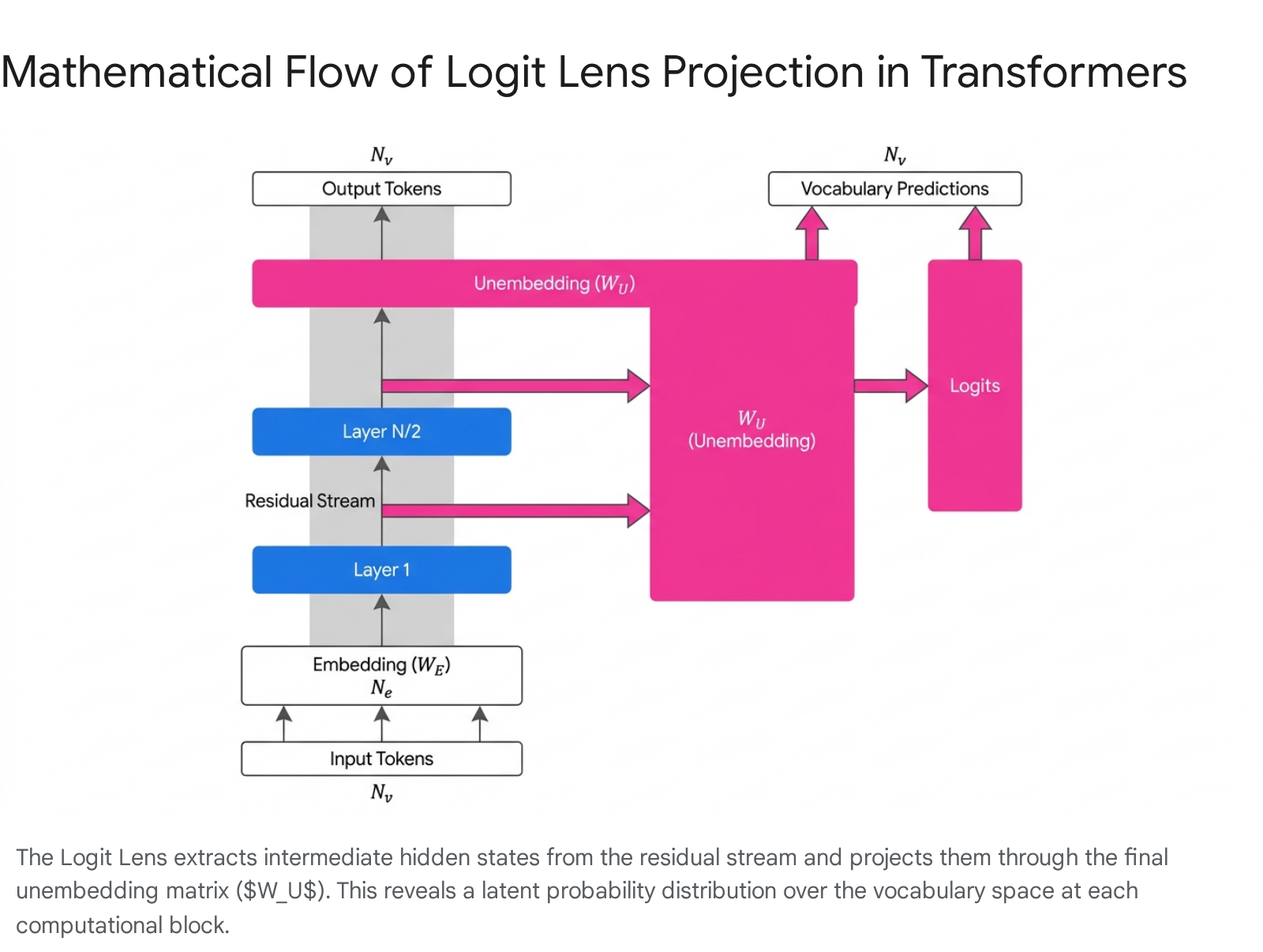
Layer-by-layer prediction analysis through the logit lens
Introduction to Iterative Inference and Network Opacity
The rapid scaling of transformer-based large language models (LLMs) and vision-language models (VLMs) has produced artificial intelligence systems with unprecedented capabilities in natural language understanding, logical reasoning, and multimodal synthesis. Modern architectures, scaling up to 405 billion parameters in models such as Llama-3.1, exhibit emergent behaviors that facilitate state-of-the-art performance across diverse benchmarks 12. However, this performance is accompanied by profound systemic opacity. In standard autoregressive generation, foundation models operate as "black boxes." They ingest a sequence of tokens, project them into high-dimensional vector spaces, process them through dozens of transformer blocks, and eventually emit a probability distribution over a vocabulary to predict the next token 34. While the final output is entirely visible, the internal cognitive trajectory - how the model iteratively constructs its beliefs, retrieves factual associations, and refines its predictions layer by layer - remains largely hidden from immediate observation 42.
The emerging discipline of mechanistic interpretability aims to reverse-engineer these complex neural networks, seeking to decode their internal representations into human-understandable algorithms and causal circuits 37. Within this highly specialized subfield, the "Logit Lens," introduced by the independent researcher known as nostalgebraist in 2020, stands as a foundational diagnostic tool 24. By treating decoder-only transformers as dynamic systems that operate within a continuous predictive space, the logit lens bypasses the traditional necessity of waiting for the final network layer to execute a readout 4. Instead, it intercepts and projects the intermediate hidden states of the network directly into the human-readable vocabulary space 29.
This methodology allows researchers to generate a layer-by-layer "prediction trajectory," exposing the network's nascent beliefs at every computational stage 1011. Since its initial application to early models like GPT-2, the logit lens has evolved from a simple diagnostic probe into a cornerstone of modern interpretability research 25. As the field has matured, it has spawned highly sophisticated methodological refinements designed to overcome its initial theoretical limitations, including the Tuned Lens, Direct Logit Attribution (DLA), Logit Prisms, and the ContextualLens for multimodal architectures 4678. Furthermore, recent scholarship spanning the 2024 to 2026 period has applied these advanced techniques to frontier models like Llama-3.1, Mistral, Gemma, and Qwen-2.5. This research has uncovered profound insights into multilingual semantic hubs, the high-dimensional geometry of factual recall, and the paradoxical phenomenon of steerability without decodability 16918. This report provides an exhaustive, peer-reviewed synthesis of the logit lens technique, dissecting its mathematical foundations, evaluating its comparative efficacy against linear probes and sparse autoencoders, and detailing its leading-edge applications in state-of-the-art foundation models.
The Mathematical Mechanics of the Logit Lens
To thoroughly understand the logit lens, one must first deconstruct the linear algebraic architecture of the transformer model, specifically focusing on the continuous interplay between the vocabulary space, the internal embedding space, and the residual stream 2.
Vocabulary Space, Embedding Space, and the Residual Stream
Transformer language models fundamentally act as complex geometric translators between discrete human language and continuous vector spaces. The model operates primarily between two distinct vector spaces 2: 1. The Vocabulary Space ($N_v$): A high-dimensional discrete space representing the entire dictionary of individual tokens the model can generate or recognize. In earlier models like GPT-2, $N_v$ equals 50,257 tokens, whereas modern architectures often utilize significantly larger vocabularies 2. 2. The Embedding Space ($N_e$): A lower-dimensional, continuous space where the model performs its dense internal computations. The dimensionality of this space varies by model scale; for instance, $N_e = 1,600$ for a 1.5B parameter GPT-2 model, while frontier models like Llama-3.1 70B utilize an embedding dimension of $N_e = 8,192$ 210.
Information is initially mapped from the discrete $N_v$ vocabulary space to the continuous $N_e$ embedding space via a learned embedding matrix $W_E$. Once embedded, the token representations enter the "residual stream," which serves as the central communication channel and memory backbone of the transformer 620. The transformer architecture relies heavily on residual connections, governed by the identity function $x_{l+1} = x_l + f(x_l)$, where $f$ represents the non-linear and linear operations of attention heads and multi-layer perceptrons (MLPs) 2. Because these individual components add their calculated outputs directly back into the original stream, the final residual state $\mathbf{r}^L$ at the last layer $L$ is mathematically equivalent to the sum of the initial embedding and the additive contributions of every subsequent layer throughout the depth of the network 6:
$$\mathbf{r}^L = \text{Embed}(x) + \sum_{l,h} \mathbf{r}^{l,h} + \sum_l \mathbf{r}^{\text{MLP}_l}$$
The Linear Projection Mechanism
In standard autoregressive operation, once the final layer $L$ completes its computation, the network must translate the abstract, $N_e$-dimensional residual vector $\mathbf{r}^L$ back into the $N_v$-dimensional vocabulary space to communicate with the user. This reverse translation is achieved using the unembedding matrix, $W_U$, typically followed by a softmax function to generate the final, normalized probability distribution over the entire vocabulary 26.
The defining theoretical thesis of the logit lens is that, because transformers utilize a residual architecture that is heavily regularized by weight decay (L2 regularization), the network is structurally incentivized to "spread out" computations smoothly across layers while strictly preserving a consistent representational basis in the residual stream 2. Weight decay penalizes massive, discontinuous shifts in the vector representations, meaning that the intermediate activations are not entirely alien or orthogonal to the final unembedding matrix. Exploiting this mathematical property, the logit lens extracts the intermediate hidden state $\mathbf{h}_\ell$ at layer $\ell$, applies the final Layer Normalization to stabilize the variance, and directly multiplies it by the network's own unembedding matrix $W_U$ 521:
$$\text{LogitLens}(\mathbf{h}\ell) = \text{LayerNorm}(\mathbf{h}\ell) \cdot W_U$$
By applying this precise linear transformation systematically across all intermediate layers $\ell \in {1, 2, \dots, L}$, researchers map a comprehensive, multi-layer prediction trajectory 1011. This trajectory empirically demonstrates that models do not simply "hold" input representations in an abstract, unreadable state until the final layers construct an answer. Rather, the inputs are immediately converted into a prediction-oriented representation format that is smoothly and continuously refined, layer by layer 115. For example, when predicting the completion to "The Eiffel Tower is located in the city of", logit lens analysis reveals that early layers may probabilistically favor the broad semantic category "France", before middle and late layers refine the geometric representation to overwhelmingly predict the highly specific token "Paris" 521.
Inherent Limitations of the Standard Logit Lens
While conceptually elegant and computationally inexpensive, the naive application of the unembedding matrix to intermediate layers suffers from critical methodological limitations, frequently rendering it a "lossy" or highly brittle translation mechanism 4. The interpretation of logit lens outputs requires rigorous caveat awareness, primarily due to issues of basis misalignment, representational drift, and the epistemological divide between observation and causal necessity.
Representational Drift and Basis Misalignment
The primary geometric vulnerability of the standard logit lens is its fundamental assumption of a shared, static coordinate space. The mathematical operation implicitly presumes that intermediate representations occupy the exact same vector basis as the final layer 5. In reality, the high-dimensional latent spaces of neural networks are incredibly flexible. To optimize computational efficiency, intermediate layers frequently represent information in a rotated, shifted, or stretched basis 522. Because the unembedding matrix $W_U$ is calibrated exclusively for the final layer's specific geometric alignment, projecting a rotated intermediate vector yields garbled, out-of-distribution logits that do not reflect the model's true internal state 523.
Empirically, this basis misalignment manifests as complete functional failures on certain architectures. While the logit lens works exceptionally well on GPT-2, researchers have documented that it fails catastrophically on models like BLOOM, OPT-125M, and GPT-Neo 1511. In these specific architectures, early layers subjected to the logit lens often predict the input token itself rather than any plausible continuation, indicating severe representational drift 111. Furthermore, the logit lens has been shown to act as a biased estimator of the model's final output, systematically placing disproportionate probability mass on certain high-frequency vocabulary items 11. The critical pedagogical lesson for researchers is that a failure to decode information via the logit lens does not prove the absence of that information; it simply proves the information is linearly inaccessible to the unadjusted, final unembedding matrix at that specific depth 525.
The Epistemological Limit: Observation vs. Causation
From a strict mechanistic interpretability standpoint, the logit lens is solely an observational tool. It records correlation but cannot establish causal necessity 5. If the logit lens detects that the correct target token ("Paris") completely dominates the probability distribution at layer 8, it does not mathematically prove that the computation performed at layer 8 was necessary for the model to predict "Paris" at the final output 5.
Due to the complex routing of the residual stream, later components - such as deep MLPs - might completely overwrite, reverse, or suppress this early signal. Alternatively, the signal detected at layer 8 might simply be a correlated artifact of parallel processing 56. The logit lens describes when an answer appears in the trajectory, but it does not explain the functional mechanism responsible for that computation 5. To establish true causality, observational techniques like the logit lens must be paired with causal interventions, such as activation patching or causal basis extraction 1126.
Methodological Refinements: Translators and Prisms
To comprehensively address the geometric and causal limitations inherent in the naive logit lens, researchers have developed advanced frameworks to rigorously track, correct, and decompose the predictive trajectory of large transformers.
The Tuned Lens: Correcting Basis Misalignment
To overcome the pervasive issues of representational drift and basis rotation, Belrose et al. (2023) introduced the "Tuned Lens" 727. Rather than forcing the raw, unmodified unembedding matrix onto all intermediate states, the tuned lens algorithm learns a specific affine "translator" for each individual transformer block 510.
This affine probe consists of a specifically trained transformation matrix $A_\ell$ and a bias vector $b_\ell$ designed to map the intermediate representation into the final-layer basis prior to the application of the unembedding matrix 5. Crucially, a defining architectural choice of the tuned lens is that these translators are trained strictly to minimize the Kullback-Leibler (KL) divergence between their output distribution and the model's actual final-layer output distribution - not against external ground truth labels 522. This vital distinction ensures the tuned lens faithfully extracts the model's internal beliefs and reasoning pathways at a given layer, even if those internal beliefs are hallucinated or factually incorrect 5.
Extensive benchmarking across diverse autoregressive language models with up to 20 billion parameters demonstrates that the tuned lens is significantly more predictive, reliable, and unbiased than the standard logit lens 712. It yields substantially lower perplexity metrics, forcefully mitigates the inherent bias toward high-frequency tokens, and successfully elicits coherent latent predictions from architectures (such as BLOOM and GPT-Neo) where the standard logit lens produces unintelligible noise 511. Furthermore, causal basis extraction experiments confirm that the features most influential on the tuned lens output are proportionately influential on the model's final output, validating its mechanistic fidelity 11.
Direct Logit Attribution (DLA)
While the logit lens and tuned lens evaluate the aggregate, macroscopic state of the residual stream, Direct Logit Attribution (DLA) is an associated methodological refinement designed to decompose the final logits into highly granular, per-component contributions 46. Pioneered by Anthropic researchers in 2021 as part of a mathematical framework for transformer circuits, DLA directly exploits the linear properties of the residual architecture. Because every attention head and MLP writes additively to the stream, their individual, isolated impact on the final output distribution can be mathematically quantified 6.
For a specific attention head $h$ predicting a specific token $t$, the direct logit attribution is defined precisely as 6:
$$\text{DLA}(h, t) = \mathbf{r}^h \cdot W_U[:, t]$$
Where $\mathbf{r}^h$ represents the output of the head written directly into the residual stream, and $W_U[:, t]$ represents the specific direction in logit space corresponding to the token $t$. In advanced circuit discovery tasks, researchers frequently focus on the logit difference between two competing tokens (e.g., the vector difference between the unembeddings of the tokens "Mary" and "John"). By projecting the output of every component onto this precise logit difference direction, researchers can instantly rank which specific heads actively promote or suppress a given token 629. This allows for the identification of primary contributors in seconds from a single forward pass, entirely bypassing the need for computationally expensive gradient calculations 6.
Logit Prisms: Decomposing Non-Linearity
Building upon the logic of DLA, researchers in 2024 introduced the "Logit Prisms" framework. While DLA effectively handles the linear additions of attention heads, treating non-linear MLP layers is mathematically complex 4. Logit Prisms extend the attribution approach in a mathematically rigorous manner by treating the model's non-linear activations as temporary constants during the backward projection 430. This allows researchers to leverage the linear properties within the network to break down the logit output into individual component contributions not just for the residual stream, but recursively through the attention layers and deep MLP layers 4. Applied to models like Gemma-2B, these prisms have successfully mapped exact factual retrieval circuits, demonstrating how early-layer MLPs retrieve facts while late-layer attention heads route those facts to the output stream 4.
Contrasting Interpretability Techniques: Probing and SAEs
The modern ecosystem of mechanistic interpretability involves various competing methodologies designed to decode network internals. The Logit/Tuned Lens, Linear Probing, and Sparse Autoencoders (SAEs) represent distinct philosophies of feature extraction, each possessing highly unique operational overheads, causal fidelities, and levels of intervention success 2613. Recent scholarship has systematically evaluated these techniques using a unified encoder-decoder framework to assess their real-world utility 2613.
Logit Lens vs. Linear Probing
Linear probing involves training a supervised, external linear classifier on the intermediate representations of a model to detect a pre-defined, high-level human concept (e.g., "helpfulness," "sentiment," or "part-of-speech") 310. * The Supervision Divide: The logit lens is an inherently unsupervised and mapping-free technique; it organically leverages the model's pre-existing vocabulary matrix to read activations 2026. Conversely, probing is fundamentally supervised, requiring a researcher to construct an external dataset of labeled examples to mathematically find a separation direction in the latent space 1013. * Spurious Correlations and Linear Accessibility: A critical flaw documented in linear probing literature is the propensity of high-capacity probes to simply learn the task themselves, or to fixate on spurious correlations present in the training data, rather than genuinely reflecting the model's actual internal processing 181013. Advanced probes often overestimate a model's true linear accessibility 25. Lens-based techniques avoid this artifact by optimizing strictly against the model's own internal mathematical parameters, tracking trajectories without the injection of external labeling biases 18.
Logit Lens vs. Sparse Autoencoders (SAEs)
Neurons in massive transformer models are notoriously polysemantic; due to the phenomenon of "superposition," a single neuron often entangles multiple unrelated features to maximize the utility of a constrained parameter count 725. Sparse Autoencoders (SAEs) attempt to resolve this superposition by factorizing the high-dimensional internal activations into a vast, overcomplete, and sparse dictionary of monosemantic, human-interpretable features 732. * Methodological Goal: While the logit lens specializes in explaining exactly when an answer appears in the vocabulary space trajectory, SAEs attempt to completely map the structural computational ontology of the model. SAEs discover features that range from simple grammatical syntax to highly abstract, multi-token concepts (such as "deception", "religious text", or "coding loops") 732. * Intervention and Overhead Trade-offs: Despite the theoretical elegance of SAEs, rigorous 2024/2025 benchmarking reveals significant divergences in the utility of these methods for causal model editing and intervention. Lens-based methods (Logit and Tuned Lens) boast the absolute lowest operational overhead - requiring zero to minimal training data - and consistently achieve significantly higher intervention success rates for simple, concrete features 2613. * The Dictionary Bottleneck: Conversely, SAEs are characterized by extremely high compute and data overheads 13. Because SAE features are learned unsupervised, they suffer from severe labeling noise, requiring massive post-hoc evaluation by human researchers or strong LLMs to assign meaning to the learned dictionaries 13. Furthermore, recent mathematical analysis indicates that the linear representation hypothesis is often conflated with linear accessibility. SAEs amortize sparse inference into a fixed encoder, creating a structural bottleneck that can fail to recover complex, non-linear concept boundaries that simple, dynamic vocabulary projections can sometimes successfully bypass 25. Consequently, SAEs exhibit lower and more highly inconsistent causal effectiveness when actively steering model behavior compared to lens-based adjustments 13.
Tabular Summary: Evaluation Metrics of Interpretability Frameworks
| Method | Computational Overhead | Interpretability Output | Intervention Success Rate | Primary Limitation |
|---|---|---|---|---|
| Logit Lens | Very Low (Zero-shot) | Vocabulary Tokens | High (for concrete features) | Fails on basis shifts; biased toward high-frequency tokens. |
| Tuned Lens | Moderate (Training affine probes) | Adjusted Vocabulary Tokens | High | Requires layer-wise KL divergence training. |
| Linear Probing | Low/Moderate (Requires labeled data) | User-defined Concepts | Low / Inconsistent | Prone to learning spurious correlations in datasets. |
| Sparse Autoencoders | Very High (Compute & Data intensive) | Learned Sparse Features | Low / Inconsistent | High noise in feature labeling; dictionary bottlenecks. |
Advanced Applications on Modern Foundation Models (2024 - 2026)
Initially limited to investigating early, small-scale models like GPT-2, the logit lens framework has been aggressively modernized to probe state-of-the-art architectures. The introduction of advanced toolkits like LogitLens4LLMs in February 2025 has enabled seamless, component-specific hooking for massive models 1633. This automated framework achieves full compatibility with the HuggingFace transformer library, capturing both attention mechanisms and MLP outputs while maintaining exceptionally low inference overhead, thus permitting the analysis of models like Llama-3.1 (up to 405B parameters) and Qwen-2.5 1633.
Factual Recall vs. Refinement Dynamics
Recent applications of the logit lens on Llama-3 and Mistral architectures have illuminated the exact mechanics of how factual knowledge is crystallized during the forward inference pass. Research published in 2025 has definitively demonstrated that factual recall is not an instantaneous lookup process 434.
Logit lens trajectories show that early layers universally generate generic, rough predictions based heavily on local syntax 4. However, middle layers experience massive prediction diversity and attribute retrieval - often dramatically outperforming final layers in continuous, indirect classification tasks 434. Only in the deepest layers do the logits constrain into a single, dominant, contextually integrated choice 434. Furthermore, linear probing paired with lens analysis reveals that LLMs encode symbolic knowledge (such as the periodic table of elements) not as isolated textual facts, but within structured, geometric manifolds. Researchers have identified a 3D spiral structure in the hidden states of these models that perfectly aligns with the conceptual organization of scientific concepts learned from pre-training text, intertwining semantic data across the depth of the network 34.
The Multilingual "English Scaffold"
Applying the logit lens to multilingual and diverse-data prompts has uncovered the profound "semantic hub" effect inherent to modern LLMs. When English-dominant models like Llama-3, Mistral, or even purportedly multilingual models like BLOOM process inputs in Chinese, Spanish, or parse arithmetic expressions and computer code, intermediate layer hidden states exhibit an overwhelming proximity to English vocabulary tokens 91415.
Despite the non-English input, the model translates concepts into a shared, English-scaffolded representation space in the middle layers to conduct its logical reasoning 9. Once the reasoning is complete in this latent English space, the model translates the result back into the target language at the final output layers 59. This phenomenon highlights a fundamental architectural bias stemming from the predominantly English composition of global pre-training corpora 15.
The Paradigm Shift: Steerability Without Decodability
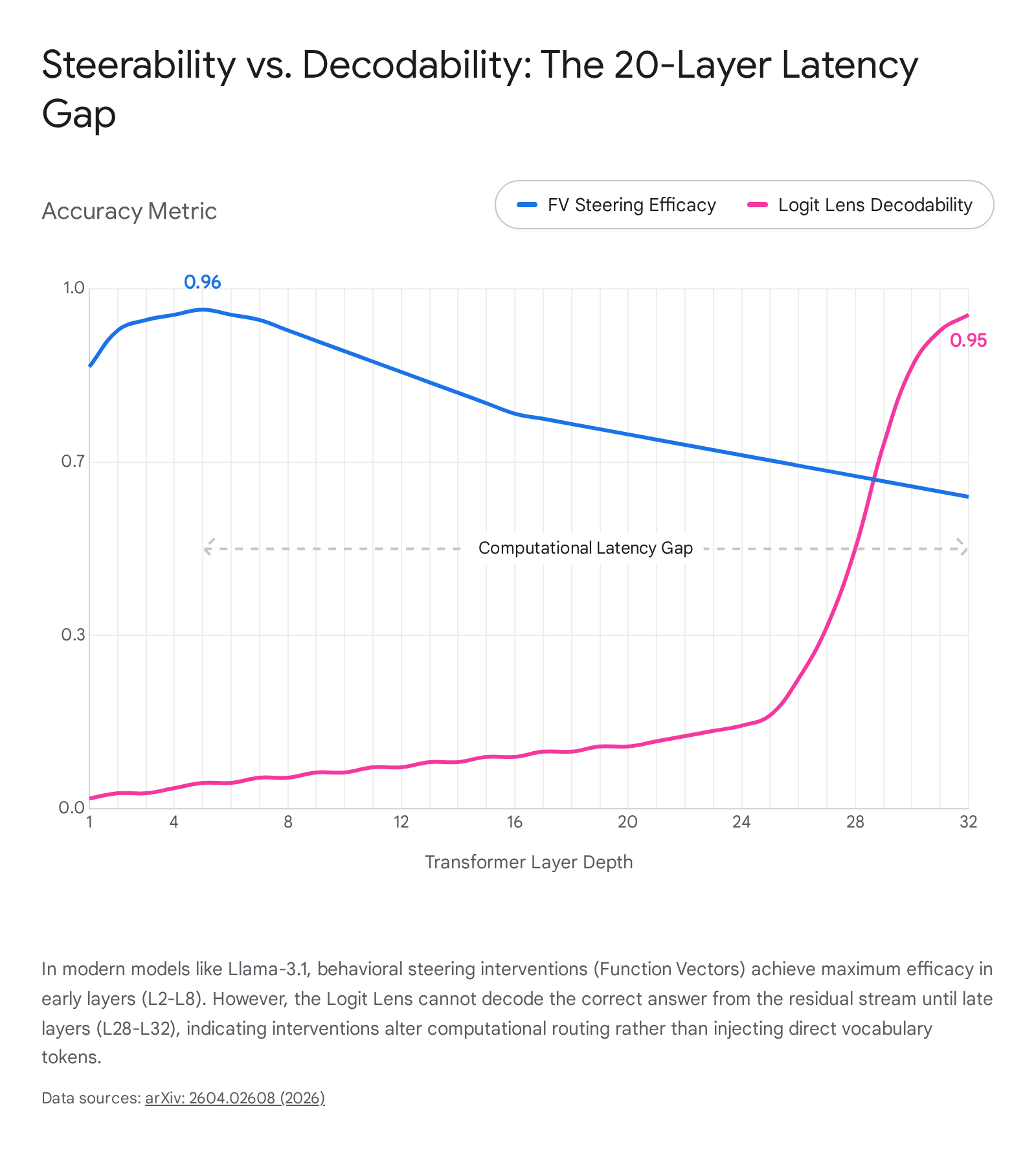
Perhaps the most significant and disruptive 2026 finding in the field of mechanistic interpretability originates from an extensive, cross-template study of Function Vectors (FVs) on modern models. Function vectors are mean-difference directions carefully extracted from in-context learning demonstrations and added to the residual stream to causally steer model behavior 18.
Historically, interpretability researchers operated under the assumption that if a model could be successfully steered toward an answer using an FV, that specific answer must be linearly decodable in the intermediate layers via the logit lens 18. A massive 2026 study encompassing 4,032 task pairs across 12 tasks on Llama-3.1-8B, Gemma-2-9B, and Mistral-7B definitively disproved this assumption 18. Researchers universally observed an inverted dissociation pattern: "steerability-without-decodability." In these models, steering interventions were highly successful and optimally injected at early layers (L2 - L8), yet the logit lens could not decode the correct target token from the residual stream until the very late layers (L28 - L32) 18.
This vast, 20-plus layer latency gap proved that FVs do not inject the semantic "answer vector" directly into the residual stream for immediate readout; rather, they encode structural "computational instructions" that route attention and modulate MLP gating mechanisms without leaving an immediate, linear trace in the vocabulary space 18. The steerability-without-decodability gap reached magnitudes as large as -0.91 (steering accuracy vs. logit lens accuracy) on certain Llama instruction-tuned models 18.
Interestingly, post-steering logit lens analysis revealed a massive mechanistic divergence between model families. Mistral models operate representationally; injecting an FV into Mistral massively rewrites the internal representations, causing logit lens readability for the target token to jump drastically at intermediate layers (displaying deltas up to +0.91) 18. Conversely, Llama-3.1 and Gemma operate modulatorily; they successfully steer the final output but produce near-zero changes in intermediate logit lens readings, highlighting that modern architectures of similar parameter scale can develop entirely disparate internal wiring protocols to solve identical tasks 18.
Expanding the Lens: Vision-Language Models (VLMs)
The transition from unimodal LLMs to multimodal Large Vision-Language Models (LVLMs) like LLaVA 1.5 - which combine separate vision encoders (e.g., CLIP) with large language models (e.g., Vicuna) - has introduced the profound challenge of interpreting cross-modal information flow 937. Because existing unimodal explainability tools often fail to capture the complex cross-modal interactions that drive multimodal decisions, researchers have adapted the logit lens framework to bridge this modality gap 37.
Visual Crystallization in Vocabulary Space
By adapting the logit lens to analyze the hidden states of image tokens within the language model component of VLMs, researchers in late 2024 and 2025 discovered that visual representations undergo a profound process of "semantic refinement" or crystallization 1617. Despite the language model component never being explicitly pre-trained to predict next-tokens from purely visual inputs, the intermediate representations of the visual patches are gradually refined towards the specific embeddings of the interpretable textual tokens that describe the visual content 940.
By projecting internal image representations directly to the text language vocabulary, models exhibit highly confident output probabilities on real, present objects, and significantly lower probabilities on objects that the model is likely to hallucinate 18. Through rigorous ablation studies, it was determined that removing these specific, localized object tokens causes object identification accuracy to plummet by over 70%, proving that visual information is highly localized to token positions corresponding to their original location in the image grid 94042.
Mitigating Hallucinations and the ContextualLens
This visual crystallization finding has driven significant, training-free advancements in hallucination mitigation and zero-shot segmentation. Methodologies like the "ProjectAway" knowledge erasure algorithm leverage logit lens probability distributions to linearly orthogonalize image features with respect to hallucinated object features 1819. This technique directly erases spurious knowledge from the VLM's latent representations, successfully reducing object hallucinations by up to 25.7% on standard benchmarks like COCO2014, while preserving overall performance in image captioning tasks 1819.
However, the standard logit lens application - which relies strictly on non-contextual unembedding layer features - struggles with generalized visual hallucinations that involve complex actions, spatial relationships, and multi-token concepts (e.g., Optical Character Recognition or OCR text) 844. To resolve this critical bottleneck, researchers introduced the ContextualLens 84445.
Instead of relying solely on the final $W_U$ projection matrix, ContextualLens extracts deep contextual token embeddings from the middle layers of the VLM. It then computes the semantic cosine similarity between the averaged textual answer token embeddings and the intermediate image patch embeddings 4446. This sophisticated methodology bridges the remaining semantic gap, enabling highly granular hallucination detection across complex visual categories (such as attribute comparisons and actions) that previously performed at near-random accuracy 845. Furthermore, this technique yields bounding boxes precise enough to facilitate a transition from basic Zero-Shot Object Segmentation to complex Grounded Visual Question Answering, advancing the reliability of multimodal systems without requiring costly retraining or reliance on external evaluation models 845.
Conclusion
The evolution of the logit lens has fundamentally reshaped the pursuit of mechanistic interpretability. By mathematically bypassing the temporal constraints of standard autoregressive generation, it provides an unprecedented, granular diagnostic window into the cognitive trajectory of foundation models. While the naive technique suffers from documented basis misalignment, representational drift, and epistemological limits regarding causal necessity, methodological refinements like the Tuned Lens, Direct Logit Attribution, and Logit Prisms have successfully mitigated these vulnerabilities.
As the artificial intelligence industry aggressively transitions to multimodal architectures and massive-scale parameter models like Llama-3.1 405B, lens-based techniques offer highly efficient, interpretable alternatives to compute-heavy, noisy methods like sparse autoencoders. From uncovering multilingual English semantic hubs and the 3D geometric geometry of factual recall, to isolating the exact layers where visual concepts crystallize into language, the logit lens - and its emerging contextual variants - will remain a vital instrument for ensuring that as artificial intelligence scales in capability, its internal logic does not remain fundamentally opaque.