Flow matching as an alternative to diffusion models
The landscape of generative artificial intelligence has undergone a fundamental architectural shift. Through the early 2020s, denoising diffusion probabilistic models (DDPMs) dominated visual and continuous-data synthesis, establishing a supremacy characterized by foundational models such as DALL-E, Midjourney, and early iterations of Stable Diffusion 12. However, by 2025 and accelerating into 2026, the computational overhead and mathematical complexities inherent to diffusion models catalyzed the widespread adoption of Flow Matching. This newer paradigm, rooted in continuous normalizing flows and optimal transport theory, rectifies the inefficient generative paths native to diffusion, enabling the rapid sampling, stable training, and vast scalability required for state-of-the-art enterprise and open-weight architectures 345.
This report provides a comprehensive analysis of the transition from stochastic diffusion systems to deterministic Flow Matching frameworks. It examines the underlying mathematical mechanisms driving this paradigm shift, the active academic debate regarding the theoretical equivalence of these systems, the latest architectural implementations defining the 2025 - 2026 ecosystem, and the persistent limitations that researchers are actively mitigating to scale these models into novel modalities.
Mathematical Foundations of Diffusion and Flow Matching
To understand the mechanics of Flow Matching, it is first necessary to examine the differential equations governing how generative models map simple prior distributions (such as Gaussian noise) to complex, high-dimensional data distributions (such as photorealistic imagery). Both paradigms frame data generation as an iterative process of converting noise into data, but they differ profoundly in their geometry, transport mechanics, and stochasticity 56.
Stochastic Differential Equations and Forward Processes
Diffusion models define a forward process that gradually corrupts a pristine data sample over a series of continuous timesteps, culminating in a state of pure, unstructured noise 56. This forward process is formulated mathematically as a Stochastic Differential Equation (SDE):
$dX_t = f(X_t, t)dt + g(t)dW_t$
In this formulation, $f(X_t, t)$ acts as the drift coefficient pulling the data toward the mean, $g(t)$ is the diffusion coefficient dictating the noise schedule, and $W_t$ represents a standard Wiener process, commonly known as Brownian motion 57. The Wiener process is the critical component here; it injects continuous, unpredictable randomness into the system, ensuring that the forward trajectory is a random walk 79.
To generate novel data, the model must reverse this process. By applying the Anderson reverse-time SDE theorem, the generative process is modeled as a reverse SDE:
$dX_t = \left[f(X_t, t) - g(t)^2 \nabla_x \log p_t(X_t)\right]dt + g(t)d\bar{W}_t$
The neural network in a standard diffusion model is trained via denoising score matching to estimate the time-dependent score function $\nabla_x \log p_t(x)$ 66. During inference, this reverse SDE is simulated numerically. Because the Brownian motion term exists in both the forward and reverse processes, the trajectory of any given sample through the latent space is inherently stochastic and highly tortuous 910. This severe curvature forces the use of hundreds or even thousands of small, discrete integration steps to avoid numerical instability, establishing the primary bottleneck of standard diffusion: extremely slow inference times and high computational costs 1011.
The Probability Flow Ordinary Differential Equation
Recognizing the inefficiency of simulating random walks for data generation, researchers derived the Probability Flow Ordinary Differential Equation (PF-ODE). Theoretical frameworks established that for any diffusion SDE, there exists an equivalent deterministic ODE that shares the exact same marginal probability densities $p_t(x)$ at every timestep 689. The PF-ODE is derived via the Fokker-Planck equation and is expressed as:
$dx = \left( f(x, t) - \frac{1}{2} g(t)^2 \nabla_x \log p_t(x) \right) dt$
While this ODE removes the stochastic Wiener process - meaning the generation of data from a specific noise sample becomes completely deterministic - it inherits the vector field defined by the original stochastic forward process 66. Consequently, while the path is no longer a random walk, it remains highly curved, continuing to demand sophisticated, high-order ODE solvers and numerous functional evaluations to generate coherent samples without severe truncation errors 710.
Mechanics of Flow Matching
Flow Matching abandons the prerequisite of a stochastic forward process entirely. Instead, it utilizes Continuous Normalizing Flows (CNFs) to formulate the transformation between a noise distribution $p_0$ and a data distribution $p_1$ directly as an ODE 711. In this framework, the generative task is purely deterministic and is reduced to learning a time-dependent vector field (or velocity field) $u_t(x)$ that transports the initial noise to the target data 57.
Continuous Normalizing Flows and Conditional Vector Fields
If one possessed a "God's eye view" of the entire dataset, they could calculate the marginal vector field mapping the entire noise distribution to the entire data distribution. However, calculating this marginal vector field directly requires solving an intractable marginalization over the entire high-dimensional data manifold 9.
To bypass this impossibility, Flow Matching employs a statistical technique called Conditional Flow Matching (CFM) 912. CFM constructs a tractable training objective by conditioning the vector field on individual, specific data points $x_1$. By defining a simple conditional path from a random noise sample $x_0$ to a specific training image $x_1$, the model establishes an exact, localized vector field $u_t(x_t | x_1)$ 917. The neural network, parameterized as $v_\theta(x_t, t)$, is then trained using a simulation-free regression objective to match this conditional velocity:
$\mathcal{L}{CFM}(\theta) = \mathbb{E}{t, q(x_1), p(x_0)} \left[ ||v_\theta(x_t, t) - u_t(x_t | x_1)||^2 \right]$
This objective entirely avoids the complex estimation of probability densities and complex score matching required by traditional diffusion models. By directly regressing the velocity field, Flow Matching establishes a clean, robust training dynamic that natively scales to vast parameter counts without suffering from the exploding gradients or signal-to-noise ratio collapses common in SDE frameworks 518.
Optimal Transport and Trajectory Rectification
The paramount mathematical advantage of Flow Matching over the PF-ODE of standard diffusion models is its capacity to construct bespoke probability paths. Because CFM does not constrain the model to follow a historical Brownian forward process, researchers can define paths that are computationally and geometrically optimal. The most transformative of these paths utilizes Optimal Transport (OT), an approach closely related to Rectified Flow 111019.
In Optimal Transport Conditional Flow Matching (OT-CFM), the interpolation between the noise and the data is defined linearly. Given a noise sample $x_0 \sim \mathcal{N}(0, I)$ and a data sample $x_1$, the intermediate state at time $t$ is defined as:
$x_t = (1 - t)x_0 + t x_1$
Taking the time derivative of this position yields a constant target velocity field required to move along this path:
$u_t(x_t | x_1) = x_1 - x_0$
By training the neural network to predict this constant velocity vector, the model learns a highly rectified, perfectly straight transport path from the prior noise manifold to the target data manifold 1117.
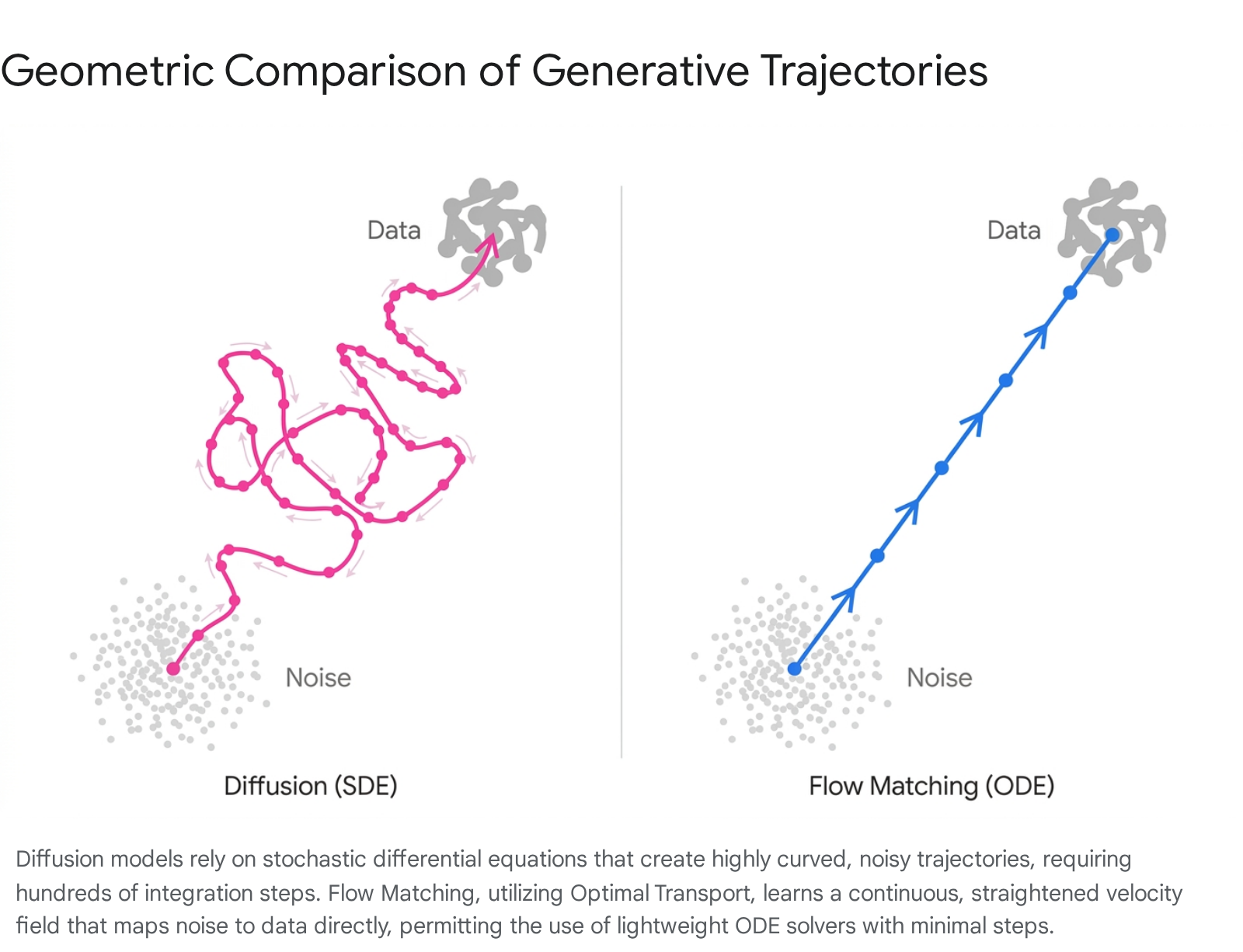
Comparative Analysis of Training and Inference
The geometric divergence between diffusion and Flow Matching dictates their respective computational footprints during the inference phase. Solving an ODE for sample generation necessitates numerical integration, a process that discretizes continuous time into finite steps of size $h$.
Inference Efficiency and Truncation Error
When a neural network utilizes a basic first-order numerical solver (such as the Euler method), it projects the state of the next step linearly based on the current velocity:
$X_{t+h} = X_t + h \cdot v_\theta(X_t, t)$
If the true mathematical trajectory is highly curved - as is the case with probability flow ODEs derived from diffusion models - taking a linear Euler step will result in massive truncation errors. The predicted sample will physically veer off the targeted data manifold into an invalid latent space unless the step size $h$ is infinitesimal 713. This mathematical reality is why early diffusion models required between 50 and 1,000 functional evaluations (NFEs) to generate a single image 910.
Because Flow Matching with optimal transport straightens the path, the tangent of the trajectory at any given point is essentially pointing directly at the target data. Therefore, the truncation error of a large, linear Euler step is drastically minimized 1010. According to geometric analyses conducted on low-resource hardware, the topological nature of the OT path yields a trajectory curvature ($\mathcal{C}$) of approximately 1.02 for Flow Matching, approaching the theoretical perfection of a straight line ($\mathcal{C} = 1.0$). In stark contrast, standard diffusion trajectories remain tortuous, exhibiting a curvature of $\mathcal{C} \approx 3.45$ 10.
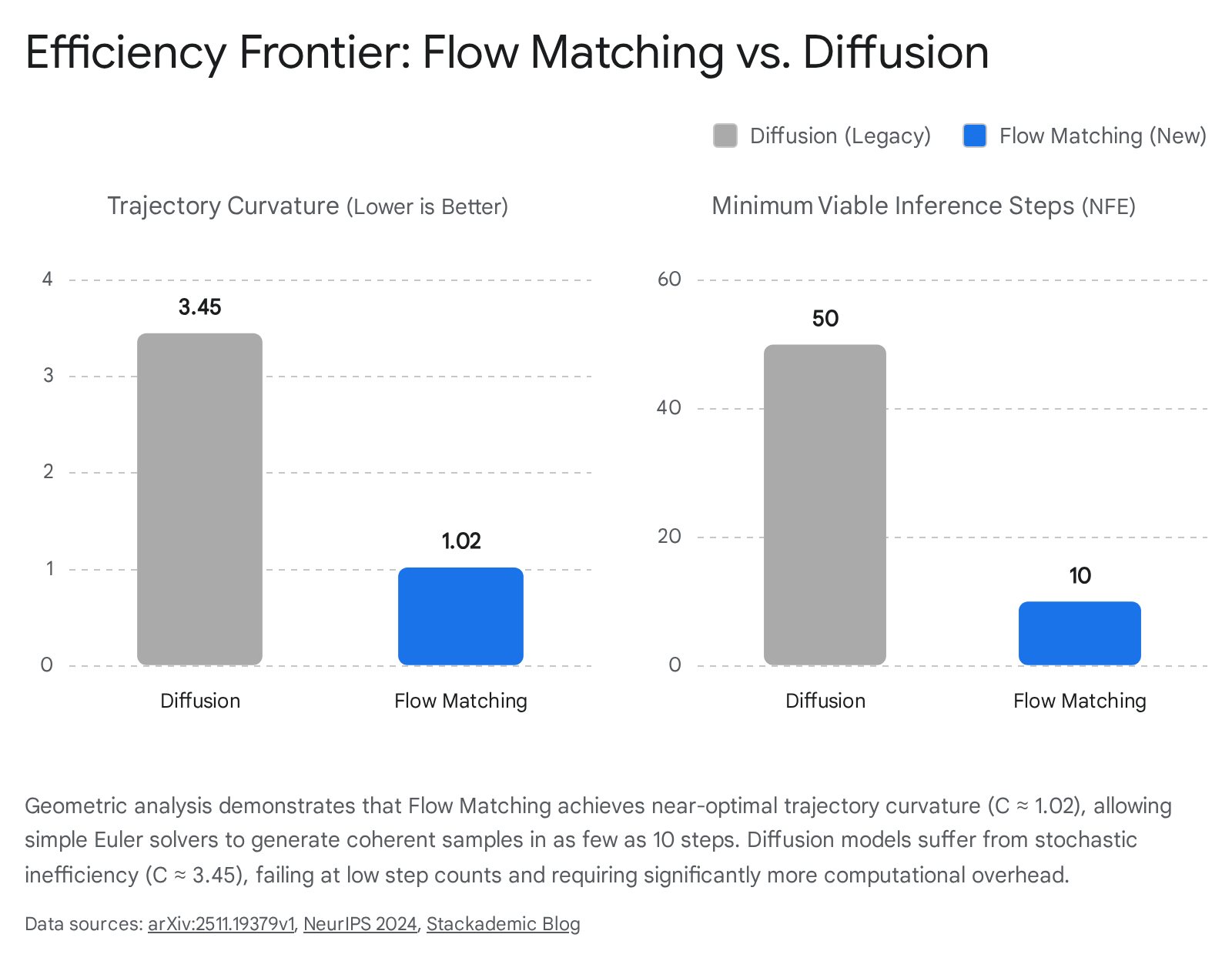
This difference establishes an undeniable "efficiency frontier." At a threshold of $N = 10$ steps, Flow Matching models retain high fidelity and precise generation capabilities, whereas traditional diffusion models collapse into structural noise 10. This capability has transformed the operational economics of generative AI at the enterprise level, moving generation times from the 30-to-60 second delays characteristic of 2023 diffusion networks down to sub-second latencies suitable for real-time production 311.
Mathematical Equivalence and Academic Debate
As Flow Matching surged in prevalence throughout 2024 and 2025, an active theoretical debate emerged regarding its exact relationship with diffusion. Can Flow Matching be considered a distinctly new paradigm, or is it merely a mathematical reformulation of diffusion? Prominent publications from Google DeepMind and MIT researchers have formalized mathematical proofs demonstrating that, under specific conditions, the two paradigms are functionally identical 814.
The unification argument hinges on the fact that the probability flow ODE of a diffusion model can perfectly mirror the deterministic trajectory of Flow Matching. If one constructs a "Gaussian Flow Matching" model - assuming the source distribution is strictly Gaussian - and forces the Flow Matching schedule to use linear coefficients equivalent to a standard diffusion variance schedule ($\alpha_t = 1 - t$ and $\sigma_t = t$), the forward processes of both paradigms perfectly align 8. Furthermore, researchers established that the iterative update rule of the widely used Denoising Diffusion Implicit Models (DDIM) sampler is mathematically identical to a first-order Euler step in Flow Matching 8. Consequently, via a specific mathematical transformation, one can convert the score function $\nabla_x \log p_t(x)$ learned by a diffusion model directly into the velocity field $u_t(x)$ utilized by Flow Matching, rendering the frameworks theoretically interchangeable under these narrow constraints 1415.
Despite this theoretical equivalence under specific edge-case schedules, Flow Matching is definitively replacing diffusion in empirical practice due to fundamental disparities in parameterization flexibility and loss robustess 516.
- Robust Vector Field Parameterization: Diffusion models are forced by their derivation to predict the score function or the injected noise $\epsilon$. This often leads to numerical instabilities at the temporal boundaries ($t \to 0$ or $t \to 1$) and requires complex weighting schemes in the loss function to maintain stability 819. Flow Matching networks are tasked to predict the target velocity vector directly, resulting in smoother gradients and a loss landscape that generalizes more efficiently to novel architectures 519.
- Independence from Gaussian Priors: SDE-based diffusion fundamentally demands that the terminal noise distribution be a standard Gaussian. Flow Matching imposes no such restriction. The ODE formulation can define a continuous transport path between any two arbitrary distributions 1219. This is particularly vital in scientific domains where starting from a Gaussian prior is biologically or physically nonsensical.
| Generative Characteristic | Denoising Diffusion Models (SDE / PF-ODE) | Flow Matching Models (OT-CFM) |
|---|---|---|
| Mathematical Basis | Stochastic Differential Equations (SDE) | Ordinary Differential Equations (ODE) |
| Target Prior Distribution | Strictly Gaussian $\mathcal{N}(0, I)$ | Arbitrary base distributions |
| Generative Trajectory | Curved, stochastic, and tortuous | Straightened, optimal transport paths |
| Neural Network Objective | Score Matching / Noise ($\epsilon$) prediction | Velocity field / Vector field regression |
| Typical Sampling Steps | High (50 to 1,000+ functional evaluations) | Low (10 to 20 via simple Euler solvers) |
| Inference Geometry | Trajectory Curvature $\mathcal{C} \approx 3.45$ | Trajectory Curvature $\mathcal{C} \approx 1.02$ |
State-of-the-Art Flow Matching Architectures
The architectural shift from diffusion to Flow Matching has closely coincided with the transition from U-Net neural backbones to Diffusion Transformers (DiTs). By 2026, the fusion of Flow Matching mathematical objectives with scalable Transformer architectures has established a new frontier for multimodal generation.
Foundational Visual Synthesis Models
FLUX.2 (Black Forest Labs) Released in November 2025, FLUX.2 represents the commercial pinnacle of the Flow Matching paradigm. Built by the original academic architects of Stable Diffusion, FLUX.2 pairs a massive 32-billion parameter latent flow matching transformer with a 24-billion parameter Mistral-3 Vision-Language Model (VLM) functioning as the primary text encoder 324. Unlike earlier models that treated image generation purely as statistical pixel denoising, the integration of the Mistral-3 VLM allows the rectified flow transformer to process complex spatial relationships, physical constraints, and lighting physics with high semantic fidelity 317. Utilizing FP8 quantization optimized in collaboration with NVIDIA, FLUX.2 achieves 4-megapixel, highly prompt-adherent image generation in under 10 seconds on consumer RTX hardware. Its architecture uniquely supports multi-reference compositional control, seamlessly integrating up to 10 distinct image prompts concurrently without degrading identity consistency 318. The model family covers various scaling needs, including the flagship FLUX.2 [Pro] and a distilled, highly efficient FLUX.2 [Klein] variant comprising 4B to 9B parameters for sub-second generation 27.
Stable Diffusion 4 Ultra (Stability AI) Following extensive corporate restructuring throughout 2024 and 2025, Stability AI launched Stable Diffusion 4 Ultra in early 2026. Abandoning the legacy U-Net architecture completely, SD4 Ultra is built upon a radically upgraded DiT backbone functioning entirely on flow matching principles 28. Positioned as the preeminent open-weight competitor to closed systems like Midjourney v7 and DALL-E (which OpenAI formally deprecated in May 2026 in favor of their new GPT Image system) 228, SD4 Ultra leverages the straight-line inference of flow models to solve historical diffusion failures. It achieves unprecedented photorealistic text rendering within generated imagery and drastically improves the anatomical accuracy of human hands and limbs 128.
Lumina-Image 2.0 (BAAI) Developed by the Beijing Academy of Artificial Intelligence (BAAI), Lumina-Image 2.0 was introduced as a highly efficient open-source alternative. Operating on a novel "Unified Next-DiT" architecture, this 2.6B parameter model departs from standard cross-attention paradigms by concatenating text embeddings and image latent tokens into a single, joint sequence 1920. Coupled with the Gemma 2 text encoder, the Flux VAE, and a proprietary Unified Captioner (UniCap) system that produces semantically rich training pairs, Lumina-Image 2.0 achieves top-tier aesthetic performance 1920. Because Flow Matching provides straighter gradients during the backward pass, Lumina-Image 2.0 requires 38% less training compute than its predecessor, proving that flow formulations accelerate training convergence as successfully as they accelerate inference 1921.
| Model Framework | Primary Architecture | Parameter Scale | Notable Architectural Features | Modality Focus |
|---|---|---|---|---|
| FLUX.2 | Flow Matching DiT + Mistral-3 VLM | 32 Billion | FP8 Quantization, Multi-reference processing | High-Fidelity Vision |
| Stable Diffusion 4 Ultra | Flow Matching DiT | Undisclosed | Open-weights, Sub-pixel text rendering | High-Fidelity Vision |
| Lumina-Image 2.0 | Unified Next-DiT | 2.6 Billion | Joint token sequence, UniCap pairs | Vision / Multitask |
| Pyramid Flow | Pyramidal Flow Matching | Varies | Temporal pyramid history compression | Video Generation |
| Pi0 (VLA) | Flow Matching DiT + VLM | Varies | 50Hz continuous action latent output | Robotics Motor Control |
Temporal Scaling and Video Generation
Extending Flow Matching into the temporal axis for high-fidelity video generation presents intense computational hurdles. Standard spatial-temporal attention layers operating over hundreds of frames natively trigger quadratic computational complexity limits, making sequence generation prohibitively expensive 3222. Furthermore, current methodologies force a choice between autoregressive (AR) models and full-sequence parallel models. Full-sequence models benefit from bidirectional attention to correct temporal errors but require fixed generation lengths and immense parallel compute 32. AR models enable streaming capabilities but rely on causal attention masks, limiting contextual expressiveness and inducing error accumulation over time 32.
Pyramidal Flow Matching
To resolve these computational barriers, the Pyramid Flow framework, introduced in late 2025, utilizes autoregressive video generation powered by a temporal pyramid structure 2234. Instead of fully denoising a vast spatial-temporal latent space in parallel across all layers, Pyramid Flow compresses the full-resolution history. It heavily downsamples the temporal dimension in the early stages of generation and limits full-resolution flow matching exclusively to the final stages of the pyramid. This optimization massively curtails the token count fed into the Diffusion Transformer, enabling the generation of seamless 10-second, 768p videos at 24 frames per second after a remarkably efficient 20,700 A100 GPU hours of training 2234.
Adaptive Inference Acceleration: FastFlow
To further accelerate Flow Matching specifically for video and temporal generation, researchers at ICLR 2026 introduced FastFlow, a plug-and-play adaptive inference framework 2324. Recognizing that adjacent video frames often require only minor structural adjustments during the denoising phase, FastFlow utilizes a multi-armed bandit algorithm during inference to identify which ODE integration steps produce redundant velocity calculations 2324. The algorithm balances an exploration-exploitation trade-off to determine how many sequential steps can safely be skipped. Missing velocities are approximated using simple finite-difference Taylor series expansions rather than executing a full neural network forward pass. This framework yields a 2.6x speedup over standard flow-matching inference without sacrificing visual fidelity or requiring costly model retraining 2324.
Extensions to Discrete and Scientific Domains
Beyond media synthesis, Flow Matching has rapidly supplanted diffusion in physical and biological sciences. The deterministic stability of the ODE formulation, paired with the ability to define non-Gaussian arbitrary base distributions, makes it uniquely suited for rigorous scientific modeling.
Robotic Control and Visual Language Action Models
In the field of robotics, standard generative policies often rely on autoregressive models to output discrete token commands, which lack the fine-grained continuity required for dexterous manipulation. Alternatively, SDE-based diffusion policies suffer from high-variance gradients and computationally prohibitive inference times that prevent real-time feedback 37.
Modern Visual Language Action (VLA) models, such as Pi0, now utilize Flow Matching to convert discrete web-scale semantic knowledge directly into continuous motor commands 25. By mapping a random noise prior directly to the physical action distribution of a robotic arm, Flow Matching allows generative policies to operate at required 50Hz control frequencies, circumventing the latency issues of SDE policies 25. Frameworks like FMER (Flow Matching Policy with Entropy Regularization) enhance this by using ODE vectors to steer policy updates toward high-reward zones during online reinforcement learning, dramatically increasing exploration efficiency compared to legacy offline diffusion cloning 37.
Computational Biology and Molecular Design
In molecular biology, the generative design of functional proteins and 3D small molecules requires rigid adherence to physical geometries. FlowMol3, an open-source, multi-modal flow matching model, has achieved near 100% molecular validity for generating 3D drug-like molecules 16. By incorporating architecture-agnostic techniques like training-time geometry distortion and self-conditioning, FlowMol3 effectively detects and corrects distribution drift during inference, generating accurate functional group compositions with an order of magnitude fewer parameters than comparable diffusion methods 16.
Similarly, ProtFlow applies Flow Matching to discrete protein sequence design. Rather than relying on standard discrete relaxations of continuous diffusion models - which historically biased output toward local, natural sequence statistics and ignored global protein folding semantics - ProtFlow embeds raw protein sequences into a continuous, biologically meaningful latent space provided by large-scale pre-trained protein Language Models (pLMs) 26. By learning an optimal flow over this semantic manifold, ProtFlow successfully maps continuous noise to highly viable, diverse antimicrobial peptides that display broad-spectrum activity against under-represented pathogens 26.
Current Limitations and Mitigation Strategies
While Flow Matching has incontrovertibly resolved the efficiency bottlenecks of SDE diffusion, the paradigm possesses inherent vulnerabilities. Active research throughout 2026 remains focused on mitigating biases introduced by the deterministic ODE process and adapting the framework to strictly discrete token architectures.
The Exposure Bias Dilemma
The primary structural vulnerability of Flow Matching during inference is Exposure Bias, a phenomenon historically associated with autoregressive language models. Because Flow Matching relies on a deterministic ODE trajectory during inference, the numerical solver must recursively use its own prior step predictions to compute the subsequent velocity vector 4041.
During training, the model is exposed only to pristine, ground-truth trajectories that map perfectly between noise and real data. During inference, however, a minuscule prediction error early in the Euler integration process will place the state slightly off the true data manifold 4041. Unlike SDE diffusion models - which inherently inject continuous stochastic noise ($g(t)d\bar{W}_t$) that can act as a regularizing buffer against minor drift - the Flow Matching ODE formulation possesses no self-correcting random injection 4041. Consequently, minor prediction errors cascade unchecked. As the solver progresses, the trajectory drifts further from the target manifold, leading to severe artifact accumulation that rapidly degrades output quality in long-horizon video generation or highly detailed image rendering 3227.
To combat exposure bias, recent literature proposes several refinement strategies. Bi-stage Flow Refinement (BFR) introduces post-hoc lightweight latent-space augmentations and data-space refinement steps that force the straying trajectory back onto the manifold without relying on computationally costly multi-step resampling 41. Other approaches, such as those presented at ICLR 2026, impose rigid geometric manifold constraints during integration to curb error accumulation natively, requiring no additional training overhead 27.
The Train-Test Gap in Optimal Transport Coupling
Despite the theoretical elegance of Optimal Transport paths, naive minibatch OT algorithms introduce subtle challenges in conditional generative settings. Research presented at ICCV 2025 demonstrated that default minibatch OT mappings evaluate transport costs based purely on spatial distance, entirely disregarding conditioning variables (such as text prompts or class labels) when computing transport assignments 13.
This algorithmic oversight creates a conditionally skewed prior distribution during training; the model learns optimal paths mapping highly specific noise clusters to specific data points. However, at inference, the model must sample from a full, unbiased, standard Gaussian prior. This mismatch between the skewed training prior and the unbiased testing prior creates a significant "train-test gap," which heavily degrades conditional alignment and prompt adherence 13. To rectify this, researchers developed Conditional Optimal Transport (C2OT), which inserts a condition-aware weighting term into the cost matrix during training. This forces the OT assignment to respect semantic boundaries, restoring prompt adherence while maintaining straight-path efficiency 13.
Discrete Token Spaces and the Curse of Dimensionality
While Flow Matching excels in continuous spatial environments (pixels, dense latents, continuous action spaces), modeling fundamentally discrete modalities - such as natural language text tokens or quantized audio representations - presents theoretical friction. Purely continuous flow matching ignores the hard categorical structure of language, whereas purely discrete generation frameworks collapse the underlying transport geometry 40.
Models such as SDFlow attempt to bridge this divide by introducing discrete mathematical supervision into continuous transport dynamics. By applying a categorical posterior over Vector Quantized (VQ) token codebooks within a variational flow-matching formulation, models can learn continuous paths over discrete embedding spaces. This approach effectively mitigates the curse of dimensionality while substantially reducing Context-FID scores for sequence generation, presenting a pathway for Flow Matching to eventually challenge autoregressive transformers in pure language tasks 40.
Conclusion
The transition from diffusion models to Flow Matching represents a fundamental mathematical realignment within generative artificial intelligence. By discarding the stochastic, Brownian motion inherent in traditional SDE diffusion, Flow Matching models embrace deterministic Ordinary Differential Equations. The coupling of this ODE framework with Optimal Transport objectives results in highly rectified, straightened generative paths that dramatically minimize truncation error during numerical integration.
This geometric optimization translates directly into unprecedented real-world performance. In 2026, state-of-the-art Flow Matching architectures such as FLUX.2, Stable Diffusion 4 Ultra, and Lumina-Image 2.0 demonstrate that the inference steps required to produce high-fidelity multimodal output can be safely reduced from over fifty down to ten or fewer. While theoretical proofs confirm that Diffusion and Flow Matching can be framed as unified entities under strict Gaussian parameters, Flow Matching's reliance on simple vector field regression provides unparalleled architectural flexibility, allowing models to operate across arbitrary base distributions with far more stable training dynamics. Although limitations such as deterministic exposure bias and discrete-space adaptation remain areas of active research, Flow Matching has decisively superseded diffusion, establishing itself as the dominant generative paradigm of the current era.