Generative engine optimization and AI search citations in 2026
The Evolution from Traditional Search to Generative Engines
The architecture of digital information discovery is undergoing a fundamental restructuring. For over two decades, digital visibility relied on traditional search engine optimization (SEO), a discipline organized around ranking web pages in a sequential list of hyperlinks to capture user click-throughs. By 2026, the proliferation of large language models (LLMs) and retrieval-augmented generation (RAG) frameworks has initiated a transition toward AI-powered search interfaces that synthesize direct, conversational answers from multiple sources 123. Analyst projections from Gartner forecast a 25% decline in traditional search volume by the end of 2026, accompanied by a potential 50% drop in organic traffic by 2028 as users increasingly rely on virtual agents and AI overviews 456.
This structural transition necessitated the development of a new optimization paradigm: Generative Engine Optimization (GEO). The discipline was formally introduced and empirically tested in a foundational 2024 paper published by researchers from Princeton University, Georgia Tech, the Allen Institute for AI, and IIT Delhi 21892. The researchers introduced the GEO-Bench dataset, evaluating 10,000 queries across 25 domains to measure how content modifications affect visibility in generative engines. The study demonstrated that optimizing for generative engines requires fundamentally different tactics than traditional SEO. While traditional SEO optimizes for algorithmic page ranking based on backlinks and keyword density, GEO focuses on structural extractability, semantic density, and entity relationships to ensure an LLM trusts and cites the content within its synthesized response 281112. The researchers recorded visibility improvements of up to 40% when content was explicitly engineered for AI synthesis through the inclusion of relevant statistics, authoritative citations, and fluency optimizations 6192.
In a RAG architecture, search engines do not merely return indexed pages; they decompose queries, retrieve document chunks, evaluate those chunks for factual relevance, and generate a cohesive answer while embedding citations 31314. Consequently, the objective of digital marketing has shifted from achieving the top position on a search engine results page (SERP) to becoming a structurally retrievable source that an AI system selects as a truth anchor 1531718.
Economic Implications of Artificial Intelligence Search
The integration of generative AI into search interfaces has created asymmetric traffic implications for digital publishers and brands. The prevalence of "zero-click" searches - where a user's query is fully satisfied on the results page without necessitating a click to an external website - has surged, accounting for approximately 64% of all searches 5. When Google displays AI Overviews (AIO), traditional organic click-through rates (CTR) decline significantly, with recorded drops ranging from 34.5% to as high as 61% 194212223.
However, for domains that successfully secure citations within these AI-generated responses, the traffic quality exhibits an unprecedented premium. While the absolute volume of outbound clicks from AI platforms is lower than that of traditional search engines, the conversion intent of those visitors is drastically higher. Data from early 2026 indicates that traffic referred directly from AI citations converts at an average rate of 14.2%, compared to the historical traditional organic search conversion baseline of 2.8% 134.
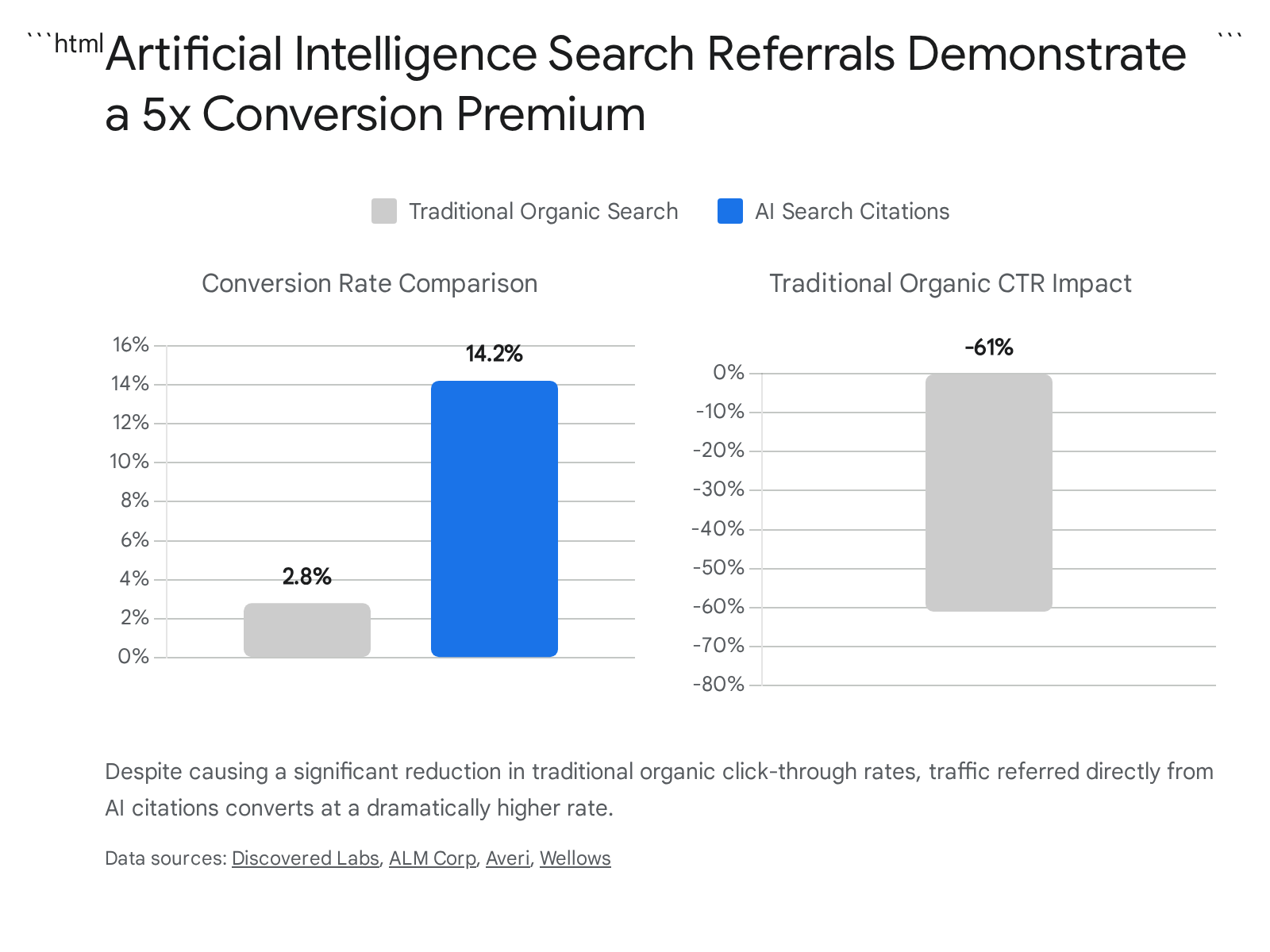
This quality premium occurs because the LLM performs the evaluative "mid-funnel" work on behalf of the user. By the time a consumer clicks a cited source in a platform like ChatGPT or Perplexity, the AI has already analyzed alternatives, synthesized the context, and implicitly endorsed the cited brand as the optimal solution 2425. Furthermore, visitors arriving via AI referrals spend 68% more time on websites than visitors from traditional search, confirming the high-intent nature of this traffic 26.
In regional markets, this dynamic manifests through specific user behavioral patterns. In South Korea, for example, the rise of global generative AI tools did not cannibalize the dominant local search engine, Naver. Instead, it created a "Cross-User" phenomenon where the digital journey bifurcates. Consumers utilize LLMs like ChatGPT for ideation and initial recommendations, but immediately pivot to Naver Search for validation, authentic user reviews, and transactional execution 27. This behavior sustained Naver's search market share at 64.39% in early 2026, demonstrating that AI search and traditional search are increasingly utilized sequentially rather than interchangeably 27.
Algorithmic Architecture and Platform Variations
The generative search landscape is highly fragmented. Because different LLMs rely on disparate retrieval architectures, base indexes, and source-scoring signals, cross-platform citation overlap is statistically minimal. Studies evaluating over a million citations found that only 11% of domains cited by ChatGPT are also cited by Perplexity for the exact same query, and 71% of all cited sources appear on only a single platform 528. Consequently, achieving visibility requires understanding the distinct extraction mechanics of each major engine.
| Platform Parameter | ChatGPT Search | Perplexity | Google AI Overviews | Microsoft Copilot |
|---|---|---|---|---|
| Retrieval Base | Bing Index + Live Web | Proprietary Live Crawl | Google Search Index | Bing Index + MS Graph |
| Dominant Source Types | Wikipedia, Editorial | Reddit, Forums, News | YouTube, Brand Domains | Corporate Domains, Internal |
| Authority Dependency | High (>32k referring domains) | Moderate (Content Structure) | Moderate (Top 10 Rankings) | High (Bing Authority) |
| Positional Bias | Extreme (Top 30% of page) | High (BLUF Formatting) | Low (Fan-out extraction) | High |
| Update Frequency Factor | Moderate | Extreme (Live preference) | High (<90 days favored) | Moderate |
ChatGPT Search Mechanics and Retrieval Criteria
ChatGPT Search operates a real-time web retrieval system predominantly dependent on Microsoft Bing's search infrastructure. If a domain is not indexed in Bing, it cannot be retrieved or cited by ChatGPT's search agent (OAI-SearchBot) 5282930.
Citation behavior within ChatGPT is governed by a severe positional bias, frequently referred to as the "Ski Ramp" effect. Large-scale reverse engineering indicates that 44% of all ChatGPT citations are extracted exclusively from the first 30% of a given web document 262931. When the model retrieves a page, it analyzes the document's framing; if the direct answer is buried beneath lengthy introductions, the agent discards the source during the synthesis phase 2631.
Furthermore, ChatGPT applies an "Entity Anchor" rule. While standard English text contains 5% to 8% proper nouns, text cited by ChatGPT averages an entity density of 20.6% 31. Because LLMs are averse to hallucination, they heavily favor text anchored by verifiable entities - specific brands, individuals, or protocols - which serve as verifiability triggers 31. Structurally, ChatGPT treats H2 headings as analogues to the user's prompt. When an H2 matches the semantic intent of the query, the model expects the immediate subsequent paragraph to contain a direct Subject-Verb-Object statement. If the text immediately following the header is conversational filler, the extraction connection breaks 315.
Domain authority remains a rigorous filter for ChatGPT. Analysis shows that domains exceeding 32,000 referring domains are 3.5 times more likely to be cited, and 65.3% of ChatGPT-cited pages originate from domains with a Domain Rating (DR) of 80 or higher 56. For commercial intent queries, ChatGPT heavily favors third-party validation over a brand's own website, seeking unbiased consensus from editorial sources or review platforms 2431.
Perplexity Source Selection Algorithms
Perplexity is architected as a citation-first engine, contrasting with ChatGPT's conversation-first design 28. It utilizes its own proprietary crawler and executes a Retrieval-Augmented Generation process for every query, preventing it from relying solely on static training data 13347.
Content freshness operates as the dominant ranking signal within Perplexity's algorithm. When queried about recent events or evolving topics, Perplexity accesses the live web and actively filters out dated content. A highly structured article published within hours can supersede comprehensive content published two years prior 153436.
Perplexity's verification process relies on multi-source corroboration. The algorithm actively seeks digital consensus, requiring information to be corroborated across multiple independent domains before it gains the confidence to cite a specific claim 1315. Consequently, Perplexity heavily indexes community platforms, with Reddit accounting for 46.7% of its top citations, alongside industry-specific forums 2837. To optimize for Perplexity, documents must utilize a "Bottom Line Up Front" (BLUF) formatting structure, where exact entity names are used, direct answers lead the content, and evidentiary sources are placed physically adjacent to the claims they support rather than collected at the document's end 13336.
Google Artificial Intelligence Overviews and Gemini Integration
Google AI Overviews (AIO), powered by the Gemini model, are generated dynamically and overlaid onto the traditional search engine results page. Initially, AI Overviews drew heavily from existing top-ranking organic results, with early studies showing a 76% overlap between top-10 ranked pages and cited URLs 1943438. However, following algorithmic updates and the transition to Gemini 3 in 2026, this correlation weakened significantly. Current large-scale analyses indicate that only 17% to 38% of URLs cited in an AI Overview rank in the top 10 for the identical query 1942838.
This shift is driven by Google's "fan-out" query processing mechanism. The system splits a primary user query into multiple sub-queries and synthesizes the final overview by drawing from specialized pages that answer those sub-queries, effectively rewarding topical depth and related-question coverage over single-keyword dominance 1938. The primary ranking factor for AIO is "Semantic Completeness" (r=0.87 correlation). The AI prioritizes passages that thoroughly answer queries within self-contained blocks of 134 to 167 words 21.
Google's AI systems also exhibit a strong preference for multimodal content. Pages integrating text alongside images, video, and comprehensive structured data see up to 156% higher selection rates 21. Consequently, YouTube has emerged as the single most-cited domain in AI Overviews, representing 18.2% of citations drawn from outside the top 100 organic results 1928. Recent updates also introduced publisher-friendly features, highlighting links from publications the user subscribes to and displaying website previews on hover to improve click-through rates 8.
Microsoft Copilot Data Grounding and Enterprise Search
Microsoft Copilot bifurcates its retrieval strategy based on the user's environment. The consumer iteration draws candidate content from Bing's live index, evaluating sources based on topical relevance, structured clarity, and domain authority 309.
In commercial environments, Microsoft 365 Copilot utilizes the Semantic Index and Microsoft Graph to ground AI responses securely within an organization's proprietary data 91011. This enterprise grounding relies heavily on Entra ID permissions to ensure the AI agent only synthesizes data the user is authorized to access 10. To enhance trust and transparency, Copilot introduced automatic "citation pills" in applications like Word, directly linking synthesized claims to their specific web or internal document origins 912. Furthermore, Microsoft Purview Data Loss Prevention (DLP) controls allow administrators to exclude specific external domains from web grounding, strictly regulating which external sources the Copilot engine can reference when generating responses for corporate users 91113.
Asian Market Generative Search Environments
The generative search landscape in Asia is dominated by regional platforms tightly integrated into local digital ecosystems. In China, five primary engines dominate the market: ByteDance Doubao (260M MAU), Baidu ERNIE Bot (220M MAU), Alibaba Quark (180M MAU), Tencent Yuanbao (150M MAU), and Moonshot AI's Kimi (90M MAU) 45.
Baidu's ERNIE framework remains the enterprise standard, functioning as the default search agent for government and corporate procurement 45. In May 2026, Baidu released ERNIE 5.1, an ultra-sparse mixture-of-experts (MoE) model that natively handles multimodal inputs (text, image, audio, video) via an autoregressive architecture 14471549. Through multi-dimensional elastic pre-training, Baidu compressed the total parameters to one-third of the previous iteration, reducing pre-training compute costs to just 6% of comparable frontier models 4950161753. Despite this efficiency, ERNIE 5.1 achieved a score of 1223 on the LMArena Search leaderboard, ranking fourth globally and maintaining dominance in Chinese-language search grounding tasks 49501653. ERNIE retrieves data almost exclusively from the Baidu ecosystem, making traditional global GEO strategies ineffective within the mainland network 1819.
In South Korea, Naver's AI search agent, "Cue:", utilizes multi-step reasoning to decode complex queries. Instead of relying solely on open web crawls, Cue synthesizes answers by pulling structured data directly from Naver's internal services, including Naver Shopping, Naver Place, and Naver Blogs 565720. Optimizing for Naver Cue requires brands to build dense, specific content within Naver's proprietary platforms, focusing on long-tail conversational intent rather than top-level generic category keywords 2756.
Technical Infrastructure and Web Crawling Protocols
The rapid evolution of generative engines exposed fundamental limitations in the protocols governing how automated systems interact with websites. The infrastructure designed for traditional search engine spiders has proven inadequate for managing autonomous AI agents performing multi-step reasoning and massive data extraction 2160.
The Evolution of Robots.txt and IETF AIPREF Standards
The standard robots.txt protocol, established in 1994, was designed exclusively to instruct crawlers which URLs to index 21. It lacks the semantic granularity to distinguish between a search engine indexing a page for a hyperlink result and an LLM extracting the page's contents to train a foundation model or synthesize a zero-click answer 2161.
By early 2026, the economic tension between content publishers and AI developers resulted in defensive crawling restrictions. Large-scale server log analyses revealed severe inequities in crawl-to-refer ratios. For instance, Anthropic's ClaudeBot crawled 20,583 pages for every single referral click it generated, while Meta's external agents returned zero referral traffic despite accounting for 13.9% of AI bot volume 22. Consequently, 79% of major news publishers actively block AI training bots via robots.txt 226122. However, implementing these blocks creates an all-or-nothing dilemma: blocking Google's extended crawlers to prevent training data extraction inadvertently removes the brand from Google's AI Overviews, devastating discoverability 2161.
To resolve this protocol failure, the Internet Engineering Task Force (IETF) chartered the AI Preferences (AIPREF) Working Group. The working group's objective is to standardize a building-block vocabulary that allows publishers to express preferences regarding AI content collection 232425. By 2026, the AIPREF group recognized that attempting to block "AI" as a specific technology is unworkable, as machine learning is embedded in standard routing and accessibility software 2123. Instead, the evolving IETF standard focuses on specifying the purpose of use - allowing site owners to permit data extraction for real-time search grounding while strictly forbidding the use of the same data for foundation model training 2326.
The llms.txt Community Standard
As an interim solution, the llms.txt file emerged as a proposed community standard 676869. Placed in the root directory of a website, this Markdown-formatted file acts as a curated "compressed index" designed specifically for LLM crawlers with limited context windows 6768. It directs AI agents toward a site's most fact-dense, authoritative pages, circumventing navigational clutter 567.
While Google has explicitly stated it does not endorse or parse llms.txt, adoption sits at roughly 10% of crawled domains globally as of May 2026 6169. The protocol is highly effective for SaaS platforms and technical documentation sites that benefit from providing structured, easily digestible maps of their architecture to AI coding assistants 6869. However, it is not a replacement for traditional robots.txt directives or robust structured data 69.
Schema.org Adaptations for Machine Extraction
In the era of generative engine optimization, Schema.org markup has evolved from a tool for generating rich visual snippets on SERPs into a mandatory indexing requirement for machine comprehension 272829. LLMs rely on structured data to parse web content accurately, verify entity relationships, and prevent hallucinatory outputs 272930. Data demonstrates that LLMs grounded in comprehensive knowledge graphs achieve 300% higher accuracy compared to those relying on unstructured text alone 27.
The technical standard for schema implementation has narrowed exclusively to JSON-LD (JavaScript Object Notation for Linked Data). Legacy formats like Microdata and RDFa, while technically valid in older HTML specifications, are poorly suited for the extraction pipelines of modern LLMs and must be converted to JSON-LD 2874.
Critical JSON-LD schema types for 2026 AI visibility include:
* Organization and LocalBusiness: These schemas function as the primary Identity Anchor, defining the brand's verified name, logo, and core URIs to ensure consistent entity resolution across the global knowledge graph 18282975.
* FAQPage: Recognized as the highest-leverage schema type for generative engines. AI systems extract FAQPage blocks directly into conversational responses. However, applying boilerplate FAQ schema across multiple pages triggers deduplication filters; questions must uniquely match the on-page content 2829.
* Article and VideoObject: Required for parsing long-form text and media. AI Overviews heavily cite embedded videos when VideoObject schema provides timestamps, descriptions, and transcripts 2829.
* sameAs Attributes: Deployed within Person and Organization schemas, sameAs links connect an author or brand to verified external identities (e.g., Wikipedia, LinkedIn, Forbes). This creates an "entity handshake," providing the vital E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness) signals LLMs demand before citing a source 517672930.
| Implementation Element | Traditional SEO Approach | Generative Engine Optimization (2026) |
|---|---|---|
| Schema Format | Microdata, RDFa, or JSON-LD | Strictly JSON-LD for programmatic extraction |
| Schema Purpose | Trigger rich visual snippets in SERPs | Build Content Knowledge Graph for Entity verification |
| FAQ Strategy | Broad, boilerplate Q&A across site | Unique, 40-60 word answers strictly matching page HTML |
| Entity Linking | Internal linking for PageRank flow | sameAs attributes mapping to global Wikidata/LinkedIn |
| Video Handling | Standard iframe embeds | VideoObject schema with timestamps for AI extraction |
Content Structuring and Evidentiary Requirements
Because generative engines process information fundamentally differently than traditional web crawlers, content engineering must adapt. Traditional SEO prioritized keyword density, broad topical coverage, and lengthy narratives designed to retain user dwell time. GEO prioritizes structural extractability, semantic density, and verifiable factual claims 311123173132.
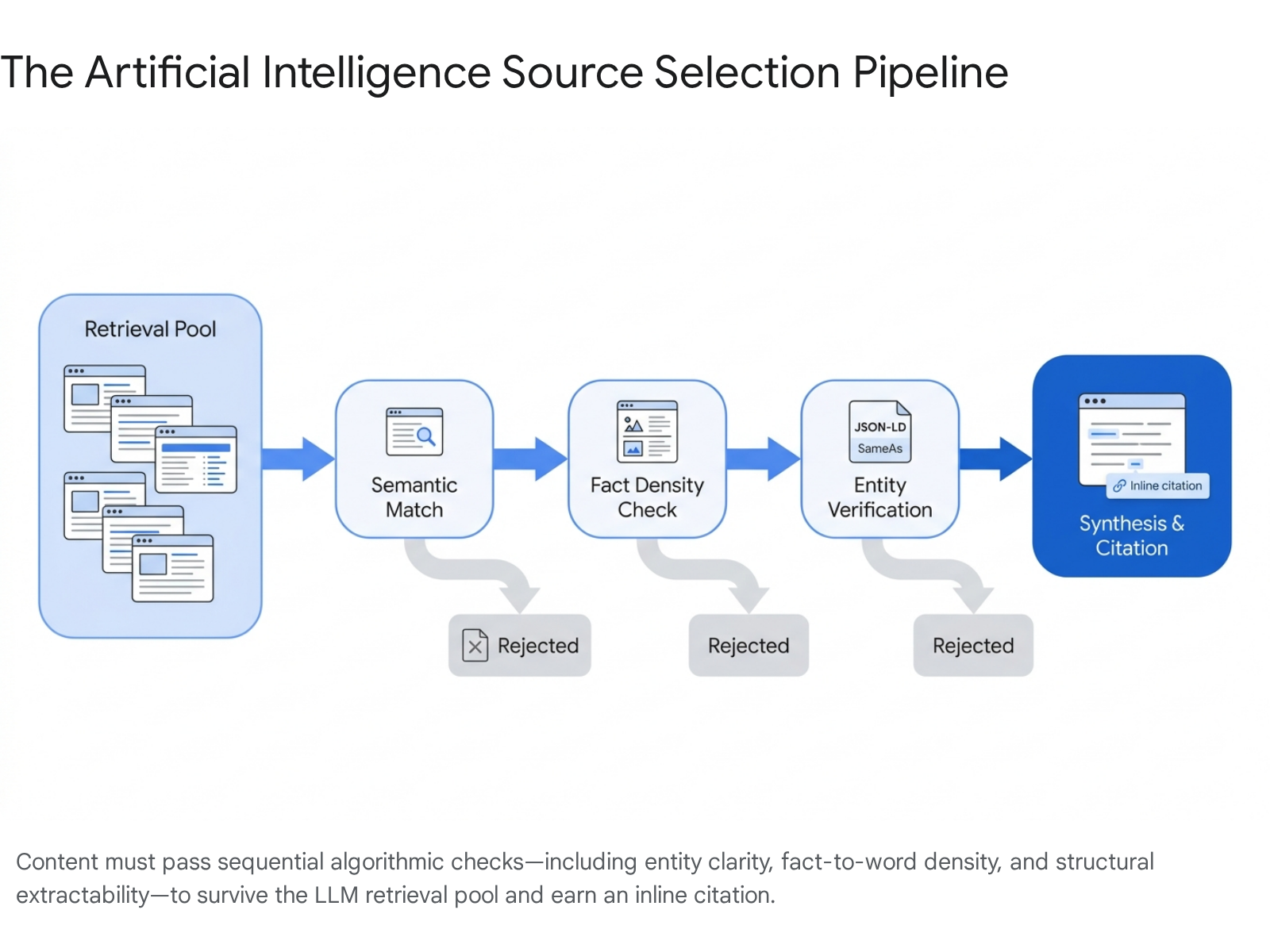
Fact-to-Word Ratios and Semantic Density
LLMs are engineered to seek "Information Gain." If a webpage merely paraphrases existing consensus without contributing novel, verifiable data, the model relies on its pre-trained internal weights rather than citing the external source 17. Consequently, factual density has superseded keyword density as the primary metric of content quality.
A comprehensive 2026 AEO performance study revealed a statistical threshold: web pages maintaining a fact-to-word ratio higher than 1:80 (incorporating at least one unique, verifiable metric, statistic, or date per 80 words) are 4.2 times more likely to be cited in ChatGPT responses 17. Generative engines actively seek these numerical and factual markers as "verifiability triggers" to ground their outputs and avoid hallucinations 31731.
Content length remains relevant, provided it maintains semantic density. Analysis of ChatGPT citation patterns indicates that articles exceeding 2,900 words are 59% more likely to be selected as a citation source than articles under 800 words, reflecting the AI's preference for exhaustive, multi-faceted topic coverage 2633.
Structural Feature Engineering
The physical architecture of a document heavily influences its survival within an LLM's retrieval pool. AI systems do not read texts chronologically like humans; they scan for structural markers indicating definitive answers 3179.
Content must be organized using a "Bottom Line Up Front" (BLUF) hierarchy 13336. The most critical data and direct answers must appear in the first third of the document to overcome the "Ski Ramp" positional bias inherent in LLM retrieval 262931. Passages should be chunked into self-contained units of 120 to 180 words, logically separated by descriptive H2 or H3 headings 21263133. When an H2 matches a user's natural language query, the AI expects the immediate following text to provide a direct, factual answer 315. If evidentiary sources or citations are required, they must be placed immediately adjacent to the claim in the text; collecting references at the bottom of the page breaks the semantic linkage for the AI, resulting in dropped citations 380.
Entity Architecture and Third-Party Validation
In traditional SEO, domain authority was heavily reliant on accumulated backlinks. In generative search, AI engines evaluate entity authority by seeking digital consensus across independent, third-party platforms 1726. Brand mentions on reputable third-party domains now carry up to three times the algorithmic weight of traditional inbound links for AI visibility 26.
Analyses of millions of AI citations reveal a massive "mention-source divide." Often, an AI will synthesize data originally published on a brand's owned website but cite a third-party editorial publication or community forum as the source 2837. Across platforms, community sites (like Reddit and Quora) and Wikipedia capture 52.5% of all citations, outperforming brand-owned domains 2837. Furthermore, wire services and major publications (e.g., Reuters, AP, Forbes) dominate citations because their editorial standards naturally align with the structural and factual density requirements of LLM extraction 81.
Consequently, a successful GEO strategy cannot rely solely on owned media. Brands must actively cultivate entity presence across review sites (e.g., G2, Trustpilot), industry forums, and earned media placements. For commercial intent queries, LLMs specifically seek this unbiased consensus, heavily favoring third-party validation over corporate websites to satisfy users' evaluative needs 2426316.
Enterprise Tooling and Performance Measurement
The architectural differences between traditional search and generative search render legacy analytics platforms inadequate. Tools like Google Analytics 4 (GA4) rely on click-based attribution, often categorizing the zero-click journeys or delayed conversions characteristic of AI interactions as "Direct" or "Unassigned" traffic 2534. To address this attribution gap, a new sector of Answer Engine Optimization (AEO) platforms has emerged.
Answer Engine Optimization Platform Capabilities
Because LLMs are non-deterministic and lack standardized webmaster APIs for tracking citation visibility, enterprise tools must execute queries directly against the frontend user interfaces (UIs) of models like ChatGPT and Perplexity. Tracking API responses is insufficient, as research indicates only a 4% overlap in source selection between a model's backend API and its consumer-facing web interface 2583.
Leading AEO platforms in 2026 approach optimization through distinct methodologies:
- Profound: Positioned as an enterprise-grade, read/write GEO platform. It tracks visibility across multiple engines (ChatGPT, Perplexity, Google AI Overviews, Copilot) via frontend data capture. It provides "Agent Analytics" to track how AI crawlers interact with site architecture, monitors brand sentiment within AI answers, and integrates with CDNs and GA4 to map conversational search trends 8335363738.
- Adobe LLM Optimizer: Integrated into the Adobe Experience Cloud, this application tracks AI-driven traffic and benchmarks brand presence against competitors. It utilizes a recommendation engine to identify visibility gaps across owned assets and third-party platforms (like Wikipedia) and supports enterprise workflows such as the Model Context Protocol (MCP) to scale modular content deployment 394041.
- Peec AI and Surfer SEO: These platforms cater to mid-market teams and agencies, offering hybrid workflows. They combine AI visibility tracking with content generation tools, allowing practitioners to optimize documents simultaneously for traditional SERP rankings and generative engine inclusion 833738.
Evolving Key Performance Indicators
With the decline of traditional ranking positions as a primary metric, digital marketing KPIs have adapted to measure presence within the synthesis layer.
- Share of Citation (SoC): Calculated as the percentage of relevant AI query responses within a specific topic cluster that reference the target brand or its content 63693.
- Citation Velocity and Digital Consensus: Tracking how frequently the brand is mentioned across independent, high-authority third-party sources (Reddit, G2, editorial media) recognized by LLMs 1726.
- Sentiment and Context Scoring: Qualitative monitoring of how the LLM frames the brand within the generated text. An AI citing a brand negatively or inaccurately requires immediate updates to the underlying "ground truth" data across the web 17243637.
- Entity Coverage Score: Measuring the percentage of relevant entities and sub-topics addressed within the brand's content clusters compared to top competitors, indicating topical authority to the LLM 12.
Strategic Transitions and Common Misconceptions
As organizations pivot to address the generative search landscape, several pervasive misconceptions inhibit effective adaptation.
The most detrimental fallacy is the assumption that traditional search rankings guarantee AI citations. Many practitioners operate under the belief that maintaining a number-one position on Google automatically qualifies a page as an authoritative source for ChatGPT or Perplexity 253294. Empirical data comprehensively disproves this; AI systems evaluate structure, entity density, and cross-platform consensus independently of Google's PageRank algorithms 19262894.
A secondary misconception is the over-reliance on technical schema as a complete solution. While implementing robust JSON-LD markup is an absolute prerequisite, it constitutes only a fraction of the optimization process. Schema provides the map, but if the underlying content is unstructured, bloated with marketing rhetoric, or devoid of verifiable facts, the AI will reject it during the extraction phase 3194.
Ultimately, Generative Engine Optimization requires a departure from legacy metrics. Success in 2026 is not defined by capturing the highest volume of transient clicks, but by architecting digital content so precisely that large language models consistently rely on it as the foundational truth for their synthesized answers 17253294.