Feature universality in neural networks
Feature universality describes the empirical observation that distinct artificial neural networks, despite significant differences in architecture, parameter scale, initialization constraints, and training data, consistently converge upon highly analogous internal representations and computational mechanisms to solve similar tasks 12. This convergence implies that deep learning models do not memorize arbitrary, dataset-specific functions; rather, they discover fundamental, robust structures inherent to the data distribution itself 13.
The systematic study of feature universality forms the theoretical bedrock of mechanistic interpretability, a subfield of artificial intelligence research aiming to reverse-engineer the opaque, high-dimensional weight matrices of trained neural networks into discrete, human-understandable algorithms 44. By identifying universal features and circuits, researchers seek to bridge the epistemic gap between microscopic neuronal activations and macroscopic model behavior, thereby facilitating cross-model knowledge transfer, safety auditing, and the development of robust alignment protocols 26.
Foundational Concepts in Mechanistic Interpretability
To rigorously investigate the universality hypothesis, researchers must first isolate the functional units of computation within a neural network. In the context of mechanistic interpretability, a "feature" is defined as a specific property of an input - such as a geometric curve in a visual field, a syntactic dependency in a sentence, or an abstract conceptual entity - that is systematically and causally represented by the model's internal latent states 1.
The Linear Representation Hypothesis and Polysemanticity
Early approaches to interpretability attempted to map single features to individual neurons. However, empirical studies quickly demonstrated that neural networks inherently utilize distributed representations. This phenomenon, formalized as the linear representation hypothesis, posits that features are represented as linear directions within the activation space rather than being bound to orthogonal, individual neurons 5.
A direct consequence of this geometric arrangement is polysemanticity, or superposition. Superposition occurs when a network learns to represent a greater number of distinct features than the mathematical dimensionality of its activation space allows. It achieves this by storing features as nearly orthogonal vectors in a high-dimensional space, causing individual neurons to activate in response to multiple, entirely unrelated concepts 567. Because features are entangled and distributed across numerous neurons, direct neuron-to-neuron comparisons across different models are largely ineffective for proving universality, necessitating advanced mathematical interventions to disentangle the representation space 108.
Resolving Superposition with Sparse Autoencoders
To overcome the challenges posed by superposition, researchers have widely adopted dictionary learning techniques, primarily utilizing Sparse Autoencoders (SAEs). An SAE is an auxiliary, unsupervised neural network trained to reconstruct the dense, polysemantic activations of a primary model (such as a vision encoder or a large language model) by projecting those activations into a much larger, but strictly sparse, set of learned feature directions 913.
By applying sparsity constraints during training - such as an $L_{1}$ penalty, JumpReLU functions, or TopK activation constraints - SAEs effectively disentangle the compressed activation space into discrete, monosemantic, and human-interpretable features 1310.
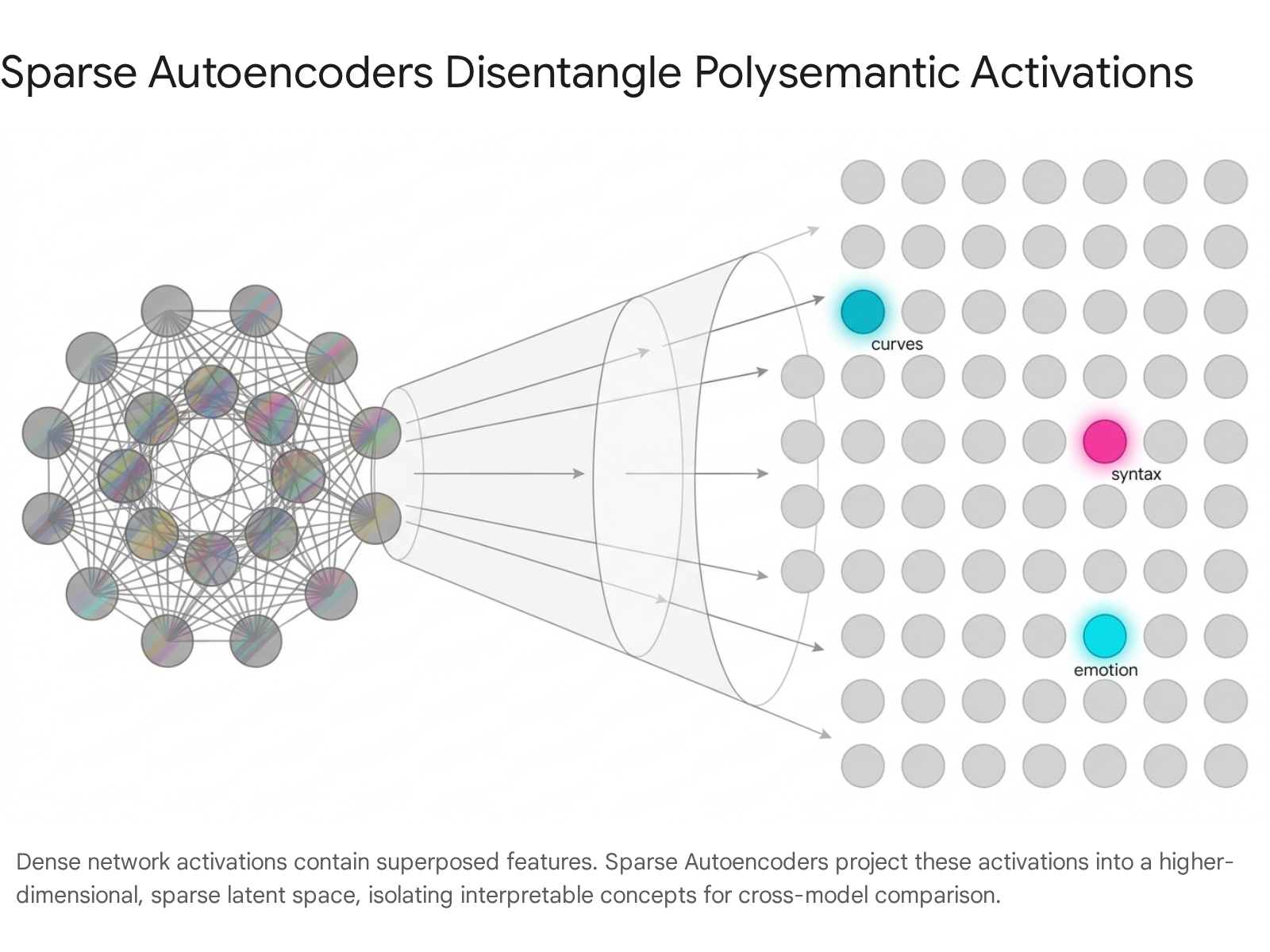
This projection reveals the underlying compositional variables that the model uses to reason about its input. Once the latent representations are decomposed via SAEs, researchers possess a structured vocabulary of features that can be systematically compared across different models using correlation and similarity metrics 815.
Theoretical Frameworks of Universality
The concept of universality is not monolithic; it exists on a spectrum ranging from strict anatomical isomorphism to broad functional alignment. To adequately capture the nuances of cross-model convergence, researchers typically divide the hypothesis into strong and weak formulations, applying sophisticated measurement techniques to validate these claims.
Strong Universality Versus Analogous Feature Universality
The strong universality hypothesis posits that different models trained on similar data distributions will learn identical circuits and features, represented in highly similar structural configurations 15. Evidence for strong universality is often found at the lowest levels of computational abstraction. For example, local edge detectors, orientation-specific line detectors, or color contrast receptors emerge identically across nearly all vision architectures, regardless of whether the model utilizes convolution or self-attention 1112. However, strong universality frequently breaks down at higher levels of abstraction or across fundamentally different architectures, where models may calculate the same semantic output utilizing highly divergent internal algorithms 13.
To account for this architectural variance, recent studies have introduced "Analogous Feature Universality." This weaker hypothesis suggests that even if different models do not learn the exact same feature representations point-for-point, the geometric spaces spanned by their learned features are structurally similar 69. Under this framework, one model's representation space can be effectively mapped to another's using rotation-invariant transformations. This implies that while the specific coordinate systems of the features may vary depending on the model's initialization, the underlying relational manifold of the concepts remains constant.
Methodologies for Measuring Representational Similarity
To quantify Analogous Feature Universality, researchers employ a multi-step analytical pipeline. First, the permutation issue - where models represent features in different orders and physical locations - is resolved by pairing SAE features across models based on activation correlation over a shared dataset 9. Once features are paired, the rotational variance is addressed by applying invariant representational similarity measures to the SAE decoder weight matrices rather than the raw activation spaces 9.
The primary metrics used in this analysis are Singular Value Canonical Correlation Analysis (SVCCA) and Representational Similarity Analysis (RSA). SVCCA measures how well the subspaces of paired features align via linear transformations, while RSA quantifies the similarity of relational distances between features across models 109. If the relative distance between the feature vector for "king" and the feature vector for "queen" is identical in two different models, RSA will yield a high similarity score, providing robust mathematical evidence that both models have developed a universal semantic map of the world.
Equivariance and Motif Reusability
Universality is inextricably linked to the mathematical concept of equivariance. Equivariance occurs when a network learns a family of distinct but analogous features that respond systematically to predictable transformations in the input data 119. In vision models, rotational equivariance manifests when a model learns identical "curve detector" circuits for different angles of a curve, simply rotating the internal weights to match the geometric transformation 19.
Similarly, models frequently exhibit translation and scale equivariance, effectively reusing a learned algorithmic motif across different spatial locations or image resolutions 314. Mechanistic interpretability heavily leverages equivariance by assuming that understanding one feature within a functional family allows researchers to reliably generalize that understanding to the entire manifold of related features, significantly reducing the dimensionality of the interpretability challenge 12.
Feature Convergence in Vision Architectures
The visual domain provides some of the earliest, most rigorously tested, and robust evidence for feature universality. Despite significant historical shifts in computer vision architectures - moving from rigid convolutional filters to dynamic attention mechanisms - the internal abstractions learned by these models exhibit stark, undeniable similarities.
Convolutional Abstractions and Inductive Biases
In Convolutional Neural Networks (CNNs) such as ResNet and InceptionV1, feature extraction heavily relies on structural inductive biases - specifically, local receptive fields and translation invariance enforced by the sliding window of the convolution operation 315. Extensive studies utilizing feature visualization techniques have comprehensively mapped the depth-wise evolution of features in these models.
Analyses reveal that early layers universally develop high- and low-frequency detectors, curve detectors, and highly specialized edge detectors 11142223. These primitive features act as the foundational building blocks of visual perception. As depth increases, CNNs systematically synthesize these low-level features into increasingly complex geometries, eventually forming highly specific, semantic object detectors in the final layers 1216. Interestingly, complexity metrics based on $\mathcal{V}$-information indicate that these features follow a recognizable "sedimentation process" during training. Foundational, simpler features compute early in the network and bypass the deep visual hierarchies via residual connections to directly influence final predictions, ensuring that robust, low-level signals are not lost during deep processing 1225.
Global Self-Attention in Vision Transformers
Vision Transformers (ViTs) radically disrupted the traditional CNN paradigm by abandoning the convolution operator entirely in favor of global self-attention applied to sequences of flattened image patches 152617. Because ViTs lack the strict spatial inductive biases of CNNs, one might theoretically expect their internal representations and computational mechanisms to diverge completely from those of convolutional models.
However, mechanistic interpretability studies reveal profound universality between the two distinct architectures. Despite lacking local receptive fields, ViTs spontaneously learn curve detectors, frequency detectors, and edge detectors that are functionally indistinguishable from those found in ResNets 1128. Through a framework known as the Block-Recurrent Hypothesis, researchers have demonstrated that the attention residual stream in ViTs functions much like the deep layers of a CNN, dynamically building scale-invariant representations and holistic spatial understanding through the continuous aggregation of patch interactions 31114.
Empirical Comparisons Between CNNs and Vision Transformers
To understand the practical implications of this universality, researchers conduct large-scale benchmarking tests comparing deep CNNs with Transformer-based architectures on standardized datasets.
| Evaluation Metric | ResNet-50 (Convolutional Baseline) | ViT-Base (Transformer Architecture) | Evidence of Universality and Divergence |
|---|---|---|---|
| Validation Accuracy (ImageNet) | 80.4% 18. | 80.3% 18. | Statistically identical macroscopic performance indicates functional universality at the task level 18. |
| Prediction Agreement Rate | N/A | N/A | When evaluated on 50,000 ImageNet validation images, the two models output the exact same prediction in 73.6% of cases, proving high algorithmic convergence 18. |
| Inference Speed | 7.26ms per image 18. | 5.35ms per image 18. | Differences emerge in hardware utilization; ViTs achieve 26% faster inference due to highly parallelizable matrix multiplication 18. |
| Low-Level Feature Emergence | High/low frequency, curve, and edge detectors 1114. | High/low frequency, curve, and edge detectors 11. | Foundational visual primitives are universally learned regardless of whether the mathematical operator is convolution or attention 11. |
| Spatial Dependency Tracking | Hardcoded via sliding convolutional windows 1517. | Dynamically learned via positional embeddings and self-attention 1517. | ViTs must expend parameter capacity to learn spatial hierarchies that are natively built into CNNs, though both ultimately represent space similarly 1117. |
Architectural Isomorphism in Large Language Models
As interpretability research extends beyond vision to analyze Large Language Models (LLMs), the universality hypothesis has been rigorously tested across varying parameter scales, training paradigms, and core sequence-modeling architectures. The evidence suggests a highly conserved set of algorithmic structures governing natural language processing.
Induction Heads and Function Vector Mechanisms
A defining hallmark of LLM capability is in-context learning (ICL) - the ability to generate highly relevant, task-specific responses based purely on a few prompt demonstrations without requiring any underlying weight updates 13. The discovery of "induction heads" provided the first mechanistic explanation for this behavior. Induction heads are highly specialized attention heads that execute a nearest-neighbor search within the context window; they search for a previous occurrence of the current token and systematically copy the token that followed it in the past 41330.
Induction heads demonstrate an exceptionally high degree of universality. They form at highly predictable points during the pretraining process across radically different language models, consistently aligning with a sharp, macroscopic drop in training loss 4. Furthermore, researchers have identified a broader class of "function vector" (FV) heads. FV heads compute a latent semantic encoding of an ICL task. Mechanistic tracing reveals a deep developmental connection: many FV heads actually originate as simple induction heads early in the pretraining process before organically transitioning to compute a more complex functional role, suggesting an evolutionary pathway for feature development within transformers 13.
Transformer Mechanics Versus State Space Models
To test the extreme boundaries of structural universality, researchers have compared standard Transformer architectures with entirely different sequence modeling paradigms, such as State Space Models (e.g., Mamba). When analyzing the internal mechanics of Pythia (a standard autoregressive Transformer) against an open-source Mamba model, studies confirmed that both models achieve highly similar internal representations 719.
By employing SAEs, researchers found that the depth of features along the model layers roughly matches across both architectures, suggesting a fundamental, architecture-agnostic feature hierarchy for language processing 719. Moreover, Mamba's induction circuits are structurally analogous to the induction heads found in Transformers. However, universality is not absolute. Mamba models exhibit a distinct "Off-by-One" motif - writing the information of one token into the State Space Model state at its subsequent position - a temporal dynamic inherently absent in the parallelized, stateless attention mechanism of standard Transformers 19.
Layer-Wise Evolution of Syntactic and Semantic Features
Across varying LLM families (such as Meta's Llama, Google's Gemma, and Mistral AI models), a highly consistent three-phase information flow emerges over the depth of the network. Early layers (typically Layer 0 to 10) primarily capture token-specific, syntactic features. These features act as low-level grammatical detectors, identifying punctuation structures, basic syntax rules, and mathematical notations 102021.
As information propagates deeper into the network, middle layers transition to broader semantic and conceptual processing, mapping entities, facts, and categorical relationships 921. Finally, the deepest layers encode highly abstract task semantics, complex logic derivations, and emotion-related features, preparing the final representation for next-token prediction 2021.
Crucially, quantitative analysis utilizing SVCCA reveals that Analogous Feature Universality is not uniform across model depth. When comparing the latent spaces of different models (e.g., matching Gemma-1-2B against Gemma-2-2B or Pythia architectures), the highest degree of spatial similarity consistently occurs in the middle layers. The SVCCA similarity scores form a distinct bell curve across network depth. Early layers display minimal similarity (scores often below 0.3) as they are highly sensitive to specific tokenization schemes and vocabulary quirks. The middle layers peak significantly, with SVCCA scores reaching between 0.7 and 0.8, indicating that disparate models universally converge on similar semantic sub-spaces to represent worldly concepts. In the final layers, similarity scores drop again as the representations diverge to accommodate model-specific output projection matrices and fine-tuning idiosyncrasies 89.
Scalable Alignment and Cross-Model Transfer
If feature universality holds true, it theoretically enables researchers to transfer insights, capabilities, and safety guardrails from one model to another without the need for expensive retraining or RLHF (Reinforcement Learning from Human Feedback). This represents the ultimate, practical objective of mechanistic interpretability: scalable AI alignment 44.
Universal Sparse Autoencoders and Crosscoders
Standard SAEs are inherently model-specific; an SAE trained on Llama cannot directly decode the activations of Mistral. To map concepts universally, researchers have developed "sparse crosscoders" and Universal Sparse Autoencoders (USAEs) 1022. A USAE is an overcomplete dictionary trained simultaneously on the dense activations of multiple, distinct pretrained neural networks 22. By optimizing a shared reconstruction objective, the USAE learns a singular, universal concept space capable of reconstructing the internal activations of any model included in its training manifold 22.
This advanced methodology proves that different architectures encode the exact same fundamental factors of variation. For example, crosscoders deployed on multilingual models show that monolingual linguistic features learned early in training consolidate into highly abstract, multilingual grammatical features in later checkpoints. This allows researchers to track how concepts map continuously across both temporal training stages and linguistic boundaries, proving that the underlying logic of language is universally represented 1035.
Concept-Basis Reconstruction for Safety Circuits
A highly impactful application of universality is the cross-model transfer of "steering vectors." Activation engineering allows researchers to modulate an LLM's behavior by intervening on specific latent directions (features) during inference, circumventing the need to alter the base weights 62035.
A prime example is the study of "refusal circuits," which dictate a model's propensity to decline harmful or malicious prompts. Recent studies demonstrate that safety alignment behaviors are implemented via stable, transferable semantic structures 636. Through sophisticated techniques like "Trajectory Replay" and "Concept-Basis Reconstruction," researchers can extract an intact refusal circuit from a donor model (e.g., a standard dense network) and successfully transfer it into a target model (e.g., a massive Mixture of Experts architecture) without requiring any target-side fine-tuning or refusal supervision 636.
By aligning the layers via geometric concept fingerprints and projecting the interventions away from high-variance weight subspaces using Singular Value Decomposition (SVD) stability guards, the intervention successfully suppresses refusal behaviors while preserving the model's overall capabilities. This capability to transplant cognitive mechanics provides the most compelling evidence to date for the semantic universality of safety alignment across LLMs 6.
Macro-Level Convergence Among Frontier Models
At a macroscopic, behavioral level, model behavior increasingly exhibits convergence, lending further credence to the universality hypothesis. Extensive analysis of cutting-edge models from Western providers (including OpenAI, Anthropic, and Google) and leading Chinese providers (such as Alibaba, Baidu, and DeepSeek) demonstrates that models trained on vast, internet-scale corpora invariably develop indistinguishable operational baselines on standardized benchmark tasks 233824.
For instance, DeepSeek-R1 and Alibaba's Qwen models not only match the output quality of their Western counterparts but exhibit highly correlated classification outputs, stylistic tics, and specific failure modes 234041. In rigorously controlled citation classification and authorship identification tasks, the textual outputs of DeepSeek showed maximum statistical similarity to those of Claude and Gemini 4041. This profound behavioral overlap strongly suggests that as pretraining datasets homogenize (often relying on Common Crawl and Wikipedia) and objective functions standardize, disparate engineering efforts ultimately force neural networks to approximate the same universal cognitive functions.
Methodological Skepticism and the Artifact Debate
Despite the considerable optimism surrounding mechanistic interpretability, the universality hypothesis is actively debated within the machine learning community. Critics argue that the analytical tools used to identify and extract features - particularly Sparse Autoencoders - carry heavy structural assumptions that may fundamentally bias the findings, creating illusions of universality 2543.
Temporal Priors and Stationarity Assumptions
A fundamental critique involves the mathematical priors inherently imposed by SAEs. SAEs utilize sparse coding techniques that were originally designed for stationary, non-sequential data, such as static visual images, where independent components combine linearly to construct the final output 4326. Human language, however, is a highly dynamic, sequential process defined by complex temporal dependencies.
By blindly applying visual-centric SAEs to LLM activations, researchers implicitly assume that the number of concepts necessary to explain the textual data remains constant over time (stationarity) and that features activate independently of temporal context 43. When the rigid mathematical structure of the interpretability tool misaligns with the fluid structure of the underlying data distribution, it can yield pathological results. Critics warn that this mismatch may artificially force the network's data into a "universal" linear format that does not accurately reflect the model's genuine, potentially non-linear internal mechanics 4345.
Initialization Variance in Dictionary Learning
Another significant methodological limitation is the inherent instability of dictionary learning algorithms. Empirical research indicates that SAEs trained on the exact same base model and identical dataset, differing only in their random initialization seeds, frequently converge on drastically different feature sets 713. In one comprehensive study evaluating an SAE with 131,000 latent variables trained on Llama 3, researchers found that only 30% of the learned features were shared across different initialization seeds 13.
If the interpretability tools themselves cannot reliably converge on a consistent set of features across independent runs, the broader theoretical claim that completely different neural networks universally converge on specific features becomes exceedingly difficult to validate definitively. Furthermore, strong universality is challenged by empirical variations in circuit prevalence. For instance, while induction heads are widespread, their relative contribution to in-context learning compared to function vector heads varies significantly depending on the specific model architecture evaluated 13.
| Domain of Analysis | Evidence Supporting Feature Universality | Evidence Challenging Feature Universality |
|---|---|---|
| Circuit Architectures | Both Transformers and State Space Models (Mamba) autonomously develop analogous induction circuits with similar depth profiles to perform in-context learning 719. | Significant functional variations exist, such as the "Off-by-One" memory motif which is present in Mamba but physically absent in standard Transformers 19. |
| Feature Representation | USAEs and crosscoders successfully align latent semantic spaces (e.g., emotions, syntax, and multilingual grammar) across structurally disparate models 922. | SAEs trained with identical data on the same model but different random seeds yield an alarmingly low 30% feature overlap, highlighting measurement instability 13. |
| Cross-Model Inference | Complex safety behaviors (such as refusal circuits) can be mathematically mapped and successfully transferred between different model families via steering vectors 636. | Interpretability tools may impose false stationarity priors on temporal language data, creating analytical artifacts rather than uncovering true mechanisms 43. |
Future Directions in Representation Engineering
Feature universality proposes that artificial neural networks, irrespective of their specific architectural design, tend to learn a common language of representations dictated by the fundamental statistical structure of the data they process. Supported by advances in mechanistic interpretability and Sparse Autoencoders, researchers have successfully identified conserved computational circuits - such as curve detectors in vision models and induction heads in language models - that persist across diverse architectures.
The theoretical transition from strong universality (the search for identical, isolated circuits) to analogous feature universality (the mapping of similar semantic subspaces) has allowed the field to successfully align concepts across models. This progress enables groundbreaking applications like zero-shot safety circuit transfer and cross-lingual conceptual mapping. However, the exact extent of this universality remains constrained by the limitations of current interpretability tools, which are demonstrably susceptible to initialization variance and structural biases that may misrepresent non-linear processes.
Moving forward, establishing rigorous, invariant mathematical definitions for interpretability will be essential. Researchers must develop dynamic analytical tools capable of handling temporal data without enforcing strict stationarity priors. Only by resolving the artifact debate can the field separate genuine universal cognitive mechanisms from the methodological biases of the tools used to observe them, ultimately paving the way for transparent, universally aligned artificial intelligence.