Science of Artificial Intelligence Forecasting
Introduction to Capability Prediction Methodologies
The science of artificial intelligence forecasting seeks to quantify, project, and bound the future capabilities of machine learning systems. Predicting the exact timing and nature of artificial intelligence milestones requires a multidisciplinary synthesis of computational scaling trends, psychometric benchmarking, and economic infrastructure modeling. Forecasting methodologies typically divide into three primary approaches: model-based computational extrapolations (often termed "inside-view" models), empirical task-based capability evaluations, and expert elicitation frameworks 12.
Inside-view models operate on the premise that intelligence is primarily a function of computational resources. These models attempt to calculate the raw floating-point operations (FLOP) required to achieve human-level cognition and then project when global infrastructure will economically support such a training run 34. Conversely, empirical task-based evaluations measure the current capabilities of frontier models on standardized tests, establishing trend lines for capability growth based on the maximum time horizon of tasks that systems can successfully complete autonomously 56. Finally, outside-view methodologies rely on the aggregated expertise of domain researchers, industry executives, and calibrated forecasters to integrate qualitative and quantitative signals into probabilistic timelines 77.
As investment in artificial intelligence research scales globally, the precision of these forecasts assumes profound strategic importance. Governments, regulatory bodies, and enterprises rely on capability timelines to design safety protocols, forecast labor market disruptions, and allocate sovereign infrastructure capital 89. However, predicting the advent of specific cognitive milestones - often aggregated under the umbrella of Artificial General Intelligence (AGI) - remains highly sensitive to definitional choices, evaluation noise, and methodological assumptions 111.
Resource Scaling and Computational Trajectories
A foundational driver of artificial intelligence forecasting relies on the empirical tracking of underlying computational resources. The scaling hypothesis, which has dominated deep learning progress over the past decade, posits that model performance is reliably predictable based on the volume of training compute, the size of the pre-training dataset, and the parameter count 1013. Consequently, forecasting physical constraints and financial investments yields a quantitative baseline for capability timelines.
Historical and Frontier Compute Growth
Historically, the computational power utilized to train notable artificial intelligence models grew by approximately 4.5 times annually between 2010 and 2022 10. This period encompassed the rise of deep learning, early transformer architectures, and initial generative models. However, recent empirical analyses indicate a severe structural break in this trend. Between 2023 and 2026, the training compute dedicated to the largest frontier language models surged, growing by an estimated 44 times per year 8. This acceleration signifies a departure from historical baselines, running more than 11 times faster than the already rapid growth observed during the previous decade 8.

This massive expansion is heavily driven by the deployment of hyperscaler infrastructure. The largest known individual training runs in early 2026 commanded around 5e26 FLOP 810. Supporting this computational volume requires infrastructure footprints that exceed gigawatt-scale power consumption. For example, frontier data centers supporting advanced models frequently exceed 1.1 gigawatts in capacity 8. The total computing power of the global stock of artificial intelligence chips is simultaneously expanding at a rate of 3.4 times per year, translating to a doubling of global physical compute capacity roughly every 6.8 to 7 months 10. This global scale-up is heavily concentrated, with five major hyperscale technology companies controlling over two-thirds of the world's artificial intelligence computing power 11.
Algorithmic Efficiency and Cost Dynamics
Raw physical compute growth is compounded by steady software progress. Algorithmic efficiency - defined as the reduction in physical compute required to achieve a static, historical level of model performance - is improving at roughly 3.0 times per year 10. This metric dictates that pre-training compute efficiency effectively doubles every 7.6 months 10. Rather than serving as a moderating economic force, this efficiency gain acts as an accelerant to capability thresholds. As the cost to train models at previous frontier scales plummets, a higher volume of organizations can deploy highly capable systems, widening the base of applied research and pushing the frontier further 8.
Despite these algorithmic efficiency gains, the sheer scale of modern training runs has resulted in exponential cost increases for developers operating at the absolute frontier. The capital required to train a frontier language model has climbed by approximately 3.5 times per year since 2020 10. The absolute cost of premier training runs has scaled from roughly $2 million for early large language models to nearly $390 million by 2024, with subsequent generational iterations projected to cost billions of dollars 10.
Theoretical Inside-View Forecasting Models
A major subset of artificial intelligence forecasting relies on calculating the theoretical computing threshold required to replicate human cognition. These methodologies, known as inside-view models, establish baseline "anchors" to estimate the computational prerequisites for Transformative Artificial Intelligence (TAI). TAI is broadly defined as an intelligence paradigm capable of precipitating an economic and societal shift comparable in magnitude to the Industrial Revolution 4.
The Biological Anchors Framework
First published in 2020 by Ajeya Cotra and widely updated in subsequent years, the Biological Anchors framework models timelines by anchoring the algorithmic computation requirements of neural networks to biological analogues 21213. Because the human brain is the sole existing proof-of-concept for general intelligence, the framework deduces computational bounds based on evolutionary and developmental biology. The framework utilizes multiple primary anchors: 1. Evolution Anchor: Estimates the total computation performed by natural selection from the emergence of the first neurons to the development of the modern human brain 23. 2. Lifetime Anchor: Estimates the computation performed by a human brain maturing from birth to a 32-year-old adult 3. 3. Neural Network Parameter Anchors: Extrapolates the parameter counts of the human brain to estimate the processing power needed to train an artificial neural network of equivalent complexity. This includes evaluating various "effective horizon lengths," which estimate the amount of cognitive processing an agent must perform during individual forward passes to accomplish a task 23.
The initial iteration of the Biological Anchors model combined these weighted computational distributions with economic extrapolations of hardware affordability, producing a median forecast for the arrival of Transformative Artificial Intelligence by approximately 2050 1313. However, by 2022, after observing faster-than-expected progress in algorithmic efficiency and capital investment, Cotra significantly shortened the median timeline to 2040 1213. In this revised projection, the model assigned a 15% probability of reaching the capability threshold by 2030, and a 35% probability by 2036 13.
The Direct Approach to Neural Scaling
In contrast to biological comparative methodologies, the "Direct Approach," developed by researchers at Epoch AI, avoids biological equivalencies entirely. Instead, this framework relies on extrapolating empirically observed neural scaling laws to forecast when a model will achieve a specified benchmark of generalized intelligence 414. The framework operates by calculating the intersection of projected hardware price-performance, total financial investment in training runs, and algorithmic progress multipliers. By combining these variables, the Direct Approach model forecasts the precise year the necessary "effective FLOP" will be available to saturate advanced cognitive benchmarks 413.
The Direct Approach requires fewer free parameters than the Biological Anchors model and generalizes standard scaling laws over multiple orders of magnitude 14. Because it tracks measurable hardware deployment rather than theoretical evolutionary biology, the model can be updated continuously against verifiable financial and hardware datasets 1314. When calibrated on historical scaling data and current investment trajectories, baseline parameters in the Direct Approach suggest a median expectation of transformative systems arriving by 2033, with a 10% probability of achieving the threshold as early as 2025 412.
Comparative Analysis of Computational Models
| Forecasting Framework | Primary Methodological Anchor | Core Inputs | Estimated Median Arrival of TAI |
|---|---|---|---|
| Biological Anchors | Biological processes (evolution, human maturation, brain parameter counts) | Biological FLOP estimates, hardware cost projections, effective horizon lengths | ~2040 (Revised from 2050 original) |
| Direct Approach | Neural network scaling laws | Extrapolated scaling equations, capital investment trajectories, algorithmic efficiency | ~2033 (Base calibration) |
Sources: 23413121314
Empirical Capability Measurement and Task Decomposition
While top-down models estimate raw computational capacity, empirical methodologies evaluate how effectively current models translate that compute into autonomous, real-world behavior. A central challenge in predicting economic utility is that while modern language models possess vast factual knowledge and micro-task proficiency, their reliability degrades severely over long, sequential execution horizons 1519.
The Monolithic Context Degradation Problem
Research into the architectural limits of large language models indicates that monolithic executions fail on multi-step problems due to positional attention biases. Often described in psychometric literature as the "lost in the middle" phenomenon, models systematically underweight critical instructions buried deep within a long context window 20. Consequently, an agent attempting to execute a complex, long-duration task in a single generative pass will inevitably hallucinate, drift from the core objective, or fail to adhere to structural constraints 1920. This inherent flaw renders monolithic models unreliable for automating complex enterprise processes, regardless of the underlying parameter count or intelligence of the model 19.
Architectural Shifts Toward Task Decomposition
Task decomposition is the systematic algorithmic approach of partitioning complex objectives into atomic, verifiable, and independent subtasks 1516.
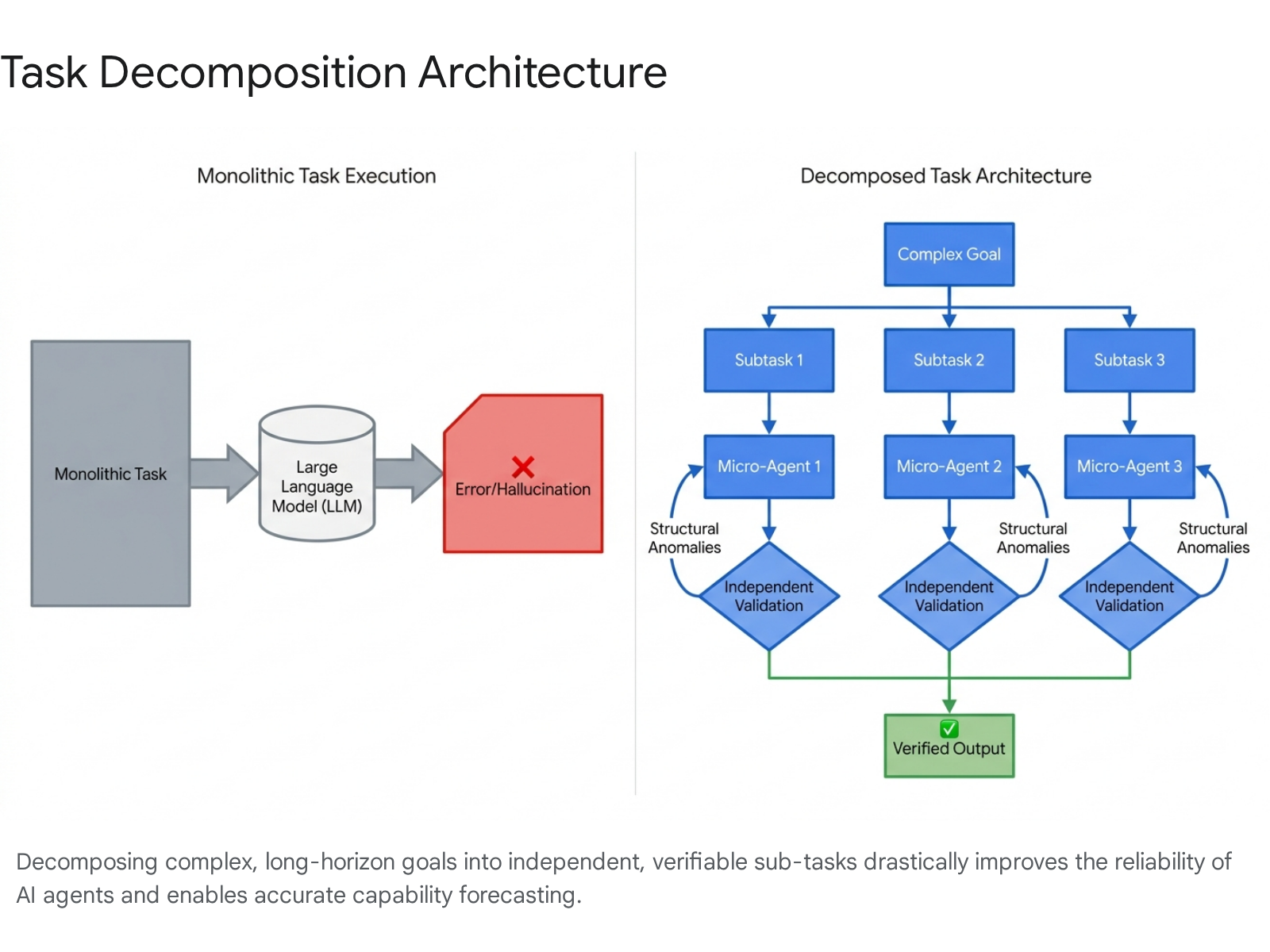
When tasks are systematically decomposed, the cognitive load per inference call is drastically reduced, enabling models to maintain contextual fidelity 1517. Decomposition strategies increasingly leverage formal models such as sequential decomposition, hierarchical planning, and automata-theoretic methods to balance performance with computational resource costs 16.
Empirical studies validate the efficacy of this architecture in forecasting models. In a controlled evaluation using the "Towers of Hanoi" logic puzzle, which requires over one million dependent moves for a 20-disk configuration, unmodified monolithic models collapsed after a few hundred steps due to compounding error rates 19. However, by deploying a step-level voting and structural validation system - termed the "MAKER" architecture - researchers successfully navigated the entire 1,048,575-step sequence with zero errors 19.
Similarly, research comparing human-AI interaction paradigms demonstrates that decomposition enhances predictability. Systems that utilize "Phasewise" decomposition (separating tasks into input assumptions, execution plans, and verifiable code outputs) allow for finer-grained steering and validation compared to standard conversational baselines 23. By reshaping the error distribution of nondeterministic models into managed, recoverable micro-failures, decomposition allows smaller, domain-adapted models to achieve reliability metrics previously assumed to require advanced artificial general intelligence 1917.
The METR Time Horizon Benchmark
To standardize the measurement of autonomous agent capabilities across these architectural shifts, Model Evaluation and Threat Research (METR) developed the "50%-task-completion time horizon" metric. This benchmark defines an agent's capability by the maximum length of time a given task would take a human expert to complete, provided the artificial intelligence can successfully complete that identical task autonomously with a 50% probability 5618.
The evaluation methodology utilizes logistic curve fitting against hundreds of software engineering and research tasks ranging from one second to 16 hours in human-equivalent duration. The tasks are aggregated from rigorous domain datasets including HCAST, RE-Bench, and SWAA 519. By evaluating models released between 2019 and 2023, METR initially established that the 50% time horizon of frontier models doubled approximately every seven months (roughly 212 days) 5620.
Acceleration in Time Horizon Doubling Rates
However, subsequent updates to this empirical benchmark in early 2026 (designated as Time Horizon 1.1) revealed a dramatic acceleration in capability growth. The updated suite expanded testing to 228 tasks and evaluated advanced models utilizing test-time compute paradigms, such as OpenAI's o-series 2021. Analyzing data strictly from late 2024 and 2025 releases, the doubling rate of the time horizon compressed to approximately 3.5 to 4.3 months (roughly 128 to 131 days) 202122.
Under this accelerated trend, models like Claude 3.7 Sonnet demonstrated a 50% time horizon of roughly one hour, while later iterations such as Claude Opus 4.6 pushed the boundary to 718 minutes (nearly 12 hours of human-equivalent labor) 20.
| Benchmark Era | Evaluation Cohort | Estimated Doubling Time | Annual Growth Rate (Log Space) |
|---|---|---|---|
| Historical Baseline (TH 1.0) | Frontier models from 2019 to late 2023 | ~7 months (~212 days) | ~3.3x increase per year |
| Recent Acceleration (TH 1.1) | Frontier models from 2024 to early 2026 | ~3.5 to 4.3 months (~128 to 131 days) | ~10.0x increase per year |
Sources: 5202122
Extrapolating the historical 7-month trend suggested that generalist agents would achieve the capability to independently execute tasks requiring a month of human labor by the late 2020s or early 2030s 52023. If the accelerated 128-day trend sustains, multi-week autonomous capability will arrive significantly earlier, compressing the timeline for profound labor automation 2022.
The Saturation of Cognitive Benchmarks
Forecasting accurate timelines is frequently complicated by the rapid obsolescence of evaluation metrics. Historically, psychometric benchmarks designed to test machine intelligence were expected to pose rigorous challenges for several years; in the current paradigm, benchmarks saturate almost immediately upon release 2425.
Rapid Exhaustion of Traditional Evaluations
Between 2023 and 2025, frontier models rapidly exhausted complex, domain-specific evaluations. For instance, performance on the GPQA (Google-Proof Q&A) benchmark rose by nearly 49 percentage points in a single year, while the software engineering benchmark SWE-bench saw success rates jump from a mere 4.4% in 2023 to 71.7% in 2024 2426.
Benchmark saturation occurs when an evaluation loses reliable discriminative power among top-performing models due to score compression near the performance ceiling 11. Evaluators calculate an "uncertainty-aware saturation index" to determine if a benchmark has stagnated. This saturation does not intrinsically indicate the achievement of artificial general intelligence; rather, it frequently reflects a loss of relative separability among models or a lack of evaluation resolution, rather than complete mastery of a domain's edge cases 1127. Because traditional benchmarks frequently measure single-dimensional skills - such as factual recall or isolated, closed-ended code generation - they fail to capture the multi-dimensional cognitive flexibility required for broad economic and scientific utility 112534.
The Shift Toward Multidimensional Thresholds
In response to rapid saturation, forecasting paradigms are shifting away from defining intelligence as a singular threshold crossed on a static test. Evaluators are increasingly emphasizing interactive, tool-enabled, and cognitively diverse frameworks 2527. For example, the ARC-AGI benchmark targets abstract visual and inductive reasoning, attempting to expose the residual gap between machine memorization and genuine human generalization. While humans score 100% on ARC-AGI 3, unassisted artificial intelligence systems historically scored below 1%, though advanced models integrating test-time compute have recently pushed success rates toward 84% 2534.
Similarly, the Stanford AI Index notes that while models excel at specific mathematical Olympiad challenges via test-time compute, they continue to struggle significantly with complex logic matrices where provably correct, multi-step solutions are required. This highlights a "jagged frontier" of capabilities, where models exhibit superhuman proficiency in isolated domains while failing at basic human-level reasoning in others 2526. Frameworks like DeepMind's 10-dimension cognitive evaluation address this by testing systems against human baselines across perception, memory, and social cognition, yielding a profile of strengths rather than a single aggregate score 34.
Expert Consensus and Prediction Markets
In the absence of a unified, mathematically provable definition of artificial general intelligence, expert elicitation surveys and prediction markets provide probability distributions based on aggregate sentiment. Across all major surveys and financial markets, timeline estimates for transformative capabilities have compressed dramatically in recent years 735.
Divergence Between Industry and Academic Estimates
Forecasts reveal a notable and persistent bifurcation between researchers employed at frontier laboratories and the broader academic economics community 2837. Leaders at prominent commercial organizations routinely predict that artificial intelligence systems will achieve human or superhuman parity across all cognitive domains between 2026 and 2030 3528. Anthropic policy documents, for example, have officially noted expectations of "powerful AI systems" capable of executing Nobel-level scientific research by late 2026 or early 2027 35.
In contrast, broader academic and econometric surveys reflect a more conservative, albeit accelerating, timeline. The 2023 Expert Survey on Progress in AI (ESPAI), polling thousands of published researchers, established a median prediction for "High-Level Machine Intelligence" (HLMI) at 2047 3829. Notably, this 2047 median represented a drastic 13-year compression from the 2060 estimate generated by the exact same survey parameters just one year prior in 2022 3538. The ESPAI survey also cleanly delineated technical capability from economic deployment, forecasting the "Full Automation of Labor" (FAOL) at a distant median of 2116, accounting for regulatory, physical, and integration frictions 38.
Crowdsourced Capability Forecasts
Crowdsourced prediction markets have demonstrated intense, real-time timeline compression. In 2020, the Metaculus community consensus for the arrival of general artificial intelligence hovered around 2070. Following the releases of advanced transformer paradigms, the median prediction plunged. By late 2024 and persisting through early 2026, the aggregate community forecast settled on a median arrival between 2029 and 2031 35294030.
Specific occupational thresholds are forecast to arrive even earlier. The AI Futures Project originally forecast the internal development of a "Superhuman Coder" - defined as an agent capable of executing any software engineering task faster and cheaper than top human engineers - by 2027 3143. In 2025 and 2026 updates, the researchers adjusted this window slightly to 2029 - 2032 due to varying estimates regarding internal feedback loops, yet maintained substantial probability for the 2027 threshold based on the exponential improvements of agentic coding architectures 3143.
Aggregated Artificial Intelligence Timelines
| Forecasting Source | Specific Metric or Definition Assessed | Median Projected Year | Methodological Note |
|---|---|---|---|
| Metaculus Market | First weakly general artificial intelligence | 2027 | Crowd-sourced prediction market aggregation 35 |
| Metaculus Market | General AI (Strict Turing/Robotics) | 2031 | Utilizes stringent criteria including physical robotics 35 |
| Epoch Direct Approach | Transformative AI (TAI) Compute | 2033 | Extrapolation of neural scaling laws 12 |
| Bio Anchors (Cotra) | Transformative AI (TAI) | 2040 | 2022 personal update derived from 2050 baseline 13 |
| ESPAI 2023 Survey | High-Level Machine Intelligence (HLMI) | 2047 | Expert survey of published AI researchers 38 |
| ESPAI 2023 Survey | Full Automation of Labor (FAOL) | 2116 | Accounts for global economic friction in deployment 38 |
Macroeconomic and Societal Impact Forecasting
Forecasting the systemic effects of advancing capabilities requires integrating raw technical timelines with macroeconomic labor models. A major forecasting study conducted between late 2025 and 2026 by the Forecasting Research Institute (FRI) surveyed leading economists, industry experts, and superforecasters regarding the impacts of artificial intelligence on the United States economy by 2030 and 2050 732.
Projections on Labor Force Participation
While the median expert surveyed assigned a 47% probability to a "Moderate Progress" scenario (where systems serve as effective collaborators but do not displace core economic trends), a significant 14% to 23% probability was assigned to a "Rapid Progress" scenario 728. In this rapid trajectory, economists forecast a structural drop in the US labor force participation rate from a 2025 baseline of 62.6% down to 55% by 2050. This equates to the permanent displacement of roughly 10 million jobs directly attributable to algorithmic automation 7.
Research indicates that labor displacement will not occur uniformly. A task decomposition approach to employment forecasting suggests that occupations are not automated outright; rather, the routine cognitive and repetitive subtasks within those occupations are isolated and automated. Depending on institutional contexts and innovation capacity, this can lead to positive employment effects in high-level services while heavily penalizing low-skilled roles, creating heterogeneous labor impacts 33.
The Enterprise Maturity Gap
A critical variable in macroeconomic forecasting is the pace of enterprise adoption. Achieving a cognitive benchmark in a laboratory setting does not guarantee immediate economic integration. Econometric analyses from Singapore highlight this specific "maturity gap." While aggressive national funding has driven a 60.9% domestic enterprise adoption rate, a deeper review reveals significant friction 3435. Within the financial services sector, 75% of small and medium enterprises report using artificial intelligence, yet only 29% have progressed to advanced integrations involving custom systems or multi-model workflows 35. The primary bottlenecks are not the intelligence of the models, but legacy systems integration, data cleanliness, and the establishment of internal regulatory approval processes 35.
AI-Driven Economic and Scientific Applications
Where systems have been successfully integrated, the economic leverage is substantial. The application of artificial intelligence to atmospheric science forecasting provides a clear empirical proof point. The China Meteorological Administration (CMA) has deployed a suite of multimodal models - such as the Fengyuan, Fenglei, and Pangu systems - to forecast extreme weather events 363738.
These neural network models decompose complex atmospheric time series data, achieving linear time complexity compared to the slower log-linear complexity of traditional frequency-based Fourier Transform methods 51. The Pangu model generates high-resolution global forecasts in under ten seconds, extending forecast lead times by 0.6 days while maintaining accuracy parity with traditional physics-based models 38. Given that approximately 40% of China's GDP is weather-dependent, reducing wind speed forecast errors by a fraction of a meter per second yields estimated economic savings of over $3 billion annually, demonstrating the massive compounding value of applied forecasting 38.
Sovereign Trajectories and Geopolitical Forecasting
The science of capability forecasting must increasingly account for geopolitical resource allocation and state-level strategic deployments, as sovereign infrastructure drastically alters the horizons for scientific discovery.
Capability Convergence Between the United States and China
While the United States currently dominates raw private capital investment - reaching $109.1 billion in 2024 compared to China's $9.3 billion - performance gaps at the technological frontier have virtually vanished 26. In 2023, United States models enjoyed double-digit advantages across major reasoning benchmarks. By late 2024, Chinese models had closed the deficit entirely; the gap between top open-weight models and closed-weight frontier models narrowed to a statistically negligible 1.7% 2439. Chinese organizations, operating with heavy governmental support and novel architectures like reinforcement pre-training, frequently match or exceed western counterparts in specific mathematical and coding evaluations 373940.
State-Level Infrastructure Investments in Asia
Advanced capabilities are inextricably linked to sovereign infrastructure investments. Japan is executing a massive technological modernization, committing over ¥10 trillion to semiconductor and artificial intelligence sovereignty by 2030 54. Japan's specific infrastructure market is forecast to grow seven-fold, surpassing $5.5 billion annually by 2026 41. The nation's computing capacity is slated for a 10x expansion to accelerate scientific discovery via national research institutes like RIKEN and the National Institute of Advanced Industrial Science and Technology (AIST) 942. This includes the deployment of the ABCI-Q supercomputer, optimized explicitly for quantum computing and complex life science hypothesis generation, targeting the rapid acceleration of pharmaceutical drug discovery pipelines 95457.
Similarly, Singapore has elevated artificial intelligence to an unprecedented national priority, committing over S$1 billion for public research through its RIE2030 plans 3443. These sovereign investments guarantee that capability scaling will not be bottlenecked purely by private market capital, fundamentally shortening the global timeline for advanced autonomous systems.
Conclusion
The science of artificial intelligence forecasting has evolved rapidly from philosophical speculation into a rigorous interdisciplinary synthesis of compute econometrics, psychometric benchmarking, and algorithmic task analysis. While diverse methodologies naturally yield disparate absolute dates, a strong directional consensus has emerged across the literature: the timelines for profound, transformative capabilities are contracting sharply.
Raw computational scale is breaking from historical baselines to compound at rates exceeding 40 times annually at the frontier, while algorithmic efficiencies consistently double effective capacity every seven months 810. Concurrently, empirical evaluations like the METR time horizons confirm that the maximum duration of complex, multi-step tasks that models can autonomously execute is growing exponentially, driven by architectural innovations in systematic task decomposition and test-time reasoning 51922.
Whether one subscribes to the hardware-centric projections of the Direct Approach (median ~2033), the aggregated expert sentiment of prediction markets (~2031), or the more conservative estimates of broad academic surveys (~2047), the data indicates that models capable of automating weeks or months of high-level cognitive labor will likely be technically viable within the next decade 122338. The primary challenge for the next phase of forecasting will be cleanly differentiating between the theoretical capability of an artificial system to perform a task, and the complex economic, regulatory, and architectural frictions that dictate when that system is actually deployed at scale in the global economy.