Parameter-Efficient Fine-Tuning of Large Language Models
The Computational Baseline of Full Fine-Tuning
The proliferation of large language models has fundamentally altered the landscape of natural language processing. As foundational models scale from billions to over a trillion parameters, they exhibit emergent capabilities in reasoning, instruction following, and complex text generation. However, adapting these generalized models to specific downstream tasks, proprietary domains, or specialized conversational formats poses a severe computational challenge. Traditional deep learning adaptation relies on full fine-tuning, an operation that calculates gradients and updates every weight in the neural network architecture 12. For modern models, this approach requires extreme computational hardware, vast amounts of high-bandwidth memory, and substantial energy expenditure.
To comprehend the necessity of parameter-efficient methodologies, it is essential to outline the resource consumption profile of full fine-tuning. Adjusting all parameters within a dense transformer model requires maintaining a vast memory footprint throughout the backpropagation process 2. For a given model loaded in half-precision (16-bit floating point), the general heuristic requires approximately 16 gigabytes of graphics processing unit memory per one billion parameters for training 24. This memory consumption is driven by four primary components: model weights, optimizer states, gradients, and intermediate activations. A 7-billion parameter model in 16-bit precision requires approximately 14 gigabytes of memory strictly to hold the static weights 23. However, the training process demands significantly more.
Advanced optimizers, such as AdamW, maintain running averages of the gradient and its square (momentum and variance) to stabilize training. For a 7-billion parameter model, maintaining these optimizer states typically consumes around 32 to 42 gigabytes of memory, depending on whether the states are kept in 16-bit or 32-bit precision 23. Furthermore, storing the gradients for every parameter requires an additional 14 gigabytes of memory in half-precision 23. Finally, intermediate activation tensors generated during the forward pass and stored for the backward pass consume variable memory depending on the sequence length and batch size, frequently ranging between 2 gigabytes and 10 gigabytes 23.
In totality, full fine-tuning a 7-billion parameter model often demands between 70 gigabytes and 120 gigabytes of memory, necessitating high-end multi-node clusters utilizing multiple enterprise-grade accelerators 234. Scaling this traditional operation to a 70-billion parameter architecture inflates the memory requirement to over 1.4 terabytes, restricting model adaptation to entities capable of sustaining massive hardware expenditure 27. Additionally, full fine-tuning is highly susceptible to catastrophic forgetting, a phenomenon where the model overwrites pre-trained world knowledge and reasoning capabilities in favor of the specialized downstream task 89. Parameter-Efficient Fine-Tuning emerged as a fundamental paradigm shift to address these precise infrastructural and algorithmic constraints.
Evolution of Parameter-Efficient Adaptation
Rather than adjusting the entire parameter space, parameter-efficient architectures freeze the vast majority of the pre-trained weights and introduce a marginal number of trainable parameters into the network. This selective updating preserves the generalized knowledge of the foundational model while achieving targeted domain adaptation 15. Early iterations of this concept utilized serial adapter modules, which were small neural layers inserted between existing transformer blocks 612. While highly efficient in parameter reduction, these serial adapters forced the forward computational pass to execute sequentially through additional layers 67. This architectural limitation inherently added inference latency, particularly severely impacting generation tasks with small batch sizes 714.
The desire to eliminate this inference latency overhead catalyzed the development of parallel adaptation structures. By injecting trainable parameters in parallel to the base network weights rather than sequentially, models could be adapted efficiently and later merged back into a unified weight matrix 148. This mathematical insight forms the basis for the most dominant adaptation architectures utilized in modern machine learning environments.
Low-Rank Adaptation Mechanics
Low-Rank Adaptation circumvents the inference bottlenecks of serial adapters by mathematically restricting weight updates to a low-dimensional space. The theoretical premise relies on the hypothesis that the intrinsic dimensionality of a pre-trained model's weight updates is remarkably low 910. Consequently, the dense parameter matrices of a massive neural network do not require full-rank updates to learn new representations effectively.
Mathematical Formulation of Low-Rank Adaptation
Given a pre-trained weight matrix within a transformer layer, a standard fine-tuning operation seeks to calculate a weight update matrix of the exact same dimensions. Low-Rank Adaptation mathematically constrains this update by representing the delta matrix as the product of two significantly smaller, low-rank matrices 51112. If the original layer matrix possesses dimensions of size $d \times k$, the update is factorized into a matrix $A$ with dimensions $d \times r$, and a matrix $B$ with dimensions $r \times k$. The defining feature of this architecture is that the rank parameter $r$ is substantially smaller than the original layer dimensions 41212.
The forward pass computation for a specific linear projection is subsequently modified to compute the original frozen weights alongside the parallel adapter matrices. The original pre-trained matrix receives no gradient updates during backpropagation 59. Only the localized adapter matrices are updated. A scaling factor, determined by a hyperparameter $\alpha$ divided by the rank $r$, is applied to the adapter output to modulate the magnitude of the learned updates 4811. Standard initialization protocols specify that the first adapter matrix is initialized with random Gaussian noise, while the second adapter matrix is strictly initialized with zeros 912. This zero-initialization ensures that at the exact onset of training, the adapter matrices compute a strict zero value, rendering the model's behavior perfectly identical to its base pre-trained state 9.
This decomposition drastically truncates the trainable parameter count. For instance, modifying a dense attention projection matrix of $10,000 \times 10,000$ dimensions in full fine-tuning requires tracking 100 million trainable parameters. By applying a low-rank adapter with a rank of $r=8$, the system only requires updating 160,000 parameters - representing a parameter reduction exceeding 99.8% 1120. Despite this extreme reduction, models adapted through this protocol routinely recover 95% to 99% of full fine-tuning performance across downstream tasks while slashing memory requirements by a factor of three to four 413.
Quantized Low-Rank Adaptation Architecture
While standard Low-Rank Adaptation minimizes the memory required for optimizer states and gradients, the frozen base model weights remain in high precision, continuing to consume massive memory merely for the base footprint 1322. Quantized Low-Rank Adaptation systematically resolves this persistent bottleneck by aggressively compressing the frozen base model weights into a 4-bit representation format during the fine-tuning process 111314.
This quantized architecture integrates three distinct computational innovations to maximize memory efficiency without sacrificing model capability. First, the framework utilizes a 4-bit NormalFloat data type. Standard integer quantization algorithms often distort the normally distributed weights of neural networks, leading to severe representation degradation. The NormalFloat data type is an information-theoretically optimal format designed specifically for zero-mean, normally distributed neural network weights, ensuring that the aggressive 4-bit compression retains maximal fidelity 41113. Second, to further condense the memory footprint, the architecture applies double quantization, subjecting the quantization constants themselves to a second round of compression. This yields an additional memory recovery of roughly 0.5 bits per parameter 41124. Third, the implementation relies heavily on paged optimizers, integrating with unified host memory to automatically page optimizer states to system memory during extreme graphical processing memory spikes 41122.
During the forward computational pass, the compressed 4-bit weights cannot be multiplied directly. They are dynamically dequantized to a 16-bit format, typically bfloat16, on the fly to perform standard matrix multiplications 1314. The gradients are then computed in 16-bit precision and backpropagated through the frozen quantized network directly into the higher-precision adapter matrices 1422. This highly localized precision strategy enables the fine-tuning of a 70-billion parameter model on a single 48-gigabyte workstation graphic processing unit - an operation that traditionally required highly specialized server infrastructure 112214.
Advanced Structural Adapter Variants
The foundational success of low-rank matrix decomposition has spawned a complex taxonomy of evolved adapter architectures. These advanced variants target specific mathematical limitations in standard implementations, addressing accuracy gaps in complex reasoning tasks, optimization inefficiencies, and severe initialization constraints in extreme quantization regimes.
Weight-Decomposed Low-Rank Adaptation
While highly efficient, empirical analysis repeatedly demonstrates that standard low-rank adaptation occasionally struggles to match full fine-tuning performance on complex, multi-step reasoning tasks 2526. The Weight-Decomposed Low-Rank Adaptation (DoRA) architecture isolates the mathematical cause of this persistent accuracy gap: magnitude-direction coupling. In a standard adapter architecture, updating the low-rank matrices simultaneously alters both the overall magnitude and the directional orientation of the target weight matrix. Full fine-tuning, by contrast, possesses the inherent flexibility to decouple these properties; the optimizer can independently update directional feature patterns while keeping the overall vector magnitude stable, or shift the magnitude without disrupting the orientation 2715.
DoRA mimics the learning trajectory of full fine-tuning by explicitly decomposing the pre-trained weight matrix into two distinct components: a one-dimensional magnitude vector and a multidimensional directional matrix 272916. Low-rank adaptation is subsequently applied strictly to the directional matrix, while the magnitude vector is decoupled and trained independently as a separate parameter 2729.
This decomposition introduces a mathematically negligible parameter increase - approximately 0.01% more parameters than a standard baseline implementation - while dramatically enhancing training stability and learning capacity 2729. Benchmarks across foundational language architectures and vision-language models demonstrate that this decomposition consistently outperforms standard adapter implementations. Notably, empirical results show that DoRA achieves equivalent or superior accuracy on commonsense reasoning benchmarks even when utilizing half the adapter rank size of standard algorithms, enabling further parameter reduction 272916.
Principal Singular Values and Vectors Adaptation
Standard adapter implementations suffer from initialization inefficiency. By initializing the first matrix with Gaussian noise and the second with zeros, the initial fine-tuning steps are expended traversing a highly noisy gradient landscape before the adapter discovers meaningful representational features 931. Principal Singular values and Singular vectors Adaptation (PiSSA) overhauls this initialization protocol by entirely replacing random noise with Singular Value Decomposition 93117.
PiSSA relies on the principle that the most vital updates required for domain adaptation logically exist within the principal components of the pre-trained weight matrix itself 917. Prior to initiating the training loop, PiSSA executes a rapid singular value decomposition operation on the target pre-trained weights. The principal singular values and vectors form the precise initial state for the trainable adapter matrices. The remaining, less significant components are mathematically isolated and compressed into a frozen residual matrix 93117.
Because PiSSA initializes the trainable parameters with the intrinsic principal representations of the base model rather than arbitrary statistical noise, it entirely circumvents the slow initial convergence phase 917. Empirical data indicates that this initialization strategy requires significantly fewer training iterations to achieve targeted validation loss metrics 91531. In standardized benchmarks, this approach frequently outperforms standard random-noise initializations while utilizing identical hyperparameters and parameter counts 1231.
Vector-Based Random Matrix Adaptation
As the industry advances toward massive open-weight models exceeding 70 billion parameters, the parameter footprint of standard low-rank adapters can pose logistical hurdles. This is particularly prevalent in multi-tenant serving environments that require hosting hundreds or thousands of unique, localized adapters for distinct users 3318. Vector-Based Random Matrix Adaptation (VeRA) represents an extreme architectural approach designed to maximize parameter minimization 33.
Unlike standard implementations, which construct unique, trainable matrices for every single targeted transformer layer, VeRA generates a single, global pair of low-rank matrices that are shared universally across all layers of the neural network. Crucially, these global matrices are initialized randomly and frozen permanently 333519.
To enable localized, layer-specific learning, VeRA introduces two highly compressed, trainable scaling vectors into each targeted layer 3319. The layer's weight update is computed by multiplying the frozen global random matrices with the trainable diagonal scaling vectors 19. Because the expansive low-rank matrices are shared and frozen, the trainable parameter count scales linearly with the depth of the network rather than exponentially with the dense matrix dimensions 19. Consequently, VeRA typically operates with 10 times fewer trainable parameters than standard adapter methods 1519. For organizations prioritizing extreme storage efficiency and rapid contextual adapter switching, this method offers a compelling alternative, albeit with a slight accuracy penalty compared to heavier adapter configurations 1533.
Fine-Tuning-Aware Quantization Initialization
When attempting to compress base models into extreme low-bit regimes, such as 2-bit or mixed 2-bit and 4-bit architectures, standard quantized adapter methods frequently exhibit severe convergence failures and catastrophic performance degradation 203821. The standard paradigm quantizes the base model entirely independently of the adapter initialization, creating a massive discrepancy between the initial quantized state and the optimal full-precision pre-trained state 203822.
LoftQ (LoRA-Fine-Tuning-Aware Quantization) mitigates this severe initialization gap through a complex joint optimization framework. Rather than quantizing the base model blindly, LoftQ seeks an optimal combination of a quantized base matrix and low-rank adapter matrices such that their mathematical sum strictly approximates the original, full-precision pre-trained weight 382223.
Through an alternating optimization algorithm utilizing precision quantization and singular value decomposition, LoftQ iteratively refines both the frozen backbone and the adapter initialization prior to the commencement of backpropagation 3823. This mathematically rigorous pre-alignment results in immense training stability. In highly challenging 2-bit quantization natural language understanding evaluations, models initialized via LoftQ achieved robust accuracy benchmarks in scenarios where baseline methods suffered from complete convergence collapse 3821.
Inference Latency and Production Deployment
The production deployment profiles of full fine-tuning, standard parallel adapters, and heavily quantized adapters present distinct architectural and latency trade-offs that dictate engineering strategy.
Weight Merging and Zero-Overhead Inference
Standard low-rank adapters and weight-decomposed variants boast a unique structural advantage for production environments: zero inference latency overhead. Because the adapter update matrix shares the exact geometric dimensions as the frozen base weight matrix, the trained adapter parameters can be permanently merged via simple matrix addition with the base weights post-training 81113.
The resultant merged model checkpoint is mathematically equivalent to the base model structure during the forward pass. At inference time, the model processes input tokens without executing any secondary computational branches or additional low-rank multiplications 14813. A controlled deployment benchmark indicates that a merged model executes inference at speeds virtually indistinguishable from an unadapted base model, demonstrating no statistically significant latency penalty 8.
Unmerged Graph Swapping and Dequantization Overhead
Alternatively, serving infrastructure can host the adapter weights in a non-merged state, dynamically injecting them into the inference graph. A single resident base model loaded in memory can be paired dynamically with dozens of distinct, lightweight adapter files. For every incoming user request requiring a different domain adaptation, the system executes a rapid weight swap operation to apply the relevant adapter matrices 67. While highly efficient for multi-tenant memory utilization, swapping explicit delta weights introduces a noticeable computational overhead compared to fully merged deployments, mildly impacting token generation throughput 78.
Quantized adaptation architectures introduce further latency complexities. When deploying a 4-bit quantized base model alongside higher-precision 16-bit adapters, the forward computational pass necessitates continuous, on-the-fly dequantization of the 4-bit weights back to 16-bit precision to execute the matrix multiplication operations 132214. This active dequantization overhead generally yields a 15% to 30% reduction in inference speed 22. Furthermore, merging quantized adapters directly into the base weights is profoundly challenging; the 4-bit base weights must be permanently dequantized to 16-bit to execute the mathematical addition, which immediately forfeits the vital memory savings achieved by quantization in the first place, while simultaneously risking numerical instability from lossy requantization 7. Consequently, machine learning engineers frequently accept higher inference latency as an unavoidable trade-off for the extreme memory efficiency provided by quantized deployment 22.
Scaling Laws for Parameter-Efficient Fine-Tuning
The pre-training of foundation models is fundamentally governed by empirical scaling laws. Decisive literature demonstrates that model generalization loss decreases predictably as a power-law function of computational investment, dataset token volume, and neural network parameter count 2425262728. The mathematical formalization of scaling dynamics for parameter-efficient adaptation has emerged as a critical research frontier, ensuring optimal hyperparameter configurations without exhaustive, resource-intensive trial and error 4729.
Rank Stabilization and Gradient Dynamics
In standard deep learning scaling formulations, the relationship between training resources and performance plots smoothly on a logarithmic scale 2426. However, researchers identified a distinct breakdown in scaling behavior when attempting to increase the rank hyperparameter in standard adapter frameworks. Conventional deep learning intuition dictates that expanding the rank capacity should yield proportional, power-law decreases in evaluation loss. Empirically, increasing the adapter rank beyond trivial thresholds (such as 16 or 64) yielded diminishing returns, resulting in severely saturated performance curves that offered no benefit for the increased parameter expenditure 1549.
Theoretical analysis isolated the failure to the standard scaling factor utilized in adapter matrices: dividing the learning rate scaling variable by the rank dimension. As the rank dimension increases exponentially, this inverse-linear scalar forces the gradients computed with respect to the adapter matrices to collapse, severely retarding the pace of adaptation and preventing the model from utilizing its expanded parameter space 49.
Rank-Stabilized adaptation architectures rectify this mathematical flaw by replacing the scaling factor with a theoretically derived alternative: scaling by the square root of the rank dimension 49. This refined adjustment maintains the statistical stability of both forward-pass activations and backward-pass gradients 49. This adjustment successfully restores standard power-law scaling properties to adapter layers, unlocking efficient, continuous learning dynamics at extreme rank dimensions required for highly complex, multi-modal domain adaptation 49.
Mutual Information Upper Bound Modeling
Traditional evaluation metrics such as cross-entropy and perplexity effectively quantify external generation performance, but they obscure the internal interplay between the frozen, generalized knowledge base and the novel, task-specific knowledge captured by the adapter 295051. To mathematically define parameter-efficient scaling relationships, researchers derived the Mutual Information Upper Bound, an internal metric tracking the strict dependency between the hidden states of the base neural network and the trainable adapter module 295051.
The Mutual Information Upper Bound scaling law isolates three variables: the parameter size of the base model, the adapter rank dimension, and the dataset complexity 29. Empirical assessments demonstrate a reliable inverse relationship across all three computational factors. As the foundational model size scales upwards, or as the rank dimension and dataset sizes expand, the mutual information boundary consistently decreases 472950. A decreasing mutual information metric proves that the adapter module relies significantly less on the base model's generalized features, demonstrating a stronger internal capacity to generalize and encapsulate task-specific domain knowledge independently 475052.
Empirical Benchmarks and Resource Requirements
The theoretical mathematical elegance of parameter-efficient methods directly translates to verifiable, empirical engineering advantages. By evaluating comparative hardware resource demands and accuracy metrics across structural variants, researchers can construct highly optimized model deployment pipelines.
Graphics Processing Unit Memory Utilization
The following structured comparison documents the approximated peak graphics processing unit memory required during the active training phase, contextualized across different parameter magnitudes and computational strategies.
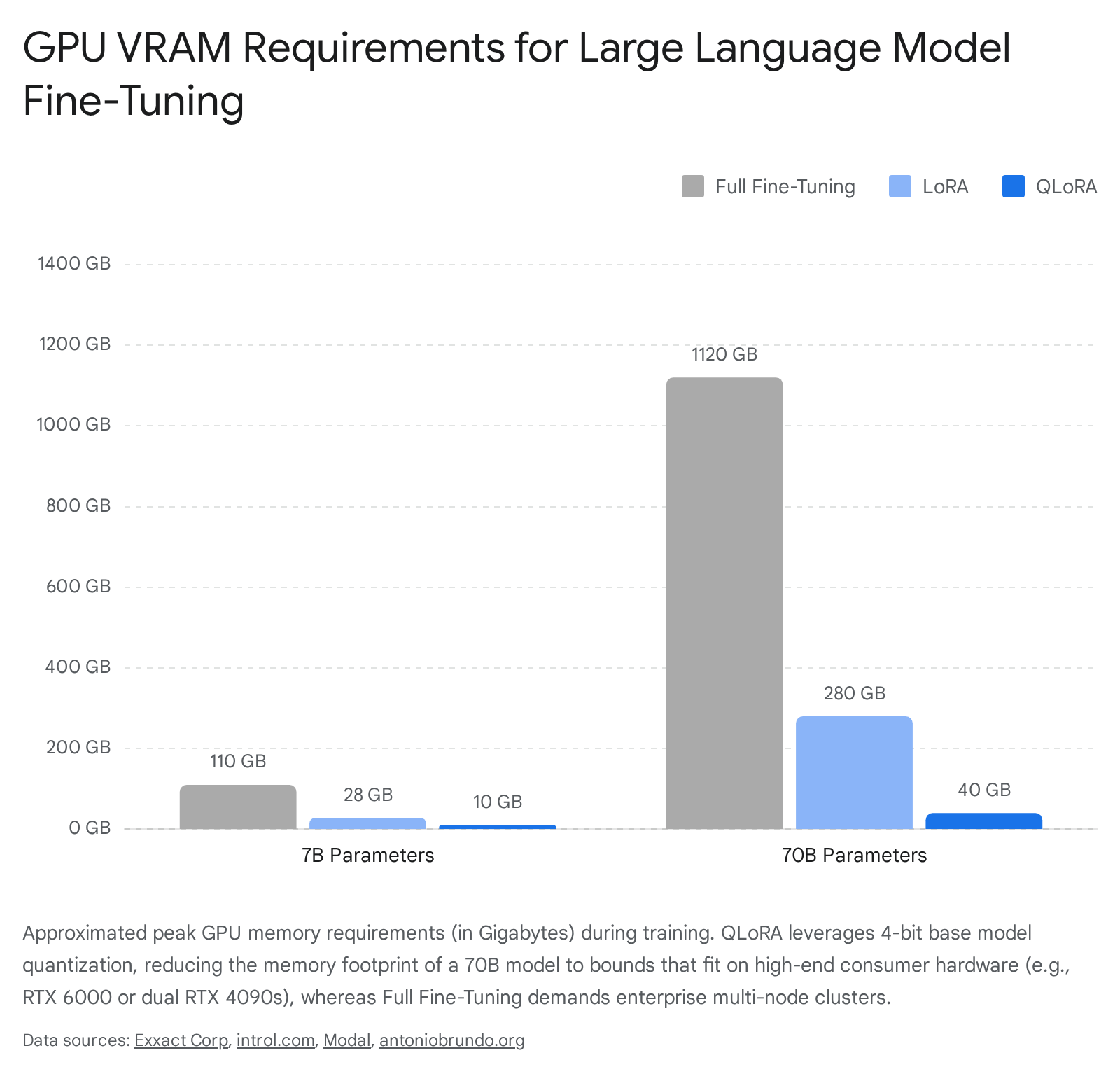
| Neural Architecture Scale | Full Fine-Tuning | Standard Adapter (16-bit) | Quantized Adapter (4-bit) | Representative Hardware |
|---|---|---|---|---|
| 7 Billion Parameters | ~100 - 120 GB | ~24 - 32 GB | ~8 - 12 GB | Single RTX 4090 |
| 13 Billion Parameters | ~180 - 200 GB | ~48 - 52 GB | ~15 - 20 GB | Single RTX 6000 / A6000 |
| 32 Billion Parameters | ~512 GB | ~64 - 80 GB | ~24 - 32 GB | Dual RTX 5090 / Single A100 |
| 70 Billion Parameters | ~1.4 - 1.8 TB | ~280 GB | ~35 - 48 GB | Multi-Node / Dual RTX 4090 |
The data reveals that at the 70-billion parameter threshold, full fine-tuning fundamentally ceases to be viable outside of specialized enterprise datacenters 47. Conversely, aggressive 4-bit quantization compresses the operational memory requirement to under 48 gigabytes, empowering high-end single-workstation fine-tuning environments and dramatically democratizing access to frontier model adaptation 71122.
Downstream Task Accuracy and Convergence
Determining the appropriate adaptation architecture relies on balancing the trilemma of training convergence speed, memory constraints, and ultimate task accuracy.
| Adaptation Architecture | Primary Structural Mechanism | Training Memory | Task Accuracy Profile |
|---|---|---|---|
| Standard Low-Rank | Parallel matrix update | Medium | High (Comparable to Full Fine-Tuning) |
| Quantized Adaptation | 4-bit base model compression | Ultra-Low | High (Slight degradation vs. Standard) |
| Weight-Decomposed | Magnitude & direction decoupling | Medium | Very High (Outperforms Standard) |
| Principal Singular | SVD matrix initialization | Medium | Very High (Faster convergence) |
| Vector-Based Random | Frozen global random matrices | Lowest | Moderate (Below Standard baseline) |
Empirical benchmarks consistently validate these structural profiles. On mathematics and coding evaluation datasets, architectures relying on singular value initialization achieve peak accuracy significantly faster than noise-initialized baselines, outperforming them by considerable percentage points under identical hyperparameter conditions 91231. Similarly, weight-decomposed variants demonstrate superior stability and accuracy on complex reasoning tasks, effectively closing the subtle performance gap that historically existed between standard parameter-efficient methods and resource-intensive full fine-tuning 262716.
Conclusion
The evolution from full parameter fine-tuning to Parameter-Efficient Fine-Tuning represents a fundamental optimization in machine learning architecture, transcending simple hardware workarounds. By mathematically constraining neural updates to intrinsic, low-rank sub-spaces, parameter-efficient methodologies effectively mitigate the severe risks of catastrophic forgetting while unlocking rapid, multi-tenant deployment strategies via dynamic adapter swapping.
Standard parallel adapters provide a highly robust, mathematically sound baseline that offers immense parameter reduction alongside the critical benefit of zero inference latency overhead. Quantized methodologies exponentially magnify memory efficiency via sophisticated data compression protocols, acting as the definitive gateway for training massive 70-billion parameter models on accessible hardware. Simultaneously, advanced structural innovations such as magnitude-direction decomposition, singular value initialization, and quantization-aware alignment resolve highly specific mathematical edge cases regarding training stability, convergence velocity, and extreme compression thresholds. Governed by increasingly precise empirical scaling laws, these advanced adaptation frameworks have definitively cemented themselves as the ubiquitous, optimal standard for aligning and customizing foundation models across both industry deployments and academic research sectors.