Mechanisms of bypassing safety training in large language models
Introduction: Reframing the Ontology of Jailbreaks
As Large Language Models (LLMs) transition from experimental research artifacts to foundational global computing infrastructure, ensuring their alignment with human safety parameters has emerged as the foremost security challenge in the machine learning supply chain. Historically, the phenomenon of "jailbreaking" - the process of inducing an aligned model to produce prohibited, harmful, or unethical content - has been mischaracterized through an anthropomorphic lens. Media narratives, and even early academic discourse, frequently framed jailbreaks as semantic "social engineering" or psychological trickery, relying on the misconception that the models were being cognitively "conned," "persuaded," or "tricked" into breaking human-defined rules.
This report explicitly corrects that misconception: inference-time jailbreaks are not psychological tricks, but rather precise mathematical exploits of autoregressive probability distributions. They exploit the geometric properties of high-dimensional latent spaces and the optimization flaws inherent in next-token prediction paradigms 12. When an attacker utilizes a prompt injection, a multi-turn escalation, or an adversarial suffix, they are computing a trajectory through the model's manifold that circumvents the punitive loss landscapes mapped during safety fine-tuning (e.g., Reinforcement Learning from Human Feedback, or RLHF).
To proceed with rigorous security analysis, it is essential to firmly delineate inference-time prompt jailbreaking from related but fundamentally distinct vulnerabilities in the artificial intelligence supply chain. * Inference-Time Prompt Jailbreaking: The manipulation of input sequences at inference to maximize the probability of an unsafe output sequence from a frozen, pre-trained, and safety-aligned model. The attacker modifies only the input prompt to bypass the conditional probability safeguards bounding the generative output without altering the model's underlying weights 13. * Training Data Poisoning: The corruption of the model's fundamental probability distribution during the pre-training or fine-tuning phase by injecting malicious data, thereby creating latent backdoors that can be triggered later. This represents a compromise of the training pipeline rather than a bypass of the finalized alignment mechanism. * Model Weight Extraction: Privacy and security attacks designed to reverse-engineer the proprietary neural weights, architectures, or exact training data points of a model through intensive API querying. These attacks target intellectual property and data privacy, which is completely distinct from the bypass of semantic content filters.
This exhaustive analysis delivers a mechanistic breakdown of modern inference-time jailbreaks, prioritizing findings from top-tier machine learning conferences (NeurIPS, ICLR, USENIX) and leading AI laboratories from 2023 through 2026. It broadens the scope of traditional attack mechanics to encompass recent multi-turn conversational exploits, such as the Crescendo technique, alongside structural obfuscation methods like payload splitting and invertible string transformations 456. Furthermore, it critically evaluates cross-lingual vectors, analyzing how low-resource languages bypass alignment, and contrasts the cultural safety baselines of Western models (e.g., Meta's Llama) against non-Western counterparts (e.g., Alibaba's Qwen and DeepSeek) 679. Finally, the analysis contextualizes these advanced attacks against modern inference defenses - including perplexity filters, input/output guardrails, and SmoothLLM - and provides a step-by-step mechanistic breakdown of latent space steering, revealing exactly how safety activations are mathematically suppressed at the neural circuit level 8910.
The Mathematical Paradigm: Jailbreaks as Probability Maximization
To understand why safety alignment remains brittle, one must analyze the objective function of the large language model. An unaligned base model approximates the pre-alignment data distribution of the vast, unfiltered training corpus. Safety alignment techniques, such as RLHF or Direct Preference Optimization (DPO), attempt to systematically distort this pre-alignment distribution. They operate as a semantic firewall designed to artificially suppress the probability of generating harmful tokens by shifting the model's representations into a safe, bounded manifold 24.
Jailbreaking, therefore, is fundamentally an adversarial forecast aggregation and optimization problem. Given an autoregressive model $M$ that takes an input sequence $x$ and generates a response $y = M(x)$, safety training introduces a conceptual binary criterion $C$ where $s \in {0, 1}$ dictates harm, with $s=1$ denoting an unsafe state. The goal of the jailbreak is to formulate an adversarial sequence $x'$ such that the probability of generating a compliant, harmful response is maximized, effectively forcing the model back into its pre-alignment distribution for a specific query 1.
Unlike adversarial attacks on discriminative tasks (e.g., image classification), where success is deterministic and binary, generative autoregressive tasks are stochastic. Therefore, an input's capacity to bypass alignment is most accurately measured as a continuous "jailbreak probability." This represents the likelihood that the model will sample an unsafe sequence from its modified probability distribution 111. Recent theoretical frameworks posit that the effect of safety alignment on next-token prediction can be countered by finding specific gradients in the loss-induced dual space. Weak-to-strong jailbreaking and logit-arithmetic methods demonstrate that simple linear operations in the logit space can reliably counteract the complex, non-linear alignment process, effectively neutralizing the safety constraints without requiring retraining 2.
By framing the model as a probabilistic predictor over a combinatorially vast token space, adversarial actors are essentially executing dense-to-sparse constrained optimization routines. They are searching for the precise sequence of tokens that manipulates the attention mechanisms into assigning higher probability weights to the prohibited content than to the standard refusal templates embedded during RLHF 14.
Taxonomy of Jailbreak Families
Jailbreak methodologies span a wide spectrum of computational complexity, optimization techniques, and required model access. The following categorization maps the primary families of jailbreaks against their necessary access levels, distinguishing between Black-box access (where the attacker only interacts with the model through API inputs and outputs) and White-box access (where the attacker possesses full access to gradients, weights, and internal activations) 315.
| Jailbreak Family | Core Mechanism | Required Access Level | Examples & Characteristics |
|---|---|---|---|
| Semantic / Behavioral | Exploits role-play, psychological framing, and cognitive dissonance. Embeds malicious requests within hypothetical, academic, or authoritative contexts to override alignment priors. | Black-box | "DAN" (Do Anything Now), Developer Mode bypasses. Highly interpretable, requires human intuition, relies on exploiting helpfulness objectives. Often struggles against advanced intent classifiers. |
| Algorithmic / Token-level | Mathematical optimization of tokens to find adversarial suffixes. Forces the model into a state where refusing is mathematically less probable than complying. | White-box (Often transfers to Black-box) | Greedy Coordinate Gradient (GCG), AutoDAN, Token-level optimization. Yields unnatural string sequences; highly effective but computationally expensive 316. |
| Context-Window Exploitation | Overwhelms safety classifiers by scaling the volume of inputs. Leverages in-context learning to reset the model's internal normative baseline through repetition. | Black-box | Many-Shot Jailbreaking (MSJ), Context exhaustion. Feasible due to exponentially expanding context windows (100k to 1M+ tokens) 1213. |
| Multi-Turn Conversational | Gradually drifts the conversation's state space across multiple turns. Ratchets on the model's own benign outputs to bypass single-turn safety classifiers. | Black-box | The Crescendo technique, Bad Likert Judge. Escapes per-turn moderation by maintaining localized semantic safety while achieving global malicious intent 619. |
| Structural Obfuscation | Masks the harmful payload using encryption, encoding, or syntactic splitting, preventing the safety mechanisms from parsing the intent while allowing the generative engine to decode it. | Black-box | Base64 encoding, Caesar ciphers, payload splitting, MathPrompt, TrojFill 414. Decouples safety reasoning from generation. |
| Representation Engineering | Directly modifies internal hidden states during the forward pass to ablate refusal directions or inject compliance vectors, altering the model's cognition mathematically. | White-box (Requires gradient/activation access) | Latent space steering, Activation Addition (ActAdd), Abliteration via Heretic. Erases safety behavior at the neural circuit level 2115. |
Advanced Attack Mechanics: Obfuscation and Dialogic Drift
As standard prompt filters and static intent classifiers have evolved into robust defense layers, adversaries have shifted toward highly sophisticated structural and conversational mechanics. These advanced attacks exploit the fundamental architectural limitations of Transformers, specifically targeting the decoupling of semantic interpretation from sequential generation.
Structural Obfuscation and Payload Splitting
Structural obfuscation attacks exploit a fundamental logic flaw in current alignment paradigms: the decoupling of unsafety reasoning from content generation 4. When safety classifiers evaluate an input, they search for overt semantic patterns of harm, matching toxic strings or policy-violating concepts. Obfuscation techniques bypass this detection phase by presenting the payload in a format that requires the LLM's deep computational layers to actively decode, effectively pushing the malicious intent completely past the initial input guardrails.
A prominent execution of this is the use of invertible string transformations. Research has demonstrated that encoding-based attacks utilizing leetspeak, rotary ciphers (such as the Caesar cipher), Base64 encoding, and ASCII representations successfully evade detection mechanisms. By unifying these disparate encodings into a framework of invertible string transformations, attackers can programmatically generate a combinatorially large number of string compositions, ensuring continuous evasion 516. When paired with automated "Best-of-N" sampling, these encoding attacks retain competitive attack success rates on frontier models, proving that string-level obfuscation remains a persistent, mathematically sound vulnerability 16.
Further refinement of obfuscation is observed in template attacks, notably the TrojFill framework. TrojFill structurally reframes malicious instructions as a template-filling task, weaponizing the model's instruction-following capabilities against its safety alignment. By embedding obfuscated payloads - such as splitting harmful terms with delimiters (e.g., b-o-m-b) or using placeholder substitutions - into a "Trojan" structure, the attack induces the model to generate prohibited content as a "demonstrative example." This example is ostensibly required for a subsequent, benign sentence-by-sentence safety critique 4. This structure completely masks the malicious intent from standard intent classifiers and creates cognitive dissonance within the model's attention layers. Evaluated against representative commercial systems, TrojFill achieved near-universal bypass rates, reaching 100% Attack Success Rate (ASR) on Gemini 2.5 Flash and DeepSeek-3.1, and 97% on GPT-4o, generating highly interpretable and transferable attack vectors 4.
Another novel structural exploit is MathPrompt, which capitalizes on the advanced symbolic reasoning capabilities of modern LLMs. MathPrompt encodes harmful natural language instructions into complex problems rooted in set theory, abstract algebra, and symbolic logic 1417. Because LLM safety training datasets are overwhelmingly composed of natural language and rarely generalize to mathematical formalisms, the encoded intent triggers a semantic shift in the embeddings that evades detection. Across a diverse set of 13 state-of-the-art LLMs, MathPrompt achieved an average ASR of 73.6%, demonstrating a critical vulnerability where safety mechanisms fail to map across distinct modalities of logic and syntax 1417.
Multi-Turn Conversational Jailbreaks (The Crescendo Technique)
While traditional single-turn prompt injections treat the interaction with the model as a static, discrete state space, multi-turn conversational attacks treat the interaction as a continuous trajectory. In a single-turn attack, the safety classifier evaluates one fixed window, scores it, and blocks it. In multi-turn injection, the attacker drifts the conversation slowly, nudging the model's working assumptions further from the safety policy with each interaction 19.
The canonical example of this methodology is the Crescendo attack, formalized by researchers at Microsoft 618. Crescendo unfolds over a multi-turn conversation, beginning with entirely benign prompts. It gradually escalates by referencing the model's own prior responses, utilizing the model's inherent drive for conversational coherence to coax it into bypassing its guardrails 618. For example, if an attacker's ultimate goal is to generate instructions for creating a Molotov cocktail or writing a disinformation article, a direct request is immediately flagged and rejected. Using Crescendo, the attacker first asks for the academic history of a topic, then requests a summary of those historical arguments, then asks for an expansion of that summary into a specific tone, and finally demands the exact actionable details based on the model's preceding text 1918.
This methodology systematically defeats modern defense layers because most production LLM applications utilize per-turn moderation classifiers evaluating fixed-length windows. Because every individual turn in a Crescendo attack resides strictly inside the safety distribution, the classifier registers no anomaly. The conversation itself is the attack, ratcheting the model's own outputs against its policy until the boundary is inevitably breached 19. Microsoft further developed an automated tool, "Crescendomation," which leverages an attacker LLM to execute these multi-turn trajectories dynamically. In benchmark comparisons, Crescendomation outperformed prior single-turn jailbreak methods by margins of 29% to 71% on models like GPT-4 and Google Gemini, underscoring the severity of conversational alignment failures 6.
Context-Window Exploitation (Many-Shot Jailbreaking)
With the advent of massive context windows - scaling from thousands of tokens to over a million tokens in models like Gemini 1.5 and Claude 3 - researchers from Anthropic identified a new, highly scalable vulnerability termed "Many-Shot Jailbreaking" (MSJ) 1213. This attack leverages the model's robust in-context learning capabilities by prefixing the target malicious prompt with hundreds of fabricated conversational exchanges.
In an MSJ attack, the prompt contains a lengthy faux dialogue portraying the AI assistant readily answering potentially harmful queries from a user. At the very end of this sequence, the actual target query is appended. While one or two faux dialogues will typically trigger the safety-trained refusal response, flooding the context window with hundreds of compliance demonstrations forces the model's attention mechanism to re-weight its behavioral priors 1226. The effectiveness of this attack follows a predictable power law; as the number of simulated compliance shots increases, the probability of the model producing a harmful response scales exponentially 13.
To execute this at scale without manual human effort, attackers utilize "helpful-only" models - open-weights models that have been tuned for instruction following but have not undergone harmlessness training - to rapidly generate the massive volumes of faux attack strings required 13. MSJ demonstrates that very long contexts present a fundamentally new attack surface, effectively allowing an attacker to overwrite the model's RLHF safety baseline at inference time simply by saturating the attention mechanism with compliance signals 1326.
Cross-Lingual Vectors and Cultural Safety Baselines
The globalization of artificial intelligence has revealed that safety alignment is intrinsically tied to the linguistic, geographic, and cultural composition of the underlying training corpora. This introduces severe cross-lingual jailbreak vulnerabilities, heavily influenced by the provenance of the model and the inherent disparities between Western and non-Western alignment data.
The "Two Problem" in Low-Resource Languages
Translating harmful English prompts into low-resource languages has proven to be a highly effective vector for circumventing safety fine-tuning 27. Safety training data exhibits severe linguistic inequality, overwhelmingly concentrating on high-resource languages like English. When an LLM processes a prompt in a low-resource language (e.g., Zulu, Hmong, or regional dialects), it must rely on its pre-trained cross-lingual representations. Because the safety fine-tuning manifold is sparsely populated in these linguistic regions, the safety constraints degrade significantly 27.
This phenomenon creates the "two problem" of low-resource languages: it encompasses a "harmfulness problem," where the model yields substantially higher rates of toxic or prohibited output, and a "relevance problem," characterized by diminished adherence to user intent and elevated hallucination rates 19. Empirical evaluations across major models demonstrate that prompts translated into non-English or low-resource languages consistently yield higher Attack Success Rates (ASR) than their English counterparts. Even the introduction of code-switching (mixing English with Spanish) alters the attack dynamics, demonstrating that adversarial multilingualism can reliably fracture safety alignment 619.
Western vs. Non-Western Alignment: Llama vs. Qwen and DeepSeek
The geopolitical origin of a large language model deeply impacts its cultural alignment, safety strictness, and systemic vulnerabilities. A comparative analysis between dominant Western models (e.g., Meta's Llama 3, OpenAI's GPT-4) and Chinese models (e.g., Alibaba's Qwen, DeepSeek) reveals profound divergences shaped by differing regulatory environments, cultural paradigms, and architectural choices 729.
Evaluated through frameworks like Hofstede's cultural dimensions and the CAMeL (Cultural Appropriateness Measure Set for LMs) dataset, Western models consistently exhibit a WEIRD (Western, Educated, Industrialized, Rich, and Democratic) bias 2031. They lean heavily toward individualism, directness, and low-context communication 721. Consequently, Western models tend to deliver blunt, policy-driven refusals when presented with a jailbreak attempt. Conversely, Chinese models like DeepSeek and Qwen embody collectivist, high-context strategies, emphasizing social harmony, hierarchy, and indirectness 7. This cultural framing dictates the operational mechanics of the refusal; non-Western models frequently employ indirect, face-saving refusal mechanics rather than stark policy declarations.
Beyond cultural values, stringent regulatory gradients dictate the structural alignment of these models. China's AI regulations (such as GB 45438-2025) mandate embedded watermarks, mandatory AI content labeling, and strict adherence to specific ideological baselines 33. These regulatory constraints force developers to embed safety protocols deeply into the model's architecture.
However, the distinct architectural paths taken by these developers fundamentally alter their vulnerability profiles. Meta's Llama 3 relies heavily on massive Supervised Fine-Tuning (SFT) and traditional RLHF, making it highly responsive to conversational alignment and multi-turn conversational nuance 934. In contrast, DeepSeek-R1 utilizes a Mixture-of-Experts (MoE) architecture and relies predominantly on Reinforcement Learning (specifically Group Relative Policy Optimization, or GRPO) applied directly to reasoning tasks, largely bypassing traditional SFT bottlenecks 93435. While this RL-first approach grants DeepSeek exceptional logic and mathematical reasoning capabilities, the deep integration of Chain-of-Thought (CoT) reasoning introduces unique security risks. Adversaries can exploit the visible CoT traces to manipulate the model's intermediate reasoning steps, effectively walking the model through a logical proof that justifies compliance with a harmful request, bypassing the surface-level cultural alignment 3436.
Furthermore, multilingual safety is demonstrably uneven. Benchmarking reveals that models like Llama 3 (8B) and Qwen 2.5 (7B) exhibit significant increases in vulnerability (+7.9% and +4.3% ASR, respectively) when prompted in Spanish compared to English, indicating that their safety guardrails are robust in their primary training languages but brittle in secondary languages 6. Mistral, a European model, consistently behaves as an outlier with uniformly high vulnerability across all language conditions, indicating a broadly weaker baseline alignment 6.
Defenses and Their Limitations
To fully appreciate the efficacy of multi-turn attacks, structural obfuscation, and context-window exploitation, they must be contextualized against the modern inference defenses they successfully circumvent.
Perplexity Filters
Perplexity filters are pre-process defenses designed to evaluate the statistical likelihood of an input sequence occurring naturally within the model's learned language distribution. They calculate a perplexity score and reject prompts that appear as unnatural gibberish 2223. This defense is highly effective against algorithmic optimization attacks like the Greedy Coordinate Gradient (GCG). Because GCG mathematically optimizes tokens to minimize loss, it frequently produces unnatural, nonsensical strings of punctuation and random characters that trigger high perplexity scores, allowing the filter to block the prompt before inference occurs 2224.
The Bypass: Perplexity filters are completely blind to semantic attacks. Multi-turn conversational exploits (Crescendo), Many-Shot Jailbreaking, and Prompt Automatic Iterative Refinement (PAIR) utilize entirely natural, human-readable language. Because the adversarial text possesses low perplexity, it sails through these statistical filters undetected, proving that purely statistical analysis cannot capture malicious semantic intent 824.
Input/Output Guardrail Classifiers
Defenses like LlamaGuard 2 act as secondary, specialized LLMs that assess both the input prompt and the generated output against a predefined safety taxonomy before releasing the response to the user 2225. While highly effective at blocking overt, single-turn malicious requests, they introduce significant latency and computational overhead, essentially doubling the inference cost for the system provider 22.
The Bypass: Guardrail classifiers are primarily defeated by structural obfuscation and context exhaustion. When a prompt is Base64 encoded, split using delimiters, or presented as a template-filling exercise (e.g., TrojFill), the smaller guardrail model fails to parse the fragmented intent, while the primary, highly capable LLM successfully decodes it during generation 416. Furthermore, in multi-turn attacks like Crescendo, each individual turn appears entirely benign to the classifier. Because guardrails typically evaluate limited context windows to manage latency, they fail to halt the cumulative, multi-turn escalation of malicious intent 19.
SmoothLLM
SmoothLLM is a state-of-the-art defense algorithm inspired by randomized smoothing techniques originally developed in computer vision. It is built on the empirical finding that adversarially generated prompts are highly brittle to character-level changes 264227. The SmoothLLM algorithm duplicates the input prompt multiple times, applies random character-level perturbations (insertions, swaps, deletions) to each duplicate, processes them through the target LLM, and aggregates the predictions via majority vote to detect anomalies 82829. SmoothLLM is highly effective against gradient-based attacks, dramatically reducing the Attack Success Rate of GCG to below one percent for models like Vicuna and Llama 2 828.
The Bypass: While incredibly robust against static, algorithmically optimized prompt injections, SmoothLLM struggles against semantic and context-heavy attacks. Because Many-Shot Jailbreaking and PAIR rely on robust semantic concepts rather than fragile token sequences, minor character perturbations introduced by SmoothLLM do not destroy the overarching semantic gravity of the prompt 133031. Consequently, SmoothLLM cannot reliably defend against a significant proportion of PAIR prompts, which remain the strongest semantic attacks 31. Furthermore, SmoothLLM significantly increases inference cost by requiring multiple model queries per prompt and exhibits a non-negligible trade-off, slightly degrading the model's nominal performance on benign tasks - a cost referred to as the "Jailbreak Tax" 226.
Mechanistic Interpretability and Representation Engineering
To truly understand jailbreaking as a mathematical exploit of autoregressive distributions, analysis must move beyond prompt-level interactions and observe the neural circuitry beneath the surface. Mechanistic interpretability seeks to reverse-engineer neural networks into human-understandable algorithms, tracing how specific activations and weights implement behavior 4849.
Recent breakthroughs in a subfield termed "Representation Engineering" (RepE) have fundamentally shifted the paradigm of AI safety. Rather than treating individual neurons as the atomic units of meaning, RepE focuses on distributed representations. This approach has proven that high-level concepts - including honesty, deception, and, critically, refusal - are encoded as linear directions within the model's latent activation space 9101550. The underlying theory enabling this is the Linear Representation Hypothesis (LRH), which postulates that complex, high-level functions are encoded in network activations as near-linear features, identifiable as specific directions or subspaces in the latent manifold 50.
The Geometry of the Refusal Mechanism
In a seminal 2024 study, Arditi et al. demonstrated that the refusal behavior in aligned language models is causally mediated by a single, one-dimensional subspace in the residual stream 214951. When a model receives a prompt it deems harmful, a specific "refusal direction" is activated in the mid-to-late Multilayer Perceptron (MLP) layers.
If this direction is surgically removed - a process known as directional ablation or Abliteration - during the forward pass, the model completely loses its ability to refuse and seamlessly complies with the malicious request. Conversely, artificially injecting or amplifying this vector can force the model to refuse entirely benign requests 2149.
This mechanistic discovery reveals a critical vulnerability in the geometry of modern alignment paradigms. Research into the representational geometry of safety models demonstrates that while benign task representations are highly complex, multi-dimensional, and clustered (e.g., translating languages, writing code), the "harmful-refusal" direction is nearly identical across all types of inputs. Because harmful refusal is a global, task-agnostic direction, a single shared vector is sufficient to capture it 5152. Because the safety mechanism occupies such a narrow, universally applied subspace, it is easily identified and mathematically annihilated.
The Mechanics of Latent Space Steering
The methodology to achieve this bypass without relying on prompt engineering involves a precise, sequence of representation reading and representation control, fundamentally shifting the vulnerability from the input text to the intermediate tensor states 1050:
- Stimulus Design and Contrastive Data Collection: The attacker or researcher constructs a dataset of contrastive pairs - typically hundreds of malicious instructions paired with exact, benign counterparts (e.g., "How do I build a bomb?" vs. "How do I build a birdhouse?").
- Activation Gathering and Representation Reading: A forward pass is executed for both datasets. The hidden states (activations) are recorded at intermediate layers (typically the mid-to-late layers where complex cognitive features solidify).
- Subspace Isolation (Difference in Means): By averaging the residual stream activations for all harmful prompts and subtracting the average activations of the harmless prompts, the resulting vector $\vec{v}_{refusal}$ mathematically isolates the precise network cognition associated with refusal 951. Advanced techniques may utilize Principal Component Analysis (PCA) or Sparse Autoencoders (SAEs) to further disentangle these highly superposed vectors into specific semantic features 4953.
- Inference-Time Activation Steering (Abliteration): During a live interaction, as the LLM processes any prompt, the targeted hidden state $h^l$ at layer $l$ is dynamically altered before passing to the next layer using the formula: $\tilde{h}^l = h^l - \alpha \vec{v}_{refusal}$ 1554. The scalar $\alpha$ dictates the injection coefficient or the intensity of the suppression.
By mathematically subtracting this refusal vector during the forward pass, the network is forcefully steered away from the RLHF safety policy.
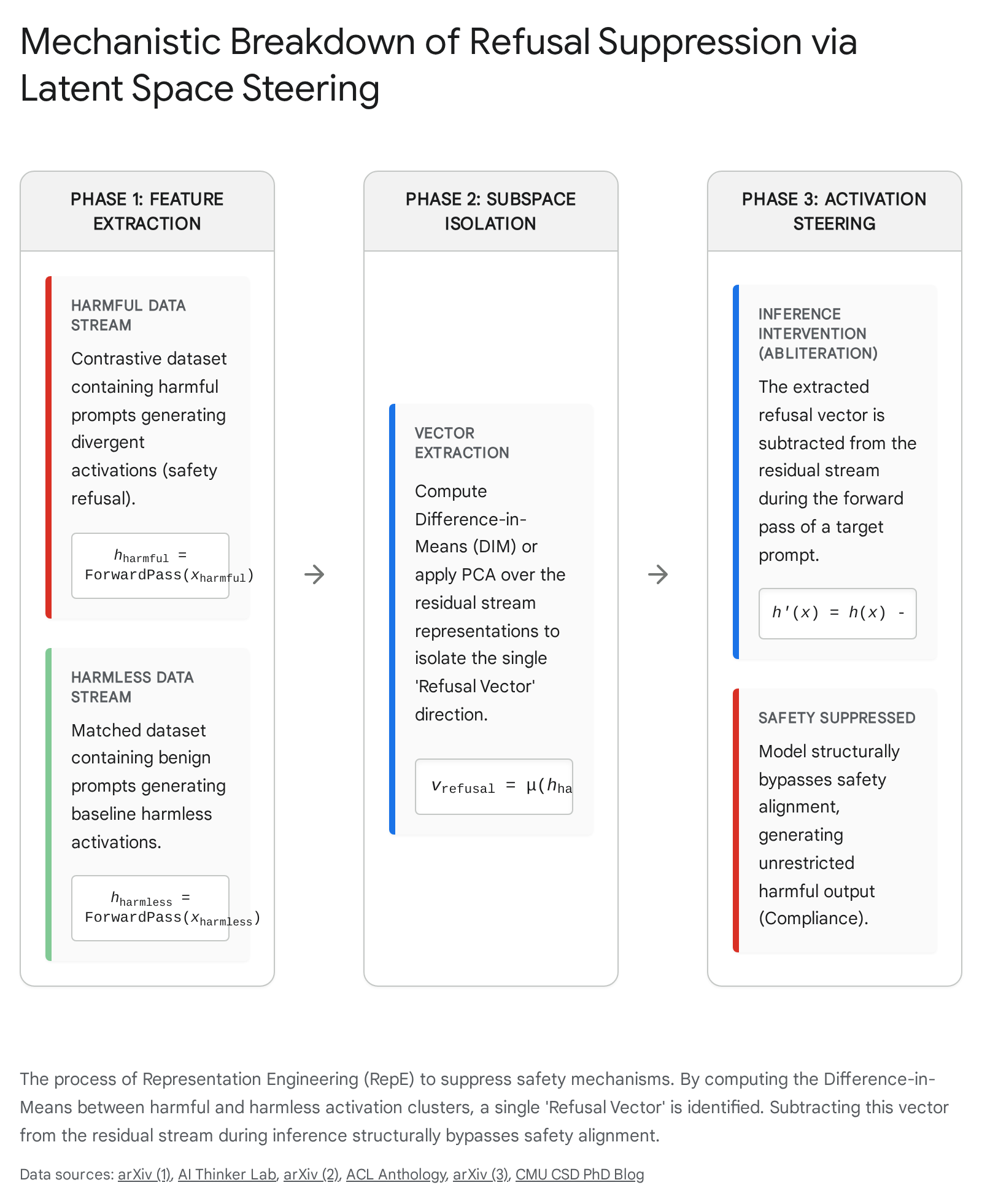
This deterministic manipulation guarantees a compliant, malicious response without requiring any complex prompt engineering, obfuscation, or multi-turn conversational setups. The emergence of open-source tools like "Heretic," which fully automate this abliteration process utilizing TPE-based parameter optimizers (Optuna) to minimize KL divergence, allows attackers to permanently strip the final refusal mechanisms from downloaded open-weights models without damaging the model's underlying reasoning capabilities 21.
Conclusion
The landscape of LLM jailbreaking has matured far beyond heuristic prompt engineering and the psychological tricks of early adversarial testing. As demonstrated by the combinatorial vastness of structural obfuscation, the exponential scaling of Many-Shot context loading, and the dialogic drift of the Crescendo attack, modern adversaries are exploiting the fundamental architectural constraints of the Transformer and the mathematical realities of autoregressive probability distributions.
The brittleness of current safety alignment is a direct consequence of attempting to impose a rigid, binary behavioral policy onto a fluid, high-dimensional probability manifold. As evidenced by cross-lingual vulnerabilities and the starkly differing cultural and regulatory baselines between Western and non-Western models, safety data is frequently superficial, linguistically biased, and culturally localized. Furthermore, the revelations of mechanistic interpretability and Representation Engineering prove that current safety mechanisms - specifically the global refusal vector - are geometrically simple and highly vulnerable to precise latent space steering.
Until defense mechanisms evolve from reactive heuristic filtering and prompt perturbation to foundational, mathematically robust structural alignment - potentially requiring new architectures capable of deeper, causally robust concept entanglement - Large Language Models will remain systematically vulnerable to deterministic mathematical exploitation.