Latent Diffusion Architecture for AI Image Generation
Evolution of Generative Image Synthesis
The advent of deep learning in image synthesis was historically dominated by Generative Adversarial Networks (GANs) and standard Variational Autoencoders (VAEs). While GANs demonstrated remarkable visual fidelity, they suffered from persistent issues such as mode collapse, training instability, and an inability to reliably capture the full diversity of the underlying data distribution. Standard diffusion models - formulated as Denoising Diffusion Probabilistic Models (DDPMs) - emerged as a principled alternative to these adversarial frameworks. These models conceptualize image generation as a thermodynamic process, learning to invert the gradual, stepwise addition of Gaussian noise to an image 123. By iteratively denoising a completely random tensor over hundreds or thousands of discrete steps, the network mathematically recovers the underlying data distribution 24.
However, early DDPMs operated directly in the high-dimensional pixel space. For a standard high-resolution image, the generative model was forced to evaluate gradients across millions of spatial dimensions at every single denoising step. This pixel-level optimization meant that likelihood-based models allocated a disproportionate amount of computational capacity to modeling imperceptible, high-frequency details rather than overarching semantic structures 54. Optimization often consumed thousands of GPU days, and the highly sequential nature of inference rendered the models computationally prohibitive for broad deployment on consumer hardware 45.
The paradigm shifted fundamentally with the introduction of Latent Diffusion Models (LDMs) by Rombach et al. The core theoretical insight of the LDM framework is the decoupling of perceptual compression from semantic synthesis 5. By recognizing that the overarching semantic structure and composition of an image can be represented in a much lower-dimensional space without sacrificing human-perceptible details, LDMs apply the iterative diffusion process within a tightly compressed latent space rather than the original, unwieldy pixel space 245. This architectural decision drastically reduces computational overhead while simultaneously boosting visual fidelity, establishing the operational foundation for the entire Stable Diffusion ecosystem 45.
The Variational Autoencoder Bottleneck
The bridge between the human-readable pixel space and the computationally efficient latent space is the Variational Autoencoder (VAE) 6. The VAE consists of two distinct neural networks: an encoder that maps an input image from pixel space into a lower-dimensional latent representation, and a decoder that reconstructs the visual image from these abstract latents 26.
Conceptualizing Latent Compression
In foundational latent diffusion models such as Stable Diffusion 1.5 and Stable Diffusion XL (SDXL), the VAE relies on convolutional layers with a spatial downsampling factor of 8 67. An image with dimensions of 512 * 512 pixels across 3 RGB color channels contains 786,432 individual data points. The VAE encoder aggressively compresses this data into a 64 * 64 tensor across 4 latent channels, yielding only 16,384 distinct values 2. This represents a massive spatial compression ratio of 48x, drastically shrinking the coordinate space where the subsequent diffusion model must calculate its noise predictions 26.
While this aggressive compression is the fundamental engine of latent diffusion's computational efficiency, it introduces an absolute mathematical bottleneck for fine, high-frequency visual details 6. A common misconception regarding generative failures is that the diffusion model itself "forgets" or fails to render minute details like skin texture, distant facial features, or legible typography during the denoising process. In reality, these high-frequency details are often irreversibly destroyed during the initial VAE encoding phase. If a specific detail is smaller than the 8x8 pixel block that gets compressed into a single latent pixel, it is smoothed out of existence before the diffusion network ever interacts with the data 68.
Trade-offs in Channel Depth and Frequency Preservation
To mitigate this inherent blurriness and detail loss, the VAE is typically trained using a highly specific combination of Mean Squared Error (MSE) loss, perceptual loss (such as Learned Perceptual Image Patch Similarity, or LPIPS), and patch-based adversarial objectives (PatchGAN) 9. Without these perceptual and adversarial penalties, a purely MSE-optimized autoencoder yields mathematically averaged, blurry reconstructions because MSE penalizes all pixel deviations equally, failing to account for how human vision prioritizes sharp edges and structural coherence 9.
In more advanced iterations of generative architectures, such as those utilized in specialized text-to-image frameworks like Flux or the newer components of the Stable Diffusion 3 family, the VAE channel depth is significantly expanded. For instance, increasing the latent representation from the standard 4 channels to 16 channels vastly improves the preservation of spatial relationships and textural fidelity 78. This larger channel capacity effectively lowers the destructive compression ratio, allowing the decoder to reconstruct highly intricate substructures and distinct, high-frequency patterns 8.
However, this architectural expansion comes at a strict computational cost. A 16-channel VAE produces a much denser latent space, meaning the diffusion model must process four times as much data per generation step compared to a 4-channel architecture. This directly materializes as higher VRAM requirements and longer inference times, forcing developers to carefully balance the trade-off between absolute structural fidelity and consumer-hardware accessibility 810. The inability of older diffusion models to utilize these deeper VAEs stems from the fact that a diffusion network is hardcoded to accept a specific latent dimensionality; upgrading a model like SDXL to a 16-channel VAE would require retraining the entire multi-billion parameter U-Net from scratch 8.
U-Net Backbones and Cross-Attention Constraints
Following VAE compression, the latent representation requires a massive neural backbone to predict and iteratively subtract Gaussian noise. In the first generations of Stable Diffusion (versions 1.4 through 2.1), this backbone was constructed using a convolutional U-Net 1112. Originally developed for medical image segmentation tasks, the U-Net architecture utilizes a series of downsampling convolutional blocks to capture broad, global context, followed by symmetric upsampling blocks. These blocks are connected via skip-connections that ferry high-resolution spatial features across the network, preventing the loss of structural geometry during the downsampling phase 1112.
Convolutional Foundations and Text Conditioning
To condition the image generation process on natural language text, the U-Net relied heavily on cross-attention modules interspersed between the convolutional processing blocks 45. A frozen text encoder - primarily OpenAI's CLIP ViT-L/14 - processed the user's text prompt, translating it into a dense sequence of token embeddings 1314. Inside the cross-attention layer, the visual image latents acted as the "Queries" (Q), while the text token embeddings acted as the "Keys" (K) and "Values" (V) 5. This mathematical matrix multiplication allowed the evolving image to contextually "attend" to specific words in the prompt, guiding the denoising process to form relevant shapes and colors.
Scaling Parameters in High-Resolution Models
As the demand for higher output resolutions and greater prompt adherence grew, the standard U-Net architecture began to encounter severe expressivity constraints. Stability AI addressed this with Stable Diffusion XL (SDXL), which implemented a U-Net backbone significantly larger than its predecessors, expanding the architecture to 3.5 billion parameters 1715. The parameter scaling was heavily weighted toward adding more attention blocks and expanding the cross-attention context window 151617.
To overcome the semantic limitations of a single text encoder, SDXL introduced a dual text-encoder system, utilizing both OpenCLIP-ViT/G and CLIP-ViT/L. The model concatenated their output embeddings to provide a much richer, multi-faceted semantic understanding of the prompt 1819. Furthermore, SDXL incorporated advanced micro-conditioning techniques directly into the training pipeline. The network was fed specific coordinates detailing original image dimensions, crop coordinates, and target aspect ratios during training 151617. This explicitly resolved a persistent phenomenon observed in Stable Diffusion 1.5, where subjects were frequently generated with severed heads or cropped limbs because the network had implicitly learned to replicate the poorly cropped, arbitrary framing of its training data 17.
To achieve its 1024 * 1024 base resolution without collapsing under computational weight, SDXL utilized an ensemble of experts approach. A massive base model generated the initial noisy latents to establish broad composition, which were then handed off and processed by a separate, specialized refinement model. This refiner utilized SDEdit (a stochastic differential image-to-image technique) to execute the final, low-noise denoising steps, vastly improving the clarity of background details and overall visual fidelity 17182021. Despite these extensive advancements, the fundamental architecture - bolting sequential cross-attention layers onto a convolutional image processor - remained computationally inefficient at extreme scales. It persistently struggled with strict spatial reasoning, multi-subject separation, and the accurate rendering of typography 72522.
The Shift to Diffusion Transformers
The systemic limitations of the U-Net backbone catalyzed a critical paradigm shift toward Transformer architectures in generative modeling. Researchers demonstrated that the Vision Transformer (ViT), which had already revolutionized standard image classification tasks, could seamlessly replace the convolutional U-Net in latent diffusion models 112328. The resulting architecture, the Diffusion Transformer (DiT), abandons continuous convolutions and instead treats the compressed latent space as a grid of non-overlapping patches, converting them into a flat sequence of distinct tokens 112324.
Replacing Convolutions with Patch Tokens
By adopting the DiT framework, generative models inherited the highly predictable scaling laws characteristic of Large Language Models (LLMs). Empirical analysis across multiple training runs revealed that scaling the transformer's depth, width, or the number of input tokens (achieved by reducing the physical size of the latent patches) reliably decreased the Fréchet Inception Distance (FID), a standard metric used to evaluate image quality 11232825. This scalability directly and predictably correlated with the model's forward-pass computational complexity, measured in Gflops 112325. The transformer's global receptive field allowed every token to attend to every other token immediately, bypassing the slow, hierarchical receptive field expansion required by deep convolutional networks 11.
Adaptive Layer Normalization and Timestep Conditioning
A critical innovation within the DiT architecture is its method of conditioning the network on the temporal state of the diffusion process. Diffusion models must be acutely aware of the "timestep" - the current noise level - to apply the exact correct magnitude of denoising operations 1124. Instead of relying on simple concatenation or inefficient cross-attention for this temporal data, DiT utilizes Adaptive Layer Normalization (AdaLN), specifically the AdaLN-Zero variant 242526.
In standard Layer Normalization, the scale and shift parameters are learned once during training and remain entirely static during inference 24. In stark contrast, AdaLN dynamically generates these scale and shift parameters on the fly from the timestep embedding and the conditional text vectors via a Multi-Layer Perceptron (MLP) 24. This means the actual normalization behavior of the network fundamentally shifts at every single noise level. Because diffusion noise is applied uniformly across the entire spatial domain of the image, AdaLN acts as an incredibly efficient global modulator. It simultaneously instructs all image patches on whether they should be reconstructing broad, low-frequency structural shapes (at high noise levels) or refining minute, high-frequency semantic textures (at low noise levels) 24. Furthermore, AdaLN-Zero initializes the internal gate parameters exactly to zero, ensuring that the transformer block essentially acts as a harmless identity function at the very start of training, vastly accelerating early optimization and improving overall training stability 2425.
Multimodal Diffusion Transformers
Building upon the success of the DiT foundation, Stability AI introduced the Multimodal Diffusion Transformer (MMDiT) alongside the release of Stable Diffusion 3 (SD3) 1322. The MMDiT architecture targets the central flaw of all previous text-to-image models: the operational assumption that a fixed text representation can be passively fed into an image-processing network via isolated cross-attention layers 1932.
Separating Weight Spaces for Text and Vision
Because language token embeddings and visual latent tokens are conceptually disparate entities, forcing them to interact through identical linear projections destroys modality-specific nuances 22. MMDiT resolves this architectural tension by deploying two entirely separate sets of learned weights - one dedicated exclusively to processing text tokens and one dedicated exclusively to processing image tokens 1322. Functionally, this creates two parallel transformer backbones operating simultaneously 22.
Sequence Concatenation and Joint Attention
The key innovation of MMDiT occurs precisely at the attention mechanism: the sequential matrices of both modalities are concatenated into a single, massive, unified string of tokens 72226. In a standard MMDiT layer, the incoming text tokens pass through a specialized "ContextBlock," while the image tokens pass through a separate "XBlock" 26. Both of these blocks independently apply the AdaLN modulation based on the current timestep 2426. Following normalization, each block independently generates its own Query (Q), Key (K), and Value (V) tensors tailored to its specific modality 26.
Once generated, these QKV tensors are concatenated along the sequence dimension, and a single, shared Joint Attention operation is executed across the entire unified sequence 1926.
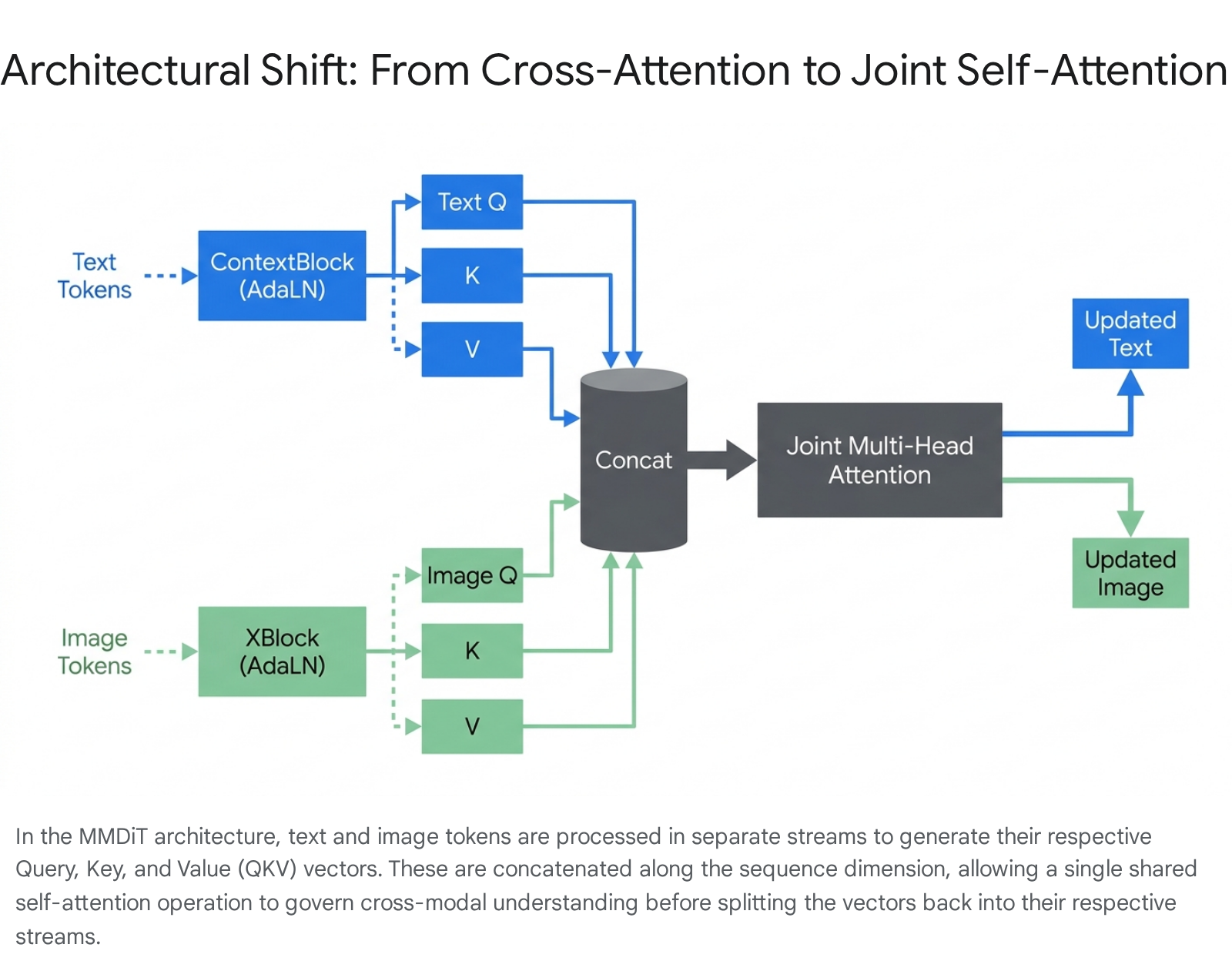
This unified attention allows for profound bidirectional information flow 322728. Image patches can directly attend to specific text tokens to understand their semantic requirements. Crucially, text tokens can also attend to the evolving image representation, allowing the textual context to update dynamically based on the current state of visual synthesis 222728. After the complex attention calculation is complete, the sequence is split back into isolated text and image streams, passing through their respective residual connections and Feedforward Networks (MLPs) 726.
This deep architectural fusion is the primary mathematical reason Stable Diffusion 3 demonstrates vastly superior typography generation and multi-subject prompt adherence. It inherently solves the "concept bleeding" issue - where attributes of one subject erroneously applied to another in older models - by allowing the text to maintain spatial awareness of the image composition throughout every layer of the network 252235.
Triple-Encoder Prompt Pipelines
To provide maximum semantic depth for the joint attention blocks, the SD3 and SD 3.5 architectures utilize a massive ensemble of three distinct text encoders: OpenCLIP-ViT/G, OpenAI's CLIP-ViT/L, and Google's T5-xxl 35293738. The text embeddings generated by the two CLIP models (which have a strict context window of 77 tokens) are concatenated along the channel dimension. This combined CLIP embedding is then concatenated with the highly dense embedding from the T5 model 19.
The inclusion of the 4.7-billion-parameter T5-xxl encoder fundamentally alters the model's capabilities. It extends the functional context window up to 256 tokens, allowing the generative network to parse complex, highly descriptive scene layouts, nuanced spatial relationships, and exact typographic spelling that standard CLIP models typically truncate or compress into vague approximations 133830. However, operating a 4.7B parameter text encoder alongside an 8B parameter diffusion transformer requires immense computational resources. To optimize memory footprint during inference on standard consumer hardware, the architecture is designed so the T5 encoder can be dynamically unloaded or skipped. Testing indicates this results in only a minor measurable reduction in general visual aesthetics, though it induces a substantial drop in strict prompt adherence and typography capabilities, demonstrating the outsized role T5 plays in rigid semantic reasoning 1330.
Rectified Flow Training Framework
Parallel to the shift in neural backbones from U-Nets to Transformers, modern latent diffusion architectures have completely overhauled their foundational training objectives. Earlier iterations of generative models relied strictly on Denoising Diffusion Probabilistic Models (DDPM), which dictate a highly stochastic, Markov chain process to approximate the reverse execution of noise addition over time 1340. DDPMs define a complex, curved Ordinary Differential Equation (ODE) trajectory connecting the random noise distribution to the target data distribution 341.
Stable Diffusion 3 abandons standard DDPMs entirely in favor of Rectified Flow (frequently referred to in literature as Flow Matching) 131927. Rectified flow constitutes a Continuous Normalizing Flow (CNF) that connects the theoretical prior (pure random Gaussian noise) directly to the data (the target image latents) along a mathematically straight line during training 3132842. Instead of learning to predict the specific amount of noise present at a given timestep, the transformer network learns a continuous velocity field that smoothly transports the samples along this linear trajectory from chaos to coherence 34243.
Inference Speed and Trajectory Reweighting
The shift to a rectilinear ODE path has profound, immediate implications for inference speed. Because the model's predicted trajectory (approximating a curvature of $C \approx 1.0$) does not weave stochastically through high-dimensional space, first-order differential equation solvers like Euler's method can take massive integration steps without deviating from the target data distribution 341. This allows Rectified Flow models to generate high-fidelity images in a fraction of the total steps required by DDPMs, where stochastic inefficiency historically necessitated 50 to 100 iterations just to produce coherent shapes 342.
Furthermore, Stability AI introduced a specialized logit-normal timestep sampling schedule during the training of their Rectified Flow models 722. Instead of uniformly sampling points across all noise levels, this technique intentionally and aggressively biases the training computations toward the middle of the trajectory 1322. The mathematical intuition driving this is that the extreme ends of the trajectory (predicting pure noise or reconstructing almost-clean data) are relatively easy tasks for the model. Conversely, the intermediate steps - where broad, low-frequency structures begin to resolve into fine, high-frequency semantic textures - pose the most challenging, error-prone prediction tasks 1322. Reweighting the training objective to focus compute on these perceptually critical transitional scales yields drastic, documented improvements in human-preference evaluations and overall image sharpness 13222728.
Advancements in the Version Three Point Five Models
Despite the theoretical robustness and superior alignment of the MMDiT architecture, scaling the parameter count to 8 billion introduces profound mathematical instabilities during training. The core attention mechanism operates by computing the dot product of massive Query and Key matrices; in exceptionally large models, these dot products can escalate rapidly, causing large magnitude variance, severe loss spikes, feature collapse, and gradients that fail to converge properly 3531.
Query-Key Normalization for Training Stability
To counter this architectural fragility, Stable Diffusion 3.5 systematically integrated Query-Key Normalization (QK-Normalization) directly into the processing pipeline of the transformer blocks 3531454632. By applying LayerNorm or RMSNorm independently to the Query and Key matrices before calculating the final attention scores, the variance is explicitly and mathematically constrained 3148. This architectural intervention prevents extreme attention logits from inappropriately dominating the softmax function 4648.
Beyond merely stabilizing the initial pre-training phase for the developers, QK-Normalization proves absolutely vital for the end-user open-source community. The normalization makes the resulting released model dramatically easier to fine-tune using Low-Rank Adaptations (LoRA) and other specialized techniques, allowing users to inject custom styles or characters without the massive network catastrophically unlearning its foundational spatial representations 314532.
Variant Specifications and Hardware Accessibility
The Stable Diffusion 3.5 family comprises multiple discrete model variants utilizing these parameters to target different hardware tiers and operational requirements.
| Variant Specification | Parameter Count | Core Architecture Focus | Hardware / VRAM Target | Key Use Case |
|---|---|---|---|---|
| SD 3.5 Large | 8.1 Billion | Standard MMDiT + QK-Norm | 24GB+ VRAM (Professional) | 1-Megapixel generation, max prompt adherence 353249. |
| SD 3.5 Large Turbo | 8.1 Billion | Distilled MMDiT (Rectified Flow) | 24GB+ VRAM (Optimized) | Rapid iteration (generates in exactly 4 steps) 3249. |
| SD 3.5 Medium | 2.5 Billion | MMDiT-X (Self-attention shifted) | 9.9GB VRAM (Consumer) | Consumer GPU accessibility, multi-resolution 3233. |
The flagship model, Stable Diffusion 3.5 Large, possesses 8.1 billion parameters optimized explicitly for 1-megapixel base generation, exhibiting market-leading prompt adherence and compositional complexity 353249. To facilitate faster generation workflows, a distilled variant - SD 3.5 Large Turbo - utilizes progressive trajectory distillation on the Rectified Flow paths to achieve competitive, high-fidelity outputs in as few as 4 sampling steps 3249.
Conversely, the SD 3.5 Medium variant strategically scales the backbone down to 2.5 billion parameters 3249. It operates on an adjusted MMDiT-X architecture, which intentionally restricts specific self-attention modules to the first 13 layers of the transformer to enhance overall image coherence while saving compute 3233. The Medium model underwent an exhaustive, progressive mixed-resolution training stage (scaling systematically from 256x256 up to 1440x1440), enabling the final network to generalize robustly across widely varying aspect ratios and detail densities 33. By requiring less than 10 GB of VRAM to operate effectively, the Medium variant preserves the local, open-hardware accessibility that originally defined the Stable Diffusion ecosystem 3248.
Noise Scheduling and Denoising Algorithms
The ultimate generative speed, detail retrieval, and stylistic variance of a latent diffusion model are heavily dictated by the user's choice of sampler - the specific numerical algorithm responsible for mathematically solving the differential equations across the timesteps.
Deterministic and Ancestral Solvers
The simplest available solver is Euler, which strictly applies a first-order linear approximation to subtract the noise difference predicted by the network 51. It is entirely deterministic; passing the exact same initial latent noise seed, prompt, and step count will invariably yield the exact same output image pixel-for-pixel 51.
The ancestral variant, Euler a (Euler Ancestral), behaves completely differently by intentionally over-subtracting noise and mathematically injecting a new, stochastic Gaussian noise distribution at every single step 434. Because the denoising trajectory is actively and randomly perturbed, the final image relies heavily on the unique noise added during the intermediate iterations. Ancestral samplers often produce images that fail to properly "converge" - meaning the image continues to change compositionally even at very high step counts, making them excellent for rapid exploratory generation but exceptionally poor for precise, iterative prompt control 4.
Predictor-Corrector and Higher-Order Methods
More advanced multi-step algorithms, such as DPM++ (Diffusion Probabilistic Models) and UniPC (Unified Predictor-Corrector), leverage deep historical information from previous time steps to drastically improve prediction accuracy 5134. UniPC functions similarly to highly traditional numerical ODE solvers: it executes a rapid prediction step to guess the next latent state, followed immediately by a correction step to mathematically refine the error. This predictor-corrector loop results in high-fidelity image generation in an exceedingly low step count (often converging in just 5-10 steps) 5134.
Denoising Diffusion Implicit Models (DDIM) emerged earlier as a method to vastly accelerate standard DDPMs. DDIM fundamentally reparameterizes the generation as a non-Markovian process, enabling the numerical solver to safely skip large segments of the noise schedule 513435. Rather than iterating through every consecutive micro-step, DDIM approximates the final denoised image at the current step and uses that mathematical projection to guide the long-range transition, ensuring a coherent outcome in 20-30 steps rather than 1000 451.
The choice of sampler profoundly impacts the generation efficiency: first-order samplers (Euler) are exceptionally fast but require the highly straight Rectified Flow paths of modern models to work well; second-order solvers (Heun) are highly accurate but must evaluate the massive neural network twice per step, effectively halving generation speed; while ancestral solvers preserve deep stylistic variance at the cost of stability 51343554.
Anatomical Generation Limitations and Spectral Bias
Despite immense parameter scaling and the shift to Rectified Flows, latent diffusion models occasionally suffer from catastrophic failures in anatomical generation - most notoriously characterized by extra fingers, merged limbs, or fragmented spatial coherence 25. While casual users often attribute this trivially to "poor training data," deep architectural analysis reveals the root cause lies within the model's spectral dynamics and optimization constraints.
Generative Myopia and Frequency Filtering
Research demonstrates that standard diffusion models exhibit a pronounced "spectral bias," intrinsically functioning as mathematical frequency filters 55. The Evidence Lower Bound (ELBO) objective utilized during training inherently optimizes for statistical average-case likelihood 5556. Consequently, the models overwhelmingly prioritize abundant, dense local textures (high-frequency, repeating patterns like fur, scales, or skin pores) over structurally mandatory but statistically rare global topological constraints 55.
This phenomenon, academically termed Generative Myopia, systematically leads to gradient starvation during the reverse diffusion process 5556. When generating a human hand, the network easily and rapidly learns the repetitive texture and localized geometry of a single finger. Because human hands are highly self-similar, the statistical probability of a generic finger texture repeating along a continuous bounding edge is extremely high within the localized patch domain 25.
Optimization Dynamics and Gradient Starvation
However, the strict topological constraint - that a healthy human hand must possess exactly five digits - is a low-frequency, global structure 55. During the forward noising process of training, these rare topological "bridges" are rapidly overwhelmed by Gaussian noise 56. Upon reversal, the optimization landscape inherently suppresses these weak, sparse structural signals in favor of the loud, repetitive texture signals. No matter how large the transformer backbone becomes, without explicit topological guidance or spectrally-weighted diffusion capable of amplifying the gradient of rare structural constraints (items with high Effective Resistance), the model will probabilistically stack repeating local features indefinitely. This mathematical oversight results in the infamous seven-fingered hand, generated not out of ignorance, but out of a statistically optimal application of local textures without global boundary conditions 255556.
Architectural Comparison of Generative Ecosystems
To properly contextualize the open-source Latent Diffusion architecture, it must be evaluated against proprietary ecosystem equivalents, most notably OpenAI's DALL-E 3. While both solve the fundamental text-to-image synthesis problem, their underlying philosophies, architectures, and deployment paradigms differ significantly.
DALL-E 3 largely abandons the pure, raw diffusion pipeline in favor of a heavily Transformer-based framework combined with deep Large Language Model (LLM) infrastructure 5758. A primary advantage of the DALL-E 3 system is its direct, native integration with ChatGPT, which functions as middleware to intercept the user's raw prompt and automatically rewrite it into an exceptionally dense, descriptive caption before synthesis 5759. Because DALL-E 3 was trained predominantly on similarly dense, synthetic captions rather than noisy, user-generated web-scraped alt-text, it exhibits unparalleled prompt adherence and spatial relational accuracy 59. However, this acts as a strict black-box mechanism; the user cannot manipulate the raw latent space, utilize localized structural constraints like ControlNet, or explicitly dictate the iterative noise reduction schedule 5759.
| Feature | Stable Diffusion XL | Stable Diffusion 3.5 Large | DALL-E 3 |
|---|---|---|---|
| Core Architecture | U-Net (2.6B parameters) | MMDiT (8.1B parameters) | Transformer-based Diffusion |
| Latent Compression | 8x VAE (4-channel) | 8x/16x Enhanced Autoencoder | Unknown (Proprietary) |
| Conditioning Mechanism | Cross-Attention Layers | Joint Self-Attention Matrix | Transformer Attention |
| Text Encoders | OpenCLIP-ViT/G + CLIP-ViT/L | OpenCLIP + CLIP-L + T5-xxl | Proprietary LLM Pipeline |
| Training Objective | DDPM (Curved Score Matching) | Rectified Flow (Linear Matching) | Unknown (Proprietary) |
| Base Resolution | 1024 * 1024 | 1 Megapixel (~1024 * 1024) | Variable (up to HD sizes) |
| Ecosystem Strength | Realism, massive LoRA base | Typography, prompt adherence | Zero-shot accuracy, accessibility |
Stable Diffusion models, by strictly operating in an accessible latent space, purposefully sacrifice some immediate, out-of-the-box conceptual fusion in exchange for absolute deterministic control 60. The open-source and open-weight nature of the architecture allows researchers to inject geometric guidance directly into the U-Net or DiT layers, supporting advanced image-to-image workflows, localized inpainting, and precise stylistic fine-tuning 1759.
The entire trajectory of the Stable Diffusion architecture - evolving from computationally bound pixel DDPMs to efficient latent U-Nets, and ultimately arriving at the QK-Normalized Multimodal Diffusion Transformers optimized via Rectified Flow - represents a comprehensive scaling of generative AI capabilities. By fusing the spatial processing of visual image tokens with the semantic depth of massive language models directly within a unified self-attention matrix, the architecture has mathematically resolved historical bottlenecks in typography, prompt adherence, and multi-subject composition, firmly paving the way for the next iteration of visual synthesis 2192235.