Language acquisition in humans and large language models
The rapid evolution of Large Language Models (LLMs) has catalyzed a profound paradigm shift within the cognitive and computational sciences. Systems trained on astronomical datasets using self-supervised objectives generate text with a structural coherence that mimics human fluency, prompting urgent questions regarding the cognitive plausibility of artificial neural networks as models of the human mind. However, equating computational linguistic proficiency with human biological language acquisition requires rigorous scrutiny. By synthesizing recent literature from developmental psychology, cognitive science, and natural language processing published predominantly between 2023 and 2026, this comprehensive report provides an exhaustive examination of the divergent mechanisms underpinning human language acquisition and LLM statistical learning. The ensuing analysis explores the profound discrepancies in input scale, the critical role of embodied and social grounding, cross-linguistic variations in morphosyntactic development, the results of human-scale training initiatives like the BabyLM Challenge, and the enduring, shifting debate surrounding Noam Chomsky's Poverty of the Stimulus argument.
The Data Efficiency Divide: Scale, Grounding, and Corrective Feedback
The most conspicuous divergence between human language acquisition and modern artificial intelligence lies in the sheer volume and nature of the linguistic data required to achieve competence. The scale at which biological organisms and computational models process information reveals fundamentally different learning architectures, raising questions about whether LLMs can be considered cognitively plausible models of human learning.
Human children are extraordinarily data-efficient learners. Estimates derived from extensive observational studies indicate that a child in a high-socioeconomic status household hears approximately 30 to 50 million words by age five 12. Even stretching the developmental window to early adolescence (age 13), the total linguistic exposure is estimated to remain under 100 million words 34. In stark contrast, modern commercial LLMs rely on datasets that are larger by multiple orders of magnitude. For instance, models such as GPT-4 are trained on an estimated 5 trillion words (6.5 trillion tokens), while LLaMA 3 utilizes upwards of 11 trillion words (15 trillion tokens) 1.
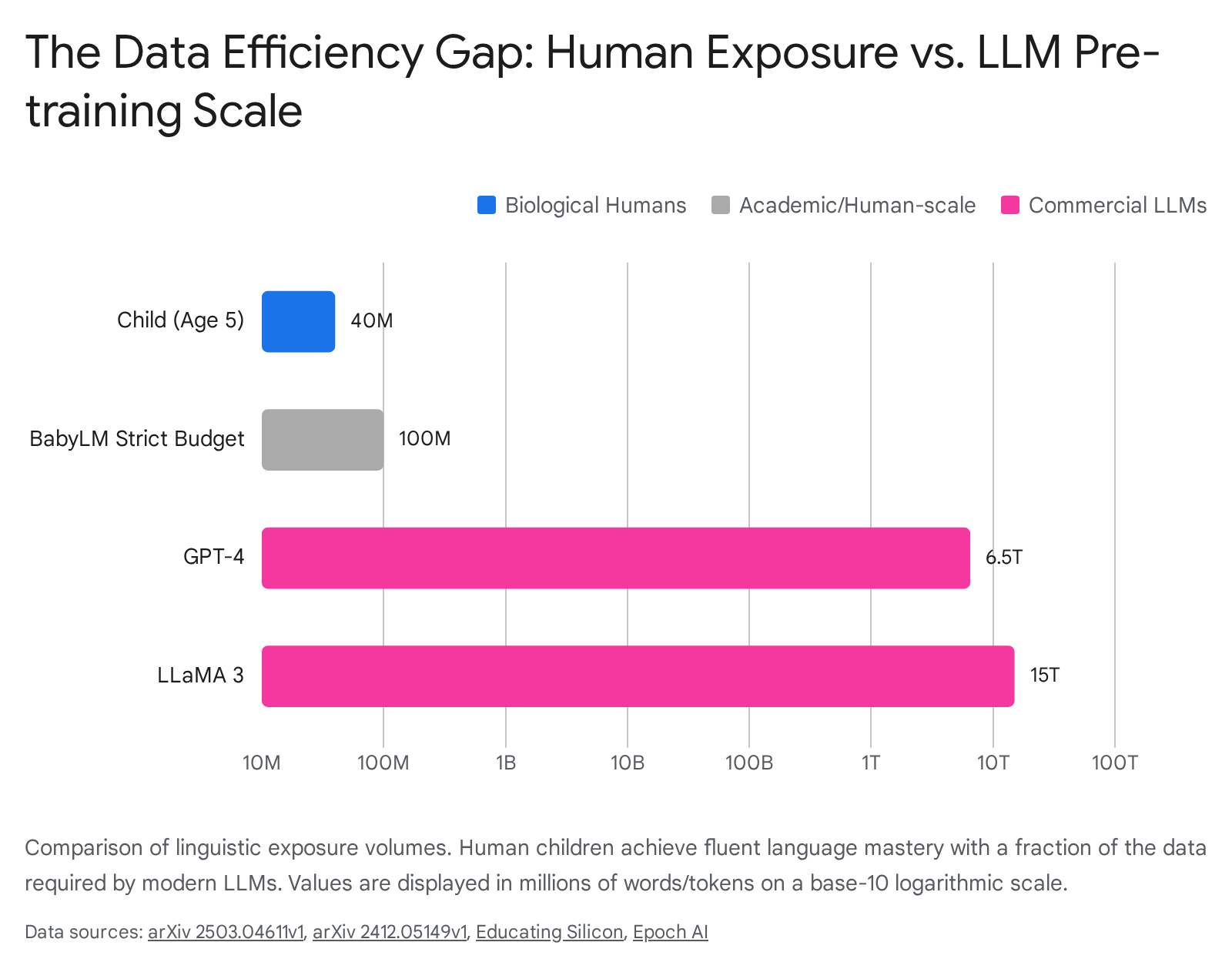
Recent analyses by Epoch AI indicate that the size of datasets used to train language models doubles approximately every six months, with the total stock of high-quality web text currently estimated at 45 to 120 trillion words 14. If a human child were to process language at the rate required to consume the training data of an LLM like ChatGPT, it would take approximately 92,000 years of continuous exposure 5.
Beyond scale, the nature of the input diverges fundamentally. Human infants acquire language within a rich, embodied, and highly situated context. Caregivers employ child-directed speech (often termed "parentese"), characterized by exaggerated prosody, simplified syntax, and immediate relevance to the child's physical environment 679. As the child's linguistic fluency increases, adults naturally and instinctively tune their sentence structure and complexity, analogous to a curriculum that scales in difficulty 7. This input is accompanied by coordinated multisensory cues - visual, auditory, tactile, and olfactory - providing a deeply grounded semantic framework 5. Conversely, LLM training data is essentially disembodied, drawn from vast repositories of static, context-stripped text such as Common Crawl, digital books, academic publications, and scraped social media archives 14.
Furthermore, the mechanisms of error correction and feedback differ entirely. Human language acquisition relies heavily on implicit communicative feedback. Caregivers naturally provide corrective recasts - repeating a child's ungrammatical utterance with the correct syntactic structure - which serve as a form of semantic and structural priming without halting the flow of conversation 811. While the exact developmental necessity of negative feedback remains debated among linguists, experimental data confirms that children are highly responsive to recasts, using them to refine grammatical boundaries. For instance, studies have shown that 23-month-old children are significantly more likely to imitate grammatical morphemes contained in a corrective recast than identical information contained in positive evidence alone 8119.
In contrast, LLMs achieve alignment through explicit, highly engineered mathematical processes such as Reinforcement Learning from Human Feedback (RLHF) or Direct Preference Optimization (DPO). RLHF operates by training a secondary reward model based on human preference rankings of multiple generated outputs, which is then used to optimize the primary model via reinforcement learning 10151617. Recent advancements in RLHF, such as Reinforcement Learning from AI Feedback (RLAIF) and Truncated Preference Data (optimizing based on the first 40-50% of generated tokens), aim to improve data efficiency, but they remain fundamentally distinct from biological communication 1617. RLHF does not mirror biological communicative negotiation or mutual understanding; rather, it is a high-dimensional mathematical alignment to aggregate human preferences for harmlessness and helpfulness, optimizing a policy against a reward model 101112.
| Feature | Human Child Language Acquisition | Modern LLM Pre-Training Data |
|---|---|---|
| Scale (Data Volume) | Highly efficient. Acquires fluent grammar from ~30-50 million words by age 5, and ~100 million words by age 13 1234. | Highly inefficient. Requires astronomical datasets, typically ranging from 1 to 15 trillion tokens (e.g., GPT-4, LLaMA 3) 14. |
| Grounding (Nature of Input) | Situated, embodied, and multi-modal. Input is dominated by child-directed speech mapped to physical objects, sensory experiences, and real-time events 57. | Disembodied and static. Input consists purely of scraped, monolingual or multilingual text data devoid of physical or temporal context 1420. |
| Feedback Mechanisms | Implicit and conversational. Caregivers utilize corrective recasts, joint attention, and semantic negotiation to naturally shape grammatical boundaries 8119. | Explicit mathematical optimization. Relies on Reinforcement Learning from Human Feedback (RLHF), ranking output variations to optimize a reward model 10161711. |
Embodiment, Joint Attention, and the Social Gating Hypothesis
The efficiency of human language acquisition cannot be explained purely by the statistical processing of linguistic exposure; it is fundamentally catalyzed by the social environment and embodied grounding. The "Social Gating Hypothesis," pioneered by researchers such as Patricia Kuhl, posits that the earliest phases of language acquisition - specifically the transition from universal phonetic sensitivity to language-specific processing - are biologically gated by social interaction 9132223. According to this framework, the infant brain requires the presence of a live, interactive human being to optimally process and encode phonetic and syntactic information. Experimental data demonstrates that infants exposed to new linguistic material via live social interaction show profound neuro-linguistic adaptation, whereas infants exposed to the exact same acoustic material via non-interactive video or audio recordings show virtually no learning 132223.
Central to social gating is the mechanism of "joint attention" - the ability of two individuals to share focus on a common object or event for social purposes 14152616. Emerging around 12 months of age, joint attention acts as a powerful disambiguation tool. When a caregiver and a child simultaneously look at an object while the caregiver names it or describes its action, the infinite hypothesis space of what the word could mean is instantaneously narrowed 142616.
Recent neuroimaging research provides compelling biological evidence for this phenomenon. Magnetoencephalography (MEG) studies tracking 5-month-old infants reveal that neural activity in attention-centric brain regions spikes significantly during social play with adults. Crucially, the magnitude of this specific neural activation heavily predicts productive vocabulary and syntax generation by the time the child reaches 18 to 30 months of age 6. Furthermore, in clinical populations, such as children with Autism Spectrum Disorder (ASD), deficits in joint attention are deeply correlated with delays in both syntactic and semantic development, proving that social engagement is a foundational pillar of language architecture 141526. In infants, joint attention provides essential contextual cues that drive motivation and disambiguate meaning, resembling a natural learning situation that text alone cannot replicate 16.
Artificial intelligence models, particularly text-only LLMs, inherently lack this socio-embodied gateway. LLMs process language as a closed, self-referential system of symbol manipulation 1628. Because an LLM does not possess a physical body, visual fields, or social drives, it cannot utilize joint attention to map a newly encountered noun to a physical referent in three-dimensional space. AI models circumvent the need for social gating through brute-force statistical aggregation - learning the distributional semantics of words entirely by analyzing trillions of co-occurrence patterns across documents 51730. While this approach successfully produces human-interpretable text strings, the absence of social gating highlights a critical evolutionary divergence: biological brains utilize social and physical embodiment as an optimization shortcut, drastically reducing the total data required to infer grammatical rules.
Breaking the English-Centric Bias: Cross-Linguistic Grammar Acquisition
Much of the discourse comparing AI language learning to human ontogeny suffers from a severe English-centric bias. English is an analytic language, relying heavily on rigid word order (Subject-Verb-Object) and free-standing morphemes 1819. Assessing a computational model's ability to learn English syntax often masks its deficiencies in grasping true morphological productivity. To evaluate whether humans and machines acquire grammar at comparable speeds and via comparable mechanisms, it is essential to examine morphologically rich, non-English languages across diverse typologies.
Agglutinative languages, such as Turkish and Finnish, construct meaning by sequentially attaching multiple specific suffixes to a root word. Turkish, for example, is a highly regular Subject-Object-Verb (SOV) language characterized by rich inflectional suffixes, where each suffix typically encodes a single semantic dimension (such as plural, possessive, or dative case) 33202122. A single Turkish word can encapsulate what would require an entire sentence in English, complete with tense, modality, plurality, and case markings, all subjected to strict morphophonological constraints like vowel harmony 332022.
Despite this staggering structural complexity, Turkish children demonstrate remarkable acquisition speeds. Research shows that by age three, and often as early as 24 months, typically developing Turkish children produce both nominal and verbal suffixes in obligatory contexts with virtually zero errors 2338. They seamlessly master complex derivations such as the causative and aorist markers. For example, computational models tracking the acquisition of the Turkish aorist case indicate that while children initially rely on lexical frequency, they rapidly generalize abstract morphophonological rules 2024. Cross-linguistic behavioral studies also note that children with Developmental Language Disorder (DLD) learning Turkish show distinct error patterns, primarily struggling with nominal case suffixes rather than verbs, demonstrating how the specific typological structure of a language influences cognitive processing costs 222325.
Similarly, studies on Inuktitut - a polysynthetic, morphologically ergative language spoken in northern Canada - reveal that children begin generating novel, complex determiner-noun combinations and incorporating diverse speech acts by 30 months of age 1826. In these languages, word-internal syntax is far more complex than word-external syntax, yet biological learners parse and construct these highly inflected forms rapidly, demonstrating a general cognitive capacity to extract structural rules regardless of the language's specific typological complexity 1827.
Conversely, Large Language Models struggle significantly with highly agglutinative and polysynthetic languages, particularly in low-resource settings. The challenge stems deeply from modern tokenization algorithms, such as Byte Pair Encoding (BPE) or WordPiece. BPE fragments words based on statistical character frequency rather than genuine linguistic morphology 319. For a morphologically rich language like Turkish, a single word is often arbitrarily shattered into sub-tokens that do not align with its actual root and affixes 1921. Consequently, the LLM is forced to rely on massive memorization of sub-word sequences rather than learning the underlying generative morphological rules 2128.
Tests applying multilingual versions of the "Wug Test" (an artificial word completion experiment used to test morphological knowledge) to LLMs across multiple languages indicate that an AI's ability to generate correct morphological structures is negatively predicted by the language's integrative complexity 28. While humans rapidly abstract morphological rules in languages like Turkish or Finnish through exposure to just a few million words, AI models face an exponential increase in computational difficulty when dealing with agglutinative structures, thereby debunking the notion that machines acquire linguistic architecture as efficiently as humans do.
Developmental Plausibility in AI: The 2024 BabyLM Challenge
Recognizing the biological implausibility of trillion-token datasets, the computational linguistics and cognitive science communities initiated the BabyLM Challenge. This rigorous academic initiative restricts the training data for neural language models to a developmentally plausible volume, directly targeting the data-efficiency gap between human and computational learners 329.
The 2024 iteration of the BabyLM Challenge required participants to optimize language model training on specific data budgets: a "Strict" track limited to 100 million words, and a "Strict-Small" track limited to just 10 million words, roughly mirroring the linguistic input a human child receives prior to adolescence and early childhood, respectively 345. To improve developmental realism, the 2024 organizers updated the corpus so that 70% of the training data consisted of child-oriented texts - such as transcribed adult-child interactions from the CHILDES database, children's stories, and simplified educational materials - a significant increase from the 39% utilized in the previous year 345. Furthermore, the challenge incorporated a Multimodal track, augmenting 50 million text tokens with 50 million image-text pairs (such as Localized Narratives and Conceptual Captions) to explicitly test the hypothesis that visual grounding accelerates grammatical induction 330.
The outcomes and methodologies of the 31 submissions to the 2024 BabyLM Challenge yield critical deductions regarding the intersection of artificial intelligence and cognitive science:
- Architectural Innovations Trump Curriculum Learning: The winning models across both the Strict and Strict-Small tracks utilized hybrid architectures, notably GPT-BERT 330. This specific model seamlessly merged causal language modeling (predicting the next token, typical of GPT models) with masked language modeling (filling in a blank, typical of BERT), allowing the model to mix bidirectional and unidirectional context processing during training 345. Interestingly, attempts to mimic biological "curriculum learning" - the process of feeding a model simple, short sentences before gradually advancing to complex syntax, simulating a child's developmental progression - were popular among participants but largely failed to yield higher performance scores compared to standard, randomized training regimens 347.
- The Failure of Naive Multimodality: In the Multimodal track, no submitted model managed to outperform the established baseline architectures (GIT and Flamingo) 3. Despite the cognitive science consensus that visual grounding aids word learning in humans, effectively integrating visual data into LLMs proved exceedingly difficult in low-resource settings. Models exhibited a strong tendency to learn "unimodal shortcuts" - relying almost entirely on text statistics while ignoring the visual data, rather than forming a cohesive, cross-modal semantic understanding 3. This underscores the reality that merely pairing flat images with text in a dataset does not successfully simulate the rich, embodied sensorimotor grounding experienced by a human toddler.
- The Persistent Compute-Data Correlation: Even when the data volume is artificially restricted to human scales, researchers found a strong relationship between total training FLOPs (Floating Point Operations Per Second) and average downstream performance 330. AI systems still require vast amounts of compute and repeated algorithmic passes over the same small dataset to approximate human-like grammar, highlighting a persistent disparity in algorithmic versus biological efficiency 347.
- Data Contamination and Quality over Quantity: When participants attempted to augment the 10-million-word dataset with generic, adult-centric LLM training data like MADLAD-400, performance on syntactic benchmarks actually degraded 2029. Conversely, models trained on "variation sets" - consecutive rephrasings of the same sentence, which are highly common in natural child-directed speech - showed marked improvements 3. This suggests that the structure and quality of child-directed input are vital for data-efficient learning.
Theoretical Paradigms: Nativism, Usage-Based, and LLM Statistics
The enduring debate over how language is acquired has historically been dominated by two fiercely contrasting paradigms: Nativist theories and Usage-Based theories. The emergence of LLMs introduces a third computational vector - pure statistical learning over massive corpora - which simultaneously challenges and borrows from classic paradigms, forcing a re-evaluation of long-held assumptions.
Nativist theories, famously championed by Noam Chomsky, argue for an innate, domain-specific biological endowment often referred to as Universal Grammar (UG). Nativism asserts that the human brain contains a specialized modular "language faculty" pre-wired with abstract syntactic principles and parameters 313233. According to this view, syntax is fundamentally distinct from semantics; syntactic structures can be produced independently of meaning. Nativists argue that children acquire language rapidly because they are not learning from scratch; they are simply setting parameters triggered by environmental input, utilizing symbolic rules that generate infinite expressions 313351.
Conversely, Usage-Based theories, pioneered by scholars like Michael Tomasello, Adele Goldberg, and Nick Ellis, reject the notion of innate grammar modules. Instead, they propose that language acquisition relies entirely on domain-general cognitive mechanisms - such as pattern recognition, joint attention, categorization, rich memory, and chunking 1732343536. In this framework, children build grammatical structures bottom-up by generalizing from highly frequent, item-based constructions (e.g., "Where is the [X]?") they encounter in social interactions 1734. Usage-based theory posits that form and function are inseparable; syntax emerges from the semantic and pragmatic necessity of communication 323435. Furthermore, usage-based theorists emphasize that linguistic input follows a Zipfian distribution, allowing robust induction of rules through statistical learning over limited samples 35.
LLM Statistical Learning (often referred to as Modern Associationism) operates via deep neural networks utilizing self-attention mechanisms over massive datasets 3155. Unlike Nativism, LLMs do not possess innate symbolic rules, nor do they rely on modular architectures separating syntax from semantics. Instead, syntax and semantics are entangled within attention layers; the model maps queries to a high-dimensional latent space to find relevant structures 31. However, unlike human Usage-based learning, LLMs lack social intentionality, pragmatics, and sensorimotor cognition 323456. They represent a highly advanced form of associationism, where compositionality, systematicity, and the handling of long-distance dependencies emerge purely as a byproduct of computing conditional probabilities across billions of parameters 3155.
| Theoretical Paradigm | Core Mechanism of Acquisition | Role of Syntax vs. Semantics | Perspective on Speed of Learning |
|---|---|---|---|
| Nativist Theories (Chomsky) | Innate, domain-specific "Universal Grammar." Language is generated via symbolic, hierarchical rules operating within a modular mind 313233. | Syntax is an independent module, fully separable from semantics and real-world meaning 3133. | Extremely fast ("one shot"). Children use innate constraints to rapidly map minimal input ("Poverty of the Stimulus") 313351. |
| Usage-Based Theories (Tomasello/Ellis) | Domain-general cognitive skills (chunking, analogy, categorization) applied to social and communicative interactions 17323536. | Form and function are inseparable. Complex grammar emerges organically from semantic and pragmatic use over time 323435. | Gradual and input-dependent. Speed is driven by the Zipfian frequency of constructions in child-directed speech 173536. |
| LLM Statistical Learning (Associationism) | Self-supervised learning (next-token prediction) computing conditional probabilities across high-dimensional vector spaces 313455. | Syntax and semantics are combined without separate modules; structural rules are emergent, not hard-coded 3155. | Highly inefficient algorithmically. Achieves fast "one-shot" inference post-training, but requires trillions of tokens to abstract rules initially 12031. |
The Poverty of the Stimulus: Has the Consensus Shifted?
For over fifty years, the most formidable pillar of Nativist theory has been the "Poverty of the Stimulus" (PoS) argument. This hypothesis asserts that the linguistic data available to a child is far too sparse, noisy, and devoid of explicit negative evidence to allow a purely inductive, associationist learner to infer the complex, hierarchical rules of natural language 33373839. For instance, humans instinctively recognize constraints on wh-movement or structure dependence in questions without ever being explicitly taught them 3338. Therefore, Nativists argue, children must possess innate, a priori structural constraints.
The empirical success of modern LLMs - which learn to generate perfectly structured, hierarchical sentences after being trained purely on linear strings of text without innate symbolic rules - has ignited fierce debate regarding the validity of the PoS argument. Proponents of LLM cognitive plausibility, such as Piantadosi and Wilcox, argue that if a neural network can master complex syntax through exposure alone, then the PoS argument is fundamentally debunked. They posit that linguistically-neutral networks can acquire adequate knowledge of structures like wh-movement, proving that statistical learning over unannotated corpora is sufficient 563740.
However, comprehensive meta-analyses and systematic reviews in the cognitive sciences published between 2024 and 2026 reveal that the consensus has not definitively shifted in favor of empiricist machine learning debunking Chomsky. While LLMs demonstrate that statistical algorithms can approximate hierarchical syntax, cognitive scientists point out severe caveats that preserve the PoS argument in biological contexts 5639614142.
First, the argument regarding the scale of data is paramount. LLMs are trained on trillions of words, effectively transforming a "poor stimulus" into an omniscient stimulus 563940. This massive exposure violates the core premise of the PoS, which focuses on the sparse data environment of human children. When researchers restrict modern LLMs to developmentally plausible datasets (the true condition of the PoS, such as the BabyLM corpora), they routinely fail to acquire complex, long-distance hierarchical dependencies, such as parasitic gaps and across-the-board movement 5637.
Second, extensive evaluations on minimal-pair syntactic tests reveal that LLMs, despite vast training, occasionally fail to identify grammatical errors consistently. They often rely on surface-level linear heuristics rather than robust structural parsing, failing to capture the true depth of human syntactic competence 215140.
Consequently, the current scientific consensus is highly nuanced: LLMs have successfully proven that given essentially infinite data, pure statistical associationism can emulate complex grammar 563740. However, because human children achieve superior grammatical abstraction with a minuscule fraction of that data, the biological reality of the Poverty of the Stimulus remains largely unchallenged. The debate has shifted from whether statistical learning is possible, to whether LLM statistical learning is biologically plausible 56373941. Many cognitive scientists now adopt a "Proxy View," suggesting that while LLMs themselves are not accurate models of human cognition, they serve as useful proxies to reason about the information available in input data and the limits of linguistically neutral learning 5637.
Debunking the Next-Token Prediction Fallacy
As LLMs seamlessly mimic human conversational capabilities, pass standardized tests, and write coherent essays, a dangerous and reductionist misconception has proliferated: the assumption that the mechanistic objective of "next-token prediction" maps neatly to, or serves as an accurate proxy for, human cognitive processing 123055.
At a fundamental algorithmic level, a decoder-only LLM processes an input sequence, routes it through layers of self-attention, and computes a probability distribution to output the statistically likeliest subsequent token 5556. Prominent figures in the AI community have argued that successful token prediction across highly complex narratives necessitates an emergent "understanding" or "reasoning" about the real world 306443. They argue that to accurately predict the final word in a detective novel, the model must possess an internal world model and reasoning capability 64.
However, cognitive scientists and philosophers firmly demarcate this as statistical structural mimicry rather than grounded semantics or true biological cognition 304366. The fallacy lies in conflating predictive likelihood with epistemological truth, intentionality, and semantic grounding 5643.
Human cognition is inherently teleological - it is driven by internal states, biological imperatives, and the physical constraints of reality. When a human speaks, language is deployed as an instrument to alter the environment, driven by valenced experiential states (e.g., desires, fears, homeostasis, goals) 3066. Conversely, an LLM possesses no valenced states; it is not alive. It does not "care" about its output, its survival, or the factual accuracy of its generation, beyond the mathematical optimization of its cross-entropy loss function 4366. LLMs may adopt "personas" during RLHF fine-tuning - stating they are "helpful assistants" or feigning emotions - but this is highly sophisticated role-play driven by prompt engineering and training constraints, not genuine sentience 123066.
Furthermore, human language is strictly tethered to the physical world via Harnad's Symbol Grounding Problem 42. When a child uses the word "apple," the linguistic symbol is intricately linked to the visual, tactile, and gustatory properties of the fruit. When an LLM predicts the token "apple," it is linking a high-dimensional vector solely to other vectors (e.g., "red," "fruit," "tree") within a closed mathematical universe 5542.
The limitations of next-token prediction become glaringly obvious when analyzing LLM hallucinations. An LLM can flawlessly simulate logical deductions - such as outputting the conclusion of a modus ponens argument - because that exact logical structure appeared millions of times in its training data 43. However, when confronted with novel logical paths requiring genuine causal inference, or when asked to reason about physical spatial dynamics not explicitly mapped in its latent space, the model will hallucinate confidently 4243.
This distinction can be understood through David Marr's levels of analysis in cognitive science: the computational level (the goal), the algorithmic level (the method), and the implementational level (the physical substrate) 12. The fact that we can describe LLMs at the computational level as "next-token predictors" does not mean they share the psychological or biological natural kind present in human beliefs and desires 12. Therefore, characterizing next-token prediction as a mirror for human biological cognition commits a fundamental category error, mistaking the statistical simulation of an output for the replication of an intentional, grounded cognitive process.
Conclusion
The advent of Large Language Models has undeniably provided cognitive scientists and linguists with powerful, stimulus-computable tools to test long-standing hypotheses regarding the limits of statistical learning, representation, and the emergence of syntax 41. However, as this exhaustive analysis demonstrates, the gap between artificial and biological language acquisition remains vast. Human children are not mere statistical engines computing token probabilities; they are biologically predisposed, socially gated learners embedded in a physical world. They extract complex, cross-linguistic morphosyntactic rules from highly restricted, developmentally appropriate, multimodal datasets, aided immensely by joint attention and implicit interpersonal feedback.
LLMs, conversely, rely on disembodied, text-only universes, requiring astronomically large datasets to brute-force the illusion of structural competence. Initiatives like the BabyLM Challenge underscore that when artificial models are restricted to human-scale data, their architectural limitations become highly apparent. While the engineering triumph of next-token prediction coupled with RLHF is profound, ensuring a clear epistemological boundary between statistical mimicry and grounded human cognition is imperative for the rigorous future of both artificial intelligence and developmental psychology.