Graph Neural Networks
Introduction to Graph Representation Learning
Graph Neural Networks represent a fundamental shift in machine learning, enabling the direct processing of non-Euclidean, relational data structures. Unlike traditional deep learning architectures designed for grid-like data such as two-dimensional images or sequential data such as natural language text, graph neural networks operate natively on mathematical graphs consisting of nodes and edges 12. This structural flexibility allows these networks to mathematically model complex, interrelated systems ranging from molecular chemistry and protein folding interactions to large-scale social networks, transportation grids, and commercial recommendation engines 345.
The primary challenge in analyzing graph data historically stemmed from its mathematical irregularity. Graphs vary wildly in size, exhibit complex topological structures, and lack a fixed coordinate system or natural ordering of nodes 13. Consequently, any machine learning model applied to them must be permutation invariant; the model's output must remain identical regardless of the arbitrary order in which the nodes are presented to the algorithm 36. Early approaches to graph machine learning relied on spectral methods that utilized the eigendecomposition of the graph Laplacian 7. While mathematically elegant, these spectral filters were computationally expensive and tightly bound to the specific graph structure on which they were trained, severely limiting their generalizability to new, unseen graphs 7.
Modern graph neural networks resolve these limitations by operating directly in the spatial domain 78. By passing feature information along the physical edges of the graph, these models iteratively build complex representational embeddings of local and global topologies 15. This paradigm shift has catalyzed rapid advancements across multiple scientific disciplines, shifting the focus of artificial intelligence research toward systems capable of relational reasoning and structural understanding 24.
The Message Passing Neural Network Framework
The dominant paradigm for spatial graph learning was formalized by Gilmer et al. in 2017 through the introduction of Message Passing Neural Networks 65. This framework abstracted prior variants of graph convolutional networks into a single, unified mathematical workflow consisting of three differentiable phases: message generation, aggregation, and state updating 611.
Information propagates through a graph by allowing each node to generate a message based on its features and edge attributes, which is then aggregated by its neighbors using a permutation-invariant function before passing through an update network 511. In standard implementations, this manifests as a three-stage horizontal flow: a focal node receives feature vectors from its immediate structural neighbors, an aggregation operation (such as a sum, mean, or maximum) compiles these vectors into a single localized representation, and a neural update function yields the final state embedding 1112.
Mathematical Formalism of Message Passing
In this formalism, a graph is defined mathematically as $G = (V, E)$, consisting of a set of vertices $V$ with node features $x_v$, and a set of edges $E$ with edge features $e_{vw}$ 612. During the message-passing phase, which operates iteratively over $T$ time steps or network layers, each node computes a localized message to send to its connected neighbors 6.
The message function, denoted as $M_t$, typically conditions jointly on the sender's hidden state ($h_w^t$), the receiver's hidden state ($h_v^t$), and the specific features of the edge connecting them ($e_{vw}$) 36. This is expressed as $m_v^{t+1} = \sum_{w \in N(v)} M_t(h_v^t, h_w^t, e_{vw})$, where $N(v)$ represents the immediate neighborhood of the target node $v$ 3. The actual computation of these messages is frequently parameterized by a differentiable neural network, allowing the model to learn the optimal way to transform adjacent node features into communicable signals 36.
Once messages are generated across the entire graph, each node collects the incoming messages from its local neighborhood. Because a node may have an arbitrary number of neighbors, and because graph data lacks a canonical ordering, this aggregation step must be strictly permutation invariant 3611. Standard aggregation functions include summation, averaging, or maximization 5116. Summation, in particular, has been shown to retain more structural information than averaging, which can inadvertently obscure the topological degree of a node 86.
Following aggregation, the update function processes the aggregated message vector alongside the node's previous hidden state to produce a new hidden state for the subsequent layer, defined mathematically as $h_v^{t+1} = U_t(h_v^t, m_v^{t+1})$ 35. This update module is typically parameterized by a neural network, such as a multi-layer perceptron or a Gated Recurrent Unit, enabling non-linear transformations of the aggregated structural data 3.
With each successive layer of message passing, a node incorporates information from further distances within the network. A single layer allows a node to process information from its immediate neighbors, while a network with a depth of $K$ layers allows each node to compute a representation based on its $K$-hop neighborhood 127. Finally, for tasks that require predictions at the macroscopic graph level - such as predicting the toxicity of a full molecule rather than the specific property of a single atom - a readout function aggregates the hidden states of all nodes in the graph into a single, global feature vector: $\hat{y} = R({h_v^T })$ 36. This readout phase, like the neighborhood aggregation phase, relies on permutation-invariant operations to ensure that the final prediction is unaffected by the arbitrary ordering of the input nodes 6.
Expressivity and the Weisfeiler-Lehman Hierarchy
As graph neural networks proliferated across diverse scientific disciplines, researchers sought rigorous mathematical frameworks to evaluate their expressive power - specifically, their theoretical ability to determine whether two graphs are topologically identical or non-isomorphic 8910. The standard theoretical benchmark for this capacity is the Weisfeiler-Lehman graph isomorphism test, a foundational algorithm originating from graph theory and logic 8111220.
Theoretical analyses have definitively proven that the standard message passing architecture is strictly upper-bounded by the 1-dimensional Weisfeiler-Lehman (1-WL) test 111213. The 1-WL algorithm operates by iteratively refining node colors (representing discrete labels or continuous feature vectors) based on the multiset of colors present in each node's immediate neighborhood 1011. If two distinct graphs cannot be distinguished by the 1-WL test, they will inherently yield identical embeddings in any standard graph neural network, regardless of the network's depth, width, or extensive training duration 822.
This limitation means that conventional message passing networks cannot detect certain higher-order structural regularities 1314. For instance, a 1-WL bounded network cannot easily distinguish between certain regular graphs or identify the presence of specific closed cycles (loops) versus chords, which are vital topological markers for understanding complex organic molecules or identifying tightly knit cliques within social networks 1113.
The k-Dimensional Weisfeiler-Lehman Test
To transcend these severe limitations, researchers have developed higher-order graph neural networks explicitly aligned with the $k$-dimensional Weisfeiler-Lehman ($k$-WL) hierarchy 1012. The 3-WL test, for example, operates by iteratively refining the coloring of all triples of vertices in a graph simultaneously, allowing it to capture highly intricate multi-node substructures that remain entirely invisible to 1-WL and 2-WL algorithms 1011.
Neural network variants designed to mimic the $k$-WL process process tuples of nodes rather than individual nodes, mathematically guaranteeing greater expressive power 201516. Architectures such as Invariant Graph Networks ($k$-IGN) have been mathematically proven to be as expressive as the $k$-WL test, providing a theoretical ceiling for spatial graph learning 16.
However, scaling theoretical expressivity comes at a prohibitive computational cost. Higher-order models aligned with 3-WL or beyond require cubic or even exponential memory and time complexity relative to the number of nodes, rendering them largely impractical for massive real-world datasets containing millions of edges 1011. To address this, hybrid frameworks such as the $(k, c)^{(\le)}$-SETWL hierarchy have been proposed, which attempt to reduce complexity by moving from rigid $k$-tuples to subsets defined over connected components, offering a more gradual expressiveness-complexity tradeoff 10. Similarly, the Neighbourhood WL ($N$-WL) hierarchy proposes equivalence structures based on induced connected subgraphs to bypass the combinatorial explosion of standard tensorized $k$-WL variants 917.
Message Passing Complexity and Practical Expressivity
Recent critiques within the geometric deep learning field suggest that the strict focus on isomorphism-based expressivity may be fundamentally misaligned with practical engineering goals. Many real-world classification tasks do not require graphs to be strictly distinguishable beyond the 1-WL level 1022. Datasets frequently exhibit natural variations that make extreme isomorphism detection redundant 10.
Instead, alternative frameworks such as Message Passing Complexity (MPC) have been proposed. This continuous measure quantifies the actual difficulty of solving a specific task through iterative message passing 22. Unlike the Weisfeiler-Lehman hierarchy, which assumes idealized conditions such as lossless information propagation over unbounded network layers, the MPC framework accounts for practical limitations like information bottlenecks and over-squashing - phenomena that severely degrade network performance long before theoretical expressivity limits are reached 22. By shifting focus from binary distinguishability to continuous message passing difficulty, researchers aim to design architectures that perform better on noisy, real-world benchmarks 1022.
Higher-Order Topological Graph Data Models
An alternative approach to scaling expressivity without incurring the combinatorial explosion of $k$-WL tuple algorithms involves fundamentally altering the underlying data structure from a standard node-and-edge graph to a higher-dimensional topological space. This burgeoning subfield, known as Topological Deep Learning, maps traditional graphs onto complex mathematical structures such as simplicial complexes or regular cell complexes 8142728.
Simplicial Complexes and Cell Networks
In a standard graph, interactions are strictly dyadic, defined exclusively by pairwise edges connecting exactly two vertices 1429. Simplicial Neural Networks and Cell Complex Networks generalize this paradigm by encoding polyadic, multi-node interactions directly into the physical topology of the space 273018.
Within these architectures, vertices are treated mathematically as 0-dimensional cells, and edges are mapped as 1-dimensional cells. Higher-order interactions are modeled by introducing 2-dimensional cells (surface areas or faces bounded by cycles of edges, such as triangles or polygons) and 3-dimensional cells (solid volumes, such as tetrahedrons) 282930.
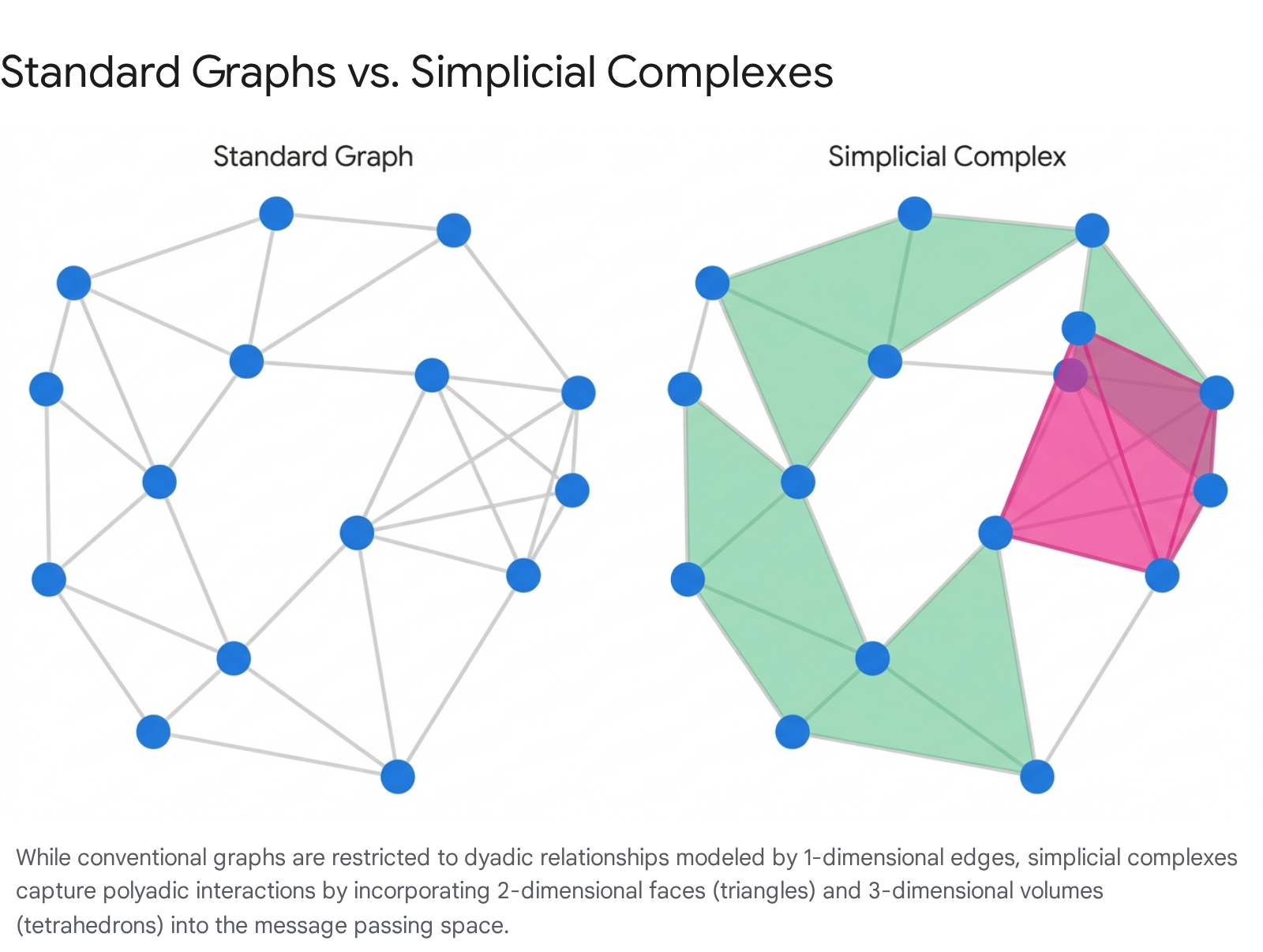
By lifting a graph into a cell complex - for example, by algorithmic identification of all chordless cycles of length three and attaching a 2D cell to each - the neural network is provided with a structural representation that naturally bypasses traditional message passing bottlenecks 82730. Message passing in a simplicial complex does not merely occur between nodes across edges; it dynamically flows between edges across shared faces, or between faces across shared volumes 28.
This allows the architecture to natively respect the homology of the data, rapidly identifying voids, cavities, and higher-dimensional connections that signal vital topological features 1328. For example, a Cell Complex Neural Network can immediately recognize that three nodes forming a closed triangle represent a fundamentally different chemical or structural signal than three individual nodes connected in a linear, tree-like chain, as the former can be mathematically encapsulated and processed as a single 2D entity 1327.
Cellular Weisfeiler-Lehman Framework
The Cellular Weisfeiler-Lehman (CWL) framework governs the mathematics of message passing on these structures 8. To execute these operations, traditional adjacency matrices are replaced by more complex incidence matrices or boundary matrices, which dictate how lower-dimensional cells bind to higher-dimensional geometries 2832.
Frameworks such as FORGE (Framework For Higher-Order Representations In Graph Explanations) utilize these representations to enhance the interpretability and performance of graph models on complex tasks, mapping output explanations back to the original graph 1432. While transforming a graph into a cell complex introduces a minor preprocessing overhead, integrating these complex incidence matrices into message passing layers yields network architectures that are strictly more expressive than the 1-WL test 832. Crucially, they maintain superior computational scalability compared to native 3-WL algorithmic implementations, offering a highly practical middle ground for advanced topological learning 828.
Architectures for Three-Dimensional Molecular Modeling
While topological complexes address structural expressiveness, the application of graph neural networks to atomistic modeling, pharmaceutical drug discovery, and physical chemistry simulations necessitates strict adherence to geometric physical symmetries 333419. Molecules are essentially three-dimensional graphs embedded in Euclidean space, where atoms serve as nodes, chemical bonds serve as edges, and their exact spatial coordinates dictate the system's potential energy surfaces and kinetic dynamics 33336.
Standard message passing networks are invariant to node permutation, but they are not inherently equipped to handle continuous geometric transformations 2036. If a molecule is rotated or translated in three-dimensional space, its underlying physical properties remain identical, but its raw Cartesian coordinate data changes drastically 37. To ensure robust and accurate prediction under arbitrary reference transformations, graph networks operating on physical data must explicitly encode Special Euclidean group SE(3) equivariance 333438. Equivariance ensures that the model's internal hidden feature representations transform predictably when the input coordinates are subjected to continuous 3D rotations, ensuring mathematical fidelity to the physical world 203738.
Distance Invariance Versus Geometric Equivariance
Early approaches to geometric graph learning achieved stability through scalarization; they achieved structural invariance by reducing raw 3D coordinates into a matrix of pairwise Euclidean distances between atoms 1936. While computationally efficient and strictly invariant, distance-only models discard vital angular information and multi-body geometric interactions 3637.
This scalarization severely limits their ability to distinguish molecules that share identical pairwise distances but differ in their absolute 3D conformation, such as chiral molecules which are mirror images of one another but possess vastly different biological activities 363720.
Tensor Field Networks and the SE(3)-Transformer
State-of-the-art equivariant architectures resolve this by processing vector spaces of irreducible representations (irreps) rather than scalar distances 3338. Models such as Tensor Field Networks and the SE(3)-Transformer decompose network filters into learnable radial functions and fixed angular components utilizing spherical harmonics 3738.
In these architectures, message passing between nodes occurs via the Clebsch-Gordan tensor product 3321. This mathematical operation combines equivariant values with invariant weights to produce an output that strictly preserves SE(3) equivariance at every hidden layer of the neural network 3738. This approach has yielded significant performance increases on benchmark datasets such as QM9, predicting complex quantum chemical properties with high precision 3738.
| Architecture Constraint | Symmetry Handled | Primary Mathematical Mechanism | Expressive Limitation |
|---|---|---|---|
| Standard MPNN | Permutation | Permutation-invariant neighborhood aggregation | Blind to geometric orientation and absolute spatial coordinates. |
| Distance-Invariant GNN | Translation, Rotation | Pairwise Euclidean distance scalarization | Fails to distinguish identical distance geometries with different angular layouts. |
| SE(3)-Equivariant GNN | Translation, Rotation | Spherical harmonics and Clebsch-Gordan tensor products | High computational complexity restricts the maximum degree of representations. |
Advanced Equivariant Architectures
The intense computational complexity of taking tensor products historically restricted the maximum degree of equivariant representations these networks could feasibly process, limiting their application to massive molecular systems 33. Recent architectural advancements aim to decouple this complexity to scale up physical simulations 3334.
For instance, the EquiformerV3 architecture explicitly decomposes complex $SO(3)$ tensor products during the message passing phase into simpler rotation layers and $SO(2)$ linear layers 33. This model introduces specialized SwiGLU-$S^2$ activation functions to model complex many-body interactions while preserving strict equivariance 3341. By reducing the complexity of sampling $S^2$ grids and employing attention mechanisms with smooth radius cutoffs, EquiformerV3 achieves significant algorithmic speedups (up to 1.75x) over previous generations, allowing for accurate modeling of smoothly varying potential energy surfaces 3341.
Other frameworks bypass standard tensor products by generating equivariant local complete frames 3421. These models establish localized orthonormal bases that inherently avoid direction degeneration 3421. By projecting tensor information directly onto these local frames, the network can be built entirely through computationally efficient cross-product operations, ensuring high expressiveness with a much lower hardware footprint 3421.
Scalability and Subgraph Sampling Paradigms
Beyond theoretical expressiveness and geometric equivariance, deploying graph neural networks on industrial-scale datasets presents severe infrastructural bottlenecks 224323. Real-world network data - such as multi-million-node social networks, vast e-commerce recommendation systems, or billion-edge citation graphs like the ogbn-papers100M dataset - cannot fit into standard GPU memory limits 222324.
The central obstacle preventing scalable deployment is the "neighbor explosion" phenomenon 4323. In traditional full-batch training, computing the final embedding for a single target node in a $K$-layer graph network requires recursively fetching the embeddings of its neighbors, its neighbors' neighbors, up to $K$ hops away 432547. In dense, scale-free networks, this receptive field grows exponentially with network depth, rapidly exhausting available memory and creating massive, highly redundant computations across standard mini-batches 4323. To mitigate this, several advanced sampling methodologies have been developed to construct tractable, memory-efficient computation graphs.
| Sampling Methodology | Core Mechanism | Primary Computational Advantage | Known Limitations |
|---|---|---|---|
| Layer-Wise Sampling (GraphSAGE) | Randomly samples a fixed number of neighbors per node at each forward pass layer. | Enables inductive learning on new nodes; restricts immediate fan-out. | Recursive expansion can still cause exponential growth in deep networks; gradient variance. |
| Subgraph Sampling (GraphSAINT) | Extracts a fully connected localized subgraph before the forward pass begins. | Cost scales linearly with depth; eliminates recursive neighbor explosion. | Requires strict normalization to correct sampling bias during gradient estimation. |
| Decoupled Scope (ShaDow-GNN) | Decouples network depth from neighborhood scope; applies deep networks to shallow subgraphs. | Prevents over-smoothing while drastically reducing inference computation costs. | Subgraph extraction overhead; requires tuning of extraction algorithms (e.g., PPR). |
Layer-Wise Neighborhood Sampling
GraphSAGE addresses neighbor explosion by randomly sampling a fixed number of neighbors for each node at each individual layer of the forward pass 7843. Rather than expanding the computation graph exhaustively, GraphSAGE processes standard mini-batches of target nodes and only aggregates information from the truncated sample 843.
This methodology introduces a powerful inductive capability: it allows the model to generate accurate embeddings for newly introduced nodes (or entirely unseen graphs) based solely on their sampled neighborhood, making it highly effective for rapidly evolving networks 8. However, because GraphSAGE still samples outward layer-by-layer during the forward pass, deep networks can still trigger exponential fan-out, and the disjoint sampling process can introduce significant variance into gradient estimates during training 43.
Graph-Level Subgraph Sampling
To completely halt exponential expansion, frameworks like GraphSAINT discard layer-wise expansion in favor of global subgraph sampling 4323. Rather than sampling outward from a target node, GraphSAINT samples entire localized subgraphs from the broader network topology before executing the forward pass 4323.
GraphSAINT utilizes specific statistical sampling algorithms - such as random node sampling, random edge sampling, or random walk samplers - to extract a localized, manageable graph 4323. The entire multi-layer graph neural network is then executed strictly within the confines of this sampled subgraph 23. Because the computation graph is fixed and does not grow exponentially with depth, the computational cost per mini-batch scales linearly relative to the network architecture 23. GraphSAINT mitigates the inherent statistical bias of operating on incomplete subgraphs by applying rigorous normalization techniques during the backpropagation and gradient calculation phase, ensuring that the model accurately approximates the full-graph training distribution 4323.
Decoupled Scope Sampling
ShaDow-GNN identifies a structural inefficiency in standard message passing: a network's computational depth is inherently coupled to the physical size of the subgraph it operates on 432547. Historically, a three-layer network was forced to process a full three-hop neighborhood 25.
ShaDow-GNN successfully decouples the model depth from the subgraph scope 2547. It utilizes algorithms to extract a shallow, highly localized "shadow" subgraph around a target node, and then executes a deep neural network entirely within that constrained scope 2547. This approach proves mathematically that deeper graph convolutions can be applied to shallow, highly relevant local neighborhoods without triggering over-smoothing 2547. This targeted approach significantly reduces inference and training costs by orders of magnitude while maintaining or exceeding the expressiveness of full-batch baselines 2547.
Graph Transformers and Global Attention Mechanisms
While spatial message passing networks excel at capturing localized structural signals, their reliance on recursive neighborhood aggregation leads to critical failures when modeling long-range dependencies 264927. If critical information is separated by extensive topological path lengths, a message passing network requires numerous sequential layers to bridge the gap 27.
This depth leads to over-smoothing, a phenomenon where repeated Laplacian aggregations cause the node features across the entire graph to converge to indistinguishable mean vectors, completely destroying the model's predictive utility 254751. Furthermore, information propagating through dense network bottlenecks suffers from over-squashing, resulting in severe signal degradation as wide neighborhood data is compressed into fixed-size node vectors 13274951.
Graph Transformers were developed to bypass these physical bottlenecks by adapting the self-attention mechanisms of Natural Language Processing to structured network data 264951. Unlike a standard graph convolutional layer, which restricts information flow strictly to physical edges, a standard Graph Transformer treats every node as fully connected to every other node 262751. During the self-attention calculation, the model computes a similarity score between every possible pair of nodes, effectively establishing dynamic, data-driven pathways across the entire graph regardless of the topological distance separating them 2627.
Linearization and Hybridization
The primary obstacle to the widespread adoption of Graph Transformers is their massive computational complexity 262751. Standard all-to-all attention requires materializing an $N \times N$ attention matrix, scaling quadratically ($O(N^2)$) with the number of nodes 492751. This restricts dense Graph Transformers to exceptionally small datasets, primarily individual molecular graphs consisting of fewer than 100 atoms 2751.
To deploy global attention on massive networks, researchers have engineered scalable hybrid frameworks. The GraphGPS (General, Powerful, Scalable) architecture processes graphs in parallel, routing node features through both a standard local message passing layer and a global attention layer 264951. By utilizing linear approximations of the softmax attention matrix (such as the Performer architecture, which utilizes random feature maps), GraphGPS reduces the quadratic complexity to a linear scaling factor ($O(N)$), preserving global context without exhausting GPU memory 2651.
Anchor-Based and Maximum Inner Product Attention
Alternative variants rely on advanced sampling and mathematical algorithms to limit the scope of attention computations. The AnchorGT model, for example, selects a small, mathematically rigorous subset of highly influential "anchor" nodes (a $k$-dominating node set) 4952. Standard nodes only compute attention scores relative to these sparse anchors rather than every other node, granting the model a global receptive field at a fraction of the computational cost ($O(K \times N)$) 52.
Similarly, $k$-Maximum Inner Product ($k$-MIP) attention utilizes symbolic matrices to identify and process only the most relevant attention scores, accelerating computation by an order of magnitude compared to full attention 49. While technically remaining computationally quadratic in the worst case, empirical implementations of $k$-MIP enable the processing of massive city-scale networks comprising over 500,000 nodes on a single modern GPU 49.
Structural and Positional Encodings
Because the core self-attention mechanism inherently ignores graph topology by treating all nodes as a fully connected set, Graph Transformers must be artificially injected with positional and structural encodings 1251. These encodings provide the mathematical context necessary for the model to differentiate between nodes that are structurally adjacent versus those that are disparate 5128.
Early implementations utilized Shortest Path Distance (SPD) encodings, which bias the computed attention scores based on the minimum number of graph hops between two nodes 5228. More sophisticated encodings, such as the Shortest Path Induced Subgraph (SPIS) technique, provide detailed topological profiles of the exact paths connecting nodes 2829.
The introduction of generalized frameworks, such as the SEG-WL test (Structural Encoding enhanced Global Weisfeiler-Lehman test) and the broader GT test, provide formal theoretical tools to measure the discriminative power of these encodings 2829. Theoretical findings confirm that when equipped with advanced encodings like SPIS, Graph Transformers possess structural discriminative power that mathematically exceeds that of standard graph neural networks and base Weisfeiler-Lehman tests 122829.
The Emergence of Graph Foundation Models
Driven by the monumental success of foundational Large Language Models (LLMs), the graph learning ecosystem is undergoing a rapid paradigm shift toward Graph Foundation Models (GFMs) 23056. Historically, graph neural networks have been highly specialized, disparate systems. A model trained to predict toxicological properties of a molecular graph could not be repurposed to detect fraudulent accounts in a financial transaction network 5758. The distinct feature spaces, varying data dimensionalities, and unique topological distributions of different graph datasets precluded meaningful cross-domain generalization 45859.
Graph Foundation Models attempt to resolve this fragmentation by unifying diverse graph datasets into a single, highly adaptable system capable of zero-shot and few-shot learning across fundamentally disjoint domains 245758.
Text-Attributed Graphs and Semantic Alignment
The core innovation enabling this cross-domain transferability is the widespread adoption of Text-Attributed Graphs (TAGs) 575831. In a TAG framework, raw numerical node and edge features are converted into descriptive natural language formats 575861.
For example, instead of feeding a graph neural network a sparse numerical vector representing an atom's charge and valency, the node is assigned a textual prompt explicitly describing its chemical state. Similarly, a node in a massive citation network is represented natively by the textual abstract of its corresponding academic paper 5731. A frozen, pre-trained Large Language Model is then utilized to encode these diverse textual descriptions into unified, high-dimensional semantic embedding vectors 57585931. This standardizes the feature space across all graphs; the downstream graph neural network no longer processes disparate numerical tensors, but rather a universal, aligned semantic language 616232.
Prominent Foundation Architectures
Several groundbreaking architectures have been introduced to capitalize on this unified format, demonstrating unprecedented flexibility 433.
| Foundation Model | Primary Alignment Strategy | Core Architectural Innovation | Generalization Capability |
|---|---|---|---|
| OFA (One-for-All) | Text-Attributed Graphs via LLM Embeddings | Nodes-of-Interest (NOI) prompt subgraph injection | Cross-domain classification (Supervised / Zero-shot) |
| UniGraph | Text-Attributed Graphs via cascaded LM + GNN | Masked Graph Modeling for self-supervised pre-training | Unseen domains via Graph Instruction Tuning |
| AnyGraph | Multi-domain structural expert training | Graph Mixture-of-Experts (MoE) with dynamic routing | Fast adaptation to heterogeneous graph distributions |
| GOFA | Interleaved GNN layers within frozen LLM | Generative graph language modeling | Generative multi-tasking (QA, Next-word, Retrieval) |
Frameworks like OFA (One-for-All) train a single graph backbone on a massive amalgamation of multi-domain graphs simultaneously 576134. To manage varying predictive objectives - such as node classification, link prediction, and entire graph categorization - OFA utilizes novel structural prompting techniques. It introduces the concept of a "Nodes-of-Interest" (NOI) prompt node, which is dynamically injected into the computation graph to specify the task, eliminating the need to architecturally alter the model's pooling layers for different types of predictions 575961.
The UniGraph architecture pushes this further by introducing self-supervised pre-training mechanisms 5831. UniGraph utilizes Masked Graph Modeling on massive Text-Attributed Graphs, followed by graph instruction tuning utilizing Large Language Models to enable true zero-shot prediction capabilities on entirely unseen datasets 5862.
Alternatively, models like AnyGraph handle extreme structural heterogeneity through a Graph Mixture-of-Experts (MoE) architecture 23536. Rather than forcing a single neural pathway to process both dense social clusters and linear chemical chains, the MoE architecture features multiple specialized expert subnetworks 236. An automated routing mechanism analyzes the incoming graph data and dynamically activates the specific experts best suited to process its unique structural patterns 23536.
Scaling Laws and Cross-Domain Generalization
As these models expand, researchers are documenting emergent properties. Models such as GraphBFF (Graph Billion-Foundation-Fusion) have successfully scaled to over 1.4 billion parameters, pre-trained on a billion graph samples 56. Extensive evaluations of these massive systems reveal the first neural scaling laws for general graphs: validation loss decreases predictably as either model capacity or training data scales 5636. These foundation models exhibit performance gains across zero-shot and few-shot settings that exceed previous state-of-the-art specialized models, proving that massive pre-training on generalized graph structures yields highly transferable relational intelligence 5637.
Benchmarking and the Institutional Ecosystem
To track the rapid evolution of these advanced architectures, the academic and industrial communities rely on rigorous standardized environments, most notably the Open Graph Benchmark (OGB) maintained by Stanford University 243839. The OGB provides large-scale, highly diverse datasets with realistic out-of-distribution evaluation splits, entirely replacing older, heavily saturated datasets (such as Cora or Citeseer) that failed to measure true generalization or scalability 2224.
Standardized Evaluation Metrics
For molecular property prediction and expressiveness testing, the ogbg-molhiv and ogbg-molpcba datasets serve as the primary proving grounds 2038. These benchmarks track the ability of networks to predict binary biological activities based on complex molecular scaffolds 20. Because class balance is often skewed in biological data, specific metrics are enforced: ogbg-molhiv is ranked by ROC-AUC scores, while ogbg-molpcba utilizes Average Precision (AP) 2038. Top-performing models on these highly competitive leaderboards, such as the Multi-RF Fusion + Multi-GNN architecture, achieve ROC-AUC scores approaching 0.8476 by heavily combining deep learning with optimized random forest ensembles 38.
Scalability and neighborhood sampling techniques are rigorously tested on the massive ogbn-papers100M dataset, a colossal directed citation graph containing over 111 million nodes and 1.6 billion edges 222440. Evaluating on this dataset demands massive multi-GPU infrastructural efficiency and advanced sampling logic, with current state-of-the-art models like GLEM+GIANT+GAMLP achieving over 70% test accuracy on multi-class node classification tasks 2240. Forecasting and reasoning abilities of Large Language Models augmented with graph data are increasingly tracked on platforms like ForecastBench, utilizing rigorous Brier Index scoring 72.
Global Research Landscape
The geographic distribution of innovation in graph representation learning reflects broader, highly competitive trends in global artificial intelligence 7341. Major industrial advancements in foundational modeling, global attention architectures, and geometric deep learning are heavily driven by United States-based entities, particularly Google DeepMind, OpenAI, Meta FAIR, and NVIDIA 75424378.
Conversely, leading research on highly scalable graph frameworks, Mixture of Expert models, and cross-domain foundation architectures is increasingly concentrated in Asian academic institutions and corporate labs 73414445. The AnyGraph foundation model, for instance, represents a direct collaboration between the Hong Kong University of Science and Technology (HKUST) and Tsinghua University, indicative of massive regional investments in graph capabilities 353646. Chinese corporate giants such as Alibaba, Tencent, and ByteDance are prominently featured across major benchmark leaderboards, deploying heavily optimized GNN variants for internal e-commerce and recommendation networks 384042.
European entities continue to contribute heavily to the mathematical and theoretical foundations of graph machine learning 7582. Institutions such as the Max Planck Institute, the Technical University of Munich, and the French National Centre for Scientific Research (CNRS) consistently lead research into topological expressivity constraints, message passing complexity, and cellular neural networks 227583. Collaborative networks like CAIRNE (Confederation of Laboratories for Artificial Intelligence Research in Europe) aim to unify these diverse European labs to maintain parity in the rapidly accelerating graph foundation model race 4582.