Distribution shift in machine learning systems
Introduction to the Generalization Problem
The foundational premise of traditional supervised machine learning relies heavily on the independent and identically distributed (i.i.d.) assumption. This core statistical principle posits that the dataset utilized to train an algorithmic model and the dataset encountered during real-world inference are drawn from the exact same underlying probability distribution. When the i.i.d. assumption holds, the paradigm of empirical risk minimization (ERM) functions exceptionally well, enabling algorithms to achieve high predictive accuracy by minimizing the average loss over the finite training sample. However, in practical deployment environments, the i.i.d. assumption frequently breaks down. Changing environments, shifting user demographics, evolving linguistic behaviors, and degraded hardware sensors invariably cause the source distribution (training) to diverge from the target distribution (deployment) 1234.
This systemic divergence is mathematically defined as distribution shift, sometimes referred to as data drift. According to the No Free Lunch Theorems for Optimization and Supervised Machine Learning, average performance across all possible problem distributions is identical; thus, a model's effectiveness is inextricably tied to its specific training data distribution 2. When a deployed model is fed data drawn from a shifted distribution, its performance undergoes severe degradation. This dynamic explains why artificial intelligence (AI) systems that demonstrate state-of-the-art accuracy in controlled laboratory benchmarks often fail catastrophically in production 56. Understanding the underlying topologies of distribution shift, measuring their impact across domains, and designing robust mitigation architectures form a critical frontier in modern AI reliability research.
Mathematical Taxonomy of Distribution Shifts
To systematically address distribution shifts, it is necessary to mathematically formalize how the joint probability distribution of input features ($X$) and target labels ($Y$), denoted as $P(X, Y)$, can morph over time or across geographies. The joint distribution can be factored into marginal and conditional probabilities via two standard decompositions: $P(X, Y) = P(Y|X)P(X)$ and $P(X, Y) = P(X|Y)P(Y)$. By isolating which specific components of these equations change, researchers categorize distribution shifts into distinct, well-defined typologies 2778.
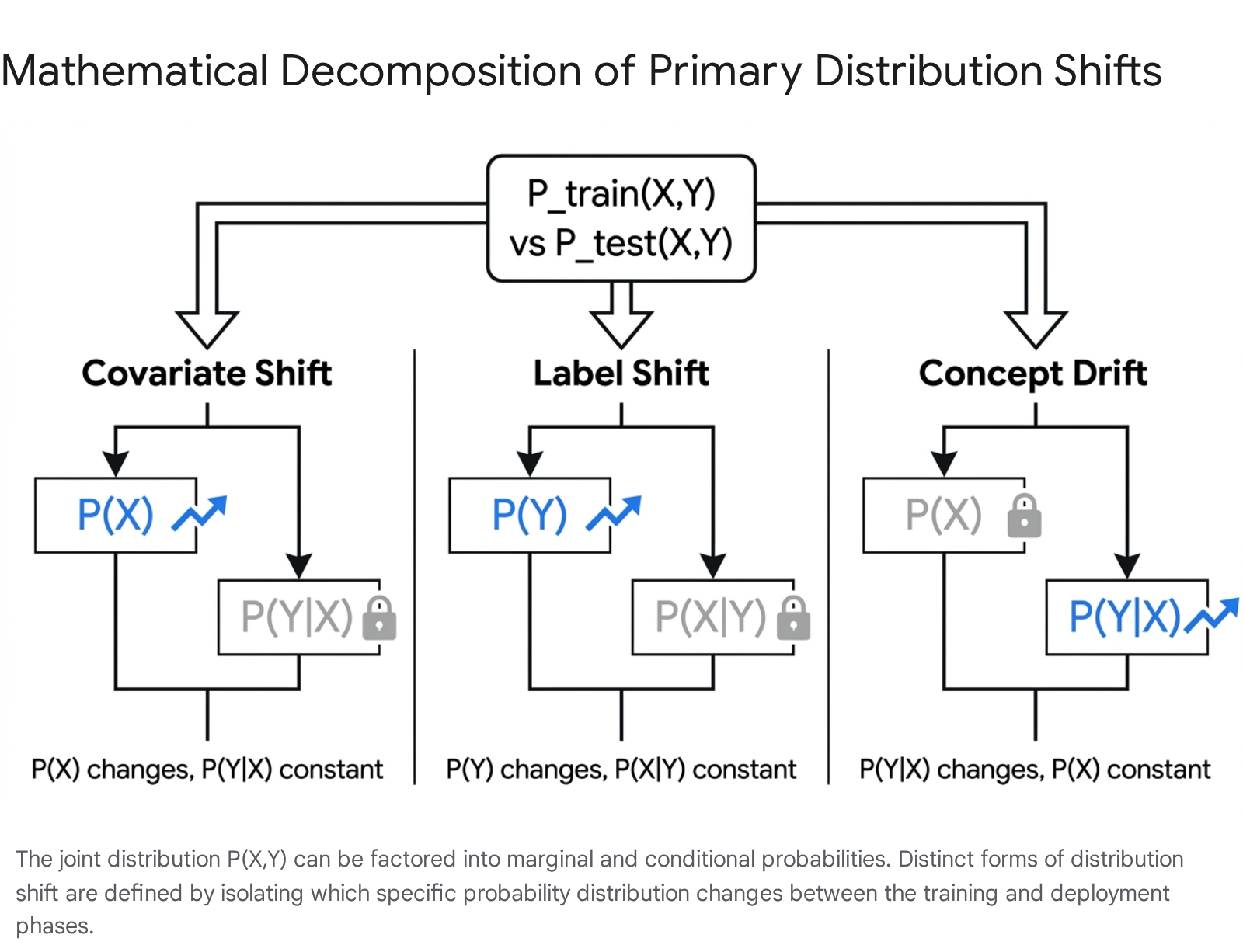
Covariate Shift
Covariate shift, occasionally documented as independent variable shift, occurs when the marginal distribution of the input features changes between training and testing environments ($P_{train}(X) \neq P_{test}(X)$), while the conditional distribution of the labels given the features remains absolutely constant ($P_{train}(Y|X) = P_{test}(Y|X)$) 12377. As the most widely studied form of distribution shift, covariate shift implies that the fundamental mapping or underlying rule defining the relationship between features and the correct output is stable, but the model is exposed to a vastly different density or frequency of inputs.
A classic illustration involves a self-driving car vision system trained exclusively on data captured during sunny conditions in California but deployed in the snowy streets of Boston. The visual covariates (snow, altered lighting, obscured lane markers) change drastically, yet the definition and conditional probability of a "pedestrian" or "stop sign" ($P(Y|X)$) remain identical 1. Similarly, an email spam filter trained on short text snippets experiences covariate shift when deployed to an environment characterized by lengthy emails from diverse time zones, provided the indicators of spam remain conceptually unchanged 7.
Prior Probability Shift (Label Shift)
Prior probability shift, or label shift, manifests when the marginal distribution of the target labels changes ($P_{train}(Y) \neq P_{test}(Y)$), but the conditional distribution of the features given the labels is preserved ($P_{train}(X|Y) = P_{test}(X|Y)$) 2377. This shift is fundamentally associated with anti-causal learning scenarios, wherein the target label $Y$ is the underlying root cause of the observed features $X$ 23.
In medical diagnostics, for instance, an AI model might be trained to predict an infectious disease based on observed patient symptoms. During a sudden localized epidemic, the prior probability of patients arriving at the clinic with that specific disease spikes drastically. The biological mechanism causing the symptoms - the conditional distribution $P(X|Y)$ - has not mutated, but the baseline frequency of the disease in the population has radically shifted 239. Because the class balance shifts, models optimized via standard cross-entropy for the original prior probabilities will severely miscalibrate their predictions 710. Overcoming label shift often requires leveraging invariant density ratios and establishing "Fisher consistency," utilizing techniques like Adjusted Count or Expectation-Maximization (EM) algorithms to unbiasedly recalibrate estimators to the new test set prevalences 10.
Concept Drift
Concept drift, or concept shift, is a more pernicious phenomena occurring when the relationship between the inputs and outputs organically evolves. Mathematically, the conditional distribution of the label given the input changes ($P_{train}(Y|X) \neq P_{test}(Y|X)$), while the marginal distribution of inputs $P(X)$ may or may not remain stationary 2377. This type of shift represents a structural fracture in the underlying forward causal mechanism.
A standard manifestation is observed in algorithmic financial forecasting or housing price predictions. A machine learning regressor trained on housing data prior to the COVID-19 pandemic learned a specific mapping of house features (square footage, location) to market prices. Following the pandemic, systemic macroeconomic conditions altered the market value of identical houses, fundamentally changing the output $Y$ for the exact same input features $X$ 7.
Conditional Probability Shift and Domain Shift
While the three categories above form the traditional taxonomic baseline, computational statisticians have identified more granular variations. Conditional Probability Shift (CPS) defines a novel scenario where the conditional distribution of the class variable given specific isolated features changes, while the distribution of the remaining features given the specific features and the class is rigorously preserved. Advanced modeling utilizing multinomial regression and the EM algorithm on medical databases like MIMIC has shown that traditional label-shift methods frequently fail to detect CPS 11. Furthermore, "domain shift" is frequently utilized as an overarching term describing a complete change in the joint distribution, often implying simultaneous covariate shift and concept drift across completely distinct operational environments 7.
Differentiating Systemic Machine Learning Failure Modes
In practical AI governance and error analysis, distribution shift is frequently conflated with distinct failure modes such as catastrophic forgetting and data poisoning. Understanding the origin, mechanics, and required mitigations for each vulnerability is essential for deploying appropriate architectural safeguards.
Catastrophic forgetting (or catastrophic interference) is an internal, algorithmic failure mode occurring within sequential or continual learning systems 12131416. It arises when a neural network is trained on a new task and subsequently overwrites the internal parameter weights and hidden layer representations that encoded critical information from previous tasks 131417. Unlike distribution shift, which is caused by external changes in the environment's data generation process, catastrophic forgetting is a systemic consequence of shared parameters and the mechanics of gradient descent backpropagation in non-stationary environments 1314. For example, a model successfully fine-tuned to classify vehicles may permanently overwrite the feature extractors it previously used to classify animals.
Data poisoning, by contrast, is an adversarial, training-time vulnerability where malicious actors intentionally inject corrupted or manipulated data samples into the training dataset 1215191617. The objective of data poisoning is to covertly alter the model's logic, introducing targeted misclassifications or hidden backdoors that activate only under specific trigger conditions during deployment 151916. In medical imaging AI, for instance, standard convolutional neural networks (CNNs) can be compromised by poisoning as few as 250 samples - a mere 2.5% of a 10,000-image dataset - embedding false associations without triggering standard validation alarms 16. Unlike distribution shift, which is a naturally occurring statistical phenomenon, data poisoning is a deliberate and malicious security breach 1918.
Weight decay, while sometimes viewed conceptually alongside forgetting, serves as a controlled optimization tool rather than a failure mode. In stationary settings, it acts as a regularizer biasing weights toward zero to prevent overfitting. In online non-stationary settings characterized by distribution shift, adaptive weight decay can be utilized intentionally as a mechanism for "controlled forgetting." This allows an agent with finite parameter capacity to navigate the stability-plasticity trade-off, selectively discarding outdated historical information to free capacity for learning new, shifted environmental patterns 12.
| Failure Mode | Origin of Failure | Underlying Mechanism | Primary Mitigation Strategies |
|---|---|---|---|
| Distribution Shift | External (Environmental) | The real-world data generation process naturally diverges from the training data distribution ($P_{train} \neq P_{test}$) 13. | Distributionally Robust Optimization (DRO), Invariant Risk Minimization (IRM), Test-Time Adaptation (TTA) 192025. |
| Catastrophic Forgetting | Internal (Algorithmic) | Gradient descent backpropagation overwrites shared network weights essential for past tasks when optimizing for new incoming data 131416. | Elastic Weight Consolidation (EWC) via Fisher Information Matrix, Replay/Rehearsal Buffers, Knowledge Distillation 1314. |
| Data Poisoning | External (Adversarial) | Malicious actors inject subtly corrupted labels or hidden backdoor triggers into the training pipeline to subvert learned logic 151916. | Strict data auditing, anomaly and outlier detection (e.g., Isolation Forests), rigorous provenance tracking, input sanitization 1918. |
Domain-Specific Manifestations of Distribution Shift
When models optimized purely via ERM on static, localized datasets are deployed in dynamic global environments, their reliance on spurious correlations rather than true causal mechanisms becomes painfully evident. This structural fragility results in severe, sometimes dangerous, performance degradation across high-stakes industrial and clinical domains.
Healthcare Inequities and Demographic Shortcuts
Nowhere are the consequences of distribution shift more acute than in medical artificial intelligence. The vast majority of medical datasets used to train diagnostic models originate from the Global North. An analysis evaluating U.S.-based clinical machine learning applications found that 71% of algorithms were trained on patient data localized to just three states (California, Massachusetts, and New York), with the majority of the country entirely unrepresented 21. Globally, the geographic disparity is much starker: while the African continent bears 25% of the world's total disease burden, only 1% of the data used for global health AI originates from African countries 22.
When Western-trained diagnostic systems are diffused to the Global South, they encounter extreme covariate and concept shifts. Genetic diversity, dietary habits, environmental toxins, and baseline disease prevalences vary drastically, causing imported algorithms to routinely misdiagnose or entirely miss region-specific pathologies 2228. Furthermore, differences in medical hardware induce significant feature distribution shifts. Resource-constrained rural clinics frequently rely on older, lower-resolution imaging equipment or smartphone attachments, which differ radically from the high-end MRI and CT scanners used to construct standard Western training corpora 23242526.
This phenomenon is actively contributing to the "pilotitis" syndrome in developing nations. Multilateral organizations fund promising AI pilots - such as a Kenyan diagnostic program utilizing $50 smartphone microscopes to achieve 98.5% accuracy in detecting Plasmodium falciparum malaria, reducing inappropriate antibiotic prescriptions by 31% 33 - but these interventions rarely scale nationwide. Once the controlled pilot ends, unchecked localized data shifts, unstable internet infrastructure, and lack of interoperable data standards degrade the tool's efficacy in neighboring counties 2533.
Crucially, distribution shifts in healthcare also expose the tendency of high-capacity deep learning models to rely on what researchers term "demographic shortcuts." Extensive studies at institutions like MIT have demonstrated that diagnostic imaging models can easily predict a patient's self-reported race, gender, and age strictly from chest X-rays - a task that is entirely impossible for human radiologists 27. Consequently, rather than learning the actual physiological markers of a disease, the model correlates these demographic proxies with health outcomes. When the demographic distribution shifts between hospitals, the model's accuracy drops disproportionately for women, minority ethnic groups, and other historically marginalized populations 26272829. Subgroup-specific calibration gaps remain a pervasive failure point, and attempts at purely algorithmic fairness fixes often present harsh trade-offs, sometimes degrading overall model reliability for all groups 2829.
Financial Systems and Algorithmic Hiring
In the financial sector, machine learning models parse dense earnings calls, assess complex credit risks, and execute high-frequency trades at superhuman speeds. However, models trained on historical financial data are highly susceptible to temporal distribution shifts caused by sudden macroeconomic events or changing regulatory regimes. For instance, during the regional banking crisis of early 2023, quantitative trading algorithms utilized by major hedge funds executed inexplicably poor strategies. Post-mortem analyses revealed a severe concept drift: the models had learned to associate specific regional bank characteristics with stability based entirely on pre-2008 training data 37. The historical correlations between those features and financial health had fundamentally drifted over a 15-year period, rendering the models' predictions disastrously outdated 37.
Similar structural failures routinely occur in algorithmic hiring, human resources software, and corporate compliance systems. Systems designed to automate resume screening frequently suffer from covariate and label shift rooted in historical societal biases. When tech conglomerates trained hiring algorithms on 10 years of historical recruitment data, the models inherited the overwhelming class imbalances of the past (i.e., predominantly male engineering workforces). The models efficiently learned to utilize proxy features - such as heavily penalizing resumes containing the word "women's" (as in "women's chess club captain") or downgrading graduates from all-women's colleges - because the training distribution overwhelmingly correlated male-associated text features with the "successful hire" label 3031. These represent textbook cases of machine learning models optimizing for historically shifted correlations rather than extracting generalizable, causal indicators of candidate competence.
Scientific Computing and Hybrid Simulations
Beyond enterprise software, distribution shift poses a severe bottleneck in physics-informed AI and scientific computing. Machine Learning Force Fields (MLFFs) are increasingly utilized as computationally cheap surrogates for expensive ab initio quantum mechanical molecular simulations. However, because chemical spaces are practically infinite, MLFFs frequently encounter connectivity distribution shifts when simulating out-of-distribution molecular systems 32.
Similarly, in machine-learning augmented hybrid simulations (MLHS) - such as using a neural network to replace the Poisson pressure solver in the incompressible Navier-Stokes equations for fluid dynamics - distribution shift generates compounding errors. Because the outputs of the neural network feed recursively back into the simulation at subsequent time steps, the inputs rapidly drift away from the training distribution. This temporal shift leads to accumulating trajectory errors, rendering long-term physical simulations highly unstable without targeted tangent-space regularizers 63334.
Test-Time Degradation in Large Language Models
In the era of generative AI, the deployment of Large Language Models (LLMs) represents a unique frontier for distribution shift challenges. LLMs are subjected to continuous, open-ended "natural prompt distribution shift." When models move from sanitized pre-training and alignment phases into the real world, user behavior, regional dialects, intent complexities, and the structural nature of queries naturally evolve 3536.
The LLM Evaluation under Natural prompt Shift (LENS) framework quantified this degradation meticulously. Across a large-scale evaluation utilizing 192 real-world post-deployment prompt shift settings, 81 trained models, and 4.68 million training prompts, the data revealed a massive vulnerability: even moderate shifts in user prompting behavior resulted in an average performance loss of 73% in the instruction-following capabilities of deployed LLMs 35. This degradation is particularly prevalent when models interact with localized geographic user groups or latent sub-communities entirely unrepresented in the foundational alignment data 35.
Distribution shift directly exacerbates the rate of LLM hallucinations - instances where the model generates grammatically flawless and logically coherent text that contains factually fabricated or inconsistent information 37464738. Research mapping the internal dynamics of transformers indicates that as models process out-of-distribution prompts, their internal token probabilities and latent state spaces shift measurably toward uncertainty. The model essentially hallucinates to bridge the probability gap created by the shifted input, generating misinformation while maintaining structural fluency 374647. Without proper mitigations, hallucination rates across modern LLMs vary severely, scaling aggressively with domain complexity and input length.
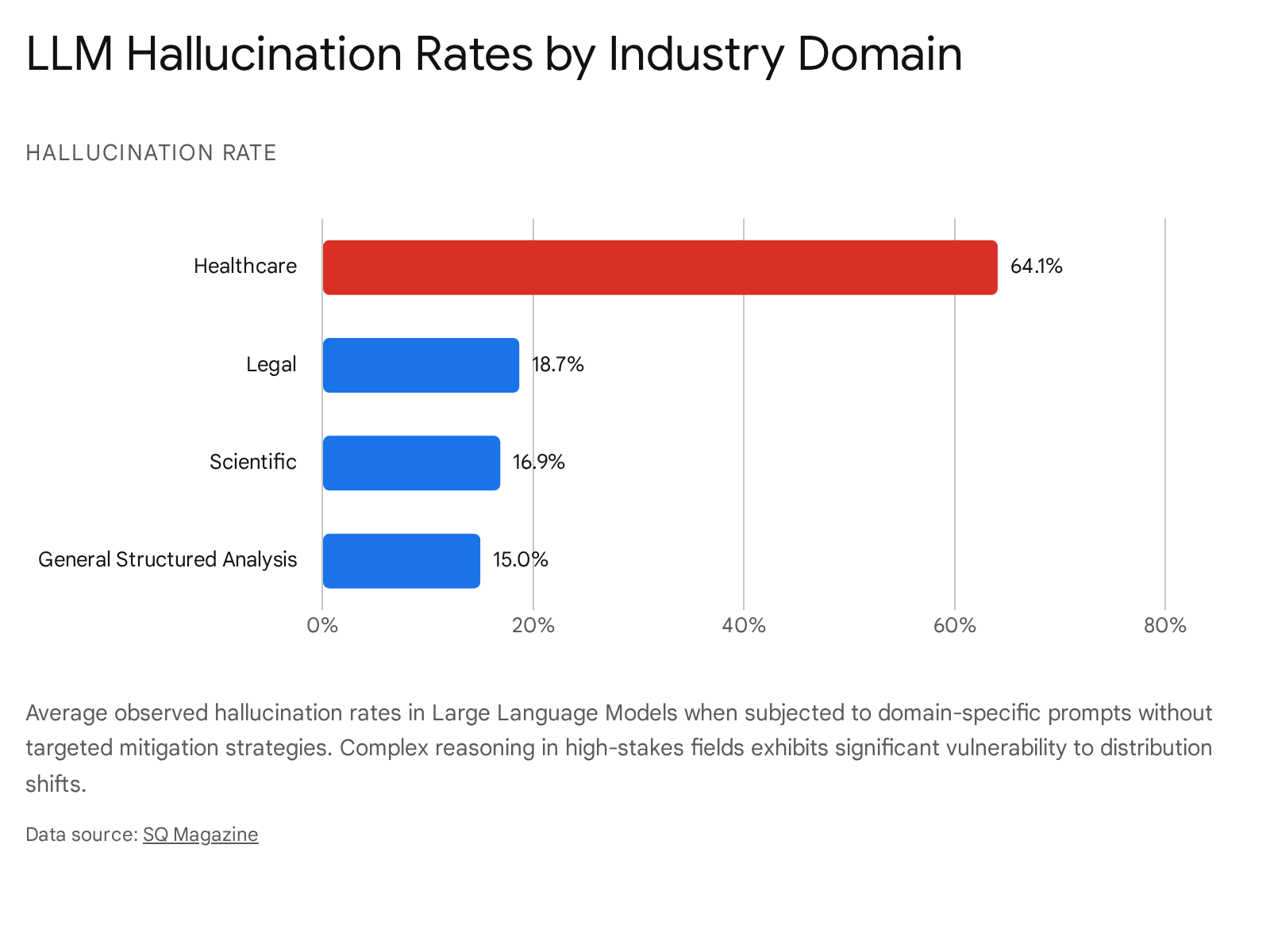
The breakdown extends to complex inference techniques. The widely utilized Chain-of-Thought (CoT) reasoning paradigm - which prompts the model to output intermediate logical steps before a final answer - is exceptionally sensitive to semantic distribution shifts involving latent disjointness 3950. Controlled experiments featuring arithmetic and logical tasks with Wasserstein-type latent permutations reveal that CoT performance drops sharply under distribution shift. This phenomenon exposes a critical truth: contemporary LLMs often rely on shallow semantic pattern replication rather than possessing authentic, generalizable logical deduction capabilities. When the distribution of the test prompt deviates even slightly from the training exemplars, the seemingly coherent reasoning chain breaks down, leading to mathematically or factually impossible conclusions 3950.
Algorithmic Mitigation Strategies and Optimization Frameworks
Addressing the inherent fragility caused by distribution shift requires moving beyond standard ERM. A variety of advanced optimization frameworks and adaptive methodologies have been engineered to yield models capable of robust out-of-distribution (OOD) generalization. These span from training-time interventions to dynamic inference-time recalibrations.
Invariant Risk Minimization (IRM)
Invariant Risk Minimization (IRM) is a paradigm designed to estimate nonlinear, causal predictors by leveraging data from multiple distinct training environments 25404142. The core mathematical philosophy of IRM asserts that any dataset is composed of both spurious correlations (which fluctuate across domains) and causal mechanisms (which are strictly invariant). By evaluating the model simultaneously across diverse training environments, the IRM objective enforces a gradient norm penalty to ensure that the learned data representation acts as an optimal classifier across all environments simultaneously 254142.
When executed successfully, IRM forces the neural network to discard environment-specific biases and rely solely on invariant causal features, theoretically granting the model extraordinary extrapolation capabilities well outside the noise levels seen in training 4042. However, practical, large-scale implementations of IRM (such as IRMv1) encounter severe theoretical and empirical limitations. The objective function involves a highly challenging, non-convex, bi-level optimization process that is notoriously sensitive to random seed initialization 414254. Empirical studies on deep models using Natural Language Inference (NLI) datasets reveal that IRM's performance is heavily dependent on massive dataset sizes, a high prevalence of environmental bias, and strict "linear general position" assumptions that are exceedingly difficult to satisfy in deep, non-linear representation spaces 40414254. Consequently, in highly complex, naturalistic settings, IRM's advantage over standard ERM shrinks considerably, often resulting in unstable performance across initialization seeds 4041.
Distributionally Robust Optimization (DRO)
Distributionally Robust Optimization (DRO) adopts a pessimistic, minimax game-theoretic approach to environmental uncertainty. Rather than minimizing the expected loss on the empirical training distribution, DRO seeks to compute an estimator that minimizes the worst-case expected loss over an "ambiguity set" - a mathematically defined family of probability distributions that reside within a specified geometric or statistical distance from the observed training data 1943565758.
The geometry of the ambiguity set is typically defined using either f-divergences (such as Kullback-Leibler) or optimal transport costs (such as the Wasserstein distance) 5758. The optimal transport formulation is particularly advantageous for machine learning because its distributional uncertainty region encompasses distributions containing samples that fall completely outside the immediate support of the empirical training measure, naturally generating robust out-of-sample generalization 57. DRO is highly effective for applications involving critical subpopulation shifts, extreme rare events, and fairness constraints, as the min-max formulation prevents the model from ignoring low-frequency but safety-critical data points 56.
However, by continuously optimizing for an adversarial worst-case scenario that occurs after the decision is made, DRO estimators can frequently become overly conservative, dampening overall model performance in average-case scenarios 1958. Furthermore, the minimax formulations require solving highly complex conic or semi-definite programming equations, making large-scale deep learning applications computationally expensive. The recent release of dedicated Python libraries (like dro) aims to abstract this mathematical complexity into standard APIs, increasing accessibility for production engineering teams 5658.
Test-Time Adaptation (TTA) and Domain Adaptation
Instead of attempting the computationally gargantuan task of learning a universally robust model during training, Test-Time Adaptation (TTA) allows a deployed model to dynamically update its parameters on the fly using incoming, unlabeled test samples during inference 20324460614546. When an unpredicted distribution shift occurs, TTA algorithms bypass the need for access to the original source data or new ground-truth labels.
Adaptation mechanisms vary heavily by architecture. In computer vision and image quality assessment, TTA frequently involves minimizing the entropy of the model's output distribution, computing auxiliary group contrastive losses, or exclusively updating the batch normalization layers to rapidly align internal feature representations with the new, shifted incoming data statistics 44604547.
For foundational Large Language Models, emerging Test-Time Learning (TTL) paradigms formulate adaptation as input perplexity minimization 61. By actively isolating high-perplexity (highly informative and heavily shifted) out-of-distribution samples in the inference stream, the system applies lightweight, targeted parameter updates - such as Low-Rank Adaptation (LoRA). This enables the LLM to recalibrate to specialized domain knowledge or linguistic shifts organically at runtime without requiring expensive full-parameter retraining, completely avoiding the risk of catastrophic forgetting 6146.
Computational Economics and Hardware Overhead
The practical feasibility of deploying these shift-mitigation strategies depends entirely on their computational burden. As foundational AI architectures scale to trillions of parameters, hardware utilization, specifically floating-point operations per second (FLOPs), has become an absolute constraint 484967. Historical analyses indicate that the cost of compute utilized for the final training runs of milestone ML systems has grown by approximately 0.49 orders of magnitude (OOM) per year since 2009 48. To contextualize this scale, training a frontier model in the GPT-4 class currently requires between 1,174 and 8,800 NVIDIA A100 GPUs functioning continuously, depending on the assumed Model FLOPs Utilization (MFU) 67.
Requiring a system of this scale to be fully retrained every time it encounters a geographical or temporal distribution shift is economically and logistically impossible. Consequently, the computational overhead introduced by advanced mitigation frameworks dictates their adoption in the industry.
| Mitigation Framework | Phase of Intervention | Core Mathematical Mechanism | Computational Cost / FLOP Overhead |
|---|---|---|---|
| Empirical Risk Minimization (ERM) | Training Time | Minimizes average loss on static empirical training data samples. | Baseline computational cost. Highly efficient in static environments but entirely vulnerable to target shifts 4056. |
| Invariant Risk Minimization (IRM) | Training Time | Bi-level optimization computing gradient norm penalties to enforce invariance across multiple diverse environments 42. | High overhead during pre-training. Requires continuous inner optimization constraints and multi-environment tracking logic 42. |
| Distributionally Robust Opt. (DRO) | Training Time | Minimax optimization over an adversarial ambiguity set (e.g., Euclidean/Wasserstein distance bounds) 195758. | Exceedingly high computational complexity. Solving underlying conic or semi-definite programming equations at scale is expensive 58. |
| Test-Time Adaptation (TTA) | Deployment (Inference) | Unsupervised, dynamic gradient steps on a restricted subset of parameters (e.g., BN layers, LoRA) utilizing live test data streams 6145. | Minimal overhead. Circumvents massive retraining FLOP costs, preserves memory, and does not require costly ground-truth labels 3261. |
Conclusion
The transition of artificial intelligence from controlled laboratory benchmarks to chaotic, real-world deployment continuously exposes the severe vulnerability of these systems to distribution shift. The statistical i.i.d. assumption upon which modern empirical risk minimization is built is effectively dead in production environments. Whether manifesting as an algorithmic hiring bias triggered by evolving workplace demographics, the catastrophic misdiagnosis of patients in the Global South due to disparities in imaging hardware and genetics, or the rapid reasoning degradation and hallucinations of LLMs processing novel user prompts, the implications of shifted data are profound and systemic.
Addressing these failures requires a structural departure from traditional training paradigms. While advanced frameworks like Invariant Risk Minimization and Distributionally Robust Optimization provide formidable theoretical foundations for causal discovery and worst-case robustness guarantees, they currently face steep computational costs and non-convex optimization hurdles in deep learning contexts. Conversely, dynamic solutions like Test-Time Adaptation present a highly pragmatic approach for the modern scale of AI, allowing models to continuously and cheaply recalibrate to environmental volatility at inference time. Ultimately, bridging the widening gap between testing accuracy and deployment reliability demands rigorous, data-driven continuous monitoring, the diversification of global training corpora, and the widespread adoption of adaptive architectures capable of weathering the inherent non-stationarity of the real world.