Model-based reinforcement learning for sample-efficient planning
Sequential Decision-Making and Reinforcement Learning
The evolution of artificial intelligence has been fundamentally accelerated by reinforcement learning (RL), a paradigm through which autonomous agents learn optimal decision-making strategies by interacting continuously with an environment. The most prominent early successes in this domain, including the mastery of complex board games and the achievement of superhuman performance across the Atari 57 suite, were driven primarily by model-free reinforcement learning (MFRL) architectures 12. Model-free systems directly approximate a value function or a control policy by processing vast quantities of interaction data, entirely bypassing the need to understand the underlying physical or logical rules governing the environment. While MFRL algorithms can achieve exceptionally high asymptotic performance, they are notoriously sample-inefficient. They typically require millions, and sometimes billions, of environmental interactions to converge on an optimal behavior policy 23.
In digital simulations, the computational cost of rapid trial-and-error is manageable. However, this sample inefficiency becomes a critical bottleneck when transitioning reinforcement learning to real-world applications such as robotics, healthcare, autonomous driving, and industrial control systems. In these physical domains, data collection is strictly bound by the constraints of time, hardware wear-and-tear, safety considerations, and prohibitive operational costs 25. Training a physical autonomous vehicle or a robotic manipulator for millions of iterations is practically impossible 2.
Model-based reinforcement learning (MBRL) directly addresses this fundamental limitation by altering the core learning architecture. Instead of learning a policy purely through trial-and-error interactions, an MBRL agent actively builds an internal predictive model of the environment's dynamics 45. By learning the transition probabilities and reward functions, the agent can simulate future states internally - a process conceptually identical to forward planning or latent imagination. This mechanism allows the agent to conduct thousands of simulated trials entirely within its own neural network, optimizing its policy with significantly fewer real-world interactions 26.
Formal Foundations of Markov Decision Processes
Reinforcement learning formalizes sequential decision-making through the mathematical framework of a Markov Decision Process (MDP). An MDP is rigorously defined by the tuple $(\mathcal{S}, \mathcal{A}, \mathcal{P}, \mathcal{R}, \gamma)$ 16:
- $\mathcal{S}$: The continuous or discrete state space representing all possible configurations of the environment.
- $\mathcal{A}$: The action space available to the agent.
- $\mathcal{P}(s_{t+1} | s_t, a_t)$: The transition kernel, which defines the probability distribution of moving to the next state given the current state and a specific action.
- $\mathcal{R}(s_t, a_t)$: The reward function, providing a scalar feedback signal for executing a specific state-action pair.
- $\gamma \in [0, 1)$: The discount factor, dictating the present value of future rewards and determining the agent's planning horizon.
In model-free RL, the agent directly optimizes a policy $\pi(a|s)$ or an action-value function $Q(s,a)$ based on observed trajectories, never attempting to calculate $\mathcal{P}$ or $\mathcal{R}$. In model-based RL, the central objective is to explicitly construct an approximation of the environment, denoted as $\hat{\mathcal{P}}(s_{t+1} | s_t, a_t)$ and $\hat{\mathcal{R}}(s_t, a_t)$, which are typically parameterized by deep neural networks with weights $\phi$ 56.
The taxonomy of MBRL is broadly divided based on the agent's prior access to the environment's transition dynamics. In specific, highly structured environments, the exact transition matrices $\mathcal{P}$ and $\mathcal{R}$ are explicitly defined and accessible. Classical board games like Chess, Shogi, and Go belong to this category. Algorithms such as AlphaZero leverage the exact ground-truth rules of the game to run Monte Carlo Tree Search (MCTS), expanding possible future trajectories with perfect fidelity because the "model" is simply the game engine itself 67.
However, in the vast majority of real-world scenarios, the environmental dynamics are highly complex, stochastic, and entirely unknown. Algorithms operating in this regime must autonomously construct an approximate model $\hat{\mathcal{P}}$ from raw observational data 6. The efficacy of the downstream policy is entirely bottlenecked by the fidelity and predictive capacity of this learned model. If the dynamics model is insufficiently precise, the policy optimization phase is prone to overfit to the deficiencies of the model, leading to suboptimal behavior or catastrophic failure - a phenomenon widely known as model bias 5.
| Algorithmic Paradigm | Prior Knowledge of Dynamics | Primary Planning Mechanism | Representative Algorithms | Typical Application Domains 610 |
|---|---|---|---|---|
| Model-Based (Known Model) | Perfect ground-truth rules | Monte Carlo Tree Search (MCTS) | AlphaZero | Board games, deterministic logical puzzles |
| Model-Based (Learned Model) | None (learned from data) | Latent Imagination / Rollouts | Dreamer (V1-V3), MBPO, PETS | Robotics, visual control, continuous domains |
| Model-Based (Implicit Model) | None (learned from data) | Value-Equivalent MCTS | MuZero, EfficientZero | Atari, complex visual discrete-action spaces |
| Model-Free (Baseline) | None | Direct Policy/Value Updates | PPO, SAC, DQN, Rainbow | General digital simulation, low-cost data domains |
Architectural Paradigms for World Modeling
The central challenge in building a learned model is accurately representing high-dimensional, partially observable, and noisy state spaces, such as raw pixel inputs from a camera or complex multi-joint proprioception in robotics. Early attempts at model learning struggled because predicting raw pixel transitions in high-dimensional space is computationally prohibitive and highly sensitive to compounding errors 78. Recent advancements have shifted entirely away from modeling the environment in its native observation space, favoring the construction of compact, latent "world models."
Recurrent State-Space Models
A dominant architecture for pixel-based MBRL is the Recurrent State-Space Model (RSSM), popularized by the Dreamer family of algorithms 91011. The RSSM compresses raw observations into a latent representation to perform forward predictions. It structurally divides the latent state into two distinct mathematical components to manage uncertainty. The deterministic state, typically modeled via a Gated Recurrent Unit (GRU) or Long Short-Term Memory (LSTM) network, tracks the temporal history and context across multiple timesteps 10. Conversely, the stochastic state is a probabilistically sampled vector that explicitly encodes the uncertainty and multi-modal nature of the environment's transitions.
By separating deterministic memory from stochastic variations, the RSSM effectively handles partial observability while retaining the diversity of possible future outcomes in its simulated rollouts 10. During the learning phase, the world model is trained via self-supervision to reconstruct the original observation, predict the immediate reward, and forecast whether the episode will terminate 10. More recent variations, such as decoder-free extensions, utilize contrastive learning and InfoMax objectives to bypass the image reconstruction phase entirely. This mitigates issues like "object vanishing," where an autoencoder fails to prioritize small but critical objects in an image simply because they occupy few pixels 15.
Value-Equivalent and Implicit Models
While models like Dreamer rely on generative reconstruction to learn a latent space, this approach forces the neural network to expend massive representational capacity on reconstructing task-irrelevant visual details, such as the exact rendering of clouds moving in a racing game or the specific texture of a wall 7812.
The MuZero algorithm pioneered an alternative paradigm known as the value-equivalent model. Instead of predicting the next pixel frame, the MuZero model is trained strictly to predict quantities that directly impact decision-making: the expected reward, the state value, and the policy prior 7812. The underlying latent state is completely implicit; it has no requirement to map back to a human-interpretable image.
This value-equivalence principle dictates that two states are functionally equivalent if they yield the same sequence of rewards and optimal actions. By forcing the latent dynamics model to predict the multi-step Bellman update rather than the raw observation, the algorithm filters out environmental noise, enabling highly efficient planning over long horizons without the heavy computational burden of image decoding 78.
Policy Optimization and Planning Mechanisms
Once an approximate model of the environment is constructed, MBRL agents leverage this model to derive an optimal policy. The specific mechanism of policy optimization varies significantly across different algorithmic architectures, balancing computational constraints against the need for rigorous forward exploration.
Background Planning and Data Augmentation
In algorithms descended from the classical Dyna architecture, the learned model acts primarily as an advanced data augmentation engine. The agent interleaves real-world interaction with "imagined" interaction, injecting synthetic data into the training pipeline of a standard model-free algorithm 6.
A prominent modern implementation of this is Model-Based Policy Optimization (MBPO). MBPO utilizes a model-free algorithm - typically Soft Actor-Critic (SAC), a highly reliable off-policy continuous control method - but supplements the real-world replay buffer with synthetic trajectories generated by the learned dynamics model 613. To prevent the compounding errors inherent in imperfect models from degrading the policy, MBPO strictly relies on short-horizon rollouts. The model generates predictions branching only a few steps into the future, originating from real states previously visited by the agent 613. This careful bounding of the imagination horizon ensures that the policy benefits from dense, model-generated data without collapsing under the weight of accumulated predictive inaccuracies. Similar frameworks, such as Aligned Latent Models (ALM), execute this process entirely in a latent space using algorithms like Deep Deterministic Policy Gradient (DDPG), further reducing wall-clock training times 13.
Decision-Time Planning
Decision-time planning involves computing a localized policy "on the fly" at each timestep by projecting multiple possible futures. AlphaZero and MuZero epitomize this approach by utilizing Monte Carlo Tree Search (MCTS) 6710. When the agent encounters a state, it pauses to conduct a massive tree search through the latent space. It simulates thousands of potential action sequences, evaluates their predicted rewards using the value-equivalent network, and backs up those values to the root node to inform the immediate action 1018.
This yields an highly optimized, context-specific action selection. MCTS provides robust lookahead capabilities, making it exceptionally powerful in discrete-action environments. However, MCTS is computationally expensive to execute at every single inference step, and adapting tree-search algorithms to high-dimensional continuous control spaces remains an ongoing mathematical challenge 6.
Latent Imagination and Global Policy Learning
The Dreamer algorithms (DreamerV1 through V3) adopt a "latent imagination" approach, which bypasses decision-time search entirely. After training the RSSM world model on collected data, Dreamer freezes the model and uses it to simulate millions of trajectories entirely within the continuous latent space 10.
An actor-critic network is then trained on these imagined trajectories.
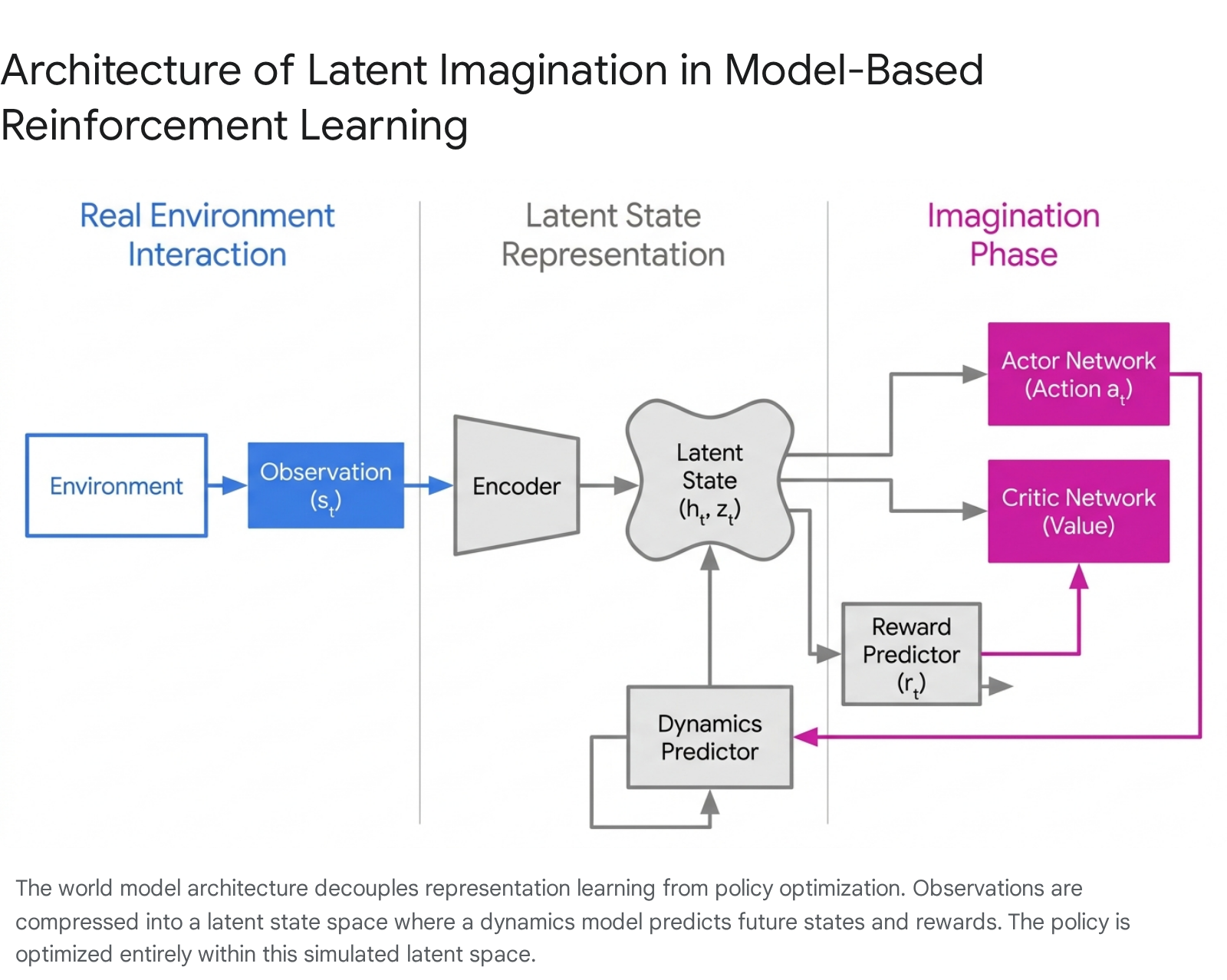
The critic learns to estimate the cumulative future reward of a latent state, and the actor learns to select actions that maximize this value 10. Because this policy optimization happens in the compact, low-dimensional latent space without the necessity of decoding back to high-resolution pixels, it is remarkably fast. Crucially, once the actor network is fully trained via imagination, the agent reacts almost instantaneously at inference time. It uses the global policy to select actions directly from the current encoded state, circumventing the massive inference-time computational overhead associated with MCTS or Model Predictive Control (MPC) 610.
To address the limitations of short-horizon optimization in standard MBRL, researchers have also developed Long Short-Term Imagination (LS-Imagine). This framework allows the world model to simulate goal-conditioned "jumpy" state transitions, calculating long-term intrinsic rewards without requiring granular one-step predictions, thereby vastly improving exploration in open-world environments 11.
Sample Efficiency and Atari Benchmarks
To rigorously evaluate the sample efficiency of reinforcement learning algorithms, the research community relies heavily on the Atari 100k benchmark. Historically, agents tested on the full Atari 57 suite (such as standard DQN, PPO, or SAC) were permitted 200 million frames (equivalent to 50 million environmental steps) to learn a task 31914.
The Atari 100k benchmark artificially constrains the agent to exactly 100,000 environment interactions - roughly equivalent to two hours of real-time human gameplay, mirroring the amount of practice time professional human testers were given before evaluation 1415. This severe data constraint effectively exposes the sample inefficiency of pure model-free approaches and highlights the rapid learning capabilities of model-based systems. Performance on this benchmark is standardized using Human-Normalized Scores (HNS), where a score of 1.0 (or 100%) represents median human performance, and 0.0 represents a random baseline.
The integration of world models has allowed MBRL architectures to achieve previously unattainable sample efficiency thresholds. The advent of EfficientZero - an algorithm building upon MuZero with self-supervised consistency, value-prefix prediction, and model-based off-policy correction - marked a paradigm shift in the discipline. EfficientZero was the first algorithm to achieve superhuman performance on the Atari 100k benchmark, recording a mean HNS of 194.3% and a median HNS of 109.0% 31522. The agent effectively matched the performance that classical Deep Q-Networks (DQN) required 200 million frames to achieve, but did so using 500 times less data 3.
| Algorithm | Primary Architecture Paradigm | Atari 100k Mean HNS | Atari 100k Median HNS | Relative Data Budget vs Legacy Baselines | Notable Algorithmic Characteristics 319142223 |
|---|---|---|---|---|---|
| EfficientZero | Model-Based (MCTS / Value-Equivalent) | 194.3% | 109.0% | 1/500th (100k steps) | Utilizes off-policy correction and value-prefix prediction. Highly sample-efficient but computationally intensive. |
| DreamerV3 | Model-Based (Latent Imagination) | ~130.0% | ~110.0% | 1/500th (100k steps) | Employs symlog predictions and twohot encoding. Highly robust across discrete and continuous domains. |
| BBF (Bigger, Better, Faster) | Model-Free (Value-Based Scaling) | > 190.0% | > 100.0% | 1/500th (100k steps) | Uses 50% parameter perturbation, exponential horizon decay, and large Impala-CNN networks. |
| PPO / SAC | Model-Free (Policy Gradient / Actor-Critic) | Sub-human | Sub-human | 1/500th (100k steps) | Standard baseline methods. Highly unstable under extreme data constraints; requires ~10M steps to stabilize. |
| DQN / Rainbow | Model-Free (Value-Based) | ~20% - 30% | ~10% - 20% | 1/500th (100k steps) | Legacy baseline. Fails to generalize rapidly; typically requires the full 200M step budget to reach optimal capacity. |
While EfficientZero demonstrated the supremacy of MBRL in low-data regimes, recent developments indicate that the boundary between model-based and model-free efficiency is blurring. The BBF (Bigger, Better, Faster) agent is a purely value-based, model-free algorithm that manages to match, and in some metrics exceed, EfficientZero's sample efficiency on Atari 100k 1416. BBF achieves this by massively scaling the neural networks used for value estimation using Impala-CNN architectures, significantly increasing the replay ratio, and resetting 50% of the network parameters periodically to avoid early statistical overfitting 1416. Furthermore, BBF implements an exponentially decaying update horizon. This suggests that while explicit world models offer an elegant solution to sample efficiency, aggressive computational scaling and regularization in model-free architectures can yield competitive results, challenging the assumption that environment modeling is strictly necessary for rapid learning 1416.
The Objective Mismatch Phenomenon
Despite their theoretical appeal and benchmark successes, model-based reinforcement learning systems suffer from distinct structural vulnerabilities that limit their reliable deployment. The most pervasive vulnerability is the accumulation of predictive inaccuracies, commonly termed model bias or compounding errors 251726. Because the learned transition model is only an approximation, its predictions diverge slightly from reality at each simulated timestep. When the agent attempts to roll out a trajectory far into the future, these minor step-wise errors compound multiplicatively 1718. Consequently, the agent begins optimizing its policy against a hallucinated environment.
However, researchers have identified a deeper structural flaw driving this failure, termed the Objective Mismatch phenomenon 18192030. In standard MBRL architectures, the dynamics model and the control policy are optimized using completely divergent objective functions. The dynamics model is traditionally trained via supervised learning to minimize a prediction error metric, such as the Mean Squared Error (MSE) or Negative Log-Likelihood (NLL) of one-step-ahead state transitions 261920. Conversely, the actor policy is trained strictly to maximize the cumulative discounted reward generated by the environment 18.
Empirical analysis demonstrates that the log-likelihood of a model's one-step prediction accuracy is frequently uncorrelated with the downstream performance of the control policy it supports 1920. A model might achieve an excellent global MSE by perfectly reconstructing the static background pixels of a scene, while utterly failing to predict the trajectory of a small, fast-moving, high-reward object. Conversely, a globally inaccurate model that correctly captures the local dynamics directly relevant to the agent's immediate task may yield vastly superior control policies 19.
To mend this mismatch, researchers have proposed four primary categories of decision-aware model learning paradigms designed to synchronize the model and policy objectives.
| Solution Category | Core Mechanism | Practical Implementation Example 1821 |
|---|---|---|
| Distribution Correction | Re-weights transition data during model training to prioritize states frequently visited by the policy or states with high rewards. | Adjusting the Negative Log-Likelihood minimization by applying Euclidean distance weights to state-action spaces (e.g., in CartPole). |
| Control-As-Inference | Mathematically unifies model learning and policy optimization under a single probabilistic inference objective. | Joint Model-Policy Optimization algorithms that bind transition accuracy directly to optimal trajectory generation. |
| Value-Equivalence | Abandons raw feature prediction; penalizes the model only if it incorrectly predicts the value of a state or the multi-step Bellman update. | MuZero and EfficientZero algorithms, which optimize implicit latent states strictly for reward, value, and policy prediction. |
| Differentiable Planning | Embeds the entire planning mechanism into a continuous differentiable computational graph. | Allowing reward maximization gradients to flow backward directly through the planner into the dynamics model's weights. |
Computational Cost and Inference-Time Trade-Offs
While MBRL is heralded for its sample efficiency, it is often heavily penalized in computational efficiency. Model-free algorithms like PPO or SAC do not expend resources training auxiliary environment simulators. If a domain possesses a hyper-fast, parallelized digital simulator (e.g., Isaac Gym for robotics or hardware-accelerated grid-worlds), executing 100 million model-free steps across an array of GPUs can take mere minutes or hours 3222. In such instances, deploying a model-based algorithm like DreamerV3 can result in a massive net loss in human wall-clock time.
Training a generative world model, encoding historical observations into latent states, decoding them, and generating millions of steps of internal imagination imposes an intense computational overhead. Implementing algorithms like DreamerV3 requires specialized multi-GPU clusters, and training times are frequently measured in days rather than hours; for instance, training a competent agent for complex 3D environments like Minecraft using Dreamer requires approximately 9 GPU-days 32. Furthermore, efforts to port DreamerV3's advanced stabilization tricks - such as symlog predictions and twohot encoding - directly to PPO have shown that these techniques do not universally improve model-free algorithms, often underperforming standard PPO implementations unless reward clipping is explicitly disabled 23.
Conversely, when real-world data collection is strictly constrained - such as a physical robot traversing a room where each interaction takes seconds or minutes of real physical time - the computational overhead of MBRL becomes trivial compared to the physical time saved 2. Additionally, recent frameworks like Parallelized Model-based Reinforcement Learning (PaMoRL) are attempting to mitigate these costs by introducing parallel world models and eligibility trace estimations, allowing model learning and policy learning to be parallelized over sequence lengths 24.
Integration of Generative Foundation Models
As the broader artificial intelligence landscape pivots toward massive, self-supervised foundation models, a significant paradigm shift is occurring in the conceptualization of world models. Rather than training a narrow, task-specific dynamics model from scratch within a closed RL loop, researchers are investigating the adaptation of pre-trained Large Language Models (LLMs), Vision-Language Models (VLMs), and Video Diffusion Models as generalized world simulators 362538.
Text-to-video diffusion models have demonstrated an emergent, statistical capacity to simulate intuitive physics, multi-object interactions, and spatial continuity 3625. These models act as passive observers of physical dynamics learned from petabytes of uncurated web video. To integrate them into an MBRL pipeline, they must be converted into action-conditioned simulators. Recent frameworks, such as Action-Conditioned Video Diffusion (AVID), attempt to bridge this gap 3839. Because state-of-the-art diffusion models are often closed-source or computationally prohibitive to fine-tune directly, AVID utilizes a black-box adaptation strategy. It trains an external adapter module on a small, domain-specific dataset of action-labeled videos. By applying learned masks to the intermediate representations of the frozen diffusion model, the system forces the generative output to branch conditionally based on a specified agent action, allowing it to function as a predictive world model for downstream policy optimization 3839. Similarly, the DINO-world architecture leverages a pre-trained image encoder (DINOv2) to train a future frame predictor entirely in latent space, which is subsequently fine-tuned on observation-action trajectories to support planning 40.
Despite the impressive visual fidelity of these foundational video generators, they currently fail to satisfy the rigorous physical constraints required for robust control 3641. Present architectures suffer from severe limitations. They frequently violate conservation of mass, object permanence, and causal logic over long horizons, manifesting in physical incoherence 3641. Furthermore, video models operating autoregressively suffer rapidly from compounding errors; small spatial inconsistencies in earlier frames cascade, causing the simulated world to disintegrate rapidly 2627. Crucially, current visual foundation models are fundamentally interpolators of statistical patterns rather than strict logical engines; they struggle to reliably simulate counterfactual reasoning in out-of-distribution states 2544. Bridging the gap between visually plausible generative video and mechanically rigorous simulation requires structural shifts toward persistent memory architectures and physically grounded latent disentanglement 412744.
Real-World Implementations in Robotics
The ultimate validation of sample-efficient MBRL is its deployment in embodied artificial intelligence and robotics. In recent years, the robotics sector has witnessed accelerating integration of RL pipelines into complex hardware, moving beyond basic locomotion into unstructured mobile manipulation and dynamic control 284629.
Leading institutes are aggressively pursuing RL to bridge the sim-to-real gap, a notoriously difficult challenge where policies trained in digital simulation fail in the physical world due to unmodeled friction, latency, and sensor noise. The Robotics & AI Institute (RAI), in collaboration with Boston Dynamics, established shared reinforcement learning training pipelines to generate highly dynamic, full-body contact strategies for humanoid robots like the electric Atlas 46. MBRL is particularly suited for this transition, as the learned dynamics model can rapidly adapt to compensate for the discrepancies between the rigid physics simulator and the chaotic reality of physical joints 46.
In aerial robotics, the Mobile Robotics Lab at ETH Zurich has demonstrated the capability of training quadrotor navigation policies directly from raw camera pixels using model-based techniques. By integrating latent imagination, these drones map vision directly to control commands, outperforming traditional model-free approaches in high-speed autonomous flight and obstacle avoidance scenarios without relying on explicit state estimation 3031. Across global institutions, including Tsinghua University and the Hong Kong University of Science and Technology (HKUST), parallel efforts are optimizing multi-agent cooperative exploration (MARL) and physical dexterity. Researchers are expanding classical single-agent algorithms, modifying Proximal Policy Optimization (PPO) into Multi-Agent PPO (MAPPO) to handle complex, non-zero-sum environments where agents must dynamically learn to cooperate and compete 323334.
By explicitly modeling the transition dynamics and reward structures of an environment, model-based reinforcement learning replaces costly real-world trial-and-error with internal, high-speed latent imagination. While the architecture remains constrained by compounding trajectory errors, objective mismatch, and heavy computational overhead, its unparalleled sample efficiency makes it a foundational technology for the future of physically embodied artificial intelligence.