Impact of AI on scientific research productivity and discovery
The integration of artificial intelligence into scientific research methodologies represents a fundamental structural shift in how empirical knowledge is generated, processed, and validated. Over the past several years, algorithmic tools have transitioned from peripheral data-processing utilities to central mechanisms of scientific discovery across disciplines ranging from structural biology to the computational social sciences. Early empirical data regarding this technological integration reveals a complex and rapidly evolving landscape. While individual researcher productivity and the pace of high-computational discoveries have accelerated significantly, emerging evidence suggests potential epistemic risks, including a contraction in the diversity of scientific inquiry and an increasing reliance on automated mechanisms that may foster cognitive illusions of understanding.
Global Adoption Rates and Sector Integration
The adoption of generative and analytical artificial intelligence tools among the global scientific community has expanded at an unprecedented rate, outpacing historical technology adoption curves such as those associated with the personal computer and the commercial internet. Survey data from academic publishers, federal agencies, and research institutions indicates that the transition from experimental use to regular workflow integration occurred primarily between 2023 and 2025.
According to an October 2025 global survey of over 2,400 researchers conducted by Wiley, overall usage of artificial intelligence tools in research workflows surged to 84%, an increase from 57% in the previous year 1. An earlier 2025 survey covering active researchers from 113 countries recorded an adoption rate of 58%, up from 37% in 2024 2. This widespread uptake across the academic sector parallels trends in the broader commercial enterprise market, where regular generative technology usage roughly doubled from 33% in 2023 to over 65% by the end of 2024 3.
Population-wide data collected by the Federal Reserve Bank of St. Louis via the Real-Time Population Survey further underscores the velocity of this integration. As of August 2025, 54.6% of the United States working-age population reported using generative technologies, with significant utilization directly within workplace and analytical tasks . Within the scientific domain, this broad adoption is largely driven by researchers seeking to automate time-intensive phases of the scientific lifecycle, particularly data parsing and literature synthesis.
Disparities in Disciplinary Integration
The penetration of algorithmic technology is not uniform across scientific domains. An analysis of foundation model usage in published academic literature up to 2024 reveals distinct disciplinary hierarchies.
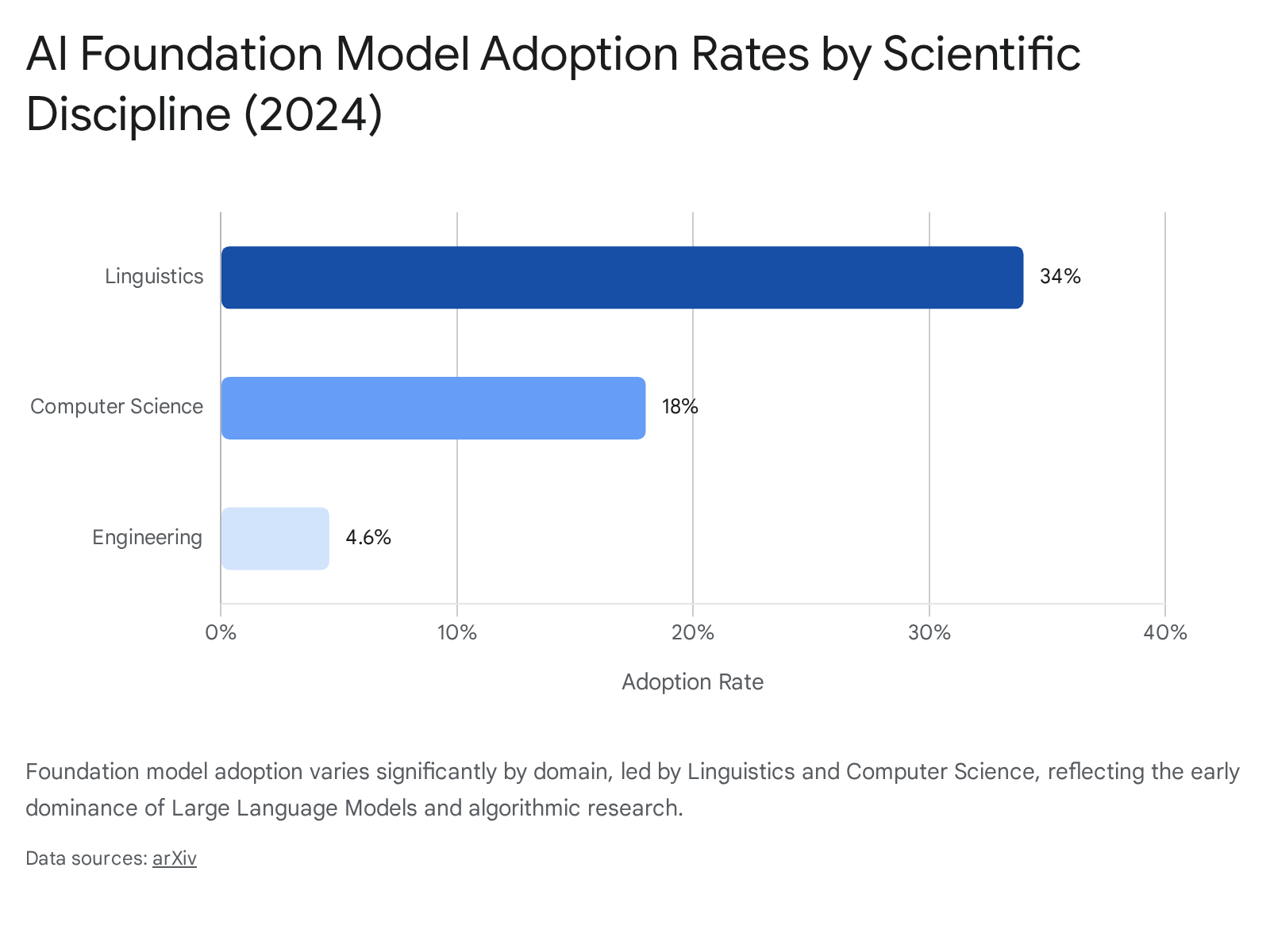
The variance in adoption correlates strongly with the availability of structured, machine-readable datasets within each respective field.
| Scientific Discipline | Estimated Foundation Model Adoption Rate (2024) | Primary Algorithmic Use Cases |
|---|---|---|
| Linguistics | 34.0% | Natural language processing, syntax modeling, language acquisition simulation |
| Computer Science | 18.0% | Algorithm development, code generation, foundation model architecture |
| Social Sciences | 11.2% | Unstructured data extraction, sentiment analysis, behavioral simulation |
| Life Sciences / Biology | 7.1% | Protein structure prediction, genomics, drug compound screening |
| Physical Sciences / Engineering | 4.6% - 5.0% | Fluid dynamics, material property prediction, sensor data analysis |
Table 1: Estimated adoption rates and primary use cases of foundation models across major scientific domains, synthesizing full-text analysis and bibliometric data 64.
Fields with long-standing traditions of digital open-access repositories, such as genetic sequencing in biology or particle event modeling in physics, have integrated algorithmic models more seamlessly than disciplines reliant on unstructured or highly qualitative data 45. Furthermore, researchers in the corporate and industrial scientific sectors exhibit higher adoption rates than their purely academic counterparts, benefiting from greater institutional provision of specialized tools and fewer bureaucratic barriers to deployment 16.
Public Perception and Researcher Sentiment
As the deployment of algorithmic systems expands, sentiment among scientific professionals and the general public has bifurcated. Broad population surveys indicate a persistent "optimism divide" between domain experts and lay consumers. A comprehensive 2025 demographic survey involving professionals and the public revealed that 47% of technology experts feel more excited than concerned about the growing role of autonomous systems, compared to just 11% of the general public 3. Public anxiety frequently centers on the loss of human connection and the potential for labor displacement, whereas scientific professionals generally prioritize utility and workflow acceleration 37.
Despite the high utilization rates among researchers, professional sentiment exhibits a maturing trajectory characterized by informed caution. While a vast majority of researchers report that automated tools improve their efficiency, their expectations regarding the autonomous capabilities of these systems have undergone a significant downward recalibration. In 2024, researchers estimated that artificial intelligence outperformed humans in over half of all potential scientific use cases; by late 2025, that estimation dropped to less than one-third 1.
This shift corresponds directly with an increase in concerns regarding hallucinations, unverified synthetic data, and inaccuracies, which rose from 51% to 64% over the same period 16. Privacy and data security concerns have similarly intensified, climbing from 47% to 58%, reflecting a research community moving beyond initial technological enthusiasm toward a nuanced understanding of present algorithmic limitations 1. Researchers are increasingly aware that while these tools excel at processing vast quantities of text, they frequently fail to capture the nuanced processes characteristic of rigorous human cognition 8.
Workflow Automation and Research Productivity
The most immediate and measurable impact of algorithmic integration on scientific research is the severe compression of the research lifecycle. Automated systems are accelerating tasks that traditionally required extensive human labor, particularly in the preliminary phases of research design, literature review, and raw data extraction.
Literature Review and Data Extraction
A substantial structural bottleneck in modern scientific research is the exponential growth of published literature. Automated literature review tools and specialized coding platforms have fundamentally altered how researchers process prior knowledge 12910. These platforms utilize natural language processing to execute semantic searches - interpreting overarching research intent rather than relying strictly on exact keyword matches - and automate the synthesis of key findings, methodologies, and multi-source structured data 12.
Empirical data derived from tool utilization metrics indicates that researchers report a 50% to 70% time savings on data extraction and initial manuscript screening 12. Systematic reviews, which traditionally require eight to twelve weeks of manual screening and coding, can frequently be completed in three to four weeks with algorithmic assistance 12. However, critical appraisal, methodology evaluation, and final analytical synthesis remain highly dependent on human oversight, indicating that current systems function primarily as data-processing accelerants rather than autonomous evaluators 129.
Quantitative Enhancements in Output
The acceleration of systematic workflows correlates strongly with increased individual publication output. Researchers who proactively incorporate machine learning and generative tools into their data collection and analysis pipelines publish significantly more than their non-adopting peers. Recent bibliometric analyses reveal that algorithmically-augmented scientists publish, on average, 3.02 times more papers and receive 4.84 times more citations than scientists who do not utilize these technologies 11.
Furthermore, this adoption has been shown to alter traditional career trajectories; junior scientists utilizing automated analytical tools transition to principal investigator or independent research roles an estimated 1.37 years earlier than non-adopting peers, holding a 45% probability of transitioning to established status 11. Team compositions are concurrently shifting in response to automated productivity. Augmented research projects are associated with smaller team sizes - averaging 1.33 fewer scientists - largely due to a 31% reduction in the requirement for junior scientists and research assistants who traditionally handled routine data cleaning, literature screening, and preliminary coding 11.
Discovery Gains in the Biological and Medical Sciences
Beyond process optimization, predictive models are directly generating novel scientific discoveries. By identifying complex, high-dimensional patterns in vast datasets that exceed human cognitive processing limits, these architectures have achieved breakthroughs across multiple biological and pharmaceutical domains.
Protein Structure Prediction and Biomolecular Mapping
The life sciences have experienced one of the most profound technological transformations, driven primarily by structure-aware, physics-informed models. The historical challenge of determining the three-dimensional structure of proteins from one-dimensional amino acid sequences - a process that previously required costly and slow experimental techniques like X-ray crystallography - was fundamentally resolved by deep learning models. Systems such as AlphaFold, and subsequent iterations including AlphaFold 3 and ESM3, have expanded these capabilities to predict highly complex interactions between proteins, DNA, and other biomolecules 1213. The magnitude of this breakthrough was recognized globally when the developers of the AlphaFold architecture were awarded the 2024 Nobel Prize in Chemistry 1214.
Further refinement of these tools has focused on integrating rigid algorithmic prediction with the dynamic laws of physics. Methodologies such as AlphaFold2-RAVE (AF2RAVE) fuse machine learning predictions with advanced thermodynamic computer simulations, allowing researchers to predict not just the static shape of a protein, but its multiple configurations and non-native structures, which is critical for targeting complex diseases at the cellular level 15.
Pharmaceutical Development and Diagnostics
In the pharmaceutical sector, structural knowledge translates into tangible reductions in drug discovery timelines. Traditional drug development relies heavily on intuition-driven heuristics and trial-and-error laboratory synthesis. Advanced models, specifically Large Quantitative Models (LQMs), are now utilized for hit triage, lead optimization, and early safety screening, effectively pruning vast chemical search spaces before physical synthesis occurs 16. Major pharmaceutical entities have documented these operational gains: AstraZeneca's proprietary generative framework, Reinvent, has reduced the time required to identify lead molecular structures by 50%, contributing to an overall expected 30% reduction in cycle times across clinical trial design and drug discovery 17.
Diagnostic capabilities have similarly advanced. In oncology, diagnostic models evaluating histopathological slides have identified metastatic cancers with up to 98% accuracy, a level of precision that standardizes diagnostics and predicts patient responses to specific treatments 18. In infectious disease research, tools pairing bacterial cytological profiling with deep learning - such as the MycoBCP system developed at UC San Diego - can detect microscopic cellular changes in tuberculosis pathogens that escape human observation, fast-tracking the development of urgently needed therapies 19. Similar predictive techniques have been utilized to discover the hidden "moonlighting" role of the PHGDH gene in triggering Alzheimer's disease by disrupting brain cell gene expression 19.
Discovery Gains in the Physical and Environmental Sciences
In the physical sciences, the search for novel, stable compounds for infrastructure, energy storage, and environmental remediation has been historically constrained by the slow pace of physical synthesis. The application of predictive algorithms has dramatically expanded the catalog of theoretical materials.
Materials Science and Automated Experimentation
Models such as GNoME (Graph Networks for Materials Exploration) have rapidly advanced the field of crystallography and solid-state chemistry. Deep learning architectures have successfully predicted over 11,630 new, stable two-dimensional materials and identified dozens of potential high-temperature superconducting materials 20. The Royal Society noted in its 2024 assessment that machine learning has directly facilitated the discovery of new "invar alloys" characterized by extremely low thermal expansion, as well as novel solid-state battery components 20.
The integration of these algorithms with automated physical infrastructure - often termed "self-driving laboratories" - further accelerates this field. By pairing machine learning with automated robotic synthesis platforms, systems can autonomously design an experiment, physically mix chemical reagents, analyze the resulting compound, and use the feedback to optimize the subsequent iteration. This closed-loop automated experimentation reduces the timeline from conceptualization to commercialization from decades to years, lowering the cost per experiment significantly while maximizing yield and efficiency 20.
Climate Modeling and Disaster Prediction
Environmental and atmospheric sciences have utilized deep learning to fundamentally restructure forecasting methodologies. Models trained on massive troves of historical meteorological data, such as GraphCast and GenCast, have demonstrated the ability to forecast extreme weather events with greater speed and accuracy than traditional supercomputer models relying strictly on thermodynamic equations. These systems accurately predicted the precise trajectory and impact of major hurricane events days ahead of conventional methods 182122.
In geophysics, algorithms have demonstrated emerging capabilities in predictive disaster monitoring. A longitudinal trial of a predictive model utilizing real-time seismic data and statistical anomalies successfully predicted 70% of earthquakes a week in advance, a milestone in a field where exact disaster forecasting has remained notoriously elusive 23. Similarly, researchers in regions prone to extreme weather, such as Japan and Saipan, are utilizing combinations of satellite imagery, environmental data (including phytoplankton concentrations and wave height), and deep learning to reduce the computational time required to calculate flood inundation extents from days to a matter of minutes 242526.
Innovations in the Social Sciences and Humanities
While historically reliant on qualitative assessment and structured human surveys, the social sciences are increasingly leveraging large language models and computer vision to parse unstructured historical data at scales previously deemed impossible.
Digitization and Archival Extraction
Researchers utilize generative text models to digitize, extract, and categorize massive archival datasets that defy conventional analysis. For instance, economists mapping 16th-century transatlantic immigration utilizing large language models reduced the processing time for transcribing and extracting genealogical links from historical Spanish ship manifestos from hours per record to minutes, condensing a multi-decade project into a few years 27.
Political scientists have similarly employed automated systems to extract structured voting endorsements from decades of scanned historical newspapers, correcting severe optical character recognition errors and instantly tabulating the data 27. In legal and sociological research, algorithms have been utilized to extract and process vast amounts of unstructured text from foreign-language legal proceedings - such as tens of thousands of Chinese child custody and property dispute records spanning nearly a decade - achieving accuracy rates exceeding 90% and reducing project timelines from years to months 27. Other novel applications include extracting textual data from historic papal bulls to map the implementation of social policies across the early modern era 8.
Simulated Participants and Agent-Based Modeling
Advanced language models are increasingly being investigated as simulated proxies for human behavior. By generating synthetic survey responses or acting as simulated agents in agent-based models, researchers attempt to theorize social dynamics, consensus building, and political persuasion without the immediate logistical constraints or financial costs of human subject recruitment 828.
Experimental research has demonstrated that algorithmic models can effectively simulate language acquisition in children, providing a controlled experimental environment to study cognitive processes that are ethically or logistically difficult to observe in human subjects 27. Furthermore, experiments utilizing generative models as arbiters in political discussions have suggested that these systems can be more effective at finding consensus between polarized groups of individuals than the human participants themselves 8. However, the epistemological validity of treating synthetic text outputs as equivalent to human sociological data remains a subject of intense academic and ethical debate, as models frequently fail to capture the nuanced, often irrational realities of genuine human cognition 828.
Epistemic Risks and Systemic Methodological Challenges
The rapid integration of autonomous analytical tools into scientific inquiry has introduced severe, systemic epistemic risks. While metrics of output and efficiency rise, the qualitative rigor and diversity of scientific understanding may be paradoxically degrading.
Scientific Monocultures and Topic Contraction
A critical vulnerability identified in recent scientometric analyses is the contraction of collective scientific focus. While individual researchers produce more papers, the breadth of topics being explored across science is narrowing. Bibliometric studies indicate a 4.63% contraction in the overall volume of scientific topics studied following widespread algorithm adoption 11. This phenomenon is driven by data availability bias; modern models require massive, pre-existing datasets for training. Consequently, research disproportionately coalesces around these data-rich topics, ignoring critical but under-documented phenomena - a statistical correlation that has intensified significantly in the era of large foundational models 11.
This dynamic fosters a process termed "collective hill-climbing," wherein the scientific community utilizes algorithms to optimize and automate existing fields of inquiry rather than generating entirely new scientific domains or theoretical frameworks. The result is a highly overlapping research landscape characterized by a high GINI coefficient for citations, indicating a "Matthew Effect" where a small fraction of augmented papers dominates the citation network while broader exploratory research languishes 11. Furthermore, algorithmically-supported papers exhibit a substantially higher retraction rate across most fields, underscoring the severe risks of automated data generation and lax methodological oversight 611.
The Royal Society's 2024 "Science in the Age of AI" report highlights additional structural barriers, noting that the black-box nature of proprietary tools severely limits the reproducibility of research 2029. Barriers such as insufficient documentation, lack of explainability, and the contamination of datasets through artificial data generation (data poisoning) make it exceedingly difficult for independent researchers to scrutinize, verify, and replicate experiments 20.
The Four Visions of AI and Illusions of Understanding
In a highly cited 2024 analysis published in Nature, anthropologists and cognitive scientists categorized the core epistemic risks of algorithmic science, noting that these tools exploit human cognitive biases to create "illusions of understanding" 303136.
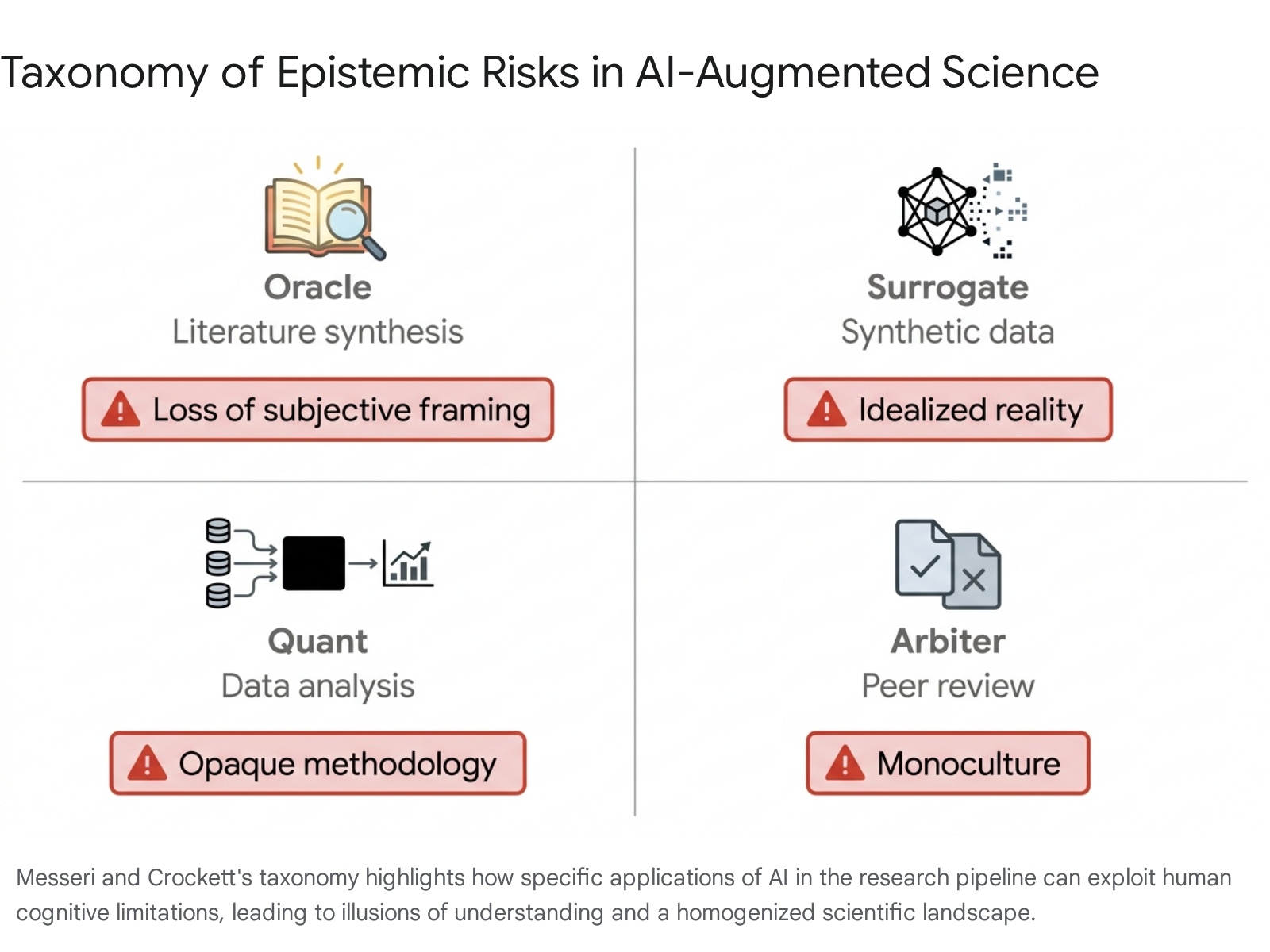
Because humans possess a natural cognitive preference for simple, quantifiable explanations, the fluent and highly structured outputs of modern systems can convince researchers that they understand a complex biological or social phenomenon deeply, even when the underlying causal mechanisms remain entirely opaque.
The authors categorize the integration of algorithmic systems into science into four distinct visions, each carrying specific systemic risks 3732:
- The Oracle: The vision of the system digesting exhaustive literature to communicate universal truths. The risk lies in automation bias, where users defer to synthesized consensus, losing the subjective, divergent framing that often sparks paradigm shifts.
- The Surrogate: The use of algorithms to generate synthetic data or simulate human subjects. The risk is an over-reliance on idealized, algorithmic approximations of reality that fail to capture biological or social anomalies.
- The Quant: The deployment of systems for data preparation and statistical analysis. The risk involves delegating analytical rigor to opaque black-box systems, rendering reproducibility and methodological verification virtually impossible.
- The Arbiter: The use of automated systems to screen manuscripts and conduct peer review. The risk is the enforcement of a rigid scientific monoculture, where algorithms trained on past successful paradigms systematically reject highly novel or heterodox research 3732.
If left unmitigated, these risks threaten a future scientific ecosystem characterized by high production but shallow comprehension - producing a vast quantity of papers and optimized materials while fundamentally understanding less about the intricacies of the natural and social world 3031. This aligns with findings indicating a growing interdisciplinary disconnect; computer scientists are increasingly attempting to solve complex social and ethical problems using code alone, while becoming increasingly insulated from the theoretical rigor of the social sciences and humanities 33.
Geopolitical Strategies and Infrastructure Development
The capacity to accelerate scientific discovery via predictive algorithms is increasingly viewed as a critical component of national security, economic sovereignty, and geopolitical influence. Consequently, the global landscape of scientific research is currently defined by massive state investments, infrastructural development, and shifting publication dominance.
| Nation / Region | Primary Strategic Focus | Key Infrastructure & Policy Initiatives |
|---|---|---|
| China | National-scale integration and volume dominance | ScienceOne 100 research platform; Distributed innovation ecosystem across 150+ institutions |
| Japan | Labor-saving automation and hardware integration | 10 Trillion JPY investment; Fugaku supercomputer; Maholo humanoid wet-lab robots |
| United States | Democratization of compute and fundamental research | NAIRR Pilot; NSF CloudBank; $700M+ annual fundamental research investment |
Table 2: Comparison of national strategic priorities and infrastructural investments aimed at dominating next-generation scientific research 3441353637.
China's Research Pre-eminence
In recent years, China has systematically positioned itself as the pre-eminent world power in terms of publication volume and patent generation. By integrating algorithmic tools into a "nationwide innovation ecosystem," China produced 273,900 related academic publications in 2024, representing an output that matched the combined totals of the United States, the United Kingdom, and the European Union 383940. The scope of this research apparatus is massive; China possesses an estimated 30,000 active researchers in the field, and in 2024, 156 separate Chinese institutions published more than 50 relevant papers each, indicating a distributed, national-scale capability that contrasts with the geographically clustered, elite research hubs typical of Western nations 3840.
The Chinese Academy of Sciences has reinforced this systematic integration by deploying "ScienceOne 100," a foundational model specifically designed to support multi-disciplinary scientific research. Deployed across more than 50 institutes, the platform operates as an "agent factory" equipped with over 2,000 tools for automated literature analysis, hypothesis testing, and complex simulation, heavily accelerating discoveries in materials, aerospace, and environmental research 34. While the United States continues to hold a slight lead in the percentage of global citation attention for papers in top-tier journals, China entirely dominates patent filings 3940.
Japan's Automation and Infrastructure Pivot
Faced with a steadily declining population and severe manpower shortages across industrial and scientific sectors, Japan has implemented aggressive state policies to utilize robotics and autonomous systems for labor-saving scientific advancement. In late 2024, the Japanese government announced a 10 trillion JPY investment aimed at the semiconductor and autonomous technology industries through 2030, projecting an eventual 160 trillion JPY economic impact 41.
A central pillar of Japan's strategy is the integration of predictive algorithms with advanced robotics to automate wet-lab biology and chemistry experiments. Institutions such as the Institute of Science Tokyo have deployed "Maholo" humanoid robots, co-developed with the National Institute of Advanced Industrial Science and Technology (AIST). Equipped with visual processing and decision-making capabilities, these robots perform highly complex biological sample handling continuously. Researchers estimate that by eliminating human error, physical fatigue, and procedural inconsistencies, these automated systems can speed up fundamental scientific experimentation by a factor of 10 to 100 35.
Additionally, Japan is leveraging its high-performance supercomputing infrastructure, notably the Fugaku supercomputer, to train advanced scientific models. Programs such as RIKEN's "TRIP-AGIS" are developing domain-specific foundation models to autonomously drive research processes by linking data, robotics, and simulation 41. To support these advancements, the state-backed Japan University Fund utilizes vast investment returns to distribute billions of yen in grants specifically targeting international research excellence and doctoral support 42.
The United States and Cyberinfrastructure Democratization
The strategy of the United States focuses heavily on maintaining its historical lead in cutting-edge foundation models - largely driven by massive private sector entities - while simultaneously democratizing access to expensive computing power for academic researchers. The National Science Foundation (NSF) leads this public sector initiative, managing an annual investment of over $700 million dedicated to fundamental research, with specific allocations for specialized research institutes focusing on agriculture, biotechnology, and cybersecurity 3637.
A cornerstone of the U.S. strategy is the implementation of the National Artificial Intelligence Research Resource (NAIRR). Initiated as a pilot program in 2024 following presidential executive orders, the NAIRR functions as a shared national cyberinfrastructure designed to provide essential computational resources, massive datasets, and software platforms to researchers and students who operate outside well-funded corporate technology hubs 3743.
Programs like CloudBank further facilitate this by simplifying academic access to public commercial clouds 37. By bridging the compute-deficit in academia, and implementing initiatives like ExpandAI to broaden interdisciplinary participation, the U.S. aims to ensure that foundational scientific research - which often yields lower immediate commercial returns but exceedingly high long-term societal value - is not completely monopolized by private industry 3743.
Conclusion
The application of autonomous analytical tools to scientific research is yielding undeniable dividends in productivity and computational discovery. The chronological constraints required to map intricate protein structures, identify novel industrial materials, model highly complex climate phenomena, and synthesize vast bodies of historical literature have been compressed by orders of magnitude.
However, as early longitudinal data indicates, the scientific community is entering a highly precarious phase of methodological transition. The rapid acceleration of paper output and citation velocity masks a troubling contraction in the diversity of scientific inquiry, as research clusters densely around data-rich, computationally friendly topics. If researchers succumb to the illusions of understanding generated by highly persuasive but structurally opaque models, the scientific enterprise risks sacrificing deep, causal exploration for optimized, automated output. To ensure that these technologies act as an authentic catalyst for human knowledge rather than a homogenizing force that enforces a rigid methodological monoculture, the future of science will require strict transparency regarding training data, the maintenance of rigorous human peer review, and continuous, intentional cross-disciplinary collaboration between engineers, ethicists, and domain experts.