Positional encoding in transformer architectures
The advent of the transformer architecture revolutionized machine learning by replacing the sequential processing bottlenecks of Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks with highly parallelized attention mechanisms. However, the core mathematical operation that enables this massive parallelization - scaled dot-product self-attention - presents a fundamental architectural limitation. Attention mechanisms compute relationships between all tokens simultaneously, processing the input sequence not as an ordered progression of data, but as an unordered mathematical set.
Without a mechanism to explicitly inject sequence order, a transformer is functionally blind to time and syntax, unable to distinguish between identical words in different structural arrangements. Positional encoding serves as the critical solution to this constraint, acting as the mechanism by which transformers comprehend the spatial and temporal relationships between tokens. The evolution of positional encoding - from fixed sinusoidal waves to dynamic, complex-plane rotations - mirrors the broader evolution of large language models (LLMs) toward expansive context windows, highly efficient inference, and robust out-of-distribution generalization.
Permutation Equivariance and the Self-Attention Mechanism
The necessity of positional encoding stems directly from the algebraic properties of the self-attention mechanism. In a standard transformer, an input sequence of tokens is projected into three distinct vector spaces via learned weight matrices: Queries ($Q$), Keys ($K$), and Values ($V$) 123. The attention output is subsequently computed using the following formulation:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
This operation is mathematically defined as permutation equivariant. If the rows of the input sequence matrix are shuffled, the resulting output matrix is shuffled in the exact same permutation, but the semantic representations of the individual tokens remain entirely unchanged 124. Because the projection matrices $W_q$, $W_k$, and $W_v$ are applied identically across all sequence positions regardless of their sequential index, the attention mechanism inherently processes text as a "bag of words" 2567.
In practical terms, an unencoded model processes the sentence "the cat sat on the mat" identically to "the mat sat on the cat." The model recognizes the vocabulary and the semantic embeddings of the isolated words, but fails to compute the causal and syntactic relationships established by word order 678. To break this symmetry, a unique mathematical signature indicating a token's absolute or relative position must be incorporated into the token's representation vector either before or during the attention calculation 279.
Absolute Positional Embeddings
Early solutions to the permutation equivariance problem focused on Absolute Positional Embeddings (APE). In this paradigm, a unique vector representing the explicit position index (e.g., position 1, position 2, position $N$) is generated and added directly to the input token embedding prior to the first transformer layer 17910.
Learned Absolute Positional Embeddings
The most straightforward computational approach, utilized by early architectures such as GPT-2, involves initializing a positional embedding matrix of shape $T \times d_{model}$, where $T$ is the maximum pre-defined context length and $d_{model}$ is the dimension of the semantic token embeddings 11313. During the training phase, the model treats this matrix as a set of standard network weights, using gradient descent and backpropagation to learn the optimal vector representation for each distinct absolute position 9313.
While empirically effective within the bounds of the training data, learned embeddings suffer from a hard extrapolation limit. If a model is trained with a maximum context window of 1,024 tokens, no positional vector exists in the learned matrix for the 1,025th position 693. Consequently, if the model is fed a sequence exceeding its pre-training maximum during inference, the mathematical operations break down, preventing the model from generalizing to longer documents 910.
Sinusoidal Positional Encoding
To resolve the constraints of strictly finite learned parameters, Vaswani et al. (2017) introduced Sinusoidal Positional Encoding in the original Transformer architecture. This deterministic, training-free approach assigns a unique positional vector using continuous, interlocking sine and cosine functions operating at varying frequencies 678.
For a token at position $pos$ and an embedding dimension $i$, the encoding is defined by the following equations:
$$PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right)$$ $$PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right)$$
This continuous formulation functions analogously to a high-dimensional clock or a smoothed binary counter 8144. Lower dimensions of the embedding vector (governed by high-frequency sine and cosine waves) oscillate rapidly, changing values almost every token, acting like the "second hand" of a clock to capture fine-grained, local positional relationships between adjacent words 8145. Conversely, higher dimensions (governed by low-frequency waves) oscillate very slowly, capturing global structural awareness and long-range dependencies across the entire sequence 8145.
The inclusion of both sine and cosine functions is a deliberate geometric choice rooted in Fourier analysis. By pairing these functions, the model can theoretically represent the positional encoding of any offset position $pos + k$ as a direct linear transformation of the encoding at $pos$ 1417. The transformation matrix required to shift an encoding by $k$ positions is independent of the absolute position, allowing the attention mechanism to implicitly learn relative distances across the sequence 14417.
However, sinusoidal encodings exhibit several critical limitations. Because these positional vectors are added directly to the semantic token embeddings, the model is forced to disentangle "what the token means" from "where the token is" using the exact same vector space, leading to representational crowding and the pollution of semantic data 8186. Furthermore, empirical studies have demonstrated that standard sinusoidal encodings fail to extrapolate gracefully when evaluated on sequence lengths dramatically longer than those observed during training, as the attention mechanisms struggle to interpret extreme absolute coordinates 61018.
Relative Positional Embeddings
To address the limitations of absolute indexing, architectural research shifted toward Relative Positional Embeddings (RPE). The RPE paradigm posits that linguistic grammar and logical structures rely far more on the relative distance between two tokens than their absolute, fixed coordinates within a document 61018.
A highly influential RPE implementation is the T5 Bias introduced by Raffel et al. (2020), which abandons input-level modifications entirely 207. Instead of altering the input embeddings, the model learns a discrete scalar bias for different relative distances and adds these biases directly to the attention logits prior to the softmax operation 20823. For inference tasks requiring sequences beyond the trained context window, the T5 architecture clamps or clips the relative distance to the maximum distance observed during training, reusing that maximum bias 9208.
While T5 Bias and similar RPE mechanisms demonstrably improve long-sequence generalization compared to absolute methods, they introduce severe computational bottlenecks. Because RPE must calculate the precise offset between every pair of queries and keys dynamically across the sequence, it requires the materialization of the full $N \times N$ attention matrix 7249. This structural requirement renders standard RPE incompatible with modern, efficient, sub-quadratic attention implementations (such as FlashAttention), severely limiting the scalability of these models 79.
Rotary Position Embedding
Rotary Position Embedding (RoPE), introduced by Su et al. (2021), has become the de facto standard for modern open-source LLMs, including LLaMA, Qwen, and Mistral 9262728. RoPE elegantly unifies absolute and relative positioning without adding learnable parameters to the token embeddings, and without disrupting the efficiency of the attention calculation 137.
Mathematical Formulation and Complex Plane Rotation
Rather than adding a positional vector to the initial token embedding, RoPE modifies the Query ($Q$) and Key ($K$) vectors immediately before the attention dot product is computed 13610.
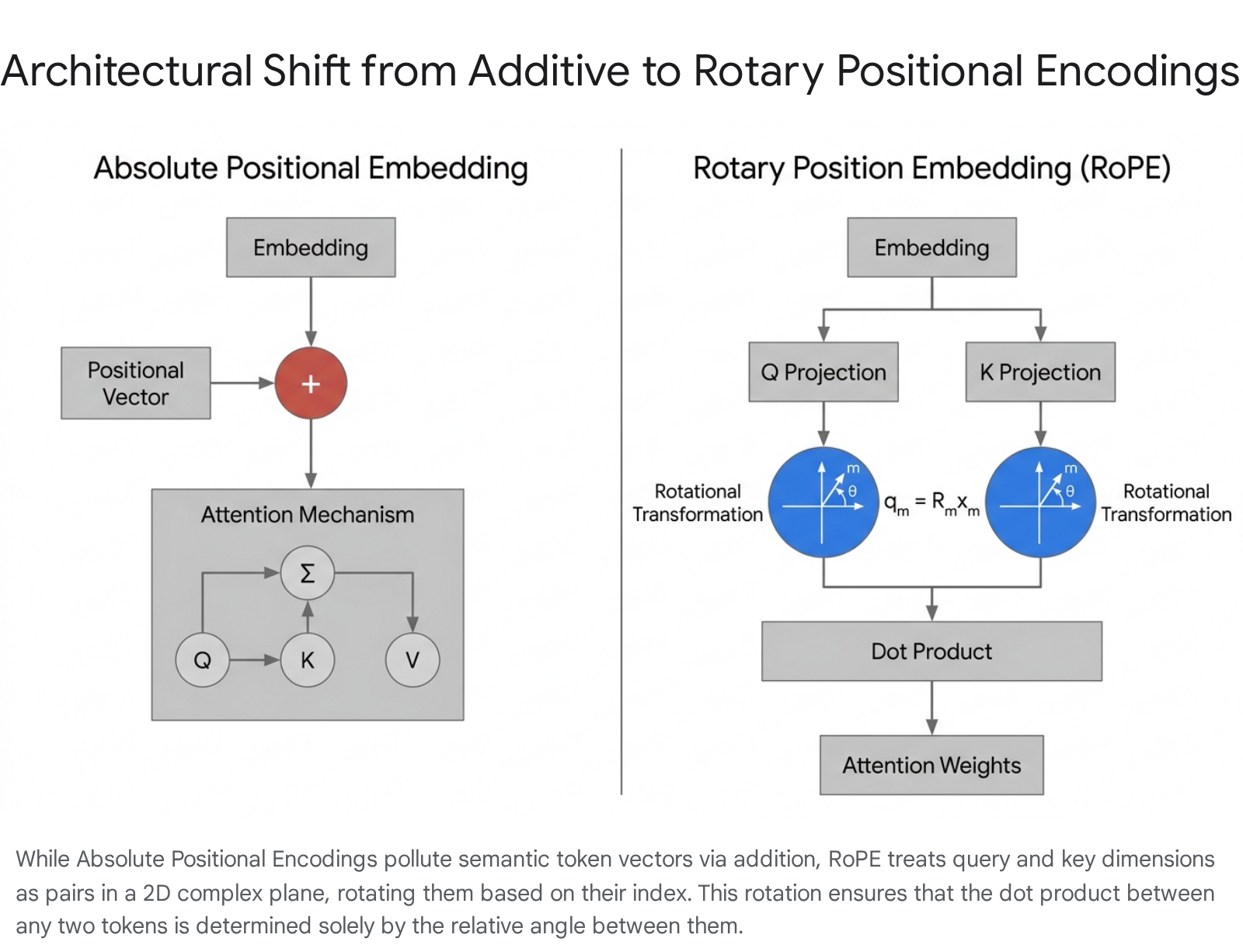
It achieves this by splitting the $d$-dimensional embedding vector into $d/2$ discrete pairs. Each pair is treated as a coordinate $(x, y)$ in a two-dimensional complex plane 131810.
RoPE then geometrically rotates these 2D vectors by an angle proportional to the token's absolute sequence position $m$ 710. The rotation angle relies on a frequency base, typically initialized to $\theta = 10000$ 2630. The mathematical brilliance of RoPE emerges specifically during the dot product of a query vector at position $m$ and a key vector at position $n$. Because the inner product of two vectors in a 2D plane depends solely on the angle between them, the resulting attention score becomes entirely dependent on the relative distance $(m - n)$ 671030.
This property is formally expressed as:
$$\langle f_q(x_m, m), f_k(x_n, n) \rangle = g(x_m, x_n, m - n)$$
Through this transformation, the model computes self-attention with perfect relative awareness while maintaining the sub-quadratic computational profile of an absolute encoding method 37. Furthermore, RoPE scales cleanly to multidimensional data required for Vision-Language Models (VLMs) by applying independent rotational frequencies across different axes (e.g., width, height, and time), enabling spatial awareness without altering the core architecture 62810.
Implementation and Extrapolation Limits
In modern deep learning frameworks like PyTorch, RoPE is implemented efficiently using the "rotate-half trick," which negates and swaps pairs of embedding components before applying the sine and cosine transformations, bypassing the need for computationally heavy matrix multiplications 10.
Despite its elegance, vanilla RoPE faces extrapolation limits. If a model trained on 2,048 tokens receives an input of 8,192 tokens, the relative rotations for tokens beyond position 2,048 involve angles $\theta$ that the model has never optimized weights for 1030. Relying strictly on these out-of-distribution rotation angles causes sequence coherence to degrade rapidly, necessitating the development of post-training context scaling mechanisms 1030.
Attention with Linear Biases
Attention with Linear Biases (ALiBi), proposed by Press et al. (2021), represents a philosophy of radical architectural minimalism that completely sidesteps the complexities of input embedding alterations and complex-plane rotations 76. ALiBi abandons explicit positional embeddings entirely, injecting positional awareness strictly as an inductive recency bias 13611.
The ALiBi Distance Penalty Mechanism
In ALiBi, no positional parameters are added to the input sequence, and the Query and Key vectors are not rotated. Instead, after the attention matrix is computed via the standard dot product ($QK^T$), ALiBi subtracts a static, non-learned penalty from the resulting attention scores before they pass through the softmax function 713. This penalty grows linearly as the physical distance between the query token and the key token increases, effectively forcing the model to prioritize proximate context over distant context 1311.
To maintain the capacity for long-range sequence dependency, this distance penalty is scaled by a head-specific slope scalar $m$ 713. In a typical multi-head attention setup, this scalar is structured as a geometric sequence starting at $2^{-8/n}$. Consequently, some attention heads possess a steep slope - aggressively penalizing distant tokens to focus narrowly on local grammar - while other heads feature a highly gentle slope, allowing them to retain broad, long-range contextual awareness 713.
Extrapolation Capabilities and Known Pathologies
Because the ALiBi penalty is based purely on a continuous, linear relative distance penalty, it excels in zero-shot length extrapolation 10132011. The mathematical operation remains stable regardless of sequence length, allowing models to process text far beyond their training bounds without fine-tuning 1011. Furthermore, ALiBi is slightly faster to train than RoPE due to the removal of trigonometric computations 723.
However, the simplicity of ALiBi introduces distinct architectural pathologies. Empirical analyses of ALiBi-based models (such as BLOOM) reveal an "attention sink" phenomenon where the aggressive linear penalties compel a significant portion of attention heads to collapse 632. Studies indicate that 31% to 44% of attention heads in ALiBi networks may effectively shut down, directing almost all their probability mass indiscriminately to the Beginning of Sequence (BOS) token 6. As the ecosystem evolved, the development of robust RoPE scaling methods ultimately superseded ALiBi's initial extrapolation advantages, establishing RoPE as the preferred standard 6.
Taxonomic Comparison of Positional Encoding Frameworks
The selection of a positional encoding framework profoundly influences a transformer's memory footprint, training velocity, and context extrapolation ceiling.
| Encoding Framework | Injection Point | Core Mathematical Mechanism | Learnable Parameters | Extrapolation Capability | Computational Footprint |
|---|---|---|---|---|---|
| Absolute (Learned) | Input embeddings | Static parameter lookup | Yes | None (Hard sequence limit) | Minimal |
| Absolute (Sinusoidal) | Input embeddings | Interlocking sine/cosine addition | None | Poor (OOD values) | Minimal |
| Relative (T5 Bias) | Attention logits | Learned distance-based scalar bias | Yes | Moderate (Clamped at max) | High (Requires $N \times N$ matrix) |
| Rotary (RoPE) | Query/Key vectors | 2D complex plane geometric rotation | None | Moderate (Requires scaling) | Minimal (FlashAttention compatible) |
| Linear Bias (ALiBi) | Attention logits | Static linear distance penalty | None | Excellent (Zero-shot) | Minimal |
The Context Extrapolation Challenge
As the demand for processing massive documents, entire codebases, and long-form conversational histories has increased, standard LLMs encounter severe degradation when pushed past their pre-training context windows 63312. When evaluated on extended sequences, models frequently fail to retrieve information and hallucinate, driven by two primary mathematical breakdowns: Out-of-Distribution (OOD) positional values and Attention Entropy Collapse 123513.
Out-of-Distribution Positional Values
Transformers optimize their projection weights ($W_q, W_k, W_v$) based on the distribution of data observed during pre-training 1813. If an LLM is trained on a context window of 4,096 tokens, it learns how to handle the specific rotation angles (in RoPE) or positional vectors (in APE) corresponding to indices 1 through 4,096 183037.
When an inference sequence extends to 10,000 tokens, the model encounters positional variables that lie entirely outside its training manifold 1338. These out-of-distribution positional inputs generate catastrophic values in the attention dot product, destabilizing the sequence's internal representations and leading to immediate representational collapse 13373814.
Attention Dispersion and Entropy Collapse
Even if OOD values are mitigated, models face a secondary limitation embedded in the scaled dot-product attention formula itself. The softmax function normalizes attention scores across all available tokens, ensuring they sum to 1.0 3540.
As the context length $N$ grows exponentially, the attention probability mass is fundamentally forced to spread across a vastly larger set of tokens 3515. This causes "attention dispersion," where the softmax distribution flattens and approaches uniformity 3515. Known formally as attention entropy collapse, this dilution prevents the model from sharply focusing on crucial tokens, burying highly relevant information beneath the accumulated mathematical noise of thousands of irrelevant tokens 35401542. Without adjustments, the information entropy of the attention distribution breaks the bounds optimized during the model's training phase 4043.
Methods for Context Window Scaling
To avoid the prohibitive, multi-million-dollar computational costs required to pre-train LLMs from scratch on 100k+ token sequences, researchers developed a class of post-training scaling techniques. These methods manipulate RoPE frequencies to fit longer sequences into smaller, pre-trained domains with minimal required fine-tuning 693716.
Position Interpolation and Linear Scaling
The earliest viable intervention was Position Interpolation (PI), which prevents token positions from extrapolating into unknown territory 454617. Rather than allowing inference to proceed to position 8,192 on a 4,096-trained model, PI linearly scales down the position indices by a scaling factor $s$ (e.g., $m/s$) 451748. If the target context is doubled, position 8,192 is mathematically compressed and processed as position 4,096 3017.
While PI successfully bounds the positional inputs within the trained distribution, it compresses the entire frequency spectrum uniformly 3046. This uniform stretching severely distorts the high-frequency RoPE dimensions, which are responsible for discerning precise local grammatical relationships, causing an immediate degradation in short-range reasoning and language modeling perplexity 64246.
Neural Tangent Kernel (NTK) Aware Scaling
NTK-Aware Scaling resolved the uniform compression flaw by applying non-uniform scaling grounded in signal processing and Neural Tangent Kernel theory 424617. NTK theory demonstrates that neural networks struggle to learn or recover high-frequency information if it is artificially compressed into low-dimensional spaces 4246.
Therefore, NTK-Aware scaling alters the base frequency ($\theta$, typically $10,000$) dynamically based on the scaling factor 264249. It leaves the fast-rotating, high-frequency dimensions largely uncompressed, preserving local grammatical fidelity. Simultaneously, it applies aggressive interpolation to the slow-rotating, low-frequency dimensions to accommodate the longer global sequence 424849.
YaRN (Piecewise Frequency Scaling)
The evolution of NTK-Aware scaling culminated in YaRN (Yet Another RoPE Extension) 1243. YaRN systematically segments the RoPE dimensions into three distinct topological groups: 1. Pre-critical (High Frequency): Left completely unscaled, allowing the model to extrapolate perfectly for adjacent, high-resolution local patterns 384249. 2. Post-critical (Low Frequency): Aggressively interpolated to force long-distance relationships into the bounds of the original context window 3842. 3. Transition Zone: Bridged using a smooth ramp function to prevent abrupt mathematical discontinuities between the extrapolated and interpolated dimensions 4243.
Crucially, YaRN simultaneously addresses the Attention Entropy Collapse problem 404243. YaRN introduces a pre-softmax temperature scaling parameter $t$ 4042. By artificially altering the attention logits before normalization, YaRN prevents the attention probability mass from dispersing across hundreds of thousands of tokens, keeping the attention entropy in the regime the model was originally trained on 404243. This allows models to scale up to 128k contexts with fewer than 400 fine-tuning steps 384346.
LongRoPE: Scaling to 2 Million Tokens
Microsoft Research expanded the frontier of context extrapolation with LongRoPE, a methodology capable of extending context limits to an unprecedented 2 million tokens 93714. LongRoPE identifies that non-uniformities in positional embeddings exist not just across the embedding dimensions, but also across absolute token positions within the sequence (i.e., early tokens influence the model differently than late tokens) 375051.
LongRoPE employs an efficient evolutionary search algorithm to dynamically locate optimal, highly specific rescaling factors for every RoPE dimension and position 371450. To stabilize the model at extreme lengths, it utilizes a progressive extension strategy: the model is first fine-tuned lightly at 256k tokens, after which a secondary evolutionary search interpolates the weights out to 2,048k tokens 371451. Finally, LongRoPE readjusts the scaling parameters on short, 8k sequences to recover any performance lost in standard, short-context tasks, maintaining near-lossless capability across all sequence lengths 145051.

Systems Implications: KV Caching and Inference Latency
The choice of positional encoding has profound implications for hardware efficiency during autoregressive generation, particularly regarding the Key-Value (KV) cache 185354.
KV Cache Dynamics in LLM Inference
Autoregressive inference operates in two phases: the prefill phase (processing the input prompt in parallel) and the decode phase (generating new tokens sequentially) 1854. To prevent the LLM from redundantly recalculating the attention states for historical tokens during the decode phase, the system stores previously computed Key ($K$) and Value ($V$) matrices in the GPU's memory as the KV cache 185319. This optimization reduces generation complexity from $O(n^2)$ to $O(n)$, drastically accelerating inter-token latency (ITL) 535419. For instance, decoding a 4,096-token sequence is functionally 20 to 40 times faster with KV caching enabled 54.
Absolute Positional Encodings (APE) are highly compatible with simple KV caching 54. Because APE adds positional data to the token embedding before entering the attention layer, the $K$ and $V$ matrices inherently contain static positional information 5456. As new tokens are generated, the absolute position of earlier tokens never changes, meaning the cached vectors remain permanently valid and addressable 5620.
Positional Disruption in Cache Eviction
Conversely, relative methods, specifically RoPE, severely complicate cache management during extended generation and multi-turn conversations 5458. RoPE dynamically rotates the $Q$ and $K$ vectors at query time based on their explicit sequence index 54.
When an LLM engages in an infinite-context scenario where the accumulated token count exceeds the physical bounds of the GPU VRAM, the serving engine must evict older tokens from the cache 535859. Common token eviction strategies (such as AttentionTop, which attempts to retain the top 99% of semantically important tokens) often delete non-contiguous tokens from the middle of the sequence 1959.
This eviction fundamentally alters the relative sequence indices for all subsequent tokens 59. Because RoPE relies strictly on the linear distance $(m-n)$ to calculate attention, compacting the cache scrambles the rotational angles 59. The model attempts to attend to a cached token using an outdated relative rotation, leading to catastrophic cache invalidation, model confusion, and degenerative text output 5859.
Advanced Cache Decoupling and Compression
To mitigate caching constraints in RoPE-based models, engineers utilize advanced decoupling mechanisms. Frameworks like CachedAttention explicitly decouple the positional encoding from the KV caches when saving them to secondary storage, recalculating and re-embedding the RoPE rotations dynamically upon retrieval to prevent invalidation 58.
Furthermore, architectural optimizations like Multi-Head Latent Attention (MLA), deployed in models like DeepSeek-V2, apply low-rank compression to the KV cache while decoupling the rotary position embeddings from the head-specific KV storage, dramatically reducing memory footprint while maintaining the relative positional awareness critical for high-fidelity generation 21.
| Caching Metric | Baseline (Uncached) | Standard KV Cache | Impact of KV Eviction on RoPE |
|---|---|---|---|
| Time to First Token (TTFT) | 20-50ms (Prompt dominated) | 20-50ms (Unchanged) | N/A |
| Inter-Token Latency (ITL) | Scales linearly $O(n)$ | Constant time $O(1)$ | Spikes significantly upon invalidation |
| VRAM Footprint | Low (Discarded dynamically) | High (Grows unboundedly) | Fluctuates based on eviction policy |
| Positional Stability | Perfect (Recalculated every step) | Perfect for APE; Complex for RoPE | Severe degradation if non-contiguous |
Out-of-Distribution Generalization and Algorithmic Reasoning
Positional encoding mechanisms also dictate an LLM's capacity for out-of-distribution (OOD) generalization, particularly in environments requiring algorithmic logic and symbolic reasoning 1322. Standard transformers are generally capable of solving complex tasks within the data distributions they were trained on, but often fail when presented with variables or lengths outside that distribution 136223.
Recent theoretical proofs demonstrate that decoupling attention weights from semantic values and relying heavily on positional attention - where attention is driven predominantly by positional encodings rather than the token content - significantly enhances a model's ability to extrapolate logical rules 23. By utilizing fixed positional encodings across layers, transformers can effectively simulate arbitrary algorithms defined in parallel computation models, allowing them to solve synthetic algorithmic tasks (like sorting or copying) on OOD datasets 23.
This behavior is observable in "Induction Heads," which are specialized two-layer attention circuits within the transformer 3213. The first layer utilizes positional encodings to shift its attention to an adjacent or previous token, storing historical context. The second layer uses that positional context to identify repeating patterns and predict the next token algorithmically, rather than relying strictly on semantic memory 3213.
Architectural Alternatives to Explicit Encoding
Given the complexities of length extrapolation, rotation scaling, and KV cache invalidation, a growing body of research explores architectures that bypass explicit positional encodings entirely.
Transformers Without Positional Encoding (NoPE)
Studies evaluating decoder-only causal language models (such as the GPT family) have demonstrated that models trained entirely without explicit positional encodings (NoPE) can still generate coherent text and deduce structural order 3646524.
This phenomenon occurs due to the causal attention mask, a standard component in autoregressive generation that prevents tokens from "looking forward" into the future to predict the current token 6524. This mask creates an inherently asymmetric flow of information 65. By implicitly analyzing the number of predecessor tokens available to attend to, the neural network derives a functional approximation of absolute position 646524.
In certain synthetic length-extrapolation benchmarks, NoPE models have occasionally outperformed APE, RoPE, and ALiBi, largely because NoPE is not constrained by out-of-distribution mathematical values (like unknown rotation angles) 24. However, this implicit positional awareness is generally insufficient for complex, broad-domain reasoning tasks, and explicit encodings remain mandatory for non-causal Encoder-Decoder architectures (like BERT or T5), which do not utilize causal masking 16.
Selective State Space Models (Mamba)
The most aggressive departure from the positional encoding paradigm is found in modern selective State Space Models (SSMs) like Mamba 246768. Mamba architectures completely discard the $O(n^2)$ scaled dot-product self-attention mechanism, replacing it with a selective state-space update that processes sequence tokens in linear $O(n)$ time 2467.
Because Mamba sequentially updates a fixed-size hidden state vector (a Markovian representation of the past context), the architecture possesses an intrinsic, structural awareness of time and sequential order 6768. Consequently, selective SSMs do not require explicit positional encodings, RoPE scaling tricks, or complex relative bias mechanisms 2467. This fundamental architectural shift allows models like Mamba to seamlessly process sequences spanning millions of tokens - such as high-resolution genomics data or continuous multi-hour audio streams - bypassing the out-of-distribution extrapolation limits and KV-cache explosions that plague traditional transformer arrays 2468.
Future Outlook
The trajectory of positional encoding underscores a central theme in deep learning architecture: the transition from rigid, absolute memorization to fluid, relational representation. The dominance of Rotary Position Embedding (RoPE) and Attention with Linear Biases (ALiBi) validates the hypothesis that language and logic are defined fundamentally by relative distances rather than absolute coordinates.
Moving forward, the architectural bottleneck is no longer simply injecting positional information, but maintaining the thermodynamic stability of the attention matrix at extreme scales. As industry models push beyond multi-million token contexts, methodologies like YaRN and LongRoPE - which selectively manipulate frequencies to preserve local grammar while compressing global structure, combined with entropy-stabilizing temperature scaling - will dictate the immediate future of LLM context extension. Simultaneously, the systemic hardware challenges surrounding KV-cache invalidation and the rise of inherently sequential State Space Models suggest that the ultimate solution to sequence awareness may eventually involve abandoning the $O(n^2)$ attention paradigm entirely.