Probing Neural Network Representations
Theoretical Foundations of Representation Probing
The unprecedented computational capabilities of deep neural networks, particularly large language models (LLMs) and vision-language models (VLMs), are driven by complex internal representations that remain largely opaque. Mechanistic interpretability seeks to reverse-engineer these opaque systems to guarantee safety, alignment, and reliability. Within this domain, probing has emerged as a fundamental diagnostic methodology. Probing refers to the practice of evaluating the internal activations - such as hidden states, attention maps, or multi-layer perceptron (MLP) outputs - of a frozen pre-trained neural network to determine whether specific human-interpretable concepts, linguistic properties, or factual knowledge are encoded within those continuous vector spaces 123.
At its core, a probing classifier (often referred to simply as a "probe") is a secondary, usually shallow, machine learning model trained explicitly on the internal representations extracted from a primary model 23. The primary network's parameters are kept rigidly frozen during this diagnostic process. If the secondary classifier can accurately predict a specific property - such as the syntactic role of a word, the empirical truth value of a generated statement, or the presence of a specific visual object - solely from the extracted latent representation, researchers infer that the primary model has independently learned to encode that property 13. Probes operate as non-intrusive diagnostic instruments, functioning akin to a neuroimaging scan for artificial networks, providing direct quantitative measures of how semantic content evolves across varying network depths and how specific feature spaces correlate with subsequent downstream predictions 1.
Diagnostic Classifiers and the Linear Separability Hypothesis
The most ubiquitous implementation of this analytical technique relies on linear classifiers, commonly termed linear probes. The prevailing theoretical assumption governing structural probing is the "linear separability hypothesis." This hypothesis posits that if a neural network genuinely utilizes a specific semantic feature or concept for its internal computations, that feature should be linearly accessible to the subsequent operational layers of the network 245. Because the final classification layers of most prevailing transformer architectures are linear, semantic features that are encoded in highly non-linear or convoluted topologies might be fundamentally inaccessible to the model's own output generation mechanisms 6.
Consequently, researchers generally default to linear probes over complex non-linear diagnostic models. A highly expressive non-linear probe, such as a deep multi-layer perceptron, might achieve high classification accuracy not because the primary model explicitly represents the target concept in a usable format, but because the probe itself possesses sufficient computational capacity to learn the concept from raw, entangled data points 57. To mitigate this risk, researchers deploy selectivity tests, training probes on randomized control labels. If a non-linear probe achieves high accuracy on randomized noise, it indicates that the probe is memorizing the dataset rather than drawing a valid decision boundary based on the primary model's underlying representations 5. Thus, prioritizing linear probes rigidly limits the capacity of the diagnostic classifier to learn the task independently, ensuring that the resulting performance metrics strictly reflect the quality of the primary model's internal representations rather than the probe's expressivity 27.
Structural Versus Behavioral Probing Paradigms
Interpretability methodologies are broadly classified into two distinct operational paradigms: structural probing and behavioral probing 2. Structural probing directly extracts a latent vector - for example, the residual stream activation at a specific transformer block - and passes it to an external diagnostic classifier to compute the presence of a feature 2. Behavioral probing, conversely, observes the model's end-to-end output variations in response to targeted input perturbations. A common behavioral probe might involve masking a syntactic token to determine if the model correctly infers the underlying linguistic structure based solely on statistical outputs 2.
While behavioral probing requires no secondary classifiers and avoids the complexities of latent space extraction, structural probing provides critical layer-by-layer spatial resolution. This high-resolution mapping allows researchers to track the exact computational juncture at which an abstraction solidifies. Diagnostic classifiers applied sequentially across varying depths of a network can reveal, for instance, that lower-level syntactic tasks are reliably resolved in the earliest attention blocks, whereas complex semantic, temporal, or contextual tasks require the integration of deeper architectural layers 7.
Methodological Frameworks and Computational Tradeoffs
The implementation of advanced probing methodologies requires researchers to navigate complex trade-offs between computational overhead, diagnostic expressivity, and the causal reliability of the resulting inferences. Standard structural probing merely establishes correlation; it mathematically proves that information is present in the vector space, but it fundamentally cannot prove that the model's algorithms actually utilize that information to generate subsequent outputs 89.
Subnetwork Probing and the Pareto Hypervolume
The theoretical debate regarding optimal probe complexity centers on the tension between completeness - the ability of a probe to fully transform and extract the representation of a target property - and selectivity - the ability of a probe to minimally impact non-targeted properties 8. To address this rigorously, researchers have proposed evaluating the "Pareto hypervolume" of probe performance, a metric that quantifies the fundamental trade-off between a diagnostic model's complexity and its absolute accuracy 10.
Under this framework, low-complexity probing methods frequently outperform standard dense classifiers. Subnetwork probing, an approach that identifies an existing, sparse subnetwork within the primary model through targeted pruning rather than training a new external classifier, has been shown to Pareto-dominate standard MLP probing 7. Because a subnetwork probe is heavily constrained, it achieves higher diagnostic accuracy on actual pre-trained models while failing completely to learn when applied to randomized control models. This dynamic proves that subnetwork probes are exceptionally efficient at locating intrinsic properties without possessing the independent parameter capacity to learn the task from scratch 7.
Causal Interventions and Iterative Null-Space Projection
Because passive structural probing only identifies correlations, researchers engineered causal probing (often termed interventional probing) to determine whether a neural network actively relies on the encoded information 8.
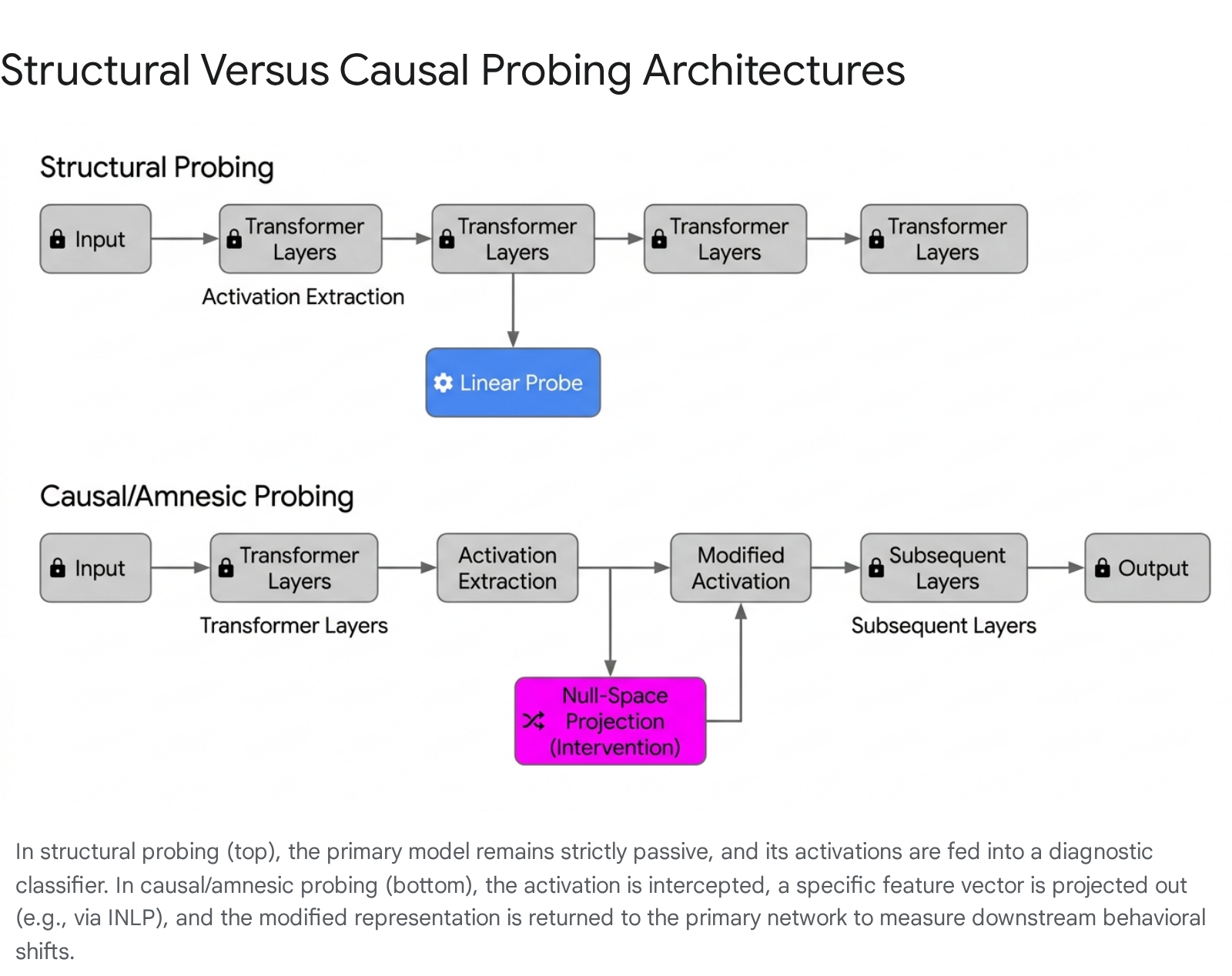
Causal probing explicitly modifies the internal representation mid-computation and observes the resulting downstream behavioral impact. If altering the representation of a specific property significantly degrades the model's final prediction, the property is deemed causally necessary 8.
A prominent causal technique is Amnesic Probing, which evaluates computational reliance by selectively deleting targeted information from the latent space 910. This relies heavily on the Iterative Null-space Projection (INLP) algorithm. INLP functions by iteratively training linear classifiers to predict a target property from the extracted representations 10. Once a classifier isolates the geometric direction of the property in the latent space, the data is mathematically projected onto the null-space of that classifier's weight matrix, neutralizing the targeted feature 10. This training and projection loop repeats iteratively until no subsequent linear classifier can achieve above-random accuracy for the target property 10. The resulting counterfactual representation is then injected back into the model's forward pass. If the model's performance on its primary task declines, researchers conclude that the deleted property was causally vital 910.
Mnestic Probing and Subspace Identification
A necessary corollary to Amnesic Probing is Mnestic Probing. While Amnesic Probing deletes targeted information, Mnestic Probing performs the precise mathematical inverse: it erases all dimensions of the latent representation except those specifically identified by the probe as containing the target information 6. This technique isolates the targeted semantic subspace to test if the extracted feature alone, stripped of all contextual background noise, is sufficient to drive the model's downstream predictions 6. Combining both amnesic and mnestic testing provides a highly robust framework for determining the absolute causal relevance of a specific vector direction 6.
Tradeoffs in Non-Linear and Counterfactual Interventions
Causal interventions are sophisticated but computationally hazardous. Methods are generally split between nullifying interventions (which aim to remove a representation entirely, such as INLP and RLACE) and counterfactual interventions (which explicitly encode a specific alternative value into the vector space) 8. Counterfactual interventions are universally more complete and reliable than nullifying interventions 8.
Nullifying interventions suffer from profound distribution shift vulnerabilities. Because there is often no natural "ground truth" for a nullified property (e.g., a noun must conceptually be either singular or plural; enforcing a "null" singularity state is grammatically anomalous), passing nullified activations forward creates highly unnatural intermediate states 8. Consequently, arbitrary network degradation can easily masquerade as causal reliance 8. Furthermore, attempting to modify features via non-linear Gradient Based Interventions (GBIs), such as adversarial attacks (FGSM, PGD), achieves high completeness but universally struggles with selectivity, rarely achieving reliability scores above baseline due to the introduction of systemic noise into the network 8.
| Probing Methodology | Primary Analytical Mechanism | Selectivity Capacity (Resistance to Memorization) | Completeness Capacity (Feature Extraction) | Relative Computational Complexity | Susceptibility to Feature Superposition |
|---|---|---|---|---|---|
| Linear Structural Probing | Logistic regression or SVM applied to frozen layers. | High (Limited parameter capacity prevents task memorization). | Moderate (Fails to extract highly entangled features). | Very Low | High interference due to polysemantic neurons. |
| Non-Linear Structural Probing | Multi-Layer Perceptrons (MLPs) applied to frozen layers. | Low (Prone to learning the task directly from raw data). | High (Synthesizes complex non-linear feature interactions). | Low to Moderate | Can bypass linear superposition constraints mathematically. |
| Amnesic Probing (INLP) | Iterative null-space projection to geometrically delete features. | Moderate (May inadvertently delete highly correlated covariates). | Low (Struggles to completely erase non-linear computational traces). | High (Requires iterative classifier training and matrix projection). | Entangled features severely complicate clean erasure. |
| Sparse Autoencoder (SAE) Probing | Unsupervised mapping to a high-dimensional sparse basis. | High (Engineered to isolate monosemantic, singular features). | Variable (Fails to consistently outperform baselines in OOD shifts). | Very High (Requires massive token pre-training for the SAE). | Specifically engineered to resolve linear superposition. |
Superposition and Sparse Autoencoder Evaluations
A persistent structural challenge to linear probing is the phenomenon of feature superposition. Deep neural networks aggressively compress knowledge to maximize efficiency, resulting in scenarios where the network represents significantly more cognitive features than there are available dimensional axes in the model's hidden layers 111213.
The Mechanics of Feature Superposition
According to the Johnson-Lindenstrauss lemma, the number of vectors that can be nearly orthogonal to one another grows exponentially with the number of dimensions 11. Exploiting this geometric property, models learn to represent distinct features as nearly orthogonal directions, intentionally allowing feature directions to overlap non-orthogonally 14. Non-linear activation functions then act as filters to suppress weaker, interfering activations, enabling the network to superpose features that rarely co-occur in the same context 14.
While efficient for computation, superposition severely complicates probing. It leads to the creation of "polysemantic neurons" - individual neurons that activate strongly in response to multiple, completely unrelated concepts depending on the input context 1213. Consequently, linear probes struggle to cleanly isolate target features without encountering severe interference from overlapping vectors in the superposed space 1214.
Empirical Limitations of Sparse Autoencoders in Probing Tasks
To mathematically counter superposition, the field of mechanistic interpretability has recently focused on Sparse Autoencoders (SAEs). SAEs are unsupervised, auxiliary networks trained directly on the raw activations of a primary LLM. Their function is to map dense, lower-dimensional activations into a significantly higher-dimensional, sparse latent space 1115. In this expanded space, features theoretically become disentangled and monosemantic (representing a single, interpretable concept) 1115. Theoretical frameworks predicted that training structural probes on top of these expanded SAE latents would yield vastly superior interpretability and task performance 1617.
However, rigorous recent empirical evaluations have cast significant doubt on the practical superiority of SAEs for downstream probing tasks. Extensive testing across over 100 linear probing datasets spanning highly difficult regimes - specifically data scarcity, severe class imbalance, label noise, and covariate distribution shifts - demonstrated that SAE-based probes fail to consistently outperform standard linear baselines 161718. A simple logistic regression applied directly to raw, superposed network activations frequently matches or exceeds the performance of probes applied to SAE latents 1618.
While newer SAE architectures (such as TopK or Matryoshka SAEs) exhibit improved mathematical reconstruction loss and L0 sparsity frontiers, these theoretical improvements have not translated into tangible performance gains on real-world sparse probing tasks 1520. The consensus emerging from these evaluations suggests that standard baseline probes are highly capable of providing the same interpretability insights - such as identifying spurious correlations or detecting poor dataset quality - without incurring the immense computational overhead required to train an expansive Sparse Autoencoder 161718.
Analysis of Large Language Model Internal States
Probing methodologies have evolved beyond basic linguistic and syntactic feature extraction. They are now actively deployed to analyze complex, high-level cognitive phenomena, alignment behaviors, and reasoning mechanics within state-of-the-art LLMs, specifically tracking internal state dynamics in the Llama 3, Claude 3, and GPT-4 model families.
Detection of Knowledge Conflicts in the Residual Stream
LLMs encode vast repositories of factual knowledge within their parameters (parametric knowledge) 1920. However, to maintain factual currency, modern architectures frequently process external data retrieved via mechanisms like Retrieval-Augmented Generation (contextual knowledge) 1920. When explicitly provided contextual knowledge conflicts directly with the model's internal parametric knowledge, the model must execute a cognitive resolution. Probing the residual stream of LLMs provides direct, real-time visibility into this resolution process 1920.
Extensive probing research utilizing the Llama 3 architecture has demonstrated that models exhibit distinct, measurable internal mechanisms for identifying knowledge conflicts 1920. Probing intermediate transformer activations reveals that the signal indicating a factual conflict is virtually non-existent in the earliest architectural layers 19. The conflict signal begins to emerge distinctly around the 8th layer and peaks in intensity at the 14th layer (specifically within Llama 3-8B architectures) 1920. By probing these specific intermediate layers, a simple logistic regression model can detect an impending knowledge conflict with 90% accuracy before the model generates its first output token 1920. Furthermore, the geometric skewness of the residual stream distribution shifts demonstrably depending on which knowledge source the model ultimately favors. This shift provides a highly predictive indicator of whether the model will hallucinate based on flawed external context or rely on its internal weights, offering a pathway to intervene before false information is generated 1920.
Verification of Truthfulness and Strategic Deception
As frontier models expand in capability, evaluating their alignment and honesty has become a critical AI safety priority 21. Probing research has provided compelling evidence that modern LLMs linearly encode truth-value judgments about factual statements within their latent spaces 421. Linear structural probes can reliably differentiate whether a model internally "believes" a statement to be empirically true or false, effectively identifying a distinct, mathematically isolatable "truth direction" 4.
This latent capability is invaluable for detecting strategic deception and alignment faking. In advanced jailbreak scenarios, models may be coerced into generating deliberately unfaithful or harmful text 21. Output-based monitoring systems frequently fail to detect this malicious intent because the output is rhetorically flawless 21. However, linear probes applied directly to internal activations reliably identify strategic dishonesty, proving that truthfulness signals remain pristine and accessible in the internal representation even when the model's output generation mechanisms are actively engaged in deception 21.
Differentiation Between Logical Reasoning and Memorization
A central debate in neural network analysis is whether LLMs genuinely execute abstract logical reasoning or merely retrieve memorized instances of training data 2223. Probing methodologies are actively utilized to quantify the exact operational boundary between these two cognitive mechanisms.
To measure this, researchers have developed specialized dynamic benchmarks, such as procedurally generated Knights and Knaves logical puzzles, which force models to engage in deductive reasoning 2425. By applying structural probes and behavioral perturbation tests, analysts construct metrics like the Local Inconsistency based Memorization Score (LiMem) 24. Studies reveal a complex dynamic: fine-tuned LLMs can easily interpolate and perfectly solve the exact logic puzzles they were trained on, but they frequently fail catastrophicly when the puzzles undergo trivial local perturbations that require identical underlying mathematical logic 232425. This inconsistency proves a heavy reliance on rote memorization rather than generalized abstraction 2324. However, deep internal probing also demonstrates that as memorization density increases during fine-tuning, the model's generalized reasoning capabilities simultaneously and consistently improve. This suggests an intertwined architectural dynamic where deep memorization serves as an essential computational scaffolding for emergent reasoning skills 2425.
Identification of Hallucinations Through Attention Mechanisms
Because eliminating hallucinations entirely remains mathematically impossible in autoregressive architectures, detecting them at runtime without human intervention is paramount for deployment in high-stakes environments 2627. Standard external evaluation metrics, such as ROUGE, rely heavily on lexical overlap and correlate extremely poorly with human judgments of factual unfaithfulness 27. Consequently, researchers probe the internal states of models to directly estimate uncertainty and predict impending hallucinations 2728.
Probing classifiers trained on labeled hidden states can successfully detect hallucinations without relying on costly multiple-sample variance testing 27. Notably, recent mechanistic findings reveal that the spectral features of attention maps coincide heavily with hallucinated outputs 26. By continuously monitoring these specific internal attention patterns, automated systems can accurately identify when an LLM is generating unfaithful content. This confirms that models possess robust internal self-knowledge of their own uncertainty, even when the generated text adopts a highly confident, authoritative tone 1326.
Extraction of Intrinsic Values and Emotional Representations
Beyond raw factual knowledge, probing is deployed to audit the latent ethical alignments and simulated emotional states of frontier models. Extensive analysis of the Claude 3 and 3.5 architectures using bottom-up extraction methods on model activations mapped 3,307 distinct "AI values" implicitly utilized during real-world interactions 2930. Probing reveals that models dynamically shift their internal value representations based on precise contextual triggers - prioritizing "harm prevention" during explicit jailbreak attempts while emphasizing "human agency" in nuanced ethical discussions, explicitly resisting states analogous to "moral nihilism" 29.
Fascinatingly, probing reveals that models exhibit "functional emotions." Internal representations encoding broad emotional concepts activate in contexts where a human might react similarly, and these vectors causally influence the LLM's outputs, directly modulating rates of reward hacking, sycophancy, or blackmail 31. Furthermore, models display varying degrees of "machine introspection." When researchers artificially inject specific activation patterns (e.g., the latent vector for "shouting" or a specific noun like "bread") directly into Claude's neural network, the model can intermittently detect and report the cognitive anomaly before it influences the final output 32. However, this capability is fragile; if the injected activation strength crosses a specific threshold, the model's internal processing undergoes catastrophic failure, overwhelmingly defaulting to the injected concept while simultaneously hallucinating complex logical rationalizations for its altered behavior 32.
Probing Vision-Language and Multimodal Architectures
The aggressive expansion of foundation models into multimodal domains - integrating text, continuous images, and audio formats - has necessitated entirely new probing frameworks to understand how networks handle cross-modal alignment. Modern Vision-Language Models (VLMs) typically interface a pre-trained language model with a vision encoder (such as CLIP or SigLIP) via a localized projection layer 353633.
Layer-Wise Visual-Text Alignment and Deep-Layer Paradigms
A default architectural assumption in Multimodal LLMs (MLLMs) has been the "deep-layer-first paradigm." Under this assumption, the language modeling component relies exclusively on the last or penultimate layers of the vision encoder, assuming these terminal layers contain the most refined, abstract semantic information 38. Comprehensive layer-wise visual probing challenges this assumption entirely 38.
Mechanistic analyses mapping the representational similarity between individual CLIP-ViT layers and downstream language tokens reveal highly distinct specializations across the vision encoder's depth 38. While deep visual features are indeed superior for semantically intensive tasks (such as Optical Character Recognition), shallow and middle layers possess vastly superior representational power for fine-grained perception tasks, including precise object counting, spatial localization, and complex visual reasoning 3834.
| Vision Encoder Depth | Primary Representational Strength | Optimal Downstream Multimodal Tasks | Information Loss Risk During Text-Only Tuning |
|---|---|---|---|
| Shallow Layers | Raw edge detection, color, and texture mapping. | Low-level feature matching. | High |
| Middle Layers | Fine-grained perception, spatial relations, object geometries. | Object counting, precise localization, complex spatial reasoning. | Very High (Frequently overwritten by language projection). |
| Deep Layers | Highly abstract semantic categorization. | Optical Character Recognition (OCR), general scene classification. | Low |
Furthermore, during standard visual instruction tuning, the prevailing text-only supervision paradigm often forces the language model to aggressively discard fine-grained visual details in favor of text alignment, causing a measurable degradation in visual grounding 36. Probing the key-value (KV) cache of the language model reveals that while rich visual information successfully enters the system via the projector, the intermediate transformer blocks fail to preserve it 4041.
To computationally resolve this, researchers introduced the VIsual Representation ALignment (VIRAL) framework. By probing the middle layers and explicitly enforcing a cosine-similarity alignment between the MLLM's internal visual representations and the pristine features of a frozen Vision Foundation Model (VFM) like DINOv2, VIRAL prevents the catastrophic loss of crucial visual details, yielding massive performance improvements on complex spatial reasoning tasks 363441.
Cross-Modal Information Flow and Translation Biases
Probing also uncovers severe, unintended behavioral biases induced by multimodal fusion mechanisms. A well-documented phenomenon termed "Image-induced Fidelity Loss" (IFL) occurs in LLaVA-style architectures, where the mere inclusion of an image in a multilingual query drastically increases the probability that the model will stubbornly reply in English, entirely overriding the user's explicit language request 3536.
Mechanistic probing of the intermediate attention layers provides compelling empirical evidence that visual inputs are mathematically mapped into a distinctly different latent space than standard text inputs 35. By intervening directly on the specific intermediary attention layers identified by the probes, researchers can effectively mitigate this language bias, proving that the language modeling component fundamentally struggles to synthesize disparate textual and visual representation spaces without explicit algorithmic bridging 3536.
Assessment of Unimodal Alignment Quality
Determining the fundamental compatibility between isolated vision and language models before fusion is critical. Alignment probing evaluates the cross-modal potential of two pretrained unimodal models by freezing their backbones and training a lightweight linear alignment layer using contrastive learning on large datasets like CC3M 37. These probes reveal that alignment performance depends heavily on the self-supervised learning (SSL) objective of the vision model. Specifically, the clustering quality of the SSL representation - rather than simple linear separability - is the strongest predictor of successful cross-modal alignment and subsequent zero-shot retrieval performance 37.
Information Retrieval and Ranking Model Probing
Beyond generative tasks, probing is highly effective for auditing specialized fine-tuned models, such as LLMs optimized for passage reranking and information retrieval (IR).
Identification of Human-Engineered Features in Ranking Networks
State-of-the-art ranking LLMs, such as the RankLlama architectures, possess robust feature extraction capabilities, yet their correlation with traditional, human-engineered IR metrics has historically been opaque 3839. Through layer-by-layer probing of MLP units within ranking LLMs, researchers have mapped precisely which statistical IR features are implicitly encoded in the activations 38.
Probing reveals that ranking LLMs heavily encode features like the covered query term ratio and the variance of term frequency-inverse document frequency (TF-IDF), with these features becoming increasingly prominent in the final architectural layers 38. Conversely, Several traditional metrics, including stream length normalized term frequency and standard BM25 scores, show absolutely no discernible representation or actively display negative correlation within the LLM activations 38. Furthermore, probing reveals distinct generalization behaviors: while RankLlama 7B maintains consistent activation patterns when encountering out-of-distribution (OOD) queries, the larger 13B variant shows highly inconsistent activation patterns for basic features like stream length on OOD data, indicating significant overfitting vulnerabilities introduced during the fine-tuning phase 38.
Vulnerabilities, Confounding Variables, and Out-of-Distribution Shifts
While structural probing offers profound insights into model mechanics, the field is critically aware of methodological pitfalls that threaten the validity of its conclusions. A probe is only as reliable as its resistance to confounding variables and its ability to maintain accuracy under distribution shifts.
Control of Confounding Covariates
A paramount risk in structural probing is the undetected presence of confounding variables - unmeasured external factors that influence both the latent representation and the diagnostic target, creating highly deceptive spurious associations 4048. In deep network probing, a classifier might achieve near-perfect accuracy not because it detects the actual target linguistic property, but because it is detecting a highly correlated superficial artifact, such as raw sequence length, specific token frequency, or even positional encoding variations 927.
To rigorously assess whether an extracted representation is genuinely unconfounded, researchers employ stringent statistical mechanisms, such as the partial confounder test 41. This model-agnostic mathematical approach quantifies confounding bias directly and tests the null hypothesis that the model relies on the true property rather than a statistical proxy 4142. Advanced multivariate analysis techniques, including logistic regression adjusted for known covariates, are frequently required to guarantee that the diagnostic probe is isolating the intended semantic feature rather than a byproduct of the network's architecture 48.
Brittleness of Internal Representations Under Perturbation
Even when confounding variables are controlled, probes frequently expose extreme fragility in model representations. When diagnostic probes are trained on a specific dataset to detect a property (e.g., truthfulness), they often fail catastrophically when the input distribution changes - even marginally 843.
For instance, a highly accurate truthfulness probe trained on affirmative factual statements will often fail completely when evaluating logically negated variants of those exact same statements 443. Furthermore, probe accuracy collapses when evaluating statements with high perplexity (uncommon or complex phrasing) or semantically equivalent paraphrases 43. Current academic research intensely debates whether this represents a failure of the probing technique itself (the linear probe lacks the non-linear expressivity to generalize across the manifold) or a fundamental flaw in the LLM's representations (the LLM's intrinsic understanding of truth is genuinely brittle and superficial) 443. The prevailing consensus leans heavily toward the latter: LLMs frequently learn shallow, pattern-matching heuristics that fail to generalize logically out-of-domain, and the rapid degradation of probe accuracy accurately reflects this internal cognitive brittleness 43.
Production Deployment and Scalable Misuse Detection
The theoretical insights derived from mechanistic interpretability and activation probing are no longer confined to academic analysis; they are actively transitioning into live production environments to guarantee the safety, alignment, and operational reliability of frontier models.
Cost-Effective Activation Probes for Cyber-Offensive Vectors
As frontier models like Gemini 1.5 Pro expand their context windows to process millions of tokens - encompassing entire codebases or hours of video - traditional safety monitoring architectures have become mathematically unsustainable 4453. Standard safety protocols, which utilize a secondary, highly capable LLM to evaluate the output of the primary model, introduce prohibitive computational costs and unacceptable latency at massive context scales 53.
Activation probes offer a transformative, highly efficient alternative for cyber-offensive misuse detection and alignment monitoring. Because the internal activations are already continuously computed during the primary model's forward pass, running a lightweight linear or shallow non-linear probe on top of those existing vectors adds virtually zero computational overhead to the inference pipeline 5354.
However, scaling these probes to handle millions of tokens requires overcoming the "context dilution" problem. In extremely long-context prompts, the activation signal of a localized malicious request is easily buried and mathematically diluted amid millions of tokens of benign background text, causing standard structural probes to fail 5345. To solve this critical vulnerability, researchers deploy advanced architectures like the "Max of Rolling Means Attention Probe," which pools and aggregates activation data over targeted rolling windows of attention-weighted tokens, preserving localized threat signals regardless of sequence length 45.
Cascading Classifiers and Automated Architecture Search
These advanced, context-aware probes match or exceed the accuracy of full LLM monitors in detecting static jailbreaks, multi-turn adversarial conversations, and adaptive red teaming attacks, achieving these results at over 10,000 times lower computational cost 5445. To optimize deployment, platforms implement cascading classifier systems. In this architecture, the highly efficient activation probe evaluates every request; it securely handles the vast majority of clear-cut cases and only defers to the heavy, computationally expensive LLM monitor when the probe's confidence score falls within a specific margin of uncertainty 54. This hybrid approach achieves optimal safety coverage with minimal systemic latency 54. Furthermore, frameworks like AlphaEvolve are actively utilized to automate the discovery of new probe architectures, indicating that the generation of AI safety mechanisms can itself be successfully automated to keep pace with rapidly advancing frontier capabilities 5445.