Federated Learning Systems and Architectures
Machine learning model development has traditionally relied on the centralization of vast datasets into singular computing environments, such as cloud infrastructure or localized data centers. While this centralized paradigm maximizes computational efficiency and simplifies the optimization process, it introduces severe vulnerabilities regarding data privacy, security, and regulatory compliance 123. Federated Learning represents a transformative distributed machine learning architecture wherein the mathematical model is brought directly to the data, rather than transferring the data to the model. In a federated architecture, a global machine learning model is distributed across multiple decentralized devices or servers that hold local data samples. These decentralized nodes train the model locally and transmit only the updated mathematical parameters - such as weights or gradients - back to a central aggregator. This methodology completely eliminates the need to exchange raw, sensitive data over external networks, establishing a robust framework for privacy-preserving artificial intelligence 1345.
Foundational Paradigms in Machine Learning Topologies
The structural architecture of a machine learning network determines how data is stored, how model parameters are synchronized, and the degree to which administrative authority is centralized. The industry currently utilizes three primary topologies: centralized learning, federated learning, and fully decentralized peer-to-peer learning.
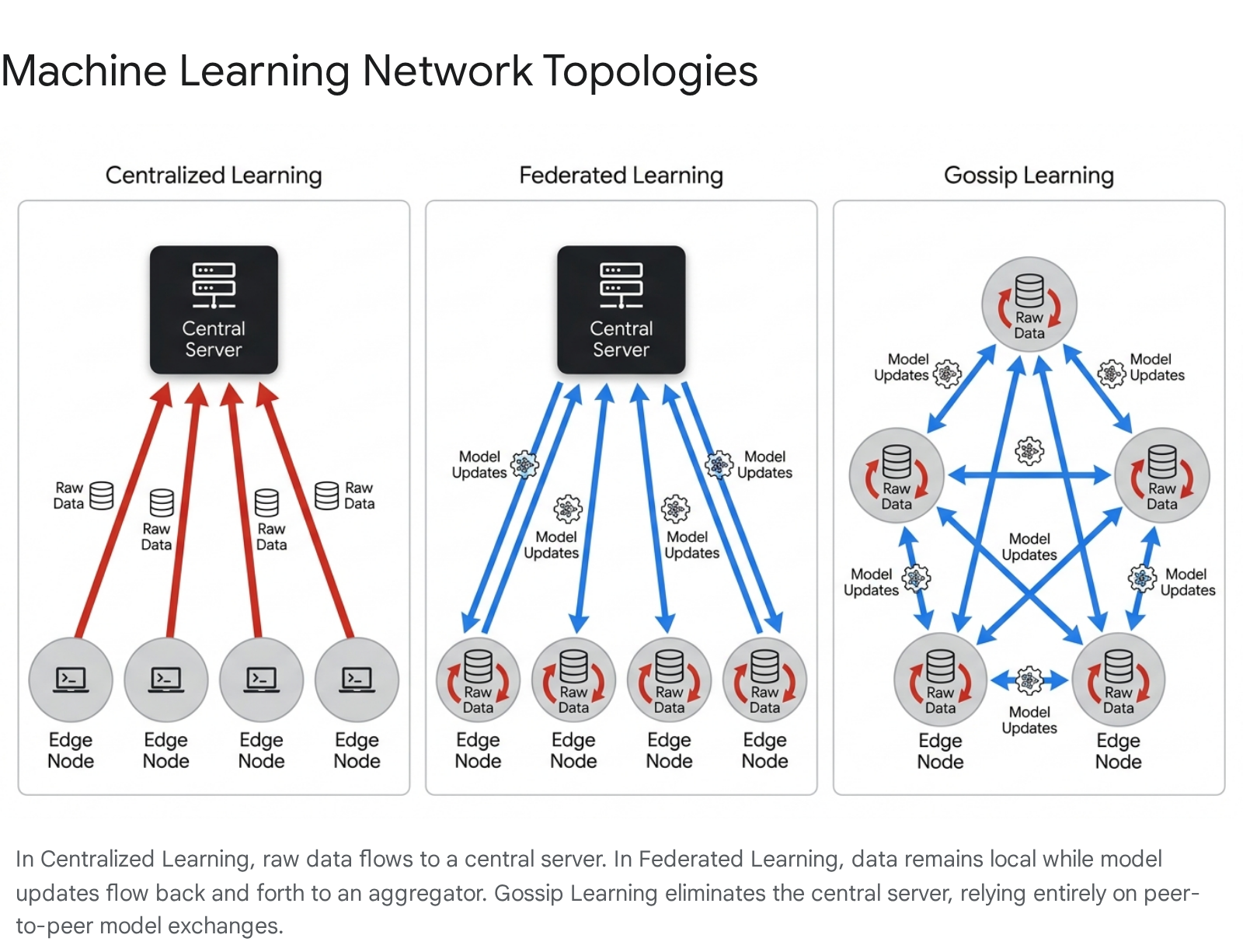
The Transition from Centralized to Distributed Models
In a traditional centralized learning environment, all training data is harvested from edge devices and stored within a central repository. The model trains directly on this consolidated dataset. Centralization provides developers with absolute control over the data distribution, simplifying the process of debugging and optimization by allowing direct inspection of the dataset for imbalances 2. Furthermore, centralized data centers deploy hardware with massive memory bandwidth and processing power, ensuring that the computational overhead of training foundation models is minimized. However, this approach presents significant liabilities. Centralizing vast amounts of data creates a highly lucrative target for cyberattacks, resulting in a single point of failure 36. Additionally, the transfer of raw data incurs exorbitant bandwidth costs and frequently violates modern data sovereignty regulations, rendering centralized learning untenable for highly sensitive sectors such as healthcare and banking 258.
The Mechanics of Federated Aggregation
Federated learning mitigates the vulnerabilities of data centralization by keeping raw data localized on the edge devices or organizational servers where it was originally generated. A central orchestrator server distributes a baseline global model to the participating nodes. The nodes execute training algorithms using their private datasets to compute localized parameter updates. These parameter updates, representing learned insights rather than underlying data, are transmitted back to the orchestrator. The central server aggregates these updates to refine the global model 58. While this architecture successfully preserves raw data privacy and reduces the bandwidth required for bulk data transfer, it introduces new systemic complexities. The central aggregator must synchronize updates across highly heterogeneous devices, many of which may experience intermittent network connectivity. Furthermore, the reliance on a central server for model aggregation retains a structural bottleneck and a centralized point of trust within the network 27.
Fully Decentralized Peer-to-Peer Networks
To address the bottleneck of the central orchestrator inherent in federated learning, researchers have developed fully decentralized architectures, commonly referred to as Gossip Learning. Gossip Learning operates as an asynchronous, peer-to-peer network that entirely eliminates the need for a central aggregation server. In this topology, each participating node maintains its own local model and trains it using its private dataset. The nodes communicate directly with neighboring peers via a dynamic discovery mechanism, engaging in random walks to exchange model parameters 8910. When a node receives a model from a peer, it merges the incoming parameters with its own local model. This protocol relies solely on message passing and requires no centralized cloud resources. Empirical studies comparing Gossip Learning to standard federated learning reveal that the decentralized approach offers comparable predictive accuracy and superior resilience against single points of failure. However, the lack of a central coordinator means that Gossip Learning can experience slower global convergence rates and increased localized communication overhead as models propagate organically through the network topology 91011.
Architectural Feature Comparison
The distinctions between the three primary machine learning architectures dictate their applicability to specific enterprise and consumer use cases. The decision to deploy a specific topology requires balancing computational scale, privacy requirements, and network reliability.
| Architectural Feature | Centralized Learning | Federated Learning | Fully Decentralized (Gossip) Learning |
|---|---|---|---|
| Data Location | Centralized on a primary server | Localized on edge devices | Localized on edge devices |
| Model Training | Executed centrally over aggregated data | Executed locally; aggregated centrally | Executed and merged locally via peer-to-peer |
| Network Dependence | Requires continuous, high-bandwidth connection | Can operate over intermittent connections | Highly resilient to network disruptions |
| Privacy Protection | Low; raw data is fully exposed to the host | High; only parameter weights are transmitted | High; weights are passed only to adjacent peers |
| Scalability Limitations | Bounded by central server storage and compute | Bounded by central orchestrator synchronization | Highly scalable; limited by local device capacity |
| Communication Overhead | Maximum; continuous raw data upload | Moderate; full parameter transmission | Moderate; continuous peer-to-peer parameter exchange |
Table 1: Comparative analysis of machine learning network topologies 581213.
Federated Learning Network Classifications
Within the domain of federated learning, architectures are broadly categorized into two primary frameworks depending on the scale, reliability, and computational power of the participating nodes. These are defined as cross-device and cross-silo computations.
Cross-Device Federated Computations
Cross-device federated learning encompasses massive populations of edge hardware, typically ranging from hundreds of thousands to hundreds of millions of individual endpoints, such as smartphones, wearable fitness trackers, and autonomous IoT sensors 1415. In this environment, the data distribution is overwhelmingly characterized by Horizontal Federated Learning (HFL), meaning the datasets across all devices share the exact same feature space but contain completely different data samples 14.
Because mobile devices rely heavily on limited battery capacities and unstable wireless connections, node reliability in cross-device networks is exceptionally low. Only a tiny fraction of the total device population is available to participate in training at any given time. To manage this volatility, cross-device architectures employ complex microservice ecosystems, including task-assignment schedulers, active-task collectors, and differential privacy aggregators, ensuring the central server can construct a viable model despite continuous node drop-outs 14. Primary applications for this architecture include mobile predictive typing, localized voice recognition processing, and personalized content recommendation engines 21418.
Cross-Silo Federated Computations
In contrast, cross-silo federated learning operates across a highly restricted consortium of institutional participants, generally numbering between two and one hundred entities 1415. These nodes represent substantial legal or corporate entities, such as distinct hospital networks, regional banks, or competing pharmaceutical research laboratories. Participants in cross-silo networks possess robust computational hardware, continuous high-availability power infrastructure, and dedicated high-bandwidth network connections.
The data distribution in cross-silo environments is significantly more complex. While it supports standard Horizontal Federated Learning, it also frequently encounters Vertical Federated Learning (VFL), where participating institutions hold data regarding the exact same individuals but track entirely different features. For example, a bank and an e-commerce platform may collaborate on the same user base to refine credit risk models without exposing their respective proprietary metrics 1416. Additionally, cross-silo networks utilize Federated Transfer Learning (FTL) when there is only partial overlap in both data samples and features. Primary use cases for cross-silo collaboration include inter-institutional medical diagnostics, genomic sequencing, and anti-money laundering investigations 1417.
| Feature Metric | Cross-Device Federated Networks | Cross-Silo Federated Networks |
|---|---|---|
| Participant Scale | Massive (100,000s to millions of devices) | Restricted (2 to ~100 distinct entities) |
| Node Characteristics | Mobile devices, IoT sensors, vehicles | Institutional servers, enterprise data centers |
| Node Reliability | Intermittent; highly dependent on battery state | Continuous availability; high uptime guarantees |
| Primary Data Partitioning | Horizontal Federated Learning (HFL) | Horizontal, Vertical (VFL), Transfer Learning (FTL) |
| Collaboration Model | Managed entirely by a central orchestrator | Centralized, decentralized, or consortium coordination |
| Operational Challenges | Intermittent connectivity, strict memory limits | Secure communication channels, legal coordination |
Table 2: Delineation of cross-device and cross-silo federated learning architectures 141517.
The Communication and Optimization Cycle
The efficacy of a federated learning architecture depends entirely on its communication protocol, which dictates how decentralized, asynchronous computations are synchronized into a cohesive and accurate global model.
The Federated Averaging Protocol
The foundational algorithm driving modern federated networks is Federated Averaging (FedAvg). FedAvg serves as an advanced generalization of Federated Stochastic Gradient Descent (FedSGD). Under the older FedSGD protocol, edge devices were required to transmit gradients back to the server after every single computational batch, which created an insurmountable communication overhead on constrained networks 1218. FedAvg fundamentally alters this dynamic by permitting local nodes to execute multiple mini-batch updates over several local epochs before initiating communication with the central server.
The FedAvg communication cycle executes through a meticulously structured iterative loop. The process commences with the initialization phase, wherein the central orchestrator selects a specific neural network architecture and establishes the baseline global parameters. The server then executes the client selection phase, algorithmically choosing a subset of available nodes to participate in the current round, leaving unselected nodes dormant to preserve network bandwidth and localized energy reserves 81818.
Following selection, the central server enters the configuration phase, transmitting the current global model state along with strict training hyperparameters to the chosen nodes. During the local training phase, the edge devices apply stochastic gradient descent using their private, isolated data repositories to modify the model weights. The nodes subsequently enter the aggregation phase, transmitting their updated weights back to the central server. The server then executes a global update by calculating the weighted average of the received parameters, prioritizing the contributions based on the respective data volumes processed by each node. This entire cycle loops continuously until the global model achieves convergence or satisfies a predefined performance threshold 818.
Advanced Optimization Strategies
While FedAvg revolutionized decentralized training, it faces limitations when applied to the vast parameter spaces of Large Language Models (LLMs). The risk of exploding or vanishing gradients during the local training of complex transformer architectures significantly destabilizes the global aggregation process. Consequently, modern federated deployments increasingly rely on adaptive optimizers, such as FedAdamW, which algorithmically adjust learning rates and incorporate weight decay to accelerate model convergence and improve the qualitative output of the final model while minimizing total communication rounds 19.
Systemic Bottlenecks and Physical Limitations at the Network Edge
Although federated learning successfully mitigates the severe privacy risks associated with centralized data harvesting, distributing algorithmic training to the edge of the network introduces profound physical constraints. These systemic limitations manifest primarily across computational efficiency, energy consumption, and transmission bandwidth 1920.
Hardware Heterogeneity and Memory Bandwidth Constraints
A fundamental bottleneck in federated learning is the vast discrepancy in computational hardware between centralized cloud environments and edge devices. Within a data center, enterprise-grade processors such as the NVIDIA H100 NVL deliver a massive memory bandwidth of approximately 7.8 terabytes per second (TB/s) 19. This allows the hardware to maximize Model-FLOP Utilization (MFU) by rapidly feeding massive data batches into parallel processing cores. In contrast, the most advanced embedded edge processors, such as the NVIDIA Jetson AGX Orin, cap out at a memory bandwidth of roughly 0.2 TB/s 19.
Because of this restrictive memory bandwidth, increasing the batch size on edge hardware does not scale computational throughput efficiently. The duration of training steps, specifically backward passes and optimization routines, scales linearly on edge platforms rather than logarithmically as seen in data centers. Consequently, MFU metrics stagnate entirely on edge devices, rendering the hardware incapable of fully utilizing its theoretical parallel computation potential during federated training cycles 19.
Network Infrastructure and Transmission Latency
The sheer scale of modern machine learning models creates severe communication bottlenecks over standard wireless networks. Transmitting the full parameter updates of a large-scale foundation model requires a transmission capacity that exceeds the capabilities of standard enterprise and consumer infrastructure.
Data centers optimize distributed training by utilizing specialized, high-density interconnects. Technologies such as InfiniBand NDR or NVIDIA NVLink achieve node-to-node communication speeds ranging from 50 GB/s to 900 GB/s, facilitating the synchronization of billion-parameter gradients in milliseconds 2421. Conversely, edge federated learning relies on commercial wireless networks. A standard 4G LTE connection averages 40 Mbit/s for downloads and a severely restricted 15 Mbit/s for uploads 1926. Even assuming ideal 5G millimeter-wave deployments, the available bandwidth remains a fraction of data center interconnects 22.
Transmitting the gradient updates for a modern foundational model, which can easily exceed 1 gigabyte of data per round, over a 15 Mbit/s upload link transforms the communication phase into an hours-long process. In these scenarios, the system's granularity factor - the mathematical ratio of computation time to communication time - drops significantly below one. When communication totally eclipses computation, adding additional clients to the federated network provides no positive effect on total processing speed 19.
Energy Consumption and Battery Management
The power requirements necessary to support both intense edge computation and extended wireless transmission create severe constraints for cross-device federated networks. Edge hardware is frequently deployed in remote environments or relies entirely on finite mobile battery reserves. Furthermore, wireless data transmission is exponentially more energy-intensive than localized matrix multiplication. During federated workloads involving large foundation models, the energy consumed by the network interface to upload the parameter updates can exceed the energy consumed by the local GPU computation by up to four orders of magnitude 19. Without aggressive model compression techniques, full-parameter federated fine-tuning remains physically impossible on standard mobile hardware.
| Constraint Domain | Data Center Environment (Centralized) | Edge Environment (Federated) |
|---|---|---|
| Peak Memory Bandwidth | ~7.8 TB/s (e.g., NVIDIA H100) | ~0.2 TB/s (e.g., Jetson AGX Orin) |
| Network Interconnects | NVLink / InfiniBand (50 - 900 GB/s) | 4G LTE / Wi-Fi (~15 - 40 Mbit/s) |
| Computational Scaling | Logarithmic step-time scaling | Linear step-time scaling |
| Power Supply Reliability | Continuous, multi-megawatt capacity | Constrained, battery-dependent |
| Energy Disparity | Computation represents the primary energy draw | Transmission draws up to 10,000x more energy |
Table 3: Comparison of systemic physical constraints between centralized and federated network environments 19242122.
Parameter-Efficient Fine-Tuning in Large Language Models
To bridge the insurmountable gap between the massive architecture of foundational Large Language Models (LLMs) and the severe bandwidth and memory constraints of decentralized edge networks, developers employ Parameter-Efficient Fine-Tuning (PEFT). This methodology abandons full-parameter updates, choosing instead to isolate and train only a minuscule fraction of the neural network 192823.
The Necessity of Dimensionality Reduction
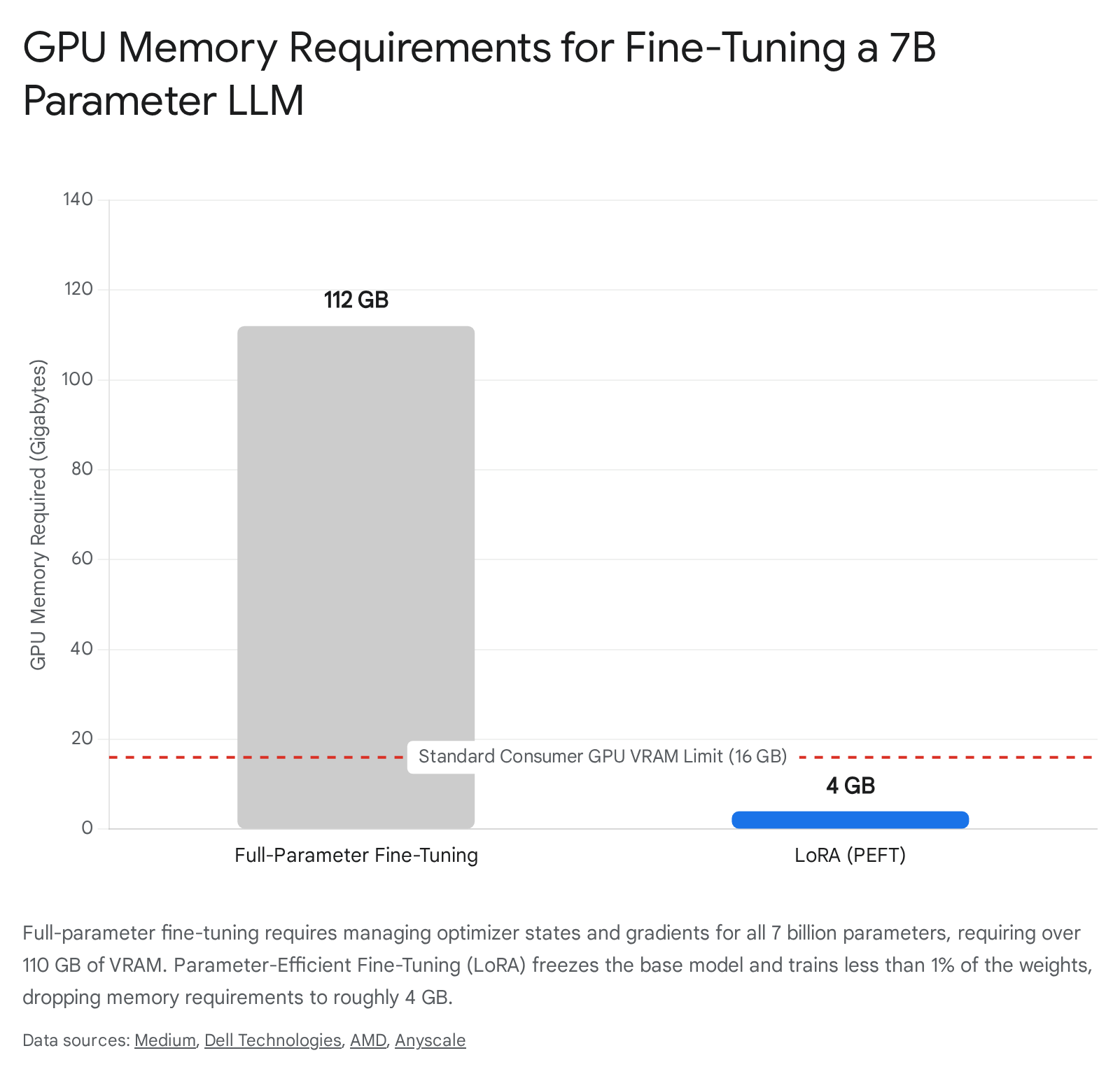
Applying standard full-parameter fine-tuning to an open-source model such as Meta's Llama 2 (featuring 7 billion parameters) requires devastating amounts of memory. If loaded in half-precision (FP16), the model's base weights alone require approximately 14 GB of Video RAM (VRAM) 242526. However, full-parameter training requires the allocation of vast amounts of memory to manage gradient checkpointing and the Adam optimizer states. Specifically, each trainable parameter requires 2 bytes for the weight, 2 bytes for the gradient, and 12 bytes for the optimizer states, totaling 16 bytes per parameter. Multiplying this across 7 billion parameters swells the required GPU memory footprint to over 112 GB 242633. This requirement vastly exceeds the capabilities of standard consumer GPUs or edge servers, rendering standard federated fine-tuning impossible.
Low-Rank Adaptation Mechanisms
Low-Rank Adaptation (LoRA) serves as the primary PEFT methodology utilized to overcome these constraints. LoRA operates by entirely freezing the base parameters of the pre-trained foundation model. Instead of updating the massive original weight matrices, LoRA injects highly compressed, trainable rank decomposition matrices (specifically, up-projection and down-projection matrices) directly into the model's transformer attention layers 192627.
By forcing the model to learn only within this low-rank subspace, the total volume of trainable parameters drops exponentially. In standard deployments, LoRA reduces the trainable parameter count to between 0.062% and 0.6% of the original model 2426. Consequently, the memory required to maintain the optimizer states and gradients collapses. Fine-tuning a 7-billion parameter model utilizing LoRA requires only about 4 GB to 5 GB of total GPU memory - a drastic reduction that allows advanced LLMs to be fine-tuned directly on consumer-grade edge devices, thoroughly unlocking the potential of Federated LLM (FedLLM) architectures 242526.
Overcoming Rank Heterogeneity in Federated Environments
Deploying LoRA across a federated network introduces severe mathematical complexities due to hardware heterogeneity. Because edge devices possess varying computational capacities, they often initialize their localized LoRA adapters using different internal rank configurations. The standard Federated Averaging (FedAvg) algorithm assumes that all model matrices share the exact same dimensionality. When FedAvg attempts to perform element-wise aggregation across LoRA updates of heterogeneous ranks, it generates profound mathematical alignment noise, severely corrupting the global model and causing accuracy degradation 2328.
To address this structural incompatibility, researchers have formulated specialized federated protocols to manage adaptive parameter integration:
- FLoRA: To neutralize the assumption that all clients must operate identical adapter configurations, FLoRA implements a novel stacking-based aggregation methodology. This algorithm expands the low-rank subspace and aligns heterogeneous parameter updates into a shared dimensional plane, entirely eliminating the generation of aggregation noise without resorting to arbitrary parameter padding or truncation 2328.
- RoLoRA (Robust Federated Finetuning): Early iterations of federated LoRA (such as FFA-LoRA) mandated the freezing of the down-projection matrices across all edge devices to aggressively conserve bandwidth. While communication-efficient, this drastically limited the neural network's expressiveness and increased volatility in environments suffering from severe non-IID (non-independent and identically distributed) data distribution. RoLoRA solves this by employing an alternating optimization sequence. It dedicates specific communication rounds strictly to updating the up-projection matrices, and alternating rounds strictly to the down-projection matrices. This technique fully restores the model's expressiveness and robustness against data heterogeneity while still successfully halving the required network bandwidth 27293038.
- FlexLoRA: This framework introduces dynamic adjustment protocols for local LoRA ranks. During aggregation, the server synthesizes a full-size weight matrix based on individual client contributions and utilizes Singular Value Decomposition (SVD) for subsequent weight redistribution. This approach completely circumvents the "buckets effect," wherein the entire federated network is constrained by the processing limitations of the weakest participating edge device 31.
Privacy Preservation Technologies and Regulatory Compliance
While the foundational principle of federated learning - keeping raw data localized - serves as an inherent privacy safeguard, the architecture is not immune to sophisticated cryptographic attacks. Hostile entities monitoring network traffic can potentially reverse-engineer the transmitted model gradients to extract sensitive information utilizing model inversion or membership inference attacks 3233. Consequently, enterprise federated systems must layer robust cryptographic and statistical defenses over the base architecture.
Cryptographic Defenses and Secure Aggregation
Secure Aggregation (SecAgg) provides a cryptographic shield against adversarial infiltration during the synchronization phase. Operating under the principle of extreme data minimization, SecAgg utilizes cryptographic masking to ensure that the central orchestrator server cannot inspect, read, or isolate the individual model updates transmitted by single devices. Instead, the mathematical protocol ensures that the server is only capable of decrypting the final, aggregated average of all participating weights 3443. This cryptographically guarantees that the orchestrator learns absolutely nothing about any specific user's individual contribution, establishing a zero-trust environment between the clients and the server.
Differential Privacy and Noise Injection
To further safeguard against reverse-engineering attacks, federated networks deploy Differential Privacy (DP). DP functions by injecting carefully calibrated statistical noise into the local model parameters before the device transmits them over the network. This deliberate obfuscation makes it mathematically impossible for an attacker to determine whether a specific, localized data point was utilized during the training cycle 4123536.
While traditional implementations utilize example-level differential privacy, modern federated systems deployed on mobile devices increasingly require user-level differential privacy. User-level DP represents a much stricter threshold, guaranteeing that adversaries cannot deduce anything regarding an entire user's participation history within the network 36. However, enforcing user-level DP requires the injection of exponentially larger volumes of noise into the model parameters. Because the model is continually fed imperfect, obfuscated information, its predictive accuracy inevitably degrades. The precise calibration of this noise multiplier remains a critical and highly contested area of research, as engineers struggle to balance mathematical privacy guarantees against the utility and convergence speed of the resulting machine learning model 183436.
Legal Frameworks: The GDPR and the EU Artificial Intelligence Act
Federated learning's decentralized nature aligns comprehensively with the core tenets of the European Union's General Data Protection Regulation (GDPR). By ensuring that personal data never leaves the host device, the architecture inherently fulfills the GDPR's mandates regarding data minimization and strict purpose limitation, drastically reducing the legal liabilities associated with cross-border data transfers and centralized cloud storage 323738.
However, the recent enactment of the European Union Artificial Intelligence Act (AI Act) presents profound legal complexities for federated systems. The AI Act categorizes specific use cases (such as medical diagnostics and automated biometric identification) as high-risk, mandating rigorous protocols concerning data governance, cyber resilience, and bias mitigation 3940. The legislation explicitly requires system operators to audit and evaluate all training data for potential bias and data poisoning prior to deployment. This establishes a severe architectural paradox: an FL server operator cannot legally audit the training data for bias because the secure aggregation and differential privacy protocols explicitly prevent them from accessing or viewing the decentralized data sets 50. Furthermore, legal analysts debate the specific liability of the central server. If an orchestrator enforces strict operational requirements upon the edge nodes regarding how their localized data must be processed, the server operator may inadvertently be classified legally as a "controller" under Article 4 of the GDPR, significantly escalating their regulatory liability 5051.
Sector-Specific Implementations and Clinical Case Studies
The capacity of federated learning to decouple the optimization of artificial intelligence from strict data ownership has catalyzed its rapid deployment across heavily regulated, data-sensitive industries worldwide.
Healthcare and Biomedical Diagnostics
In the medical sector, data is fiercely protected by stringent confidentiality regimes such as HIPAA in the United States. Such regulations actively prohibit the merging of patient databases. Cross-silo federated learning circumvents this barrier, enabling competing hospitals to collaboratively construct clinical AI models utilizing a diverse, global patient population without violating local privacy mandates.
A prominent implementation occurred in South Korea, spearheaded by Kakao Healthcare. The organization deployed an extensive federated platform across 16 competing university hospitals to predict breast cancer recurrence. The initiative processed records from approximately 25,000 patients. Without a federated framework, the legal compliance procedures required to centralize this data volume would have stalled research for years. The final federated model achieved an exceptional predictive performance score of 0.8482, definitively outperforming the siloed models trained independently at the participating hospitals, which recorded scores ranging from only 0.6397 to 0.8362 41.
The technology has similarly proven vital for increasing healthcare equity in data-scarce environments. A massive study evaluating COVID-19 mortality prediction across 21 geographically diverse Brazilian hospitals - encompassing 17,022 patients - utilized horizontal federated architectures, deploying Logistic Regression, Multi-Layer Perceptrons, and Random Forest models 42. The analysis revealed that the most profound statistical performance gains occurred within severely data-limited, under-resourced hospitals. The smallest participating facility, providing only 86 patient records, witnessed a dramatic performance improvement (ΔAUC of 0.3682) using the Random Forest model 42. However, researchers noted that federated systems remain highly vulnerable to non-IID data distribution; the Multi-Layer Perceptron model proved extremely volatile when exposed to diverse ethnic and socioeconomic patient data across the network, occasionally resulting in localized performance degradation 42.
Further expanding equitable access, researchers successfully deployed a federated obstetric ultrasound diagnostic tool across clinics in Algeria, Ghana, Egypt, Malawi, and Uganda. To overcome the severe infrastructure deficits and rolling power blackouts prevalent in rural Sub-Saharan Africa, the architecture was explicitly designed to operate on minimal edge hardware, successfully completing localized model training entirely on Raspberry Pi devices 545556.
| Medical Implementation | Geographies Involved | Data / Scale | Analytical Purpose |
|---|---|---|---|
| Kakao Healthcare | South Korea | 16 hospitals; 25,000 patients | Predicting breast cancer recurrence |
| Brazilian FL Study | Brazil | 21 hospitals; 17,022 patients | COVID-19 mortality prediction |
| African Ultrasound Project | Algeria, Ghana, Egypt, Malawi, Uganda | Multi-clinic; deployed on Raspberry Pi | Obstetric fetal plane classification |
| MELLODDY Consortium | Europe, Global | 10 major pharmaceutical corporations | Target-agnostic drug discovery |
Table 4: Prominent cross-silo federated learning implementations in global healthcare 41425443.
Financial Fraud Detection and Anti-Money Laundering
The financial sector faces an acute data scarcity problem regarding criminal activity. Specifically, fraudulent occurrences such as money laundering or sophisticated credit card theft represent a microscopic fraction (often less than 1%) of the total global transaction volume 4445. Isolated banking institutions lack the requisite volume of anomalous data necessary to train a highly reliable machine learning model, leading to systems plagued by excessive false-positive alert rates 45.
Federated learning resolves this data scarcity. In China, WeBank - the digital bank established by Tencent - developed the Federated AI Technology Enabler (FATE) platform. Collaborating alongside enterprise partners such as Clustar, WeBank deployed an industrial-grade federated network to merge credit insights across disparate financial institutions. By training shared models on encrypted updates, the banks successfully evaluated electronic invoices and shared consumer bases without directly exchanging proprietary transaction histories, resulting in an estimated 12% improvement in overall risk control effectiveness and lowering credit approval costs 164647. Similarly, the firm Consilient deployed specialized federated AML (Anti-Money Laundering) models capable of detecting illicit financial networks that intentionally distribute their laundering operations across multiple banks. By pooling behavioral insights rather than raw data, the federated approach proved three times more efficient than traditional centralized rules-based systems, increasing the detection rate of rare criminal events by 10% 456263.
Agricultural Yield Prediction and Internet of Things
Precision agriculture increasingly relies on massive sensor telemetry arrays and multispectral drone imagery to predict crop yields, monitor soil saturation, and preemptively detect localized plant diseases 6448. However, recent sociological surveys indicate extreme hesitation regarding data sharing; specific studies denote that up to 13% of farmers unequivocally refuse to upload operational data to centralized cloud servers due to profound concerns regarding corporate data sovereignty and the lack of regulatory oversight concerning agricultural AI 48.
Federated learning facilitates the integration of advanced agricultural AI by ensuring data remains localized. Edge processors mounted directly on farming equipment or local silos evaluate high-resolution RGB drone imagery and sensor telemetry. Only the optimized model weights are transmitted to the regional cooperative server. This methodology constructs a vastly superior, globally aware predictive model that spans highly diverse geographical soil types, while simultaneously ensuring individual farmer data privacy and completely sidestepping the severe bandwidth restrictions inherent to rural broadband networks 6448.
Global Market Dynamics and Geographic Adoption
The accelerated commercialization of federated learning has generated a rapidly expanding global market. The global federated learning market size was estimated at approximately $138.6 million to $151.1 million in 2024, with conservative projections indicating a Compound Annual Growth Rate (CAGR) between 13.6% and 14.4%, pushing the market valuation toward $300 million to $500 million by the early 2030s 6667.
Market Dominance in North America and Europe
Presently, North America commands absolute market dominance, representing roughly 32% to 36.7% of the global market share in 2024 6667. This hegemony is fueled by a highly mature digital infrastructure landscape, dense clusters of cloud computing providers, and aggressive capital investment in enterprise artificial intelligence. More critically, the implementation of severe data privacy mandates - including the California Consumer Privacy Act (CCPA) and the overarching Health Insurance Portability and Accountability Act (HIPAA) - forces North American institutions to aggressively adopt decentralized, privacy-preserving machine learning architectures 676869.
Europe mirrors this trajectory, utilizing federated architectures strictly to navigate the severe compliance penalties mandated by the General Data Protection Regulation (GDPR). European technological growth is heavily supplemented by state-sponsored research grants, cross-border academic consortia, and strategic deployments within the automotive and manufacturing sectors 666970.
Accelerated Expansion in the Asia-Pacific Region
The Asia-Pacific region is currently witnessing the most explosive adoption rate globally, with industry analysts projecting an aggressive CAGR exceeding 31% over the next decade 6670. Strategic deployments in China, Japan, South Korea, and India are prioritizing the integration of federated AI directly into telecommunications, advanced manufacturing, and state-sponsored digital healthcare programs 6667. The region's distinct advantage lies in its aggressive rollout of 5G infrastructure. By establishing dense, high-bandwidth, and low-latency mobile networks, the Asia-Pacific market effectively neutralizes the primary communication bottleneck inherent to edge-based federated training, allowing complex architectures to operate seamlessly across mobile and IoT devices 6670.
Democratizing Artificial Intelligence in Emerging Markets
Latin America, the Middle East, and Africa are currently characterized as developing markets regarding federated learning implementations. The structural deficit is stark; in 2023, these regions collectively accounted for a mere 11.2% of total global digital data creation, while North America, Europe, and the Asia-Pacific region generated the remaining 88.8% 49. This massive disparity positions developing regions overwhelmingly as passive consumers of AI technologies rather than active developers. Consequently, foundation models trained exclusively on Western datasets suffer from severe demographic, medical, and socioeconomic bias when deployed in these emerging markets 4249.
Federated learning is increasingly recognized as the primary technological vector capable of rectifying this imbalance. By enabling decentralized collaboration, federated architectures allow under-resourced medical facilities, agricultural cooperatives, and regional banks in Africa and Latin America to collaboratively construct localized, highly accurate, and culturally unbiased AI models. Crucially, the technology allows these regions to develop advanced AI ecosystems independently, bypassing the need for massive, centralized cloud infrastructure that remains economically or structurally unviable in emerging markets 4255567049.