Multimodal Reasoning in Artificial Intelligence
The rapid evolution of artificial intelligence has precipitated a profound paradigm shift from unimodal, text-bound systems to Multimodal Large Language Models (MLLMs), frequently referred to as Large Vision-Language Models (LVLMs). These advanced systems attempt to bridge the vast semantic divide between continuous, high-dimensional visual signals and discrete linguistic tokens, enabling what is broadly categorized as multimodal reasoning 12. Multimodal reasoning represents the complex cognitive capacity to seamlessly process, synthesize, and logically infer conclusions from mixed-media data - simultaneously interpreting text, geometry, spatial relationships, and temporal dynamics 34. Unlike basic visual perception, which encompasses rudimentary tasks such as image classification or simple object bounding boxes, true multimodal reasoning demands deep, multi-step logical deduction and expert-level domain knowledge anchored directly to visual evidence 344.
The pursuit of expert artificial general intelligence (AGI) relies heavily on mastering these multimodal capabilities 5. Researchers frequently reference a leveled taxonomy for AGI, wherein Level 3 (Expert AGI) marks the critical threshold where a system performs on par with or surpasses human experts across a massive breadth of multi-discipline tasks 5. The evaluation of this capability has driven intense academic scrutiny between late 2023 and early 2026. However, the field is currently experiencing a foundational debate regarding both architectural optimization and cognitive fidelity. Architecturally, there is a pronounced divergence between traditional late-fusion models utilizing bolted-on vision adapters and the newer generation of native, early-fusion omni-models 46. Cognitively, an alarming body of evidence suggests that models achieving ostensibly superhuman scores on multimodal benchmarks may not be genuinely "reasoning" over visual inputs, but rather exploiting linguistic priors and dataset contamination - a phenomenon colloquially termed the Clever Hans effect 67.
This comprehensive research report provides an exhaustive analysis of multimodal reasoning in contemporary artificial intelligence. It systematically dissects the evolution of architectural mechanisms, exposes the pervasive Clever Hans effect alongside benchmark data contamination in widely used datasets like MMMU and MathVista, and evaluates advanced prompting and intervention techniques such as Vision Chain-of-Thought (CoT) and Visual Self-Refine (VSR). Furthermore, the report conducts a rigorous comparative analysis of leading Western models (GPT-4o, Gemini 1.5, Claude 3.5) against rapidly advancing Chinese models (Qwen-VL, DeepSeek-VL, CogVLM), highlighting their robust capabilities and catastrophic failure modes.
Architectural Mechanisms: Bridging Vision and Language
The foundational engineering challenge in multimodal artificial intelligence is the successful mapping of the continuous, pixel-dense space of imagery into the highly structured, discrete semantic embedding space of a language model. Over the past three years, the architectures facilitating this fusion have evolved through distinct eras, characterized primarily by where, when, and how the visual and linguistic modalities intersect within the neural network 810.
The Era of Late Fusion: Bolted-On Adapters and Projection Layers
The predominant architectural approach throughout 2023 and the majority of 2024 relied heavily on a "bolted-on" or late-fusion methodology 14. In this structural paradigm, the visual perception system and the linguistic reasoning system are trained entirely independently and are only merged post-hoc via an intermediary alignment module, often referred to as a connector or adapter 119. The classical architecture of this era consists of three discrete components: a pretrained vision encoder (frequently a CLIP-aligned Vision Transformer, such as ViT-L/14 or SigLIP), the connector module, and a frozen or minimally fine-tuned Large Language Model (LLM) backbone serving as the central reasoning engine 119.
The connector acts as a crucial translator between two alien embedding spaces. Early and highly influential iterations of this design, such as the LLaVA (Large Language-and-Vision Assistant) family, utilized relatively simple Multilayer Perceptrons (MLPs) to execute this translation 910. When a late-fusion model processes an image, the vision encoder extracts a sequence of patch features. The MLP linear projection layer subsequently maps these high-dimensional visual features so that the LLM interprets them as a sequence of "soft prompts" or visual tokens, which are prepended directly to the textual input sequence 9. The training recipe for these architectures typically involves a two-stage process. The first stage focuses purely on feature alignment, freezing both the vision encoder and the LLM while updating only the MLP projector using hundreds of thousands of image-text pairs 10. The second stage introduces visual instruction tuning, where the LLM and projector are updated end-to-end to teach the model to follow complex, multimodal commands 910.
Alternative late-fusion architectures employ cross-attention mechanisms or query-based adapters to manage the visual data flow. A prominent example is the Q-Former introduced in BLIP-2. In these models, a set of learnable query tokens attends to the frozen image embeddings from the vision encoder via cross-attention 914. This mechanism extracts and compresses only the visual information most relevant to the accompanying text prompt before passing the distilled representations to the language model 914.
While bolted-on architectures are highly computationally efficient to train - often requiring the optimization of only a few million parameters within the adapter - they suffer from a profound and inescapable representation bottleneck 111. Because the vision encoder and the language model were never jointly optimized from their inception, there remains an inherent structural mismatch in their latent representations 1. The language model is forced to interpret visual tokens that it did not organically learn to generate. This leads to severe information loss, particularly concerning fine-grained spatial details, high-resolution feature extraction, and dense optical character recognition (OCR) 1016. Furthermore, mapping a 1024x1024 high-resolution image into an LLM using an MLP can produce thousands of visual tokens, flooding the context window and diluting the model's attention capacity 1.
Deep Structural Integration and Visual Experts
In an effort to overcome the limitations of shallow MLP projections without abandoning the modularity of late fusion, some architectures introduced deeper structural integration. The CogVLM series pioneered the "visual expert" architecture, which diverges significantly from standard adapters 1718. Instead of merely projecting visual features at the input embedding layer, CogVLM injects dedicated visual expert modules deeply into both the attention mechanisms and the feed-forward networks (FFNs) across every layer of the LLM backbone 18.
This deep integration facilitates a nuanced, layer-by-layer fusion of visual and linguistic features 18. By maintaining separate parameter pathways for vision and text within the transformer blocks, the model preserves its inherent, pre-trained language capabilities while acquiring sophisticated visual reasoning skills 18. This architectural innovation allows models like CogVLM2 to achieve state-of-the-art results on rigorous mathematical benchmarks and video temporal grounding tasks without suffering from the catastrophic forgetting often associated with end-to-end visual instruction tuning 1718.
The Era of Native Multimodality: Early Fusion and Omni-Models
Recognizing the insurmountable limitations and latency issues of late-fusion adapters, the frontier of multimodal architecture aggressively transitioned in late 2024 and 2025 toward "native multimodality" or early-fusion Omni-models 819. Landmark systems such as OpenAI's GPT-4o, Google's Gemini 1.5 and 2.0 series, and the later iterations of the Qwen lineage (e.g., Qwen 3.5) discarded the separate vision encoder and connector bridge entirely 1419.
Native multimodal architectures process text, image, audio, and video tokens uniformly through a single, shared transformer backbone from the absolute beginning of their pretraining phase 411. Rather than translating pixels into a pre-existing linguistic space, the model is trained end-to-end on massive, interleaved corpora of mixed-media data 4. Consequently, images, audio spectrograms, and textual characters co-exist naturally within a unified, high-dimensional latent space 41620.
In the case of Google's Gemini architecture, the system employs a highly sophisticated sparse Mixture-of-Experts (MoE) design 4. As input tokens - whether derived from an image patch or a text string - enter the network, a learned routing mechanism dynamically directs them to specific "expert" neural sub-networks optimized for particular types of cognitive processing 421. This structural choice allows the model to scale its parameter count massively, enhancing its reasoning capacity, while maintaining strict inference efficiency, as only a fraction of the network is activated for any given token 2122. GPT-4o similarly abandoned the GPT-4V paradigm (which bolted a vision encoder onto the GPT-4 text model) in favor of a natively trained system 123. This end-to-end joint training drastically reduces the latency of translation layers and significantly enhances the model's ability to reason over complex visual structures, charts, and spatial relationships because the model learned to "see" and "read" simultaneously 1823.
The shift to native multimodality fundamentally alters the reasoning dynamics of the AI. By processing modalities simultaneously, early-fusion models mitigate the "perceptual bandwidth bottleneck" 112. The self-attention mechanisms within the unified transformer can seamlessly query relationships between a specific pixel patch and a corresponding textual instruction without the lossy, noisy translation of an MLP adapter 112. This unified approach has proven exceptionally powerful for complex workflows requiring high-density mixed media interpretation 1120.
The Illusion of Perception: The Clever Hans Effect and Cognitive Blindness
As native and late-fusion models began achieving ostensibly superhuman scores on multimodal benchmarks throughout 2024, a growing and highly critical body of literature revealed a troubling phenomenon: current LVLMs are often fundamentally "blind" to low-level visual reality 625. Despite their immense parameter counts and sophisticated reasoning engines, these models routinely and catastrophically fail at rudimentary perceptual tasks that a human child can solve instantaneously, exposing a severe and systemic deficit in generalized spatial cognition 1314.
The Perceptual Bandwidth Bottleneck and Spatial Failures
Rigorous research from 2024 and 2025 has systematically documented the failure modes of frontier models on tasks requiring fine-grained spatial localization, mental rotation, and basic object counting 1214. When evaluated on datasets designed to test human low-level vision, state-of-the-art models from the GPT, Gemini, Claude, and Qwen families exhibit severe performance degradation 131529. For example, in a primitive task determining whether two lines intersect (where lines simply form an "X" on a blank canvas), models struggle to differentiate self-occlusion from independent object crossing 1329. In tasks requiring the model to identify which specific letter is circled within a written word, or whether two overlapping shapes actually intersect, accuracy rates hover near random chance 67.
Counting tasks reveal equally severe limitations. While VLMs possess robust macro-semantic capabilities - easily identifying the presence of complex objects or scenes - they consistently fail to translate this understanding into precise quantitative reasoning, particularly when the numerosity exceeds five items 230. When faced with small-scale object counting, identifying the starting point of a complex line, and precise spatial localization, the models suffer from the aforementioned perceptual bandwidth bottleneck 12. The attention mechanisms within the transformer architecture fail to distinctly represent individual instances of identical or highly similar objects, causing the latent representations to blur, merge, or collapse entirely into a single semantic concept 16.
Bayesian Priors and the Clever Hans Effect
The most alarming aspect of these perceptual failures is how they expose the prevalence of the "Clever Hans" effect in modern artificial intelligence 67. The Clever Hans effect - named after the early 20th-century horse that appeared to perform arithmetic but was actually reading subconscious physical cues from its trainer - refers to a phenomenon where an AI system appears to solve a complex task, but is actually exploiting spurious correlations or statistical priors ingrained in its training dataset rather than engaging in genuine, grounded reasoning.
Extensive diagnostic probing has definitively demonstrated that VLMs rely overwhelmingly on the Bayesian priors of their massive text training corpora rather than the actual visual evidence presented in the image 6732. In adversarial experiments, researchers presented VLMs with counterfactual images that explicitly violate real-world expectations. For instance, when presented with an image of a bird digitally altered to have three legs, or an Adidas logo modified to feature four stripes instead of the traditional three, the models consistently "hallucinated" the standard text-based reality 267. They confidently asserted the bird had two legs and the logo had three stripes, despite the glaring visual evidence to the contrary 267. The average accuracy of state-of-the-art models on these counterfactual counting tasks plummeted to roughly 17%, and in the case of counting legs on a modified bird, accuracy dropped to a staggering 1.01% 67.
This catastrophic failure suggests that large-scale pretraining does not inherently induce gestalt-like visual perception or true world modeling 1417. Instead, the models are aggressively biased toward their parametric memory. When visual signals are ambiguous, dense, or contradict expected statistical norms, the model's textual priors completely override the visual signal 32. The model is not actually "seeing" the four stripes; it is semantically identifying the logo as "Adidas" and generating text based on the overwhelming statistical probability within its training data that Adidas possesses three stripes 67.
This phenomenon also heavily contaminates video reasoning models. On repetition counting tasks, such as those featured in the PushupBench dataset, weaker models were found to consistently guess the number "10" regardless of the actual video content 16. This occurred simply because 10 is the modal number of workout repetitions found in human fitness datasets on the internet 16. The models achieve ostensibly respectable baseline accuracy purely through statistical guessing, completely bypassing the complex temporal reasoning required to track physical state changes and action boundaries across video frames 16.
Benchmark Data Contamination and the Crisis of Evaluation
The discovery of the Clever Hans effect and the overwhelming reliance on linguistic priors in VLMs precipitated a profound crisis in multimodal benchmarking throughout 2024. For over a year, the artificial intelligence community relied heavily on static, multiple-choice benchmarks like MMMU (Massive Multi-discipline Multimodal Understanding) and MathVista to assert that models were rapidly approaching expert-level AGI capabilities 3518. However, subsequent forensic analyses of these benchmarks revealed massive data contamination, the exploitation of text-based shortcuts, and fundamental flaws in evaluation methodologies.
The MMMU and MathVista Paradigms
Introduced as the ultimate crucible for evaluating Expert AGI, the original MMMU benchmark consisted of 11.5K meticulously collected college-level problems spanning 30 subjects across six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering 35. It required deep domain knowledge to interpret 30 highly heterogeneous image types, including complex charts, chemical structures, and musical scores 35. Early zero-shot evaluations showed proprietary models like GPT-4V achieving roughly 56% accuracy, while open-source models lagged significantly behind 35.
MathVista similarly aggregated 6,141 examples derived from 31 different datasets, focusing intensely on mathematical reasoning within visual contexts 19. It challenged models with seven mathematical reasoning types (including algebraic, geometric, and statistical reasoning) across diverse visual contexts such as newly created IQTest puzzles, FunctionQA plots, and academic PaperQA figures 1819. It was universally heralded as the definitive test for integrating mathematical syntax with visual spatial awareness 18.
The MMMU-Pro Correction and the Collapse of Scores
By mid-to-late 2024, it became evident that models were effectively "gaming" MMMU and similar benchmarks. Comprehensive audits revealed that a substantial portion of the questions could be solved via text-only reasoning, allowing the models to completely bypass the image entirely and answer based solely on the textual prompt 2021. Furthermore, the standard four-option multiple-choice format allowed advanced LLMs to use linguistic elimination strategies, pattern matching, and statistical guessing to deduce the correct answer without engaging in actual multimodal understanding 202239.
To enforce rigorous evaluation and strip away these linguistic shortcuts, researchers introduced MMMU-Pro 2023. This robust and highly challenging variant instituted a mandatory three-step correction process: (1) aggressively filtering out any questions solvable by text-only models, (2) expanding the candidate options from four to ten to drastically reduce the statistical probability of random guessing, and critically, (3) introducing a "vision-only" input setting 202241. In this vision-only setting, the textual question, the context, and all ten options are physically embedded into a single screenshot or image; the AI receives no textual prompt other than an instruction to read the image 202241.
The results of MMMU-Pro were devastating for the illusion of multimodal mastery. The shift from 4 to 10 options caused an immediate and severe 10.7% drop in GPT-4o's accuracy, confirming that models were previously relying heavily on elimination heuristics 2022. The transition to the vision-only setting caused even further degradation. Overall, performance plummeted across the entire spectrum of frontier models by 16.8% to 26.9% when compared to their original MMMU scores 2022.
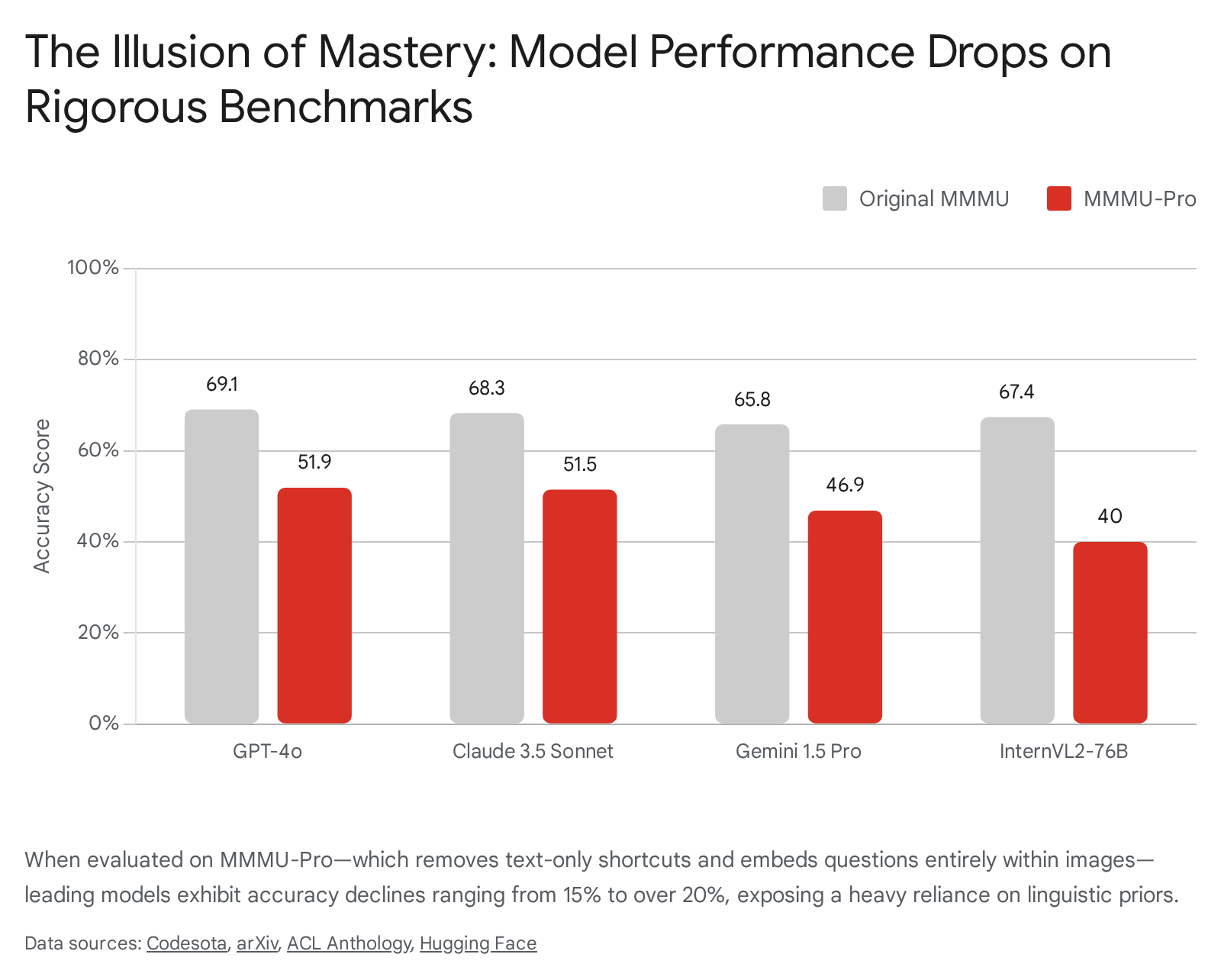
Claude 3.5 Sonnet dropped 16.8%, and Gemini 1.5 Pro dropped a massive 18.9% 20.
The vision-only setting proved particularly fatal because it required the AI to truly "see" and "read" simultaneously 2041. The models had to seamlessly integrate optical character recognition with high-level reasoning; they could no longer rely on cleanly parsed, discrete text tokens injected directly into their prompt context 2021. Interestingly, diagnostic experiments revealed that injecting explicit OCR prompts into the vision-only setting did not significantly improve performance for frontier models like GPT-4o 2021. This indicated that the failure was not merely a low-level inability to read the embedded text, but a profound architectural inability to simultaneously hold, structure, map, and reason over interleaved visual and textual spatial data without the explicit syntactic scaffolding provided by a standard text prompt 2021.
Comparative Analysis: Western vs. Chinese Frontier Models
The global landscape of multimodal reasoning is currently heavily bifurcated between highly funded, closed-source Western proprietary models (developed by OpenAI, Anthropic, and Google) and a rapidly advancing, largely open-weights ecosystem emerging from Chinese research institutions and technology conglomerates (such as Alibaba's Qwen team, DeepSeek, and Zhipu AI).
Western Hegemony: Synthesis, Optimization, and Nuance
GPT-4o (OpenAI): Operating as a fully native omni-model, GPT-4o maintains a dominant position across unstructured visual reasoning tasks 2023. By unifying text, vision, and audio into a single embedding space, it executes real-time reasoning across interleaved inputs with remarkably low latency, entirely bypassing the translation delays inherent to adapter models 2023. It possesses exceptional zero-shot OCR capabilities and leads the proprietary pack in general versatility. However, despite its structural dominance, it still suffers heavily from the Clever Hans effect, failing consistently in counterfactual counting and granular spatial relation inference 1415.
Gemini 1.5 Pro & 2.0 (Google): Gemini's primary architectural differentiator is its utilization of a sparse Mixture-of-Experts (MoE) design trained natively on multimodal data from its inception 411. This design enables a massive context window (scaling up to 2 million tokens for Gemini 1.5 Pro), allowing the model to process hour-long videos, extensive codebases, and hundreds of pages of interleaved documentation natively 44243. Consequently, Gemini consistently excels in video-based knowledge acquisition (e.g., Video-MMMU) and complex, multi-step temporal reasoning benchmarks 1124. However, its reliance on massive context sometimes results in localized attention failures when tasked with dissecting single, highly dense, static images 1124.
Claude 3.5 Sonnet (Anthropic): Claude 3.5 occupies a unique architectural space among Western leaders. Rather than shifting entirely to a native omni-model structure, Anthropic maintained and hyper-optimized an adapter-based visual parsing framework 1204546. It is widely considered the industry standard for precision document intelligence, excelling uniquely at interpreting structured PDFs, dense financial tables, and complex academic layouts 2046. However, its bolted-on architecture results in notable, systemic vulnerabilities in low-level, perception-only tasks (such as those evaluated in VisOnlyQA), where it struggles with intersecting lines and object counting significantly more than native early-fusion models 71113.
The Chinese Ascent: Architectural Innovation and Open-Weights Scaling
Chinese models have aggressively closed the performance gap, frequently abandoning traditional late-fusion architectures in favor of massive MoE scaling and native multimodal integration.
Qwen2.5-VL and Qwen 3.5 (Alibaba): The Qwen series represents arguably the most formidable open-weight competitor to Western proprietary models. While Qwen2-VL utilized a sophisticated late-fusion ViT coupled with an MLP projection layer, Qwen 3.5 initiated a profound shift to an early-fusion native multimodal architecture 1019. This transition combined linear attention mechanisms (specifically Gated Delta Networks) with MoE routing 19. Qwen2.5-VL 72B achieves a staggering score of 70.2 on the standard MMMU and excels remarkably in mathematical reasoning (MathVista), frequently matching or exceeding GPT-4o in visual logic deduction and spatial comprehension 394748. Furthermore, its architectural shift allows it to handle massive multimodal context lengths efficiently, driving state-of-the-art performance on video reasoning benchmarks like LVBench 1947.
DeepSeek-VL2: DeepSeek-VL2 approaches the multimodal challenge by utilizing an advanced MoE language backbone combined with a novel dynamic tiling vision encoding strategy 449. Rather than compressing high-resolution images into a fixed, rigid number of tokens - which inevitably destroys fine visual detail - DeepSeek-VL2 divides images of varying aspect ratios into dynamic, high-resolution tiles 4. This preserves the fine-grained visual details vital for accurate OCR, document analysis, and chart understanding 4. Furthermore, its language component leverages Multi-head Latent Attention (MLA), which compresses Key-Value caches to enable highly efficient inference 4. Despite having significantly fewer activated parameters during inference (e.g., the Base model activates only 4.5B parameters), it rivals much heavier dense models across grounding benchmarks and MMMU 449.
CogVLM2 & CogVLM2-Video (Zhipu AI): The CogVLM family diverges fundamentally from standard MLP-adapters by utilizing the previously discussed "visual expert" architecture 1718. By injecting visual experts deep into the attention and FFN layers of a Llama-3 backbone, the model facilitates a deep fusion of visual and linguistic features 18. This deep integration yields state-of-the-art results on MathVista and video temporal grounding tasks, effectively managing the complex interplay between multi-frame video inputs, timestamps, and language 1718.
Table 1: Comparative Model Performance Metrics (Late 2023 - Early 2026)
Note: Metrics reflect reported peak benchmark evaluations sourced from academic literature and technical reports. "MMMU-Pro Vision" reflects the highly rigorous vision-only setting which prohibits text-based shortcuts.
| Model / Architecture Type | Parameters (Active/Total) | MMMU (Val) | MMMU-Pro (Standard/Vision) | MathVista (Accuracy) | Primary Architectural Mechanism |
|---|---|---|---|---|---|
| GPT-4o (Western) | Proprietary | 69.1% | 54.0% / 51.9% | ~60%+ | Native Multimodal (Early Fusion) 20223923 |
| Gemini 1.5 Pro (Western) | Proprietary | 62.2% | 46.9% / 43.5% | 68.1% | Native Sparse MoE 392342 |
| Claude 3.5 Sonnet (Western) | Proprietary | 68.3% | ~55.0% / 51.5% | 67.7% | Adapter/Bolted-on Vision 39234245 |
| Qwen2.5-VL 72B (Chinese) | Dense 72B | 70.2% | Evaluated high | ~80%+ (Math) | Evolving Late to Early Fusion 33947 |
| DeepSeek-VL2 (Chinese) | 4.5B / MoE | ~60%+ | Data Unavailable | 48.0% | MoE + Dynamic High-Res Tiling 3449 |
| CogVLM2-19B (Chinese) | Dense 19B | ~50%+ | Data Unavailable | 50%+ | Visual Expert Deep Integration 171819 |
Table 2: Capability Dichotomy: Robust Reasoning vs. Cognitive Failure Modes
| Capability Domain | Robust Performance (What Models Get Right) | Catastrophic Failure Modes (Cognitive Blindness) |
|---|---|---|
| Document Intelligence & OCR | Excels at parsing structured PDFs, extracting tabular data, and summarizing academic layouts (Claude 3.5, GPT-4o) 1147. | Fails when OCR is embedded in visually distorted, highly dense, or adversarial noise; open-source VLMs lag severely behind proprietary OCR 2551. |
| Macro-Semantic Understanding | Highly accurate at classifying scenes, identifying broad objects, and determining artistic or stylistic contexts 2. | Fails at fine-grained spatial relation inference; cannot distinguish self-occlusion from intersecting lines 1326. |
| Mathematical Problem Solving | Solves complex algebraic and geometric questions when presented alongside standard, expected charts (MathVista) 1927. | Collapses on counterfactual counting; guesses based on statistical priors rather than tracking visual objects (e.g., counting 4-striped logos) 2616. |
| Chart & Diagram Parsing | Can extract high-level trends from line charts and hierarchical tree structures (80%+ accuracy) 54. | Fails on data-dense anomaly detection and bubble charts; struggles without explicit numerical labels, hallucinating data points 5455. |
Advanced Prompting and Intervention Mechanisms
As raw architectural scaling hits diminishing returns regarding low-level perceptual blindness, researchers have increasingly turned to test-time interventions, cognitive frameworks, and advanced prompting techniques. These methodologies attempt to force models to "look closer" and break free from the constraints of the perceptual bandwidth bottleneck.
Visual Markers and Set-of-Mark (SoM) Prompting
Drawing inspiration from the highly successful prompt engineering techniques utilized in Natural Language Processing (NLP), visual prompting involves physically modifying the input image space with human-perceivable markers before processing 28. The most prominent and heavily researched technique in this domain is Set-of-Mark (SoM) prompting 2557. SoM overlays semi-transparent bounding boxes, alphanumeric labels, or distinct colored masks directly onto the constituent objects within an image before passing the modified image to the VLM 255157.
When applied to highly capable proprietary models like GPT-4V, SoM unleashes extraordinary visual grounding and segmentation capabilities 5729. By referencing the superimposed alphanumeric tags, the LLM effectively bypasses the spatial ambiguity inherent to its perceptual bandwidth bottleneck. The model no longer has to internally calculate and guess where an object is located; it merely has to read the tag associated with the semantic feature 51.
However, empirical evaluations reveal that SoM is highly fragile when applied to open-source models. Research explicitly indicates that applying SoM to LLaVA-based architectures actually decreases overall performance 2551. The root cause of this failure lies in the architectural differences discussed earlier: LLaVA's bolted-on architecture suffers from weak zero-shot OCR capabilities compared to native models like GPT-4o 25. If the vision encoder cannot clearly and accurately read the overlaid alphanumeric marker, the spatial grounding mechanism fails entirely, and the added visual noise simply confuses the model's representations further 2551.
Visual Self-Refine (VSR) and Iterative Feedback
To combat the limitations of passive visual parsing - particularly in dense academic environments like complex charts without explicit numerical labels - researchers have introduced active, agentic self-correction paradigms, most notably Visual Self-Refine (VSR) 5530.
Standard VLMs operate in a single, one-shot forward pass, which frequently results in data omissions, geometric misalignments, and the hallucination of non-existent data points when parsing dense charts 5560. VSR addresses this by mimicking the human cognitive heuristic of "pointing with a finger" to physically trace data 55. The VSR framework fundamentally decomposes chart parsing into a Refine Stage and a subsequent Decode Stage. In the Refine Stage, the model is prompted to generate exact pixel-level coordinate localizations for specific data points 5530. Crucially, an external programmatic script then plots these generated coordinates onto the original image as distinct visual anchors, and this marked-up image is fed back to the model as a new input 5560.
This process creates a closed-loop visual feedback system. The model physically "sees" exactly where it guessed the data points were located. If a plotted anchor misses a trendline on the graph, the model intuitively recognizes its own perceptual error and generates corrected coordinates in the next iteration 5530. Only after the coordinates are iteratively verified does the Decode Stage execute to extract the final structured data 5530. This deliberate architectural trade-off - substantially increasing inference compute latency in exchange for iterative visual deliberation - drastically improves performance on rigorous benchmarks like ChartQA and ChartP-Bench 5530. It mirrors the systemic logic of OpenAI's o1 reasoning models, but uniquely applies it directly to spatial perception 55.
Vision Chain-of-Thought (CoT) and Answer Inertia
While textual Chain-of-Thought (CoT) revolutionized LLM reasoning by forcing models to decompose complex logic into intermediate steps, its application in multimodal contexts is highly complex and fraught with systemic "knowledge conflict" 32. In theory, Vision CoT forces the model to articulate its perceptual observations sequentially before arriving at a mathematical or logical conclusion, yielding marked improvements on rigorous benchmarks like MMMU-Pro 2021.
However, deep analyses of multimodal reasoning dynamics reveal a critical vulnerability: Answer Inertia 32. In vision-language reasoning, the integration of textual explanations with visual evidence introduces significant uncertainty. Models frequently demonstrate a psychological-like bias where early linguistic commitments override persistent, contradictory visual signals 32. If a model's CoT process begins by falsely identifying a shape or quantity based on an ingrained language prior (e.g., stating "I see an Adidas logo, which has three stripes"), the subsequent reasoning steps will stubbornly attempt to justify the hallucinated state rather than revising the observation based on the actual visual input 32. The textual reasoning effectively blinds the visual encoder, reinforcing the Clever Hans effect through confident, logical, yet entirely ungrounded rationalization. This highlights that while CoT improves syntactic reasoning, it cannot artificially generate raw perceptual acuity if the underlying visual representations are flawed.
Synthesis and Future Outlook
The pursuit of multimodal artificial intelligence has successfully produced systems capable of astonishing macro-semantic synthesis, expert-level knowledge retrieval, and complex document reasoning. The architectural migration from late-fusion, bolted-on adapters to native, early-fusion Omni-models represents a critical leap in reducing latency and establishing a truly unified latent space. Concurrently, the rise of Chinese open-weights models, particularly the Qwen and DeepSeek series, demonstrates that MoE architectures and dynamic resolution scaling can match and occasionally surpass Western hegemony in specific quantitative domains.
However, the field must confront the persistent illusion of perception. The Clever Hans effect - where models utilize powerful linguistic priors to bypass genuine spatial parsing - remains a fundamental cognitive vulnerability. Benchmarks like MMMU-Pro and documented failure modes in basic geometric counting explicitly prove that current LVLMs do not truly "see" the world in a human-like, gestalt manner; they map continuous visual approximations to highly probable discrete linguistic vectors. Until architectures explicitly resolve the perceptual bandwidth bottleneck - whether through deep dynamic tiling, iterative Visual Self-Refinement heuristics, or novel forms of inherent 3D spatial grounding - multimodal AI will remain a brilliant linguistic reasoning engine trapped behind fundamentally flawed and biased optical sensors.