Initial Token Attention and KV Cache Optimization in LLMs
Introduction to the Attention Sink Phenomenon in Modern Architectures
The evolution of Large Language Models (LLMs) has been irrevocably defined by an unrelenting drive to expand context windows, evolving from the modest limits of early architectures to the multi-million token capacities of contemporary frontier models such as Llama 3.1 and Qwen 2.5 12. However, this scaling exacerbates a fundamental architectural bottleneck: the quadratic computational and memory complexity of the standard multi-head self-attention mechanism. At the intersection of resolving this bottleneck and understanding the internal geometric representations of LLMs lies a structural anomaly that has transitioned from an esoteric quirk to a foundational pillar of modern LLM design: the attention sink phenomenon.
Initially documented in the seminal literature surrounding the StreamingLLM framework by Xiao et al. in 2023, the attention sink refers to the systematic and disproportionate allocation of attention probability mass to specific tokens, often those situated at the absolute beginning of a sequence, regardless of their semantic relevance to the current generative step 123. The initial discourse surrounding this behavior often framed it as a potential artifact of limited training data or suboptimal hyperparameter initialization 6. However, rigorous mathematical and empirical scrutiny spanning recent publications across major global AI conferences - including ICLR, NeurIPS, and ICML throughout 2024, 2025, and early 2026 - has confirmed that attention sinks are universally emergent 456. They are not anomalies; rather, they are a mathematically necessary property of the softmax normalization constraint operating within autoregressive architectures, deeply intertwined with pre-training optimization dynamics 47.
This exhaustive report dissects the attention sink phenomenon from its foundational mathematical principles to its profound implications for pre-training dynamics and inference optimization. It delineates the geometric intersection between positional embeddings and sink token emergence, evaluates the introduction of explicit artificial sink tokens and multi-token prediction (MTP) registers, and provides a structured, multi-dimensional comparative analysis of modern Key-Value (KV) cache compression strategies that either leverage or mitigate these phenomena to enable infinite-context generation.
The Rigorous Mathematical Mechanisms of the Attention Sink
To understand why a large language model systematically dumps attention mass onto functionally void tokens, one must dissect the non-linear constraints of the core attention operation. In a standard Transformer, the attention matrix for a given layer and head is computed using a scaled dot-product formulation.
Dissecting the Softmax Normalization Constraint
The attention sink is fundamentally driven by the mathematical properties of the softmax function, which maps the dot product of query and key vectors into a probability distribution. Softmax enforces two strict, immutable constraints: all attention weights must be strictly positive (a consequence of the exponential function), and the sum of all attention weights for a given query over the key sequence must equal exactly unity 711.
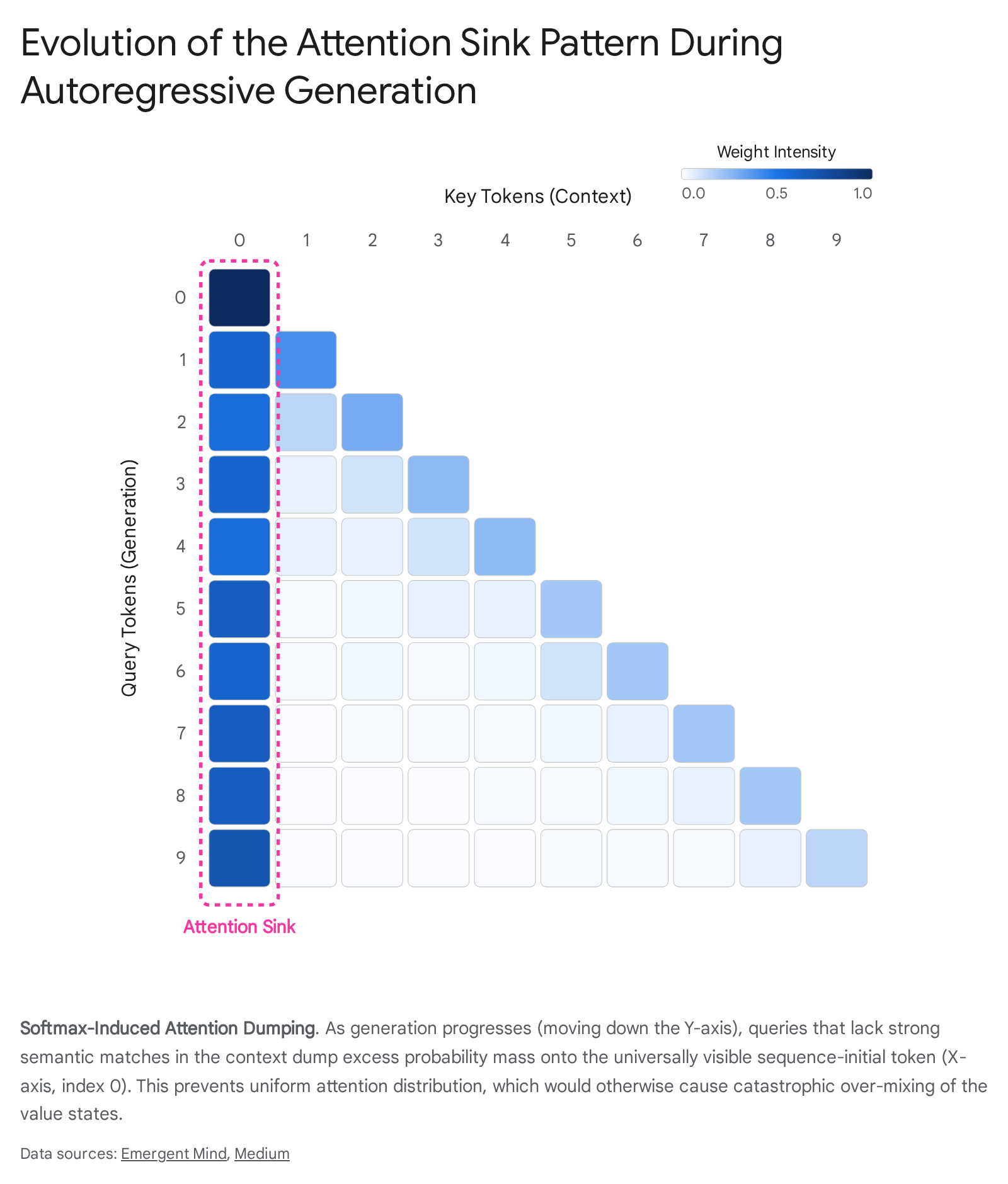
During autoregressive generation, a model frequently encounters queries that do not have strong, informative semantic dependencies on the preceding context. For example, transition words, punctuation, or generic structural formatting may not need to retrieve specific factual information from the prompt. In an ideal, unconstrained mathematical framework, the model would simply assign a near-zero attention score to all past tokens to prevent irrelevant context from corrupting the current representation 411. However, the sum-to-one constraint strictly prohibits an all-zero attention vector. If the model were forced to distribute this "unwanted" attention mass uniformly across the entire sequence to satisfy the summation constraint, it would retrieve a smeared, highly entropic average of the sequence's value vectors 78. This uniform distribution leads to catastrophic over-mixing, functionally destroying the query's residual state and severely degrading the model's predictive accuracy 78.
To bypass this architectural limitation, the model learns a highly effective optimization strategy during early pre-training epochs: it designates a specific token as an attention sink, effectively creating a structural dumping ground 4611. By allocating the vast majority of the surplus attention mass - often upwards of ninety percent in deep layers - to a single token, the model restricts the infusion of noise to a known, highly stable vector, thereby preserving the integrity of the semantic representation 4611.
Recent mathematical proofs, such as the comprehensive analysis of trigger-conditional tasks in softmax Transformers published in early 2026, formally demonstrate that computing simple trigger-conditional behaviors necessarily induces an attention sink 4513. The proofs confirm that any single-layer softmax attention model achieving vanishing error on specific routing tasks must place nearly all attention on a fixed sink token at every non-trigger position, establishing that the normalization constraint is the fundamental driver of the behavior rather than a mere training artifact 45.
Alternatives to Softmax: Validating the Hypothesis
The absolute mathematical necessity of the sink is further proven through rigorous architectural ablation studies. When the strict sum-to-one softmax constraint is removed or systematically modified, the attention sink phenomenon disappears entirely 4514. For instance, replacing standard softmax with non-normalized ReLU attention eliminates sink formation while preserving task accuracy, corroborating that the geometry of the probability simplex forces the collapse 4513.
Similarly, the introduction of mechanisms like "Softpick" or Rectified Softmax - which applies a ReLU activation prior to normalization and allows for the sum of attention weights to equal less than or exactly one - results in an observed zero percent sink rate 715. Models trained with Softpick produce hidden states with significantly lower kurtosis and highly sparse attention maps, completely bypassing the massive activation outliers typical of softmax-based networks without degrading downstream benchmarks 15. In the broader research community, theoretical proposals such as Centered Shifted-Quadratic (CSQ) Attention argue that the true optimization landscape for attention is mathematically lower-dimensional, and that softmax artificially inflates the rank, causing both the quadratic complexity curse and the pathological need for sinks 16. Furthermore, post-attention gating mechanisms, such as the Sigmoid gate implemented in GateSWA (Gate Sliding-Window Attention), dynamically suppress query-irrelevant attention outputs, allowing the network to effectively turn off the attention sink and bypass the sum-to-one constraint at the output projection level 111718.
Differentiating Mathematical Dumping Grounds from Semantic Importance
A pervasive and critical misconception in the analysis of long-context models is the conflation of tokens that absorb attention as a mathematical dumping ground - the true sink phenomenon - with tokens that maintain consistently high attention due to actual semantic or structural importance to the prompt 6119. Distinguishing between these two classifications is vital for effective context compression, model interpretability, and the prevention of catastrophic knowledge eviction during inference.
The Value-State Drain and Residual-State Peaks
Attention sinks can be mathematically isolated from semantic heavy hitters by analyzing the norm of their respective value vectors. Semantic heavy hitters - such as a critical noun defining a system prompt, a complex logical operator in code, or a numerical value in a chain-of-thought reasoning trace - receive high attention scores because their key vectors strongly align with the current query, and crucially, their value vectors contain dense, vital information necessary for accurate next-token prediction 2021.
Conversely, pure attention sinks are functionally void of informational content. Because the sink token is structurally forced to absorb arbitrarily high attention to prevent over-mixing, this excessive attention allocation threatens to aggressively corrupt the output with the sink token's own semantic content 89. To prevent this corruption, the optimizer, during the pre-training phase, reactively minimizes the norm of the sink token's value vector 89. This adaptation results in a documented "value-state drain," where the value vectors of true sink tokens exhibit pathologically small, near-zero magnitudes 8.
This dynamic creates a mutually reinforcing positive feedback loop deeply embedded within the network's parameters. The drained value state ensures that attending to the sink adds virtually zero magnitude to the attention output, making the token an even safer, more attractive 'no-op' target for future attention dumping 89. This cycle locks the model into a stable, yet arguably pathological, equilibrium 8. Therefore, an attention sink is definitively characterized not merely by a high attention weight, but by the unique juxtaposition of disproportionately high attention scores and near-zero value-state norms. If a cache eviction algorithm naively preserves all tokens with high attention without distinguishing between void sinks and dense semantic heavy hitters, it risks optimizing for structural artifacts rather than actual informational content, which has driven the development of more nuanced eviction oracles 921.
Pre-Training Dynamics: Positional Embeddings and Emergent Behaviors
The mathematical constraints of softmax explain why the model desperately requires an anchor, but it does not intrinsically dictate which token in a sequence of potentially thousands becomes that designated anchor. The selection of the absolute sequence-initial token as the primary sink is a direct consequence of pre-training dynamics, the application of causal masks, and the specific geometry of positional embeddings utilized in the architecture 31122.
The Geometric Privilege of Positional Embeddings
Due to the nature of the autoregressive causal mask, the first token is universally visible; it is the only token structurally guaranteed to be in the receptive field of every subsequent query generated by the model 11. More profoundly, the implementation of Rotary Position Embeddings (RoPE), heavily utilized in leading foundational models like Llama 3.1 and Mistral, introduces a severe geometric asymmetry into the embedding space. In standard RoPE implementations, the rotation angle calculated for the first position is zero, resulting in an identity rotation matrix 3. Because it undergoes no rotation, the first token occupies a privileged computational status, allowing query vectors originating from anywhere across the long sequence to maintain a higher baseline cosine similarity with the first token's key vector compared to other tokens at similar relative semantic distances 322. This mathematical reality establishes the first token as a centralized reference frame, acting as a universal origin point within the representation manifold 323.
However, modifications to the positional encoding scheme drastically alter this sink behavior. Models employing NTK-aware scaled RoPE, a technique prominent in the Qwen 2.5 architectural family, reduce angular separation by applying a specific scaling factor to the rotation angles. This deliberate geometric modification shifts the attention topology from a single-pointed manifold to a complex multi-pointed manifold 3. Consequently, rather than converging entirely on the absolute first token, Qwen 2.5 models dynamically distribute attention sinks across diverse tokens throughout the sequence, creating distributed reference frames and secondary sinks that emerge in deeper layers 32324. These distributed sinks often latch onto highly frequent, low-semantic tokens such as punctuation or common articles, demonstrating that the sink behavior adapts fluidly to the underlying geometric constraints of the positional embedding 324.
Information Retrieval Demands and the "Lost in the Middle" Phenomenon
The emergence of the sink is also intricately tied to the information retrieval demands imposed on the model during large-scale pre-training. The extensively documented "lost-in-the-middle" phenomenon - where LLMs exhibit degraded recall for critical information placed in the center of an extended context - can be interpreted not strictly as an architectural flaw, but as a learned adaptation 10. During pre-training on diverse, unstructured web corpora, models face competing demands: short-term memory demands that heavily favor recent tokens (resulting in a strong recency effect) and long-term memory demands that require uniform recall across the text 10. The primacy effect, characterized by unusually high attention on early tokens, is induced by this long-term demand, but its extreme, pathological manifestation is structurally anchored by the formation of the attention sink at position zero, linking pre-training data distributions directly to the geometric anomalies observed during inference 610.
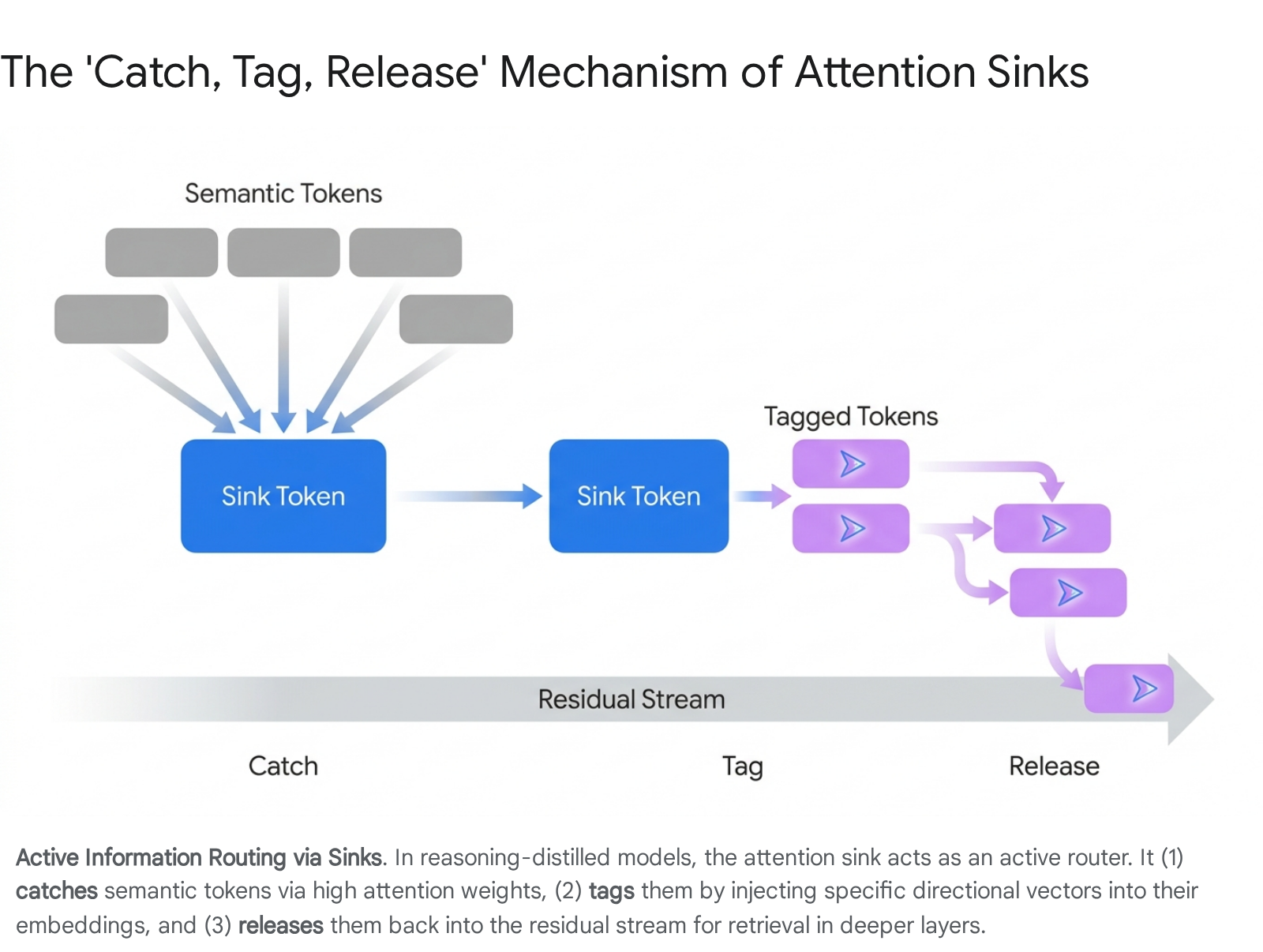
The "Catch, Tag, Release" Routing Mechanism and Massive Activations
Beyond serving as a passive dumping ground for surplus probability mass, recent mechanistic interpretability studies presented at premier conferences in 2025 have mapped the downstream computational consequences of attention sinks, revealing an emergent "catch, tag, release" routing mechanism 111213. This mechanism is particularly prominent in models explicitly distilled for complex reasoning tasks, such as the DeepSeek-R1 variants distilled into the Llama 3.1 8B and Qwen 2.5 14B architectures 1113.
In this framework, the attention sink acts as an active, highly sophisticated information router. The sink token "catches" a sequence of semantic tokens by attracting their attention. Subsequently, it "tags" them by imprinting a common directional vector into their embeddings, effectively copying specific value vectors as operational tags 111214. Finally, the sink "releases" this tagged information back into the residual stream 1114. In the deeper layers of the Transformer, these tagged tokens are selectively retrieved and routed based on the specific geometric tags they acquired from the sink 1112.
This routing mechanism provides a structural explanation for why "massive activations" - extreme outlier values in the feature space - consistently appear in the intermediate states of Feed-Forward Networks (FFNs) for the sequence-initial token across models like Llama 3, Mistral, and Phi-3 303115. These massive activations drive a profound representational compression within the residual stream, creating what researchers have termed "compression valleys" 15. This phenomenon organizes the LLM's computation in depth, separating processing into distinct phases: broad mixing in early layers, compressed computation with limited mixing mediated by massive activations in the middle layers, and selective refinement in the late layers 15. The prominence of this catch, tag, release mechanism even in models utilizing Query-Key (QK) normalization confirms that sinks are deeply embedded in the functional logic of the network, not merely superficial anomalies of attention magnitude 111214.
Artificial Sink Tokens and Multi-Token Prediction (MTP) Registers
Recognizing that large language models naturally weaponize existing tokens to serve as structural anchors, the research community has increasingly shifted from mitigating the sink post-hoc to explicitly engineering artificial sinks during the pre-training phase.
The intentional inclusion of a globally visible, highly trainable placeholder token - designated specifically as an artificial attention sink - provides the model with a dedicated repository for unnecessary attention scores 1233. When LLMs are pre-trained from scratch with a dedicated sink token, the models do not inadvertently hijack semantically valuable tokens, such as standard punctuation or early contextual nouns, to serve as mathematical anchors 1234. This architectural foresight results in cleaner, substantially more interpretable attention maps, stabilizes the attention mechanism, and preserves the value-state integrity of the actual user prompt, ensuring that genuine contextual information is not subjected to value-state draining 1235.
Vision Registers and Multimodal Extensions
This structural intervention has rapidly extended beyond purely textual models. In vision-language models and advanced Vision Transformers (ViTs) such as the DINOv2 architecture, "register tokens" have been introduced to absorb attention artifacts within visual encoders 151617. Without these registers, vision models historically stored global spatial context in irrelevant background patches, leading to massive activation outliers in empty space and directly exacerbating multimodal hallucination 1638. By utilizing designated registers, the model condenses visual information efficiently, separating feature extraction from structural attention dumping 16. In multimodal generation, frameworks like SinkTrack and SAGE actively leverage the attention sink phenomenon, intervening at these natural structural boundaries to assess grounding reliability and mitigate contextual forgetting over extended sequences 394041.
Multi-Token Prediction (MTP) and Speculative Decoding
More recently, the conceptual foundation of artificial sink and register tokens has been radically repurposed to facilitate Multi-Token Prediction (MTP), a training paradigm utilized to remarkable effect in the latest generation of state-of-the-art models, including DeepSeek-V3 and advanced Llama 3.1 derivatives 424318. In standard autoregressive generation, tokens are predicted strictly sequentially. In MTP frameworks - such as MuToR, FSP-RevLM, and DeepSeek-MTP - learnable register tokens are systematically interleaved into the input sequence and assigned shifted, future-oriented position IDs 184519.
Instead of merely acting as passive reservoirs to absorb excess attention, these specific register tokens function as "foresight tokens." They learn to predict multiple non-sequential future tokens in a single forward pass, relying on the rich, compressed representations stored in the residual stream 4519. This design entirely circumvents the necessity for independent, massive auxiliary prediction heads, drastically reducing the limitations associated with teacher-forcing 1819. Furthermore, it vastly accelerates speculative decoding during inference, as the model inherently generates high-quality drafts of future token blocks simultaneously, maximizing hardware utilization without compromising the mathematical stability of the self-attention mechanism 4319.
Evolution of Key-Value (KV) Cache Optimization Strategies
The relentless expansion of context windows - moving rapidly from the 128K-token capacity of early Llama 3 iterations to the potentially infinite data streams demanded by enterprise applications - has fundamentally transformed the Key-Value (KV) cache from a minor computational optimization into the primary bottleneck governing GPU memory capacity, bandwidth, and total inference throughput 24748. Storing the high-precision key and value vectors for millions of historically generated tokens results in volatile memory requirements that easily eclipse the model's static parametric weight, pushing single-request memory footprints into the tens of gigabytes 474950.
To address this critical limitation, the industry has diverged into a multitude of competing KV cache management paradigms. Table 1 provides a highly structured, multidimensional comparative analysis of the most prominent strategies as of 2026, explicitly noting their memory footprints, context limits, and their specific handling of the underlying attention sink phenomenon.
Table 1: Comparative Analysis of KV Cache Optimization Strategies
| Strategy | Core Mechanism | Memory Footprint / Complexity | Context Limit Support | Handling of Excess Attention (The Sink) |
|---|---|---|---|---|
| Standard Dense Attention | Retains all KV pairs for every generated and processed token. | $O(N \cdot L \cdot d)$ Massive linear growth. Requires aggressive memory paging (PagedAttention) 250. |
Hard constraints strictly dictated by available GPU VRAM. Fails on infinite streams 251. | Inherently processes the sink naturally, but wastes massive memory bandwidth caching millions of irrelevant tokens 2. |
| StreamingLLM (Sink Attention) | Preserves the initial $K$ tokens (the sink) permanently, combined with a rolling sliding window of recent tokens 25152. | $O(W)$ Strictly bounded by the specified window size $W$. Constant memory 5152. |
Infinite / Unbounded Prevents perplexity collapse in infinite generation streams 1251. |
Explicit Preservation. Relies entirely on safeguarding the attention sink to absorb excess probability mass 251. |
| Heavy Hitter Oracle (H2O) | Evicts tokens greedily based on accumulated attention scores. Retains tokens that receive high attention throughout generation 12020. | Dynamically bounded. Often reduces total GPU memory footprint by 70% 12048. | High, but risks evicting critical tokens if attention distribution shifts abruptly over long horizons 2054. | Implicit Preservation. The sink token naturally accumulates massive attention scores, ensuring it is never evicted by the oracle 20. |
| SnapKV / SnapKV-D | Uses an "observation window" at the end of the prompt prefill stage to vote on token importance via clustered attention scores 12055. | High compression. Only retains "voted" important KV pairs per independent attention head 15556. | Highly effective for long-prompt prefilling, though static mapping may fail in multi-step reasoning 205556. | Preserves the sink if the observation window detects its high attention, but primarily optimizes for semantic "heavy hitters" 2056. |
| PyramidKV | Allocates asymmetric cache sizes per layer. Lower layers retain large caches; higher (deeper) layers receive exponentially smaller budgets 12055. | Deeply compressed. Achieves state-of-the-art performance retaining <12% of total KV cache 120. | Very High. Maintains long-context comprehension superior to flat-budget methods 120. | Adapts naturally. Sinks are rigorously maintained in early layers where broad mixing occurs, easing the burden on deeper layers 120. |
| DynamicKV / EvolKV | Uses evolutionary optimizers and dynamic modeling of spatial and temporal utility to assign precise cache budgets 2021. | Highly variable, optimized per task. Reduces memory dramatically while maintaining mathematical exactness 2021. | High. Adapts specifically to whether the task is QA, summarization, or complex mathematics 2021. | Actively preserves sinks based on continuous evolutionary fitness scores calculated during the inference cycle 21. |
| Multi-Head Latent Attention (MLA) | Architectural change (e.g., DeepSeek). Compresses all KV information into a single low-dimensional latent vector per token 1858. | Ultra-low. Reduces cached elements by approximately 75% compared to GQA/MHA 58. | Exceptional. Enables massive context lengths with minimal overhead, shifting the bottleneck to compute 58. | Sinks are heavily compressed into the latent space. Often requires gated attention modifications to suppress sink noise post-SDPA 1718. |
Navigating the Deployment Trade-Offs
The comparative analysis reveals unequivocally that no single caching technique dominates across all hardware and deployment settings; architectural selection depends inherently on the specific nature of the desired workload 2.
StreamingLLM remains the undeniable gold standard for unbounded, high-velocity data streams - such as multi-round daily chatbots, real-time audio transcription, or continuous video processing - where the user primarily values recent context but requires the model to strictly avoid the catastrophic fluency and perplexity collapse that invariably plagues naive sliding window approaches 515259. By artificially pinning the initial tokens in the cache, StreamingLLM ensures the softmax function always has its required mathematical dumping ground, stabilizing the autoregressive generation indefinitely with a strictly constant $O(W)$ memory footprint 25152. However, StreamingLLM is fundamentally blind to historical tokens outside its rolling window, making it unsuitable for exhaustive document analysis.
Conversely, for complex multi-step reasoning tasks, dense mathematical proofs, or repository-level code generation where distant historical tokens are semantically critical, attention-based eviction strategies like H2O and SnapKV-D prove significantly superior 20. These methods dynamically recognize that while the mathematical sink must be preserved, semantic heavy hitters scattered throughout the massive prompt must also survive aggressive eviction 2056. Further refinements, such as DapQ and CompressKV, improve upon this by injecting synthetic pseudo-queries into observation windows or explicitly distinguishing between generic attention heads and specialized "streaming heads" that only focus on sequence boundaries, thereby refining the eviction oracle to an extraordinary degree 5659.
PyramidKV and EvolKV advance the paradigm by applying macro-structural insights regarding how Transformers process information. Acknowledging that LLMs engage in broad mixing in their early layers and selective, highly specific refinement in their deep layers, PyramidKV allocates massive cache budgets to layer 1 and increasingly sparse budgets up to layer 32 120. This pyramid structure mirrors the model's natural entropy funnel, radically outperforming uniform allocation methods and preserving long-context comprehension even when operating on less than twelve percent of the total available KV cache budget 120.
Future Trajectories: Quantization Resilience and the Eradication of the Sink
As the deployment of foundation models transitions from resource-rich research clusters to severely memory-bound edge environments and highly concurrent inference datacenters, the interaction between attention sinks, precision reduction, and hardware-level optimizations has become the primary frontier of study.
Quantization Vulnerabilities and KVSink
The extreme activation values intrinsically associated with attention sinks present severe, previously unanticipated challenges for post-training quantization (PTQ) schemes. Traditional quantization methodologies that aggressively map floating-point values down to INT8, INT4, or even sub-4-bit formats are easily destabilized by the massive $\ell_2$-norms present in the sink token's hidden states 60. Forcing these extreme outliers into a narrow, low-precision quantized grid obliterates the nuanced coordinate system of the attention mechanism, leading to unacceptable perplexity degradation 60.
Modern advanced frameworks, such as KVSink, directly combat this vulnerability by identifying stable activation outliers exceptionally early in the prefill stage 60. These systems explicitly preserve the original 16-bit floating-point precision solely for the isolated sink tokens while aggressively quantizing the remainder of the vast sequence. This highly targeted, mixed-precision approach effectively guards the network's mathematical anchor, ensuring that the model's fundamental coordinate system remains rigidly intact even under extreme compression ratios 60.
The Drive Toward Architectural Eradication
Looking toward the next generation of foundational AI, while current methods like StreamingLLM embrace and leverage the sink phenomenon, a growing faction of leading researchers argues that the attention sink is ultimately a pathological equilibrium. It is viewed as an unstable positive feedback loop that monopolizes parameter capacity, complicates mechanistic interpretability, and induces massive activation outliers that hinder scaling efficiency 8.
The recent introduction of architectures that utilize non-normalized attention mechanisms, element-wise sigmoid gating (such as GateSWA), or continuous sequence normalization strongly suggests that future models may eradicate the attention sink entirely at the source 471718. Doing so would inherently resolve the massive activation outliers, paving the way for native ultra-low precision pre-training and dramatically simplifying long-context KV cache management. By stripping away the mathematical requirement for a structural dumping ground, models can operate without the need for complex, heuristically-driven eviction policies, relying entirely on genuine semantic relationships.
Conclusion
The attention sink is far more than a superficial artifact of imperfect training data or hyperparameter selection; it is a profound manifestation of the strict geometric and mathematical constraints imposed by softmax normalization operating in high-dimensional representational spaces. Prevented from uniformly ignoring irrelevant context by the rigid sum-to-one constraint, autoregressive models ingeniously elect sequence-initial tokens - privileged by causal masking and the zero-rotation state of positional embeddings - as structural dumping grounds.
While these chosen tokens are largely semantically void and characterized by pathologically drained value states, their flawless preservation is absolutely critical for the operational stability of the model. The 2024 through 2026 landscape of LLM inference and architecture has been predominantly defined by the industry's mastery of this phenomenon. From explicitly inserting artificial register tokens during pre-training to engineer highly efficient Multi-Token Prediction networks, to designing sophisticated KV cache eviction protocols like PyramidKV, H2O, and StreamingLLM that dynamically protect these mathematical anchors, researchers have weaponized the attention sink to push context windows into the millions of tokens. As the field advances toward novel, non-normalized attention architectures that may eventually render the sink obsolete, the rigorous study of this phenomenon remains an unparalleled masterclass in how deep neural networks self-organize, adapt fluidly to their strict mathematical constraints, and dictate the ultimate hardware and algorithmic realities of modern artificial intelligence.