Quantum machine learning speedups compared to classical AI
The intersection of quantum mechanics and machine learning represents one of the most heavily theorized and rigorously debated frontiers in contemporary computer science and physics 12. By mapping classical or quantum-native data into the exponentially large vector spaces inherent to quantum systems and leveraging the physical phenomena of superposition, entanglement, and quantum interference, researchers hypothesize that Quantum Machine Learning (QML) could surpass classical machine learning in both computational time complexity and feature representation 245.
The central inquiry dominating the discipline is whether quantum computers offer genuine, mathematically provable speedups over classical artificial intelligence, or if the projected capabilities are primarily the result of idealized theoretical models that fail to account for severe hardware realities and highly optimized classical algorithms. An exhaustive analysis of academic literature, algorithm development, and hardware roadmaps between 2018 and 2026 reveals a highly nuanced landscape. While early claims of exponential algorithmic speedups for processing classical data have been largely systematically dismantled through a process known as "dequantization," new frameworks for processing quantum-native data and streaming classical data have successfully established mathematically rigorous domains of true quantum advantage 3489.
This report examines the underlying mathematical mechanisms of QML, the severe limitations imposed by classical data loading, the theoretical boundaries of algorithmic speedups, the trajectory of fault-tolerant hardware, and the geopolitical investment landscape funding these technological developments.
Mathematical Foundations of Quantum Information Processing
At its core, classical machine learning operates by optimizing parameters across high-dimensional feature spaces to identify patterns, classify data, or generate predictive text 24. These models process information sequentially or in parallel using bits and floating-point arithmetic. QML diverges fundamentally from this paradigm by encoding information into quantum states, frequently represented by density matrices, with transformations executed via unitary operations (quantum gates) 12.
A single quantum system containing $n$ qubits exists in a $2^n$-dimensional complex vector space, known as a Hilbert space. This mathematical property allows an $n$-qubit system to inherently represent an astronomically large feature space 5. The theoretical appeal of QML relies heavily on the premise that this exponential dimensionality can be utilized to evaluate global properties of a dataset simultaneously through quantum parallelism, rather than evaluating data points sequentially 256.
QML models generally fall into distinct combinatorial categories based on the nature of the data being processed and the hardware executing the algorithm:
- Classical-Classical (CC): Standard machine learning using classical data on classical hardware.
- Quantum-Classical (QC): Quantum algorithms designed to process classical data. This is often termed "quantum-enhanced machine learning" and represents the vast majority of commercial enterprise applications 17.
- Classical-Quantum (CQ): Classical machine learning applied to understand, optimize, or control physical quantum systems, such as optimizing quantum error correction codes or learning Hamiltonians 18.
- Quantum-Quantum (QQ): Quantum algorithms processing quantum states directly generated from physical quantum systems, completely bypassing classical data translation 18.
The vast majority of commercial interest, venture capital, and industry hype surrounds the QC domain - using quantum processors to accelerate classical tasks such as image recognition, natural language processing, and financial portfolio optimization 178. However, this specific domain is precisely where the theoretical advantages of QML face the most severe algorithmic and physical bottlenecks.
Algorithmic Speedups and the Dequantization Paradigm
For much of the 2010s, researchers proposed various QML algorithms that promised exponential speedups over their best-known classical counterparts 14. A foundational example was the 2016 algorithm by Kerenidis and Prakash for recommendation systems, which mathematically demonstrated an exponential reduction in processing time compared to classical recommendation engines 314. This algorithm was widely considered one of the strongest candidates for demonstrating provable exponential speedups in machine learning 3.
This assumption of intrinsic quantum superiority was fundamentally challenged by the work of researcher Ewin Tang, initiated in 2018 and expanded upon through 2024. Tang successfully "dequantized" the Kerenidis-Prakash recommendation algorithm, proving that a classical randomized algorithm could achieve similar performance metrics with only a minor polynomial overhead, rather than an exponential slowdown 31415.
The Mechanism of Dequantization
Dequantization exposes a critical, often minimized assumption hidden within many early QML proposals: the reliance on Quantum Random Access Memory (QRAM) 916. Many QML algorithms achieve their exponential speedup by assuming that massive amounts of classical data can be mapped into a quantum superposition in logarithmic time, $O(\log N)$. To do this, theorists relied on an idealized QRAM structure that allows quantum computers to query classical databases entirely in superposition 169.
Tang demonstrated that if a quantum algorithm is granted the powerful assumption of QRAM, a classical algorithm must be granted a mathematically equivalent data structure to ensure a fair complexity comparison. Specifically, Tang provided the classical algorithm with $l^2$-norm sampling access to the input data distributions 315. With this specific access, classical algorithms can utilize randomized sketching and Monte Carlo techniques to accurately mimic the quantum state's probability distribution 1019.
Following Tang's breakthrough, a generalized framework emerged - formalized by researchers including Chia, Gilyén, Li, Lin, Tang, and Wang - that successfully dequantized a wide array of QML algorithms operating on low-rank matrices 151019. The algorithms proven to lack exponential quantum advantage under these specific data-access assumptions include:
- Quantum Principal Component Analysis (QPCA)
- Quantum Support Vector Machines (QSVM)
- Supervised clustering algorithms
- Low-rank stochastic regression
- Sublinear classical algorithms for solving low-rank linear systems
By utilizing stochastic techniques and exploiting special properties within the input data, these classical counterparts replicate the quantum output with minor polynomial overhead 151020. Consequently, the scientific consensus shifted drastically: for standard classical data represented as dense, low-rank matrices, QML does not offer an exponential algorithmic speedup if the classical counterpart is granted equivalent memory access 31511.
| Algorithm | Original Quantum Promise | Dequantization Status | Classical Counterpart Performance |
|---|---|---|---|
| Recommendation Systems | Exponential speedup | Dequantized (Tang, 2019) | Polynomial slowdown using $l^2$-norm sampling 314 |
| Principal Component Analysis | Exponential speedup via eigenvalue estimation | Dequantized | Randomized classical sketching matches performance 1510 |
| Support Vector Machines | Exponential speedup via quantum kernel estimation | Dequantized (for low-rank data) | Comparable complexity under QRAM-equivalent assumptions 1510 |
| Supervised Clustering | Exponential speedup | Dequantized | Polynomial equivalent established 151019 |
Classical Data Loading and State Preparation Bottlenecks
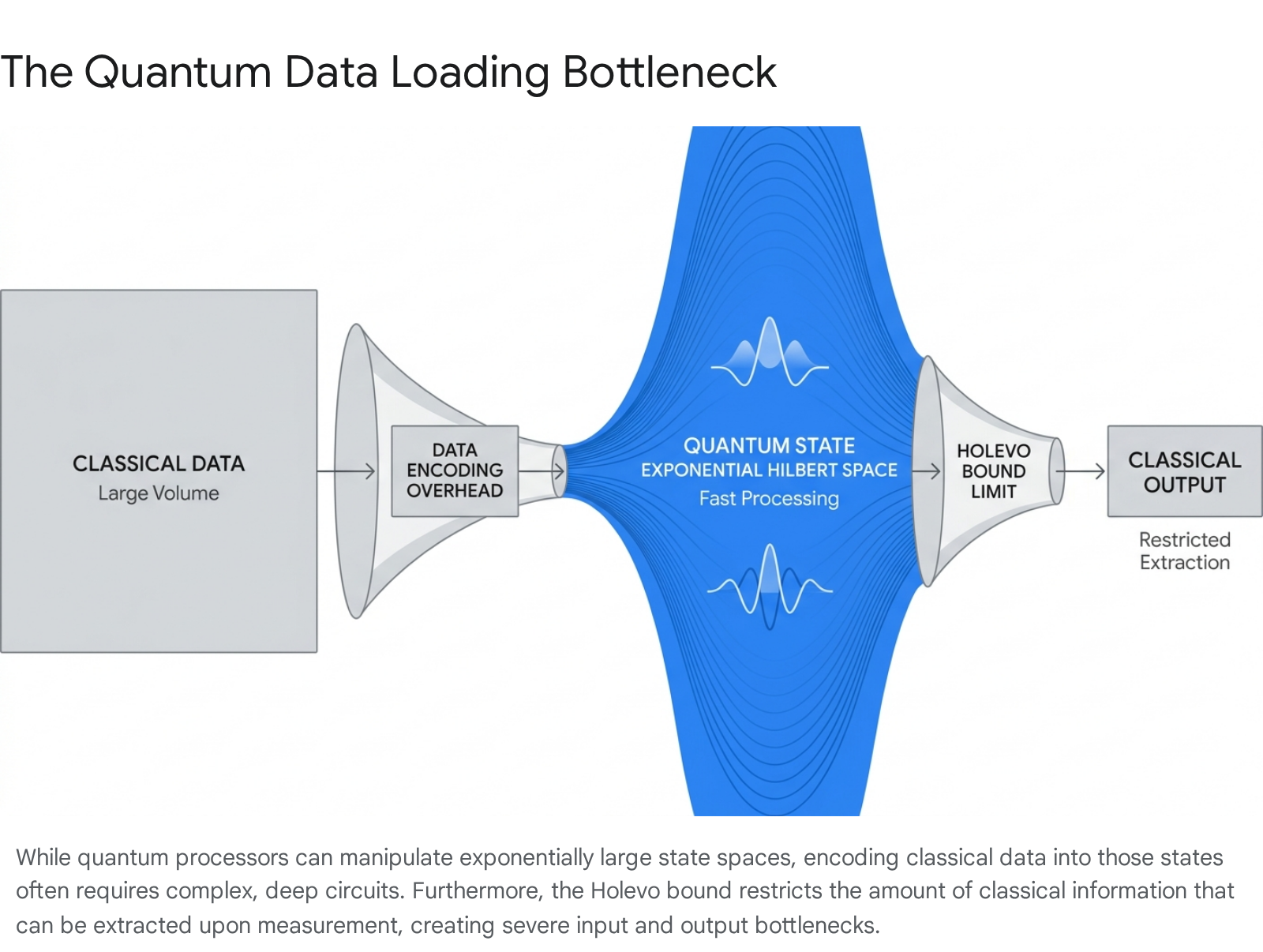
Even if a QML algorithm resists mathematical dequantization, it faces a severe physical barrier regarding the initialization of classical data into a quantum state. This is formally known in the literature as the state preparation or data loading bottleneck 4816.
Before a quantum processor can manipulate classical data - such as a high-resolution image, a complex molecular structure, or a financial time series - the classical bits must be translated into the amplitudes, basis states, or phases of qubits. Given the diverse applications of QML, multiple encoding strategies have been developed, each with distinct scaling challenges:
| Encoding Method | Mechanism | Primary Limitation |
|---|---|---|
| Basis Encoding | Maps binary strings directly to computational basis states (e.g., classical '1001' becomes $ | 1001\rangle$). |
| Amplitude Encoding | Normalizes continuous classical vectors and maps them to the continuous amplitudes of a quantum state. | Allows exponential compression (encoding $2^n$ values in $n$ qubits), but preparing the state natively requires an intractable $O(2^n)$ quantum gates 52223. |
| Angle / Sinusoidal Encoding | Encodes classical features as rotation angles of quantum gates. | Only loads one feature per qubit; fails to exploit the exponential Hilbert space for compression 623. |
For dense, high-dimensional data, basic encoding strategies like amplitude encoding require deep, complex quantum circuits that introduce overwhelming noise on current hardware 2223.
The Impact of the Holevo Bound
Furthermore, the extraction of data from a quantum system is strictly restricted by the Holevo bound. The Holevo bound mathematically stipulates that while $n$ qubits can represent an exponentially large data state in internal superposition, the maximum amount of classical information that can be extracted via measurement is exactly $n$ bits 42224.
This physical asymmetry creates a severe operational constraint for end-to-end QML applications: 1. Loading $N$ classical data points into a quantum state takes linear time $O(N)$ or requires theoretical, currently unbuilt QRAM architectures 2325. 2. Once successfully loaded, the quantum computer can process the high-dimensional space exponentially faster. 3. Due to the Holevo bound, reading the exact results out into a classical format collapses the superposition, destroying the probability wave and limiting retrieval 4922.
Because of these I/O bottlenecks, for many realistic scenarios in the Noisy Intermediate-Scale Quantum (NISQ) era, the physical time required to encode the data into the machine and extract the answer completely nullifies any computational speedup achieved during the quantum processing phase 1692312.
Near-Term Heuristics and Noisy Hardware Constraints
The current generation of quantum hardware exists within the Noisy Intermediate-Scale Quantum (NISQ) era - a term coined by physicist John Preskill in 2018 to describe systems that possess between 50 and 1,000 physical qubits but lack the capability for large-scale quantum error correction 1328. In this regime, qubits easily lose their delicate quantum properties (a process known as decoherence) when exposed to minimal environmental disturbances like heat, vibrations, or electromagnetic interference 2930.
Because deep algorithms cannot execute reliably on error-prone hardware, the prevailing approach for QML in the near-term relies on Variational Quantum Algorithms (VQAs) 14. VQAs are hybrid quantum-classical algorithms. A Parameterized Quantum Circuit (PQC) prepares a quantum state using a shallow circuit depth; the state is then measured to evaluate a cost function, and a classical optimizer (such as gradient descent) updates the circuit's parameters iteratively 61314. Variational Quantum Classifiers (VQCs) and Quantum Neural Networks (QNNs) operate entirely on this principle, bypassing the need for deep circuits by offloading the heavy optimization tasks to classical CPUs 614.
The Barren Plateau Phenomenon
While theoretically promising for circumventing hardware noise, VQAs face a severe mathematical limitation known as "Barren Plateaus." In foundational research published by McClean et al. (2018), it was discovered that in high-dimensional parameterized quantum circuits, the gradient of the cost function vanishes exponentially as the number of qubits increases 143215.
This "flatness" in the optimization landscape means that classical optimizers cannot find the minimum to update the weights, rendering large-scale VQAs effectively untrainable without highly specific, structured initializations 414. Due to these optimization failures, empirical benchmarks of NISQ-era algorithms often show underwhelming results compared to classical baselines. A comprehensive 2025 benchmark study comparing a range of variational quantum algorithms against classical machine learning models for time series forecasting across 27 prediction tasks found that quantum models consistently struggled to match the accuracy of simple classical counterparts of comparable complexity 16.
Fault-Tolerant Algorithmic Architectures
To achieve the exponential speedups theorized by quantum mechanics, QML must transition from heuristic VQAs to deep, mathematically rigorous algorithms that require Fault-Tolerant Quantum Computing (FTQC) 42835.
The Harrow-Hassidim-Lloyd (HHL) Algorithm
Introduced in 2009, the Harrow-Hassidim-Lloyd (HHL) algorithm is the foundational bedrock of FTQC algorithmic theory for machine learning. It is designed to solve systems of linear equations of the form $Ax = b$ 1136.
Classically, finding the vector $x$ takes time polynomial in $N$ (the number of variables), typically scaling as $O(N\kappa)$ where $\kappa$ is the condition number of the matrix $A$. The HHL algorithm reduces this complexity to $O(\log(N)\kappa^2)$, providing a true exponential speedup in the dimension $N$ 113738. Because matrix inversion and linear algebra form the mathematical engine of machine learning optimization, HHL theoretically enables quantum support vector machines, quantum neural networks, and least-squares learners to operate on feature spaces too vast for classical supercomputers 3617.
However, the HHL algorithm possesses strict mathematical prerequisites that limit its immediate applicability: 1. Matrix Sparsity: The input matrix $A$ must be sparse, containing relatively few non-zero entries per row 113738. 2. Conditioning: The matrix must be well-conditioned, exhibiting a low condition number $\kappa$ 1137. 3. State Preparation: The vector $b$ must be efficiently loaded into the quantum state $|b\rangle$ without requiring $O(N)$ operations 91137. 4. Output Extraction Limitations: The algorithm outputs the solution as a quantum state $|x\rangle$. Measuring the state to determine every specific entry of $x$ would require repeating the algorithm $O(N)$ times, completely destroying the exponential speedup. Therefore, the user must only require aggregate scalar properties of $x$, such as an expectation value $\langle x|M|x\rangle$ for some operator $M$ 91136.
While Tang's work successfully dequantized dense, low-rank systems, the exponential speedup of HHL remains mathematically robust for sparse, high-rank matrices where classical approximation algorithms fail 3738.
Domains of Mathematically Proven Quantum Advantage
To separate industry hype from reality, it is necessary to identify where QML avoids the pitfalls of dequantization, barren plateaus, and classical data loading overheads. Recent academic and empirical breakthroughs highlight two specific domains of genuine quantum advantage.
Learning from Quantum-Native Data
The most uncontested domain for QML is the analysis of quantum-native data - data generated directly from a quantum physical system, such as a molecule, a superconducting qubit, or a quantum material sensor. In these Classical-Quantum (CQ) or Quantum-Quantum (QQ) paradigms, the classical data loading bottleneck simply does not exist because the data is inherently formatted as a quantum state 48.
A classical machine learning algorithm operating on quantum systems must first measure the system. This act of measurement destroys the quantum superposition, collapsing it into a classical "snapshot." To fully reconstruct a quantum state composed of $n$ qubits, classical algorithms require approximately $O(2^n)$ discrete experiments 4.
Conversely, a quantum machine learning algorithm can directly interact with the unmeasured quantum state. By utilizing techniques like Bell measurements - where two saved copies of a quantum state are entangled and measured simultaneously - the QML algorithm evaluates correlations directly without collapsing the state prematurely 14. In an experiment utilizing Google's Sycamore processor, researchers demonstrated that QML required only a linear $O(n)$ number of experiments. For a 20-qubit system, this mathematical scaling resulted in the QML algorithm requiring 10,000 times fewer measurements than classical models to reach a 70% prediction accuracy 4. Crucially, this advantage is information-theoretic; it is permanent and cannot be matched by any future increase in classical computing power 4.
Quantum Oracle Sketching (2026 Breakthrough)
While QML on classical data has long been hindered by QRAM assumptions, an April 2026 publication by a joint Caltech, Google Quantum AI, and MIT team introduced a novel framework titled "Quantum Oracle Sketching" that established a provable exponential space advantage for processing massive classical data 8924.
The algorithm circumvents the theoretical QRAM requirement by processing classical data as a continuous stream. For each classical data sample observed, the algorithm applies a small, incremental quantum rotation and immediately discards the sample without storing it in memory 8924. These sequential rotations accumulate to incrementally approximate a target quantum oracle "on the fly."
Coupled with a readout technique known as interferometric classical shadows, Quantum Oracle Sketching completely bypasses the data loading and Holevo measurement bottlenecks 241819. The research proved mathematically that a quantum computer of polylogarithmic size (requiring fewer than 60 logical qubits) could perform complex classification and dimension reduction on massive datasets, consuming four to six orders of magnitude less memory than the most efficient classical sparse-matrix algorithms 919. This advantage persists irrespective of computational complexity conjectures (i.e., even if BPP = BQP) and relies strictly on the mathematical constraints of the Born rule 91920. The team validated these advantages using real-world datasets, including single-cell RNA sequencing and IMDb movie review sentiment analysis 919.
Error Mitigation and Algorithmic Resilience
Given that fault-tolerant systems requiring millions of physical qubits are not yet available, researchers are actively developing Quantum Error Mitigation (QEM) techniques to extend the utility of current NISQ hardware. Unlike Quantum Error Correction (QEC), which uses redundant qubits to actively fix errors during computation, QEM involves the classical post-processing of quantum measurement outcomes to mathematically rectify noise-induced effects 2921.
Common data-driven QEM techniques include: * Zero-Noise Extrapolation (ZNE): Running quantum circuits at artificially elevated noise levels and mathematically extrapolating the results backward to predict a zero-noise outcome 2921. * Probabilistic Error Cancellation (PEC): Actively reversing specific profiles of quantum noise using mathematical models of the hardware's error channels 29. * Virtual Distillation (VD): Preparing multiple copies of a quantum state to identify and discard erroneous outcomes 21.
In 2023, researchers proposed unifying these disparate techniques under a single data-driven framework called UNITED (UNIfied Technique for Error mitigation with Data) 21. Furthermore, a significant 2024 presentation by IBM researchers at the APS March Meeting detailed the integration of classical machine learning directly into the error mitigation pipeline (ML-QEM). By training classical models - including linear regression, random forests, multi-layer perceptrons, and graph neural networks - on device-noise profiles, researchers successfully mitigated errors on diverse quantum circuits containing up to 100 qubits 2245. The ML-QEM approach drastically reduced the exponential computational overhead typically associated with standard mitigation techniques, yielding near noise-free results for quantum algorithms running on imperfect hardware 2245.
Structural Constraints in Large Language Models
The unprecedented commercial and technical success of Large Language Models (LLMs) like OpenAI's GPT-4 and Meta's LLaMA has triggered widespread speculation regarding the quantum acceleration of generative artificial intelligence. However, technical consensus across the quantum industry firmly debunks the notion that quantum computers will replace classical GPUs for end-to-end LLM training in the foreseeable future 23472449.
The limitations preventing quantum LLM training are severe and structural. Modern LLMs contain hundreds of billions, or even trillions, of trainable parameters. Because every quantum parameter requires a distinct representation within a delicate qubit state, running a production-scale LLM natively would demand billions of high-fidelity, coherent qubits 232450. Current quantum processors support only a few hundred to a thousand noisy physical qubits, which degrade due to environmental decoherence within fractions of a second 3023. Furthermore, LLM architectures rely heavily on approximate vector additions and self-attention mechanisms that are already hyper-optimized for parallel execution on classical hardware, leaving little room for quantum parallelism to provide an edge 24.
Hybrid Quantum-Classical Adaptations
Despite the impossibility of full native quantum LLM training, hybrid approaches show early, specialized viability for fine-tuning. In 2026, researchers at Multiverse Computing successfully demonstrated the integration of quantum capabilities into a production-scale classical LLM using block-diagonal unitary (BDU) adapters.
Instead of attempting to move the entire massive network to a quantum processor, the research team inserted Cayley-parameterized unitary adapters specifically into a pre-trained classical 8-billion-parameter Llama 3.1 model. Executing this fine-tuning step on a 156-qubit IBM processor required only 6,000 additional quantum parameters to achieve a 1.4% improvement in perplexity 2350. The experiment demonstrated that quantum layers could aid in capturing highly complex, non-local language correlations that classical architectures struggle to identify 2350. Thus, while quantum computers will not train foundation models natively, quantum-enhanced architectures may be utilized as specialized classification heads or parameter-efficient fine-tuning modules to reduce overall energy consumption 234925.
Hardware Scaling and the Transition to Logical Qubits
The long-term viability of exponential QML speedups is inextricably linked to the progression of underlying quantum hardware. To execute deep, mathematically proven algorithms like HHL, hardware must transition from fragile physical qubits to stable logical qubits 3026. Logical qubits utilize Quantum Error Correction (QEC) protocols to spread a single unit of quantum information across dozens or hundreds of physical qubits, detecting and correcting errors actively without measuring and destroying the underlying quantum state 282930.
The hardware industry is currently undergoing the official transition from the NISQ era toward the FTQC era 42835. Milestones achieved across 2024 and 2025 validate this trajectory. Google Quantum AI's "Willow" chip (105 qubits) successfully demonstrated that scaling physical qubits can reduce overall logical error rates, crossing the critical threshold necessary for eventual fault tolerance 2823.
IBM's updated 2024 technology roadmap explicitly codifies the timeline for logical qubit scaling. Recognizing that raw physical qubit counts are meaningless without corresponding improvements in gate fidelity, IBM's roadmap projects the realization of quantum utility through modular architectures and advanced error correction 272855.
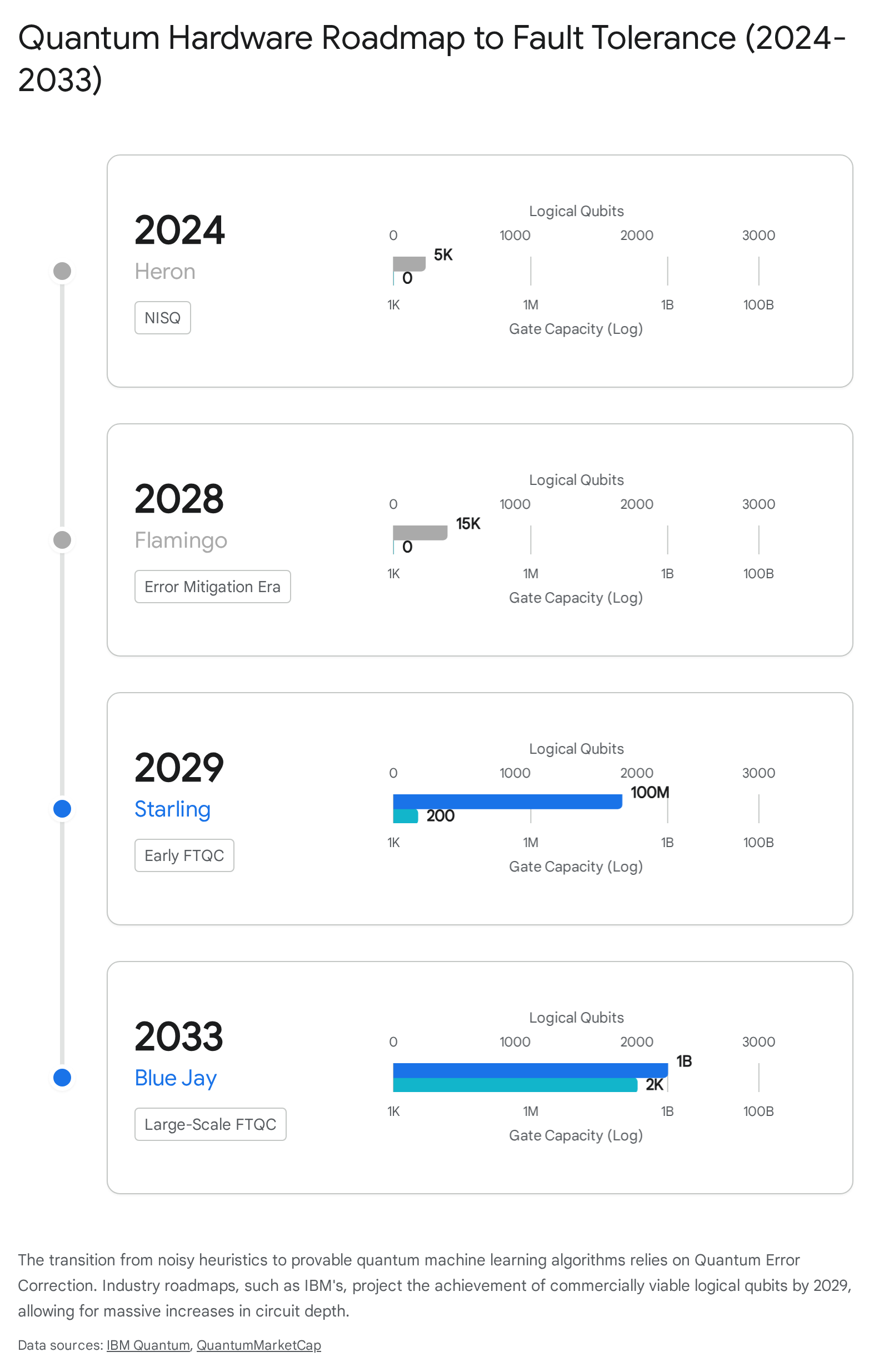
Key milestones in the transition to fault tolerance include: * 2024 (IBM Heron): Execution of circuits containing 5,000 gates with the lowest error rates achieved to date 2755. * 2028 (IBM Flamingo): Execution of circuits containing 15,000 gates using advanced error mitigation techniques 2728. * 2029 (IBM Starling): Delivery of the first commercial fault-tolerant quantum computer, utilizing approximately 200 logical qubits capable of running 100 million gate operations 272856. * 2033 (IBM Blue Jay): Deployment of a large-scale FTQC system utilizing 2,000 logical qubits capable of executing 1 billion gates 272829.
Geopolitical Funding Mechanisms and Legislative Strategies
The realization of fault-tolerant QML architectures requires enormous, sustained capital expenditure. In recognition of the profound economic and national security implications - ranging from the decryption of cryptographic standards to the acceleration of sovereign artificial intelligence - governments and private entities have committed over $65.9 billion globally to quantum initiatives through 2026 58.
The global quantum ecosystem is distinctly tri-polar, divided fundamentally by funding mechanisms and strategic intent:
The United States
The US ecosystem is predominantly driven by aggressive private venture capital and large technology conglomerates (including Google, IBM, and Microsoft). In 2024, private global investment in quantum startups surged 50% year-over-year to nearly $2.0 billion, with the US capturing roughly 50% of this global capital flow 5930. Additionally, the first three quarters of 2025 alone saw $1.25 billion injected into quantum startups globally 3132. Federal initiatives, such as the DARPA Underexplored Systems for Utility-Scale Quantum Computing (US2QC) program, seek to evaluate whether computational value can exceed hardware costs by 2033 31. Consequently, US companies dominate hardware commercialization and maintain a substantial lead in overall quantum computing patents granted globally 33.
China
China approaches quantum supremacy as a critical, state-directed imperative, executing the largest centralized investment strategy globally. The Chinese government has committed an estimated $15 billion toward quantum technologies, significantly outpacing the estimated $6 billion in US federal funding 5832. In March 2025, China announced the establishment of a 1 trillion RMB ($138 billion) venture capital guidance fund targeting deep tech, including quantum technologies and artificial intelligence 583132. Unlike the US, China's research focus heavily skews toward quantum communications and security networks - representing 39% of global publications in the field - to establish physically unhackable state infrastructure and sovereign supply chains 5833.
Europe and the 2026 Quantum Act
Europe generates the highest concentration of quantum research publications and talent globally, driven by academic institutions and steady public funding. However, the continent has historically failed to translate this academic excellence into commercial dominance 3065. In 2024, despite housing roughly 32% of global quantum companies, Europe attracted only 5% of global private quantum capital 593066.
To address deep market fragmentation across its member states and combat severe supply chain vulnerabilities, the European Commission developed the Quantum Europe Strategy in 2025, paving the way for the European Quantum Act 653435. Set for formal legislative proposal in Q2 2026 and targeted for adoption by 2027, the Quantum Act aims to unify standardizations, pool transnational resources, and financially incentivize the manufacturing of sovereign quantum hardware 59653435. For heavily regulated sectors like European banking, the Act intersects critically with mandates like the Digital Operational Resilience Act (DORA) and the Network and Information Security 2 (NIS2) Directive, enforcing a mandatory transition to post-quantum cryptographic (PQC) standards to mitigate "harvest now, decrypt later" cyber threats 6634.
| Region | Primary Funding Model | Strategic Imperatives & Market Position | Investment Scale |
|---|---|---|---|
| United States | Private VC, Technology Conglomerates | Dominates hardware patents, enterprise commercialization, and venture funding. Focus on gate-based FTQC. | Capture of ~50% of global private capital; ~$6B Federal funding 3233. |
| China | State-directed Public Funding | Focus on sovereign supply chains and unhackable quantum communication networks. Closed ecosystem. | ~$15B state funding; 1 Trillion RMB deep-tech guidance fund 583132. |
| Europe | Supranational Public Grants | High academic output, low private commercialization. Focus on standardizing the fragmented market via the Quantum Act. | ~$11B+ public investment; captures only 5% of global private capital 59303233. |
Conclusion
The assertion that Quantum Machine Learning will rapidly eclipse classical artificial intelligence across all domains is mostly hype, heavily influenced by an early theoretical reliance on the unrealistic assumption of Quantum RAM. The rigorous mathematical process of dequantization has conclusively proven that for standard, classical data represented in dense, low-rank matrices, randomized classical algorithms can effectively match the exponential speedups originally claimed by quantum theory 31510. Furthermore, integrating QML into massive, probabilistically driven models like classical Large Language Models remains fundamentally obstructed by hardware memory limits, parameter disparities, and the classical data loading bottleneck 162324.
However, the field of Quantum Machine Learning is not entirely illusory; it offers profound, mathematically proven acceleration in highly specific, structured domains. For quantum-native data, QML algorithms analyze exponentially large state spaces directly, bypassing the Holevo bound and reconstructing models exponentially faster than any conceivable classical counterpart 48. Additionally, novel streaming architectures like Quantum Oracle Sketching (2026) have established that exponential space advantages are attainable for classical data processing using as few as 60 logical qubits, circumventing the need for QRAM altogether 924.
The realization of these theoretical frameworks now awaits the engineering transition from the NISQ era to Fault-Tolerant Quantum Computing. With major hardware providers slated to deliver the first large-scale, error-corrected quantum computers by 2029 2756, QML is poised to shift from an academic exercise in heuristic approximation to a specialized, commercially devastating tool for physical simulation, cryptography, and high-dimensional sparse data analysis.