Dopamine and reward prediction error in learning and motivation
The Electrophysiological Foundations of Reward Prediction
For much of the twentieth century, the dominant paradigm in neuroscience characterized dopamine primarily as the biological substrate of hedonic pleasure. This conceptualization was driven by early intracranial self-stimulation studies demonstrating that rodents would relentlessly engage in operant behaviors to electrically stimulate dopaminergic pathways. However, this hedonic interpretation was fundamentally restructured in the late 1990s following a series of seminal electrophysiological experiments on nonhuman primates 12. These studies demonstrated that midbrain dopamine neurons do not encode the consummatory experience of a reward itself, but rather signal a reward prediction error (RPE) - the mathematical discrepancy between the anticipated value of a forthcoming outcome and the actual value received 123.
The paradigm shift surrounding dopaminergic function was catalyzed by the meticulous experimental designs of Wolfram Schultz and his colleagues at the University of Fribourg. By recording the extracellular action potentials of individual dopamine neurons in the ventral tegmental area (VTA) and substantia nigra pars compacta (SNc) of awake macaques, researchers observed precisely how these cells responded during associative learning 213. The experimental protocol generally involved pairing a previously neutral stimulus, such as a visual cue or a tone, with the subsequent delivery of a primary physiological reward, typically a small squirt of fruit juice delivered at a fixed temporal delay 213.
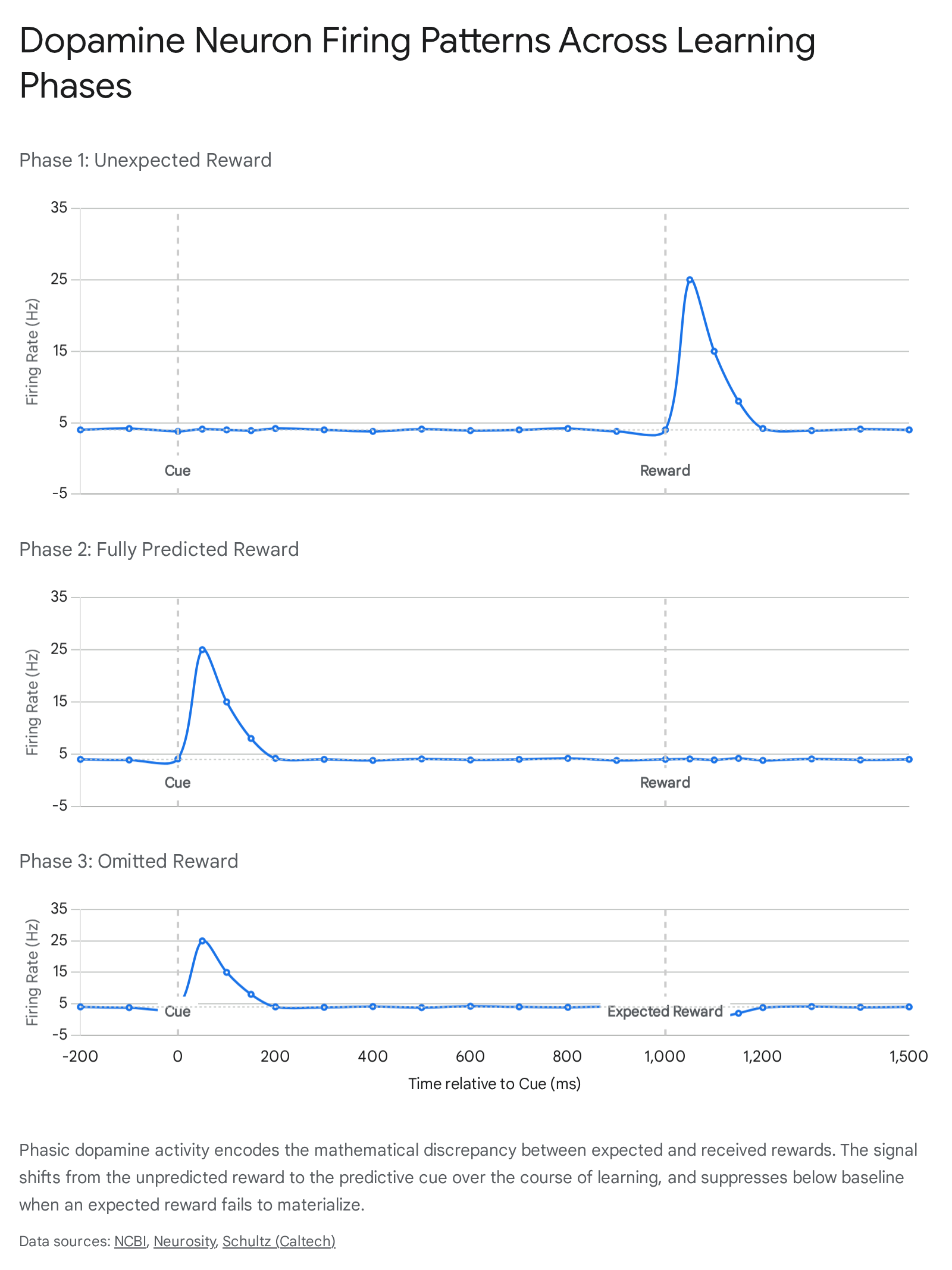
Schultz documented three highly specific, distinct phases of dopaminergic firing that perfectly aligned with formal computational models of learning:
First, in the initial stages of training before the animal had learned the predictive association, the delivery of the unpredicted juice elicited a rapid, phasic burst of action potentials. The basal firing rate of these dopaminergic neurons normally hovers between 3 and 5 Hertz (Hz). Upon the unexpected delivery of the reward, firing rates spiked dramatically to between 20 and 30 Hz in a brief burst lasting approximately 200 milliseconds. This neurophysiological spike constitutes a positive prediction error, signaling that the environment yielded an outcome better than currently expected 24.
Second, as the macaque learned that the visual or auditory cue reliably predicted the arrival of the juice, the phasic dopamine burst shifted temporally. The neurons began firing immediately upon the presentation of the predictive cue, reflecting a sudden increase in the expected future value. Crucially, at the exact moment the actual reward was delivered, the neuronal response remained precisely at the 3 to 5 Hz baseline. Because the outcome entirely matched the organism's updated expectation, the prediction error was zero, and no further teaching signal was generated 224.
Third, in probe trials where the predictive cue was presented but the expected reward was subsequently withheld by the researchers, the neurons fired upon cue presentation but exhibited a sharp, active suppression of firing at the exact millisecond the reward was scheduled to arrive. Firing rates dropped from the baseline rate to near 0 Hz. This constitutes a negative prediction error, signaling that the outcome was worse than the expectation 24.
These three fundamental conditions established that the primary function of phasic dopamine is not reward detection, but rather surprise detection. The dopamine signal updates predictive associations by broadcasting the margin of error to downstream target regions, thereby driving continuous environmental adaptation 256.
Computational Mechanics of Temporal Difference Learning
The biological findings extracted from primate electrophysiology provided remarkable empirical validation for a preexisting framework in computer science and artificial intelligence known as temporal difference (TD) reinforcement learning. The convergence of computational theory and biological observation, initially noticed by Peter Dayan and Read Montague, suggested that the mammalian brain had evolved a mathematically optimal algorithm for navigating probabilistic environments 27811.
In formal reinforcement learning theory, an autonomous agent seeks to maximize its cumulative future return. To do this, it must learn an accurate value function, $V(S_t)$, which estimates the expected discounted future rewards obtainable from a given state $S$ at a given time step $t$ 7913. Traditional Monte Carlo methods of learning require an agent to wait until the absolute end of a behavioral sequence to evaluate the final outcome and adjust prior expectations. Temporal difference learning, pioneered in artificial intelligence by Richard Sutton and Andrew Barto, sidesteps this inefficiency by allowing an agent to update its predictions incrementally. The algorithm bootstraps from its own sequential estimates, comparing the prediction at time $t$ with the updated prediction at time $t+1$ before the ultimate outcome is known 7813.
The Bellman Equation and Error Generation
The core mechanism of TD learning relies on an error signal, $\delta_t$, which is derived from the Bellman equation. The temporal difference error defines the discrepancy between successive value predictions and the immediate reward obtained. It is formalized as:
$$\delta_t = R_t + \gamma V(S_{t+1}) - V(S_t)$$
In this algorithm, $R_t$ represents the actual, instantaneous reward received at time $t$. The variable $\gamma$ denotes the discount factor, a parameter bounded between 0 and 1 that dictates how heavily the agent weighs distant future rewards compared to immediate ones. A discount factor closer to 1 implies long-term foresight, while a factor closer to 0 indicates steep temporal discounting and myopia. $V(S_{t+1})$ represents the estimated value of the next state the agent transitions into, and $V(S_t)$ is the estimated value of the current state 1191015.
If $\delta_t$ evaluates to a value greater than zero, the environment has yielded an outcome that is objectively better than the organism's prior internal model predicted. Conversely, a negative $\delta_t$ indicates a failure of the environment to meet the calculated expectation. This error term serves directly as a biological teaching signal 111015.
Synaptic Plasticity and Model Updating
The mapping of this algorithm onto neurobiology dictates that the phasic firing rate of midbrain dopamine neurons physically instantiates the mathematical TD error ($\delta_t$). This localized neurochemical surge is subsequently broadcast across broad neural projection targets, primarily the striatum and portions of the prefrontal cortex, where it acts upon glutamatergic synapses 141011.
At the synaptic junction, this instructional signal governs neural plasticity through an adaptation of Hebbian learning mechanisms. The dopaminergic burst modulates the update of synaptic weights $w$ in the corticostriatal pathway according to an internal learning rate, denoted as $\alpha$. The gradient of the value estimate with respect to the synaptic parameters dictates the magnitude of the structural change:
$$\Delta w = \alpha \delta_t \nabla_w \hat{V}_t$$
By selectively strengthening the specific synaptic connections that were active precisely in the moments leading up to a positive prediction error, the central nervous system cements the neural representations of the specific cues and motor sequences that reliably lead to beneficial outcomes. In essence, the dopaminergic prediction error acts as the teacher, while the corticostriatal synapse acts as the student 2411.
Neuroanatomical Substrates and Heterogeneity
While the classical RPE theory treated the dopamine signal as a scalar, homogenous value broadcast uniformly throughout the brain, highly advanced single-cell transcriptomics, precision optogenetics, and spatial recording technologies have revealed profound functional and anatomical heterogeneity across the dopaminergic midbrain 12131415.
The dopaminergic midbrain is predominantly composed of two adjacent neural populations: the ventral tegmental area (VTA) and the substantia nigra pars compacta (SNc). Together, these nuclei contain approximately 75 percent of all dopaminergic neurons in the human brain. Though situated in close physical proximity, they possess distinct developmental origins, project to divergent target structures, and mediate highly unique aspects of reinforcement learning 131416.
The Ventral Tegmental Area (VTA)
Neurons originating in the VTA project primarily via the mesocorticolimbic pathway to the ventral striatum, which prominently includes the nucleus accumbens, as well as terminating in the prefrontal cortex and basolateral amygdala. The VTA is fundamentally associated with classical associative learning, the evaluation of reward outcomes, and the attribution of incentive salience to environmental cues 131416.
Electrophysiological and optogenetic interrogations have shown that the VTA drives a flexible, scalable pursuit of rewards. Activation of VTA dopamine neurons imbues associated actions and cues with high motivational value, driving an organism to persistently pursue goals even when the precise environmental parameters change. Furthermore, distinct functional differences exist even within the VTA itself; neurons in the lateral VTA, which exhibit prominent $I_h$ (hyperpolarization-activated cation) currents, tend to project to the lateral shell of the nucleus accumbens and manage responses to previously learned tasks, while medial VTA neurons with higher firing rates support instrumental learning and novel reward acquisition 12141718.
The Substantia Nigra pars compacta (SNc)
In contrast, neurons situated in the SNc project dorsally, forming the nigrostriatal pathway that heavily innervates the dorsal and lateral striatum. The SNc has traditionally been linked almost exclusively to motor execution and voluntary movement control; the progressive degeneration of this specific population is the primary pathological mechanism underlying the motor deficits of Parkinson's disease 131618.
However, recent evidence demonstrates that the SNc also acts as a sophisticated reinforcement learning teaching signal. Unlike the broad, motivational value generated by the VTA, the SNc mediates a highly specific, relatively inflexible, and time-limited form of instrumental learning. It ties prediction errors directly to specific kinematic movements and action selection rather than generalized affective or motivational states. This functional split effectively mirrors the architecture of specific artificial "actor-critic" reinforcement learning models, wherein the VTA acts as the "critic" evaluating states and outcomes, while the SNc operates as the "actor" updating specific motor policies 131618.
Topographical and Neurochemical Heterogeneity
| Feature | Ventral Tegmental Area (VTA) | Substantia Nigra pars compacta (SNc) |
|---|---|---|
| Primary Projection Pathway | Mesocorticolimbic | Nigrostriatal |
| Primary Striatal Target | Ventral Striatum (Nucleus Accumbens), PFC | Dorsal and Lateral Striatum |
| Reinforcement Function | Flexible, model-based valuation and incentive salience | Inflexible, time-limited, precise action-specific learning |
| Behavioral Output | General motivational drive and goal-directed approach | Kinematic execution and specific motor policy selection |
| Pathological Implication | Addiction, Schizophrenia, Major Depression | Parkinson's Disease, Movement Disorders |
The heterogeneity of these systems extends far beyond their projection targets to the molecular profile of the individual neurons themselves. Modern fluorescent in situ hybridization (ISH) studies utilizing triple-transporter labeling have radically altered the perception of dopamine neurons as purely monoaminergic entities. Within both the VTA and the SNc, dopaminergic cells frequently synthesize and corelease other major neurotransmitters 1619.
Within the VTA, populations of neurons that synthesize dopamine (identified via the vesicular monoamine transporter, VMAT2+) are found alongside, and frequently overlap with, neural populations that release the primary inhibitory neurotransmitter GABA (VGAT+) and the primary excitatory neurotransmitter glutamate (VGLUT2+). Quantitative assessments in rodent models indicate that within the VTA, roughly 44% of cells are VMAT2+, 37% are VGAT+, and 41% are VGLUT2+, with significant overlaps. Approximately 20% of all VTA neurons express multiple vesicular transporters. In the SNc, pure dopaminergic neurons represent a slight majority (54%), but significant proportions of GABAergic (42%) and glutamatergic (16%) neurons are also present, with 10% of cells expressing multi-transmitter capabilities 1619.
This high degree of corelease suggests that dopaminergic cells do not merely provide a slow, diffuse modulatory wash over their targets, but actively participate in rapid, precise point-to-point excitatory or inhibitory synaptic transmission depending on the precise neural microcircuit they innervate 1619.
Dissociating Incentive Salience from Hedonic Impact
While the mathematical RPE model effectively explains how an organism continually learns to predict the timing and magnitude of rewards, it does not fully encapsulate the distinct psychological components of motivation and subjective pleasure. Extensive research led by Kent Berridge and Terry Robinson fundamentally deconstructed the colloquial concept of "reward" into three dissociable psychological and neurobiological processes: associative learning (the RPE teaching signal), "wanting" (incentive salience), and "liking" (hedonic impact) 202122.
Historically, psychology and neuroscience operated under the intuitive assumption that individuals "want" what they "like," and that both phenomena were mediated by a singular neural substrate primarily governed by dopamine. However, rigorous behavioral and pharmacological studies established that these are entirely separate brain systems that can be completely uncoupled under certain physiological or pathological conditions 212823.
The Mesolimbic Architecture of "Wanting"
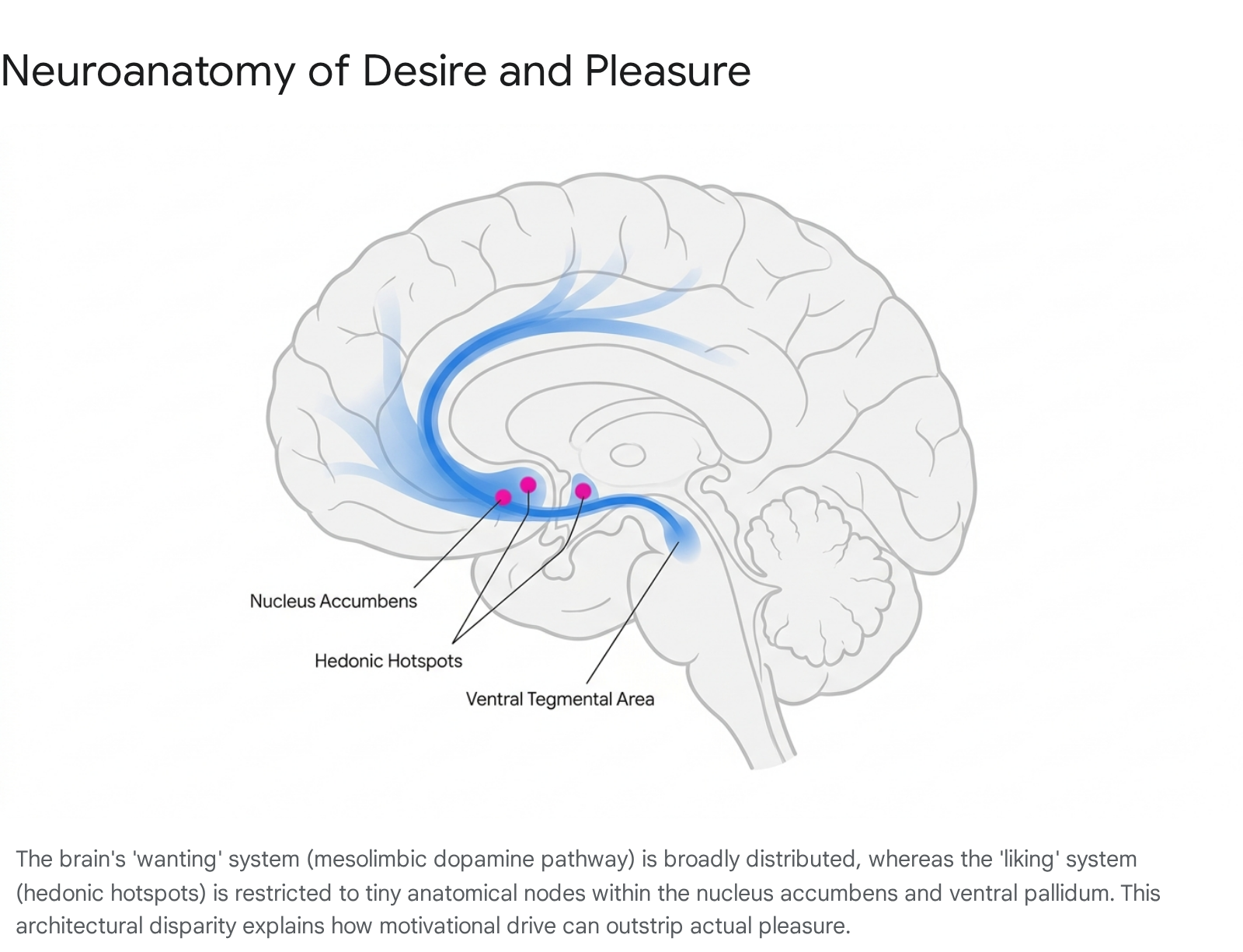
In the Berridge framework, "wanting" refers exclusively to incentive salience - a subcortical, visceral, and largely non-conscious motivational drive that compels an organism to approach a stimulus. It is the neurological process that transforms a neutral sensory representation (such as the sight of a lever, a drug paraphernalium, or a coffee machine) into an irresistible motivational magnet 202431.
This process is mediated primarily by the widely distributed mesocorticolimbic dopamine system. In experimental models where the dopaminergic system was chemically or optogenetically hyper-activated, rodents exhibited intense, compulsive "wanting" for a stimulus. For example, rodents would repeatedly approach and interact with an electrified stick despite receiving painful shocks, entirely driven by dopamine-induced incentive salience without showing any signs of increased subjective pleasure 313225. Conversely, dopamine-depleted mice lose all motivation to seek food and will starve to death if unassisted, despite maintaining the capacity to display normal facial reactions of pleasure if sweet food is placed directly into their mouths 2026.
The Micro-Anatomy of Hedonic Hotspots
"Liking," conversely, represents the actual hedonic pleasure experienced strictly during the consummatory phase of a reward. Hedonic impact is functionally independent of dopamine. The neural generation of pleasure is anatomically and neurochemically highly restricted. It relies almost exclusively on opioid, endocannabinoid, and GABAergic signaling within highly localized networks termed "hedonic hotspots" 20212427.
These hotspots are physically minuscule. In the rat brain, they measure approximately one cubic millimeter in volume, scaling up to an estimated cubic centimeter in the human brain. They are situated in very specific subregions of the nucleus accumbens, the ventral pallidum, and the brainstem parabrachial nucleus. Microinjections of opioid agonists directly into these precise hotspots can double or triple objective "liking" reactions to sensory pleasures (measured via cross-species facial expressions, such as rhythmic tongue protrusions to sweetness). However, injecting the same neurochemicals just millimeters outside of these boundaries fails to generate pleasure, demonstrating the extreme fragility and localization of true hedonic circuitry compared to the robust, brain-wide distribution of desire circuits 212427.
Pathological Uncoupling in Addiction
The stark biological division between wanting and liking provides a critical neurobiological explanation for the etiology of severe substance use disorders, formalized as the Incentive-Sensitization Theory. Addictive substances act as powerful pharmacological stressors that hijack the dopaminergic system, causing permanent neural sensitization of the incentive salience ("wanting") circuits without corresponding sensitization of the hedonic hotspots 243127.
Over time, the addicted individual experiences intense, cue-triggered cravings for the substance, even as profound neurochemical tolerance develops and the hedonic "liking" of the drug heavily diminishes. The individual continues to compulsively pursue the reward not because it yields pleasure or euphoria, but because the sensitized dopaminergic system has amplified the motivational value of the drug and its associated environmental cues to an irrational extreme. The biological decoupling explains why patients frequently report despising their addictive behavior while simultaneously feeling an insurmountable, visceral drive to execute it 20233127.
Challenges to the Scalar Model: High-Dimensional Learning
The scalar RPE hypothesis - that dopamine uniformly broadcasts a homogenous, one-dimensional value indicating whether the world is simply "better or worse than expected" - is increasingly viewed as an elegant but incomplete representation of the system's true complexity. A surge of research published throughout 2023 and 2024 demonstrates that dopamine neurons exhibit highly diverse functional tuning, calculating prediction errors across multiple non-reward dimensions and operating in highly dynamic spatiotemporal parameters 11152829.
Aversive Processing and Feature-Specific Errors
If dopamine strictly encoded reward prediction errors, it logically should not activate in response to aversive or entirely neutral, non-rewarding stimuli. However, multiple laboratories have recorded marked dopamine release in response to aversive events, such as mild electrical foot shocks, and high-intensity novel stimuli. Rather than tracking reward, these specific dopaminergic spikes suggest a tracking of sensory surprise, environmental volatility, or general stimulus salience 9112829.
Furthermore, researchers mapping populations in the tail of the striatum have discovered neurons specialized exclusively for action prediction errors and threat avoidance rather than reward acquisition. To reconcile the classic RPE theory with this undeniable heterogeneity, computational neuroscientists have proposed the "feature-specific prediction error" model. Rather than the VTA broadcasting a single, globally uniform scalar value, different subsets of dopamine neurons compute localized prediction errors for specific sub-components (or vectors) of the environment. One neuron may compute an RPE for a specific visual cue, while another computes an error for a distinct motor action. The full scalar RPE described by early theories is only effectively realized when these distributed, feature-specific signals are integrated together downstream in the intricate topography of the corticostriatal targets 152930.
Distributional Reinforcement Learning
Another profound modification to the biological implementation of the TD algorithm stems from the concept of "distributional reinforcement learning." Standard TD learning calculates a singular mean expected reward. However, organisms operating in volatile, real-world environments must assess risk and variance, requiring an understanding of the full probability distribution of possible outcomes 831.
Research combining artificial intelligence modeling with in vivo electrophysiology has demonstrated that individual dopamine neurons evaluate reward probability asymmetrically. Each dopaminergic cell possesses a unique "reversal point" - the specific threshold of reward magnitude at which the neuron ceases to register a positive prediction error. Certain neurons operate as "optimists," firing robust bursts even for minute rewards and scaling up their expectations quickly, while others operate as "pessimists," demanding massive rewards to elicit a burst and heavily amplifying negative errors. Collectively, the entire ensemble of optimistic and pessimistic dopamine neurons maps out the complete probability distribution of future outcomes across both time and magnitude, precisely mirroring the mathematical architecture of advanced distributional learning networks used in modern AI 831.
The FLEX Framework and Dynamic Time
The rigid temporal mechanics of standard TD models have also faced significant scrutiny. Traditional algorithms assume that the brain utilizes fixed serial states to track time relative to observable stimuli - an assumption that scales poorly in complex environments. Recent theoretical developments, such as the FLEX (Flexibly Learned Errors in Expected Reward) model, provide a biophysically plausible alternative 3233.
In the FLEX framework, dopamine release functions somewhat similarly to an RPE but drops the assumption of fixed temporal bases. Instead, neural representations of stimuli adjust their timing and relation to rewards dynamically and continuously in an online manner. This model accurately accounts for experimental data showing that dopamine release occasionally reflects the retrospective probability of a stimulus given a reward, a feature entirely incompatible with strictly forward-looking traditional TD algorithms 3233.
Spatiotemporal Waves and Hidden State Inference
A critical architectural assumption of the classic model was that dopamine release at the axon terminals within the striatum is purely a direct, passive consequence of somatic action potentials originating in the midbrain. Groundbreaking research has dismantled this assumption, showing that dopamine release can be locally modulated at the terminal level, entirely independent of midbrain somatic firing 3435.
Cholinergic Modulation and Traveling Waves
This localized axonal control is orchestrated primarily by striatal cholinergic interneurons (CINs). These large, specialized interneurons interact directly with dopamine axons via nicotinic acetylcholine receptors (nAChRs), specifically the alpha-4-beta-2 subtypes. When multiple CINs fire synchronously, their acetylcholine release "hijacks" the dopaminergic terminals, triggering local dopamine exocytosis without requiring a spike from the VTA or SNc 353637.
Utilizing high-resolution fluorescent biosensors, researchers have documented that this local release does not occur as a uniform wash. Instead, dopamine is released in continuous spatiotemporal "traveling waves" that traverse the mediolateral axis of the striatum. The dynamics of these waves are generated by a complex reaction-diffusion interaction between the cholinergic and dopaminergic networks. These findings necessitate a total revision of the volume-transmission paradigm, highlighting that dopamine operates with remarkable spatial precision on the micrometer scale, allowing for highly targeted modulation of specific neural ensembles 353637.
Hippocampal Coupling and Inference Ramps
Real-world environments are partially observable; organisms rarely possess complete, unambiguous sensory information about the state of the world. Consequently, dopamine must operate over hidden states using probabilistic inference 384739.
In complex behavioral tasks requiring spatial navigation or waiting through ambiguous temporal delays, dopamine levels frequently do not present as distinct, instantaneous phasic spikes. Rather, they manifest as gradual, shifting "ramps." These dopamine ramps scale continuously with an animal's proximity to a goal or fluctuate with its shifting internal belief state regarding which unobservable phase of a task it occupies. This indicates that dopamine incorporates sophisticated, model-based reasoning and continuous state inference, rather than merely caching simple model-free values 11384740.
This synthesis of memory, inference, and prediction error is further underscored by the recent discovery of hippocampal-striatal coupling during offline learning. Sharp-wave ripples (SWRs) in the dorsal CA1 region of the hippocampus - neural events associated with memory replay and behavioral planning - have been shown to reliably trigger dopamine transients in the ventral striatum approximately 0.3 seconds later. This mechanism provides the precise internal teaching signal required for temporal credit assignment, allowing the brain to update value estimates based on internally simulated memory replays rather than strictly relying on direct external feedback 41.
Clinical Misapplications: The "Dopamine Fasting" Trend
The profound expansion of dopaminergic research over the past three decades has unfortunately been paralleled by an influx of pseudoscientific misinterpretations in popular culture. The most prominent and clinically misguided of these phenomena is the "dopamine fasting" or "dopamine detox" trend 264243.
Dopamine fasting proposes that an individual can organically "reset" their brain's dopamine receptors and recalibrate baseline sensitivity by strictly abstaining from pleasurable, high-stimulation activities - such as utilizing social media, consuming highly palatable processed foods, listening to music, or even engaging in social interaction - for a predetermined temporal period 4243.
Neuroscientists universally emphasize that this concept relies on a fundamental, systemic misunderstanding of the neurotransmitter. Dopamine is not a toxin that accumulates in the nervous system, nor is it a finite metabolic resource tank that depletes and requires refilling through abstinence. Furthermore, because dopamine encodes mathematical prediction errors rather than the direct sensation of pleasure, a fast from external, pleasurable stimuli does not actually halt dopaminergic transmission. Dopamine continues to fire continuously to manage baseline motivation, posture, motor function, and the physiological processing of novel internal and external states 26425344.
A total cessation or true "fast" of dopamine signaling would not result in heightened focus or improved mental clarity; rather, it would rapidly manifest as the profound motor rigidity, anhedonia, and severe motivational deficits characteristic of advanced Parkinson's disease, effectively paralyzing the individual's capacity to initiate goal-directed behavior 264253.
The subjective utility that some individuals undeniably experience from undertaking a "dopamine fast" is not neurobiologically derived from a physical reset of dopaminergic receptor densities. Rather, it is derived from the unintentional application of basic Cognitive Behavioral Therapy (CBT) and mindfulness principles. By deliberately removing hyper-stimulating digital environments and constant technological interruptions, individuals practice impulse control and reduce psychological overstimulation. However, labeling this behavioral modification a "dopamine detox" dangerously oversimplifies the neuroscience, inappropriately conflates the chemical teaching signal with the hedonic experience itself, and propagates scientific inaccuracy within the general public 42435345.
Conclusion
The evolution of dopamine research represents a remarkable arc from a simplistic mid-twentieth-century conception of a "pleasure molecule" to the discovery of an elegant, algorithmically precise teaching signal. The temporal difference reward prediction error mechanism successfully united the biological reality of synaptic plasticity with the computational rigor of reinforcement learning, providing one of the most robust explanatory frameworks in modern neuroscience.
However, contemporary empirical data clearly indicates that the classic, homogeneous, scalar model is insufficiently complex to capture the full scope of dopaminergic action. The field is currently undergoing a paradigm shift toward high-dimensional computational frameworks. Dopamine operates through heterogeneous subpopulations that corelease multiple neurotransmitters, generates localized spatiotemporal waves through intricate cholinergic modulation, tracks sophisticated probability distributions through optimistic and pessimistic neural ensembles, and continuously integrates hidden state inferences and offline memory replays. Moving forward, unifying theories of motivation and learning must account for a distributed, feature-specific architecture, recognizing dopamine not merely as a monolithic alarm bell for reward, but as a highly nuanced, multidimensional calibration signal that continually optimizes an organism's predictive model of the world.