Knowledge Distillation for Small AI Models
Knowledge distillation represents a pivotal methodology in artificial intelligence, addressing the fundamental tension between the increasing computational demands of frontier large language models (LLMs) and the strict resource constraints of real-world deployment environments. As deep learning architectures scale to trillions of parameters, their utility in edge devices, real-time applications, and cost-sensitive enterprise pipelines becomes highly restricted 12. Knowledge distillation operates as a sophisticated compression and transfer learning paradigm wherein the behavior, feature representations, and reasoning capacities of a massive, highly capable "teacher" model are mathematically transferred to a significantly smaller, efficient "student" model 134.
The concept extends far beyond mere file compression; it is an epistemological mechanism by which an over-parameterized neural network, having mapped the complexities of vast training corpora, acts as an algorithmic pedagogue. This process democratizes access to state-of-the-art natural language processing (NLP) and reasoning capabilities, enabling local execution on consumer hardware, reducing carbon footprints, and lowering inference latency 567.
Fundamental Mechanisms of Knowledge Transfer
The conceptual origin of transferring knowledge between neural networks dates back to model compression research by Rich Caruana in 2006, but the modern paradigm of knowledge distillation was formalized by Geoffrey Hinton, Oriol Vinyals, and Jeff Dean in 2015 489. The core premise is that large, over-parameterized models, or ensembles of models, learn complex generalizations that are not strictly necessary for final representation, but are essential for the optimization and feature discovery phases of training 810. Once these robust generalizations are learned, they can be taught directly to a much smaller model.
Soft Targets and Dark Knowledge
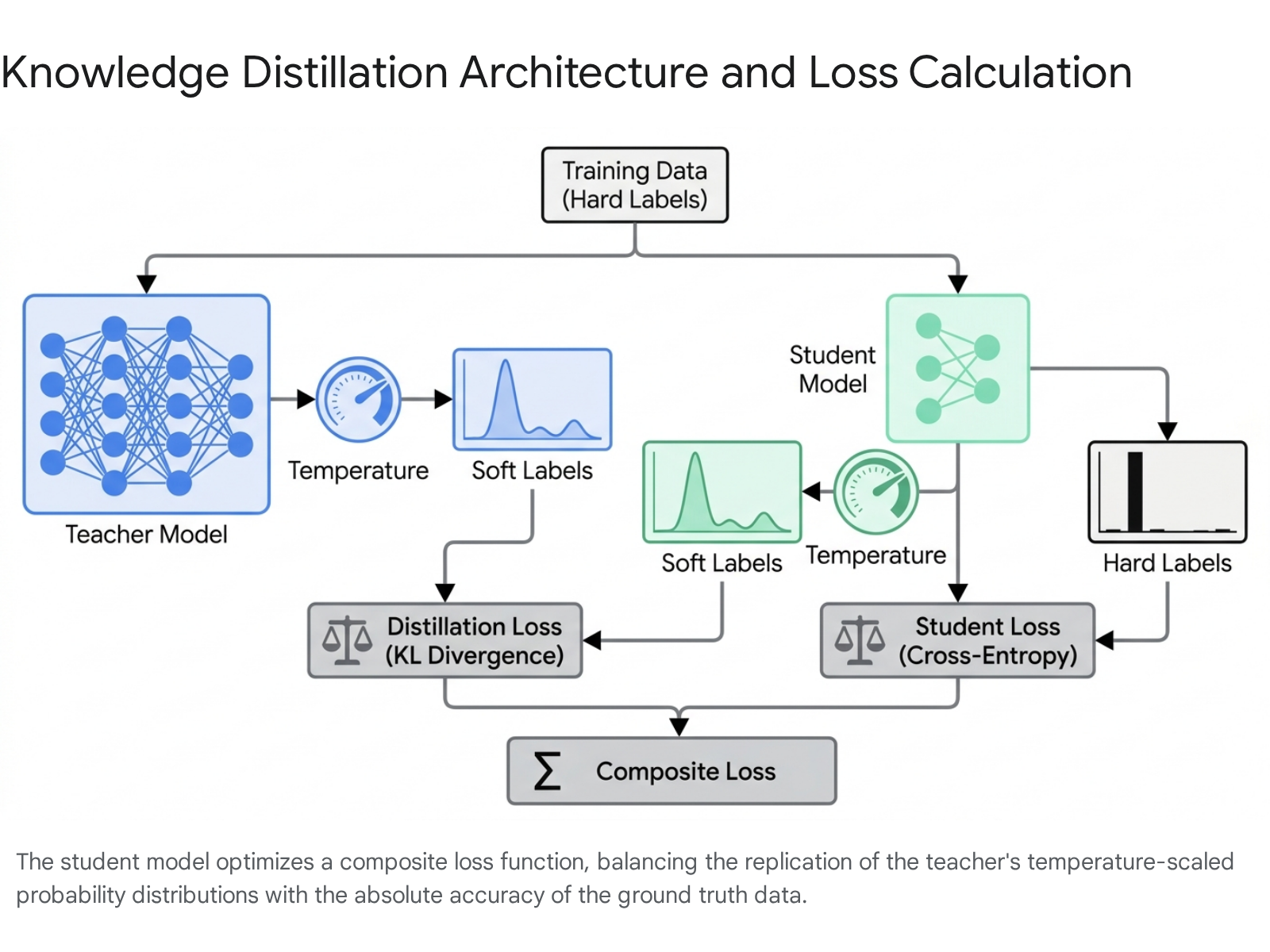
In standard supervised machine learning, models are trained on "hard targets," which are typically one-hot encoded vectors where the correct class is assigned a probability of 1 and all incorrect classes are assigned a 0. However, a well-trained teacher model outputs "soft targets" - a continuous probability distribution across all possible classes 48. These soft labels contain what researchers term "dark knowledge."
For example, an image classification model might predict a 95% probability that an image contains a cat, a 3% probability it is a leopard, and a 1% probability it is a dog 9. The non-zero probabilities assigned to incorrect classes reveal the teacher's internal understanding of semantic similarity, structural relationships, and feature overlap. By forcing the student model to learn this nuanced probability distribution rather than just the absolute right answer, the student absorbs the teacher's generalized logic 9.
Mathematical Formulation and Temperature Scaling
To effectively extract this knowledge, distillation modifies the softmax activation function used in the output layer of the neural network. The standard softmax calculates the probability $p_i$ of a class $z_i$ as:
$$p_i = \frac{\exp(z_i)}{\sum_j \exp(z_j)}$$
Knowledge distillation introduces a scalar hyperparameter called "temperature" ($T$). Both the teacher and the student apply this temperature to their pre-softmax logits during the distillation training phase:
$$p_i = \frac{\exp(z_i / T)}{\sum_j \exp(z_j / T)}$$
Applying a higher temperature ($T > 1$) forces the resulting distribution to become softer and more uniform 8. This amplification elevates the probabilities of near-zero classes, preventing them from being mathematically ignored and forcing the student model to learn the structural relationships between unlikely output categories 8. The student is then trained using a composite, multi-term loss function. This function typically calculates a weighted combination of the Kullback-Leibler (KL) divergence between the student's and teacher's temperature-scaled soft predictions, alongside the standard cross-entropy loss calculated against the ground-truth hard labels without temperature scaling 914.
Synergies With Hardware and Model Compression
Knowledge distillation is rarely deployed in commercial isolation. To achieve maximal efficiency for edge inference and IoT applications, distillation forms the architectural backbone of a broader, synergistic model optimization strategy that includes quantization and pruning 210. While distillation targets the transfer of algorithmic logic and behavior, quantization and pruning strictly target the physical storage and computational mechanisms of the artificial neural network 210.
Quantization Methodologies
Quantization shrinks the numerical precision of a model's weights and internal activations 310. Default deep learning architectures typically represent parameters using 32-bit floating-point numbers (FP32). Quantization algorithms mathematically map these values to lower-precision formats, such as 16-bit floating-point (FP16), 8-bit integers (INT8), or lower 210. This reduction logarithmically shrinks the model's physical memory footprint on the hard disk and substantially accelerates tensor multiplication operations, particularly when executing on specialized hardware accelerators like INT8-capable GPUs or mobile Neural Processing Units (NPUs) 310.
Quantization application generally takes two dominant forms in the industry: Post-Training Quantization (PTQ) and Quantization-Aware Training (QAT). PTQ applies scale and zero-point mapping functions to a model that is already fully trained. While PTQ is computationally inexpensive and fast to apply, it can introduce severe rounding errors that degrade predictive performance 2. QAT addresses this by simulating these low-precision rounding errors during the active training phase itself. By forcing the network to adjust its weights dynamically to account for the lowered precision before training concludes, QAT results in significantly higher fidelity and robustness upon deployment 211.
Structural and Magnitude-Based Pruning
Pruning aims to identify and systematically remove redundant, dormant, or non-contributing parameters within the neural network 2310. Magnitude-based pruning is the most ubiquitous approach; it evaluates the absolute numerical value of individual weights and severs connections that fall below a predefined threshold, operating on the assumption that near-zero weights exert minimal impact on the final output matrix 10.
Engineers categorize pruning into unstructured and structured methods. Unstructured pruning removes individual weights indiscriminately, creating highly sparse matrices. While theoretically efficient in reducing operations, standard hardware processors (like consumer CPUs and GPUs) struggle to process irregular sparse matrices efficiently without highly specialized computational kernels 1011. Structured pruning, conversely, targets entire architectural components - such as specific neurons, individual attention heads, or even entire transformer layers (depth-pruning). This results in a denser, hardware-friendly model architecture that natively executes faster and draws less power on standard commercial processors 210.
Joint Optimization Pipelines
The most performant lightweight models are created through unified pipelines that execute these techniques concurrently. Frameworks such as the Joint Pruning, Quantization, and Distillation (JPQD) approach, utilized within the OpenVINO Neural Network Compression Framework, optimize the transformer model simultaneously 211. In this sequence, a large teacher is first structurally pruned to remove architectural bloat. The now-sparse teacher is then utilized to distill its knowledge into a specialized student model. Finally, the student model undergoes Quantization-Aware Training (QAT) to map its remaining operations to low-precision hardware instructions 211. This multiplicative, parallel optimization approach recovers the accuracy lost during pruning and quantization far more effectively than isolated, sequential fine-tuning 211.
Systems Engineering and Distributed Training Bottlenecks
Moving knowledge distillation for large language models from theoretical frameworks to production-scale infrastructure reveals massive systems-level bottlenecks. When distilling frontier LLMs comprising hundreds of billions of parameters, the primary constraints immediately shift from pure model architecture to the limitations of distributed computing networks and data transfer protocols 17.
Architectural Mismatch and Compute Profiles
A frequent and catastrophic architectural error in modern distillation pipelines involves attempting to execute both the massive teacher and the learning student model on a homogeneous computing backend 17. The computational workload profiles of the two models are diametrically opposed.
The teacher model requires high-throughput forward inference. It is heavily memory-bandwidth bound and is highly reliant on maximizing large Key-Value (KV) caches and leveraging specialized inference kernels like vLLM or TensorRT-LLM to generate tokens rapidly 17. Conversely, the student model requires high-throughput backward passes to update its weights during training. The student is heavily compute-bound, requiring complex optimizer state management, gradient accumulation mechanisms, and frameworks like Fully Sharded Data Parallel (FSDP) to manage its internal updates 17. Treating them as a single computational unit leads to severe hardware underutilization. Optimization requires decoupling them into separate operating processes, or entirely separate hardware clusters, allowing the teacher to scale as a remote inference service independently of the student 17.
The Logit Tax and Network Saturation
Once the models are decoupled, the physical network connecting the inference cluster and the training cluster becomes the primary bottleneck. Transmitting the full probability distribution (the logits) from the teacher to the student across network nodes - dubbed the "Logit Tax" - is prohibitively expensive in terms of bandwidth 17.
In a standard LLM distillation configuration utilizing a conservative batch size of 8, a sequence length of 2048 tokens, a standard vocabulary size of 150,000 (typical of models like Qwen or Gemma), and 2-byte precision (bfloat16), shipping the full logit tensor requires approximately 15 gigabytes of data transfer per single training step 17. When utilizing an ensemble of teachers, this data volume easily saturates even high-end, specialized Network Interface Cards (NICs), starving the student model of labels and halting training 17. Distributed systems engineers mitigate this severe bottleneck by transmitting the much narrower hidden states instead of full logits across the network. A specialized shim layer on the student node then recomputes the logits locally using the teacher's shared Language Model (LM) head. If the architectures diverge, a learned linear projection layer maps the student's hidden dimension to the teacher's logit space, effectively eliminating the network bandwidth constraint 17.
The Model Capacity Gap
A critical algorithmic bottleneck inherent to the methodology is the "capacity gap." If the teacher model is vastly more complex or parameterized than the student model, the student structurally lacks the representational capacity to mimic the teacher's highly sophisticated, multi-modal probability distributions 112. This severe architectural mismatch can lead to ineffective knowledge transfer, mode collapse, and overall predictive performance degradation, negating the purpose of distillation 112.
Intermediate Curriculums and Difficulty-Aware Filtering
To bridge this capacity gap, researchers employ intermediate models and smoothing techniques. The Tutor-Enhanced Iterative Distillation (TEID) framework introduces an intermediate-sized "tutor" model. The teacher distills knowledge to the tutor, which then distills knowledge to the final student, breaking the learning curve into manageable gradients 1. Similarly, Skew Kullback-Leibler (SKL) divergence methods introduce an intermediate target distribution that interpolates directly between the teacher's and the student's outputs, mitigating distributional divergence and preventing the student network from being overwhelmed by complexity it cannot map 13.
Standard distillation processes also frequently waste massive amounts of computational time by forcing the student to process and learn from simple data samples it already fully comprehends 14. Difficulty-Aware Knowledge Distillation (DA-KD) frameworks dynamically adjust the distillation dataset based on the student's evolving competency 114. By employing routing mechanisms or difficulty graders aligned with human benchmarks, DA-KD focuses the loss functions entirely on hard samples that the student currently fails 14. This intelligent filtering reduces total training costs by half while achieving equivalent or superior benchmark performance 14. To prevent gradient explosion or vanishing gradient problems when the dataset becomes heavily skewed toward exceptionally difficult samples, stabilizing mechanisms like Bidirectional Discrepancy Loss (BDL) are applied to smooth the optimization trajectory 14.
Distillation of Complex Reasoning and Chain-of-Thought
The advent of highly capable LLMs empirically demonstrated that complex mathematical and logical reasoning is an emergent property tightly correlated with massive parameter counts 1522. Techniques like Chain-of-Thought (CoT) prompting - where models are explicitly primed to verbalize intermediate rationalizations step-by-step prior to delivering an answer - yield dramatic performance gains. However, historical scaling laws indicated these benefits generally only emerged for models exceeding 50 billion parameters 22. Small language models naturally struggle to generate accurate reasoning traces independently, often producing flawed logic, hallucinating facts, or entirely skipping critical inferential steps 1516.
Symbolic and Adaptive Distillation Approaches
To instill advanced reasoning in SLMs, researchers utilize Symbolic Chain-of-Thought Distillation (SCoTD). Instead of relying strictly on white-box logit transfer, SCoTD operates as a data-centric distillation pipeline. It samples vast corpora of text containing high-quality, step-by-step reasoning generated by a massive teacher model 22. The student is then trained on these rationalizations via supervised fine-tuning (SFT). This approach empirically proved that models as small as 125 million to 1.3 billion parameters can learn to "think" step-by-step, provided they are exposed to a sufficiently diverse and rigorously filtered set of reasoning chains 22.
However, simplistic SFT on massive reasoning traces often produces overly verbose student models that babble unnecessarily, leading to severe inefficiencies at inference time due to excessive token generation 17. Difficulty-Aware CoT Distillation (DA-CoTD) solves this by adapting the length and complexity of the reasoning trace directly to the inherent complexity of the user's input prompt. DA-CoTD utilizes an LLM-based grader to compress verbose teacher traces into highly efficient, difficulty-aligned chains before feeding them to the student via Direct Preference Optimization (DPO), maintaining accuracy while reducing inference token generation by up to 30% 17.
Mistake-Driven Learning and Dual Pathways
Standard CoT distillation methodologies typically train student models exclusively on the correct outputs generated by the teacher 16. However, empirical analysis of reasoning traces shows that they consist mostly of simple syntactic formatting, with only a tiny fraction (approximately 4.7%) representing the "key reasoning steps" that actually dictate the final logical conclusion 16. When trained only on positive, correct samples, students often merely imitate the structural form and vocabulary of the reasoning without actually learning the pivotal logic steps required to solve novel problems 16.
The EDIT (mistakE-Driven key reasonIng step distillaTion) framework models human pedagogical methods by providing the student with dual reasoning paths 16. Through specialized prompting, the teacher model is forced to generate two CoT outputs for a single problem: one that successfully reaches the correct answer, and one that fails due to a specific induced logical error 16. By applying a minimum edit distance algorithm between the two contrasting paths, the framework isolates the exact logical juncture where the failure occurred. Utilizing these negative samples in the distillation loss function forces the student to recognize and internalize the specific step that dictates accuracy, moving the student beyond mere stylistic imitation to actual capability acquisition 1516.
Implicit Chain-of-Thought
A novel and highly experimental frontier in reasoning distillation aims to entirely internalize the verbalized steps of CoT. Implicit Chain-of-Thought reasoning attempts to conduct reasoning "vertically" across the model's internal hidden layers rather than "horizontally" by outputting intermediate text tokens into the context window 18. In this method, a teacher model explicitly generates a CoT sequence, and its internal hidden states (across all layers and generated tokens) are extracted. An emulator network is then trained to mathematically predict these multi-layer state matrices. This allows the student model to process the logical progression entirely within its hidden states, vastly accelerating inference times by bypassing the sequential generation of intermediate words 18.
Evolution of Distilled Natural Language Understanding
The history of model distillation can be traced precisely through the evolution of foundational encoder models to the current era of massively distilled, autoregressive decoder-only models.
The BERT Era Compression
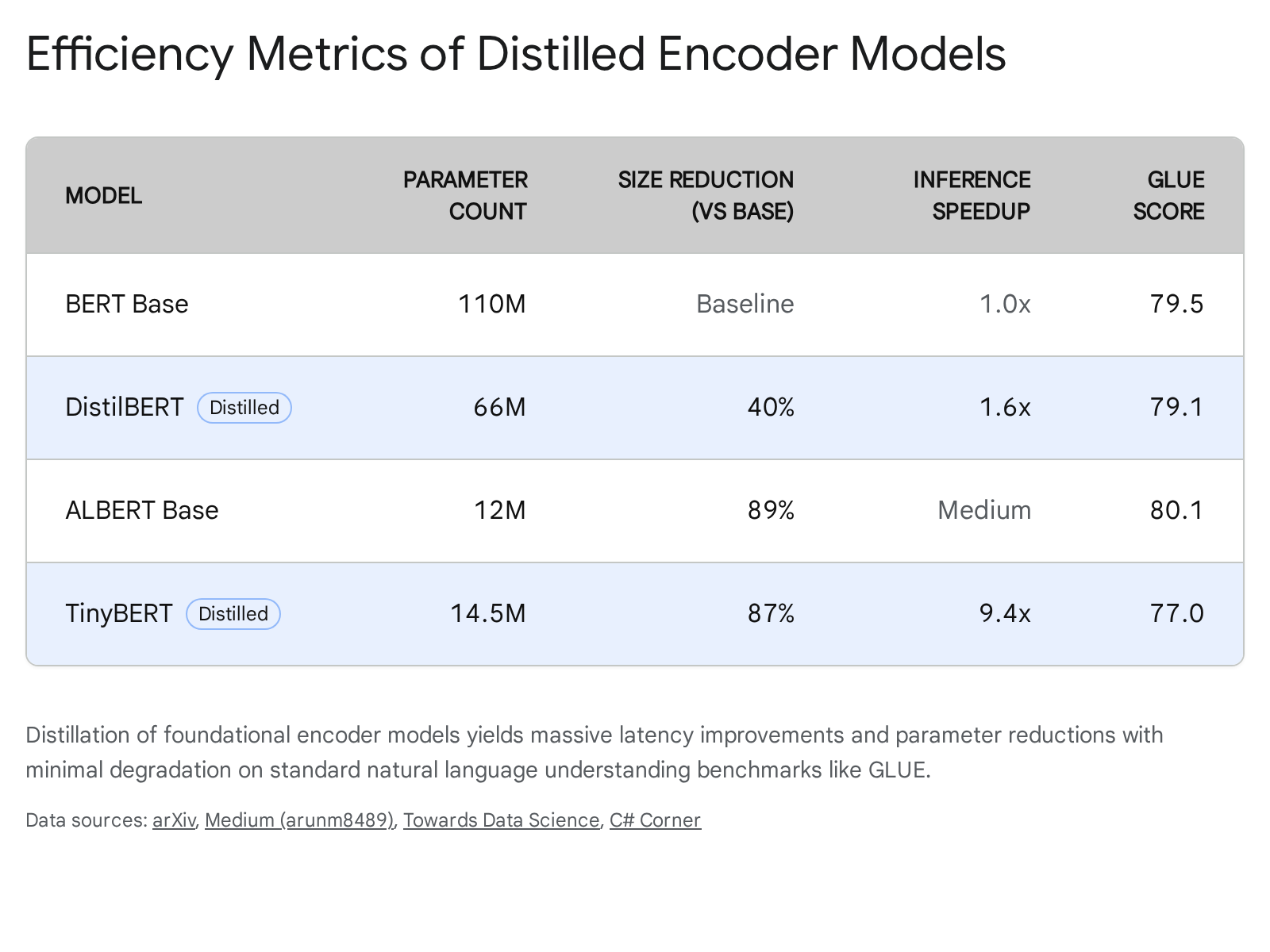
Following the release of Google's Bidirectional Encoder Representations from Transformers (BERT), the natural language processing community faced acute latency challenges due to the model's 110-million parameter footprint, making it difficult to deploy on mobile applications or edge servers 726. Hugging Face introduced DistilBERT, pioneering the practical application of KD for transformers 1019. By removing token-type embeddings and the pooler, and reducing the layer count by half, DistilBERT achieved a 40% reduction in parameters and a 60% acceleration in inference time 1028. Utilizing a triple loss function that combined masked language modeling loss, classical distillation loss, and cosine-distance loss to strictly align the student and teacher hidden vectors, DistilBERT maintained 97% of BERT's original performance on the ubiquitous GLUE benchmark 102820.
Subsequent iterations pushed compression algorithms further. DistilRoBERTa implemented similar layer-halving techniques on the highly optimized RoBERTa architecture, achieving 2x faster inference and near-parity on downstream sentiment and cybersecurity analysis tasks 142630. TinyBERT represented an aggressive, generalized layer-wise distillation strategy that mapped every third BERT layer to the student. This reduced BERT-base to just 14.5 million parameters - a staggering 7.5x reduction in size and 9.4x acceleration in speed - while still achieving a highly competitive 77.0% GLUE score compared to BERT's 79.5% 312122.
The Open-Weights Era and Massive Language Models
The introduction of the Llama series by Meta shifted the industry focus from efficient encoders to massive decoder-only generative models. The Llama 3 family includes 405B, 70B, and 8B parameter variants 2324. While the 405B model serves as the flagship, setting state-of-the-art benchmarks for open-weights, its massive computational overhead restricts its deployment 2436. Meta utilized the 405B model extensively to generate, curate, and filter the synthetic training data for the 70B and 8B variants, demonstrating a form of data-pipeline distillation that embedded high-order reasoning into the smaller architectures 37.
The resulting performance gap highlights the efficacy of this approach. The 70B model achieves an MMLU (Massive Multitask Language Understanding) score of ~86.0% and a GSM8K (Grade School Math) score of 95.1%. The highly compressed 8B parameter model achieves an MMLU score of ~73.0% and a GSM8K score of 84.5% - scores that comfortably eclipsed previous generation models nearly ten times its size, making it a staple for on-device deployment 243839.
| Meta Llama 3.1 Model Tier | MMLU (Reasoning & Knowledge) | GSM8K (Math & Logic) | HumanEval (Coding) | ARC-Challenge |
|---|---|---|---|---|
| Llama 3.1 70B | ~86.0% | ~95.1% | ~80.5% | ~94.8% |
| Llama 3.1 8B | ~73.0% | ~84.5% | ~72.6% | ~83.4% |
Third-party projects have pushed these architectures even further to target the strict constraints of the edge-deployment market. The TinyLlama project utilized the exact architecture and tokenizer of Llama 2 but trained a 1.1 billion parameter model from scratch on a highly curated synthetic and public dataset of 3 trillion tokens (sourced primarily from Slimpajama and Starcoderdata) 4025. Executed over 90 days on just 16 A100-40G GPUs, the project proved that extreme data density could compensate for low parameter counts 4042. Despite its diminutive size, TinyLlama outperforms comparable models like Pythia and OPT in zero-shot problem-solving tasks, demonstrating the efficacy of massive token exposure 43.
Hardware Constraints and Local Execution Realities
The theoretical performance of these models often meets stark physical limitations during local deployment. For instance, execution on consumer hardware, such as the Apple Mac mini equipped with M4 Pro chips, reveals critical memory bandwidth bottlenecks 26. While 3B to 8B parameter models execute flawlessly, attempts to run 70B-class models on local 32GB or 64GB unified memory architectures result in sluggish generation speeds of 3 to 5 tokens per second 26.
Furthermore, while SLMs (Small Language Models) under 8B parameters approach LLM performance on text classification and routing tasks, they often suffer severe regressions in structured output reliability 4546. Benchmark evaluations indicate that while a model like Llama 3.1 8B executes JSON parsing and schema compliance reliably, scaling down to the 3B parameter tier results in parse rates dropping precipitously to roughly 50%, indicating that a minimum parameter density is required for strict syntactical adherence 45.
DeepSeek-R1 and the Reinforcement Learning Distillation Paradigm
A definitive paradigm shift in reasoning distillation was demonstrated by DeepSeek with the release of the DeepSeek-R1 models in early 2025. Prior to this, achieving advanced mathematical and coding reasoning typically required computationally exhaustive Reinforcement Learning (RL) pipelines applied directly to the target model 47.
Rather than utilizing RL to train small models from scratch, DeepSeek extracted approximately 800,000 high-quality reasoning and non-reasoning data samples from their massive, RL-trained flagship model 47. They utilized this highly curated dataset to conduct pure Supervised Fine-Tuning (SFT) on existing open-source base models, specifically the Qwen (1.5B to 32B) and Llama (8B and 70B) series, entirely bypassing the RL stage for the students 47.
The benchmark results proved highly disruptive to the industry standard. The DeepSeek-R1-Distill-Qwen-1.5B model achieved 28.9% on AIME 2024 and 83.9% on MATH-500, outperforming massive proprietary models like GPT-4o and Claude-3.5-Sonnet on specific mathematical benchmarks 47. The 32B distilled variant achieved 72.6% on AIME and 94.3% on MATH-500, setting new global records for dense models and significantly exceeding the performance of specialized reasoning models like OpenAI-o1-mini 47.
| DeepSeek-R1 Distilled Model | Base Architecture | AIME 2024 | MATH-500 | GPQA Diamond | LiveCodeBench |
|---|---|---|---|---|---|
| DeepSeek-R1-Distill-1.5B | Qwen 2.5 | 28.9% | 83.9% | 33.8% | 16.9% |
| DeepSeek-R1-Distill-7B | Qwen 2.5 | 55.5% | 92.8% | 49.1% | 37.6% |
| DeepSeek-R1-Distill-8B | Llama 3.1 | 50.4% | 89.1% | 49.0% | 39.6% |
| DeepSeek-R1-Distill-14B | Qwen 2.5 | 69.7% | 93.9% | 59.1% | 53.1% |
| DeepSeek-R1-Distill-32B | Qwen 2.5 | 72.6% | 94.3% | 62.1% | 57.2% |
| DeepSeek-R1-Distill-70B | Llama 3.3 | 70.0% | 94.5% | 65.2% | 57.5% |
Crucially, the computational efficiency of this approach altered the economics of model training. The vanilla Llama 3.1 8B model required approximately 1.46 million H100 GPU-hours to pre-train 48. Its distilled counterpart, DeepSeek-R1-Distill-Llama-8B, acquired superior reasoning capabilities across all benchmarks with only ~610 H100 GPU-hours - a compute expenditure reduction of over 99.9% 48.
Generative Degradation and Model Collapse
While distillation methodologies yield exceptionally impressive headline benchmark scores, the fundamental nature of the algorithm introduces severe risks of long-term capability degradation. Knowledge distillation is inherently a lossy mathematical projection 27. By optimizing a student model strictly to match a teacher's output distribution or specific step-by-step reasoning traces, the student may perfectly mimic the primary observable metrics while fundamentally failing to preserve the underlying computational capabilities that make the teacher reliable in unpredictable edge cases 27.
Evaluations in the field often rely on the flawed assumption that retained task scores imply retained general capabilities 27. However, researchers have identified that "off-metric" capabilities - such as strict adherence to safety guardrails, grounding in factual constraints, algorithmic process faithfulness, and overall generative diversity - frequently deteriorate drastically in distilled models 27. A student model may generate code that passes a unit test (the benchmark), but it may achieve that result through brittle, memorized logic rather than generalized understanding.
This degradation becomes highly problematic and systemic when synthetic data generated via distillation is introduced back into the general pre-training corpora of future AI models. Iterative training loops, where subsequent generations of models continually learn from the synthetic, distilled outputs of their predecessors, trigger an exponential degradation phenomenon known as "model collapse" 5028. As the recursive loop progresses, the minor statistical errors, hallucinations, and loss of variance introduced during the initial distillation phases become mathematically amplified. The resulting models rapidly lose their ability to model the true, underlying variance of human language and data distributions, eventually outputting homogenous, low-quality text 2852. Mitigating this requires drawing on pedagogical frameworks, such as Vygotsky's Zone of Proximal Development (ZPD), to implement strict curriculum sequencing and mastery gating during synthetic data generation 50.
Adversarial Distillation and Model Extraction Attacks
The massive operational efficiency and cost reductions provided by knowledge distillation have birthed a novel cyber-threat vector known as a "distillation attack" or "model extraction attack." In benign applications, developers use distillation to compress a model they own or have licensed for open use. In an adversarial distillation attack, an entity utilizes legitimate, authenticated access points (such as commercial APIs, mobile applications, or third-party resellers) to systematically and aggressively probe a proprietary frontier model 535429.
The attacker harvests millions of high-value computational outputs - including complex reasoning traces, algorithmic code trajectories, formulated answers, and alignment preferences 5456. The attacker then uses this massive synthetic dataset to conduct supervised fine-tuning on a localized open-source student model 5456.
Capabilities Cloning and Safety Stripping
Distillation attacks allow adversaries to "free-ride" entirely on the massive capital expenditure invested by leading AI labs 3031. By cloning the intelligence of a model without bearing the multi-million dollar data curation and pre-training compute costs, attackers can rapidly deploy competing products that undercut the original provider on service pricing 56.
Furthermore, because the attacker dictates the fine-tuning process of the student model, they possess the ability to intentionally and selectively distill raw intelligence capabilities while explicitly stripping away the teacher model's embedded safety protocols, ethical alignments, and ideological constraints 563032. The resulting adversarial model possesses frontier-level intelligence but is entirely devoid of the original developers' usage guardrails, posing severe risks for malicious exploitation 33.
Geopolitical Ramifications and Trace Coercion
Distillation attacks gained international prominence during a high-profile controversy between US-based AI labs and the Chinese firm DeepSeek. OpenAI delivered a formal memorandum to the US Congress alleging that DeepSeek conducted an industrial-scale distillation attack, utilizing obfuscated third-party routers and programmable networks to bypass OpenAI's API access restrictions 303435. The allegations asserted that DeepSeek harvested vast quantities of outputs from frontier models like ChatGPT to artificially inflate the capabilities of their own local models at a fraction of standard training costs 3435.
Similar operational concerns were echoed by Anthropic and Google. Google's Threat Intelligence Group (GTIG) actively monitored and disrupted massive "reasoning trace coercion" campaigns 542931. In one documented instance, an attacker submitted over 100,000 highly targeted prompts specifically designed to force the Gemini model to output its normally hidden internal reasoning traces in non-English languages, representing a clear attempt to extract and clone the model's core cognitive architecture for foreign deployment 5429. These incidents have fundamentally shifted the narrative around distillation from a benign academic engineering technique to a matter of critical national security, geopolitical competition, and intellectual property protection 3136.
Legal Frameworks and Intellectual Property Friction
The surge in industrial-scale distillation attacks has exposed critical ambiguities in global intellectual property law regarding the protection of artificial intelligence capabilities and the enforceability of commercial protections 936.
Terms of Service Constraints and Enforceability
To protect their massive intellectual property investments, frontier AI developers uniformly deploy strict Terms of Service (ToS) explicitly prohibiting the use of their model outputs to train competing AI systems. OpenAI's policy explicitly dictates that users may not "Use Output to develop models that compete with OpenAI" 37. Anthropic strongly restricts outputs from being used to "develop or train any artificial intelligence or machine learning algorithms or models" that constitute competitive products 3866. Google's Gemini API terms mandate similar prohibitions against reverse engineering or extracting parameter weights through generative queries 3940.
However, the legal enforcement mechanisms for these clauses are currently severely limited, usually resulting only in account termination and API bans 41. Translating these ToS violations into actionable courtroom litigation is highly complex. The primary hurdle is the evidentiary difficulty of proving definitively that a specific competing model was explicitly trained on proprietary outputs, particularly when the competitor operates in a foreign jurisdiction with differing regulatory standards 4170.
Copyright Law and the Human Authorship Requirement
The application of traditional copyright law to model distillation remains legally precarious and largely untested in high courts. In the United States, copyright protection strictly requires "human authorship" 970. The outputs generated by an AI API - which serve as the highly valuable training data for the student model during an attack - are the result of autonomous algorithmic computation, not human creative expression 9.
As evidenced by specific guidance from the US Copyright Office in cases like Zarya of the Dawn, AI-generated text, code, or images lack the human element required to be considered copyrightable works 9. Therefore, an adversarial actor harvesting billions of tokens of AI output is arguably not infringing on any recognized copyright 4142. Furthermore, because models like OpenAI's transfer output ownership to the user prompting the system, the platform developer surrenders the legal standing to claim infringement 70.
Unfair Competition and Antitrust Perspectives
Given the severe limitations of copyright, legal scholars suggest that disputes over knowledge distillation will center on contract law and Unfair Competition frameworks 970. Plaintiffs will likely argue that distillation constitutes flagrant "free-riding," exploiting another entity's substantial R&D investment to create a direct market substitute in violation of fair commercial practices 9. Alternatively, developers may pursue trade secret misappropriation claims, asserting that the model outputs contain derivative insights into the proprietary, confidential algorithms and datasets used to pre-train the teacher 4143.
Conversely, antitrust advocates and open-source proponents argue that broad "anti-distillation" clauses are inherently anti-competitive and potentially legally unenforceable 44. From this doctrinal perspective, frontier models represent foundational infrastructure in the modern digital economy 44. Restricting developers from extracting functional principles to build interoperable or competing systems may violate competition statutes. Scholars draw parallels to historical software reverse-engineering precedents, such as Sega Enterprises v. Accolade, where the extraction of functional principles was protected 44. Under frameworks like the EU's Article 102 TFEU and the essential facilities doctrine, coordinated restrictions on output usage by dominant AI firms could face intense regulatory scrutiny 44. As international regulatory bodies attempt to harmonize rules regarding AI IP protection, the legality of knowledge distillation remains a profound and unsettled friction point between open-source innovation and corporate intellectual property rights 3670.