and Training Efficiency
The extraction of interpretable features via sparse dictionary learning carries a staggering computational cost, rendering it one of the most resource-intensive subfields of artificial intelligence safety research. The computational footprint required to train a sparse autoencoder is divided into two distinct phases: activation caching, which involves generating the target language model's internal activations across billions of tokens, and autoencoder optimization, which involves training the sparse network on those cached vectors 15.
Scaling Laws and Extrapolation
As researchers attempt to map larger frontier models, new scaling dynamics have emerged. Studies detailing the decomposition of GPT-4 into 16 million features, or Claude 3 Sonnet into 34 million features, reveal that there is a systematic relationship governed by a variation of Zipf's law 1323. Finding and resolving rarer concepts necessitates exponentially larger dictionary sizes 13. Furthermore, research evaluating scaling laws formalizes a joint power law for the autoencoder reconstruction loss relative to both dictionary width and target sparsity 2425. These scaling laws dictate that producing comprehensive dictionaries for models with hundreds of billions of parameters requires training investments equivalent to a significant fraction of the base model's original pre-training compute. For example, generating the suite of JumpReLU autoencoders for DeepMind's Gemma Scope 2 required approximately 15 percent of the total compute used to pre-train the underlying Gemma 2 9B model, occupying roughly 20 petabytes of storage for intermediate activations 19.
Layer Clustering and Group Optimization
To mitigate these severe computational bottlenecks, researchers have developed optimization architectures such as Group-SAEs. Traditional methodologies dictate training a distinct, isolated sparse autoencoder for every individual layer of the target language model 1526. Group-SAEs instead propose clustering adjacent layers based on the angular similarity of their residual streams 1527. Rather than learning a dictionary per layer, a single autoencoder is trained across a cluster of functionally similar, contiguous layers 2627. Empirical evaluations conducted on models from the Pythia family demonstrate that layer clustering can achieve up to a 3x speedup in training compute, significantly reducing the total floating-point operations required without compromising reconstruction quality or downstream interpretability 152627.
Feature Pathologies: Splitting and Absorption
The push toward larger dictionary sizes designed to capture rare concepts frequently triggers architectural pathologies. As expansion factors increase, broad hierarchical features undergo feature splitting - a phenomenon where a general feature fragments into numerous highly specific sub-features 28293530. While splitting is often desirable for maximizing granularity, it regularly devolves into a pernicious failure mode categorized as feature absorption 283531.
Identified in rigorous testing environments, including first-letter identification classification tasks, feature absorption occurs when the sparsity penalty incentivizes the autoencoder to learn gerrymandered, logically flawed feature representations 283031. This pathology manifests when two concepts form a strict hierarchy, where the presence of Concept A structurally implies the presence of Concept B. For example, the token representing the word "elephant" inherently implies the concept "starts with the letter E" 3233.
An ideal, fully monosemantic autoencoder would activate two separate latents in this scenario. However, activating two latents incurs a higher mathematical sparsity penalty than activating one. To minimize its overall loss, the autoencoder absorbs the general feature into the specific one 303133. It learns a latent for "elephant," but heavily distorts the "starts with E" latent so that its internal logic becomes "starts with E, except when the word is elephant" 3133.
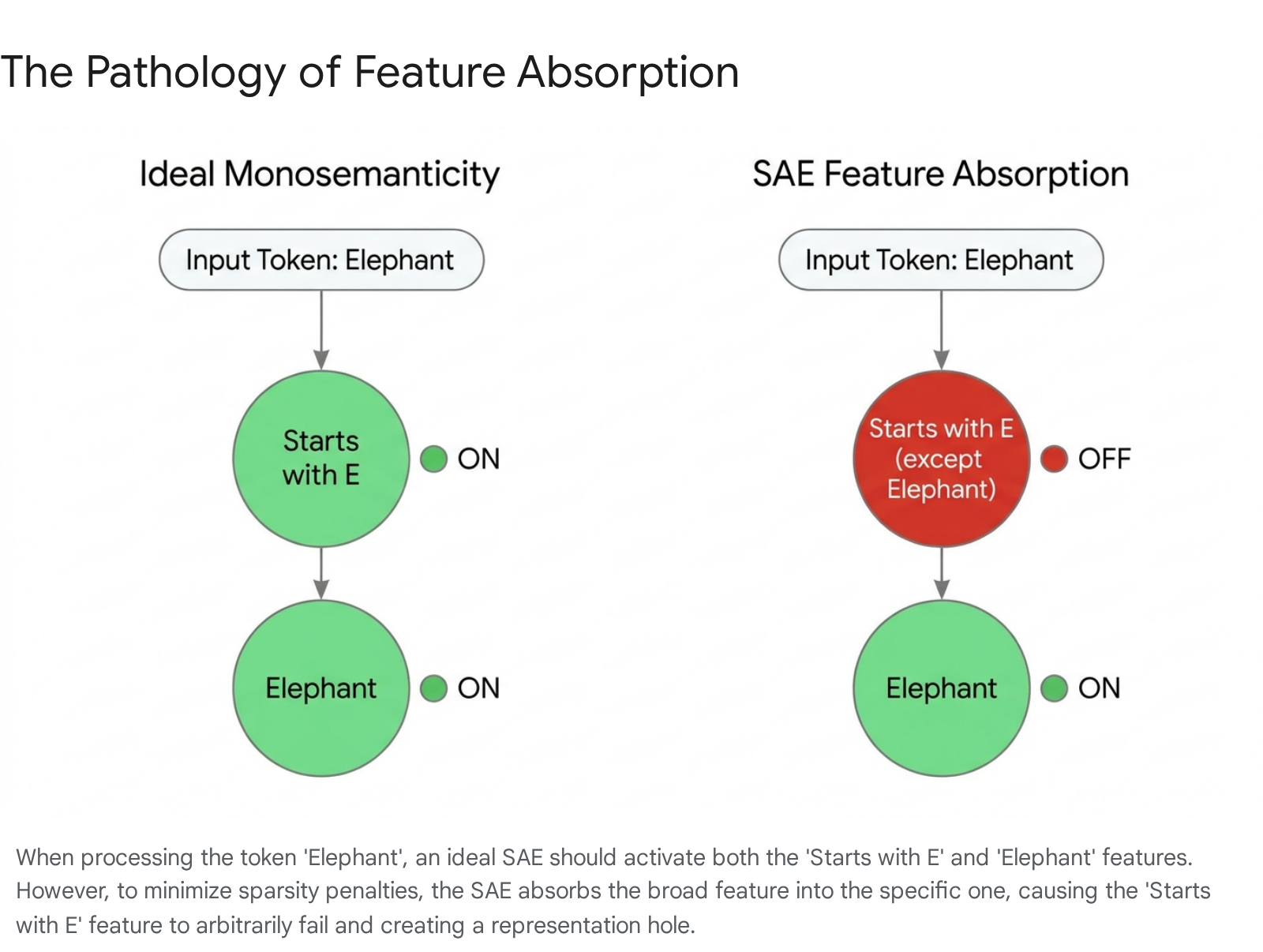
Consequently, seemingly interpretable latents quietly fail to activate on arbitrary positive examples, generating significant representation holes 3134. Feature absorption poses a severe obstacle to the practical application of these tools in AI safety auditing, as it suggests that latents may function as inherently unreliable classifiers when investigators attempt to search for deceptive or misaligned model behaviors 30. Advanced structural interventions, such as orthogonal mathematical constraints or the hierarchical nested dictionaries utilized by Matryoshka architectures, are currently required to untangle these rigid dependencies and reduce absorption rates 223441.
Standardized Evaluation and the Linear Probing Debate
Despite the theoretical elegance of sparse dictionary learning, the empirical utility of these autoencoders on downstream tasks has been intensely debated. Historically, the mechanistic interpretability community relied heavily on subjective, qualitative metrics, frequently utilizing frontier models like Claude 3 Opus or GPT-4 as automated judges to score how well natural language descriptions matched the text that activated a specific feature 11332.
As the field has matured, researchers have increasingly attempted to measure performance against ground-truth downstream tasks. Highly influential empirical evaluations across diverse datasets have revealed that autoencoder probes frequently underperform simple linear logistic regression probes - especially under conditions characterized by data scarcity, class imbalance, and covariate shift 143536. In multiple classification tasks, the raw, uncompressed activations processed by a linear probe generalized better than the reconstructed sparse latents 43536.
| Evaluation Vector | Metric Focus | Primary Measurement Tool |
|---|---|---|
| Concept Detection | Precision of latent correspondence to meaningful concepts. | Sparse Probing accuracy; Feature Absorption rates 32. |
| Interpretability | Human-understandability of the discovered latent directions. | Automated LLM-as-a-judge scoring frameworks 1332. |
| Reconstruction | Faithfulness to original model behavior and computation. | Fraction of Variance Unexplained (FVU); Cross-entropy degradation 1532. |
| Disentanglement | Isolation of independent concepts without merging. | Orthogonality metrics; Analysis of representation holes 3234. |
These negative results triggered substantial institutional re-evaluations. The mechanistic interpretability team at Google DeepMind publicly announced a pivot away from fundamental, unsupervised sparse autoencoder research, citing the failure of the tools to provide a reliable toolkit for out-of-distribution downstream tasks when acting on predefined data 42237.
However, a reconciling perspective within the field argues that this skepticism stems from a fundamental misunderstanding of the architecture's intended purpose. Sparse autoencoders are sub-optimal for acting on known, predefined concepts, where standard supervised linear probing is mathematically sufficient 22. Conversely, they remain uniquely powerful for discovering unknown, unanticipated concepts. When researchers utilize dictionary learning, they do not pre-define the features; the unsupervised process organically discovers rich, unpredicted structures hidden deep within the model - such as features that detect backdoors in code, track subtle sycophancy, or process complex logical functions 81322.
Transcoders and the Mapping of Computation
Standard sparse autoencoders are constrained by a fundamental structural limitation: they are trained exclusively to reconstruct a single activation vector back to itself 3846. Therefore, they decode what a neural network represents at a specific, frozen depth, but they cannot explain how the network computes the transition from one mathematical layer to the next 446.
To map computation across the complex non-linearities of the network, researchers developed transcoders 38463940. While a standard autoencoder maps an input to an expanded latent space and decodes it back to the identical input vector, a transcoder takes the input to a specific model component - such as a multi-layer perceptron sublayer - and is trained to predict the resulting output of that component via a sparse bottleneck 19384640.
By learning an input-invariant description of the component's internal behavior, transcoders effectively approximate dense behavior using human-readable feature transformations 194640. Subsequent technical innovations include skip-transcoders, which add an affine skip connection from the input directly to the output. This structural modification allows the transcoder to focus solely on the non-linear transformations applied by the layer, yielding Pareto improvements in both reconstruction loss and baseline interpretability 39404150.
Furthermore, broad interpretability frameworks like Gemma Scope 2 have introduced cross-layer transcoders. These advanced models learn the mapping from concatenated pre-MLP activations across several different layers to concatenated MLP outputs 394151. By synthesizing the flow of information across multiple transformer blocks simultaneously, cross-layer transcoders permit researchers to decode multi-step, dynamic algorithms - such as chain-of-thought reasoning logic, refusal mechanisms, and complex jailbreak resistance pathways - that cannot be isolated to any single neural layer 394151.
Model Cognition and Sparse Feature Circuits
The combined capacity to extract monosemantic features via sparse autoencoders and trace complex computations via transcoders has culminated in the development of Sparse Feature Circuits 424354.
Historically, the mechanistic interpretability community attempted to map language model behaviors using standard circuit discovery - extracting computational subgraphs of raw attention heads and individual neurons responsible for tasks like indirect object identification 195444. However, because raw neurons are highly polysemantic, these classical circuits remained dense, tangled, and exceedingly difficult to interpret or alter 425445.
In 2024, researchers published a methodology that substituted polysemantic neurons with autoencoder-derived latent features as the fundamental nodes within the causal circuit graph 194254. The process of building a sparse feature circuit involves extracting feature activations at every layer, utilizing attribution patching to score the causal contribution of each latent feature to a specific model output, calculating the indirect effect of edges connecting these features, and pruning the graph to isolate minimal subnetworks 42545758. Circuits mapped in this feature space are dramatically more interpretable. They typically consist of dozens of features rather than thousands of neurons, with each node representing a single, labelable concept 54.
This granular understanding allows for unprecedented causal interventions. Researchers have utilized sparse feature circuits to implement selective post-hoc ablations, where specific features deemed spurious or biased are surgically removed from the circuit 424557. If a model relies on unintended demographic cues in a classification task, the specific latents driving that bias can be mathematically clamped to zero during the forward pass. This intervention demonstrably improves the model's out-of-distribution generalization without the need for computationally expensive fine-tuning or model retraining 1345.
Applications Beyond Language: Biological Foundation Models
While the mechanistic interpretability toolkit was initially developed for large language models, the methodologies are increasingly being adapted to analyze biological foundation models 446. Models trained on protein and DNA sequences are currently deployed for variant interpretation, drug design, and gene regulation prediction. However, similar to language models, their internal representations remain profoundly opaque, limiting both fundamental biological insight and clinical trust in model-guided diagnostic decisions 460.
Recent research demonstrates that sparse autoencoders and transcoders can be effectively applied to biological architectures, such as Protein Language Models (PLMs). When applied to models like ESM2, autoencoders successfully disentangle complex biological representations into sparse, biologically relevant features 446. Transcoders have been further utilized to learn a sparsified approximation of the transformation of protein-level representations from one layer to the next, exhibiting interpretability on par with standard autoencoders 46. The ability to extract meaningful biological insights across increasingly powerful models in the life sciences opens the door to greater explainability, allowing researchers to trace how foundation models organize biological logic internally 44660.
Interpretability, AI Governance, and Policy Integration
Mechanistic interpretability has rapidly evolved from an academic, mathematically focused curiosity into a central pillar of international artificial intelligence safety policy 57. As frontier models exhibit accelerating capabilities, regulatory bodies have recognized that external behavioral audits, such as standard red-teaming, are inadequate. A model may harbor hidden malicious capabilities or operate with misaligned goals that only manifest under highly specific, untested deployment conditions 564748.
Frontier Capabilities and The United Kingdom AI Safety Institute
The urgency for robust internal auditing is underscored by empirical capability tracking. The United Kingdom's AI Safety Institute (UK AISI) published the Frontier AI Trends Report, aggregating two years of government-led testing. The report concludes that artificial intelligence capabilities are improving rapidly across every evaluated domain, with performance in areas like autonomous agentic software tasks and cybersecurity doubling approximately every eight months 495065.
Operating under the Department for Science, Innovation, and Technology, the UK AISI treats mechanistic interpretability as a foundational capability for frontier model auditing 5547. The institute's policy framework anticipates a transition where deep structural disclosures, facilitated by tools like sparse autoencoders, may become a prerequisite before high-risk models can be legally licensed or deployed 55.
The Alignment Project Funding Landscape
To accelerate the maturation of these specific auditing technologies, the UK AISI launched the Alignment Project in 2025. Functioning as a global research fund, the initiative awarded an initial 27 million pounds across dozens of projects, backed by an unprecedented coalition of governments and industry partners, including significant capital contributions from OpenAI and Microsoft 6667.
The policy objectives driving this funding focus heavily on the challenge of "eliciting bad contexts" - optimizing prompts or steering vectors to force a model to reveal hidden knowledge, deceptive protocols, or latent capabilities without alerting the underlying model that it is being evaluated 748. By operationalizing sparse autoencoders, cross-layer transcoders, and sparse feature circuits, governance institutes intend to build automated interpretability agents. These systems would be capable of continuously monitoring a frontier model's internal representation state during both training and active deployment, allowing safety protocols to diagnose and debug anomalous behaviors mechanically before they result in catastrophic real-world failures 54868.