Limitations and Practical Applications of NISQ Quantum Computers
The field of quantum computing has definitively entered a highly pragmatic phase of maturation, moving beyond the initial exuberance that characterized the early Noisy Intermediate-Scale Quantum (NISQ) era. The term NISQ, formally introduced into the scientific lexicon by theoretical physicist John Preskill in a seminal 2018 paper, originally served to frame a distinct technological epoch, tempering the pursuit of perfect fault tolerance with a focus on near-term hardware comprising 50 to 100 noisy qubits 12. However, as the field has advanced through the mid-2020s, the potential of the NISQ era has been held in check by formidable physical and mathematical constraints 1. Extensive theoretical research has proven significant limitations on NISQ-friendly methods, leading to an increasingly sober perspective on what can genuinely be achieved without robust error correction 2.
The prevailing narrative within both academia and industry is no longer centered on raw physical qubit counts - a metric recognized as fundamentally misleading when divorced from error rates - but rather on operational fidelity, algorithmic qubits, hardware-efficient error correction paradigms, and the precise conditions under which quantum hardware can outpace classical supercomputers 23. This exhaustive research report systematically investigates the physical limitations of contemporary quantum architectures, evaluates the practical utility of imperfect hardware, and contrasts the divergent trajectories of post-2023 corporate roadmaps against deeply rooted academic skepticism. By examining hardware advancements across the United States, China, Europe, and Japan, alongside breakthroughs in quantum low-density parity-check (qLDPC) codes and quantum machine learning (QML) bottlenecks, this analysis maps the current frontier of quantum computational utility.
1. Re-evaluating the NISQ Era: The Physics of Imperfection
The designation of the NISQ era successfully steered global research efforts toward the tangible reality of near-term hardware, acknowledging that devices had evolved beyond "toy" few-qubit systems while still falling short of the large-scale, fault-tolerant machines required for cryptographic algorithms like Shor's prime factorization 1. However, the fundamental limitations of this era are strictly bound by the physics of quantum decoherence. In the absence of continuous, robust Quantum Error Correction (QEC), quantum states remain exquisitely fragile, decaying rapidly through energy loss ($T_1$ relaxation) and phase loss ($T_2$ dephasing) due to uncontrolled environmental interactions 14.
1.1 The Accumulation of Uncorrected Errors and the Computational Sweet Spot
The primary bottleneck of NISQ computing is the relentless accumulation of uncorrected errors over the depth of a quantum circuit. Every operational step - whether state preparation, single-qubit rotations, two-qubit entangling gates, or final measurement - introduces a non-zero probability of error 1. In classical computing, errors are managed via massive redundancy, such as storing a bit three times and using majority voting to correct anomalous flips. In quantum computing, the no-cloning theorem prohibits direct state replication, necessitating complex, highly non-local syndrome extraction protocols that NISQ devices inherently lack the resources to support at scale 1.
Because of this pervasive noise, there exists a strict computational "sweet spot" for any given problem executed on a NISQ device 1. If a problem requires a circuit depth that exceeds the hardware's operational fidelity threshold, the noise entirely overwhelms the quantum signal, rendering the output statistically indistinguishable from random sampling 15. Recent benchmarking protocols, such as the Linear Ramp Quantum Approximate Optimization Algorithm (LR-QAOA), have explicitly quantified this limitation across hardware platforms. By testing circuits up to 10,000 layers deep, researchers have demonstrated exactly how a Quantum Processing Unit's (QPU) ability to preserve a coherent signal degrades sharply, strictly bounding the complexity of algorithms that can be executed prior to thermal noise and crosstalk irrecoverably destroying the state 56.
1.2 The Misconception of Physical Qubit Counts
For years, the most public metric for quantum progress was the raw number of physical qubits packaged onto a single chip. However, within the rigorous physics community, this metric is acknowledged as fundamentally misleading. Merely adding more highly noisy qubits to a processor does not linearly - or even logarithmically - increase its computational utility. In fact, due to the increased probability of crosstalk, spurious environmental coupling, and the immense engineering constraints of cryogenic wiring density, scaling physical qubits often degrades system-wide performance if component fidelities are not concurrently improved 167.
Below a two-qubit gate fidelity of 99.9% (the critical "three nines" threshold), quantum circuits remain far too noisy to support practical, deep applications, regardless of whether the processor contains 50, 100, or 1,000 physical qubits 8. The effort required to manage this noise dramatically curtails productivity and algorithmic complexity, ultimately preventing any significant quantum advantage from arising purely from physical scaling in the uncorrected NISQ regime 8.
2. Shifting the Evaluation Paradigm: Metrics of Holistic Utility
Recognizing the stark inadequacy of isolated physical qubit counts, the industry has pivoted toward holistic, application-centric benchmarking frameworks that measure the synergistic, system-wide performance of qubits, gate fidelities, connectivity, and coherence 34. This shift allows for the evaluation of a complete system rather than its individual, disjointed components.
2.1 Quantum Volume (QV)
Pioneered by IBM, Quantum Volume (QV) explicitly characterizes a hardware's capability to successfully execute random, square quantum circuits (where the circuit width is equal to its depth) 4. QV incorporates a multitude of variables - including qubit count, coherence times, gate errors, and hardware crosstalk - into a single, un-gameable metric. A system passes the QV test if it produces a heavy output probability (HOP) greater than 2/3 with two-sigma statistical confidence across extensive classical processing verification 56.
The industry benchmark for this metric was shattered in May 2025, when Quantinuum announced that its trapped-ion System Model H2-1 had achieved a Quantum Volume of $2^{23}$ ($8,388,608$), demonstrating an exponential advancement in holistic system performance and proving that maintaining ultra-high fidelities across a fully connected architecture yields far more computational power than simply scaling noisy superconducting loops 5.
2.2 Algorithmic Qubits (AQ)
Developed by IonQ, the Algorithmic Qubits (AQ) metric captures a system's ability to execute standard algorithmic workloads rather than random circuits. AQ measures the largest number of effectively perfect qubits that can be deployed for a typical, application-relevant quantum program 412. For example, a system with an AQ of 36 - such as the IonQ Forte - implies it can successfully execute quantum circuits up to 36 qubits wide and $36^2$ (1,296) entangling gates deep 1213.
By focusing on algorithmic utility across specific domains such as optimization (e.g., MaxCut), quantum chemistry (e.g., VQE), and machine learning circuits, metrics like AQ and QV force hardware providers to prioritize systemic fidelity over raw scaling. Comparative analyses utilizing these frameworks reveal that high-fidelity trapped-ion systems can sample optimal solutions in seconds, whereas leading superconducting systems of the same era fail to produce qualifying samples before hitting the noise floor, rendering their effective Time-to-Solution (TTS) infinite 3. Furthermore, other performance metrics, such as IBM's Circuit Layer Operations Per Second (CLOPS), evaluate execution speed, highlighting that true utility is a vector of fidelity, scale, and operational velocity 14. Data indicates a notable shift away from isolated qubit counts toward these holistic frameworks to ensure transparent hardware evaluation.
3. The Classical Pushback: Tensor Networks and the Moving Target of Advantage
The quest for quantum advantage is not a static race; rather, it is a dynamic, escalating competition against classical algorithms running on the world's most powerful exascale supercomputers. As experimental physicists push the boundaries of quantum hardware, classical computer scientists push back, continually optimizing the tensor network algorithms used to simulate quantum circuits 7.
3.1 Tensor Network Algorithms: The Classical Challenger
The current cutting-edge classical method for simulating random quantum circuits relies heavily on tensor network algorithms 8. These advanced mathematical structures break down the exponentially large Hilbert space of a many-body quantum system into a network of interconnected, lower-dimensional tensors. This effectively compresses the quantum state representation by exploiting localized entanglement. When Google originally claimed quantum supremacy in 2019 with its 53-qubit Sycamore processor, they estimated classical simulation would require 10,000 years. However, subsequent improvements in classical tensor network algorithms rapidly reduced that theoretical simulation time to mere seconds 7. This dynamic established a persistent pattern: quantum hardware leaps forward, followed shortly by classical algorithmic innovations that close the computational gap.
3.2 The Zuchongzhi 3.0 and Sycamore Milestones
In late 2024 and early 2025, this paradigm was tested again at unprecedented, record-breaking scales. Google announced that its 67-qubit Sycamore processor had solved a Random Circuit Sampling (RCS) problem that would theoretically take the Frontier supercomputer an estimated 3,600 years to simulate 7.
Concurrently, researchers at the University of Science and Technology of China (USTC) unveiled Zuchongzhi 3.0, a highly advanced superconducting quantum computer prototype equipped with 105 transmon qubits arranged in a two-dimensional rectangular lattice 817. To definitively establish a new benchmark and actively thwart classical tensor network simulations, the USTC team conducted an 83-qubit, 32-cycle random circuit sampling experiment 8. Crucially, they designed the circuit such that the two-qubit iSWAP-like gates were applied in a highly specific, hard-to-simulate pattern (an ABCD-CDAB sequence) in each cycle. This sequence maximizes the entanglement generation rate, directly breaking the low-entanglement assumption that classical tensor networks rely upon for efficient compression 8.
Zuchongzhi 3.0 generated one million samples in just a few hundred seconds. Because of the sophisticated gate sequencing, the classical simulation cost of this specific 83-qubit, 32-cycle experiment was estimated to be $6.4 \times 10^9$ years on the Frontier supercomputer 817. This achievement represents a classical simulation cost six orders of magnitude beyond Google's SYC-67 and SYC-70 experiments, firmly establishing a new frontier in quantum computational advantage 89. Yet, while this leap demonstrates that quantum hardware can decisively outpace classical simulation capabilities in highly specific, mathematically contrived sampling tasks, translating this theoretical "supremacy" into practical, economic utility remains the core challenge of the decade.
4. The Practical Utility Search: QML and the Data-Loading Bottleneck
Quantum Machine Learning (QML) has been widely touted as a primary beneficiary of NISQ-era computing. Theoretically, QML algorithms can process high-dimensional feature spaces exponentially faster than classical neural networks, promising breakthroughs in pattern recognition, anomaly detection, and optimization 1020. However, a rigorous academic analysis of data complexity reveals a profound and often overlooked limitation: the classical-to-quantum data-loading bottleneck 1021.
4.1 The Complexity of State Preparation
Before a quantum processor can execute a machine learning algorithm, classical data must be encoded into a quantum state. While quantum hardware holds the promise of rapid processing, the actual input/output mechanisms are severely restricted. Simple methods, such as basis encoding (assigning binary data to individual qubits) or angle encoding (rotating a qubit proportionally to a classical feature value), are relatively straightforward but highly space-inefficient, requiring one physical qubit per classical data feature 2011.
Amplitude encoding offers a far more intuitive advantage by encoding an entire input vector $v_i$ into the quantum state amplitudes as $\sum_i v_i \ket{i}$. This methodology requires exponentially fewer qubits (specifically, $\log_2 N$ qubits to encode $N$ features) 11. However, this theoretical space efficiency belies a massive temporal cost. The quantum circuit required to prepare such an arbitrary state generically scales with a staggering depth of $\mathcal{O}(4^n)$, where $n$ is the number of qubits 11. Consequently, for dense classical datasets, the process of encoding information into quantum states imposes a time complexity that entirely negates the theoretical speedups promised by the subsequent quantum algorithm 21. The encoding step alone often scales at $\mathcal{O}(N^2)$ or worse, creating a fatal bottleneck for real-time inference or training 21.
4.2 Data Complexity and Quantum Kolmogorov Entropy
Recent literature emphasizes that hardware scale and qubit counts alone do not dictate quantum advantage in QML; rather, the intrinsic structure of the data itself is the defining constraint 10. Metrics of data complexity, such as persistent homology and topological entanglement entropy, suggest that highly homogeneous classical data reduces the need for quantum resources, making classical simulation overwhelmingly superior 10.
Furthermore, according to theoretical bounds regarding quantum Kolmogorov complexity, most arbitrary quantum states are incompressible. Therefore, attempting to load random or densely packed classical data structures requires exhaustive algorithmic specification 10. This creates immensely deep state preparation circuits that are easily destroyed by the rapid decoherence of NISQ-era devices 10. To circumvent this, researchers are aggressively exploring quantum data augmentation and heuristic variational encodings - such as utilizing Matrix Product States (MPS) - to approximate desired input states with lower-depth circuits 2111. Nevertheless, until fault-tolerant logical qubits permit infinitely deep state preparation circuits without phase decay, the applicability of QML will remain strictly bottlenecked by the algorithmic and statistical richness of the input data.
5. Circumventing Digital Limitations: Analog Quantum Simulation
Given the stringent limitations of digital gate-based NISQ computers - where discrete errors accumulate intolerably across deep circuits - the field has witnessed a significant resurgence of interest in analog quantum simulation 2312. Unlike universal digital quantum computers, which rely on discrete single- and two-qubit logical gates, analog quantum simulators utilize continuous variables to represent information and apply continuous global transformations to govern system dynamics 2513.
5.1 Bypassing Gate Errors via Global Hamiltonian Evolution
In an analog paradigm, researchers engineer a highly controlled physical system to directly mimic the behavior of other, less accessible quantum materials and processes 13. Because these devices do not rely on discrete gate decompositions, they entirely avoid the rapid accumulation of sequential gate errors that cripple digital NISQ circuits 23.
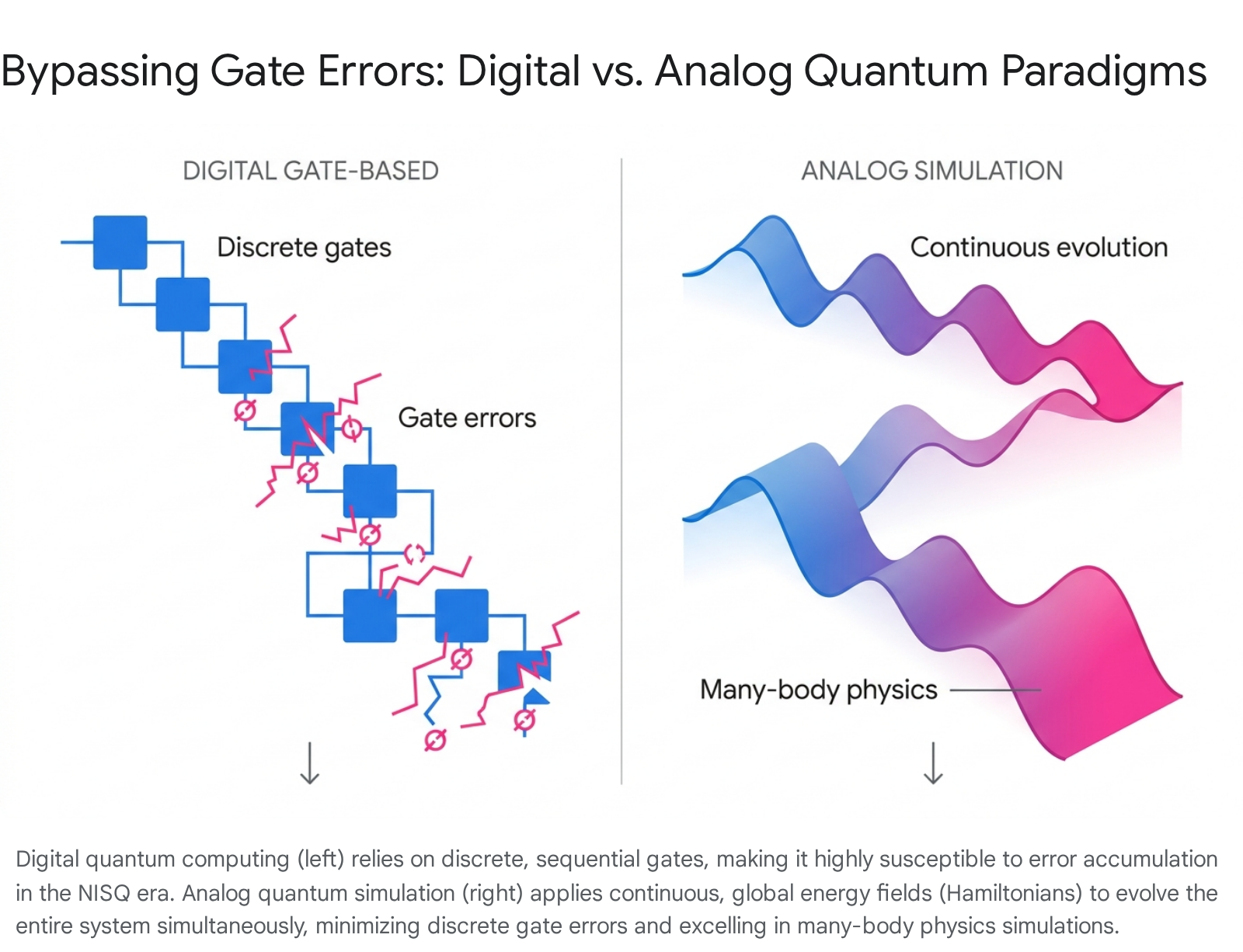
Analog systems are highly resource-efficient, utilizing the native Hamiltonian of the quantum platform to evolve the entire many-body system simultaneously 2325. While this lack of universality means an analog simulator cannot execute general-purpose algorithms like Shor's prime factorization, it offers immediate, quantitative quantum advantage for simulating quantum dynamics that underpin new materials, chemical modeling, and specific combinatorial optimization tasks 122513.
5.2 The Neutral Atom Advantage
Neutral atom arrays, controlled by precisely structured laser light (optical tweezers), have rapidly emerged as the premier modality for analog simulation 13. In mid-2024, the French quantum computing company Pasqal successfully loaded over 1,000 rubidium atoms into a single array - with up to 2,088 available trap sites - operating at cryogenic temperatures of 6 Kelvin 2714. Similarly, QuEra's Aquila system provides programmable coherent quantum dynamics on up to 256 neutral atoms, accessible via cloud platforms for analog Hamiltonian simulation 29.
These platforms boast exceptional physical stability. Because neutral atoms are naturally identical and largely isolated from environmental charge noise, they exhibit extraordinarily long coherence times 15. Pasqal has reported $T_2$ coherence times exceeding 5,000 seconds (approximately 80 minutes) for neutral atom arrays under specific trapping conditions, vastly outperforming the microsecond lifetimes characteristic of solid-state superconducting qubits 2715. By exploiting Rydberg states to induce programmable interactions between atoms, these analog simulators provide a pragmatic and immediate route to practical usefulness, bypassing the wait for fully fault-tolerant digital logic 1314.
6. Hardware Modalities and Global Advancements: A Comparative Landscape
The pursuit of practical quantum computing is a profoundly heterogeneous, multipolar race. Objective cross-platform benchmarking reveals that no single qubit modality currently dominates across all operational dimensions (scale, speed, fidelity, and coherence) 6. Concurrently, regional geopolitical strategies - ranging from the US to China, Europe, and Japan - are heavily subsidizing and shaping hardware development timelines.
6.1 State-of-the-Art Hardware Modalities
Superconducting transmons benefit from deep integration with existing microwave engineering and silicon CMOS fabrication techniques, enabling massive physical scaling, though they suffer from fragile coherence. Trapped ions utilize highly stable, naturally identical atomic isotopes suspended in electromagnetic fields, yielding world-record fidelities and coherence, but face challenges with slow gate speeds. Neutral atoms offer highly scalable analog and digital platforms via optical tweezers 61316.
Table 1 summarizes the leading global quantum processors across these diverse modalities, highlighting the sharp operational differences regarding physical qubit scale, two-qubit gate fidelities, and coherence times.
| Provider | Modality | System Name | Physical Qubits | 1Q Gate Fidelity | 2Q Gate Fidelity | Coherence ($T_1$ / $T_2$) |
|---|---|---|---|---|---|---|
| IBM | Superconducting | Heron r2 | 156 | ~99.98% | > 99.9% | ~100 - 300 μs |
| Superconducting | Willow | 105 | N/A | Sub-surface threshold | N/A | |
| USTC | Superconducting | Zuchongzhi 3.0 | 105 | 99.90% | 99.62% | ~72 μs ($T_2$) |
| Quantinuum | Trapped Ion | H2-1 | 56 | > 99.99% | > 99.9% | ~4 seconds ($T_2$) |
| IonQ | Trapped Ion | Forte | 36 | 99.98% | 99.6% | ~10 - 100 seconds |
| Pasqal | Neutral Atom | (Prototype) | 1,024 | 99.85% | N/A | > 5,000 seconds ($T_2$) |
| QuEra | Neutral Atom | Aquila | 256 | N/A | N/A | Platform Dependent |
Note: Blank or "N/A" values indicate proprietary metrics not definitively quantified in public benchmarking literature relative to the specific systems highlighted. IBM Heron r2 data reflects tunable-coupler advancements reducing two-level-system (TLS) defects 1432. USTC values are sourced from Zuchongzhi 3.0 random circuit sampling literature 148. Quantinuum and IonQ fidelities represent state-of-the-art trapped-ion randomized benchmarking 121617. Pasqal coherence represents neutral atom storage lifetimes 2734.
6.2 Global Ecosystems and Geopolitical Initiatives
Beyond North American corporate giants and China's academic strongholds at USTC, distinct global strategies are emerging. Europe has aggressively organized via the European Commission's Quantum Flagship initiative. By unveiling the Strategic Research and Industry Agenda (SRIA) 2030, the EU explicitly aims to establish the world's first autonomous "Quantum Valley." This roadmap seeks to end reliance on foreign hardware by integrating quantum technologies into EuroHPC supercomputing centers and pursuing multi-billion Euro investments to achieve strict supply chain sovereignty by 2030 181920. Furthermore, European startups like France's Alice & Bob are pioneering bosonic "cat qubits," which provide exponential suppression of bit-flip errors physically, thereby offering a hardware-efficient shortcut to logical fault tolerance 3839.
In the UK, the National Quantum Computing Centre (NQCC) has strategically funded quantum testbeds and application discovery programs. Demonstrating maturity beyond hardware construction, the NQCC successfully integrated 13 distinct industrial use cases into its 2024 hackathons, validating that software ecosystems and enterprise readiness are scaling alongside the physical hardware 214122. Similarly, in Japan, RIKEN, in partnership with Fujitsu, has deployed a 256-qubit superconducting system deliberately integrated with the Fugaku supercomputer to pioneer hybrid High-Performance Computing (HPC) architectures, recognizing that near-term quantum utility will rely heavily on classical coprocessing 43.
7. Overcoming the Overhead: Error Mitigation vs. Fault Tolerance
Because physical gate fidelities are fundamentally insufficient to support deep algorithmic execution directly, researchers employ secondary software and logical layers to bridge the gap to utility. The core debate defining post-2023 quantum computing centers on the viability and scalability of Quantum Error Mitigation (QEM) techniques versus an immediate, resource-heavy transition to full Fault-Tolerant Quantum Computing (FTQC).
7.1 The Asymptotic Limits of Quantum Error Mitigation (QEM)
QEM encompasses algorithmic methods - such as Zero-Noise Extrapolation (ZNE) and Probabilistic Error Cancellation (PEC) - that attempt to infer noiseless expectation values from noisy circuit variants without encoding overhead-heavy logical qubits 4445. While highly attractive for NISQ devices due to their lack of spatial hardware requirements, QEM techniques suffer from a fatal mathematical flaw: the variance-boosting effect.
Inverting noise channels via PEC yields an unbiased estimator of the error-free outcome, but it drastically increases the statistical variance of the results due to the "negativity" of the quasiprobabilities required to cancel noise 4423. To achieve a high-confidence estimate, the number of required sampling shots scales exponentially with the number of noisy gates. On contemporary IBM processors, the sampling overhead for certain QEM protocols scales proportionally to $\gamma^2 / \delta^2$, where $\gamma > 1$ represents an amplification factor that grows larger as the circuit deepens 24.
Consequently, beyond a strict depth threshold, the runtime sampling overhead of QEM becomes totally impractical, taking hours or days of execution just to extract a single expectation value 444524. While recent innovations, such as utilizing classical Machine Learning for QEM (ML-QEM) and layered virtual noise scaling, have drastically reduced this sampling overhead by orders of magnitude for specific circuits, QEM fundamentally remains a heuristic stopgap 4525. It trades spatial overhead for temporal (sampling) overhead, and therefore cannot scale indefinitely to arbitrary circuit depths. True scalability unequivocally mandates active error correction.
7.2 The Surface Code Crisis and the qLDPC Revolution
For the past decade, the planar Surface Code has been the absolute gold standard for FTQC. It possesses a high error threshold (capable of operating if physical errors are below ~1%) and requires only local, nearest-neighbor connectivity, making it ideal for the rigid 2D topologies of superconducting chips 2627. However, the Surface Code is astoundingly inefficient in its use of qubits. It possesses an asymptotically zero encoding rate, meaning that to protect a single logical qubit from realistic environmental error rates, it requires a staggering overhead of hundreds or even thousands of physical qubits per logical bit 3926. Estimates suggest that reaching commercial scale via Surface Codes would require millions of physical qubits, pushing practical economic timelines to 2035 or beyond 28.
In 2024 and 2025, the industry witnessed a massive paradigm shift toward Quantum Low-Density Parity-Check (qLDPC) codes. qLDPC codes maintain sparse parity-check constraints (each stabilizer acts on only a few qubits), allowing for highly efficient syndrome extraction, but crucially, they boast a constant or highly favorable encoding rate 2953. This means qLDPC codes can encode multiple logical qubits into a single, compact block of physical qubits.
Recent benchmarking of advanced qLDPC families - such as Bivariate Bicycle codes, Clifford-deformed La-cross codes, and SHYPS codes - demonstrates spectacular improvements over the legacy Surface Code 545530. For example, simulating a specific algorithmic workload protecting 12 logical qubits via independent Surface Code patches would require over 3,000 physical qubits. However, a distance-12 Bivariate Bicycle code achieves the exact same logical error suppression using only 288 physical qubits - a greater than 10-fold reduction in resource overhead 2630.
The primary physical barrier to qLDPC adoption is hardware connectivity. Unlike the Surface Code, qLDPC codes require highly complex, non-local qubit interactions that stretch across the processor 395355. This makes them exceptionally difficult to implement on static, planar superconducting lattices without massive engineering modifications 263031. Conversely, modalities with native dynamic interconnectivity - such as the ion shuttling in Quantinuum's QCCD trapped-ion architecture or the rapid optical tweezer rearrangement in neutral atom platforms (e.g., Pasqal, QuEra) - are structurally tailored to execute qLDPC codes, potentially accelerating their respective pathways to commercial FTQC by several years 533158.
8. Diverging Timelines: Corporate Roadmaps vs. Academic Skepticism
The rapid acceleration of logical qubit demonstrations and the theoretical validation of qLDPC codes have caused a stark divergence in timeline predictions for achieving "quantum utility." This divergence is particularly pronounced regarding estimates for "Q-Day" - the point at which a Cryptographically Relevant Quantum Computer (CRQC) becomes capable of breaking 2048-bit RSA encryption.
8.1 Corporate Optimism (2027 - 2030)
Major technology vendors maintain highly aggressive timelines, fueled by consecutive engineering breakthroughs. IBM's publicly updated 2030 roadmap commits to delivering "Starling" in 2029, pitched as the first modular, fault-tolerant quantum computer capable of executing 100 million gates on 200 logical qubits, utilizing qLDPC (Gross code) innovations 323260. By 2033, IBM plans to unveil "Blue Jay," a scaled system projecting 1 billion gates on 2,000 logical qubits 32.
Similarly, Quantinuum anticipates delivering fault-tolerant computation on hundreds of logical qubits by the end of the decade, while startups like Alice & Bob explicitly target a useful, error-corrected machine utilizing bosonic cat qubits by 2030 1738. Influential industry analysts, including Forrester Research, have notably revised their forecasts based on logical qubit advancements, now stating that practical business utility and the cryptographic threat of Q-Day are both highly plausible by 2030, a significant acceleration from their previous 2024 assessments 60.
8.2 Academic Consensus and Fundamental Skepticism
In sharp contrast, independent academic and governmental consortiums offer substantially more conservative assessments. Studies based on historical technological scaling trajectories - such as analyses of high-performance workloads at the National Energy Research Scientific Computing Center (NERSC) - predict that commercial applications requiring millions of qubits and massive FTQC overhead remain a 2035 - 2040 reality 616263.
More profound than timeline debates is the fundamental physical skepticism posited by esteemed theorists like Gil Kalai. Kalai argues that the failure to scale is not merely a temporary engineering hurdle, but a consequence of inherent physical laws. He hypothesizes that intermediate-scale quantum systems intrinsically display correlated, noise-sensitive behavior that acts as a fundamental barrier, rendering both quantum computational supremacy and the creation of high-quality logical qubits theoretically impossible at scale 6433. According to this view, the macroscopic noise mechanisms that degrade quantum information are deeply chaotic and simply cannot be screened off by classical error-correcting code adaptations, thus dooming large-scale fault tolerance 6466.
Conversely, researchers such as Scott Aaronson argue that a continuous stream of empirical evidence is steadily dismantling this rigid skepticism. The attainment of 99.99% two-qubit gate fidelities on trapped-ion systems and the successful execution of early topological and error-corrected logical qubits directly challenge the hypothesis of an insurmountable correlated noise barrier 146667. Aaronson notes that if a fundamental, physics-based roadblock truly exists, it must be an entirely novel and unforeseen law of physics that manifests uniquely at the scale of millions of gates, as current quantum hardware has already successfully bypassed the theoretical barriers skeptics previously predicted for the hundreds-of-gates regime 666768.
9. Conclusion
The transition out of the Noisy Intermediate-Scale Quantum era is defined by an uncompromising realism regarding physical limitations and a strategic, industry-wide pivot toward structural efficiency and error mitigation. Raw physical qubit counts have been universally discarded as inadequate indicators of computational utility, replaced by rigorous, holistic metrics like Quantum Volume and Algorithmic Qubits that enforce operational fidelity and system-wide coherence 345.
While classical tensor network algorithms continue to fiercely contest the boundaries of quantum advantage via simulation 78, and foundational data-loading complexities currently hinder the immediate, widespread adoption of Quantum Machine Learning 1021, the hardware ecosystem is rapidly adapting. Analog quantum simulators, particularly those utilizing highly stable neutral atom arrays, provide immediate, near-term workarounds for executing complex many-body physics and specific combinatorial optimization tasks without the burden of discrete gate errors 1314.
Crucially, the long-term economic viability of universal digital quantum computing hinges almost entirely on the successful physical deployment of Quantum Low-Density Parity-Check (qLDPC) codes. By drastically reducing the physical-to-logical qubit overhead required for fault tolerance, qLDPC codes transform the timeline to commercial utility from a distant, resource-prohibitive pipe-dream into an imminent architectural engineering challenge 5455. Whether one subscribes to the optimistic corporate roadmaps targeting breakthrough utility by 2030 3260 or the more conservative academic consensus stretching well into the late 2030s 6263, it is irrefutable that the hardware fidelities, algorithmic frameworks, and theoretical groundwork required for practical, fault-tolerant quantum computation are rapidly maturing across the global technological stage.